
Группа исследователей из питтсбургского подразделения Disney Research разработала систему компьютерного зрения, которая использует некоторые принципы человеческого зрения (pdf). В частности, она содержит алгоритмы для самообучения и способна со временем улучшать распознавание объектов.
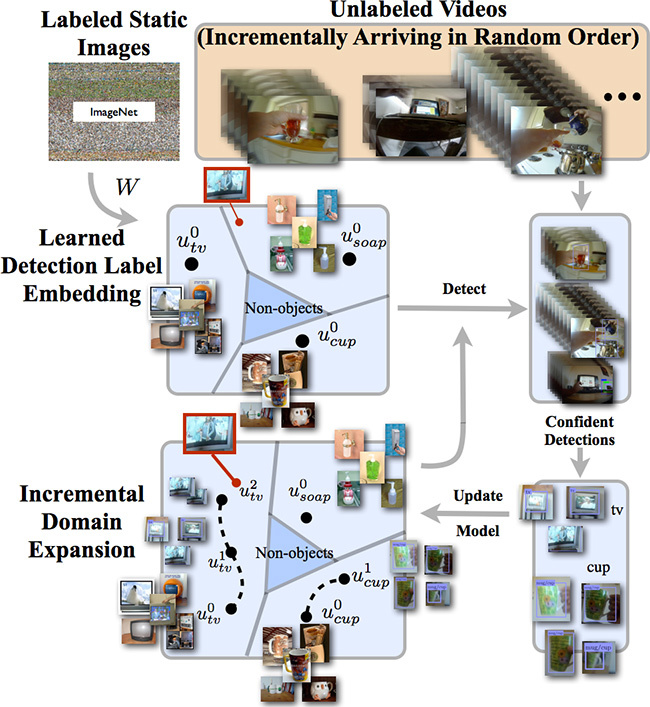
Как и большинство других систем компьютерного зрения, разработка Disney Research строит концептуальную модель для каждого объекта, будь это самолёт или дозатор мыла. При этом используется обучаемый алгоритм, который анализирует множество фотографий данного объекта.
Отличительная особенность алгоритма Disney Research — в том, что он впоследствии использует эту модель для распознавания объектов на видео, одновременно извлекая новую информацию об этих объектах и дополняя модель, заложенную изначально. Это позволяет распознавать объекты в более широком диапазоне, даже если они выглядят иначе, чем на встречавшихся ранее образцах.
На иллюстрациях (кликабельны) показан результат распознавания образов. В верхнем ряду находятся тестовые изображения из базы ImageNet, которые использовались для обучения изначальной модели. В нижнем ряду — примеры корректного распознавания объектов программой IDE-LME. Исследователи обращают внимание, что распознанные объекты на фотографиях существенно отличаются по внешнему виду от тех, которые использовались для обучения системы.


«Процесс [самообучения] продолжается, потенциально бесконечно, в течение всего срока существования системы распознавания, — говорит Леонид Сигаль (Leonid Sigal), ведущий научный сотрудник Disney Research Pittsburgh. — Это самообучаемая система, которая непрерывно развивается путём бесконтрольного получения опыта, составляя всё более полную и сложную модель мира».
Концептуальная модель для каждого объекта постепенно расширяется и уточняется по мере того, как система сталкивается с новой информацией. Теоретически, такой метод может привести к тому, что действуя без надзора, система припишет объекту несвойственные для него характеристики, из-за чего возникнут ошибки распознавания. Но авторы программы говорят, что такая проблема пока не замечена.
Кроме Сигаля, в числе авторов научной работы указаны Алина Кузнецова (Alina Kuznetsova), Бодо Розенхан (Bodo Rosenhahn) из университета Вильгельма Лейбница (Ганновер, Германия) и бывший сотрудник Disney Сен Хван Ю (Sung Ju Hwang), ныне работающий в Национальном институте науки и технологий в Ульсане (Южная Корея).
Презентация научной работы состоялась на конференции IEEE по компьютерному зрению и распознаванию образов в Бостоне (7-12 июня 2015 г.).
samodum
Интересуют детали реализации алгоритма, а то получится потом как с тем «леопардовым диваном» habrahabr.ru/post/259191
barmaley_exe
Так в тексте же есть ссылка на статью.
Что может означать, что они таки используют глубокие сети для извлечения признаков из картинок.Нейросети в их описании замечены не были, но в конце они говорят