
Итак, GitLab CI: что можно ещё рассказать о нём? На хабре уже есть статьи про установку, про настройку раннеров, про командное использование, про GitLab Flow. Пожалуй, не хватает описаний того, как используется GitLab CI в реальном проекте, где задействовано несколько команд. А в современном мире разработки ПО это действительно так: ведь есть (как минимум) разработчики, тестировщики, DevOps- и релиз-инженеры. С подобным разделением на команды мы работаем уже несколько лет. В этой статье я расскажу о том, как мы, используя и улучшая возможности GitLab CI, реализовали и применяем в production для коллектива из нескольких команд процессы непрерывной интеграции (CI) и отчасти доставки приложений (CD).
Наш пайплайн
Если вы сталкивались с CI-системами ранее, то понятие пайплайна вам знакомо — это последовательность выполнения стадий (здесь и далее в статье для термина stage использую перевод «стадия»), каждая из которых включает несколько задач (здесь и далее в статье job — «задача»). От момента внесения изменений в код до выката в production приложение по очереди оказывается в руках разных команд — подобному тому, как это происходит на конвейере. Отсюда и возник термин pipeline («конвейер» — один из вариантов дословного перевода). В нашем случае это выглядит так:
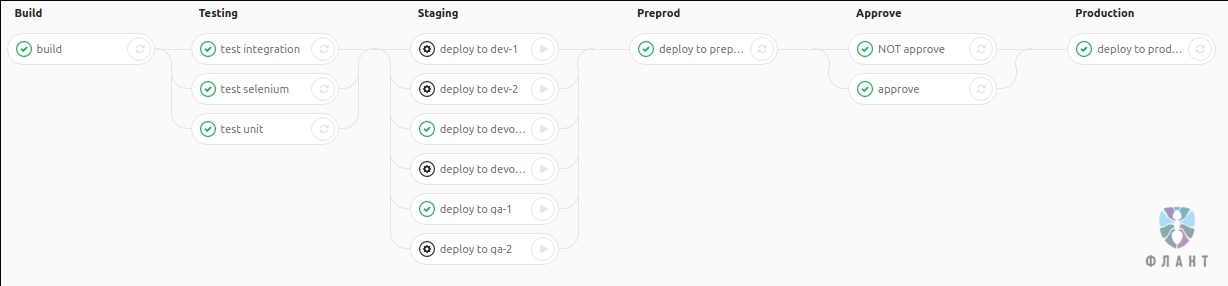
Краткие пояснения по используемым стадиям:
- build — сборка приложения;
- testing — автотесты;
- staging — развёртывание приложения для разработчиков, DevOps, тестировщиков;
- pre-production — развёртывание в «предварительный production» для команды тестировщиков;
- approve — «предохранитель», благодаря которому релиз-инженер заказчика может отказать в развёртывании на production определённого тега;
- production — развёртывание на production.
Примечание: Нет ничего совершенно универсального, поэтому для вашего конкретного случая этот пайплайн скорее всего не подходит: он либо избыточен, либо прост. Однако цель статьи не описывать единственно верный вариант, подходящий каждому. Цель — рассказать на примере о том, как можно работать в GitLab CI нескольким командам и какие возможности есть, чтобы реализовать такой пайплайн. На основе этой информации можно разработать свою собственную конфигурацию GitLab CI.
Как это используется?
Начну с рассказа о пайплайне с точки зрения его использования — то, что можно назвать user story. Тут выяснится, что на самом деле пайплайна у нас даже два: укороченный для веток и полноценный для тегов. И вот как выглядят эти последовательности:
- Разработчики выкладывают код приложения в ветки с префиксом feature_, а DevOps-инженеры — код инфраструктуры в ветки с префиксом infra_. Каждый git push в эти ветки запускает процесс сборки приложения (стадия build) и автоматические тесты (стадия testing).
- Задачи на следующих стадиях не вызываются автоматически, а определены как задачи с ручным запуском (manual).
- На стадии staging можно запустить задание и выкатить собранное и протестированное приложение на упрощенное окружение. Это могут делать разработчики, DevOps-инженеры, тестировщики. При этом для выката на окружения тестировщиков должны быть пройдены все тесты.
- После успешного прохождения тестов и выката на одно из окружений staging можно выкатить приложение в pre-production — это делают только тестировщики, DevOps-инженеры или релиз-инженеры.
- По мере накопления успешно протестированных фич релиз-инженер готовит новую версию и создаёт в репозитории тег. Пайплайн для тега отличается от пайплайна для ветки двумя дополнительными стадиями.
- После успешной сборки, тестов и выката в pre-production проводятся дополнительные ручные тесты новой версии, показ заказчику и другие «издевательства» над приложением. Если всё прошло успешно, то релиз-инженер запускает задание approve. Если что-то пошло не так, то релиз-инженер запускает задание not approve.
- Выкат приложения на production возможен только после успешного выката на pre-production и выполнения задания approve. Выкат на production может запустить релиз-инженер или DevOps-инженер.

Роль релиз-инженера в пайплайне
Пайплайн и стадии в деталях
Задачи на стадии build собирают приложение. Для этого мы используем свою разработку — Open Source-утилиту dapp (о её основных возможностях читайте и смотрите в этой статье + видео), которая хорошо ускоряет инкрементальную сборку. Поэтому сборка запускается автоматически для веток с префиксами feature_ (код приложения), infra_ (код инфраструктуры) и тегов, а не только для нескольких традиционно «главных» веток (master/develop/production/release).
Следующая стадия — staging — это набор сред для разработчиков, DevOps-инженеров и тестировщиков. Здесь объявлено несколько задач, разворачивающих приложения из веток с префиксами feature_ и infra_ в урезанных средах для быстрого тестирования новой функциональности или инфраструктурных изменений (код сборки приложения хранится в репозитории приложения).
Стадии pre-production и production доступны только для тегов. Обычно тег вешается после того, как релиз-инженеры принимают несколько merge-запросов из протестированных веток. В целом можно сказать, что мы используем GitLab Flow с тем лишь отличием, что нет автоматического развёртывания на production и потому нет отдельных веток, а используются теги.
Стадия approve — это две задачи: approve и not approve. Первая включает возможность развёртывания на production, вторая — выключает. Эти задачи существуют для того, чтобы в случае проблем на production было видно, что развёртывание происходило не просто так, а с согласия релиз-инженера. Однако суть не в лишении кого-то премии, а в том, что непосредственно развёртывание на production проводит зачастую не сам релиз-инженер, а команда DevOps. Релиз-инженер, запуская задачу approve, разрешает тем самым «нажать на кнопку» deploy to production команде DevOps. Можно сказать, что эта стадия выносит на поверхность то, что могло бы остаться в почтовой переписке или в устной форме.
Такая схема взаимодействия хорошо себя показала в работе, однако пришлось потрудиться, чтобы реализовать её. Как оказалось, GitLab CI не поддерживает из коробки некоторые нужные вещи…
Разработка .gitlab-ci.yml
Изучив документацию и различные статьи, можно быстро набросать такой вариант .gitlab-ci.yml, соответствующий описанным стадиям пайплайна:
stages:
- build
- testing
- staging
- preprod
- approve
- production
## build stage
build:
stage: build
tags: [deploy]
script:
- echo "Build"
## testing stage
test unit:
stage: testing
tags: [deploy]
script:
- echo "test unit"
test integration:
stage: testing
tags: [deploy]
script:
- echo "test integration"
test selenium:
stage: testing
tags: [deploy]
script:
- echo "test selenium"
## staging stage
.staging-deploy: &staging-deploy
tags: [deploy]
stage: staging
when: manual
script:
- echo $CI_BUILD_NAME
deploy to dev-1:
<<: *staging-deploy
deploy to dev-2:
<<: *staging-deploy
deploy to devops-1:
<<: *staging-deploy
deploy to devops-2:
<<: *staging-deploy
deploy to qa-1:
<<: *staging-deploy
deploy to qa-2:
<<: *staging-deploy
## preprod stage
deploy to preprod:
stage: preprod
tags: [deploy]
when: manual
script:
- echo "deploy to preprod"
## approve stage
approve:
stage: approve
tags: [deploy]
when: manual
script:
- echo "APPROVED"
NOT approve:
stage: approve
tags: [deploy]
when: manual
script:
- echo "NOT APPROVED"
## production stage
deploy to production:
stage: production
tags: [deploy]
when: manual
script:
- echo "deploy to production!"
Всё довольно просто и скорее всего понятно. Для каждой задачи используются следующие директивы:
stage— определяет стадию, к которой относится задача;script— действия, которые будут произведены, когда запустится задача;when— вид задачи (manualозначает, что задача будет запускаться из пайплайна вручную);tags— теги, которые в свою очередь определяют, на каком раннере будет запущена задача.
Примечание: Раннер — часть GitLab CI, аналогичная другим системам CI, т.е. агент, который получает задачи от GitLab и выполняет их
script.
Слайд про раннеры из презентации «Coding the Next Build» (? 2016 Niek Palm)
Кстати, заметили этот блок?
.staging-deploy: &staging-deploy
tags: [deploy]
stage: staging
when: manual
script:
- echo $CI_BUILD_NAMEОн демонстрирует возможность формата YAML определять общие блоки и подключать их в нужное место на нужном уровне. Подробнее см. в документации.
В описании пайплайна было сказано, что стадии approve и production доступны только для тегов. В
.gitlab-ci.yml это можно сделать с помощью директивы only. Она определяет ветки, для которых будет создаваться пайплайн, а с помощью ключевого слова tags можно разрешить создавать пайплайн для тегов. К сожалению, директива only есть только для задач — её нельзя указать при описании стадии.Таким образом, задачи на стадиях build, testing, staging, pre-production, которые должны быть доступны для веток infra_, feature_ и тегов, принимают следующий вид:
test unit:
stage: testing
tags: [deploy]
script:
- echo "test unit"
only:
- tags
- /^infra_.*$/
- /^feature_.*$/А задачи на стадиях approve и production, которые доступны только для тегов, имеют такой вид:
deploy to production:
stage: production
tags: [deploy]
script:
- echo "deploy to production!"
only:
- tagsВ полном варианте директива
only вынесена в общий блок (пример такого .gitlab-ci.yml доступен здесь).Что дальше?
На этом создание
.gitlab-ci.yml для описанного пайплайна затормаживается, т.к. GitLab CI не предоставляет директив, во-первых, для разделения задач по пользователям, а во-вторых, для описания зависимостей выполнения задач от статуса выполнения других задач. Также хотелось бы разрешить изменять .gitlab-ci.yml только отдельным пользователям.Полная реализация задуманного стала возможной только благодаря нескольким патчам к GitLab и использованию артефактов задач. Подробнее об этом читайте в следующей части статьи: «GitLab CI для непрерывной интеграции и доставки в production. Часть 2: преодолевая трудности».
Комментарии (25)

nick_volynkin
10.07.2017 12:13+1Спасибо за отличную статью про GitLab, ставлю два заслуженных плюса.
У самих GitLab есть Community Writers Program. Вы не думали о том, чтобы и туда написать (конечно, на английском)?

puker-ti
10.07.2017 14:39хотелось бы разрешить изменять .gitlab-ci.yml только отдельным пользователям
В гитлабе можно залокать файл на конкретного пользователя, либо из костылей приходит на ум вынос .gitlab-ci.yml в отдельную ветку и выдавания прав на неё
для описания зависимостей выполнения задач от статуса выполнения других задач
https://docs.gitlab.com/ee/ci/yaml/#when
вряд ли будет удобно но если разбить на большее количество стадий, то можно использовать when для зависимости выполнения задач от статуса стадии
И не сталкивались ли вы с потребностью опционального выполнения задач:
например у меня в репозитории лежит бекенд и фронтенд, правил я только бекенд, пересобирать фронтенд — не надо.
На гитлабе есть пара issue связаных с этим
https://gitlab.com/gitlab-org/gitlab-ce/issues/18667
https://gitlab.com/gitlab-org/gitlab-ce/issues/19232
мне больше понравился вариант с push-option но к сожалению это только проедложения.
Сам я придумал использовать для этого сообщения коммитов, специальной переменной в гитлабе под них нету, поэтому можно только git log -1 --pretty=%B и регуляркой искать что надо, но тут тоже проблема, потому что всё выполняется в контейнерах и гита там нетуdiafour
10.07.2017 18:08+1Лок файлов похоже доступен только EE пользователям. .gitlab-ci.yml в отдельной ветке создаст пайплайн только для этой ветки. В двух словах: про безопасность gitlab ci есть несколько задач и возможно будет даже какое-то стандартное решение, но пока мы сделали свой патч, про это будет в следующей части.
when не подходит тем, что on_failure/on_success работает только для автоматических задач и то, только в момент, когда создаётся пайплайн. Если автоматическая задача упадёт, то следующие не запустятся, но даже, если поправить проблему и перезапустить упавшую задачу, то следующие за ней не пойдут в работу. Нам это не слишком мешает, больше мешает, что ручные задачи можно запустить когда угодно. Подробнее про все эти ограничения опять же в следующей части.
Про опциональное выполнение задач скажу так:
- У нас такой потребности не возникает, потому что фронт и бэк в разных репозиториях и вообще можно сказать микросервисность, когда один фронт использует API нескольких бэков.
- В статье упомянуто, что для сборки используем dapp. В вашем сценарии, когда фронт и бэк в одном репозитории, при правильно написанном Dappfile, образ фронта не будет собираться автоматически, если изменения только в исходниках бекенда.
- Как вариант вместо git log можно попробовать файлы-флаги. Скрипт сборки будет проверять, скажем, что в корне репозитория есть .do-not-build-front и не запускать сборку фронта. На следующей стадии можно будет не запускать тесты для фронта. В следующей части будет с примерами, как использовать похожие файлы-флаги.
- Вообще проблема условного выполнения пайплайна нами тоже ощущается, но пока что хватает названий веток/тэгов. Однако этого всё равно мало, очень хочется иметь возможность перезапустить билд с другими параметрами.

mikhailian
10.07.2017 14:46В какой тулзе нарисованы такие красивые диаграммы?
diafour
10.07.2017 15:08Пайплайн в начале статьи — скриншот из gitlab. Диаграмма про раннеры — скорее всего обычный openoffice draw.

junkerSchmidt
11.07.2017 14:01Всего-то разработчикам писать еще один трежэтажный yaml? Фигня вопрос — BaaS, модная же тема — мы CI и CD «делегировали командам разработки» (будто им и так нечего делать).
diafour
11.07.2017 14:21+1В достаточно большом проекте эти трёхэтажные Yaml-ы делегированы как раз devops-инженерам. А в небольшой команде обязательно кто-то будет заниматься непрофильной, но тем не менее важной деятельностью. Если разработчики начали заниматься деплоем и это отнимает их время, то почему бы не отдать devops на аутсорс, благо сейчас много кто этим занимается.
Caravus
Статью не дочитал, но насколько я вижу — нет одной очень интересной детали:
А что происходит до этого? Почитать как собрать приложение через CI и потестировать его можно и в других статьях, а тут получается прям по канонам документации гитлаб, где всё начинается с «вот вы запушили код в репозиторий...»
Нельзя ли описать процесс до того как код попадает в репозиторий? Как разработчики разрабатывают софт, я имею ввиду как разворачиается для них среда разработки? То есть как разработчики запускают только что написанный код. Судя по рекомендациям гитлаба — каждое изменение пушится в репозиторий, а уже потом происходит какая-то магия, но это же дико неудобно — каждый раз пушить на удалённый репо, создавать 100500 разных коммитов только для того чтобы потестировать только что написанный код. Я видимо что-то не так делаю, не так понимаю?
В общем запрашиваю часть #0 этого цикла :)
kenoma
Локальные тесты у себя прогоняете и получаете проверку только что написанного кода, что вы, право.
Caravus
Чтоб локальные тесты сработали — для начала надо запустить приложение. Как вы, например, планируете тестировать веб-приложение без веб-сервера?
nick_volynkin
Юнит-тесты обычно можно запустить на машине разработчика, различные функциональные, интеграционные и дальше — тоже можно, если хватит мощности и есть возможность (помогает всяческая виртуализация).
Деплой в тестовое (да и в боевое) окружение по кнопке хорош тем, что его может выполнять кто угодно, не обязательно компетентный в девопсе в общем и деплое конкретного приложения в частности. Например, дизайнер, менеджер продукта, переводчик.
Разумеется, возможность нажать кнопку для деплоя на бой должно быть не у каждого. Эта возможность регулируется правами доступа к репозиторию. То есть кнопки просто нет у тех, кто ее жать не должен.
Caravus
Про деплой в тест или прод я вообще ничего не говорил, там всё более менее понятно — GitLab поможет.
А вот чтобы запустить тесты на машине разработчика для начала на этой самой машине нужно запустить то что мы, собственно говоря, собираемся тестировать. Если это, например, сайт — нужно поднять вебсервер (например nginx), поднять интерпретаторы (например php или ruby), собрать бэкенд (например golang) и фронтенд (js/css), потом это всё каким-то образом запустить так чтоб и разработчик мог это потрогать и скрипты тестов могли достучаться. Но это даже не основная проблема — методики отработаны годами, а сейчас с докером так вообще проблем поубавилось, но надо же развернуть максимально похоже на окружение на тесте/препроде/проде, а не просто так «как нибудь».
l0rda
Поднимите такое же окружение, как на стейджинге в докере на девелоперской машине, просто подключите папку с исходниками из IDE вместо того, что лежит в образе приложения. Для python+uwsgi удобно включить релоад по изменениям файлов, node тоже так умеет. Go ручками собирать. Никакой магии.
Caravus
Что-то сегодня народ из крайности в крайность прыгает, видимо зря я тут вопросы в понедельник задаю.
С докером тоже всё понятно, только вот запуск докера в проде и запуск докера локально могут отличаться значительно, именно за счёт окружения. Например локально вы поднимаете через docker-compose, а на проде через kubernetes и получаете разное сетевое взаимодействие между контейнерами, при этом без возможности протестировать как оно будет на проде. Или по разному передавать креды — на деве через конфиги, а на проде через gitlab втыкать.
Хотелось бы какого-то решения, подсказки, как сделать так чтоб у меня разработчики работали в той же (максимально похожей) среде что будет и у теста/прода, но при этом им не приходилось бы каждое изменение коммитить (это я про вариант с локальным гитлаб-ранером).
l0rda
Мне проще, везде compose :) так что всё одинаково
Caravus
Да я вот как раз переезжаю со связки compose+docker cloud на что-то типа gitlab+kubernetes :(
VolCh
Так настраивайте одинаково. У нас отличия прод- от дев-окружения в основном только в значениях переменных в .env файлах, да в docker-compose.override.yml, который маунтит каталоги хоста с исходниками на контейнеры и задаёт доменные имена.
Caravus
Ну запускать на проде через docker-compose — непозволительная раскошь для меня… Потому и требуются всякие kubernetes, а вот с ними уже сложнее на деве. Впрочем я уже похоже придумал свой велосипед…
VolCh
У нас и на проде, и локально docker swarm mode. От kubernetes в итоге отказались из-за проблем локального запуска как раз.
diafour
В общем хороший вопрос-то, за что минусы? Статья же висит в хабе разработки.
Про цикл разработки уже были комментарии от коллег вот в этом треде: https://habrahabr.ru/company/flant/blog/331188/#comment_10274996
С точки зрения devops-инженера всё живёт именно в gitlab — коммит в infra_*, пуш в git, выкат в своё окружение, проверка.
С точки зрения разработчика push в feature_* происходит, когда фича готова к интеграционному тестированию. То, что можно прогнать локально на среднем железе и быстро — то лучше делать локально, ведь не каждую строчку кода надо тестировать селениумом? В каждом проекте нужно приходить к некоему компромиссу — что запускать локально, какие сервисы локально разворачивать, а что проще пушнуть и потом смотреть логи в gitlab-е.
То есть часть #0 ещё более индивидуальна, чем части #1 и #2. Но тема конечно актуальная, тут сложно спорить, рано или поздно тоже статью напишем.
P.S. Есть ещё один вариант, который снимет вопросы про тесты и развёртывание окружения на локальной машине разработчика — применение web IDE.
Caravus
Сегодня просто не мой день — куда не напишу везде минусы, не обращайте внимания.
По ссылке ходил, там даже мои комментарии есть про монтирование в миникуб.
По вопросам непосредственно локальной разработки я уже всех достал, пристаю ко всем на конференциях, но толку ноль. Все говорят тоже самое — пили свой велосипед, готовых рецептов нет. Вот я и сижу пилю на том самом minikube + helm и пачке баш-скриптов. Двигаюсь уже в сторону второго этапа — разворачивание всё через гитлаб на тестовом кластере kubernetes в гугле. Медленно но верно. Просто думал что есть какой-то вариант попроще…
diafour
Быстрое развёртывание окружений предлагали ребята teatro, упомянутые в описании gitlab flow, но похоже они пропали куда-то. И как вариант, telepresence.io — локально работающее приложение как-будто работает в удалённом кластере, но ещё не пробовали.
VolCh
Мы взяли docker swarm и небольшую обвязку на bash в основном чтобы иметь на одном кластере несколько версий системы одновременно. То есть для каждой интересующей его ветки системы (монолитный репозиторий) разработчик, тестировщик и т. п., может развернуть локальную копию мало чем отличающуюся от продакшена и иметь их несколько одновременно с dns типа service.branch.project.localhost, а прод соответствует service.master.project.localhost. Основная проблема: если хочется сравнить две ветки одного сервиса в соседних вкладках, то разворачивать локально нужно 2*N контов, где N — количество сервисов, сейчас порядка 20. А различается только один. Думаю над упрощенной версией, где локально разворачивается только нужный сервис, а остальные берутся с дев-кластера, но очень не хочется связывать локальный и удаленный кластера из-за неизбежных рассинхронизаций.
Caravus
Насколько я знаю — большие компании ( со сложными сайтами) именно так и делают. На деве весит только часть над которой человек работает — останое висит на тестовых серверах. Иначе сервисы просто не помещаются в один комп…