

Статистическая информация, собираемая PostgreSQL, имеет большое влияние на производительность системы. Зная статистику распределения данных, оптимизатор может корректно оценить число строк, необходимый размер памяти и выбрать наиболее быстрый план выполнения запроса. Но в некоторых редких случаях он может ошибаться, и тогда требуется вмешательство DBA.
Помимо информации о распределении данных, PostgreSQL также собирает статистику об обращении к таблицам и индексам, вызовов функций и даже вызовов отдельных запросов (при помощи расширения pg_stat_statements). Эта информация, в отличие от распределений, больше нужна администраторам, нежели для работы самой базы, и очень помогает для нахождения и исправления узких мест в системе.
В докладе будет показано, каким образом статистическая информация собирается, для чего она важна, и как ее правильно читать и использовать; какие параметры можно «подкрутить» в тех или иных случаях, как подобрать оптимальный индекс и как переписать запрос, чтобы исправить ошибки планировщика.
Доклад состоит из двух частей:

Первая часть очень теоретическая. Посмотрим, как работает планировщик, как собирается статистика и зачем, немножко вспомним теорию вероятности.
Вторая часть будет более практическая: почему планировщик иногда косячит, какие грабли и как их можно обходить, и в конце будет мониторинг (как понять, что у нас какие то проблемы с базой и из-за чего они).

Как выполняется запрос в PostgreSQL? Сначала приложение устанавливает соединение с PostgreSQL, передает тело запроса напрямую, используя connection pool (pgbouncer и т.п.). Дальше этот запрос парсится на токены и разбивается на части. Строится дерево, передается в rewrite system, и дальше самая интересная часть — planner / optimizer. В этом месте у нас генерируется план запроса.
Планировщик один и тот же запрос может выполнить кучей разных способов, причем, чем больше у нас таблиц, тем больше способов у нас будет получаться, эта зависимость растет как факториал. Пять таблиц — это, допустим, какая-то константа 120, 10! — это уже будет очень большое число. То есть у нас получается очень много планов, если у нас очень много таблиц, поэтому не стоит делать запросы с 20-тью join-ами, которые человек-то не может нормально прочитать, а планировщик тем более будет тупить на этом моменте, и не сможет выбрать самый оптимальный план.
Итак, получили план, далее отправляем это на executor, который план пошагово выполняет и потом генерирует результат клиенту.

Генерируется множество планов выполнения. Для каждой такой элементарной операции (чтение данных с таблицы, сортировка, объединение результатов) оценивается число строк и время выполнения в абстрактных попугаях.

Создадим тестовый пример. Допустим, у нас есть абстрактный новостной сайт, на этом сайте у нас есть новости и у каждой новости есть категория, числовой рейтинг, и поле content с текстом.

Посмотрим что получилось: команда \d показывает информацию об объекте в psql. Видим много интересного: какие индексы, какие поля, какие атрибуты, в общем, все что ожидалось.

Теперь заполним эту таблицу тестовыми данными. Поле категории id будет числами от 0 до 99, которые встречаются с одинаковой вероятностью. Поле content будет словом «hello world», и в конце мы добавим к нему числовой индикатор id. А рейтинг у нас будет нормальным распределением с математическим ожиданием 50 и стандартным отклонением в 10. Сгенерируем 10 000 таких записей.

Вот что получилось. Рейтинг — это число около 50-ти, category_id — целые числа и поле content.

Посмотрим план выполнения запроса COUNT. Очевидно, что тут sequence scan, последовательные чтения. То, что нас интересует — это число строк (10 000). Откуда планировщик узнал, что у нас 10 000 строк? Только что создали таблицу, заполнили ее, а планировщик уже знает.

Есть системная таблица pg_class, в которой хранится информация о каждой таблице. В ней есть два таких выгодных поля: reltuples (число строк в этой таблице) и relpages (число страниц, которые занимает данная таблица). Эти числа не актуальные, они записываются в трех случаях:
- по таблице прошелся процесс auto-vacuum, прочитал таблицу и обновил поля;
- по таблице прошелся процесс auto-analyze, прочитал всю или часть таблицы и обновил эти же поля;
- мы создали индекс или провели еще какую-то DDL операцию по таблице, в этом случае тоже могут обновиться все эти поля.
Вроде бы хорошо, что у нас есть некие значения, но они могут быть не актуальные. Что в этом случае делать? Нам хотелось бы актуальные значения иметь. Планировщик в посгресе не может быстро посчитать число строк в таблице (потому что ему нужно их все читать), но он может быстро посчитать число страниц, которые занимает данная таблица. И, предполагая, что число строк на странице почти не изменилось после auto-vacuum или analyze, с помощью такой пропорции можно оценить число строк довольно-таки точно. Почему 10 000? После того как я записал данные, прошел процесс auto-analyze (это можно посмотреть в таблице pg_stat_user_tables, в ней хранятся всякие счетчики мониторинга).

Почему вообще запустился процесс auto-analyze, и чем он занимается? Запускается он, если сумма вставленных, обновленных и удаленных строк превышает некое пороговое значение. Пороговое значение рассчитывается на основе двух параметров:
- фиксированная константа, которая задается в config или для конкретной таблицы через ALTER TABLE (autovacuum_analyze_threshold, фиксированная часть, по умолчании она равна 50-ти);
- параметр autovacuum_analyze_scale_factor: доля строк в таблице, при изменении которых запустится analyze (по умолчанию, это 0.1 или 10%).
10 процентов — это довольно неплохо, но иногда стоит его немножко уменьшить, в каких-то сложных случаях. Например, таблица, в которой храним очередь: сейчас в ней 5 записей, а через минуту уже миллион, тогда желательно статистику обновлять почаще.
Еще параметр, который есть у auto-analyze — это default_statistics_target. Он указывает, сколько страниц и строк мы возьмем из таблицы, и еще влияет на ряд других параметров, про которые речь пойдет позже. По умолчанию этот параметр равен 100. Что делает auto-analyze? Он читает 300 * stats_target страниц, и из этих страниц он выбирает 300 * stats_target строк. Всего по-умолчанию он прочитает 30 000 строк из таблицы и на основе этих данных заполнит таблицу pg_statistic.

Эту таблицу читать не очень удобно, поэтому придумали view pg_stats, которое содержит то же самое, но в более читабельном формате. Что у нас тут есть? Одна строка этого вью представляет информацию об одном поле в таблице. Есть поле tablename, attname (имя таблицы, имя поля), и дальше начинается самое интересное:
- null_frac говорит нам как процент строк для этой таблицы является null;
- avg_width — средняя длина поля в таблице (для полей фиксированной длины это поле нам ничего не скажет);
- n_distinct показывает, сколько в этом поле различных значений;
- массивы most_common_vals и most_common_freqs содержат самые часто встречающиеся значения поля и соответствующие им частоты;
- histogram_bounds — массив интервалов, причем вероятность попасть в каждый интервал примерно одинаковая.

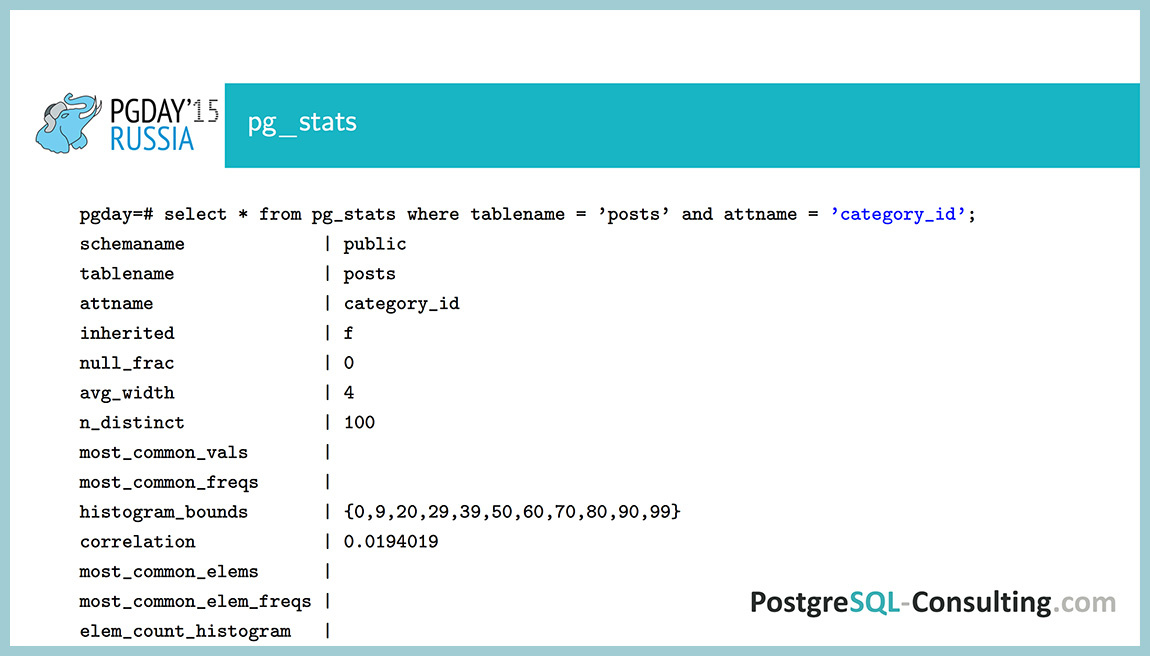
Мы создали таблицы, посмотрим, что записалось после analyze для поля ID. Мы видим, что null_frac равен нулю, т.е. все значения в таблице – NOT NULL, потому что это primary key, а он всегда NOT NULL. Средняя длина – 4 (integer), n_distinct равен -1. Почему -1, а не десять тысяч?
n_distinct может быть как больше нуля, так и меньше нуля. Если больше нуля, то он показывает число различных значений, а если меньше нуля, то показывает долю от числа строк, которые будут принимать различные значения. То есть, допустим, если было бы -0.5, то это означало бы, что половина строк у нас содержит уникальное значение, а вторая половина содержит их дубликаты. В данном случае он равен -1, то есть все значения разные.
Поля most_common_vals и most_common_freqs в данном случае пустые, потому что у нас все значения встречаются с одинаковой вероятностью, и нет такого, чтобы какие-то встречались чаще, чем другие. А histogram_bounds содержит 100 интервалов. most_common_vals, most_common_freqs и histogram_bounds задаются параметром default_statistics_target. В данном случае это 100 интервалов и 100 различных значений может хранится максимум.
Последнее поле – это корреляция. Это статистический термин, показывающий, есть ли линейная зависимость между двумя случайными величинами. В данном случае идет корреляция между значением поля и физическим положением его на диске. Этот параметр может принимать значение от -1 до 1. Возьмем пример. Корреляция между случайными величинами как рост человека и его вес, какая она будет? Скорее всего, она будет больше нуля. Это показывает, что при увеличении роста у нас, скорее всего вес тоже будет расти. Конечно, не факт, но такое может быть. Если бы она была меньше нуля, то у вас была бы обратная зависимость – с увеличением роста вес бы уменьшался. А если бы она была равна нулю, то это означало бы, что эти вещи, скорее всего, независимые, то есть с любым ростом может быть любой вес.

Как подсчитывается селективность разных условий? Запрос SELECT COUNT(*), где ID < 250. Выбирается план Index Only Scan, и видим, что извлекается 250 строк. Почему 250? Так как у нас в массиве most_common_vals и most_common_freqs нет каких-то значений, которые встречаются чаще, чем другие, планировщик берет информацию из histogram_bounds. Еще раз повторюсь, что вероятность попасть в каждый интервал примерно одинаковая. По такому критерию он и создавался. Планировщик смотрит, сколько интервалов попадает под данное условие. Под него попадает первый интервал (от 1 до 100), второй интервал (от 100 до 200) и половина третьего. То есть два с половиной интервала. А всего таких интервалов 100, и, таким образом, поделив 2.5 на 100, мы получаем selectivity 2.5%. Это процент строк, которые удовлетворяют данному условию. Число 100 получается как selectivity, умноженное на cardinality. Cardinality – это общее число строк, я уже говорил, как оно считается. Получаем 2.5% от 10 тыс., то есть 250 строк.

Теперь такой пример. Поле CategoryID: для него n_distinct равен 100, то есть в это поле мы записывали числа от нуля до 99, которые распределены равномерно. Тут мы видим, что histogram_bounds пустой, но зато полностью заполнены массивы most_common_vals и most_common_freqs. В них числа отсортированы по частоте, то есть самое популярное значение в этой таблице – это 98, которое встречается в 1.21% случаев. Корреляция здесь на уровне 0, то есть все данные здесь равномерно перемешаны на диске, нет такого, что 1 хранится в начале таблицы, а 99 – в конце таблицы. Всего значений у нас 100, и default_statistics_target у нас тоже равен 100, поэтому все значения у нас сюда поместились. Если бы не поместилось, что будет в следующем примере, то там будет по-другому.

Как в таком случае рассчитывается selectivity для условия CategoryID = 98? Просто дается значение из most_common_vals. Если у нас такое значение есть, то просто берем соответствующую частоту и считаем ее равной selectivity. В данном случае у нас 121 строка выбирается.

Попробуем теперь поменять default_statistics_target для этого поля. Поставим его 10, хотя по умолчанию у нас было 100. Сделаем analyze. Команда \d+ показывает, кроме всего прочего, еще и значение stats_target, если мы его меняли. Вот, что у нас получилось.
Теперь у нас most_common_vals и most_common_freqs пустые, но зато теперь у нас есть поле histogram_bounds. Как в этом случае рассчитывается selectivity?

По такой формуле. То есть значение у нас может быть либо null, либо most_common_vals, либо histogram_bounds. В числителе есть вероятность того, что значение будет histogram_bounds, а в знаменателе у нас число различных значений, кроме тех, что уже есть в most_common_vals. sumcommon – это сумма всех значений из массива most_common_freqs. Неочевидная формула, но если разобраться, понятно, почему это так работает. Различные значения распределены равномерно по массиву histogram_bounds. Хотя у нас получается selectivity 1%, и это уже другая оценка, в сто строк вместо 121. Но 100 или 121 – в данном случае это не проблема, даже если у нас значение отличается на полпорядка, то это бывает хорошая оценка.

Посмотрим теперь, когда у нас есть два условия: CategoryID = 98 и id < 250, то есть комбинируем два условия. Selectivity здесь считается как произведение selectivity, то есть по формуле из теории вероятности: вероятность того, что произойдет два события одновременно, равна вероятности того, что произойдет первое событие, помноженная на вероятность того, что произойдет второе событие. Это определение статистической зависимости, то есть полагается, что эти колонки никак друг от друга не зависят. В данном случае так и есть, что они не зависят друг от друга. Получается справедливая оценка, 2.5 строки. Дробную часть мы отбрасываем и получаем 2 строки. А реально, 2.5 строки — тоже хорошая оценка.
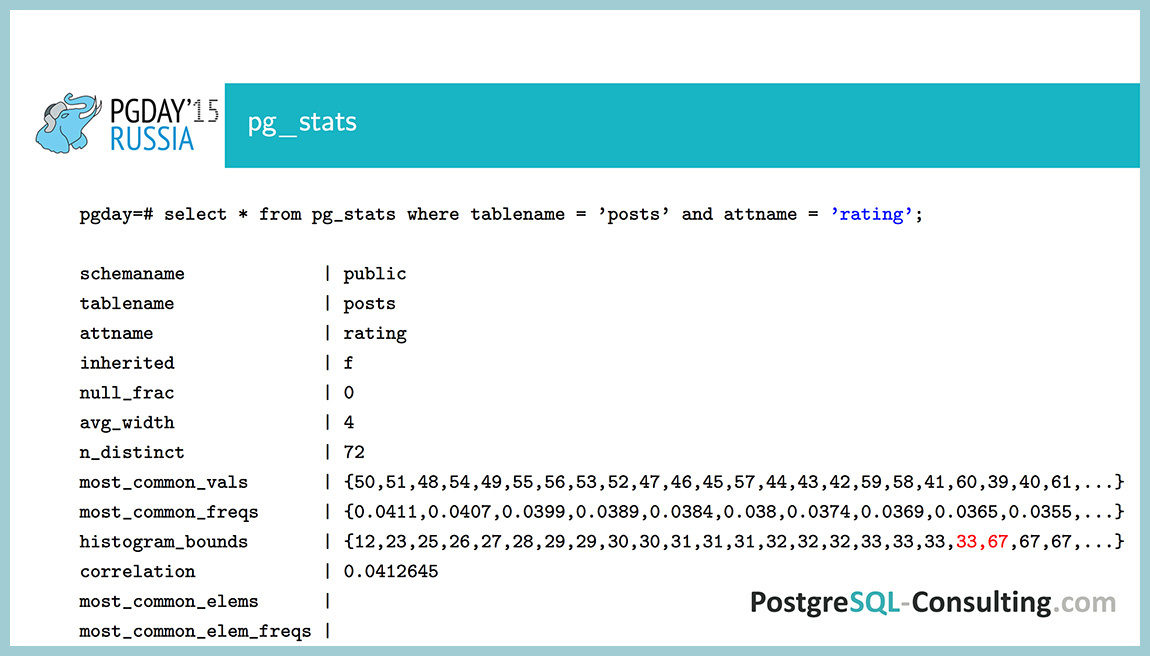
В качестве демонстрации посмотрим, как выглядит неравномерное распределение в поле rating. Тут заполнены и most_common_vals, и most_common_freqs, и даже гистограмма есть. Этого должно быть достаточно, чтобы понять, что здесь данные неравномерны. Почему так? Если бы они были равномерно распределены, то вероятность для каждого значения была бы одна 1/72, то есть около 1%. Мы видим, что есть значения с вероятностью около 4%. Заметно неравномерное распределение.

Помимо того, что собирается информация о распределении отдельных полей, также собирается информация о распределении значений функциональных индексов. Это не документировано, нигде такой информации нет, доступ к этой информации тоже не очень удобный. Если вместо tablename мы поставим название функционального индекса, то получим информацию о том, что в нем хранится.
Допустим, вы создали индекс, который хранит значение rating в квадрате. Конечно, пользы никакой от этого нет, только в качестве демонстрации, чтобы понять. Если мы сравним это с предыдущим, то увидим, что значение просто возводится в квадрат. То есть если оно было 50, то стало 2500. И histogram_bounds, соответственно, тоже будет возводиться в квадрат.
Еще есть такая недокументированная штука, как поменять statistics_target для функционального индекса: ALTER INDEX ALTER COLUMN … set statistics — этого почему-то тоже нет в документации ALTER INDEX.

До этого были примеры, где мы сравнивали число с какой-то константой, CategoryID у нас равно 98. А если у нас не константа, а подзапрос или результат какой либо функции, что тогда с этим делать? Планировщик предполагает, что есть какие-то default estimators, то есть просто берет значение selectivity в виде константы. Вероятность того, что поле равно чему-то, скорее всего, где-то 0.5%. А вероятность того, что что-то меньше чего-то будет где-то 33%. Когда мы сравниваем одну колонку с другой, такое тоже может быть.

В качестве примера: ID < Select 100. Информации никакой нет, поэтому число строк оценивается как одна треть, то есть selectivity = 0.33(3).

Все, о чем я говорю, можно посмотреть и руками, запросами, не ходя в pg_stats. Число строк мы смотрим как SELECT COUNT(*), число строк с различными CategoryID — как SELECT COUNT(DISTINCT category_id).

Это все хорошо, но в больших таблицах мы так посмотреть не можем. Это будет очень долго.

SELECT COUNT(*) по таблице в несколько гигабайт — это уже очень медленно, а если еще делать группировки — то совсем медленно. Если нам требуется не одно поле, а несколько, стоит посмотреть в pg_stats. Более удобный формат и больше информации.

Много полезной информации есть в pg_stats, stats_target можно менять для отдельных колонок в таблицах, настройки autovacuum и autoanalyze можно менять для отдельных таблиц, и тут проявляется статистическая независимость условий. Если у нас несколько условий, то они считаются независимыми, потому что никакой другой информации нет.

Все это хорошо, но зачем это надо? Если бы у нас был идеальный планировщик, нам ничего этого не надо было, у нас бы все работало, план всегда был бы оптимальный. Но планировщик у нас не идеальный, и иногда приходится в него вникать и смотреть, что можно с этим сделать.

Есть полезный прием: таблица foo, 73GB, очень большая, число строк можно посмотреть в reltuples. Оказывается, что в ней 73 млн. строк.

У нас есть запрос: SELECT * FROM foo WHERE bar_id = 183, нужно отобрать из них последние 20 записей. Если бы у нас была таблица posts, требовалось бы отобрать 20 новостей определенной категории, например. Очень типичный запрос. У поля n_distinct = 50, то есть 50 различных значений, а всего строк у нас 70 млн. И мы видим, что число 20 встречается в 55% случаев. То есть распределение крайне неравномерное. Можно поставить индекс на (bar_id, id), он будет тут работать, но таблица у нас на 73 ГБ. Получается, что этот индекс вполне может занимать 5-7 ГБ. Не очень хочется такой индекс создавать.

Если мы посмотрим, то на 4 значения приходится 88% записей. Такая мысль возникает: «А может, мне их выкинуть из индекса? Зачем они там нужны? У нас будет индекс в 10 раз меньше».

Возьмем и выкинем частично из индекса эти четыре значения bar_id. Размер индекса стал 758 МБ. Для всех значений, которые не входят в эти 4, он у нас будет работать, и все будет очень быстро выполняться.
Вопрос из зала: что если, параметры для исключения bar_id изменятся?
Если мы знаем, что у нас есть такие-то очень частые значения, то мы можем “захардкодить”. А если такого не бывает, что сегодня у нас распределение такое, а завтра оно обратное, то это не подходит очевидно. Это подходит именно для этого случая, когда мы знаем, что у нас таблица медленно растет, и если что-то не будет работать, то мы это уже заметим. То есть мы увидим, что индекс будет расти.
Так вот, индекс работает для всех значений, кроме четырех. Оказывается, что он нам не нужен. Если у нас значение 20 встречается в каждой второй строке, то мы просто берем индекс по primary key, считываем последние 40 строк и, скорее всего, 20 из них будут теми, которые нам нужны. А в худшем случае мы считаем не 40 строк, а 200 или даже 2000. Но это ерунда, 2000 строк считать по индексу – не проблема. Таким образом, мы этот случай разобрали.

Более такой абстрактный случай. Допустим, у нас есть условия: a равно некому значению и b равно некому значению, и мы думаем, как нужно создать индекс? Можно создать индекс по полю a, по полю b. Можно создать два индекса или индекс по полям a и b одновременно, или в обратном порядке. Можно создать частичный индекс по a, где b равно чему-то. А, может, нам индекс вообще не нужен. Как можно понять, какой индекс нужен на этот запрос?

Нужно смотреть, с какими параметрами он вызывается. Если у нас включено логирование запросов, мы можем поймать самые медленные. Можем посмотреть, с какими параметрами они вызвались, какие распределения есть по этим значениям. Зная, с какими параметрами вызывается запрос, какие распределения у нас в этих данных, мы можем прикинуть, какое selectivity у каждого из этих условий. Оно для каждого значения будет разным, но, в среднем, оно может быть постоянным.
Если какое-то условие с небольшим selectivity (в данном случае, это процент строк, который удовлетворяет данному условию), то мы его берем и ставим индекс. Если есть другое условие с небольшим selectivity, мы можем поставить оба индекса, если нам не хватает одного поля. А вот если selectivity большое (поле типа boolean, которое в 90% случаев равно false), то индекс нам, скорей всего, не нужен по нему. А если и нужен, то мы будем делать некий частичный индекс, скорей всего, чтобы эти 90% в индексе не тащить, пользы от них никакой не будет.

Какие есть вообще грабли с планировщиком…

Планировщик не всегда работает идеально. Например, у нас нет cross column статистики. Информацию о зависимости одного поля от другого мы никак не храним. В качестве примера, рассмотрим content < ‘hello world 250’. Условие не очень приятное. У нас выбирается 1600 строк, sequential scan получается. А если мы сделаем два условия: одно из них то же самое, а второе – id < 250, то оценка отличается на полпорядка: 142 строки против 1697 строк. Это еще не очень плохо. Если бы у нас было не два условия, а три, которые зависят друг от друга, или selectivity было поменьше, то оценка может отличаться на много порядков.

Вот такая проблема, которую сложно обойти хорошим способом. Можно как-то “захачить”, использовать информацию о том, что есть default estimator, который нам возвратит оценку в 1/3 от всех строк и вот такое вот вкрутить. Не рекомендуется так делать постоянно, но иногда так можно сделать, если больше ничего сделать нельзя.
Тут берется поле id и добавляется к нему по abs(id) < 0. Что это означает? Это условие заведомо ложное, abs – это модуль числа, а модуль числа не может быть меньше нуля. Это условие всегда false, оно не влияет на результат, но оно влияет на план. Оценка тут увеличится примерно на одну треть для этого условия, и план станет чуть получше. Можно хаки такие комбинировать, использовать знание о default estimator’ах. Наверное, можно придумать и получше, но в данном случае более-менее нормально получилось.

Следующая проблема: нет статистики по JSON полям. В таблице pg_stats никакой информации по этому полю нет. Если с этим полем у нас какое-то условие, где оно NULL, или по нему делается JOIN, планировщик ничего об этом не знает, план может быть не совсем оптимальный. Можно использовать поле JSONB, там все есть.

Следующие грабли – операторы intarray не используют статистику. Создадим тестовую таблицу, в которую запишем массив, в котором одно и то же значение в каждой строке: 100. Если мы посмотрим план выполнения запроса “входит ли значение 100 в этот массив”, то мы видим, что тут все нормально, все строки выбрались и план все правильно показывает.

Но, если мы создадим extension intarray и выполним тот же самый запрос, то окажется, что используется default estimator и он выбирает у нас 0.1%. Иногда на это можно наступить, если используются такие операторы и есть intarray, то оценка может быть не очень хорошей.
Федор Сигаев, из зала: я прокомментирую, можно? На этой неделе был “закоммичен” патч, который лечит эту проблему, но, к сожалению, это будет только в 9.6.

Пока этого патча нет, можно это как-то обходить. intarray переписывает оператор, заменяет его на свой. Если использовать посгресовый оператор в данном случае, то у нас все будет работать с использованием обычного индекса без intarray.

Следующая проблема – это когда у нас не хватает statistics_target. Допустим, бывают большие таблицы, в которых хранится небольшое число различных элементов. В таком случае, оценка какого-нибудь редкого элемента (которого может даже и не быть) может отличаться на несколько порядков. Я уже об этом говорил про эту формулу, она считает, что все оставшиеся значения распределены равномерно, но обычно это не так. В данном случае, мы можем выкрутить статистику до 10000 или до 1000. Есть артефакты, конечно. Analyze по этой таблице будет медленнее работать и план будет строиться чуть медленнее, но иногда такое приходится делать. Например, когда join идет по нескольким таблицам и не хватает статистики.

Последняя часть – про мониторинг. Я говорил про статистику по распределениям (собирается процессом auto analyze). Кроме того, процессом auto collector собирается статистика по всяким счетчикам. Тут довольно много интересного, рекомендую заглянуть во все “вьюшки” pg_stat_*. Про часть из них расскажу.
pg_stat_user_tables – я про него уже говорил, одна строка представляет собой информацию по одной таблице. Что в ней есть интересного? Сколько по этой таблице было sequence scan’ов, сколько эти сканы выбрали строк, сколько было index scan’ов, сколько index scan’ы выбрали строк, когда был последний autovacuum и autoanalyze, сколько их было всего. Также есть число вставленных записей, число удаленных записей, число живых записей. Кажется, зачем это нужно? Допустим, если у какой-то таблицы большое число строк, которые извлечены, используя sequence scan, и сама таблица тоже большая, то, скорей всего, ей не хватает какого-то индекса. У нас есть в репозитории такой запрос, который показывает TOP таблиц, по которым у нас больше всего сканов, и можно понять, где там добавить индекс.
pg_stat_user_indexes – здесь хранится информация по отдельным индексам. Можно понять, допустим, сколько раз данный индекс использовался. Полезно, если мы хотим понять, используется созданный нами индекс, или мы хотим какие-то лишние индексы взять и удалить.
pg_stat_user_functions – информация по вызовам функций. Для каждой функции есть поля, которые показывают, сколько раз она вызывалась, сколько времени это заняло. Полезно знать, если у нас много используется функций.

Это статистика stat collector’а с момента старта, и она не обнуляется сама по себе, даже при рестарте. Ее можно сбросить командой pg_stat_reset(). Она просто сбросит все счетчики. Проблем от этого, скорей всего, никаких не будет, но можно посмотреть, как поменялась картина после того, как вы что-то поменяли.
Параметр конфига track_io_timing показывает, собирать ли статистику по дисковому вводу-выводу. Это очень полезно для следующего пункта про pg_stat_statements, я чуть позже покажу про это. По умолчанию он выключен, стоит включить, но предварительно проверить overhead, в документации сказано, как это сделать.
track_functions можно включить для того, чтобы собиралась статистика по вызовам функций pg_stat_user_functions. Еще такой случай, если у нас очень много таблиц или очень много баз, то статистики может быть очень много, и stats collector пишет ее прямо в файл, это постоянная дисковая нагрузка на запись не очень полезная. Мы можем вынести stats_temp_directory на RAM-диск, и тогда будет писаться в память. При выключении посгреса просто запишется в эту директорию. Если аварийное какое-то выключение, мы потеряем статистику, но ничего страшного из-за этого не будет.
Поле track_activity_query_size говорит, какой длины запросы мы собираем в pg_stat_activity и pg_stat_statements. По умолчанию собирается 1024 байта от запроса, иногда стоит его немножко поднять, если у нас длинные запросы, чтобы их можно было целиком прочитать.
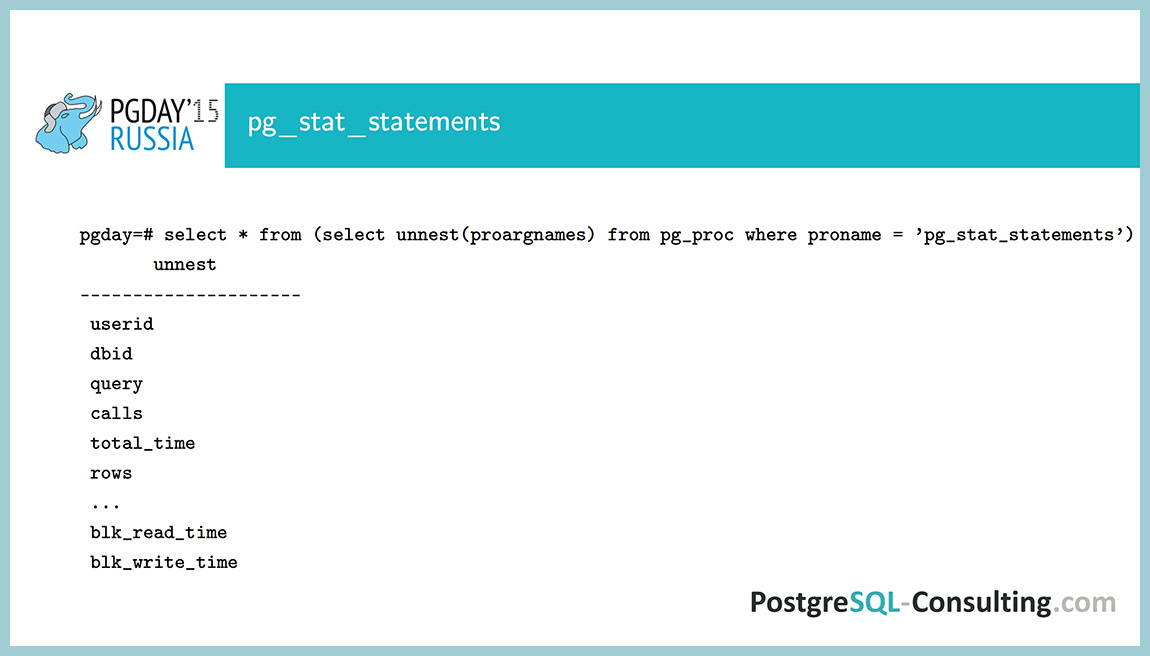
“Экстеншн” pg_stat_statements, который собирает все что надо. Почему-то не все еще его используют. На самом деле, очень удобный инструмент, собирает информацию по вызову каждого запроса: сколько раз запрос вызывался, сколько времени это суммарно заняло, сколько при этом было дисковых операций, сколько строк извлеклось суммарно.

Можно использовать специализированные запросы. Мы сделали такой запрос, который аккумулирует отчет, в котором говорится, что вообще происходит в базе за время с последнего сброса статистики. Реальный анализируемый пример, что мы тут видим?
Всего у нас запросы выполнялись 50 часов, из них времени на I/O ушло 0.6%. Самый первый запрос занял больше всего времени, на него ушло 28% времени процесса от времени всего выполнения в посгресе. Много всякой полезной информации, очень удобный. У нас лежит в репозитории, он называется query_stat_total.sql, ссылка дальше будет.

Вот такими параметрами это регулируется. Немного параметров, можно почитать про них документацию, ничего сложного нет. Иногда стоит track_utility выключать, некоторые системные команды (всякие ORM или в Java, например) любят дописывать в запрос deallocate чего-то там, и deallocate будет каждый раз иметь какой-то новый идентификатор, и вот он будет затирать значения, которые у нас есть в pg_stat_statements. Он отслеживает только ТОП запросов, по умолчанию это одна тысяча запросов (можно побольше поднять значение), но если эти запросы у нас на 90% будут deallocate какой-то идентификатор, то мы какую-то информацию потеряем. В таком случае, стоит выключить track_utility.

Заключение: есть статистика по распределениям, статистика по использованию ресурсов, записывается различными процессами, используется тоже по-разному. Статистика по распределениям используется планировщиком, а статистика по ресурсам – вряд ли чем-то используется, больше для мониторинга информация.
С помощью этих счетчиков можно узкие места выявлять, планировщик тоже может ошибаться, не идеальный мир, все еще только дорабатывается, и pg_stat_statements стоит использовать для мониторинга производительности.

Некоторые полезные ссылки на мануал, про оценку числа строк планировщиком, statistics collector, цикл статей depesz про то, как работает планировщик (пять статей, и в каждой рассматривается, как что работает). Ссылка на наш репозиторий и ссылка на наш блог.

Понравился доклад Алексея? Приезжайте к нам на PG Day'17 Russia! Алексей будет читать познавательный материал про особенности устройства планировщика PostgreSQL. Приглашаем всех, кто хочет узнать подробно, как работает планирование запросов в Посгресе. Какими способами можно воздействовать на процесс построения плана выполнения запроса? В каких случаях надо пытаться заставить планировщик работать корректно вручную? Приходите, Алексей все расскажет :-)
Комментарии (5)

kloppspb
29.05.2017 16:17Можно использовать поле JSONB, там все есть.
Вот это как раз самое интересное :-)

chemtech
29.05.2017 18:58+1Алексей, подскажите, пожалуйста, где можно посмотреть как влияют сами расширения pg_stat_statements, auto_explain на производительность PostgreSQL в нагруженной системе?
Т.е. сильно ли проседает производительность нагруженного PostgreSQL из-за этих расширений?
vyegorov
31.05.2017 12:33+1Принято считать, что
pg_stat_statementsдают до 5% по нагрузке (по синтетическим тестам). в каждом конкретном случае надо проводить нагрузочные тесты для получения точных цифр.pg_stat_statements“включаются” после запроса, и потому "чуть более" щадящи, нежелиauto_explain.auto_explainбудет писать план каждого исполняемого запроса в лог и это заметно, как по стремительному “отъеданию” места, так и по падению отклика базы, если логгирование ведётся туда же, где и сама база лежит.auto_explain-ом надо пользоваться при работе над конкретными проблемами,pg_stat_statementsхороши для общего контроля над запросами в базе
masterspline
> Дальше этот запрос парсится на токены и разбивается на части.
А почему эту часть не вынесут на клиентскую библиотеку. Только потому, что она составляет 0.1% от времени выполнения запроса? Вполне можно предусмотреть в протоколе обмена клиент-сервер как бинарный запрос, так и текстовый.
kloppspb
Выносят. Но IRL проверки нужны везде.