
В этой статье я рассмотрю стратегии резервного копирования Cache с использованием систем внешнего резервного копирования и приведу примеры интеграции с решениями на основе снимков состояния виртуальной машины (VM snapshot, снапшот). Большинство решений, с которыми я сталкиваюсь сегодня, развернуты на базе Linux и VMware, поэтому я приведу примеры решений именно с использованием снапшотов VMware.
Список моих статей из серии 'Платформы данных InterSystems и производительность' находится здесь (англ.).
Для лучшего понимания данной статьи вам следует также ознакомиться с руководством по резервному копированию и восстановлению в онлайн-документации Cache.
Cache backup: батарейки в комплекте?
Встроенное горячее резервное копирование (Cache online backup) поставляется вместе с Cache «из коробки» и предназначено для резервного копирования баз данных Cache без остановки системы. Однако существуют и более эффективные решения для резервного копирования, о которых стоит знать в те моменты, когда вы планируете масштабирование крупной системы. Внешнее резервное копирование (External Backup) с использованием технологий создания снимков — рекомендуемое мною решение для резервного копирования систем, в том числе, использующих базы данных Cache.
Что необходимо учитывать при внешнем резервном копировании?
В онлайн документации InterSystems, посвященной внешнему резервному копированию, можно найти все интересующие детали. Отметим лишь ключевой момент:
«Для обеспечения целостности снимка файловой системы Cache предоставляет возможности для заморозки (freeze) записи в базы данных в момент создания снимка. Заморозке подвергаются только попытки физической записи в файлы базы данных, что позволяет пользовательским процессам продолжать бесперебойно выполнять обновления базы данных в памяти».
Важно также отметить, что часть процесса создания снимка в виртуализированных системах вызывает небольшую паузу в работе виртуальной машины, которую принято называть замиранием (stun). Обычно замирание длится меньше секунды, поэтому его не замечают пользователи и оно не оказывает воздействия на работу системы, однако в некоторых случаях замирание может длиться и дольше. Если замирание длится дольше, чем таймаут QoS (Quality of service, показатель качества обслуживания) зеркалирования базы данных Cache, то резервный узел зеркала решит, что произошел сбой в основной системе, и произведет переключение зеркала. Позже в этой статье я расскажу как можно замерить время замирания на тот случай, если вам нужно будет внести изменения в настройку таймаута QoS для зеркалирования.
Варианты резервного копирования
Минималистичное решение для резервного копирования – встроенное резервное копирование (Cache Online Backup)
Если у вас нет возможности использовать другие средства, остается этот старый добрый способ, который входит в комплект поставки с платформами InterSystems. Учтите, что Cache online backup создает резервные копии только для файлов баз данных Cache, сохраняя все непустые блоки в базах данных, записывая их последовательно в файл. Cache Online Backup поддерживает накопительное (cumulative) и инкрементное (incremental) резервное копирование.
В контексте VMware, Cache Online Backup выполняется на гостевой машине. Подобно другим аналогичным решениям, операции, выполняемые Cache Online Backup, одинаковы независимо от того, виртуализировано ли приложение или выполняется непосредственно на физическом сервере. Соответственно, копии, полученные Cache Online Backup должны быть перемещены на резервный носитель вместе со всеми другими файлами, которыми пользуется ваше приложение. При резервном копировании системы необходимо помнить о каталоге приложения, основном и альтернативном каталогах журнала БД, и любых других каталогах, содержащих файлы, используемые приложением.
Cache Online Backup следует рассматривать либо как подход начального уровня для небольших проектов, желающих реализовать недорогое решение для «горячего» резервного копирования баз данных, либо для создания разовых резервных копий. Например, создание подобных копий очень полезно при первоначальной настройке зеркалирования. Однако, поскольку базы данных увеличиваются в размерах и поскольку базы данных Cache обычно являются лишь частью клиентского набора данных, внешние резервные копии в сочетании с технологией создания моментальных снимков при использовании сторонних утилит рекомендуются как наилучшее решение с такими преимуществами, как возможность включать в резервную копию файлы, отличных от файлов базы данных, уменьшенное время восстановления, возможность контроля данных в масштабах всей организации и доступность улучшенных инструментов для каталогизации и управления.
Рекомендуемое решение для резервного копирования: внешнее резервное копирование
Рассмотрим его на примере VMware. Использование VMware для виртуализации добавляет новые функции и возможности для защиты виртуальных машин в целом. Виртуализация решения приводит систему (включая операционную систему) к эффективной инкапсуляции вашего приложения со всеми данными внутри одного файла vmdk (и нескольких других файлов). При необходимости этими файлами можно очень легко манипулировать, и они могут использоваться для быстрого восстановления целой системы. Это сильно отличается от восстановления работоспособности вашего приложения на голом железе, где вы должны восстановить и настроить каждый компонент по отдельности — операционную систему, драйверы, сторонние приложения, СУБД и файлы баз данных и т.д.
Снимок состояния VMware
VMware vSphere Data Protection (VDP) и другие сторонние решения для резервного копирования виртуальных машин, такие как Veeam или Commvault, используют функции снимков состояния (snapshot) виртуальных машин VMware для создания резервных копий. Ниже приведено краткое объяснение механизма работы снимков VMware. Для получения более подробной информации обратитесь к документации.
Важно помнить, что снимки делаются со всей виртуальной машины и что гостевая операционная система и любые приложения или СУБД не знают о том, что сейчас с них делают снимок. Запомните также следующее:
Сами по себе снимки VMware не являются резервными копиями!
Снимки позволяют использовать ПО для резервного копирования и сделать резервные копии, но они не являются резервными копиями сами по себе.
VDP и другие сторонние решения используют процесс создания снимков состояния VMware в сочетании с каким-либо приложением для управления созданием и, что очень важно, удалением снимков. Вкратце последовательность событий для создания внешней резервной копии с помощью снимков VMware выглядит следующим образом:
- Стороннее программное обеспечение для резервного копирования запрашивает у хоста ESXi выполнение снимка состояния VMware.
- Файлы .vmdk виртуальной машины переводятся в режим «только для чтения» и для каждого файла .vmdk каждой виртуальной машины создаётся дочерний .vmdk дельта-файл.
- Любая запись на диск происходит в дельта файл виртуальной машины. Любые операции чтения выполняются сначала из дельта-файла.
- Программное обеспечение резервного копирования выполняет резервное копирование родительских .vmdk-файлов, находящихся в режиме «только для чтения»
- Когда резервное копирование завершено, снимок сливается с исходным файлом (диски виртуальной машины становятся доступными для записи и обновлённые блоки из дельта-файлов дописываются к родительским файлам).
- Снимки VMware удаляются.
Решения для резервного копирования также содержат специальные возможности, как например отслеживание измененных блоков (Changed Block Tracking, CBT), чтобы выполнять инкрементное или накопительное резервное копирование максимально быстро и эффективно (что особо важно для экономии места). Подобные решения обычно также добавляют другие полезные и важные функции, такие как сжатие данных, организация работы по расписанию, восстановление виртуальных машин с другим IP-адресом для проверки целостности, восстановление как всей виртуальной машины, так и отдельных файлов с нее, управление каталогом резервных копий и т.д.
Снимки состояния VMware, которые должным образом не управляются или оставляются висеть длительное время, могут сильно уменьшить свободное место в хранилище (по мере накопления изменений дельта-файлы становятся всё больше и больше), а также замедлить работу виртуальной машины.
Следует очень хорошо подумать, прежде чем делать снимки состояния вручную на основном сервере баз данных. Зачем вы это делаете? Что произойдет, если вы вернетесь в прошлое к тому моменту, когда создавали снимок? Что происходит со всеми транзакциями между созданием снимка и откатом изменений?
Если ваше программное обеспечение резервного копирования создает и удаляет снимки состояния — это абсолютно нормально. Снимок и должен создаваться только на непродолжительное время, а ключевой частью вашей стратегии резервного копирования будет выбор времени копирования когда система минимально загружена, что еще больше снизит влияние на пользователей и общую производительность.
Особенности Cache для снимков состояния системы
Перед выполнением снимка база данных должна быть стабилизирована (quiesced): все записи в файлы должны быть завершены и файлы баз данных должны быть в корректном состоянии. Cache предоставляет методы и API для завершения, а затем замораживания (freeze) записи в базы данных на короткий период создания снимка. Заморозке во время создания снимка подвергаются только попытки физической записи в файлы базы данных, что позволяет пользовательским процессам продолжать выполнять обновления в памяти бесперебойно. После того как снимок был сделан, возможность записи в базу данных восстанавливается, база данных «оттаивает» (thaw), и резервная копия продолжает копироваться на резервный носитель. Время между замораживанием и оттаиванием должно быть небольшим (не более нескольких секунд).
В дополнение к приостановке записи, заморозка Cache также приводит к смене файлов журнала и помещению маркера создания резервной копии в журнал. Запись в файл журнала при этом продолжается нормально, пока запись в физическую базу данных заморожена. Если система рухнет в то время, пока записи в физической базе данных будут заморожены, данные будут восстановлены из журнала как обычно при запуске.
Следующая диаграмма показывает замораживание и оттаивание с выполнением снимков для создания резервной копии с корректным файлом базы данных.
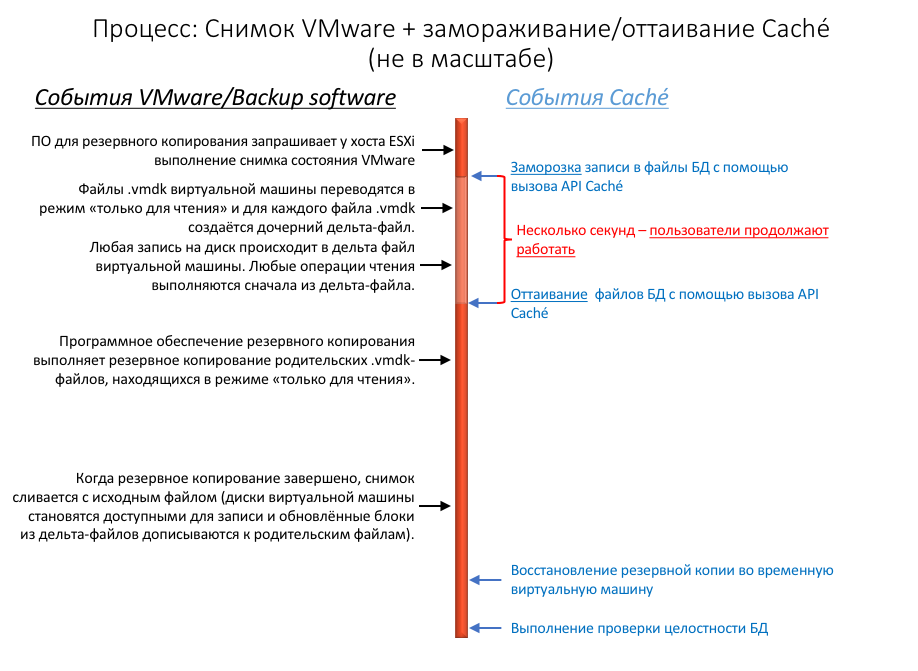
Обратите внимание на короткое время между замораживанием и оттаиванием — это время только на создание снимка, а не время, которое требуется на копирование всего родительского объекта в резервную копию.
Заморозка и оттаивание Cache
vSphere позволяет автоматически вызывать скрипты до и после создания снимка: это и есть те самые моменты, которые называются заморозкой и оттаиванием Cache. Примечание: для правильной работы этого функционала ESXi хост запрашивает у гостевой операционной системы заморозку дисков через VMware Tools.
В гостевой операционной системе должны быть установлены Инструменты VMware. Скрипты должны соблюдать строгие требования к имени и местоположению. Необходимо также назначить корректные права на файлы. Имена скриптов для VMware на Linux:
# /usr/sbin/pre-freeze-script
# /usr/sbin/post-thaw-scriptНиже приведены примеры скриптов замораживания и оттаивания, которые наша команда использует для резервного копирования с помощью Veeam в наших внутренних тестовых лабораториях. Эти скрипты также должны подойти для работы и с использованием других продуктов. Примеры были протестированы и использовались на vSphere 6 и Red Hat 7.
Хотя эти сценарии могут использоваться в качестве примеров и являются иллюстрацией к описываемому методу, вы должны убедиться в их корректности для вашей собственной среды!
Пример скрипта заморозки:
#!/bin/sh
#
# Script called by VMWare immediately prior to snapshot for backup.
# Tested on Red Hat 7.2
#
LOGDIR=/var/log
SNAPLOG=$LOGDIR/snapshot.log
echo >> $SNAPLOG
echo "`date`: Pre freeze script started" >> $SNAPLOG
exit_code=0
# Только для запущенных экземпляров
for INST in `ccontrol qall 2>/dev/null | tail -n +3 | grep '^up' | cut -c5- | awk '{print $1}'`; do
echo "`date`: Attempting to freeze $INST" >> $SNAPLOG
# Detailed instances specific log
LOGFILE=$LOGDIR/$INST-pre_post.log
# Freeze
csession $INST -U '%SYS' "##Class(Backup.General).ExternalFreeze(\"$LOGFILE\",,,,,,1800)" >> $SNAPLOG $
status=$?
case $status in
5) echo "`date`: $INST IS FROZEN" >> $SNAPLOG
;;
3) echo "`date`: $INST FREEZE FAILED" >> $SNAPLOG
logger -p user.err "freeze of $INST failed"
exit_code=1
;;
*) echo "`date`: ERROR: Unknown status code: $status" >> $SNAPLOG
logger -p user.err "ERROR when freezing $INST"
exit_code=1
;;
esac
echo "`date`: Completed freeze of $INST" >> $SNAPLOG
done
echo "`date`: Pre freeze script finished" >> $SNAPLOG
exit $exit_code
Пример скрипта оттаивания:
#!/bin/sh
#
# Script called by VMWare immediately after backup snapshot has been created
# Tested on Red Hat 7.2
#
LOGDIR=/var/log
SNAPLOG=$LOGDIR/snapshot.log
echo >> $SNAPLOG
echo "`date`: Post thaw script started" >> $SNAPLOG
exit_code=0
if [ -d "$LOGDIR" ]; then
# Только для запущенных экземпляров
for INST in `ccontrol qall 2>/dev/null | tail -n +3 | grep '^up' | cut -c5- | awk '{print $1}'`; do
echo "`date`: Attempting to thaw $INST" >> $SNAPLOG
# Detailed instances specific log
LOGFILE=$LOGDIR/$INST-pre_post.log
# Оттаивание
csession $INST -U%SYS "##Class(Backup.General).ExternalThaw(\"$LOGFILE\")" >> $SNAPLOG 2>&1
status=$?
case $status in
5) echo "`date`: $INST IS THAWED" >> $SNAPLOG
csession $INST -U%SYS "##Class(Backup.General).ExternalSetHistory(\"$LOGFILE\")" >> $SNAPLOG$
;;
3) echo "`date`: $INST THAW FAILED" >> $SNAPLOG
logger -p user.err "thaw of $INST failed"
exit_code=1
;;
*) echo "`date`: ERROR: Unknown status code: $status" >> $SNAPLOG
logger -p user.err "ERROR when thawing $INST"
exit_code=1
;;
esac
echo "`date`: Completed thaw of $INST" >> $SNAPLOG
done
fi
echo "`date`: Post thaw script finished" >> $SNAPLOG
exit $exit_code
Не забудьте установить права на файлы:
# sudo chown root.root /usr/sbin/pre-freeze-script /usr/sbin/post-thaw-script
# sudo chmod 0700 /usr/sbin/pre-freeze-script /usr/sbin/post-thaw-scriptТестирование заморозки и оттаивания
Чтобы проверить работу приведенных сценариев, вы можете вручную запустить выполнение снимка на виртуальной машине и проверить что выведет сценарий. На следующем скриншоте показан диалог «Take VM Snapshot» и его опции.

Сбросьте флажок "Snapshot the virtual machine's memory" (Сохранить оперативную память виртуальной машины)
Отметьте флажок "Quiesce guest file system (Needs VMware Tools installed)" (Стабилизировать гостевую файловую систему). Это приведет к приостановке запущенных процессов в гостевой операционной системе и сбросу буферов, чтобы содержимое файловой системы находилось в известном непротиворечивом состоянии при выполнении снимка.
Важно! После теста не забудьте удалить сделанный снимок!
Если флажок стабилизации (quiescing) отмечен и виртуальная машина работает в тот момент, когда делается снимок, для стабилизации файловой системы виртуальной машины будет использоваться VMware Tools. Стабилизация файловой системы представляет собой процесс приведения данных на диске в состояние "готов к резервному копированию". Этот процесс может включать в себя такие операции, как очистка заполненных буферов между кэшем операционной системы в памяти и диском.
Следующий вывод показывает содержимое файла журнала $SNAPLOG, указанного в приведенных выше примерах сценариев замораживания/оттаивания после запуска процедуры резервного копирования, которая в том числе делает выполнение снимка.
Wed Jan 4 16:30:35 EST 2017: Pre freeze script started
Wed Jan 4 16:30:35 EST 2017: Attempting to freeze H20152
Wed Jan 4 16:30:36 EST 2017: H20152 IS FROZEN
Wed Jan 4 16:30:36 EST 2017: Completed freeze of H20152
Wed Jan 4 16:30:36 EST 2017: Pre freeze script finished
Wed Jan 4 16:30:41 EST 2017: Post thaw script started
Wed Jan 4 16:30:41 EST 2017: Attempting to thaw H20152
Wed Jan 4 16:30:42 EST 2017: H20152 IS THAWED
Wed Jan 4 16:30:42 EST 2017: Completed thaw of H20152
Wed Jan 4 16:30:42 EST 2017: Post thaw script finishedНа этом примере видно, что время между замораживанием и оттаиванием составляет 6 секунд (16:30:36 — 16:30:42). В течение этого периода работа пользователей НЕ прерывается. Вам нужно будет собрать статистику с ваших собственных систем, но для информации отметим, что данный пример был запущен во время тестирования производительности приложения на системе без «узких мест» в системе ввода/вывода, в среднем выполнявшей более 2 миллионов операций чтения БД в секунду (Glorefs/sec), 170 000 операций записи БД в секунду (Gloupds/sec) и в среднем 1100 физических операций чтения диска в секунду и 3000 записей за цикл демона записи БД (write daemon cycle).
Помните, что оперативная память не является частью снимка, поэтому при восстановлении резервной копии виртуальная машина будет перезагружена и выполнит процедуры восстановления. Файлы базы данных будут согласованными. Вы не ставите целью «продолжить работу» из резервной копии и просто хотите, чтобы у вас были корректные резервные копии файлов на конкретный момент времени. Вы можете затем выполнить прогон журналов БД и выполнить другие процедуры восстановления, необходимые для восстановления целостности приложения и согласованности транзакций после восстановления файлов.
Для дополнительной защиты данных, смена журнала может также выполняться сама по себе, сопровождаемая резервным копированием или репликацией журнала, например, ежечасно.
Ниже приведено содержимое $LOGFILE из примера заморозки/оттаивания, приведенного выше, в котором показаны подробности журнала для снимка.
01/04/2017 16:30:35: Backup.General.ExternalFreeze: Suspending system
Journal file switched to:
/trak/jnl/jrnpri/h20152/H20152_20170104.011
01/04/2017 16:30:35: Backup.General.ExternalFreeze: Start a journal restore for this backup with journal file: /trak/jnl/jrnpri/h20152/H20152_20170104.011
Journal marker set at
offset 197192 of /trak/jnl/jrnpri/h20152/H20152_20170104.011
01/04/2017 16:30:36: Backup.General.ExternalFreeze: System suspended
01/04/2017 16:30:41: Backup.General.ExternalThaw: Resuming system
01/04/2017 16:30:42: Backup.General.ExternalThaw: System resumedЗамирание виртуальной машины
Во время создания снимка виртуальной машины, а также после завершения резервного копирования и удаления снимка виртуальную машину необходимо заморозить на короткий период времени. Это кратковременное замораживание часто называют замиранием (stun). Хорошая статья о замирании виртуальных машин есть здесь. Я изложу некоторые подробности ниже, применительно базам данных Cache.
Выдержка из статьи: «Чтобы создать снимок виртуальной машины, виртуальная машина «замирает», чтобы (i) сериализовать состояние устройства на диск и (ii) закрыть текущий работающий диск и создать точку начала снимка… При слиянии дельта-файлов виртуальная машина «замирает», чтобы закрыть диски для записи и перевести их в состояние, подходящее для слияния.»
Время замирания обычно составляет около 100 миллисекунд, однако, при очень высокой активности записи на диск, во время фазы слияния дельта-файлов замирание может длиться до нескольких секунд.
Если виртуальная машина является основным или резервным участником зеркалирования Cache, и время замирания больше, чем таймаут QoS для зеркалирования, зеркало может ошибочно сообщить о сбое основной виртуальной машины и инициировать перехват зеркала резервной системой.
Для получения дополнительной информации о параметре QoS при зеркалировании обратитесь к документации. Стратегии, сводящие к минимуму время замирания, включают выбор момента резервного копирования, когда активность базы данных является максимально низкой, а также наличие хорошо настроенной системы хранения.
Как отмечалось выше, при создании снимка есть несколько опций, которые можно указать. Одна из опций позволяет включать сохранение оперативной памяти в снимке. Помните, что сохранение оперативной памяти не требуется для резервного копирования базы данных Cache. Если установлен флаг сохранения памяти, дамп внутреннего состояния виртуальной машины будет входить в снимок. Выполнение снимка с памятью занимает гораздо больше времени. Снимки памяти используются для возврата к такому состоянию виртуальной машины, которое было на момент выполнения снимка. Этого НЕ требуется для резервного копирования файлов базы данных.
Когда выполняется снимок оперативной памяти, состояние всей виртуальной машины будет заморожено на неопределенное время.
Как уже отмечалось ранее, для резервных копий флажок «согласованность» (quiesce) должен быть отмечен, чтобы гарантировать целостное и успешное резервное копирование.
Узнаем время замирания из журналов VMware
Начиная с ESXi 5.0 время замирания регистрируется в файле журнала каждой виртуальной машины (vmware.log) сообщениями, похожими на следующие:
2017-01-04T22:15:58.846Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 38123 usВремя замирания указывается в микросекундах, поэтому в примере выше 38123 us это 38123/1,000,000 секунд или 0.038 секунды.
Чтобы быть уверенным в том, что продолжительность замирания машины находится в допустимых пределах, или если есть подозрение, что длительное время замирания машины вызывает проблемы, вы можете скачать и просмотреть файлы vmware.log из папки этой виртуальной машины. После загрузки вы можете открыть и упорядочить журнал с помощью стандартных команд Linux, которые мы рассмотрим в следующей главе.
Пример загрузки файлов vmware.log
Существует несколько способов скачать журналы, в том числе путём создания пакета поддержки (support bundle) VMware через консоль управления vSphere или из командной строки хоста ESXi. Обратитесь к документации VMware за всеми подробностями, а ниже приведен простой способ создания и сбора минимального пакета журналов поддержки, который включает в себя файл vmware.log, позволяющий узнать продолжительность замирания.
Вам понадобится длинное имя каталога, где расположены файлы виртуальной машины. Зайдите по ssh на тот хост ESXi, где запущена виртуальная машина с базой данных и выполните команду vim-cmd vmsvc/getallvms для получения списка vmx файлов и связанных с ними уникальных длинных имён.
Пример длинного имени для базы данных виртуальной машины, упоминающейся в этой статье, будет выглядеть так:
26 vsan-tc2016-db1 [vsanDatastore] e2fe4e58-dbd1-5e79-e3e2-246e9613a6f0/vsan-tc2016-db1.vmx rhel7_64Guest vmx-11Далее выполните команду для сбора файлов журнала:
vm-support -a VirtualMachines:logsКоманда отобразит местоположение созданного пакета поддержки, например:
To see the files collected, check '/vmfs/volumes/datastore1 (3)/esx-esxvsan4.iscinternal.com-2016-12-30--07.19-9235879.tgz'Теперь вы можете забрать файлы с хоста для дальнейшей обработки и анализа по протоколу sftp.
В этом примере после распаковки пакета поддержки вы можете проследовать по путям, соответствующим длинным именам баз данных виртуальных машин. Например, в данном случае:
<bundle name>/vmfs/volumes/<host long name>/e2fe4e58-dbd1-5e79-e3e2-246e9613a6f0.Там вы увидите несколько пронумерованных лог-файлов. Самый последний файл номера не имеет, это vmware.log. Журнал может быть не более 100 КБ, но при этом будет содержать очень много информации. Поскольку мы просто ищем моменты начала и конца замирания, их достаточно легко найти с помощью утилиты grep, например:
$ grep Unstun vmware.log
2017-01-04T21:30:19.662Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 1091706 us
---
2017-01-04T22:15:58.846Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 38123 us
2017-01-04T22:15:59.573Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 298346 us
2017-01-04T22:16:03.672Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 301099 us
2017-01-04T22:16:06.471Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 341616 us
2017-01-04T22:16:24.813Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 264392 us
2017-01-04T22:16:30.921Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 221633 usВ примере мы видим две группы замираний. Первая состоит из момента создания снимков, а вторая — через 45 минут для каждого диска при завершении объединения снимка (например, после того, как программное обеспечение для резервного копирования завершило копирование основного vmx файла). В приведенном выше примере мы можем видеть, что большинство замираний не превосходят секунды, хотя начальное замирание составляет чуть более одной секунды.
Короткое замирание незаметно для конечного пользователя. Тем не менее, системные процессы, такие как, например, зеркалирование Cache, постоянно контролируют, является ли база «живой». Если время замирания превышает таймаут QoS для зеркалирования, то узел может быть признан неконтактным и «мертвым», и произойдет обработка аварийной ситуации.
Совет: для обзора всех журналов или поиска неисправностей удобно использовать команду grep чтобы найти все времена замираний и затем отформатировать их с помощью утилиты awk и отсортировать, как в следующем примере:
grep Unstun vmware* | awk '{ printf ("%'"'"'d", $8)} {print " ---" $0}' | sort -nrИтог
Вы должны регулярно контролировать свою систему во время нормальной работы, чтобы знать и понимать величину времени замирания и то, как она может повлиять на средства обеспечения высокой доступности, например, зеркалирование. Как уже отмечалось ранее, стратегии, направленные на то, чтобы свести к минимуму время замирания, включают запуск резервных копий, когда активность базы данных и хранилища низкая и когда производительность хранилища максимальная. Для постоянного мониторинга журналы могут обрабатываться с помощью VMware Log insight или других инструментов.
Я ещё вернусь к операциям резервного копирования для платформ данных InterSystems в будущих статьях. А теперь если у вас есть комментарии или предложения, основанные на процессах, происходящих в ваших системах, поделитесь ими в комментариях.
Примечание переводчика: поскольку мы работаем с автором в одном офисе, я могу передать ему ваши вопросы и переслать сюда его ответы. Также обсуждение на английском есть в оригинале статьи на InterSystems Developer Community.