
Как строить рекомендательные системы? Какие модели машинного обучения можно применять? Какие проблемы решают интерактивные рекоммендеры, а какие – нет? Какие инструменты могут быть полезны для e-commerce портала? Об этом – в докладе Big Data-инженера ЕРАМ Екатерины Сотенко «Обзор подходов построения интерактивных рекоммендеров», с которым она выступила на самарском ITsubbotnik этой весной. Ниже – видеозапись доклада, еще ниже – его краткое содержание.
К EPAM обратился известный британский модный дом, которому нужен был интерактивный рекоммендер для e-commerce портала. До этого EPAM представил имплементацию обычного offline рекоммендера. Теперь заказчик хотел узнавать о желаниях пользователей в реальном времени, а не постфактум. Чтобы решить эту задачу, мы изучили портал заказчика и выбрали следующие элементы в работу:
1. Главная страница
Это страница, где пользователь – даже если он еще не залогинился – видит каталог. Какой бы пользователь не пришел – уже зарегистрированный или новый – нам нужно его заинтересовать с самого начала. Для этого мы предложили концепцию с категориальными фильтрами: вы можете выбирать из предложенного набора категорий по принципу «я хотел бы больше это, нежели это», а не точно указывать («хочу именно это»). В этом и отличие от обычного поиска: пользователю дается инструмент, с помощью которого можно быстро обнаружить что-то интересное ему, даже если человек четко не сформулировал свои пожелания. Здесь интерактивные рекоммендеры уместны, так как нам нужно понять, ищет пользователь что-то новое или уже привычное. Эту задачу можно решить с помощью группы алгоритмов «многорукие бандиты» (multi-armed bandits).
2. Основной каталог
Традиционно пользователь может отбирать элементы из каталога с помощью фильтров по цвету, размеру и другим критериям. Если нам уже известны предпочтения человека, можно сразу представить каталог с наиболее релевантным для него подбором элементов. Алгоритмы, использующие информацию о пользователе, – это demographic based рекоммендеры.
Но тут возникает вопрос: что, если мы не знаем о контексте пользователя и не понимаем, чем определяется его выбор? Здесь нам помогут context based рекоммендеры. Более того, мы можем строить рекомендации интерактивно: например, если пользователь начинает скроллить экран, мы понимаем, что он продолжает искать, и подбрасываем ему новые продукты. Мы учитываем, что варианты, которые уже были представлены, оказались неинтересны. Здесь можно снова использовать модель multi-armed bandits.
3. Корзина
Если пользователь определился с выбором, можно попробовать заинтересовать его чем-то еще. Это реализуется с помощью линейки товаров вида «С этим также покупают». Для построения этой линейки используются learning to rank или sequential pattern mining алгоритмы.
4. Подарки
Основная проблема этого раздела в том, что подарки пользователь выбирает не себе. Нужно использовать информацию не о вас, а о том, кому достанется подарок. Тут не помогут ни знания о пользователе, ни коллаборативная фильтрация. Нам нужна информация, с кем дружит пользователь, есть ли у него дети и т.д. Здесь нам поможет demographic based рекоммендер, использующий информацию об отношениях пользователя, и sequential pattern mining.
Когда мы определились с задачами и инструментами, нужно понять, какие инструменты принесут наибольшую конверсию. Рассмотрим пример apparel stores. В Германии провели исследование о поведении пользователей во время онлайн-шопинга, при покупке одежды. В нем участвовало около 50 женщин. Им нужно было подобрать себе образ на встречу выпускников в ресторане. В рамках эксперимента они могли купить любое количество вещей, но потратить не больше 300 евро. Основываясь на данных о доходах, возрасте, привычке следить за модой, исследователи разделили участниц на несколько групп и начали собирать статистику.
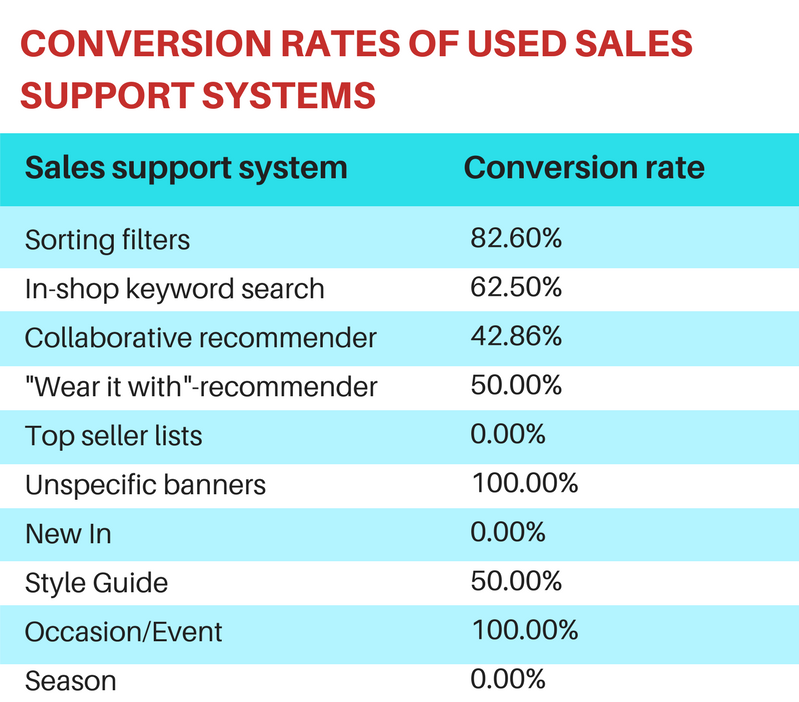
Результаты исследования показали: чаще всего участницы использовали фильтры и поиск (71%). Среди фильтров активнее всего пользовались фильтром по цвету, далее идут фильтры по размеру и стоимости. Если говорить о рекоммендерах, то чаще всего использовали коллаборативную фильтрацию, а другие инструменты – гораздо реже.
При этом основную долю конверсии сгенерировал поиск (62%) и навигация с помощью фильтров (83%). Это значит, что, если пользователь ищет, он знает, чего хочет, и не нужно мешать ему. Коллаборативная фильтрация, рекомендация «надеть с этим», style guide дали меньше 50% конверсии. Это объясняется тем, что люди не хотят выглядеть как другие и стремятся подчеркнуть свою индивидуальность. С другой стороны, 50% – это неплохо, и при уместном использовании такие рекоммендеры могут быть очень эффективными. Например, раздел Occasion/event принес 100% конверсию.
Отдельно стоит отметить, что разделы Top seller’s list, New in, сезонные предложения принесли 0% конверсии. Это не стоит воспринимать как абсолютные показатели, так как нужно помнить о задаче: женщины выбирали не повседневную одежду, кроме того, выбор не зависел от сезона. Значит, в других условиях такие рекомендации могли сработать.

Кратко рассмотрим, как можно реализовать те или иные рекоммендеры.
1. Коллаборативная фильтрация
Идея этого подхода в том, что есть пользователи и элементы, которые люди оценивают несколькими способами: ставят лайки, оценки и т.д. На их основе строится матрица оценок пользователей. Но поскольку далеко не все ставят лайки, эта матрица разряженная, и задача заключается в регрессии недостающих оценок.
Есть два типа алгоритмов, которые реализуют эту концепцию:
• Neighborhood-based (Memory-Based) методы. Они помогают восстановить оценки явно, при этом храня полную матрицу отношений, которая, как правило, очень большая. Главный недостаток этих методов – низкая эффективность из-за того, что они не дают действительно персонализованную оценку.
Примеры алгоритмов: User-Based Filtering (UBCF), Item-Based Filtering (IBCF), Slope-One.
• Model Based методы. Их идея в том, чтобы определить скрытые факторы (интересы пользователей), на основе которых люди ставят оценки.
Примеры алгоритмов:
o Matrix Factorization (MF): Singular Value Decomposition (SVD, SVD++, timeSVD++, MSVD), Non-Negative MF (ALS), Factorization Machines, Probabilistic Matrix Factorization (PMF)
o RBM (Restricted Bolzman Machines).
o Incremental CF via Co-clustering (COCL, ECOCL)
o Probabilistic Principle Component Analysis (pPCA), Probabilistic Latent Semantic Analysis (pLSA), Latent Dirichlet Allocation (LDA) and etc.
Достоинство коллаборативной фильтрации заключается в том, что для построения рекомендаций не нужны знания о предметной области вообще, не требуется знать деталей об айтемах и пользователях. Они кластеризуются между собой в режиме самоорганизации.
Недостаток: проблема холодного старта (cold start problem): если появляется новый пользователь или айтем, они не будут рекомендованы, так как нет информации и оценок.
2. Сontent based рекоммендеры
Чтобы решить проблему холодного старта и рекомендовать новые элементы, коллаборативную фильтрацию иногда интегрируют с content based рекоммендерами. При этом подходе нужно описать все айтемы. Но их свойства не всегда получается собрать по юридическим или техническим причинам.
3. Demographic based рекоммендеры
Если холодный старт произошел для пользователя, то нам нужно собрать о нем информацию и описать его.
Общая проблема группы методов, связанных с коллаборативной фильтрацией, заключается в следующем. Они работают хорошо, только если речь идет о большом количестве данных. Эти методы подходят для рекомендации объектов, выбор которых зависит от вкуса пользователя, например, для рекомендации фильмов или музыки. Но этот подход не эффективен, когда нужно рекомендовать такие сложные объекты, как машины, недвижимость и т.д. В этом случае можно использовать knowledge based recommenders.
4. Knowledge based рекоммендеры
Здесь требуются эксперты, которые оценивают предлагаемые объекты и описывают критерии, по которым их выбирают пользователи. Считается, что эти эксперты знают все: к какому типу пользователей вы принадлежите, сколько хотите потратить, какими характеристиками должны обладать товары, чтобы привлечь вас. Таким образом решается проблема и для пользователей, и для айтемов. Но тут есть недостаток: эксперты – очень дорогие и ненадежные люди, поэтому не всегда возможно описать все правила для вашего каталога.
5. Сontext-aware рекоммендеры
Оффлайн оценки экспертов могут быть ошибочны и неполны, так как на этапе оценки неизвестен контекст, в котором пользователь выбирает айтем. Контекст со временем может меняться. Например, вы все время смотрели фильмы ужасов, но вдруг начали искать мультики, потому что ваши дети захотели их посмотреть. С точки зрения рекоммендера вы сошли с ума, и он продолжит рекомендовать вам фильмы ужасов, предполагая, что однажды вы придете в себя. Что с вами случилось на самом деле? Изменился контекст, и на это нужно реагировать, что и позволяют сделать context-aware рекоммендеры.
Чтобы эффективно делать контекстные рекомендации, нужно решать задачу Change Point Detection в смысле временных рядов. Когда поведение пользователя резко меняется, это значит, что резко изменился контекст. Есть различные методы, которые позволяют нам учитывать контекст: factorization machines, Byesian Probablistic Tensor Factorization.
6. Интерактивные рекоммендеры
Их главная цель – в режиме текущей сессии пользователя выбрать варианты, наиболее релевантные его пожеланиям.
Жизненный пример
Вспомним себя в баре. Вы хотите отлично провести время. Видите краны от пива и начинаете выбирать, что выпить. В этот момент вы решаете задачу: пить незнакомое (exploration) или знакомое (exploitation) пиво? Это Exploration vs. Exploitation problem. Ее должны решать интерактивные рекоммендеры. Подходы к решению этой проблемы:
1. Active learning (AL) позволяет осуществить редукцию пространства поиска
2. Multi-armed bandits (MAB) algorithms: E-greedy, UCB, LinUCB, Tomson Sampling, Active Thompson Sampling (ATS)
3. Markov Decision Process (MDP)/Reinforcement Learning (RL)
4. Hybrid scoring approaches could be considered – models composition used.

1. E-greedy – это просто частотная оценка: мы выбираем ту или иную руку нашего бандита на основе частоты ее использования. Вспоминаем краны в баре: чем чаще мы используем тот или иной кран, тем больше мы любим это пиво.
2. Upper Confidence Bound (UCB) – стремимся оценить удовольствие, которое получит пользователь от выбора определенного айтема. Задача – достаточно точно оценить это удовольствие для каждой из ручек. Для новых айтемов в этом алгоритме присваивается потенциально максимальная оценка вознаграждения. Каждый раз, когда бандиту дергают ручку, актуализируется оценка вознаграждения. Этот алгоритм будет всегда больше склоняться к exploration, нежели к exploitation, и не может поддерживать вычисление слишком большого числа рук.
3. Tomson Sampling (TS) может представлять каждую из рук бандита в виде вероятностного распределения и каждый раз просто пересчитывать вероятность при взаимодействии с каждой из рук. Каждая рука выбирается на основе ее истории, и наша цель – минимизировать общее разочарование, которое может испытывать пользователь при взаимодействии с MAB.
Как правило, интерактивные рекоммендеры не используют сами по себе, а сочетают, например, с коллаборативной фильтрацией. На практике себя хорошо показали линейный UCB и Tompson Sampling + Probablistic Matrix Factorization.
Чтобы построить рекоммендеры, нужен дата-сет. Там должны быть фичи, описывающие нашу модель. Есть два вида фич, о которых стоит знать: implicit и explicit feedback. Implicit feedback – это когда пользователь делает скроллы, склики и так далее. А explicit feedback – это когда они явно ставят лайки или дизлайки. Что опасного кроется во втором? Explicit feedback – рейтинги, лайки, которые ставят пользователи, – сильно шумит. При этом implicit feedback – скроллы, клики, просмотры – работает гораздо круче для рекомендаций. Он менее шумный, потому что никак не связан с предпочтениями пользователей, не зависит от их настроения и понимания, что такое «оцени от нуля до пяти». Чтобы не решать проблемы смещений, можно работать с implicit фидбеком. Понятно, что только с ним работать нельзя, и нужно учитывать оба сигнала. Поэтому есть модели, которые позволяют учитывать и тот, и другой подход.
У Spotify есть рекоммендер музыки. В качестве основы они используют коллаборативную фильтрацию: следят за предпочтениями пользователей, кластеризуют их между собой. Они также делают проекцию интента пользователя в данный момент времени на пространство музыкальных интересов пользователей. Кроме того, Spotify использует NLP-методы (natural language processing) для анализа плейлистов. Он собирает данные о всех плейлистах пользователей и говорит, что ваш плейлист – это такой же текстовый документ. Здесь можно использовать классические для NLP инструменты, когда мы просто работаем с текстом и извлекаем, например, топики для плейлиста. Помимо этого они используют глубокое обучение, чтобы извлекать контент. Они берут трек, пропускают его через глубокую нейросеть, извлекают фичи, которые ценят пользователи в песне. Это content based рекоммендер, сделанный на основе deep learning. Так компания собирает данные о самих айтемах.
Что нам дарит open source? Есть два уровня технических предложений: технические библиотеки и системы.
Наиболее мощные библиотеки – Spark MLLib, RankSys, LensKit. Есть Waffles, библиотека на С++.
Есть более высокоуровневые инструменты, чем одна библиотека, – machine learning серверы. Самым интересным мне кажется PredictionIO.
Тем, кто хочет заниматься рекоммендерами, стоит прочитать «Recommendation System Handbook, 2nd Edition», где речь идет о разных подходах к построению рекоммендеров, алгоритмах и их практическом применении.
С чего все началось
К EPAM обратился известный британский модный дом, которому нужен был интерактивный рекоммендер для e-commerce портала. До этого EPAM представил имплементацию обычного offline рекоммендера. Теперь заказчик хотел узнавать о желаниях пользователей в реальном времени, а не постфактум. Чтобы решить эту задачу, мы изучили портал заказчика и выбрали следующие элементы в работу:
1. Главная страница
Это страница, где пользователь – даже если он еще не залогинился – видит каталог. Какой бы пользователь не пришел – уже зарегистрированный или новый – нам нужно его заинтересовать с самого начала. Для этого мы предложили концепцию с категориальными фильтрами: вы можете выбирать из предложенного набора категорий по принципу «я хотел бы больше это, нежели это», а не точно указывать («хочу именно это»). В этом и отличие от обычного поиска: пользователю дается инструмент, с помощью которого можно быстро обнаружить что-то интересное ему, даже если человек четко не сформулировал свои пожелания. Здесь интерактивные рекоммендеры уместны, так как нам нужно понять, ищет пользователь что-то новое или уже привычное. Эту задачу можно решить с помощью группы алгоритмов «многорукие бандиты» (multi-armed bandits).
2. Основной каталог
Традиционно пользователь может отбирать элементы из каталога с помощью фильтров по цвету, размеру и другим критериям. Если нам уже известны предпочтения человека, можно сразу представить каталог с наиболее релевантным для него подбором элементов. Алгоритмы, использующие информацию о пользователе, – это demographic based рекоммендеры.
Но тут возникает вопрос: что, если мы не знаем о контексте пользователя и не понимаем, чем определяется его выбор? Здесь нам помогут context based рекоммендеры. Более того, мы можем строить рекомендации интерактивно: например, если пользователь начинает скроллить экран, мы понимаем, что он продолжает искать, и подбрасываем ему новые продукты. Мы учитываем, что варианты, которые уже были представлены, оказались неинтересны. Здесь можно снова использовать модель multi-armed bandits.
3. Корзина
Если пользователь определился с выбором, можно попробовать заинтересовать его чем-то еще. Это реализуется с помощью линейки товаров вида «С этим также покупают». Для построения этой линейки используются learning to rank или sequential pattern mining алгоритмы.
4. Подарки
Основная проблема этого раздела в том, что подарки пользователь выбирает не себе. Нужно использовать информацию не о вас, а о том, кому достанется подарок. Тут не помогут ни знания о пользователе, ни коллаборативная фильтрация. Нам нужна информация, с кем дружит пользователь, есть ли у него дети и т.д. Здесь нам поможет demographic based рекоммендер, использующий информацию об отношениях пользователя, и sequential pattern mining.
Конверсия
Когда мы определились с задачами и инструментами, нужно понять, какие инструменты принесут наибольшую конверсию. Рассмотрим пример apparel stores. В Германии провели исследование о поведении пользователей во время онлайн-шопинга, при покупке одежды. В нем участвовало около 50 женщин. Им нужно было подобрать себе образ на встречу выпускников в ресторане. В рамках эксперимента они могли купить любое количество вещей, но потратить не больше 300 евро. Основываясь на данных о доходах, возрасте, привычке следить за модой, исследователи разделили участниц на несколько групп и начали собирать статистику.
Результаты исследования показали: чаще всего участницы использовали фильтры и поиск (71%). Среди фильтров активнее всего пользовались фильтром по цвету, далее идут фильтры по размеру и стоимости. Если говорить о рекоммендерах, то чаще всего использовали коллаборативную фильтрацию, а другие инструменты – гораздо реже.
При этом основную долю конверсии сгенерировал поиск (62%) и навигация с помощью фильтров (83%). Это значит, что, если пользователь ищет, он знает, чего хочет, и не нужно мешать ему. Коллаборативная фильтрация, рекомендация «надеть с этим», style guide дали меньше 50% конверсии. Это объясняется тем, что люди не хотят выглядеть как другие и стремятся подчеркнуть свою индивидуальность. С другой стороны, 50% – это неплохо, и при уместном использовании такие рекоммендеры могут быть очень эффективными. Например, раздел Occasion/event принес 100% конверсию.
Отдельно стоит отметить, что разделы Top seller’s list, New in, сезонные предложения принесли 0% конверсии. Это не стоит воспринимать как абсолютные показатели, так как нужно помнить о задаче: женщины выбирали не повседневную одежду, кроме того, выбор не зависел от сезона. Значит, в других условиях такие рекомендации могли сработать.
Теория. Типы рекомендательных систем
Кратко рассмотрим, как можно реализовать те или иные рекоммендеры.
1. Коллаборативная фильтрация
Идея этого подхода в том, что есть пользователи и элементы, которые люди оценивают несколькими способами: ставят лайки, оценки и т.д. На их основе строится матрица оценок пользователей. Но поскольку далеко не все ставят лайки, эта матрица разряженная, и задача заключается в регрессии недостающих оценок.
Есть два типа алгоритмов, которые реализуют эту концепцию:
• Neighborhood-based (Memory-Based) методы. Они помогают восстановить оценки явно, при этом храня полную матрицу отношений, которая, как правило, очень большая. Главный недостаток этих методов – низкая эффективность из-за того, что они не дают действительно персонализованную оценку.
Примеры алгоритмов: User-Based Filtering (UBCF), Item-Based Filtering (IBCF), Slope-One.
• Model Based методы. Их идея в том, чтобы определить скрытые факторы (интересы пользователей), на основе которых люди ставят оценки.
Примеры алгоритмов:
o Matrix Factorization (MF): Singular Value Decomposition (SVD, SVD++, timeSVD++, MSVD), Non-Negative MF (ALS), Factorization Machines, Probabilistic Matrix Factorization (PMF)
o RBM (Restricted Bolzman Machines).
o Incremental CF via Co-clustering (COCL, ECOCL)
o Probabilistic Principle Component Analysis (pPCA), Probabilistic Latent Semantic Analysis (pLSA), Latent Dirichlet Allocation (LDA) and etc.
Достоинство коллаборативной фильтрации заключается в том, что для построения рекомендаций не нужны знания о предметной области вообще, не требуется знать деталей об айтемах и пользователях. Они кластеризуются между собой в режиме самоорганизации.
Недостаток: проблема холодного старта (cold start problem): если появляется новый пользователь или айтем, они не будут рекомендованы, так как нет информации и оценок.
2. Сontent based рекоммендеры
Чтобы решить проблему холодного старта и рекомендовать новые элементы, коллаборативную фильтрацию иногда интегрируют с content based рекоммендерами. При этом подходе нужно описать все айтемы. Но их свойства не всегда получается собрать по юридическим или техническим причинам.
3. Demographic based рекоммендеры
Если холодный старт произошел для пользователя, то нам нужно собрать о нем информацию и описать его.
Общая проблема группы методов, связанных с коллаборативной фильтрацией, заключается в следующем. Они работают хорошо, только если речь идет о большом количестве данных. Эти методы подходят для рекомендации объектов, выбор которых зависит от вкуса пользователя, например, для рекомендации фильмов или музыки. Но этот подход не эффективен, когда нужно рекомендовать такие сложные объекты, как машины, недвижимость и т.д. В этом случае можно использовать knowledge based recommenders.
4. Knowledge based рекоммендеры
Здесь требуются эксперты, которые оценивают предлагаемые объекты и описывают критерии, по которым их выбирают пользователи. Считается, что эти эксперты знают все: к какому типу пользователей вы принадлежите, сколько хотите потратить, какими характеристиками должны обладать товары, чтобы привлечь вас. Таким образом решается проблема и для пользователей, и для айтемов. Но тут есть недостаток: эксперты – очень дорогие и ненадежные люди, поэтому не всегда возможно описать все правила для вашего каталога.
5. Сontext-aware рекоммендеры
Оффлайн оценки экспертов могут быть ошибочны и неполны, так как на этапе оценки неизвестен контекст, в котором пользователь выбирает айтем. Контекст со временем может меняться. Например, вы все время смотрели фильмы ужасов, но вдруг начали искать мультики, потому что ваши дети захотели их посмотреть. С точки зрения рекоммендера вы сошли с ума, и он продолжит рекомендовать вам фильмы ужасов, предполагая, что однажды вы придете в себя. Что с вами случилось на самом деле? Изменился контекст, и на это нужно реагировать, что и позволяют сделать context-aware рекоммендеры.
Чтобы эффективно делать контекстные рекомендации, нужно решать задачу Change Point Detection в смысле временных рядов. Когда поведение пользователя резко меняется, это значит, что резко изменился контекст. Есть различные методы, которые позволяют нам учитывать контекст: factorization machines, Byesian Probablistic Tensor Factorization.
6. Интерактивные рекоммендеры
Их главная цель – в режиме текущей сессии пользователя выбрать варианты, наиболее релевантные его пожеланиям.
Жизненный пример
Вспомним себя в баре. Вы хотите отлично провести время. Видите краны от пива и начинаете выбирать, что выпить. В этот момент вы решаете задачу: пить незнакомое (exploration) или знакомое (exploitation) пиво? Это Exploration vs. Exploitation problem. Ее должны решать интерактивные рекоммендеры. Подходы к решению этой проблемы:
1. Active learning (AL) позволяет осуществить редукцию пространства поиска
2. Multi-armed bandits (MAB) algorithms: E-greedy, UCB, LinUCB, Tomson Sampling, Active Thompson Sampling (ATS)
3. Markov Decision Process (MDP)/Reinforcement Learning (RL)
4. Hybrid scoring approaches could be considered – models composition used.
Основные виды MAB алгоритмов
1. E-greedy – это просто частотная оценка: мы выбираем ту или иную руку нашего бандита на основе частоты ее использования. Вспоминаем краны в баре: чем чаще мы используем тот или иной кран, тем больше мы любим это пиво.
2. Upper Confidence Bound (UCB) – стремимся оценить удовольствие, которое получит пользователь от выбора определенного айтема. Задача – достаточно точно оценить это удовольствие для каждой из ручек. Для новых айтемов в этом алгоритме присваивается потенциально максимальная оценка вознаграждения. Каждый раз, когда бандиту дергают ручку, актуализируется оценка вознаграждения. Этот алгоритм будет всегда больше склоняться к exploration, нежели к exploitation, и не может поддерживать вычисление слишком большого числа рук.
3. Tomson Sampling (TS) может представлять каждую из рук бандита в виде вероятностного распределения и каждый раз просто пересчитывать вероятность при взаимодействии с каждой из рук. Каждая рука выбирается на основе ее истории, и наша цель – минимизировать общее разочарование, которое может испытывать пользователь при взаимодействии с MAB.
Как правило, интерактивные рекоммендеры не используют сами по себе, а сочетают, например, с коллаборативной фильтрацией. На практике себя хорошо показали линейный UCB и Tompson Sampling + Probablistic Matrix Factorization.
Немного о фичах
Чтобы построить рекоммендеры, нужен дата-сет. Там должны быть фичи, описывающие нашу модель. Есть два вида фич, о которых стоит знать: implicit и explicit feedback. Implicit feedback – это когда пользователь делает скроллы, склики и так далее. А explicit feedback – это когда они явно ставят лайки или дизлайки. Что опасного кроется во втором? Explicit feedback – рейтинги, лайки, которые ставят пользователи, – сильно шумит. При этом implicit feedback – скроллы, клики, просмотры – работает гораздо круче для рекомендаций. Он менее шумный, потому что никак не связан с предпочтениями пользователей, не зависит от их настроения и понимания, что такое «оцени от нуля до пяти». Чтобы не решать проблемы смещений, можно работать с implicit фидбеком. Понятно, что только с ним работать нельзя, и нужно учитывать оба сигнала. Поэтому есть модели, которые позволяют учитывать и тот, и другой подход.
Пример рекоммендера у Spotify
У Spotify есть рекоммендер музыки. В качестве основы они используют коллаборативную фильтрацию: следят за предпочтениями пользователей, кластеризуют их между собой. Они также делают проекцию интента пользователя в данный момент времени на пространство музыкальных интересов пользователей. Кроме того, Spotify использует NLP-методы (natural language processing) для анализа плейлистов. Он собирает данные о всех плейлистах пользователей и говорит, что ваш плейлист – это такой же текстовый документ. Здесь можно использовать классические для NLP инструменты, когда мы просто работаем с текстом и извлекаем, например, топики для плейлиста. Помимо этого они используют глубокое обучение, чтобы извлекать контент. Они берут трек, пропускают его через глубокую нейросеть, извлекают фичи, которые ценят пользователи в песне. Это content based рекоммендер, сделанный на основе deep learning. Так компания собирает данные о самих айтемах.
Библиотеки и системы для создания рекоммендеров
Что нам дарит open source? Есть два уровня технических предложений: технические библиотеки и системы.
Наиболее мощные библиотеки – Spark MLLib, RankSys, LensKit. Есть Waffles, библиотека на С++.
Есть более высокоуровневые инструменты, чем одна библиотека, – machine learning серверы. Самым интересным мне кажется PredictionIO.
Тем, кто хочет заниматься рекоммендерами, стоит прочитать «Recommendation System Handbook, 2nd Edition», где речь идет о разных подходах к построению рекоммендеров, алгоритмах и их практическом применении.