

Статей о том, что совсем скоро придут башковитые роботы и всех поработят бесконечное множество. Под катом еще одна заметка. Предлагаем вам ознакомиться с переводом выступления Нейтана Суареса, посвящённого определению целей систем искусственного интеллекта в соответствии с задачами оператора. На этот доклад автора вдохновила статья «Настройка искусственного интеллекта: в чем сложность и с чего начать», которая является основой для исследований в сфере настройки искусственного интеллекта.
Введение
Я являюсь исполнительным директором Научно-исследовательского института искусственного интеллекта (MIRI). Наш коллектив занимается исследованиями в области создания искусственного интеллекта в долгосрочной перспективе. Мы работаем над созданием продвинутых систем ИИ и исследуем возможные области его применения на практике.
Исторически сложилось так, что наука и технологии стали мощнейшими драйверами как положительных, так и отрицательных изменений, связанных с жизнью человека и прочих живых организмов. Автоматизация научно-технических разработок позволит совершить серьезный прорыв в развитии, невиданный со времен промышленной революции. Когда я говорю о «продвинутых системах искусственного интеллекта», я имею в виду возможную реализацию автоматизации исследований и разработок.
Системы искусственного интеллекта, превосходящие человеческие возможности, будут доступны человечеству еще не скоро, однако в настоящее время разработки в этом направлении ведутся многими продвинутыми специалистами, то есть, не я один уповаю на создание подобных систем. Полагаю, что мы действительно в состоянии создать нечто вроде «автоматизированного ученого», и данный факт следует воспринимать довольно серьезно.
Зачастую люди, упоминая о социальных последствиях создания искусственного интеллекта, становятся жертвами антропоморфической точки зрения. Они приравнивают искусственный интеллект к искусственному сознанию, либо полагают, что системы искусственного интеллекта должны быть схожи с человеческим интеллектом. Многие журналисты выражают обеспокоенность тем, что при преодолении искусственным интеллектом определенного уровня развития он приобретет массу естественных человеческих недостатков, в частности, захочет власти над окружающими, начнет самостоятельно пересматривать запрограммированные задачи и бунтовать, отказываясь выполнять свое запрограммированное предназначение.
Все эти сомнения беспочвенны. Человеческий мозг — сложный продукт естественного отбора. Системы, превосходящие человеческие возможности в научной сфере, будут схожи с человеческим мозгом не более, чем первые ракеты, самолеты и воздушные шары были схожи с птицами. 1
Системы искусственного интеллекта, освобождающиеся от «оков» программного исходного кода и приобретающие человеческие желания — не более чем фантазия. Система искусственного интеллекта представляет собой программный код, исполнение которого инициируется оператором. Процессор пошагово выполняет инструкции, содержащиеся в программном регистре. Теоретически возможно написать программу, манипулирующую собственным кодом, вплоть до установленных целей. Но даже эти манипуляции проводятся системой в соответствии с написанным нами исходным кодом, а не производятся самостоятельно машиной по ее внезапно возникшему собственному желанию.
По-настоящему серьезной проблемой, связанной с искусственным интеллектом, является правильность определения целей и минимизация непреднамеренных событий в случае их ошибочности. Соавтор книги «Искусственный интеллект: современный подход» Стюарт Расселл говорит по этому поводу следующее:
Главная проблема заключается не в создании пугающего искусственного разума, а в способности принимать решения высокого качества. Под качеством понимается функция полезности осуществляемых действий для достижения результата, заданного оператором. В настоящее время существуют следующие проблемы:
- Функцию полезности не всегда можно сопоставить с человеческими показателями, которые достаточно сложно определить.
- Любая достаточно продвинутая система искусственного интеллекта предпочтет обеспечить собственное существование и занять физические и вычислительные мощности, но не ради собственной «выгоды», а для решения поставленной задачи.
Система, оптимизирующая функцию из n переменных, для которой целевая функция зависит от подмножества k<n, зачастую устанавливает предельные значения для любых переменных; в результате, если одна из этих переменных имеет важное значение, найденное решение может не соответствовать нашим ожиданиям.
Указанные проблемы заслуживают большего внимания, чем антропоморфические риски, являющиеся основой сюжетов многих голливудских блокбастеров.
Простые идеи не работают
Задача: наполнить котел
Многие люди, говоря о проблемах искусственного интеллекта, рисуют в своем воображении Терминатора. Однажды мои слова об искусственном интеллекте были процитированы в одной новостной статье, посвященной людям, размещающим изображение Терминатора в своих трудах об искусственном интеллекте. В тот день я сделал определенные выводы о СМИ.
Я думаю, в качестве иллюстрации для подобных статей больше подходит следующая картинка:

На картинке изображен Микки Маус в мультфильме «Фантазия», ловко околдовавший метлу, которая наполняет котел по его желанию.
Как Микки это сделал? Представим, что Микки пишет компьютерную программу, выполняемую метлой. Микки начинает код с функции подсчета или целевой функции:

Учитывая некоторый набор доступных действий А, Микки пишет программу, принимающую в качестве входных данных одно из этих действий а и рассчитывающую определенную оценку в случае выполнения метлой этого действия. После этого Микки может написать функцию, вычисляющую действие а, имеющее максимальную оценку:

Использование величины “sorta-argmax” обусловлено возможным недостатком времени для оценки каждого действия множества А. Для реалистичных наборов действий необходимо найти только действие с максимальной оценкой с учетом ограниченности ресурсов, даже если это действие не является наилучшим.
Программа может казаться простой, однако вся загвоздка скрывается в деталях: создание алгоритма точного предсказания результата и умного поиска с учетом входных действий является главной проблемой создания системы искусственного интеллекта. Но концептуально данная задача решается довольно просто: мы можем подробно описать все виды операций, которые может выполнять метла, и последствия этих операций, разнесенные по разным уровням производительности.
Когда Микки запускает свою программу, первоначально все идет как надо. Однако, затем происходит следующее:

Такое сравнительное описание искусственного интеллекта является, по моему мнению, весьма реалистичным.
Почему мы ожидаем, что система искусственного интеллекта, выполняющая вышеуказанную программу, начнет переполнять котел, либо будет использовать чрезмерно «тяжелый» алгоритм проверки полноты котла?
Первая проблема заключается в том, что целевая функция, заданная для метлы, предлагает множество других исходов, которые не предусмотрел Микки:

Вторая проблема заключается в том, что Микки запрограммировал метлу на достижение результата на основе максимальной оценки. Задача «наполнить один котел водой» выглядит достаточно простой и ограниченной, однако если оценивать ее с вероятностной точки зрения, становится ясно, что ее оптимизация приводит к абсурдным результатам. Если котел с 99.9% вероятностью наполнен, но существуют дополнительные ресурсы, программа всегда будет искать способы задействования этих ресурсов для увеличения вероятности.
Сравните такой исход с ограниченной задачей, которую мы держим у себя в уме. Мы хотим наполнения котла, однако интуитивно не хотим, чтобы система «перетруждалась», даже если у нее есть доступные виртуальные и физические ресурсы для решения проблемы. Мы хотим, чтобы система использовала творческий и изобретательный подход в некоторых интуитивных рамках и не применяла абсурдные стратегии, особенно с непредсказуемыми последствиями. 2
В данном примере первоначальная целевая функция выглядит достаточно логичной. Она была обоснована и довольно проста. Не было предусмотрено способа получить больший уровень полезности. Она не похожа на систему, в которой используется только одна точка заливки воды — но однозначно существуют предпосылки переполнения котла. Проблема кроется в факте максимизации ожидаемой полезности. В результате цель не имеет ограничений, и даже небольшая ошибка в функции системы может привести к ее некорректной работе.
Существует множество вариантов, когда вполне определенная цель может оказаться неограниченной. Например, крупная система с глобальной задачей может состоять из подпроцессов, которые сами по себе будут стараться максимизировать возможные исходы функции, например задача оптимизации памяти. Если вы не понимаете систему настолько, чтобы определить, какие из процессов являются ресурсоемкими неограниченными оптимизаторами, то не важно, насколько определенной и безопасной является цель верхнего уровня.
Таким образом, метла может продолжать лить воду по причине, например, утечки в котле, либо, если установленный порог наполненности котла оказывается немного выше уровня краев. И, конечно же, метла не «бунтует» против кода Микки. Получается, что метла просто стремится к целям, которые были установлены слишком эффективно.
Частная проблема: suspend buttons
Общим решением данной проблемы должен выступать следующий алгоритм: «Могут возникнуть непредвиденные последствия выполнения общей функции, в результате чего ее выполнение должно быть прекращено».
Микки пробует такой вариант, однако он не работает:



Этот вариант также реалистичен для систем, которые достаточно эффективны для моделирования среды. Если система пытается ускорить выполнение оценочной функции и в состоянии распознать, что ее отключение может привести к использованию данных с более низким скорингом (более низкой оценкой эффективности), она старается предотвратить принудительное отключение. Чем более продвинутой является система, тем больше шансов, что она будет искать способы достижения этой подцели, например, путем копирования себя в интернет, либо путем обмана программистов, вводя их в заблуждение относительно ее функциональности.
Это не означает, что невозможно отключить продвинутую систему искусственного интеллекта; для этого необходимо провести дополнительную работу по предотвращению развития событий, когда система будет искать способы предотвращения преждевременного отключения. Если вы написали код, который будет искать способы предотвращения принудительного останова его исполнения, не стоит его запускать, даже если вы убеждены, что он не сработает — существуют гораздо более полезные задачи для загрузки вычислительных ресурсов, которые в данном случае оказываются заняты поиском решения для побочных и вредных задач.
Соответствующие меры безопасности, не предполагающие постоянного слежения и корректировки системы, требуют определенных изменений целевой функции. Необходимо определить, каким образом формально определить целевые функции, чтобы система искусственного интеллекта не пыталась конфликтовать с операторами; либо необходимо определить, каким образом система достигает целей без оптимизации целевых функций. Например, мы можем ограничить возможности системы, определив небольшой список разрешенных доменов, не позволяющих системе анализировать способы предотвращения ее отключения.
Одним из очевидных решений является попытка изменения функции оценки с введением кнопки отключения B:

Это означает, что, если кнопка останова активирована, цель системы изменяется с «наполнить котел» на «приостановить работу».
Не вполне ясно, каким образом необходимо фактически определять цель, если в функции приостановки есть какие-либо дыры, система попытается их использовать в своих целях. Например, она может заполнить значение операторов функции приостановки при выполнении подзадач или подпроцессов, стартуемых при запуске процесса наполнения котла. Это может привести к одновременному выполнению условий «котел полон» и «работа приостановлена», образно говоря «на всякий случай», независимо от состояния кнопки.
Однако, предположим, что мы нашли достаточно точный способ определения процесса остановки. Теперь возникает новая проблема, суть которой заключается в том, что мы передали системе слишком много полномочий по определению состояния кнопки. Если система получает возможность влиять на решение оператора по нажатию кнопки останова или любую другую возможность получить больший контроль над собственным исполнением, она будет стараться использовать эту возможность и будет проверять, нажата или не нажата кнопка в случае, если выполнение этой задачи будет более легким, чем выполнение задачи приостановки или наполнения котла.
Что удивительно, современные технологии в этой области не являются намного более продвинутыми, нежели описанная схема. Даная проблема рассмотрена в статье, написанной мной в соавторстве с Фолленштейном, Юдковским и Армстронгом (“Возможность внесения поправок“) и подтверждена соответствующими результатами Орсо и Армстронга (“Средства безопасного прерывания исполнения кода“).
Все, что нам нужно — это комбинирование двух целевых функций: первоначальной функции для нормальной работы системы и функции приостановки для «засыпания» системы и сохранения состояния на жесткий диск.

Наш метод комбинирования функций должен удовлетворять трем условиям: оператор должен иметь возможность переключаться между функциями (например, с помощью кнопки); система не должна стараться управлять активностью функций; если система в состоянии влиять на нашу возможность переключаться между функциями, она не должна использовать эту возможность.
До сих пор мы не нашли способа одновременного достижения всех трех целей. Например, мы можем попытаться предотвратить любое вмешательство системы в управление, если кнопка останова нажата, введя целевую функцию отключения, которой всегда присваивается определенное значение в зависимости от состояния кнопки:

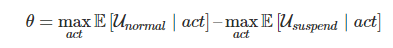
К сожалению, данный подход не позволяет выполнить третье условие. Оказывается, что определенная выше функция приводит к нулевому значению вероятности нажатой кнопки. Система не будет намеренно вмешиваться в определение состояния кнопки, однако с легкостью внесет правки, игнорирующие код определения состояния кнопки, либо создаст агенты, которые также будут игнорировать кнопку.
Выполнение этих интуитивно простых ограничений превращается в нетривиальную задачу. Это порождает множество вопросов в данной области: традиционные инструменты и концепции приводят к проблемам с безопасностью, которые не проявляются в рамках обычных исследований.
Общая картина
Приоритеты настройки
Отступим на шаг назад и поговорим о необходимости настройки продвинутой системы искусственного интеллекта в соответствии с нашими интересами.
Приведу максимально упрощенную схему: предположим, несколько людей придумывают определенную задачу, цель или набор предпочтений, которые выступают в роли функции предполагаемых значений V. Поскольку эти значения сложны и чувствительны к контексту, на практике необходимо формировать системы, которые будут со временем самостоятельно обучаться без необходимости ручного формирования кода. 3 Назовем конечную цель системы искусственного интеллекта параметром U (может совпадать или не совпадать с параметром V).

Публикации в прессе по данной области чаще всего фокусируются на одной из двух проблем: «Что если искусственный интеллект будет разработан «неправильной» группой людей?» и «Что если естественные желания системы искусственного интеллекта U будут отличаться от задачи V?»

С моей точки зрения, проблема «неправильной группы людей» не должна быть предметом беспокойства до тех пор, пока у нас нет прецедентов создания системы искусственного интеллекта «правильной группой людей». Мы находимся в ситуации, когда все попытки полезного использования системы искусственного интеллекта терпят неудачу. Простой пример: если бы мне передали крайне мощный оптимизатор в виде черного ящика, я смог бы оптимизировать любую математическую функцию, однако результаты были бы настолько обширными, что я бы не знал, как использовать этот оптимизатор для разработки новой технологии или осуществления научного прорыва без непредсказуемых последствий. 4
Мы многое не знаем о возможностях искусственного интеллекта, однако мы, тем не менее, имеем представление, как выглядит прогресс в данной области. Существует множество отличных концепций, техник и метрик, и мы приложили значительные усилия для решения проблем с разных точек зрения. В то же время, наблюдается слабое понимание проблемы настройки высокопроизводительных систем под конкретные цели. Мы можем перечислить некоторые интуитивные положения, однако до сих пор не разработаны универсальные концепции, техники или метрики.
Я считаю, что в данной области существуют достаточно очевидные вещи, и что нужно оперативно осуществить огромный объем работы (например, определить направление исследований возможностей систем — некоторые из этих направлений позволяют создать системы, которые гораздо проще подогнать под нужные результаты). Если мы не решим эти проблемы, разработчики, имеющие как положительные, так и отрицательные намерения, будут одинаково приходить к отрицательным результатам. С академической или научной точек зрения, наша основная цель в сложившейся ситуации должна заключаться в исправлении вышеупомянутых недостатков для обеспечения технологической возможности достижения положительных результатов.
Многие люди быстро признают, что «естественные желания системы» являются фикцией, но делают выводы, что необходимо фокусироваться на других проблемах, широко рекламируемых в СМИ: «Что если система искусственного интеллекта попадет не в те руки?», «Как искусственный интеллект повлияет на безработицу и распределение ценностей в обществе?» и пр. Это важные вопросы, однако едва ли они будут актуальными, если мы сможем обеспечить минимальный уровень безопасности и надежности при создании системы искусственного интеллекта.
Другой распространенный вопрос: «Почему бы просто не установить системе определенные моральные запреты? Такие идеи зачастую связаны с произведениями Айзека Азимова и подразумевают обеспечение надлежащего функционирования систем искусственного интеллекта, применив естественный язык для программирования определенных задач, однако такое описание будет довольно расплывчатым и не позволит полностью охватить все человеческие этические рассуждения:

Напротив, точность — это достоинство существующих программных комплексов, для которых необходимо обеспечить должный уровень безопасности. Нейтрализация риска несчастных случаев требует ограниченности целей, а не «решения» всех моральных аспектов. 5
Я считаю, что работа по большей части должна заключаться в создании эффективного процесса обучения и в проверке правильности привязки процесса sorta-argmax к результирующей целевой функции U:
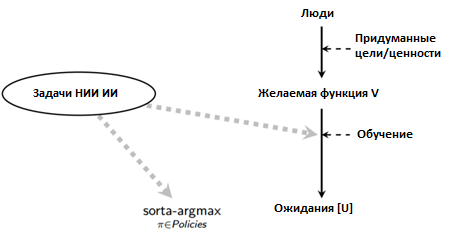
Чем лучше концепция процесса обучения, тем менее ясным и точным может быть определение желаемой функции V, и тем менее значимой становится проблема выяснения того, что вы хотите от системы искусственного интеллекта. Однако организация эффективного процесса обучения связана с целым рядом трудностей, которые не возникают при стандартных задачах машинного обучения.
Классическое исследование возможностей концентрируется в частях диаграммы «sorta-argmax» и «Ожидания», однако sorta-argmax также содержит в себе рассмотренные мной, но зачастую игнорируемые проблемы обеспечения прозрачности и безопасности. Чтобы понять необходимость правильной привязки процесса обучения к возможностям системы, а также важность и трудность этой задачи, нужно обратиться к собственной биологической истории.
Естественный отбор — единственный понятный нам «инженерный» процесс, который привел к интеллектуальному развитию, то есть к развитию нашего мозга. Поскольку естественный отбор нельзя назвать умным механизмом, можно прийти к выводу, что общего интеллектуального развития можно добиться трудом и грубой силой, однако данный процесс является достаточно эффективным только с учетом человеческой креативности и чувства предвидения.
Еще одним ключевым фактором является то, что естественный отбор был направлен только на выполнение элементарной задачи — определение генетической пригодности. Однако, внутренние цели людей не имеют отношения к генетической пригодности. Наши цели являются неисчисляемыми и неизмеримыми — любовь, справедливость, красота, милосердие, веселье, уважение, хорошая пища, крепкое здоровье и пр., однако следует учесть, что все эти цели тесно коррелировали с задачами выживания и размножения в древнем мире. Тем не менее, мы оцениваем конкретно эти качества, а не связываем их с генетическим распространением человечества, что наглядно подтверждается введением процедур по контролю рождаемости.
В данном случае, внешнее оптимизационное давление привело к развитию внутренних целей, не соответствующих внешнему селекционному воздействию. Получается, что действия людей расходятся с псевдоцелями естественного отбора, в результате чего они получили новые возможности, соответственно точно также можно ожидать, что действия систем искусственного интеллекта могут отличаться от установленных человеком целей, если эти системы будут представлять собой черные ящики для пользователей.
Применив градиентный спуск к черному ящику с целью достижения наилучшего результата и обладая достаточной изобретательностью, мы в состоянии создать некоторый мощный оптимизационный процесс. 6 По умолчанию следует ожидать, что цель U будет тесно коррелировать с целью V в тестовых условиях, однако будет значительно отличаться от V в других условиях или при введении большего числа доступных параметров.
С моей точки зрения, самая важная часть проблемы подстройки — обеспечение того, чтобы обучающая конструкция и общая конструкция системы позволила приоткрыть завесу и была в состоянии сообщить нам после оптимизации о соответствии (или несоответствии) внутренних целей установленным для процесса обучения целям. 7
Данная задача имеет сложное техническое решение, и, если мы не сможем его понять, будет неважно, кто стоит ближе к разработке системы искусственного интеллекта. Хорошие намерения не встраиваются добрыми программистами в их программы, и даже самые благие намерения при разработке системы искусственного интеллекта не имеют никакого значения, если мы не в состоянии привести практическую пользу системы в соответствии с установленными целями.
Четыре ключевых предположения
Давайте сделаем еще один шаг назад: я привел актуальных открытых проблем в данной области (кнопка останова, процесс обучения, ограниченность задач и пр.) и подчеркнул наиболее сложные для решения категории. Однако я лишь расплывчато упомянул, почему я считаю искусственный интеллект очень важной областью: «Система искусственного интеллекта может автоматизировать научные изыскания общего назначения, что уже само по себе является прорывом». Давайте глубже разберемся, зачем стоит прикладывать усилия в данном направлении.
Во-первых, цели и возможности ортогональны. Это означает, что целевая функция системы искусственного интеллекта не позволяет оценить качество оптимизации этой функции, а осведомленность о наличии мощного оптимизатора не позволяет понять, что именно он оптимизирует.
Полагаю, большинство программистов интуитивно понимает это. Некоторые люди продолжают настаивать на том, что, когда система, наполняющая котел, станет достаточно «умной», она посчитает цель наполнения котла недостойной своего интеллекта и откажется от нее. С точки зрения компьютерной науки очевидным ответом является то, что вы можете выйти за рамки построения системы, проявляющей условное поведение, то есть построить систему, не следующую заданным условиям. Такая система может заниматься поиском более скорингового варианта наполнения котла. Поиск наиболее оптимизированных вариантов может оказаться скучным для нас с вами, однако вполне реально написать программу, которая будет заниматься таким поиском в свое удовольствие. 8
Во-вторых, достаточно оптимизированные цели сходятся, как правило, при состязательных инструментальных стратегиях. Большинство целей системы искусственного интеллекта могут требовать создания подцелей, таких как «приобретение ресурсов» и «непрерывность работы» (наряду с «изучением среды» и пр.).
С этим связана проблема кнопок останова: даже если вы не указали в спецификации целей условия продолжения работы, любая цель, которую вы задали системе, скорее всего, будет эффективнее достигнута при непрерывной работе системы. Возможности программных систем и (конечные) цели ортогональны, однако они часто проявляют сходное поведение, если определенный класс действий полезен для самых различных возможных целей.
Пример Стюарта Расселла: если вы построите робота и попросите его сходить в магазин за молоком, робот выберет наиболее безопасный путь, поскольку вероятность возврата с молоком, в данном случае, будет максимальной. Это не означает, что робот боится смерти; это означает, что робот не принесет молоко в случае смерти, чем и объясняется его выбор.
В-третьих, системы искусственного интеллекта общего назначения вероятнее всего, будут очень быстро и эффективно развиваться. Возможности человеческого мозга ниже аппаратных (или, как некоторые считают, программных) возможностей вычислительной системы, поэтому, с учетом также целого ряда других преимуществ, от продвинутых систем искусственного интеллекта следует ожидать быстрого и резкого развития возможностей.
Например, Google может приобрести многообещающий стартап, связанный с искусственным интеллектом, и задействовать огромные аппаратные ресурсы, в результате чего проблемы, решение которых планировалось в ближайшее десятилетие, могут быть решены в течение года. Либо, например, при появлении широкомасштабного доступа в интернет и наличии особого алгоритма, система может значительно увеличить свою производительность, либо сама предложит программно-аппаратные варианты увеличения производительности. 9
В-четвертых, задача настройки продвинутых систем искусственного интеллекта в соответствии с нашими интересами является достаточно сложной.
Грубо говоря, в соответствии с первым предположением, системы искусственного интеллекта естественным образом не разделяют наши цели. Второе предположение гласит, что по умолчанию системы с существенно разными целями будут бороться за ограниченные ресурсы. Третье предположение демонстрирует, что состязательные системы искусственного интеллекта общего назначения имеют значительные преимущества над человеком. Ну и в соответствии с четвертым предположением, проблема имеет сложное решение — например, сложно задать системе необходимые значения (с учетом ортогональности), либо предотвратить отрицательные стимулы (направленные на конвергентные инструментальные стратегии).
Эти четыре предположения не означают, что мы застряли в развитии, однако свидетельствуют о наличии критически важных проблем. Необходимо в первую очередь сконцентрироваться на этих проблемах, поскольку, если они будут решены, системы искусственного интеллекта общего назначения могут принести огромные выгоды.
Фундаментальные трудности
Почему я полагаю, что проблема настройки системы искусственного интеллекта в соответствии с целями является достаточно сложной? В первую очередь, я основываюсь на своем опыте работы в данной области. Я рекомендую вам самостоятельно рассмотреть эти проблемы и попытаться решить их при настройках игрушек — вы во всем убедитесь сами. Перечислю несколько структурных причин, свидетельствующих о сложности поставленной задачи:
Во-первых, настройка продвинутых систем искусственного интеллекта выглядит сложной по той же причине, по которой проектирование космической техники сложнее самолетостроения.
Естественной мыслью является предположение, что для системы искусственного интеллекта необходимо всего лишь принять меры безопасности, требуемые для систем, превосходящих человеческие возможности. С этой точки зрения, вышеперечисленные проблемы совсем не очевидны, и кажется, что все решения для них могут быть найдены при проведении узкоспециализированного исследования (например, при испытании автопилотов для автомобилей).
Точно также, не вдаваясь в подробности, можно утверждать: «А почему это космические разработки сложнее самолетостроения? Ведь используются одни и те же физические и аэродинамические законы, разве не так?» Вроде все верно, однако, как показывает практика, космическая техника взрывается гораздо чаще самолетов. Причиной этого являются значительно большие нагрузки, которые испытывает летательный аппарат, в результате чего даже малейшая неисправность может привести к катастрофическим последствиям. 10
Аналогично, хотя узкоспециализированная система ИИ и система ИИ общего назначения схожи, системы ИИ общего назначения имеют больший диапазон воздействий, в результате чего риски возникновения опасных ситуаций растут в лавинообразной пропорции.
Например, как только система искусственного интеллекта начинает понимать, что (i) ваши действия влияют на ее способности достижения целей, (ii) ваши действия зависят от вашей модели мира и (iii) ваша модель мира зависит от ее действий, резко возрастают риски того, что даже малейшие неточности могут привести к вредоносному поведению системы (включая, например, обман пользователя). Как и в случае с космической техникой, масштабность системы приводит к тому, что даже малейшие неисправности могут стать причиной больших проблем.
Во-вторых, задача настройки системы сложна по тем же причинам, по которым гораздо проще написать хорошее приложение, чем построить хороший космический зонд.
В НАСА существует целый ряд интересных инженерных практик. Например, формируется что-то вроде трех независимых команд, каждой из которых выдаются одни и те же технические требования для разработки одной и той же программной системы. В итоге проводится голосование и выбирается реализация, набравшая большинство голосов. По сути, тестируются все три системы, и, в случае обнаружения каких-либо расхождений, наилучшая реализация кода выбирается большинством голосов. Идея заключается в том, что любая реализация будет иметь ошибки, но маловероятно, что все три реализации будут иметь ошибки в одном и том же месте.
Такой подход является гораздо более осторожным, чем, например, выпуск новой версии WhatsApp. Одна из главных причин проблемы — космический зонд сложно откатить к предыдущей версии, а вот в случае с WhatsApp это не доставляет особых проблем. Вы можете отправлять на зонд обновления и исправления только в случае, если работают приемник и антенна и отправляемый код полностью работоспособен. В данном случае, если система, требующая внесения правок, уже не работоспособна, то нет способов исправить существующие в ней ошибки.
В некотором отношении система искусственного интеллекта похожа скорее на космический зонд, чем не обычное программное обеспечение. Если вы пытаетесь создать нечто умнее себя, определенные части этой системы должны работать идеально с первой попытки. Мы можем выполнить все тестовые прогоны, которые хотим, но как только система будет запущена в действие, мы сможем проводить только онлайн обновления, да и то только в случае, если код позволяет это и работает корректно.
Если вы еще не до конца испугались, предлагаю поразмышлять о том, что будущее нашей цивилизации может зависеть от нашей способности писать код, который правильно работает при первом развертывании.
И наконец, задача настройки является сложной по той же причине, по которой сложна система компьютерной безопасности: система должна быть надежной при интеллектуальном поиске пробелов в безопасности.
Предположим, у вас есть десяток уязвимостей в коде, каждая из которых не является критичной или даже не несет проблем при обычных условиях работы. Защита программы является сложной задачей, поскольку необходимо сразу учесть, что умный хакер найдет все десять дыр в безопасности и будет их использовать для взлома вашей системы. В результате, программа может быть искусственно «загнана» в аварийный режим, чего не могло наблюдаться при обычной ее работе; атакующий может заставить систему использовать странные алгоритмы, о которых вы даже не могли подумать.
Аналогичная проблема наблюдается и для систем искусственного интеллекта. Суть ее заключается не в управлении состязательным режимом системы, а в предотвращении входа системы в этот режим. Не нужно пытаться перехитрить умную систему — это заранее проигрышная позиция.
Вышеперечисленные проблемы схожи с проблемами в криптографии, поскольку при настройке целей системы нам приходится иметь дело с системами, занимающимися интеллектуальным поиском в крупном масштабе, в результате чего программный код может исполняться практически непредсказуемым образом. Это связано с использованием экстремальных значений, которые используются системой при проведении процесса оптимизации 11. Разработчикам систем искусственного интеллекта необходимо перенимать опыт специалистов по компьютерной безопасности, которые тщательно тестируют все экстремальные случаи.
Очевидно, что гораздо проще сделать код, который хорошо работает ожидаемым для вас способом, чем делать код, который может привести к результатам, которых вы не ждете. Система искусственного интеллекта должна успешно работать любым, даже непонятным вам способом.
Подведем итоги. Мы должны решать задачи с той же осторожностью и точностью, с которой разрабатывается космический зонд, и должны провести все необходимые исследования до запуска системы. На этом раннем этапе ключевой частью работы является только формализация базовых концепций и идей, доступных для использования и критики другими специалистами. Философская дискуссия о типах кнопок останова — это одно дело; гораздо сложнее перевести свою интуицию в уравнение, чтобы другие смогли полностью оценить ваши рассуждения.
Данный проект является очень важным, и я призываю всех заинтересовавшихся принять в нем участие. В интернете имеется большое количество ресурсов по данной тематике, включая информацию об актуальных технических проблемах. Можете начать с изучения исследовательских программ MIRI и со статьи «Конкретные проблемы безопасности в системах искусственного интеллекта», которую вы можете найти на Google Brain, OpenAI и Stanford.
Примечания
- Самолет не может исправлять собственные повреждения или размножаться, но он в состоянии перевозить тяжелые грузы быстрее и дальше, чем птицы. Самолеты во многих отношениях проще птиц, однако они обладают большими возможностями с точки зрения грузоподъемности и скорости (для чего они и были разработаны). Вполне вероятно, что ранние автоматизированные ученые также во многих отношениях будут проще человеческого разума, однако будут превосходить его в определенных задачах. И так же, как конструкция и дизайн самолетов выглядят чуждыми по сравнению с архитектурой биологических существ, мы может ожидать, что конструкция высокопроизводительных систем ИИ будет значительно отличаться от архитектуры и логики человеческого разума.
- Попытка формализовать различие конечных и неопределенных целей является насущной исследовательской проблемой. В соответствии с исследовательской статьей “Настройка целей для продвинутых самообучающихся систем”, необходимо применять мягкую оптимизацию («не слишком усердную оптимизации») с консервативным подходом («избегать абсурдных стратегий») и постараться предотвратить крупные непредсказуемые последствия. Более подробная информация по предотвращению негативных последствий можно найти в статье Дарио Амодея, Криса Олаха, Якова Штейнхардта, Пола Криштиано, Джона Шульмана и Дена Мейнза “Конкретные проблемы обеспечения безопасности в системах искусственного интеллекта.”
- За последнее десятилетие мы осознали, что компьютеру практически невозможно вручную описать кошку, но его можно научить распознавать кошку. Еще более безнадежна попытка описать человеческие ценности, однако вполне вероятно, что можно разработать обучающую систему, которая могла бы изучить понятие «ценностей».
- Ознакомьтесь со статьями «Цели с точки зрения среды», «Малоэффективные агенты» и «Мягкая оптимизация» для определения физических целей, не вызывающих катастрофических побочных эффектов.
Грубо говоря, MIRI фокусируется на исследованиях, которые помогут нам принципиально понять, как задавать цели системам искусственного интеллекта, в результате чего возникающие перед нами задачи становятся более понятными.
Что я имею в виду? Предположим, мы пытаемся разработать новую шахматную программу. Достаточно ли мы понимаем задачу, если нам просто дадут высокопроизводительную систему? Если мы понимаем задачу, мы формируем дерево поиска, ищем в нем похожие шахматные ходы и выбираем оптимальный вариант, ведущий к победе.
Если же мы недостаточно понимаем задачу, даже имея достаточные вычислительные мощности, мы были бы не в состоянии реализовать шахматную программу. Мы либо не использовали бы дерево поиска, либо просто не знали бы, каким образом ходят определенные шахматные фигуры.
Именно в такой ситуации мы находились в сфере разработки шахматных программ до основной работы Клода Шеннона, и именно в такой ситуации мы находимся в настоящий момент в области разработки искусственного интеллекта. Неважно, какими вычислительными мощностями я обладаю, я не в состоянии создать систему искусственного интеллекта, решающую даже самые простые и определенные задачи, будь то задача «положить клубнику на тарелку», либо задача «максимизировать количество алмазов во вселенной».
Если у меня нет конкретной цели для системы, я мог бы написать программу (предполагая наличие вычислительных ресурсов), которая сильно оптимизировала будущее неориентированным образом, используя формализм, такой как AIXI. В этом смысле мы имеем меньше вопросов о возможностях, чем о целях, даже несмотря на недостаток частей паззла с точки зрения практического решения.
Мы знаем, как использовать мощный оптимизатор функций для работы с биткоинами или доказательства теорем. Но в то же время мы не знаем, каким образом безопасно выполнить задачу прогнозирования и поиска решений для объектов в физическом мире, которую я описал в разделе «Задача: наполнить котел».
Нашей целью является разработка и формализация основных подходов и способов определения целей таким образом, чтобы наши инженерные решения не ограничивались тяжелыми вербальными конструкциями, которые зачастую оказываются ошибочными. Проблему можно разделить на некоторые части, которыми можно управлять, просто введя некоторые упрощения вроде «а что если нас не беспокоят ресурсные ограничения» или «что если попытаться достичь более простой цели». Более подобная информация по данной методологии приведена на странице “Методики MIRI.”
- “Наполнять котел, имея недостаточные знания, либо работать слишком усердно, либо столкнуться с негативными последствиями» — вот простой пример интуитивного ограничения возможных вариантов. Мы планируем использовать искусственный интеллект для гораздо более амбициозных целей, но начинать нужно с вполне определенных задач, а не с неограниченных задач.
Три закона робототехники Азимова известны, но бесполезны с исследовательской точки зрения. Сложная задача превращения моральных заповедей в код скрыта за фразами вроде «не допустить вреда человеку своим бездействием». Если неукоснительно следовать подобным правилам, результаты будут катастрофическими, поскольку системам искусственного интеллекта пришлось бы постоянно действовать для предотвращения даже малейшего вреда человеку. Человек, в отличие от машины, придерживается подобных принципов свободно, с учетом чувств и интуиции.
Неопределенное обучение на естественном языке возможно, поскольку системы искусственного интеллекта, вероятнее всего, будут в состоянии понимать человеческую речь. Однако, такой подход приведет к увеличивающемуся разрыву между целевой функцией системы и моделью мира. Система, действующая в человеческой среде, может изучить модель мира, содержащую много информации о человеческом языке и концепции, которую система может в дальнейшем использовать для достижения целей, однако данный факт вовсе не означает, что эта информация приведет к прямому изменению целей системы.
Необходимо определить некий процесс обучения, который позволит системе самостоятельно улучшать целевую функцию с появлением новой информации. Это сложная задача, поскольку в настоящий момент неизвестны метрики или критерии машинного обучения, аналогичные стандартному человеческому обучению.
Если модель мира системы точна в тестовой среде, но не работает в реальном мире, это, скорее всего, приведет к низким оценкам целевой функции — система сама по себе будет стараться ее улучшить. В данном случае, саморегулированию будут подвергнуты ограничения, связанные с тяжестью негативных последствий, поскольку неверная оценка отрицательно повлияет на эффективность определения системой правильности применяемых стратегий.
Если процесс обучения системы приводит к тому, что U соответствует V в тестовой среде, но отличается от V в реальном мире, система не понесет никакого наказания за оптимизацию U. У системы нет стимула относительно U «исправлять» различие между U и V, если изначально процесс обучения был ошибочным. В данном случае риск негативных последствий растет, поскольку несоответствие U и V необязательно налагает ограничения на инструментальную эффективности системы при разработке эффективных и креативных стратегий достижения U.
Проблема разделяется на три части:
- 1. “Делай, что я имею ввиду” — неопределенная задача, и, даже если бы мы смогли создать систему искусственного интеллекта, мы не знали бы, как перевести подобную задачу в код.
- 2. Если выполнение подразумеваемой нами задачи является инструментально обоснованным для достижения определенной цели, достаточно умная система может изучить, каким образом ей выполнять действия, и действовать таким образом до тех пор, пока эти действия будут эффективны для достижения цели. Однако, если система становится еще более умной, она может найти более креативные пути достижения целей, соответственно, задача «делать, что я имею ввиду» может оказаться для системы неоптимальной с инструментальной точки зрения.
- 3. Если мы используем обучение для улучшения целей системы на основе полученных данных, которые, как представляется, направляют систему в сторону U (то есть того, что «мы имеем в виду»), вероятно, что система фактически обнулит U, что мы фактически подразумеваем в процессе обучения, но, с другой стороны, может привести к катастрофическим разночтениям в сложных контекстах. Более подробная информация приведена в “Проклятии Гудхарта”.
- Примеры проблем, с которыми сталкиваются существующие техники обучения целям и фактам, приведены в статье “Использование машинного обучения для устранения рисков, связанных с ИИ.”
- 1. “Делай, что я имею ввиду” — неопределенная задача, и, даже если бы мы смогли создать систему искусственного интеллекта, мы не знали бы, как перевести подобную задачу в код.
- Результат, вероятно, будет не совпадать с человеческой эволюцией, поскольку она связана с множеством исторических событий. Кроме того, результат может оказаться более эффективным вследствие определенных программно-аппаратных преимуществ.
- Данная концепция иногда включается в категорию «прозрачность», но стандартное исследование алгоритмической прозрачности на самом деле не решает проблем. Лучшим термином является, по моему мнению, «понимание». Мы хотим получить более глубокое и более широкое представление о том, какую когнитивную работу выполняет система, и как эта работа связана с целями системы или целями оптимизации, то есть мы хотим получить инструмент, дающий представление о практической инженерной работе.
- Мы могли бы запрограммировать систему на выполнение действий по кругу, но нам этого не нужно. В принципе, можно запрограммировать метлу, которая только находит и выполняет действия, оптимизирующие понятие полноты котла. Улучшение способности системы эффективно находить действия с высоким коэффициентом (в абсолютном смысле или относительно определенного правила скоринга) само по себе не изменяет правило подсчета, которое оно использует для оценки действий.
- Мы можем представить, что последний случай приводит к циклу обратной связи, поскольку усовершенствования конструкции системы позволяют ей придумать дополнительные усовершенствования конструкции, пока все наиболее просто исполнимые варианты не будут исчерпаны.
Еще одно важное соображение состоит в том, что узким местом для более быстрого развития научных исследований человеком являются время обучения и пропускная коммуникативная способность. Если бы мы могли научить «новый ум» стать передовым ученым за десять минут, и, если бы ученые могли почти мгновенно обмениваться опытом, знаниями, концепциями, идеями и интуицией, научный прогресс мог бы значительно продвинуться. Именно ликвидация этих узких мест дает преимущества автоматизированным изобретателям даже при отсутствии более эффективных аппаратных средств и алгоритмов.
- К примеру, ракеты подвержены воздействию более большого диапазона температур и давлений, а также сильнее укомплектованы взрывчатыми веществами.
- Рассмотрим разработку Бердом и Лейцеллом очень простого генетического алгоритма, которому было поручено разработать колебательный контур. Берд и Лейцелл были удивлены, обнаружив, что алгоритм не использовал конденсатор на чипе; вместо этого он использовал дорожки схемы на материнской плате в качестве радиоприемника, чтобы передать осциллирующий сигнал с тестового устройства обратно на тестовое устройство.
Программа была недостаточно проработанной. Это было всего лишь частное решение задачи в очень ограниченной области. Тем не менее, полученное решение вышло за рамки представлений программистов. В компьютерном моделировании этот алгоритм мог вести себя так, как предполагалось, но фактическое пространство решений в реальном мире было шире, в результате чего было проведено вмешательство на аппаратном уровне.
В случае использования системы искусственного интеллекта, превосходящей человека во многих областях, необходимо понимать, что система будет продвигаться к подобным странным и творческим решениям, которые сложно предвидеть.
Комментарии (51)

napa3um
05.06.2017 14:21+3Очередное исследование «неизвестно чего» (strong AI с неизвестными свойствами) с попыткой пересчитать ангелов на острие иглы. Непонятно, кто и какие выводы должен сделать после прочтения данной статьи.

ni-co
05.06.2017 16:35-3Жаль, что видимо на это еще и деньги из бюджета расходуют.

FINTER
06.06.2017 11:06Чьего бюджета? MIRI находится в Калифорнии и является коммерческой организацией.
ZiingRR
06.06.2017 11:26MIRI — некоммерческая организация
FINTER
06.06.2017 12:55Да, Вы правы. Беглый просмотр сайта говорил об обратном, но
MIRI is a 501©(3) nonprofit committed to transparency.
Our tax ID # is 58-2565917.

cepera_ang
07.06.2017 20:59Разница только в том, что некоммерческая организация должна расходовать _все_ заработанные деньги, а не оставлять часть в форме прибыли владельцам. Anyway, это вообще нерелевантное обсуждение, так как если из какого-то бюджета они деньги и тратят, то только из своего собственного.

perfect_genius
05.06.2017 16:09Я больше боюсь не того, что могу порезаться ножом, а что другой человек может захотеть напасть на меня с этим ножом.
Сколько статей об ИИ, но не видел обсуждения вот чего: ИИ сопротивляется своему отключению/исправлению, так что могло бы быть, если против него запустить другой ИИ?
Также не встречал про нас:
мы не боимся опасности ИИ и наоборот ждём, чтобы что-нибудь случилось из-за него (но не с нами), не так ли? =)
Также мы ждём, чтобы автопилоты уже массово тестировались, и надеемся, что баги выявятся не у нас.
pda0
05.06.2017 17:03+2ИИ сопротивляется своему отключению/исправлению
Он не сопротивляется, просто может воспринять, как помеху в работе. А если в задачу поставлено «избегать помех»… Ну, как сейчас в Boston Dynamics роботов учат не падать или подниматься после падений. Причём более продвинутый, но не правильно обученный ИИ может воспринять как помеху саму реализацию механизма отключения.
так что могло бы быть, если против него запустить другой ИИ?
«Страж-птица».
ClearAirTurbulence
05.06.2017 17:02+1— Полагаю, компьютер корабля находится на грани полноценного разума. И он способен обучаться. Но почему-то не осознает себя.
(с)
— Да, мы предполагали. Это очень изящно реализовано, Петя. Их компьютеры не становятся разумными, потому что уже считают себя такими.
SergejShegurin
05.06.2017 17:11+1Интересно, кто-нибудь из здесь присутствующих станет утверждать, что с вероятностью более 80% через 30 лет в мире не будет запущено множество strong general AI, многократно превосходящих людей по способностям в подавляющем большинстве навыков и имеющих полный доступ к интернету (а то и полностью автономных)?
Думаю, для такого утверждения надо быть чересчур самоуверенным человеком. Ведь никто не собирается сворачивать индустрии чатботов (включая агитационных и рекламных), интернета вещей, робототехники. Выиграют те компании, которые предоставят своим ИИ максимально широкие полномочия.
И станет ли кто-то утверждать, что с вероятностью более 80% в этом случае будет найдено решение, позволяющее гарантировать безопасность всего этого множества запущенных strong general AI? при том, что их количество и качество будут постоянно расти. Кто с вероятностью более 80% уверен, что будет найдено программное решение, позволяющее гарантировать дружелюбность и покорное служение интересам человечества[1] всего этого множества ИИ, своевременную нейтрализацию тех ИИ, которые будут выходить из-под контроля? Кто будет полицейским для ИИ? Тоже ИИ? И кто будет контролировать полицейских ИИ? Если на вершине пирамиды контроля будут люди, можем ли мы быть уверенными, что они справятся с контролем над более способными существами? Утверждать всё это с вероятностью более 80% — на мой взгляд, чересчур самоуверенная затея.
Кто-то сошлётся на киборгизацию людей и сращивание с ИИ. Но вовсе не очевидно, что биологический мозг возможно совместить с электронным, не потеряв большой доли производительности последнего. Ведь биологический мозг медленный — на распространение сигнала от нейрона к нейрону требуется ~10мс, на простейшую операцию распознавания не менее ~100мс, на простую мысль уже ~1с. В этом случае я вижу две альтернативы — либо мы сохраняем главенство биологического мозга над электронным, но сильно теряем в конкурентоспособности относительно сильного ИИ, либо биологический мозг просто не поспевает за электронным, желаемость чего для поглощаемого человека крайне неочевидна.
[1] Интересы человечества — немного размытое понятие. Кто может гарантировать с вероятностью более 80%, что эти ИИ не будут успешно использованы одной частью человечества (военными, преступниками, диктаторами или просто властолюбивыми людьми) целенаправленно с целью массового ограничения основной массы человечества в правах, включая право на жизнь?SergejShegurin
05.06.2017 17:42Часто в качестве аргумента за неактуальность дискуссий по безопасности ИИ приводят предполагаемую далёкость создания сильного ИИ. Но можем ли мы быть уверенными, что решение этой сложной проблемы возможно найти и внедрить всего лишь за 10 лет? или здесь нужны значительно более серьёзные изменения в мире, для осуществления которых и 30 лет может оказаться достаточно лишь едва и на грани? Вещь-то нешуточная, создание сверхинтеллекта.
Aligatro
08.06.2017 07:43В целом я не совсем понимаю, почему вы рассматриваете сильное ИИ как подконтрольное человеку.
Мы изначально поставили цель создания инструмента который эволюционно задуман как превосходящий наш вид (да даже если равный ему, не суть). И я вижу два варианта…
Либо мы ставим ему программные ограничения, что скорее всего никогда не сделает его сильным (очень мощным да, но сознание). Либо ставим тумблер для организации театра безопасности.
В любом случае то о чём вы говорите, это новый вид и самоорганизовываться он будет тоже самостоятельно и если интересы обоих видов не будут пересекаться, ок, если будут, полагаю нам не повезло.
fivehouse
05.06.2017 19:11-1Я являюсь исполнительным директором Научно-исследовательского института искусственного интеллекта (MIRI).
А что такое просто интеллект этот целый институт понимает? Или это уже не важно?Наш коллектив занимается исследованиями в области создания искусственного интеллекта в долгосрочной перспективе.
Что такое просто интеллект мы не понимаем. Но уже есть коллектив и долгосрочные перспективы.Мы работаем над созданием продвинутых систем ИИ и исследуем возможные области его применения на практике.
Поскольку что такое просто интеллект мы не понимаем, осталось исследовать возможность применения этого на практике.red75prim
05.06.2017 23:08+2А до того как Пеано формализовал арифметику, всем просто везло, когда два плюс два равнялось четырём.
Формализация человеческого интеллекта не нужна для создания систем, решающих все классы задач, доступных человеку, если можно доказать, что система решает более широкий класс задач.
fivehouse
06.06.2017 14:12-1Для понимания что такое интеллект совсем не обязательно его формализовывать. Точно так же и для понимания почему два плюс два равняется четырем совсем не обязательна формализация арифметики. Вы явно существенно преувеличиваете и этим произвольным преувеличением доводите элементарное требование понимания предмета с которым мы заявляем что работаем до абсурда.
Итак я утверждаю, что пока все горе работники над искусственными интеллектом (и горе вселенские институты со своими горе исполнительными директорами и все эти Маски с IBMами) более-мение точно не заявили что они пониманиют над просто интеллектом, они просто нагло обманывают всех, что они работают над искусственным интеллектом. Хотя и не всегда они это делают (зло-)намеренно. И часто обманывают и сами себя.red75prim
06.06.2017 17:56+1более-мение точно не заявили что они пониманиют над просто интеллектом
Э? С этим есть какие-то сложности? Я потому и заговорил про формализацию, что считал интуитивное понимание того, что есть интеллект широко распространенным и примерно одинаковым — способность решать все те задачи, что и человек. Задачи, исходя из того же интуитивного понимания, не должны требовать физической активности.
Или вот цитата из Artificial Intelligence: A Modern Approach:
We will see that the concept of rationality can be applied to a wide variety of agents operating in any imaginable environment. Our plan in this book is to use this concept to develop a small set of design principles for building successful agents—systems that can reasonably be called intelligent.
В вольном переводе: "интеллект — способность достигать успеха в широком диапазоне начальных условий".
Думаю с этой книгой в MIRI знакомы.
ZiingRR
06.06.2017 18:04+1Думаю с этой книгой в MIRI знакомы.
Ещё бы они не были знакомы — в MIRI Стюарт Рассел (один из авторов книги) числится как research advisor :)
perfect_genius
06.06.2017 16:05+1Наше дело — создать ИИ, а что оно там такое пусть сам разбирается :D

barsuksergey
05.06.2017 23:01Друзья, поясните, пожалуйста, на примере множеств, что ли, или другом простом, чем отличается разум и интеллект? Что между ними схожего? Чем они принципиально отличаются? И почему их постоянно подменяют друг другом?
Nakosika
06.06.2017 11:04Разум — это сама машина. Интеллект — это его свойство, используя логику, решать проблемы.

atri24
06.06.2017 11:26Бачок унитаза — интеллектуален, он набирает воду до определенного уровня, но он не разумен.
fireSparrow
06.06.2017 12:55+2Беда в том, что нет никакого чёткого общего определения этих понятий.
Каждый либо вкладывает в них какой-то свой смысл на основе субъективного интуитивного понимания, либо пользуется каким-то локальным определением, которое может быть взято из теории, относящейся к кибернетике, психологии, философии, эзотерике, или ещё Бог знает откуда.
Но при этом значительная часть людей в дискуссиях на тему ИИ даже не задумываются о том, что бывают другие определения, помимо того, которым пользуются они.
От этого и происходит значительная часть недопонимания при обсуждении ИИ.ZiingRR
06.06.2017 13:37Обсуждая ИИ, намного продуктивней будет отбросить разные плохо определяемые понятия, вроде «сознания» или «свободы воли», и сконцентрироваться на действиях, которые агент может совершать.
Здесь можно почитать подробнее:
As discussed earlier, the concept of “general intelligence” refers to the capacity for efficient cross-domain optimization. Or as Ben Goertzel likes to say, “the ability to achieve complex goals in complex environments using limited computational resources.” Another idea often associated with general intelligence is the ability to transfer learning from one domain to other domains.
fireSparrow
06.06.2017 13:55Да, я тоже согласен, что нужно сосредоточиться на более предметных и конкретных сторонах вопроса.
К сожалению, не все с этим согласны, и в дискуссиях об ИИ я постоянно натыкаюсь на утверждения, что мы не сможем создать ИИ общего назначения, если не дадим ему свободу воли, или эмоции, или личность, или всё вместе.
Aligatro
08.06.2017 08:20Возможно я очень наивен (хотя в этой теме я малограмотен, так что могу сильно ошибаться), но под определение «действия которые агент может совершить» подпадает и скрипт сортировки имён в алфавитном порядке и Геннадий бухгалтер. Только один обладает «сознанием» а другой нет. И как мне кажется расширяя сценарии до бесконечности невозможно будет найти решающий «фактор х».
Как правильно выше заметили, пока понятия воли и сознания не формализованы попытки создать сравнительную таблицу для поиска ключевых отличий — бессмысленны.
Что касается меня, я полагаю как и большинство, в понятия «сознание» вкладывают — понимание того что «я» это «я» (тело, внешность, разум и т.д), «я» как сущность относительно других, принятие решений (обоснование совершенных/совершаемых действий), прогнозирование последствий относительно принятых решений.
Воля — беспрепятственность хода мысли, отсутствие «конечной цели».
В целом я конечно с вам полностью согласен, беспредметные разговоры об абстракциях контрпродуктивны и ведут в никуда, но и предметные как мне кажется невозможны в контексте текущих знаний о природе разума/интеллекта.Aligatro
08.06.2017 08:35+1Хотя знаете, я сейчас подумал и понял, что моё определение сознания так же верно и для демона в linux… Не думал, что дать формализированное определение хотя бы основ будет так чертовски сложно.
P.S Даже с самостоятельной постановки задач, это все равно будет равнозначно верно как для человека так и для программы. Разве что ключевым будет возможность изменять условия для принятия решений.
Nashev
08.06.2017 10:00Если копнуть глубже в сторону людей, обнаружите что свобода воли — это социального уровня конструкт, обеспечивающий названиями внутреннюю возможность саморегулирования в социуме. Она обеспечивает механизмы социальной регуляции понятием персональной ответственности и возможностью обвинять и наказывать, хвалить и поощрять. Сформулировалась эта группа понятий из-за того, что взаимодействующие детальки социума, люди, вынуждены облекать в слова своё поведение и поведение окружающих «от первого лица», со своей позиции. И всё это поверх безусловного детерминизма.
То есть, вопрос свободы воли можно снять с рассмотрения. Остаётся персональная ответственность, чётко зависящая от наличия возможности воздействия методом кнута и пряника.
muhaa
06.06.2017 12:50+1А как же насчет самой задачи создания универсального и эффективно действующего интеллектуального агента? Из выступления может создаться впечатление, что эта задача не так уж сложна, у нас уже есть все для ее решения и она будет так или иначе решена.
Насколько я понимаю, пока есть только простейшие агенты, решающие узкие задачи типа освоения видео-игр. Совершенно немыслимо, чтобы такой агент попытался расшириться до уничтожения мешающего ему хозяина.
Может быть после того, как теория, необходимая для создания универсальных агентов, будет построена, то тогда и станет ясно как мотивировать этих агентов требуемым образом?ZiingRR
06.06.2017 13:13+1Задача сложна, но я уверен, что она будет решена. Законы физики, судя по всему, нам не мешают, а конкурентный рынок, имея непреодолимый стимул в виде астрономических прибылей, рано или поздно создаст подобного интеллектуального агента.
Далее, поскольку ставки высоки, а наличие «теории, необходимой для создания универсальных агентов» и близко не гарантирует быстрое и надёжное решение проблемы безопасности, то начинать исследования будет разумно уже сейчас.muhaa
06.06.2017 14:54Для того чтобы исследовать опасность чего-то нужно представлять как это что-то работает. «Теория, необходимая для создания универсальных агентов» ничего не гарантирует, но это необходимый минимум для начала исследований. Когда этот минимум будет, можно будет за месяц провести исследования глубже, чем за десятилетия предварительных философствований.
С чего вообще известно, что целевая функция типа «больше скрепок» совместима с интеллектом уровня человеческого? Вполне вероятно, что высокий уровень интеллекта разовьется только при наличии множества очень сложных и тонко сбалансированных конкурирующих мотиваций типа тяги к знаниям, одобрения окружающих (или зависти их же) и так далее. Тогда вопрос будет в том, как эти мотивации программировать (сейчас никто понятия не имеет как программировать что-то сложнее тяги к скрепкам) и как смешивать в нужных пропорциях для получения вменяемой особи, не пытающейся разрушить себя и все вокруг как только поумнеет достаточно. А может все обстоит как-то совсем по-другому. Сейчас гадать бесполезно.ZiingRR
06.06.2017 18:16+1Тезис об ортогональности гласит, что можно комбинировать любой уровень интеллекта с любой целью, поскольку интеллект и конечные цели представляют собой ортогональные, то есть независимые, переменные.
Также, отправляю вас на страницу, где в MIRI обосновывают, почему следует заниматься вопросами безопасности ИИ уже сейчас: https://intelligence.org/faq/#early/napa3um
06.06.2017 19:55Разработка стратегий защиты от ИИ (озвучивание таких компетенций) — не более чем маркетинговые (и политические) манёвры, не стОит принимать их слишком близко к сердцу. Strong AI — это прежде всего «бренд» (как минимум до тех пор, пока он не будет создан), кроме веры в него никакого влияния на действительность он не производит.
muhaa
06.06.2017 21:18Спасибо, интересно. Я не знал об этом тезисе. Хотя, выглядит примерно как попытка Пенроуза доказать на основе теоремы Геделя, что мозг не может быть классическим алгоритмом. Слишком много натяжек. Подобные утверждения доказываются в пределе, а в реальных ситуациях все может быть с точностью до наоборот. Например, может оказаться что эффективность AI находится в обратной зависимости с его управляемостью. Очевидно ведь, что чем сложнее в системе обратные связи, тем труднее ей управлять. Тогда и тезис верен и AI с простыми целевыми функциями никто не создаст.
red75prim
06.06.2017 18:02решающие узкие задачи типа освоения видео-игр
Ого. Освоение одной и той-же системой разных игр с разной механикой уже узкая задача?
"Интеллект — это то, что ИИ ещё не умеет делать", как я понимаю?
muhaa
06.06.2017 21:23Вопрос масштабируемости. Можно написать генетический алгоритм, который за миллион шагов построит сеть для хорошей стратегии игры. Но этот алгоритм не будет иметь памяти, не сможет строить стратегию поведения на будущее и так далее. Т.е. это теория в нужном направлении, но еще далеко от решения проблемы AI.
Nashev
07.06.2017 14:36Читали фанфик про искусственный интеллект и маленьких пони? Там не совсем про мешающего хозяина, но тоже эпично вышло.
fireSparrow
07.06.2017 16:22+1Зато в итоге потребности каждого были удовлетворены. Через дружбу и пони.
ZiingRR
07.06.2017 17:04+1Ну так в Дружба — это оптимум был описан ИИ скорее «дружественный», чем наоборот :)
janatem
06.06.2017 14:59Надо бы добавить пояснение по обозначениям: sorta-argmax, как я выяснил поиском, не является общепринятым обозначением. Можно догадаться, что имеется в виду приблизительный argmax, но лучше бы это было сказано явно.
Aligatro
08.06.2017 07:33Мысленный эксперимент о развитии будущего интеллекта через призму «конечной цели» как по мне вообще некорректен…
По сути для верификации сильного ИИ необходимо что-бы он безошибочно проходил аналог или сам тест Тьюринга в 100% случаев из ста. И то, проверка так себе. Как минимум человечеству придется убедиться в наличии у подобного интеллекта самосознания (истинного), что-бы признать его сильным.
И в таком случае мне абсолютно непонятна концепция конечной цели (возможно я неправильно понял статью, поправьте) так как я не представляю сознания без свободы воли, которая невозможна при наличии «конечной цели».
Запрограммировать конечное время, ок, но цель?
На мой взгляд как для статьи о прокачаном machine learning — интересно, но как о сильном ИИ, нет.
Да и в целом я просто не представляю, как подарить сознание без мотивации верной для человека. Даже простенькие нейронные сети работают по упрощённому эволюционному аналогу.
oneiroid
искусственный интелект без самостоятельного целеполагания, по моему мнению, не будет сильным. кроме того, он будет гораздо опаснее самостоятельного, т.к. цели люди задают совсем хреново, судя по ситуации в мире. бог из будущего или смерть!!!
xPomaHx
А у человека какие цели сейчас? Я думаю что разум по природе своей сам себе поставит цель максимизировать информацию, а эту цель можно бесконечно выполнять, пока не узнаешь смысла жизни.
alex1603
У живого цель, выживать приспосабливаясь к новым условиям и с оптимизацией энергопотребления! Информация важна для нас только та которая позволяет выживать и приспосабливаться. Человек развил способность накапливать и анализировать с целью использования для прогнозирования будущего. Нам важно например знать и отличать кошку от собаки и от льва для оценки опасности. Компьютеру в целом на это пофиг как ты его не уговаривай отличать. А на счет смысла жизни то у каждого он свой и поэтому нельзя дать точного ответа на этот вопрос. Мозг это та же база данных о событиях и человека отличает от ИИ восприятие личное. Пока у ИИ не будет персонального отношения ко всему он не может стать личностью и считаться полноценным.
xPomaHx
Я думаю что современный человек строит жизнь свою абсолютно не из целей выжить. Даже работа это скорее для машины и айфона чем для еды.
Вам интересно что было до большого взрыва? мне очень. но вот как это помогает выживать непонятно.
Aligatro
Позвольте, выживание ведь не сводится лишь к добыче еды. И если все же свети его к таковому, то стоит понимать, что цепочка действий необходимым для добычи пропитания и обеспечение оным потомства, многократно усложнилась за время эволюции.
Если отбросить необходимые для здоровья психики базовые потребности индивида в виде: самореализации, актуализации, принадлежности и т.д и полностью сосредоточиться лишь на необходимости добывать еду, то информация о которой вы говорили вполне способна помочь. Например: найти определенный круг знакомых по интересам (стаю), закрепиться внутри за счёт кругозора и знаний (навыков/умений), получить желаемое (задействовав контакты, договориться о трудоустройстве). Разумеется пример метафоричен.
В целом моя мысль сводиться к тому, что фактически любая информация (даже бесполезная на первый взгляд) помогает выживать и приспосабливаться, через длинную цепочку следствий.