
В предыдущей статье — часть 1, обзорная — я рассказал о том, зачем нужны распределенные структуры данных (далее — РСД) и разобрал несколько вариантов, предлагаемых распределенным кешем Apache Ignite.
Сегодня же я хочу рассказать о подробностях реализации конкретных РСД, а также провести небольшой ликбез по распределенным кешам.
Итак:

Начнем с того, что, как минимум в случае с Apache Ignite, РСД не реализованы с нуля, а являются надстройкой над распределенным кешем.
Распределенный кеш — система хранения данных, в которой информация хранится более чем на одном сервере, но при этом обеспечивается доступ ко всему объему данных сразу.
Основным преимуществом подобного рода систем является возможность впихнуть невпихуемое хранить огромные объемы данных без разбиения их на куски, ограниченные объемами конкретных накопителей или даже целых серверов.
Чаще всего такие системы позволяют динамически наращивать объемы хранения посредством добавления новых серверов в систему распределенного хранения.
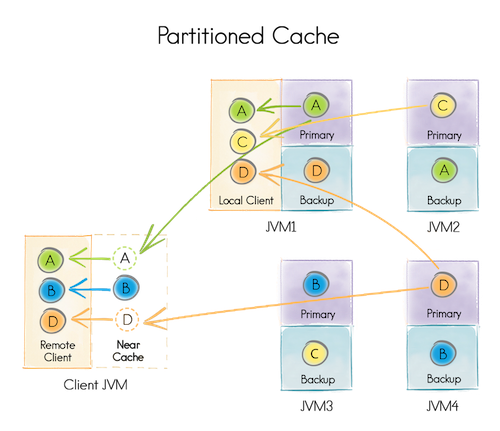
Чтобы иметь возможность изменять топологию кластера (добавлять и удалять серверы), а также балансировать данные, используется принцип партиционирования (секционирования) данных.
При создании распределенного кеша указывается число партиций, на которые будут разделены данные, например, 1024. При добавлении данных выбирается партиция, ответственная за их хранение, например по хешу ключа. Каждая партиция может храниться на одном или нескольких серверах, в зависимости от конфигурации кеша. Для каждой конкретной топологии (набора серверов), сервер, где будет храниться партиция, вычисляется по заранее заданному алгоритму.
Например, при старте кеша укажем что:
- партиций будет 4 [A,B,C,D]
- каждая партиция будет храниться на двух серверах (т.е. каждая будет иметь по одному бекапу)
Запустим четыре data node [JVM 1-4] (ответственные за хранение данных) и одну client node [Client JVM] (ответственную только за предоставление доступа к данным).
Каждая из четырёх data node может быть использована как client node (то есть предоставлять доступ ко всем данным). Например, JVM 1 смогла получить данные по партициям A,C,D, хотя, локально, располагает только A (Primary) и D (Backup).
Любая data node распределенного кеша для конкретной партиции может являться Primary или Backup, либо вообще не содержать партицию.
Primary node отличается от Backup тем, что именно она обрабатывает запросы в рамках партиции и, по необходимости, реплицирует результаты на Backup node.
В случае выхода Primary node из строя, одна из Backup node становится Primary.
В случае выхода Primary node из строя, при отсутствии Backup node, партиция считается утерянной.
Некоторые распределенные кеши предоставляют возможность локально кешировать данные, расположенные на других node. Например Client JVM локально закешировала партицию B и не будет запрашивать дополнительные данные, пока они не изменятся.
Рапределенные кеши разделяют на Partitioned и Replicated.
Разница состоит в том, что Partitioned-кеш хранит один (или один + N бекапов) экзепляр партиции в рамках кластера, а Replicated хранит по одному экземпляру партиции на каждой data node.

Partitioned-кеш имеет смысл использовать для хранения данных, чьи объемы превышают возможности отдельных серверов, а Replicated — для хранения одних и тех же данных «везде».
Хорошим примером для понимания является связка Сотрудник — Организация. Сотрудников много, и они довольно часто меняются, так что лучше хранить их в Partitioned-кеше. Организаций же мало, и меняются они редко, значит имеет смысл хранить их в Replicated-кеше, чтение из него гораздо быстрее.
Итак, перейдем к подробностям реализации.
Хочу еще раз обозначить, что речь идет о реализации в рамках исходного кода Apache Ignite, в других распределенных кешах реализация может отличаться.
Для обеспечения работы РСД используются два кеша: один Replicated и один Partitioned.
Replicated-кеш — в данном случае это системный кеш, (ignite-sys-cache) отвечающий, в том числе, за хранение информации об РСД, зарегистрированных в системе.
Partitioned-кеш (ignite-atomics-sys-cache) хранит данные, необходимые для работы РСД, и их состояние.
Итак, большинство РСД создается следующим образом:
- Транзакция стартует.
- В кеше
ignite-sys-cache, по ключуDATA_STRUCTURES_KEY, беретсяMap<Имя_РСД, DataStructureInfo>(при необходимости создается), и в нее добавляется новый элемент с описанием, например,IgniteAtomicReference. - В кеш
ignite-atomics-sys-cache, по ключу из добавленного ранееDataStructureInfoдобавляется элемент, отвечающий за состояние РСД. - Транзакция коммитится.
При первом запросе на создание РСД создается новый экземпляр, а последующие запросы получают уже ранее созданный.
IgniteAtomicReference и IgniteAtomicLong (краткая вводная)
Третий шаг инициализации для обоих типов сводится к добавлению в ignite-atomics-sys-cache объекта типа GridCacheAtomicReferenceValue или GridCacheAtomicLongValue.
Оба класса содержат одно единственное поле val.
Соответственно, любое изменение IgniteAtomicReference:
// Изменим значение, если текущее соответствует ожидаемому.
ref.compareAndSet(expVal, newVal);… это запуск EntryProcessor со следующим кодом метода process:
EntryProcessor — это функция, позволяющая атомарно выполнять сложные операции над объектами в кеше.
Метод process принимает MutableEntry (объект в кеше) и может изменить его значение.
EntryProcessor, по сути, является альтернативой транзакции по одному ключу (иногда даже реализуется как транзакция).
Как следствие, гарантируется, что над одним объектом в кеше будет выполняться только один EntryProcessor в единицу времени.
Boolean process(MutableEntry<GridCacheInternalKey, GridCacheAtomicReferenceValue<T>> e, Object... args) {
GridCacheAtomicReferenceValue<T> val = e.getValue();
T curVal = val.get();
// Переменные expVal и newVal — параметры метода
// ref.compareAndSet(expVal, newVal);
if (F.eq(expVal, curVal)) {
e.setValue(new GridCacheAtomicReferenceValue<T>(newVal));
return true;
}
return false;
}IgniteAtomicLong является дефакто расширением IgniteAtomicReference, поэтому и его метод compareAndSet реализован аналогичным образом.
Метод incrementAndGet не имеет проверок на ожидаемое значение, а просто добавляет единицу.
Long process(MutableEntry<GridCacheInternalKey, GridCacheAtomicLongValue> e, Object... args) {
GridCacheAtomicLongValue val = e.getValue();
long newVal = val.get() + 1;
e.setValue(new GridCacheAtomicLongValue(newVal));
return newVal;
}IgniteAtomicSequence (краткая вводная)
При создании каждого экземпляра IgniteAtomicSequence...
// Создадим или получим ранее созданный IgniteAtomicSequence.
final IgniteAtomicSequence seq = ignite.atomicSequence("seqName", 0, true);… ему выделяется пул идентификаторов.
// Начинаем транзакцию
try (GridNearTxLocal tx = CU.txStartInternal(ctx, seqView, PESSIMISTIC, REPEATABLE_READ)) {
GridCacheAtomicSequenceValue seqVal = cast(dsView.get(key), GridCacheAtomicSequenceValue.class);
// Нижняя граница локального пула идентификаторов
locCntr = seqVal.get();
// Верхняя граница
upBound = locCntr + off;
seqVal.set(upBound + 1);
// Обновляем экземпляр GridCacheAtomicSequenceValue в кеше
dsView.put(key, seqVal);
// Завершаем транзакцию
tx.commit();Соответственно, вызов...
seq.incrementAndGet(); … просто инкрементирует локальный счетчик до достижения верхней границы пула значений.
При достижении границы происходит выделение нового пула идентификаторов, аналогично тому, как это происходит при создании нового экземпляра IgniteAtomicSequence.
IgniteCountDownLatch (краткая вводная)
Декремент счетчика:
latch.countDown();… реализуется следующим образом:
// Начинаем транзакцию
try (GridNearTxLocal tx = CU.txStartInternal(ctx, latchView, PESSIMISTIC, REPEATABLE_READ)) {
GridCacheCountDownLatchValue latchVal = latchView.get(key);
int retVal;
if (val > 0) {
// Декрементируем значение
retVal = latchVal.get() - val;
if (retVal < 0)
retVal = 0;
}
else
retVal = 0;
latchVal.set(retVal);
// Сохраняем значение
latchView.put(key, latchVal);
// Завершаем транзакцию
tx.commit();
return retVal;
}Ожидание декрементации счетчика до 0...
latch.await();… реализуется через механизм Continuous Queries, то есть при каждом изменении GridCacheCountDownLatchValue в кеше все экземпляры IgniteCountDownLatch уведомляются об этих изменениях.
Каждый экземпляр IgniteCountDownLatch имеет локальный:
/** Internal latch (transient). */
private CountDownLatch internalLatch;Каждое уведомление декрементирует internalLatch до актуального значения. Поэтому latch.await() реализуется очень просто:
if (internalLatch.getCount() > 0)
internalLatch.await();IgniteSemaphore (краткая вводная)
Получение разрешения...
semaphore.acquire();… происходит следующим образом:
// Пока разрешение не будет получено
for (;;) {
int expVal = getState();
int newVal = expVal - acquires;
try (GridNearTxLocal tx = CU.txStartInternal(ctx, semView, PESSIMISTIC, REPEATABLE_READ)) {
GridCacheSemaphoreState val = semView.get(key);
boolean retVal = val.getCount() == expVal;
if (retVal) {
// Сохраняем информацию о получивших разрешения.
// В случае выхода из строя какой-либо node,
// захваченные ею разрешения будут возвращены.
{
UUID nodeID = ctx.localNodeId();
Map<UUID, Integer> map = val.getWaiters();
int waitingCnt = expVal - newVal;
if (map.containsKey(nodeID))
waitingCnt += map.get(nodeID);
map.put(nodeID, waitingCnt);
val.setWaiters(map);
}
// Устанавливаем новое значение
val.setCount(newVal);
semView.put(key, val);
tx.commit();
}
return retVal;
}
}
Возврат разрешения...
semaphore.release();… происходит аналогичным образом, за исключением того, что новое значение больше текущего.
int newVal = cur + releases;IgniteQueue (краткая вводная)
В отличие от остальных РСД, IgniteQueue не использует ignite-atomics-sys-cache. Используемый кеш описывается через параметр colCfg.
// Создадим или получим ранее созданный IgniteQueue.
IgniteQueue<String> queue = ignite.queue("queueName", 0, colCfg);В зависимости от указанного Atomicity Mode (TRANSACTIONAL, ATOMIC) можно получить разные варианты IgniteQueue.
queue = new GridCacheQueueProxy(cctx, cctx.atomic() ?
new GridAtomicCacheQueueImpl<>(name, hdr, cctx) :
new GridTransactionalCacheQueueImpl<>(name, hdr, cctx));В обоих случаях состояние IgniteQueue контролируется с помощью:
class GridCacheQueueHeader{
private long head;
private long tail;
private int cap;
... Для добавления элемента используется AddProcessor...
Long process(MutableEntry<GridCacheQueueHeaderKey, GridCacheQueueHeader> e, Object... args) {
GridCacheQueueHeader hdr = e.getValue();
boolean rmvd = queueRemoved(hdr, id);
if (rmvd || !spaceAvailable(hdr, size))
return rmvd ? QUEUE_REMOVED_IDX : null;
GridCacheQueueHeader newHdr = new GridCacheQueueHeader(hdr.id(),
hdr.capacity(),
hdr.collocated(),
hdr.head(),
hdr.tail() + size, // Выделяем место под элемент
hdr.removedIndexes());
e.setValue(newHdr);
return hdr.tail();
}… который, по сути, просто перемещает указатель на хвост очереди.
После этого...
// По ключу, сформированному на основе
// нового hdr.tail()
QueueItemKey key = itemKey(idx);… в очередь добавляется новый элемент:
cache.getAndPut(key, item);Удаление элемента происходит аналогично, но указатель меняется не на tail, а на head...
GridCacheQueueHeader newHdr = new GridCacheQueueHeader(hdr.id(),
hdr.capacity(),
hdr.collocated(),
hdr.head() + 1, // Двигаем указатель на голову
hdr.tail(),
null);… и элемент удаляется.
Long idx = transformHeader(new PollProcessor(id));
QueueItemKey key = itemKey(idx);
T data = (T)cache.getAndRemove(key);Разница между GridAtomicCacheQueueImpl и GridTransactionalCacheQueueImpl состоит в том, что:
GridAtomicCacheQueueImplпри добавлении элемента сначала атомарно инкрементируетhdr.tail(), а потом уже добавляет по полученному индексу элемент в кеш.
GridTransactionalCacheQueueImplделает оба действия в рамках одной транзакции.
Как следствие, GridAtomicCacheQueueImpl работает быстрее, но может возникнуть проблема консистентности данных: если информация о размере очереди и сами данные сохраняются не одновременно, то и вычитаться они могут не одновременно.
Вполне вероятна ситуация, когда внутри метода poll видно, что очередь содержит новые элементы, но самих элементов еще нет. Такое крайне редко, но всё же возможно.
Эта проблема решается таймаутом ожидания значения.
long stop = U.currentTimeMillis() + RETRY_TIMEOUT;
while (U.currentTimeMillis() < stop) {
data = (T)cache.getAndRemove(key);
if (data != null)
return data;
}Бывали реальные случаи, когда не хватало и пятисекундного таймаута, что приводило к потерям данных в очереди.
Вместо заключения
Я хотел бы еще раз отметить, что распределенный кеш — это, по сути, ConcurrentHashMap в рамках множества компьютеров, объединенных в кластер.
Распределенный кеш может быть использован для реализации множества важных, сложных, но надежных систем.
Частным случаем реализации являются распределенные структуры данных, а в целом они применяются для хранения и обработки колоссальных объемов данных в реальном времени, с возможностью увеличения объемов или скорости обработки простым добавлением новых узлов.
Cloud4Y
Спасибо, интересная статья.
Удивительно, что именно сегодня, мы опубликовали пост «Как принять закон или обработка данных в распределённых системах понятным языком» В этой статье в забавной манере рассказывается о подходах к согласованной обработке данных