
 Недавно, команда AWSDeepLearning выпустила новый фреймворк?—?“sockeye”, цель которого является упрощение обучения seq2seq сетей. Забегая вперед — я даже не ожидал такой простоты. Так что решил написать простое, быстрое и самодостаточное руководство, которое не требует от читателя глубоких знаний в области нейронных сетей. Единственное, что все же требуется для успешного выполнения всех шагов, это иметь некоторый опыт работы с:
Недавно, команда AWSDeepLearning выпустила новый фреймворк?—?“sockeye”, цель которого является упрощение обучения seq2seq сетей. Забегая вперед — я даже не ожидал такой простоты. Так что решил написать простое, быстрое и самодостаточное руководство, которое не требует от читателя глубоких знаний в области нейронных сетей. Единственное, что все же требуется для успешного выполнения всех шагов, это иметь некоторый опыт работы с:- AWS EC2;
- SSH;
- python;
Если все эти три вещи не вызывают проблем — прошу под кат.
Перед тем как продолжить, хочу высказать особенную благодарность моим патронам, которые меня поддерживают.
Как уже упомянул, намедни команда AWS DeepLearning выпустила новый фреймворк?—?“sockeye”. Позвольте мне привести цитату с официального сайта:
… the Sockeye project, a sequence-to-sequence framework for Neural Machine Translation based on MXNet. It implements the well-known encoder-decoder architecture with attention.
Вольнвый перевод:
Sockeye это фреймворк для обучения нейронных сетей машинному переводу, который базируется на известной архитектуре encoder-decoder.
Несмотря на то, что официально это framework разработан для тренировки сетей, для машинного перевода, технически он же может быть использован для тренировки более общего класса задач преобразования одной последовательности в другую(seq2seq). Я уже затрагивал тему того, почему машинные перевод и создание чата ботов, как две задачи, имеют очень много схожего и могут решаться схожими методами, в одной из прошлых статей. Так что не буду повторятся оставив возможность пытливым читателям пройти по ссылки, а тем временем я перейду к непосредственно созданию чат-бота.
Описание процесса
В целом, процесс состоит из следующих шагов:
- Поднять EC2 машину с GPU на базе DeepLearning AMI
- Подготовить EC2 машину для тренировки
- Начать обучение
- Подождать
- Profit
Поднимаем EC2 машину с GPU, на базе AWS DeepLearning AMI
В данной статье мы будем использовать AWS DeepLearning AMI, далее по тексту: DLAMI (кстати, если вы не знаете что такое AMI, то рекомендую ознакомится с официальной документацией вот тут). Основные причины использования именно этого AMI:
- в него включены драйвера Nvidia CUDA (на момент написания статьи версия: 7.5);
- собранный с поддержкой GPU — MXNet;
- включает все(почти) утилиты что нам необходимы, например: git;
- может быть использован с, сюрприз-сюрприз, машинами в которых есть GPU.
Для того что бы быстро создать нужную нам машину из AMI, идем на страницу DLAMI в AWS Marketplace. Тут стоит обратить внимание на следующие вещи:
1. Версия AMI

На момент написания — «Jun 2017» была самая свежая версия, так что если хотите, что бы ваш процесс был консистентет с остальной частью этой стать — рекомендую выбрать именно его.
2. Регион для создания
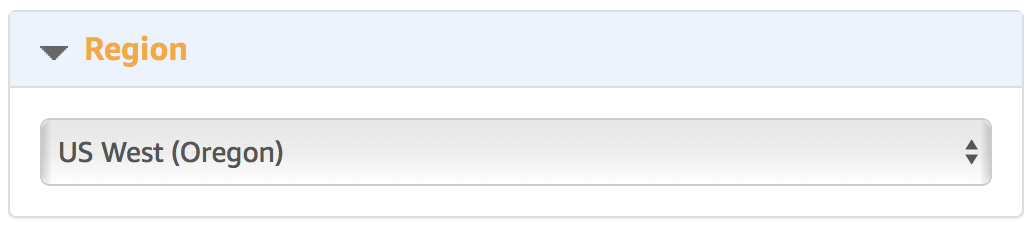
Учитывайте что не все типы машин с GPU доступны во всех регионах. Собственно, даже если они формально доступны, то не всегда есть возможность их создать. Так, например, в 2016 во время NIPS конференции с ними было очень проблематично. Нам потребуется машина типа p2, плюс, и на момент написания статьи, DLAMI был доступен только в тех регионах, где этот самый тип был доступен:
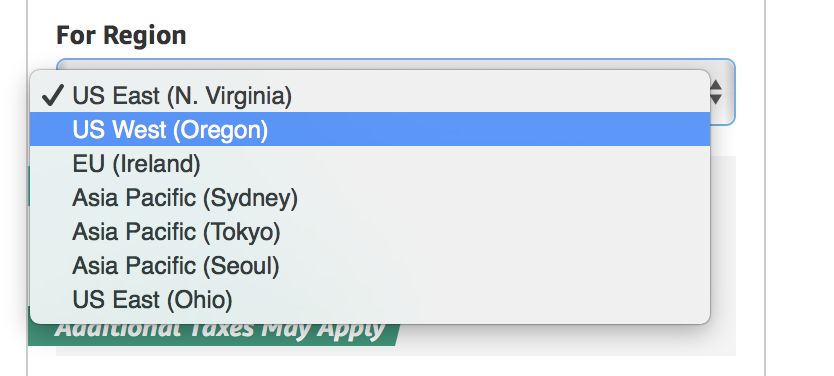
3. Выбор типа инстанса
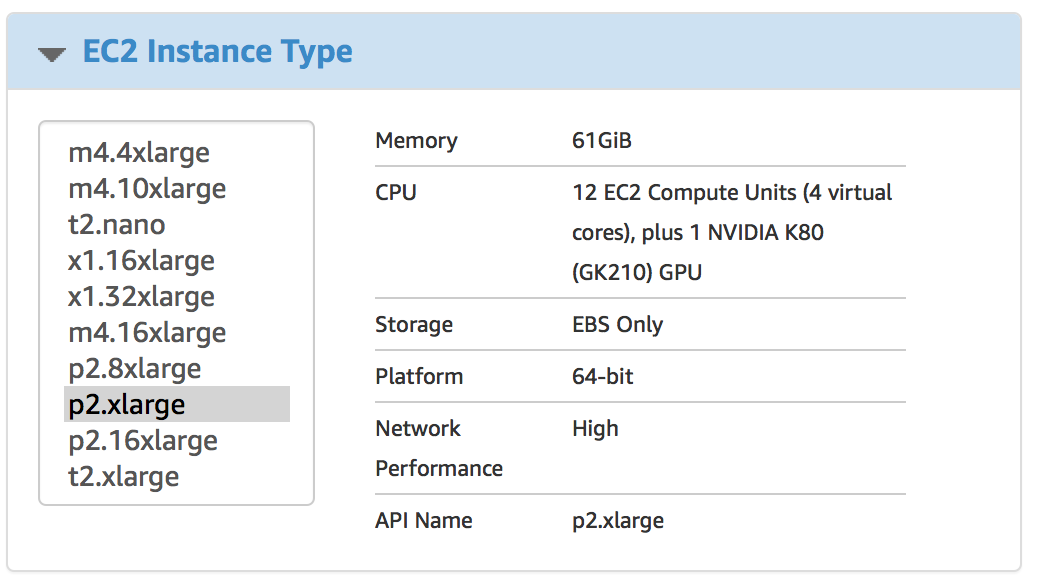
p2.xlarge — является самой дешёвой машинкой которая удовлетворяет нашим требованиям к памяти GPU (можете конечно попробовать и g2.2xlarge, но не говорите потом что вас не предупредили). На момент написания цена за него составляла ~0.9$ в час. Но лучше проверьте цену на официальном сайте.
4. VPC

Если не в курсе что с этим делать — не трогайте.
5. Security group

Так же как и с VPC, не знаете — не трогайте. Однако, если хотите использовать существующую группу, то убедитесь что там открыт SSL.
6. Key pair

Позволю себе предположить что у читателя есть опыт работы с SSH и есть понимание того что это.
7. Жмем создать!
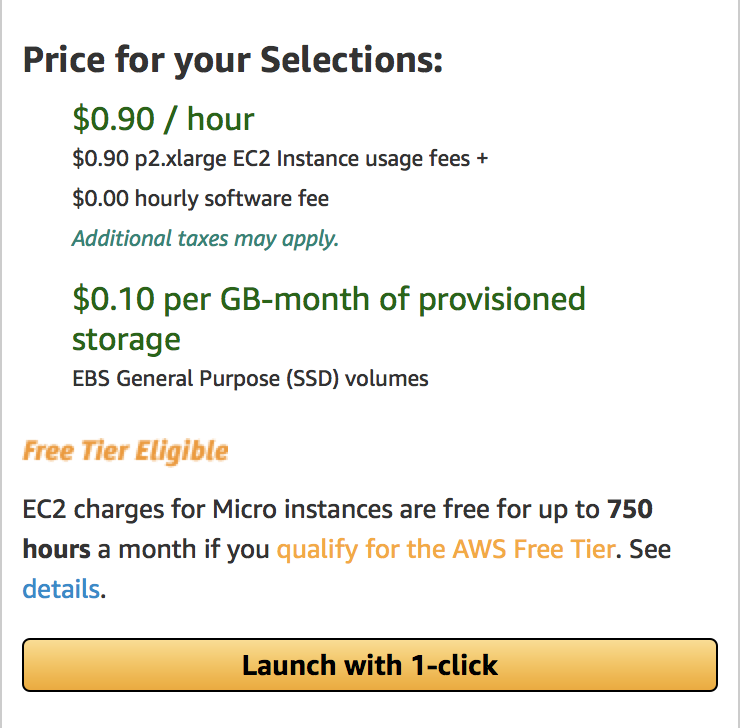
Собственно теперь можем создать машину и подключится к ней.
Подготовка к тренировке сети
Подключимся к ново созданной машине. Сразу после, самое время запустить screen. И не забудьте тот факт, что при подключении нужно использовать логин ubuntu:
Несколько замечаний по сему моменту:
- я сказал “screen” потому какDLAMI не содержит tmux из коробки!!! ага, грустно.
- если не знаете что такое screen или tmux?—?не проблема, можете просто продолжать чтение, все будет работать без проблем. Однако, лучше все же пойти и почитать о том, что это за звери такие: tmux(мой выбор) и screen.
1. устанавливаем sockeye
Первое что нам нужно, это установить sockeye. С DLAMI процесс установки очень простой, всего одна команда:
sudo pip3 install sockeye --no-depsВажная чать тут то, что нужно использовать именно pip3, а не просто pip, так как по умолчанию pip из DLAMI использует Python 2, который в свою очередь не поддерживается в sockeye. Так же нет необходимости устанавливать какие либо зависимости ибо они все уже установлены.
2. Подготовка данных(диалогов) для обучения
Для тренировки, мы будем использовать “Cornell Movie Dialogs Corpus”(https://www.cs.cornell.edu/~cristian/Cornell_Movie-Dialogs_Corpus.html). Это, по факту огромный корпус диалогов из фильмов. Для обучения его нужно «приготовить», собственно я уже реализовал скрипт который готовит корпус и рассказывал детальнее о не ранее.
Ну а теперь давайте эти самые данные, для обучения, и подготовим:
# cd ~/src
src# git clone https://github.com/b0noI/dialog_converter.git
Cloning into ‘dialog_converter’…
remote: Counting objects: 59, done.
remote: Compressing objects: 100% (49/49), done.
remote: Total 59 (delta 33), reused 20 (delta 9), pack-reused 0
Unpacking objects: 100% (59/59), done.
Checking connectivity… done.
src# cd dialog_converter
dialog_converter git:(master)# git checkout sockeye_chatbot
Branch sockeye_chatbot set up to track remote branch sockeye_chatbot from origin.
Switched to a new branch 'sockeye_chatbot'
dialog_converter git:(sockeye_chatbot)# python converter.py
dialog_converter git:(sockeye_chatbot)# ls
LICENSE README.md converter.py movie_lines.txt train.a train.b test.a test.b
Пару вещей на которые стоит обратить внимание:
- папка src уже существует, нет необходимости ее создавать;
- обратите внимание на бранч: “sockeye_chatbot”, в нем я храню код который консистентен с этой статьей. Используйте master на ваш страх и риск.
Теперь давайте создадим папку где будем проводить обучение и скопируем туда все данные:
# cd ~
# mkdir training
# cd training
training# cp ~/src/dialog_converter/train.* .
training# cp ~/src/dialog_converter/test.* .
Ну все, мы готовы начать обучение…
Обучение
С sockeye процесс обучения очень прост — нужно лишь запустить одну единственную команду:
python3 -m sockeye.train --source train.a --target train.b --validation-source train.a --validation-target train.b --output model
Знаю-знаю, НИКОГДА не используйте один и те же данные для обучения и валидации. Однако мой скрипт на данный момент не совсем корректно разбивает данные на две группы и посему более лучшие результаты (я о субъективном оценивании) получаются, как не странно, без разбивки.
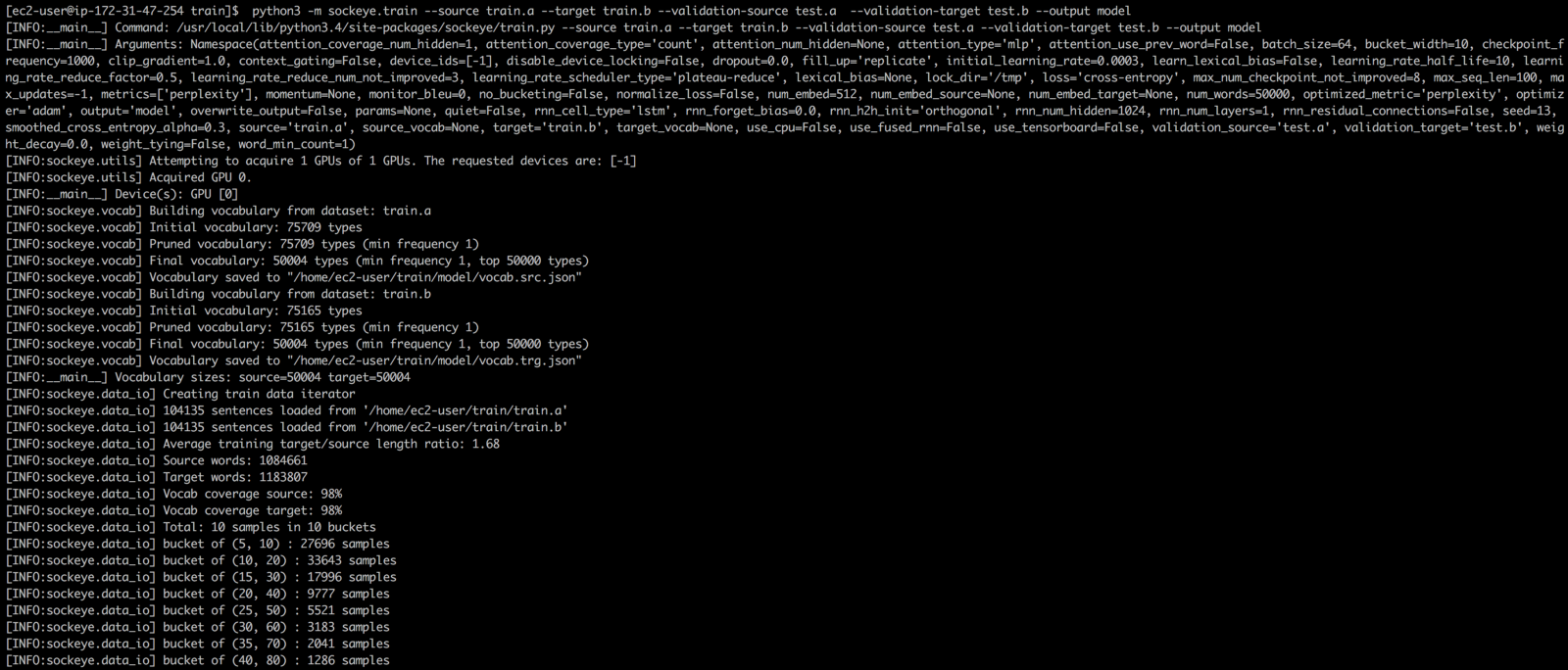
Если читали прошлую статью то могли заметить что sockeye пытается за вас найти подходящую конфигурацию для тренировки, а именно:
- размер словаря;
- параметры сети;
- и т.д.…
Это довольно неплохо, так как более близкая к оптимуму конфигурация может привести к более быстрой (читай дешёвой) тренировке. Хотя еще нужно посмотреть как именно sockeye производит поиск параметров и насколько много ресурсов тратится на этот процесс.
Также sockeye определит когда именно процесс обучения стоит завершить. Это произойдёт если качество модели не улучшилось на данных для валидации за последние 8 контрольных точек.
Ждем результат
Пока ждете можно посмотреть как MXNet пожёвывает ресурсы GPU во время обучения. Для этого нужно запустить вот эту команду в новом окне:
watch -n 0.5 nvidia-smiУвидите что-то вроде:
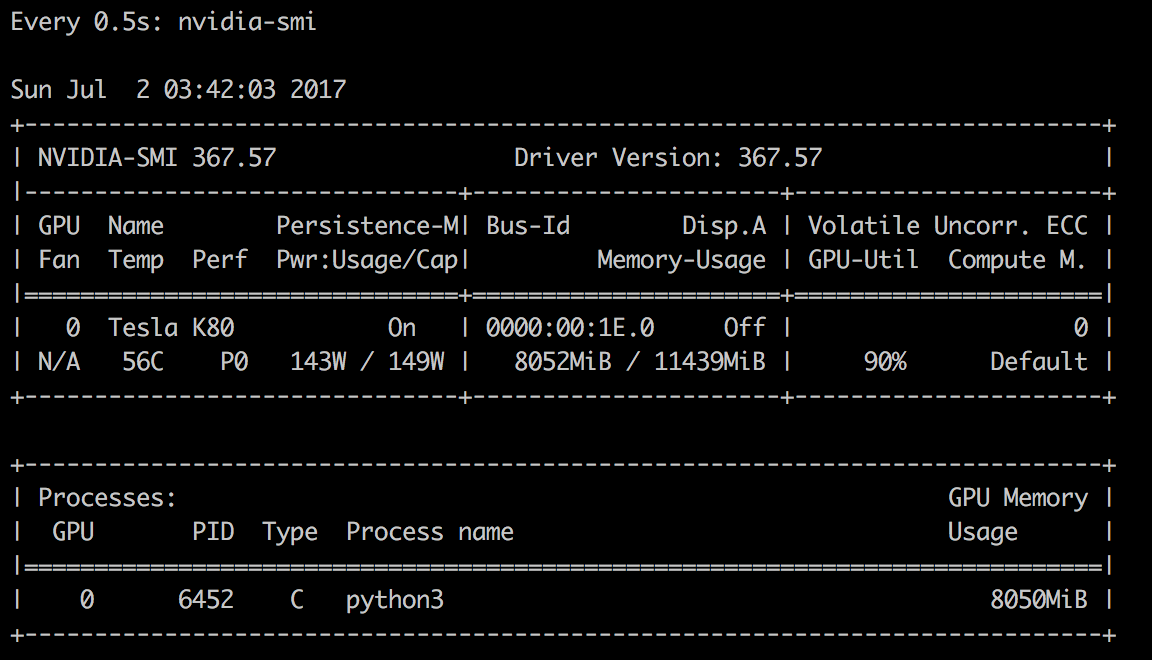
К слову, технически, что бы начтаь общение с ботом нужно лишь дождаться хотя бы первой созданной контрольной точки. Когда это произойдет вы увидите что-то вроде такого:

Теперь можно начать общение:
Чатимся...
Этот процесс не требует остановки обучения, нужно лишь открыть новое окно (ну или новое SSH соединение) перейти в ту же папку где происходит обучение и выполнить команду:
python3 -m sockeye.translate --models model --use-cpu --checkpoints 0005Несколько элементов на которых хочу с акцентировать внимание:
- python3 — естессно;
- model?—?имя папки в которую процесс обучения сохраняет модель, должно соответствовать имени указанном при обучение;
- --use-cpu?—?без этого MXNet попробует задействовать GPU что скорее всего закончится неудачей так как процесс обучения его все еще использует.
- --checkpoints 0005?- номер контрольной точки, взят из консольного вывода в момент сохранения контрольной точки.
После запуска команды sockeye будет считывать ввод из STDIN и выводить ответ в STDOUT. вот несколько примеров:
после часа обучения:
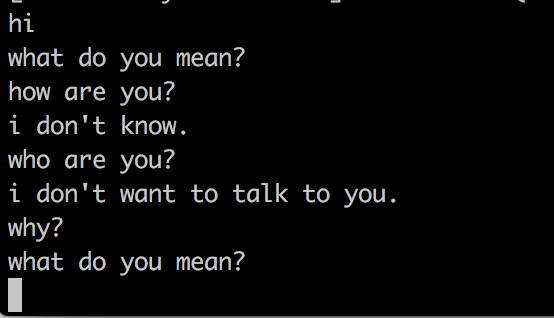
после 2х часов обучения

после 3х часов обучения оно мне начало угрожать =)

Заключение
Как можно увидеть с sockeye процесс обучения очень прост. Собственно, самое сложное, пожалуй, это поднять нужную машину и подключится к ней =) Я все до сих пор жду что бы кто-то из читателей:
- создал бота по мастере Yoda (ну или Вейдера);
- создал бота из вселенной Lord of The Rings;
- создал бота из вселенной StarWars.
PS: не забудьте скачать вашу модель и прибить машину после окончания обучения.
Натренированная модель
Вот тут можно скачать натренированную модель (тренировал всего 4 часа). Ее можно использовать на локальной машине, что бы поиграться с ботом, если не хочется тренировать своего.
Поделиться с друзьями
Комментарии (3)

LizardVojd
11.07.2017 08:03+1этот неловкий момент когда ты создал чат бота, но он не хочет с тобой говорить(I don't want to talk to you).
И не забудьте тот факт, что при подключении нужно использовать логин ec2-user
Для разних OS разные логины. Узнать можна так

js605451
По-моему не работает.