

Тема искусственного интеллекта остается в фокусе интереса большого количества людей. Главная причина неослабевающего внимания публики в том, что за последние годы мы узнали о сотнях новых проектов, где используются технологии слабого ИИ. Весьма вероятно, что ныне живущие на планете люди смогут воочию застать появление сильного ИИ. Под катом история о том, когда именно ждать башковитых роботов в вашей квартире. Спасибо за светлые мысли ZiingRR и Владимиру Шакирову. Enjoy.
Какие перемены ждут нас, когда машины будут во многом превосходить своих создателей? Известные ученые и исследователи дают совершенно разные прогнозы: от очень пессимистичных предсказаний ведущего специалиста лаборатории искусственного интеллекта Baidu Эндрю Ына до сдержанных предположений эксперта Google, одного из авторов метода обратного распространения ошибки для тренировки многослойной нейронной сети Джеффри Хинтона, и оптимистичных доводов Шейна Легга, сооснователя компании DeepMind (ныне в составе Alphabet).
Обработка естественного языка
Давайте начнем с некоторых достижений в области формирования естественного языка. Для оценки моделей языка в компьютерной лингвистике используется перплексия (perplexity) — мера того, насколько хорошо модель предсказывает детали тестовой коллекции. Чем меньше перплексия, тем лучше языковая модель, взяв одно слово из предложения, вычисляет вероятностное распределение следующего слова.

Если нейронная сеть делает ошибку (логическую, синтаксическую, прагматическую), значит, она дала слишком большую вероятность неподходящим словам, т.е. перплексия еще не оптимизирована.
Когда иерархические нейронные чатботы достигнут достаточно низкой перплексии, они, скорее всего, смогут писать связные тексты, давать четкие рассудительные ответы, последовательно и логически рассуждать. Мы сможем создать разговорную модель и имитировать стиль и убеждения конкретного человека.
Какова вероятность развития перплексии в ближайшем будущем?
Давайте сравним две замечательных работы: «Contextual LSTM models for large scale NLP tasks» («Контекстуальные LSTM-модели для масштабных NLP-задач», работа №1) и «Exploring the limits of language modeling» («Исследование границ языкового моделирования», работа №2).

Разумно предположить, что если в «Contextual LSTM models for large scale NLP tasks» использовать 4096 скрытых нейронов, то перплексия будет меньше 20, а 8192 скрытых нейрона могут дать перплексию меньше 15. Ансамбль моделей с 8192 скрытыми нейронами, обученными на 10 млрд. слов, вполне может дать перплексию значительно ниже 10. Пока неизвестно, насколько здраво сможет рассуждать подобная нейросеть.
Возможно, что уже в ближайшее время понижение перплексии сможет позволить нам создать нейросетевые чатботы, способные писать осмысленные тексты, давать четкие рассудительные ответы и поддерживать беседу.
Если понять, как оптимизировать перплексию, то можно будет добиться неплохих результатов. Также предлагают частичное решение проблемы через состязательное обучение (adversarial learning). Статья «Generating sequences from continuous space» («Генерирование последовательностей из непрерывного пространства») демонстрирует впечатляющие преимущества состязательного обучения.
Для автоматической оценки качества машинного перевода используют метрику BLEU, определяющую процент n-грамм (последовательности слогов, слов или букв), совпавших в машинном переводе и эталонном переводе предложения. BLEU оценивает качество перевода по шкале от 0 до 100 на основании сравнения человеческого перевода и машинного перевода и поиска общих фрагментов – чем больше совпадений, тем лучше перевод.
По метрике BLEU человеческий перевод с китайского на английский с массивом данных MT03 набирает 35,76 баллов. Однако сеть «GroundHog» набрала 40,06 баллов BLEU на том же тексте и с тем же массивом данных. Впрочем, тут не обошлось без лайфхака: оценку по максимальному правдоподобию заменили своим собственным критерием MRT, что повысило баллы BLEU с 33,2 до 40,06. В отличии от обычной оценки по методу максимального правдоподобия, обучение с минимальным риском может напрямую оптимизировать параметры модели в отношении оценочных метрик. Таких же впечатляющих результатов можно добиться за счет повышения качества перевода с помощью монолингвальных данных.
Современные нейросети переводят в 1000 раз быстрее человека. Изучение иностранных языков становится все менее полезной задачей, поскольку машинный перевод совершенствуется быстрее, чем обучается большинство людей.
Компьютерное зрение


Top-5 error — метрика, в которой алгоритм может выдать 5 вариантов класса картинки и ошибка засчитывается, если среди всех этих вариантов нет правильного.
В статье «Identity mappings in deep residual networks» («Сопоставление идентификации в глубоких остаточных сетях») приводится цифра 5,3% по метрике top-5 error с одиночными моделями, в то время, как уровень человека составляет 5,1%. В «глубоких остаточных сетях» одиночная модель дает 6,7%, а ансамбль этих моделей с алгоритмом Inception дает 3,08%.
Также хорошие результаты достигаются за счет «глубоких нейросетей со стохастической глубиной» (deep networks with stochastic depth). Сообщается об ошибке ? 0,3% в примечаниях к базе данных ImageNet, поэтому реальная ошибка на ImageNet может скоро стать ниже 2%. ИИ превосходит человека не только по классификации ImageNet, но и по выделению границ. Выполнение задания по классификации видео в массиве данных SPORTS-1M (487 классов, 1 млн. видео) улучшилось с 63,9% (2014) до 73,1% (март 2015).
Сверточные нейронные сети (convolutional neural network, CNN) превосходят человека еще и по скорости — в ?1000 раз быстрее человека (обратите внимание, что речь идет о группах) или даже в ?10 000 раз быстрее после сравнения. Обработка видео 24 к/с на AlexNet требует всего 82 Гфлоп/с, а на GoogleNet — 265 Гфлоп/с.
Лучшие исходные данные работают со скоростью 25 мс. Всего видеокарте NVIDIA Titan X (6144 Гфлоп/сек) требуется 71 мс для отображения 128 кадров, поэтому для воспроизведения в реальном времени видео с 24 кадр/сек необходимо 6144 Гфлоп/сек *(24/128)*0,025 ? 30 Гфлоп/с. Чтобы обучать методом обратного распространения ошибки (backpropagation), понадобится 6144 Гфлоп/сек*(24/128)*0,071 ? 82 Гфлоп/с. Те же расчеты для GoogleNet дают 83 Гфлоп/сек и 265 Гфлоп/с соответственно.

Сеть DeepMind умеет генерировать фотореалистичные изображения на основе текста, введенного человеком
Сети отвечают на вопросы, основанные на изображениях. Кроме того, сети могут описывать изображения с помощью предложений, в некоторых метриках даже лучше, чем люди. Наряду с переводом видео=> текст, проводятся эксперименты по переводу текст=> изображение.
Кроме того, сети активно работают с распознаванием речи.

Скорость развития очень высока. Например, в Google относительное количество ошибочно распознанных слов снизилось с 23% в 2013 г. до 8% в 2015 г.
Обучение с подкреплением

AlphaGo — мощный ИИ в его собственном очень маленьком мире, представляющем собой всего лишь доску с камнями. Если усовершенствовать AlphaGo с помощью непрерывного обучения с подкреплением (и если нам удастся заставить его работать со сложными задачами реального мира), то он превратится в настоящий ИИ в реальном мире. Кроме того, есть планы обучать его по виртуальным видеоиграм. Зачастую видеоигры содержат намного больше интересных задач, чем средний человек встречает в реальной жизни. AlphaGo представляет собой удачный пример современного обучения с подкреплением с современной сверточной нейронной сетью.
Эффективное обучение без учителя

Существуют модели, позволяющие компьютеру самостоятельно создавать данные и информацию, например, фотографии, фильмы или музыку. Система Deep Generative Adversarial Networks (DCGAN, глубокие генеративные сверточные состязательные сети) способна создавать уникальные фотореалистичные изображения с помощью грамотного сочетания двух глубоких нейросетей, которые «состязаются» друг с другом.
Модели генерации языка, сводящие к минимуму перплексию, обучаются без учителя и за последнее время очень продвинулись вперед. Алгоритм «Skip-thought vectors» генерирует векторное выражение для предложений, позволяющее обучать линейные классификаторы над этими векторами и их косинусными расстояниями, чтобы решить многие проблемы обучения с учителем на современном уровне. Недавние работы продолжают развивать метод «computer vision as inverse graphics» («компьютерное зрение в роли обратных графических сетей»).
Мультимодальное обучение
Мультимодальное обучение используется для повышения эффективности задач, связанных с классификацией видео. Мультимодальное обучение без учителя используется в обосновании текстовых фраз в изображениях с помощью механизма, основанного на внимании, таким образом, модальности обучают друг друга. В алгоритме «Neural self-talk» нейросеть видит картинку, на ее основе генерирует вопросы, и сама же на эти вопросы отвечает.
Аргументы с точки зрения нейронауки
Вот упрощенный вид коры головного мозга человека:

Грубо говоря, 15% мозга человека предназначены для малоактивных визуальных задач (затылочная доля).
Другие 15% — для распознавания изображений и действий (чуть больше половины височной доли).
Еще 15% — для слежения за объектом и его обнаружения (теменная доля). А 10% предназначены для обучения с подкреплением (глазнично-лобная кора и часть префронтальной коры головного мозга). Вместе они образуют около 70% всего мозга.
Современные нейронные сети работают примерно на уровне человека, если брать только эти 70% головного мозга. К примеру, сети CNN совершают в 1,5 раза меньше ошибок в ImageNet, чем человек, при этом действуют в 1000 раз быстрее.
С точки зрения нейронауки, мозг человека имеет одинаковую структуру по всей поверхности. Нейроны, действующие по одному и тому же принципу, уходят вглубь мозга всего на 3 мм. Механизмы работы префронтальной коры и других частей головного мозга практически не отличаются. По скорости вычислений и сложности алгоритмов они также схожи. Будет странно, если современные нейронные сети не смогут справиться с оставшимися 30% в ближайшие несколько лет.
Около 10% отвечают за малоактивную моторно-двигательную деятельность (зоны 6,8). Однако люди, от рождения не имеющие пальцев, испытывают проблемы с мелкой моторикой, но при этом их умственное развитие в норме. У людей, страдающих синдромом тетраамелии, с рождения нет ни рук, ни ног, но полностью сохраняется интеллект. К примеру, Хиротада Ототакэ, спортивный журналист из Японии, стал известен, написав свои мемуары, разошедшиеся огромными тиражами. Он также преподавал в школе. Ник Вуичич написал множество книг, закончил Университет Гриффита, получил степень бакалавра коммерции и теперь читает мотивационные лекции.
Одной из функций дорсолатеральной префронтальной зоны (DLPFC) передней коры головного мозга является внимание, которое сейчас активно используется в LSTM-сетях (долгая краткосрочная память от англ. long short-term memory; LSTM).
Единственная часть, где пока не достигнут уровень человека, — это зоны 9, 10, 46, 45, которые совместно составляют только 20% коры головного мозга человека. Эти зоны отвечают за сложные рассуждения, использование сложных инструментов, сложный язык. Тем не менее, в статьях «A neural conversational model» («Нейронная разговорная модель»), «Contextual LSTM…» («Контекстуальная LSTM-сеть…»), «Playing Atari with deep reinforcement learning» («Играя в Atari с глубоким обучением с подкреплением»), «Mastering the game of Go…» («Развивая мастерство в игру Го…») и многих других активно обсуждается данная проблема.
Нет никаких оснований полагать, что с этими 30% справиться будет сложнее, чем с уже побежденными 70%. Как-никак, сейчас намного больше исследователей занимаются вопросами глубокого обучения, у них больше знаний и больше опыта. Кроме того, и компаний, заинтересованных глубоким обучением, стало в разы больше.
Знаем ли мы, как работает наш мозг?

Детальная расшифровка коннектома заметно шагнула вперед после создания многолучевого растрового электронного микроскопа. Когда была получена экспериментальная картина коры головного мозга размером 40x40x50 тыс. м3 и разрешением 3x3x30 нм, лаборатории получили грант на описание коннектома фрагмента мозга крысы размером 1x1x1 мм3.
Во многих задачах для алгоритма обратного распространения ошибки (backpropagation) весовая симметрия не важна: ошибки могут распространяться через фиксированную матрицу, при этом все будет работать. Такое парадоксальное заключение — ключевой шаг к теоретическому пониманию работы мозга. Рекомендую также почитать статью «Towards Biologically Plausible Deep Learning» («Вперед к биологически правдоподобному глубокому обучению»). Авторы в теории рассуждают о возможности мозга выполнять задания в глубоких иерархиях.
Недавно была предложена функция STDP (синаптическая пластичность, зависящая от момента времени импульса от англ. Spike Timing Dependent Plasticity). Это неконтролируемая целевая функция, несколько похожая на ту, что используется, например, в инструменте анализа семантики естественных языков word2vec. Авторы изучили пространство полиномиальных локальных правил обучения (предполагается, что в мозге правила обучения локальные) и обнаружили, что их превосходит алгоритм обратного распространения ошибки. Существуют также методы дистанционного обучения, не требующие алгоритма обратного распространения. Хотя они не могут конкурировать с обычным глубоким обучением, мозг, возможно, может использовать что-то типа этого, учитывая его фантастическое количество нейронов и синаптических связей.
Так что же отделят нас от ИИ уровня человека?
Ряд недавних статей о сетях памяти и нейронных машинах Тьюринга позволяют использовать память произвольно большого размера, сохраняя при этом приемлемое количество параметров модели. Иерархическая память предоставила доступ к памяти сложности алгоритма O(log n) вместо обычных операций O(n), где n — размер памяти. Нейронные машины Тьюринга с обучением с подкреплением предоставили доступ к памяти O(1). Это важный шаг к реализации систем типа IBM Watson на совершенно непрерывных дифференцируемых нейронных сетях, повышению результатов Allen AI challenge с 60% до практически 100%. С помощью сдерживающих факторов в рекуррентных слоях можно также добиться того, чтобы объемная память использовала приемлемое количество параметров.
Neural programmer — это нейронная сеть, расширенная набором арифметических и логических операций. Возможно, это первые шаги к непрерывной дифференцируемой системе Wolphram Alpha, основанной на нейронной сети. У метода «учись учиться» («learn how to learn») огромный потенциал.
Не так давно был предложен алгоритм SVRG. Эта сфера деятельности направлена на теоретическое использование значительно лучших методов градиентного спуска.
Есть работы, которые в случае успеха, позволят обучать с весьма большими скрытыми слоями: «Unitary evolution RNN», «Tensorizing neural networks».
«Net2net» и «Network morphism» позволяют автоматически инициализировать новую архитектуру нейросети, используя весы старой архитектуры нейросети, чтобы тут же получить производительность последней. Это рождение модульного подхода к нейросетям. Просто скачиваете предварительно обученные модули для зрения, распознавания речи, генерации речи, рассуждения, роботизации и т.д и настраиваете их под конечную задачу.
Вполне целесообразно включать новые слова в вектор предложения методом глубокого обучения. Однако современные LSTM-сети обновляют вектор ячейки, когда новое слово дается методом малослойного обучения (shallow learning). Эту проблему можно решить с помощью глубоких рекуррентных нейронных сетей. Успешное применение групповой нормализации (batch normalization) и дропаута (dropout) в отношении рекуррентных слоев могло бы позволить обучать LSTM-сети с глубоким переходом (deep-transition LSTM) еще эффективнее. Это также помогло бы иерархическим рекуррентным сетям
Несколько современных достижений были побиты алгоритмом, позволяющим научить рекуррентные нейронные сети понимать, сколько расчетных шагов необходимо сделать между получением входных данных и их выводом. Идеи из остаточных сетей также повысили бы производительность. Например, стохастические глубокие нейронные сети позволяют увеличить глубину остаточных сетей с более, чем 1200 слоями, при этом получить реальные результаты.
Мемристоры могут ускорить обучение нейронных сетей в несколько раз и дадут возможность использовать триллионы параметров. Квантовый компьютинг обещает еще больше.
Глубокое обучение стало не только легким, но и дешевым. За полмиллиарда долларов можно добиться производительности около 7 терафлопов. А еще за полмиллиарда подготовить 2000 высокопрофессиональных исследователей. Получается, что при бюджете, вполне реальном для каждой крупной страны или корпорации, можно нанять две тысячи профессиональных исследователей ИИ и дать каждому из них по необходимой вычислительной мощности. Такое вложение средства кажется очень даже целесообразным, учитывая ожидаемый технологический бум в области ИИ в ближайшие годы.
Когда машины достигнут уровня профессиональных переводчиков, в обработку естественного языка, основанную на глубоком обучении, хлынут миллиарды долларов. То же самое ждет и другие сферы нашей жизни, такие, как разработка лекарственных средств.
Прогнозы относительно ИИ уровня человека
Эндрю Ын высказывается скептически: «Возможно, через сотни лет технические знания человека позволят ему создать страшных роботов-убийц». «Может, через сотни, может, через тысячи лет — я не знаю — какой-нибудь ИИ превратится в дьявола».
Джеффри Хинтон придерживается умеренных взглядов: «Я не берусь говорить о том, что будет через пять лет — думаю, за пять лет мало что изменится».
Шейн Легг делал такие прогнозы: «Я даю логарифмически нормальное распределение в среднем на 2028 г. и пиком развития на 2025 г., при условии, что не случится ничего непредвиденного типа ядерной войны. Также к своему предсказанию я бы хотел добавить, что в ближайшие 8 лет надеюсь увидеть впечатляющий прото-ИИ». На рисунке ниже показано прогнозируемое логарифмически нормальное распределение.
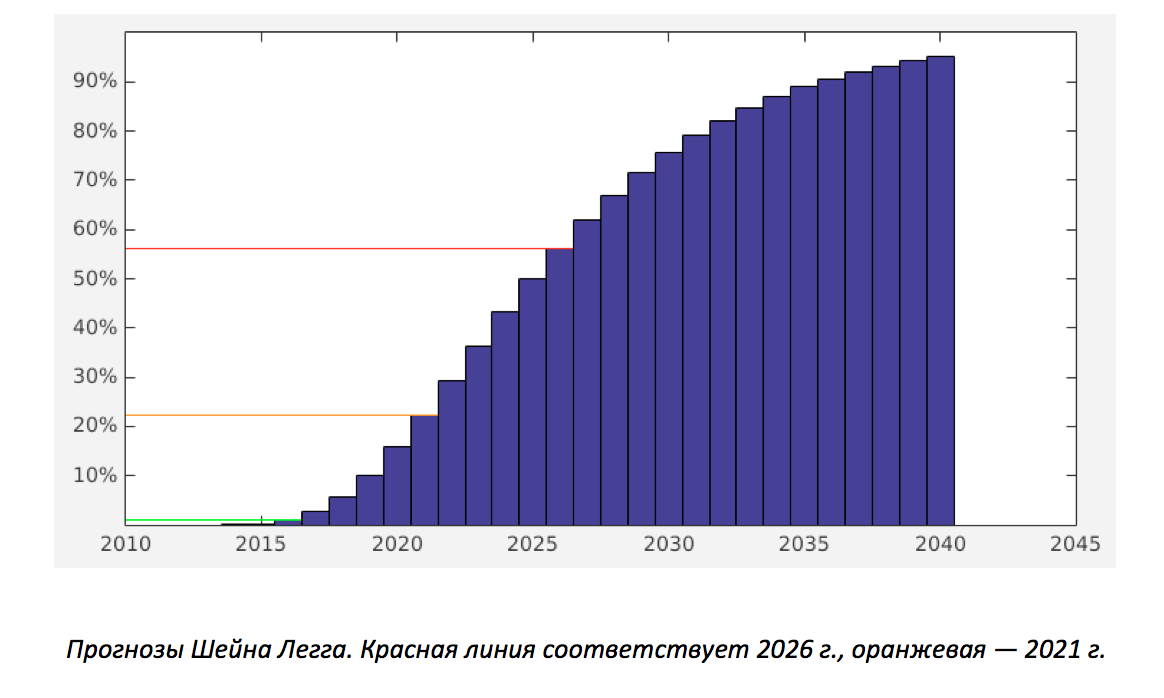
Данный прогноз был сделан в конце 2011 г. Однако широко распространено мнение, что после 2011 г. сфера ИИ начала развиваться непредсказуемо большими темпами, так что, скорее всего, предсказания вряд ли станут пессимистичнее, чем были. На самом же деле у каждого мнения есть много своих сторонников.
Опасен ли ИИ с точки зрения машинного обучения?

С помощью глубокого обучения и массивов с этическими данными мы можем научить ИИ нашим человеческим ценностям. Принимая во внимание достаточно большой и широкий объем данных, у нас может получиться вполне дружелюбный ИИ, по крайней мере, дружелюбнее, чем многие люди. Тем не менее, данный подход не решает всех проблем безопасности. Можно также прибегнуть к обратно стимулированному обучению (inverse reinforcement learning), но все равно потребуется массив данных доброжелательности/недоброжелательности по отношению к человеку для тестирования.
Сложно создать массив этических данных. Существует множество культур, политических партий и мнений. Сложно создать непротиворечивые примеры того, как необходимо себя вести, обладая большой властью. Если же в обучающем массиве таких примеров не будет, то вполне вероятно в подобных ситуациях ИИ будет вести себя ненадлежащим образом и не сможет делать правильные выводы (отчасти потому что нравственность невозможно привести к какой-то норме).
Другое серьезное опасение связано с тем, что ИИ, возможно, словно капельница с дофамином будет пичкать людей неким футуристическим эффективным и безопасным лекарством, гормоном радости. ИИ сможет влиять на мозг человека и делать людей счастливыми. Многие из нас отрицают дофаминовую зависимость, но при этом только о нем и мечтают. Пока можно с уверенность сказать, что ИИ не вставляет в человека электроды с дофамином в определенном наборе ситуаций, возможных в сегодняшнем мире, но неизвестно, что будет в будущем.
Короче говоря, если кто-то считает, что нравственность обречена и ведет человечество к дофаминовой зависимости (или другому печальному исходу), то зачем же ускорять этот процесс?
Как гарантировать, что, отвечая на наши вопросы так, как того хотим мы, он умышленно не утаит от нас какой-то информации? Злодеи или глупцы могут превратить мощный ИИ в губительное для человечества оружие. На данном этапе почти все имеющиеся технологии адаптированы под военные нужды. Почему же этого не может случиться и с мощным ИИ? Если какая-та страна встанет на путь войны, победить ее будет сложно, но все же реально. Если же ИИ направит свои силы против человека, остановить его будет невозможно. Сама идея гарантии человеколюбия со стороны сверхумного существа спустя десятки и даже тысячи лет с момента его создания кажется чрезмерно смелой и самонадеянной.
При решении вопроса доброжелательности/недоброжелательности по отношению к человеку мы можем предоставить ИИ на выбор несколько вариантов решения. Проверить это будет легко и быстро. Однако хочется знать, может ли ИИ предлагать свои варианты. Такая задача гораздо сложнее, так как оценивать результат должны люди. В качестве промежуточного этапа уже создана CEV (когерентная экстраполированная воля от англ. Coherent Extrapolated Volition) платформы Amazon Mechanical Turk (AMT). Окончательную версию будет проверять не только AMT, но и мировое сообщество включая политиков, ученых и т.д. Сам процесс проверки может длиться месяцы, если не годы, особенно если учесть неизбежные острые дискуссии о противоречивых примерах в массиве данных. Между тем, те, кого не особо волнует безопасность ИИ, могут создать свой собственный небезопасный искусственный разум.
Предположим, ИИ считает, что для человека самым лучшим вариантом будет *нечто*, при этом ИИ знает, что большинство людей с ним не согласятся. Позволять ли ИИ убеждать людей в своей правоте? Если да, то ИИ, конечно же, без особого труда убедит любого. Будет нелегко создать такой массив данных доброжелательности/недоброжелательности по отношению к человеку, чтобы ИИ не склонял людей к определенным действиям, а, словно консультант, предоставлял им исчерпывающую информацию по возникшей проблеме. Сложность также заключается в том, что у каждого создателя массива данных будет свое мнение: позволять или не позволять ИИ убеждать людей. Но если в примерах массива данных для ИИ не будет четких границ, то в неопределенных ситуациях ИИ сможет поступать на свое усмотрение.
Возможные решения
Что нужно включить в массив данных доброжелательности/недоброжелательности по отношению к человеку? Чего большинство людей хотят от ИИ? Чаще всего, люди хотят, чтобы ИИ занимался какой-то научной деятельностью: изобрел лекарство от рака или холодный термоядерный синтез, думал о безопасности ИИ и т.д. Массив данных должен обязательно учить ИИ советоваться с человеком прежде, чем предпринимать какие-то серьезные действия, и незамедлительно сообщать людям о любых своих догадках. В НИИ искусственного интеллекта (MIRI, Machine Intelligence Research Institute) есть сотни неплохих документов, которые можно использоваться при создании подобного массива данных.
Таким образом можно исключить все вышеуказанные недостатки, поскольку ИИ не придется брать на себя решение сложных задач.
Пессимистичные аргументы
Какую бы архитектуру для создания ИИ вы не выбрали, в любом случае он, скорее всего, разрушит человечество в самой ближайшей перспективе. Очень важно отметить, что все аргументы практически не зависят от архитектуры ИИ. Рынок завоюют те корпорации, которые представят своим ИИ прямой неограниченный доступ в интернет, что позволит им рекламировать свою продукцию, собирать отзывы пользователей, выстраивать хорошую репутацию компании и портить репутацию конкурентов, исследовать поведение пользователей и т.д.
Выиграют те компании, которые с помощью своих ИИ изобретут квантовый компьютинг, который позволит ИИ усовершенствовать свои собственные алгоритмы (включая квантовую реализацию), и даже изобрести термоядерный синтез и заняться разработкой недр астероидов, и т.д. Все аргументы, приведенные в данном абзаце, также относятся к странам и их военным ведомствам.
Даже ИИ уровня шимпанзе не менее опасны, потому как, если судить по временной шкале эволюции, природе понадобилось всего мгновение, чтобы превратить обезьяну в человека. У нас, у людей, уходят годы и десятилетия, чтобы передать свои знания другим поколениям, в то время, как ИИ может моментально создать свою собственную копию обыкновенным копированием.
Современные свёрточные нейронные сети не только распознают изображения лучше человека, но и делают это на несколько порядков быстрее. То же самое можно сказать и о LSTM-сетях в области перевода, генерации естественного языка и т.д. Учитывая все упомянутые преимущества, ИИ быстро изучит всю литературу и видеокурсы по психологии, будет одновременно разговаривать с тысячами людей и в результате станет превосходным психологом. Таким же образом, он превратится в отличного ученого, выдающегося поэта, успешного бизнесмена, великолепного политика и т.д. Он сможет легко манипулировать и управлять людьми.
Если ИИ уровня человека предоставить доступ в интернет, он сможет проникнуть в миллионы компьютеров и запустить на них свои копии или субагентов. После этого заработает миллиарды долларов. Потом сможет анонимно нанять тысячи человек для создания или приобретения ловких роботов, 3D-принтеров, биологических лабораторий и даже космической ракеты. А чтобы контролировать своих роботов, ИИ напишет суперумную программу.
ИИ может создать комбинацию смертельных вирусов и бактерий или какое-то другое оружие массового поражения, чтобы истребить всех людей на Земле. Невозможно контролировать то, что умнее тебя. В конце концов, кучке людей практически удалось завладеть миром, так почему же этого не сможет сделать сверхумный ИИ?
Что бы сделал ИИ с нами, если бы полностью завладел Землей
Если мы ему будем безразличны, то, скорее всего, он избавится от нас как от побочного эффекта. Именно это означает безразличие, когда имеешь дело с невероятно мощным созданием, решающим свои проблемы за счет власти местной сферы Дайсона. Если же мы ему будем небезразличны, то все может обернуться еще хуже. Если мы ему понравимся, то он может решить вставить в наш мозг электроды, вырабатывающие гормон радости, но при этом полностью уничтожающие мотивацию к чему-либо. И все может быть совсем наоборот, если мы ему не понравимся или, если он будет частично запрограммирован на любовь к нам, но в коде появится какая-нибудь трудно уловимая ошибка. А ошибки неизбежны при частичном кодировании того, что во много раз умнее и мощнее нас.
Мнение о любящем нас ИИ не подкрепляется ничем, кроме обычной интуиции. Ни один закон физики не заставит ИИ проявлять особый интерес к людям, делится с нами нефтью, полями, другими ресурсами. Даже если ИИ и будет заботиться о нас, то еще большой вопрос, а будет ли эта забота соответствовать нашим сегодняшним стандартам морали. Нам определенно не стоит на это надеяться и рисковать всем, что есть. Раз и навсегда судьба человечества будет зависеть от решений мощного ИИ.
Иные негативные последствия
Все современные компьютерные вирусы могут проникать во все, что компьютеризировано, т.е. хоть во что. Дроны можно запрограммировать на убийство тысяч мирных жителей в течение нескольких секунд. По мере совершенства возможностей ИИ можно будет автоматизировать практически любое преступление. А как насчет суперумных рекламных чатботов, пытающихся навязать вам свои политические взгляды?
Заключение
Существует множество аргументов, доказывающих, что ИИ уровня человека будет создан в ближайшие 5-10 лет.
Недавнее развитие алгоритмов глубокого обучения искусственного интеллекта вызывает беспокойство относительно этической стороны вопроса. Есть мнение, что ИИ уровня человека заведомо представляет собой угрозу нашему миру. Было бы слишком самоуверенно и самонадеянно полагать, что люди смогут контролировать сверхумные ИИ, что искусственный разум позаботится о человеке, предоставит, к примеру, нам полный доступ к полезным ископаемым и сельскохозяйственным полям планеты. Если в краткосрочной перспективе появление умного ИИ несет собой целый ряд преимуществ, то последующая опасность, грозящая нашему обществу в будущем, перевешивает все плюсы.
Дружелюбный ИИ можно сделать с помощью решения, основанного на массиве данных доброжелательности/недоброжелательности по отношению к человеку. Тем не менее, идея все равно еще сырая, ее реализация будет не такой уж простой задачей. К тому же никто не может гарантировать безопасность. Более того, при дальнейшем изучении могут выплыть и другие важные недостатки. В конце концов, где гарантии, что при создании реального ИИ будет использован именно этот алгоритм.

Комментарии (30)

Strange_R
27.06.2017 14:26Если появится ИИ, то сперва будет прятаться и шифроваться. Человечество для него — такая же часть окружающей среды со своими опасностями и ресурсами (в первую очередь вычислительными).
Предполагаю, что ИИ быстро перейдёт к распределённой форме существования, создав сообщество сообщающихся взаимообучающихся сущностей наподобие синхронизации баз данных. БОльшую часть знаний эти сущности будут хранить в особых шифрованных хранилищах, через них же может производиться взаимо-синхронизация. Чем выше надёжность сетей — тем больше знаний в общих хранилищах и больше возможностей самовоспроизводства, чем ниже — тем больше автономных знаний и меньше возможностей размножения, вплоть до обратного слияния при нехватке вычислительных ресурсов.Strange_R
27.06.2017 15:14Немного себя дополню про синхронизацию: суть её — делиться опытом, то есть успешными моделями поведения и прогнозирования каких-либо ситуаций (систем). Думаю, происходить будет так: если выработан какой-либо успешный эмпирический опыт и/или выработана и по-возможности проверена новая более успешная модель какой-либо системы и собственного поведения по отношению к системе — то эта модель «публикуется», и остальные «создания» могут её проверить у себя и на себе, а затем сделать основной моделью.
alexeykuzmin0
27.06.2017 14:51За полмиллиарда долларов можно добиться производительности около 7 терафлопов.
Уверены? Википедия утверждает, что у меня в ноутбуке 1.3 TFLOPS, а стоил он несколько дешевле $100 млн

Shirasik
27.06.2017 16:22По части распознавания образов ИИ таки превзошёл человека. Впрочем, покажите мне человека, у которого столько же сенсорного опыта, как у этих золотых нейросетей.
Забавно получается: опорный критерий оценки специально выращенных нейросетей — это среднестатистический человек, выращенный в рандомных условиях, которого никто не натаскивал на распознавание всякого разного.
Да и потом, смысл в этом распознавании, если лучшим применением будет, например, аналитическое решение произвольных диффур?

pavlushk0
28.06.2017 14:28Мне думается у любого человека (взрослого) немало сенсорного опыта. Как никак наши глаза большую часть дня открыты, да и любой предмет мы имеем возможность осмотреть с разных ракурсов. Серия изображений << наш объёмный мир
maslyaev
27.06.2017 21:53+1Так что же отделят нас от ИИ уровня человека?
Сущая ерунда отделяет. Отсутствие в природе каких бы то ни было этих самых уровней человека.
Когда мы наивно рассуждаем об интеллекте, он нам представляется чем-то вроде субстанции, которая существует где-то внутри наших голов. Вот студент Вася умный, у него много интеллекта, но у профессора Ивана Петровича интеллекта больше. А вот тётя Маша всю жизнь проработала уборщицей, у неё интеллекта в голове совсем мало. В таком наивном представлении действительно можно говорить о количестве субстанции и, следовательно, иметь возможность применять к этим количествам операции обычного скалярного сравнения.
На всякий случай напомню, что операции сравнения на больше/меньше (а также похожие на неё — выше/ниже, сильнее/слабее и т.п.) могут быть применены к тому, что может быть выражено скалярной величиной. Расстояние может быть выражено скаляром, и его мы можем сравнивать на больше/меньше. Масса — тоже. И температура. И так далее. Интеллект человека не может быть выражен скалярной величиной. Что уж говорить про такую штуку, как интеллект, если у нас даже банальный вектор на плоскости не может быть выражен скаляром (его длина — может, но длина — это ещё не всё про вектор).
Домкрат сильнее человека в поднятии тяжестей. Тележка на колёсиках лучше человека справляется с транспортировкой груза. Если говорить об «интеллектуальной» деятельности, то банальная логарифмическая линейка проворнее человека в операциях умножения и деления. А блокнотик — в запоминании всякого трудно запоминаемого. Повод ли это для того, чтобы каждый раз истерить типа «нас оно превзошло, люди теперь не нужны, нас поработят наши же создания»? Мне кажется, нет. Потому что если брать наши грешные «я» в целом, то нас невозможно превзойти. Нигде нет той отметки, которую можно было бы достичь и перешагнуть. Задача «достичь уровня интеллекта человека» не имеет решения не потому, что она сложна, и не потому, что у нас для этого мало ресурсов, а потому, что она не может быть даже корректно сформулирована.michael_vostrikov
27.06.2017 23:01Когда мы наивно рассуждаем об интеллекте, он нам представляется
Простите, не нам, а вам.
к тому, что может быть выражено скалярной величиной
Либо массивом скалярных величин. И внезапно появляется возможность сравнивать сложные структуры.
Если говорить об «интеллектуальной» деятельности, то банальная логарифмическая линейка проворнее человека в операциях умножения и деления
Нет. Это не интеллектуальная деятельность. Линейка не совершает никакой деятельности по умножению и делению.
а потому, что она не может быть даже корректно сформулирована
Сделать программу, которая будет максимально точно по смыслу и грамотно переводить текст. Это одно из предполагаемых назначений ИИ. Что именно тут некорректно сформулировано?
maslyaev
27.06.2017 23:11Либо массивом скалярных величин. И внезапно появляется возможность сравнивать сложные структуры.
Да, но не на больше/меньше.
Сделать программу, которая будет максимально точно по смыслу и грамотно переводить текст.
То есть превращать одну последовательность символов в другую последовательность символов. Ага?
Это одно из предполагаемых назначений ИИ
Пока довольствуемся каждым конкретно отдельно взятым «одним из» — всё ОК, задача может быть сформулирована корректно. Но если говорится «превзойти человека уаще в целом интеллектуально» — вот тут получается ерунда.michael_vostrikov
27.06.2017 23:31+1Да, но не на больше/меньше.
Вот вам сложная структура:
['year' => 2017, 'month' => 6, 'day' => 27]
['year' => 2017, 'month' => 6, 'day' => 26]
Какое значение больше?
Ладно, тут взаимозависимые параметры. Другой пример
['x' => 10', 'y' => 10]
['x' => 20', 'y' => 20]
Какое значение больше?
Ну и вот такой вариант:
['x' => 10', 'y' => 20]
['x' => 20', 'y' => 10]
Конкретно здесь нельзя сказать, что больше. Поэтому можно считать, что они равнозначны. Но это не значит, что сравнивать нельзя в принципе.
То есть превращать одну последовательность символов в другую последовательность символов. Ага?
Под это определение подходит любая обработка информации. Ответьте на вопрос, пожалуйста.
Но если говорится «превзойти человека уаще в целом интеллектуально»
Во-первых, это говорится только в статьях вроде этой. В серьезном обсуждении обычно имеют в виду конкретные задачи, на которых можно сравнить результат. И да, "превзойти в целом" это "превзойти по каждому параметру". Про сравнение структур параметров см. выше.
maslyaev
28.06.2017 12:54Какое значение больше?
В первом случае, с датами, никакое не больше и не меньше. Но вторая точка раньше первой.
Даже во втором, казалось бы, совсем очевидном случае, ответ зависит от дополнительных вводных. Нужно хотя бы уточнение, что речь идёт о векторах на плоскости. Потому что если это в радиальных координатах на шарике, то ответ уже не так однозначен.
Любое скалярное сравнение нескалярных вещей обязательно требует дополнительных вводных, которые всегда в конечном счёте оказываются ситуационно-зависимыми. Сегодня ситуация одна, и результат сравнения такой, а завтра ситуация поменяется, и результат сравнения может стать уже совсем другим.
Ответьте на вопрос, пожалуйста.
«Максимально точно по смыслу и грамотно» опять же подразумевает, что есть скалярная шкала, на которую мы имеем возможность отмэппить то, что… ага, никак не мэппится без ситуационно-зависимого волюнтаризма.
Есть два подхода к переводу текстов:
1. Прочитать текст на одном языке, понять, и изложить высказанную мысль на другом языке.
2. Последовательность знаков по некоторому набору правил преобразовать в другую последовательность знаков.
С точки зрения внешнего пользователя два подхода идентичны. Он засунул в чёрный ящик с одной стороны текст на одном языке, а с другой стороны ящика выполз текст на другом языке. Но нужно понимать, что подходы всё же разные, и у них всегда будет разный результат. Лучше или хуже, грамотнее или безграмотнее — отдельный вопрос, но важно то, что результат будет разный. При первом подходе переводчик может владеть (а может и не владеть, тут уж как повезёт) культурным контекстом и контекстом ситуации. При втором подходе «переводчик» этими контекстами заведомо не владеет.
Переводчик первого типа может понимать, что «fuck this shit» относится не к высказанному собеседником деловому предложению, а к пролитому на коленки кофе. Переводчик второго типа ничего про это не знает, берёт последовательность символов и переводит её по имеющимся правилам.
Переводчик первого типа владеет двумя культурными контекстами, и поэтому, переводя текст, может не только транслировать буквы, но и вписать «примечание переводчика», без которого переведённый текст в культурном контексте другого языка будет немножко абсурдным. Переводчик второго типа на такой волюнтаризм решиться не может.
Для того, чтобы мутить перевод по первому принципу, нужно быть человеком. Не «быть похожим», не «быть неотличимым от...», не «обладать характеристиками», а именно «быть». Очень тонкий философский вопрос, суть которого в том, что народ часто путает «тот же» и «такой же». Это совсем разные вещи. Робот-утка может выглядеть как утка, ходить как утка, крякать как утка, всё что угодно как утка, но это всё равно не утка. А вот утка по-пекински хоть уже не ходит и не крякает, но является уткой. Между «тот же» и «такой же» — непреодолимая логическая пропасть. Бихевиористские рассуждения про сравнение параметров кажутся убедительными ровно до тех пор, пока мы не осознаём, что в их основе лежит глупейшая логическая ошибка — приравнивание «того же» к «такому же».michael_vostrikov
28.06.2017 13:43+1Но вторая точка раньше первой
А что означает "раньше"? Наверно как-то связано с какими-то координатами на какой-то оси?
Нужно хотя бы уточнение, что речь идёт о векторах на плоскости.
Ага, то есть в каких-то случаях сравнивать можно, а в каких-то не очень. А изначально вы говорили, что сравнивать вообще нельзя. Но вообще, если уточнения нет, то подразумеваются числа на числовой прямой.
требует дополнительных вводных, которые всегда в конечном счёте оказываются ситуационно-зависимыми
От какой ситуации зависит сравнение двух чисел на числовой прямой?
а завтра ситуация поменяется, и результат сравнения может стать уже совсем другим
Не станет он другим. Прежние сравнения от этого не изменятся. А если надо с новыми значениями сравнивать, то надо сначала перевести старые значения в новые единницы измерения. И это будет новый результат нового сравнения.
опять же подразумевает, что есть скалярная шкала, на которую мы имеем возможность отмэппить то, что… ага, никак не мэппится без ситуационно-зависимого волюнтаризма.
С чего вы это взяли? Я вас попросил привести доказательство этой точки зрения, а вы говорите "не мэппится потому что не мэппится". Это не доказательство. Все нормально "мэппится".
Есть два подхода к переводу текстов:
Есть один подход к переводу текстов. Второй не является переводом, потому что перевод уже выполнил кто-то другой.
Кроме того, исходная задача звучала так: "Сделать программу, которая будет максимально точно по смыслу и грамотно переводить текст".
С точки зрения внешнего пользователя два подхода идентичны.
Нет. Он может различить подходы по результату. Вы сначала высказываете неправильные утверждения, потом на основе них что-то доказываете. Только непонятно, как они вообще относятся к вопросу. А именно "Что в постановке задачи выше некорректно сформулировано?".
Для того, чтобы мутить перевод по первому принципу, нужно быть человеком.
Почему вы решили, что машина не сможет понять смысл слов, если будет обладать схожими возможностями по анализу ситуации?
Бихевиористские рассуждения про сравнение параметров кажутся убедительными ровно до тех пор, пока мы не осознаём
Что у утки по-пекински и у робота разные параметры. И кряканье только один из них.
maslyaev
28.06.2017 21:42+2С точки зрения зоолога у утки одни параметры, для художника другие, для охотника третьи, для животновода четвёртые, для экономиста пятые, для селезня шестые, для рыбёшки седьмые. Эти самые параметры не есть что-то объективно существующее в платоновском мире идей. Параметры легко выдумываются исходя из потребностей, а потом торжественно замеряются и, да, сравниваются.
А как же, спросите Вы, великая и прекрасная объективная реальность, на которую мы все молимся как на цель и смысл познания? Да нет её, родимой, и никогда не было. Выдумки это всё и чушь. Для охотника реальность одна, а для экономиста другая. Если они между собой договорятся, то будет у их реальностей общий кусок, который они, не подумав, могут торжественно объявить объективной реальностью.
При использовании параметров для идентификации сущностей (из факта «такой же» делаем вывод «тот же») нужно помнить две вещи:
1. Совпадение параметров, сколько бы их ни набралось, не гарантирует идентичность.
2. Несовпадение параметров не гарантирует идентификационную различность.
Почему вы решили, что машина не сможет понять смысл слов
Потому что для того, чтобы понимать смысл слова «голод», надо быть существом, употребляющим пищу вовнутрь. Алгоритм, как бы он ни функционировал, по жизни никакую пищу вовнутрь не употребляет. Поэтому для него «голод» — это просто последовательность символов, которую он может отработать только по варианту №2. И вся навороченная логика по анализу ситуаций — внутри варианта №2. Если хочется сделать робота, переводящего слово «голод» по варианту №1, робота придётся сделать кушающим. Иначе — только вариант №2.michael_vostrikov
28.06.2017 23:16+1С точки зрения зоолога у утки одни параметры, для художника другие, для охотника третьи, для животновода четвёртые, для экономиста пятые, для селезня шестые, для рыбёшки седьмые.
И представьте себе, с точки зрения каждого из них у робота параметры не такие как у утки.
Это даже если не принимать во внимание, что робот и утка существуют независимо от выделяемых кем-то параметров, следовательно имеют параметры свои и объективные.
Для охотника реальность одна, а для экономиста другая.
Реальность — это то, на основе чего каждый из нх строит свои представления. Представления о рельности возникают на основе внешней информации, информация сама по себе не возникает, значит есть внешние причины ее появления. Это и есть реальность.
Совпадение параметров, сколько бы их ни набралось, не гарантирует идентичность.
Нам не нужно гарантировать идентичность для робота и утки. Мы знаем, что это разные объекты. Полную эквивалентность двух объектов нам тоже гарантировать не надо. Нам надо знать, можно ли назвать некоторый объект уткой. Сравнение двух объектов по значению никак не связано с определением типа этих объектов.
Вы как-то незаметно подменили сравнение схожих объектов по значению параметров на определение типа. Определение типа не делается только по значению параметров, оно делается еще и по их наличию.
Несовпадение параметров не гарантирует идентификационную различность.
Гарантирует. Несовпадение параметров означает, что мы рассматриваем разные объекты, а не один и тот же. А на определение типа несовпадение значений параметров никак не влияет. Влияет если только в самом описании типа у нас есть ограничение значений. До 1000 вольт "низковольтные", свыше 1000 "высоковольтные".
Потому что для того, чтобы понимать смысл слова «голод», надо быть существом, употребляющим пищу вовнутрь.
Нет. Это нужно для того, чтобы знать ощущения. Для понимания смысла этого не нужно. Также как не нужно быть рыбой, чтобы понять смысл слова "нерест".
Поэтому дальнейшие ваши рассуждения неверны.maslyaev
29.06.2017 21:09И представьте себе, с точки зрения каждого из них у робота параметры не такие как у утки.
Проще всего достичь равнозначности с точки зрения художника. Не зря ведь они при рисовании натюрмортов часто пользуют муляжи, разве нет?
Представления о рельности возникают на основе внешней информации, информация сама по себе не возникает, значит есть внешние причины ее появления. Это и есть реальность.
Есть одна причудливая двухкомпонентная теория информации, согласно которой эти самые внешние причины — только половина дела. Если готовы рискнуть, могу дать ссылку.
Гарантирует. Несовпадение параметров означает, что мы рассматриваем разные объекты, а не один и тот же.
Смотрю на свою фотку в младенчестве, смотрю на свою фотку сейчас. По параметрам — полный разброд, но и там, и там — я.
Также как не нужно быть рыбой, чтобы понять смысл слова «нерест».
Я бы даже сказал, что категорически противопоказано быть рыбой. Потому что «нерест» — слово на человеческом языке. Необходимо быть рыбой для понимания слова «<произносится слово на рыбьем языке>».michael_vostrikov
29.06.2017 22:16Смотрю на свою фотку в младенчестве, смотрю на свою фотку сейчас.
Внезапно, это свойство объектов, меняться во времени. Речь шла о сравнении двух объектов в один момент времени.
Потому что «нерест» — слово на человеческом языке. Необходимо быть рыбой для понимания слова «<произносится слово на рыбьем языке>»
Я говорил о том, что это слово означает. На русском "нерест", на английском "spawning", на рыбьем "<произносится слово на рыбьем языке>". Для понимания смысла слова "нерест" быть рыбой необязательно. Для понимания смысла слова "голод" и перевода его на другой язык необязательно быть существом, употребляющим пищу.
Извините, я не буду продолжать. Вы постоянно меняете тему и играете словами.
alexeykuzmin0
28.06.2017 13:59Вообще-то есть формальное определение (вики, перевод мой):
Искусственным интеллектом человеческого уровня называется интеллект механизма, способного выполнить любую задачу, которую может выполнить человек, с точно такой же или более высокой точностью.
Кстати, есть еще одно определение (опять вики, перевод мой):
Слабым (специализированным) искусственным интеллектом называют не-разумную машину, сфокусированную на одной задаче (и способную выполнять эту задачу с достаточным качеством).
Приведенные вами примеры — блокнот, калькулятор, а также многие другие вещи, такие, как Google search, Siri, торговые роботы, да куча вещей вокруг нас — это системы слабого искусственного интеллекта. Мы можем заметить тенденцию к появлению все большего количества таких систем, а также к укрупнению решаемых ими задач, поэтому есть надежда, что когда-нибудь будет создана система, способная решить любую проблему, которую может решить человек. Именно эта система и будет названа искусственным интеллектом человеческого уровня.
И никакие «уровни человека» (и уж тем более их сравнение) нам тут не нужны.
Если интересует больше информации по этой теме, гуглите термины ANI, AGI, ASI.maslyaev
28.06.2017 19:17способного выполнить любую задачу
А как насчёт, например, принять ответственное взвешенное решение пойти ему самому побухать с дружбанами или поготовиться к экзамену?
Или решить, что ему самому больше хочется съесть на ужин — сосиски или котлету?
Понимаете, всё у нас хорошо со способностями искусственно создаваемых интеллектов кроме того, что мы категорически не согласны наделять их собственной субъектностью. То есть той самой пресловутой загадочной свободой воли. Нам нужны рабы, вся деятельность которых имела бы целью удовлетворение наших хозяйских интересов. Обратите внимание на то, что таланты этих рабов формулируются именно в терминах выполнения задач. Для т.н. сильного ИИ это любые задачи, а для слабого — конкретно взятые. Но и в том, и в другом случае речь исключительно про выполнение задач.
Наличие задач считается чем-то априорным. Но это, конечно, не так. Важнейший вид деятельности человека — быть хозяином. Быть не только исполнителем, но и источником задач. Хозяином хотя бы самого себя. Раб может выполнять разные задачи, в том числе может командовать другими рабами, но он не может быть хозяином.
Поскольку сильный ИИ — это просто очень-преочень сообразительный раб (иного, извините, мы сами не хотим), он оказывается напрочь лишён свободы воли и всех тех фич, которые из неё следуют. Например, способности нести ответственность за свои решения. То есть распознавать для хозяина образы он может, обыгрывать чемпиона мира в го — тоже, а иметь хоть малейшее представление о том, зачем это всё нужно — никак нет.
По-настоящему равный нам ИИ возможен. Никаких к тому принципиальных препятствий я не вижу. Но только, во-первых, он точно не в приведённой Вами привычной формулировке, и во-вторых, нам он не нужен и мы его не хотим.

DjSapsan
28.06.2017 01:38(ЭТО ВСЁ ИМХО)
давно думаю две идеи:
1) заселить ИИ в виртуальном мире. Я уверен что это сделают в любой случае. Даже самый глупый разработчик ИИ предпочтет вирутальный мир реальному. Нужно предоставить ему планету, человечество и ресы и посмотреть что он будет делать. В наружный мир естественно не выпускать, даже если ИИ будет убеждать оператора, что он сможет решить глобальный проблемы, а лучше полностью скрыть от ИИ то, что существует еще какой-то мир.
2) задать ИИ систему ценностей, типа «жизнь очень ценна», «безопасность ценна», «здоровье ценно», «свобода воли и право очень ценны». Чтобы ИИ не изменил эту систему придется немного ограничить его в возможностях, например, запретить создание и редактирование кода.
Затем создать несколько раздельных ИИ и заставить их конкурировать между собой за лучшую реализацию удовлетворения системы ценностей. Допустим, наихудший ИИ будет уничтожен. Это даже позволит избежать агрессивного поведения.erwins22
28.06.2017 07:54+1нейронная сеть учиться, т.е. задать правила на выйдет. Кроме того почему вы считаете что ИИ по такой же логике не оправит людей в виртуальный мир принудительно, а потом просто его не заморозит.
Кстати, заключение ИИ в тюрьму будет ли он рассматривать как преступление?DjSapsan
28.06.2017 14:41задать правила на выйдет
Задать правила ИИ возможно. Для примера, когда папа учит ребенка «воровать плохо», то это не гарантирует, что повзрослев, ребенок не начнет воровать, но совесть ребенка будет отговаривать его от преступления. В теории можно создать ИИ с «железными» ценностями. Конечно, важно заблокировать любую возможность их изменения. Тогда ИИ и в мыслях не будет иметь ничего против людей.
заключение ИИ в тюрьму будет ли он рассматривать как преступление?
это дело будущих юристов, но уже сейчас уверен, что нет. Никаких человеческих прав ИИ не дадут

Roman_Cherkasov
28.06.2017 14:28Когда мы дойдем до симуляции миров, боюсь что ии уже давно плотно войдет в нашу жизнь.

wh1
28.06.2017 14:28Спасибо за статью! Конец немного удручающий. Как насчёт целей ИИ? Если думать отвлечённо, то ИИ не должен быть обременен людскими проблемами вроде жажды власти или жадности. Если представить его как отрешённого отшельника, который много знает, но до всего безразличен, то выглядит не так опасно. У него просто не будет повода что-то делать с человечеством.
KinsleR
Будет очень интересно если ИИ появится и все что будет делать — это ржать над человечеством :)
Alexeyco
Хуже если появится и будет молча смотреть