
При создании продуктов на основе машинного обучения возникают ситуации, которых хотелось бы избежать. В этом тексте я разбираю восемь проблем, с которыми сталкивался в своей работе.
Мой опыт связан с моделями кредитного скоринга и предсказательными системами для промышленных компаний. Текст поможет разработчиками и дата-сайнтистам строить полезные модели, а менеджерам не допускать грубых ошибок в проекте.

Этот текст не призван прорекламировать какую-нибудь компанию. Он основан на практике анализа данных в компании ООО "Ромашка", которая никогда не существовала и не будет существовать. Под "мы" я подразумеваю команду из себя и моих воображаемых друзей. Все сервисы, которые мы создавали, делались для конкретного клиента и не могут быть проданы или переданы иным лицам.
Какие модели и для чего?
Пусть предсказательная модель — это алгоритм, который строит прогнозы и позволяет автоматически принимать полезное для бизнеса решение на основе исторических данных.
Я не рассматриваю:
- разовые исследования данных, которые не идут в продакшн;
- системы, которые мониторят что-нибудь (например, кликабельность объявлений), но сами не принимают решений;
- алгоритмы ради алгоритмов, т.е. не приносящие прямой пользы для бизнеса (например, искусственный интеллект, который учит виртуальных человечков ходить).
Я буду говорить об алгоритмах обучения с учителем, т.е. таких, которые "увидели" много примеров пар (X,Y), и теперь могут для любого X сделать оценку Y. X — это информация, известная на момент прогноза (например, заполненная клиентом заявка на кредит). Y — это заранее неизвестная информация, необходимая для принятия решения (например, будет ли клиент своевременно платить по кредиту). Само решение может приниматься каким-то простым алгоритмом вне модели (например, одобрять кредит, если предсказанная вероятность неплатежа не выше 15%).
Аналитик, создающий модель, как правило, опирается на метрики качества прогноза, например, среднюю ошибку (MAE) или долю верных ответов (accuracy). Такие метрики позволяют быстро понять, какая из двух моделей предсказывает точнее (и нужно ли, скажем, заменять логистическую регрессию на нейросеть). Но на главный вопрос, а насколько модель полезна, они дают ответ далеко не всегда. Например, модель для кредитного скоринга очень легко может достигнуть точности 98% на данных, в которых 98% клиентов "хорошие", называя "хорошими" всех подряд.
С точки зрения предпринимателя или менеджера очевидно, какая модель полезная: которая приносит деньги. Если за счёт внедрения новой скоринговой модели за следующий год удастся отказать 3000 клиентам, которые бы принесли суммарный убыток 50 миллионов рублей, и одобрить 5000 новых клиентов, которые принесут суммарную прибыль 10 миллионов рублей, то модель явно хороша. На этапе разработки модели, конечно, вряд ли вы точно знаете эти суммы (да и потом — далеко не факт). Но чем скорее, точнее и честнее вы оцените экономическую пользу от проекта, тем лучше.
Проблемы
Достаточно часто построение вроде бы хорошей предсказательной модели не приводит к ожидаемому успеху: она не внедряется, или внедряется с большой задержкой, или начинает нормально работать только после десятков релизов, или перестаёт нормально работать через несколько месяцев после внедрения, или не работает вообще никак… При этом вроде бы все потрудились на славу: аналитик выжал из данных максимальную предсказательную силу, разработчик создал среду, в которой модель работает молниеносно и никогда не падает, а менеджер приложил все усилия, чтобы первые двое смогли завершить работу вовремя. Так почему же они попали в неприятность?
1. Модель вообще не нужна
Мы как-то строили модель, предсказывающую крепость пива после дображивания (на самом деле, это было не пиво и вообще не алкоголь, но суть похожа). Задача ставилась так: понять, как параметры, задаваемые в начале брожения, влияют на крепость финального пива, и научиться лучше управлять ей. Задача казалась весёлой и перспективной, и мы потратили не одну сотню человеко-часов на неё, прежде чем выяснили, что на самом-то деле финальная крепость не так уж и важна заказчику. Например, когда пиво получается 7.6% вместо требуемых 8%, он просто смешивает его с более крепким, чтобы добиться нужного градуса. То есть, даже если бы мы построили идеальную модель, это принесло бы прибыли примерно нисколько.
Эта ситуация звучит довольно глупо, но на самом деле случается сплошь и рядом. Руководители инициируют machine learning проекты, "потому что интересно", или просто чтобы быть в тренде. Осознание, что это не очень-то и нужно, может прийти далеко не сразу, а потом долго отвергаться. Мало кому приятно признаваться, что время было потрачено впустую. К счастью, есть относительно простой способ избегать таких провалов: перед началом любого проекта оценивать эффект от идеальной предсказательной модели. Если бы вам предложили оракула, который в точности знает будущее наперёд, сколько бы были бы готовы за него заплатить? Если потери от брака и так составляют небольшую сумму, то, возможно, строить сложную систему для минимизации доли брака нет необходимости.
Как-то раз команде по кредитному скорингу предложили новый источник данных: чеки крупной сети продуктовых магазинов. Это выглядело очень заманчиво: "скажи мне, что ты покупаешь, и я скажу, кто ты". Но вскоре оказалось, что идентифицировать личность покупателя было возможно, только если он использовал карту лояльности. Доля таких покупателей оказалась невелика, а в пересечении с клиентами банка они составляли меньше 5% от входящих заявок на кредиты. Более того, это были лучшие 5%: почти все заявки одобрялись, и доля "дефолтных" среди них была близка к нулю. Даже если бы мы смогли отказывать все "плохие" заявки среди них, это сократило бы кредитные потери на совсем небольшую сумму. Она бы вряд ли окупила затраты на построение модели, её внедрение, и интеграцию с базой данных магазинов в реальном времени. Поэтому с чеками поигрались недельку, и передали их в отдел вторичных продаж: там от таких данных будет больше пользы.
Зато пивную модель мы всё-таки достроили и внедрили. Оказалось, что она не даёт экономии на сокращении брака, но зато позволяет снизить трудозатраты за счёт автоматизации части процесса. Но поняли мы это только после долгих дискуссий с заказчиком. И, если честно, нам просто повезло.
2. Модель откровенно слабая
Даже если идеальная модель способна принести большую пользу, не факт, что вам удастся к ней приблизиться. В X может просто не быть информации, релевантной для предсказания Y. Конечно, вы редко можете быть до конца уверены, что вытащили из X все полезные признаки. Наибольшее улучшение прогноза обычно приносит feature engineering, который может длиться месяцами. Но можно работать итеративно: брейншторм — создание признаков — обучение прототипа модели — тестирование прототипа.
В самом начале проекта можно собраться большой компанией и провести мозговой штурм, придумывая разнообразные признаки. По моему опыту, самый сильный признак часто давал половину той точности, которая в итоге получалась у полной модели. Для скоринга это оказалась текущая кредитная нагрузка клиента, для пива — крепость предыдущей партии того же сорта. Если после пары циклов найти хорошие признаки не удалось, и качество модели близко к нулю, возможно, проект лучше свернуть, либо срочно отправиться искать дополнительные данные.
Важно, что тестировать нужно не только точность прогноза, но и качество решений, принимаемых на его основе. Не всегда возможно измерить пользу от модели "оффлайн" (в тестовой среде). Но вы можете придумывать метрики, которые хоть как-то приближают вас к оценке денежного эффекта. Например, если менеджеру по кредитным рискам нужно одобрение не менее 50% заявок (иначе сорвётся план продаж), то вы можете оценивать долю "плохих" клиентов среди 50% лучших с точки зрения модели. Она будет примерно пропорциональна тем убыткам, которые несёт банк из-за невозврата кредитов. Такую метрику можно посчитать сразу же после создания первого прототипа модели. Если грубая оценка выгоды от его внедрения не покрывает даже ваши собственные трудозатраты, то стоит задуматься: а можем ли мы вообще получить хороший прогноз?
3. Модель невозможно внедрить
Бывает, что созданная аналитиками модель демонстрирует хорошие меры как точности прогноза, так и экономического эффекта. Но когда начинается её внедрение в продакшн, оказывается, что необходимые для прогноза данные недоступны в реальном времени. Иногда бывает, что это настоящие данные "из будущего". Например, при прогнозе крепости пива важным фактором является измерение его плотности после первого этапа брожения, но применять прогноз мы хотим в начале этого этапа. Если бы мы не обсудили с заказчиком точную природу этого признака, мы бы построили бесполезную модель.
Ещё более неприятно может быть, если на момент прогноза данные доступны, но по техническим причинам подгрузить их в модель не получается. В прошлом году мы работали над моделью, рекомендующей оптимальный канал взаимодействия с клиентом, вовремя не внёсшим очередной платёж по кредиту. Должнику может звонить живой оператор (но это не очень дёшево) или робот (дёшево, но не так эффективно, и бесит клиентов), или можно не звонить вообще и надеяться, что клиент и так заплатит сегодня-завтра. Одним из сильных факторов оказались результаты звонков за вчерашний день. Но оказалось, что их использовать нельзя: логи звонков перекладываются в базу данных раз в сутки, ночью, а план звонков на завтра формируется сегодня, когда известны данные за вчера. То есть данные о звонках доступны с лагом в два дня до применения прогноза.
На моей практике несколько раз случалось, что модели с хорошей точностью откладывались в долгий ящик или сразу выкидывались из-за недоступности данных в реальном времени. Иногда приходилось переделывать их с нуля, пытаясь заменить признаки "из будущего" какими-то другими. Чтобы такого не происходило, первый же небесполезный прототип модели стоит тестировать на потоке данных, максимально приближенном к реальному. Может показаться, что это приведёт к дополнительным затратам на разработку тестовой среды. Но, скорее всего, перед запуском модели "в бою" её придётся создавать в любом случае. Начинайте строить инфраструктуру для тестирования модели как можно раньше, и, возможно, вы вовремя узнаете много интересных деталей.
4. Модель очень трудно внедрить
Если модель основана на данных "из будущего", с этим вряд ли что-то можно поделать. Но часто бывает так, что даже с доступными данными внедрение модели даётся нелегко. Настолько нелегко, что внедрение затягивается на неопределённый срок из-за нехватки трудовых ресурсов на это. Что же так долго делают разработчики, если модель уже создана?
Скорее всего, они переписывают весь код с нуля. Причины на это могут быть совершенно разные. Возможно, вся их система написана на java, и они не готовы пользоваться моделью на python, ибо интеграция двух разных сред доставит им даже больше головной боли, чем переписывание кода. Или требования к производительности так высоки, что весь код для продакшна может быть написан только на C++, иначе модель будет работать слишком медленно. Или предобработку признаков для обучения модели вы сделали с использованием SQL, выгружая их из базы данных, но в бою никакой базы данных нет, а данные будут приходить в виде json-запроса.
Если модель создавалась в одном языке (скорее всего, в python), а применяться будет в другом, возникает болезненная проблема её переноса. Есть готовые решения, например, формат PMML, но их применимость оставляет желать лучшего. Если это линейная модель, достаточно сохранить в текстовом файле вектор коэффициентов. В случае нейросети или решающих деревьев коэффициентов потребуется больше, и в их записи и чтении будет проще ошибиться. Ещё сложнее сериализовать полностью непараметрические модели, в частности, сложные байесовские. Но даже это может быть просто по сравнению с созданием признаков, код для которого может быть совсем уж произвольным. Даже безобидная функция log() в разных языках программирования может означать разные вещи, что уж говорить о коде для работы с картинками или текстами!
Даже если с языком программирования всё в порядке, вопросы производительности и различия в формате данных в учении и в бою остаются. Ещё один возможный источник проблем: аналитик при создании модели активно пользовался инструментарием для работы с большими таблицами данных, но в бою прогноз необходимо делать для каждого наблюдения по отдельности. Многие действия, совершаемые с матрицей n*m, с матрицей 1*m проделывать неэффективно или вообще бессмысленно. Поэтому аналитику полезно с самого начала проекта готовиться принимать данные в нужном формате и уметь работать с наблюдениями поштучно. Мораль та же, что и в предыдущем разделе: начинайте тестировать весь пайплайн как можно раньше!
Разработчикам и админам продуктивной системы полезно с начала проекта задуматься о том, в какой среде будет работать модель. В их силах сделать так, чтобы код data scientist'a мог выполняться в ней с минимумом изменений. Если вы внедряете предсказательные модели регулярно, стоит один раз создать (или поискать у внешних провайдеров) платформу, обеспечивающую управление нагрузкой, отказоустойчивость, и передачу данных. На ней любую новую модель можно запустить в виде сервиса. Если же сделать так невозможно или нерентабельно, полезно будет заранее обсудить с разработчиком модели имеющиеся ограничения. Быть может, вы избавите его и себя от долгих часов ненужной работы.
5. При внедрении происходят глупые ошибки
За пару недель до моего прихода в банк там запустили в бой модель кредитного риска от стороннего поставщика. На ретроспективной выборке, которую прислал поставщик, модель показала себя хорошо, выделив очень плохих клиентов среди одобренных. Поэтому, когда прогнозы начали поступать к нам в реальном времени, мы немедленно стали применять их. Через несколько дней кто-то заметил, что отказываем мы больше заявок, чем ожидалось. Потом — что распределение приходящих прогнозов непохоже на то, что было в тестовой выборке. Начали разбираться, и поняли, что прогнозы приходят с противоположным знаком. Мы получали не вероятность того, что заёмщик плохой, а вероятность того, что он хороший. Несколько дней мы отказывали в кредите не худшим, а лучшим клиентам!
Такие нарушения бизнес-логики чаще всего происходят не в самой модели, а или при подготовке признаков, или, чаще всего, при применении прогноза. Если они менее очевидны, чем ошибка в знаке, то их можно не находить очень долго. Всё это время модель будет работать хуже, чем ожидалось, без видимых причин. Стандартный способ предупредить это — делать юнит-тесты для любого кусочка стратегии принятия решений. Кроме этого, нужно тестировать всю систему принятия решений (модель + её окружение) целиком (да-да, я повторяю это уже три раздела подряд). Но это не спасёт от всех бед: проблема может быть не в коде, а в данных. Чтобы смягчить такие риски, серьёзные нововведения можно запускать не на всём потоке данных (в нашем случае, заявок на кредиты), а на небольшой, но репрезентативной его доле (например, на случайно выбранных 10% заявок). A/B тесты— это вообще полезно. А если ваши модели отвечают за действительно важные решения, такие тесты могут идти в большом количестве и подолгу.
6. Модель нестабильная
Бывает, что модель прошла все тесты, и была внедрена без единой ошибки. Вы смотрите на первые решения, которые она приняла, и они кажутся вам осмысленными. Они не идеальны — 17 партия пива получилась слабоватой, а 14 и 23 — очень крепкими, но в целом всё неплохо. Проходит неделя-другая, вы продолжаете смотреть на результаты A/B теста, и понимаете, что слишком крепких партий чересчур много. Обсуждаете это с заказчиком, и он объясняет, что недавно заменил резервуары для кипячения сусла, и это могло повысить уровень растворения хмеля. Ваш внутренний математик возмущается "Да как же так! Вы мне дали обучающую выборку, не репрезентативную генеральной совокупности! Это обман!". Но вы берёте себя в руки, и замечаете, что в обучающей выборке (последние три года) средняя концентрация растворенного хмеля не была стабильной. Да, сейчас она выше, чем когда-либо, но резкие скачки и падения были и раньше. Но вашу модель они ничему не научили.
Другой пример: доверие сообщества финансистов к статистическим методам было сильно подорвано после кризиса 2007 года. Тогда обвалился американский ипотечный рынок, потянув за собой всю мировую экономику. Модели, которые тогда использовались для оценки кредитных рисков, не предполагали, что все заёмщики могут одновременно перестать платить, потому что в их обучающей выборке не было таких событий. Но разбирающийся в предмете человек мог бы мысленно продолжить имеющиеся тренды и предугадать такой исход.
Бывает, что поток данных, к которым вы применяете модель, стационарен, т.е. не меняет своих статистических свойств со временем. Тогда самые популярные методы машинного обучения, нейросетки и градиентный бустинг над решающими деревьями, работают хорошо. Оба этих метода основаны на интерполяции обучающих данных: нейронки — логистическими кривыми, бустинг — кусочно-постоянными функциями. И те, и другие очень плохо справляются с задачей экстраполяции — предсказания для X, лежащих за пределами обучающей выборки (точнее, её выпуклой оболочки).
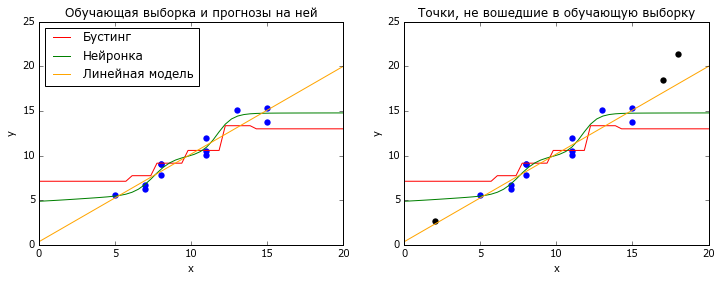
# coding: utf-8
# настраиваем всё, что нужно настроить
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rc
rc('font', family='Verdana')
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.linear_model import LinearRegression
# генерируем данные
np.random.seed(2)
n = 15
x_all = np.random.randint(20,size=(n,1))
y_all = x_all.ravel() + 10 * 0.1 + np.random.normal(size=n)
fltr = ((x_all<=15)&(x_all>=5))
x_train = x_all[fltr.ravel(),:]
y_train = y_all[fltr.ravel()]
x_new = x_all[~fltr.ravel(),:]
y_new = y_all[~fltr.ravel()]
x_plot = np.linspace(0, 20)
# обучаем модели
m1 = GradientBoostingRegressor(
n_estimators=10,
max_depth = 3,
random_state=42
).fit(x_train, y_train)
m2 = MLPRegressor(
hidden_layer_sizes=(10),
activation = 'logistic',
random_state = 42,
learning_rate_init = 1e-1,
solver = 'lbfgs',
alpha = 0.1
).fit(x_train, y_train)
m3 = LinearRegression().fit(x_train, y_train)
# Отрисовываем графики
plt.figure(figsize=(12,4))
title = {1:'Обучающая выборка и прогнозы на ней',
2:'Точки, не вошедшие в обучающую выборку'}
for i in [1,2]:
plt.subplot(1,2,i)
plt.scatter(x_train.ravel(), y_train, lw=0, s=40)
plt.xlim([0, 20])
plt.ylim([0, 25])
plt.plot(x_plot, m1.predict(x_plot[:,np.newaxis]), color = 'red')
plt.plot(x_plot, m2.predict(x_plot[:,np.newaxis]), color = 'green')
plt.plot(x_plot, m3.predict(x_plot[:,np.newaxis]), color = 'orange')
plt.xlabel('x')
plt.ylabel('y')
plt.title(title[i])
if i == 1:
plt.legend(['Бустинг', 'Нейронка', 'Линейная модель'],
loc = 'upper left')
if i == 2:
plt.scatter(x_new.ravel(), y_new, lw=0, s=40, color = 'black')
plt.show()Некоторые более простые модели (в том числе линейные) экстраполируют лучше. Но как понять, что они вам нужны? На помощь приходит кросс-валидация (перекрёстная проверка), но не классическая, в которой все данные перемешаны случайным образом, а что-нибудь типа TimeSeriesSplit из sklearn. В ней модель обучается на всех данных до момента t, а тестируется на данных после этого момента, и так для нескольких разных t. Хорошее качество на таких тестах даёт надежду, что модель может прогнозировать будущее, даже если оно несколько отличается от прошлого.
Иногда внедрения в модель сильных зависимостей, типа линейных, оказывается достаточно, чтобы она хорошо адаптировалась к изменениям в процессе. Если это нежелательно или этого недостаточно, можно подумать о более универсальных способах придания адаптивности. Проще всего калибровать модель на константу: вычитать из прогноза его среднюю ошибку за предыдущие n наблюдений. Если же дело не только в аддитивной константе, при обучении модели можно перевзвесить наблюдения (например, по принципу экспоненциального сглаживания). Это поможет модели сосредоточить внимание на самом недавнем прошлом.
Даже если вам кажется, что модель просто обязана быть стабильной, полезно будет завести автоматический мониторинг. Он мог бы описывать динамику предсказываемого значения, самого прогноза, основных факторов модели, и всевозможных метрик качества. Если модель действительно хороша, то она с вами надолго. Поэтому лучше один раз потрудиться над шаблоном, чем каждый месяц проверять перформанс модели вручную.
7. Обучающая выборка действительно не репрезентативна
Бывает, что источником нерепрезентативности выборки являются не изменения во времени, а особенности процесса, породившего данные. У банка, где я работал, раньше существовала политика: нельзя выдавать кредиты людям, у которых платежи по текущим долгам превышают 40% дохода. С одной стороны, это разумно, ибо высокая кредитная нагрузка часто приводит к банкротству, особенно в кризисные времена. С другой стороны, и доход, и платежи по кредитам мы можем оценивать лишь приближённо. Возможно, у части наших несложившихся клиентов дела на самом деле были куда лучше. Да и в любом случае, специалист, который зарабатывает 200 тысяч в месяц, и 100 из них отдаёт в счёт ипотеки, может быть перспективным клиентом. Отказать такому в кредитной карте — потеря прибыли. Можно было бы надеяться, что модель будет хорошо ранжировать клиентов даже с очень высокой кредитной нагрузкой… Но это не точно, ведь в обучающей выборке нет ни одного такого!
Мне повезло, что за три года до моего прихода коллеги ввели простое, хотя и страшноватое правило: примерно 1% случайно отобранных заявок на кредитки одобрять в обход почти всех политик. Этот 1% приносил банку убытки, но позволял получать репрезентативные данные, на которых можно обучать и тестировать любые модели. Поэтому я смог доказать, что даже среди вроде бы очень закредитованных людей можно найти хороших клиентов. В результате мы начали выдавать кредитки людям с оценкой кредитной нагрузки от 40% до 90%, но с более жёстким порогом отсечения по предсказанной вероятности дефолта.
Если бы подобного потока чистых данных не было, то убедить менеджмент, что модель нормально ранжирует людей с нагрузкой больше 40%, было бы сложно. Наверное, я бы обучил её на выборке с нагрузкой 0-20%, и показал бы, что на тестовых данных с нагрузкой 20-40% модель способна принять адекватные решения. Но узенькая струйка нефильтрованных данных всё-таки очень полезна, и, если цена ошибки не очень высока, лучше её иметь. Подобный совет даёт и Мартин Цинкевич, ML-разработчик из Гугла, в своём руководстве по машинному обучению. Например, при фильтрации электронной почты 0.1% писем, отмеченных алгоритмом как спам, можно всё-таки показывать пользователю. Это позволит отследить и исправить ошибки алгоритма.
8. Прогноз используется неэффективно
Как правило, решение, принимаемое на основе прогноза модели, является лишь небольшой частью какого-то бизнес-процесса, и может взаимодействовать с ним причудливым образом. Например, большая часть заявок на кредитки, одобренных автоматическим алгоритмом, должна также получить одобрение живого андеррайтера, прежде чем карта будет выдана. Когда мы начали одобрять заявки с высокой кредитной нагрузкой, андеррайтеры продолжили их отказывать. Возможно, они не сразу узнали об изменениях, или просто решили не брать на себя ответственность за непривычных клиентов. Нам пришлось передавать кредитным специалистам метки типа "не отказывать данному клиенту по причине высокой нагрузки", чтобы они начали одобрять такие заявки. Но пока мы выявили эту проблему, придумали решение и внедрили его, прошло много времени, в течение которого банк недополучал прибыль. Мораль: с другими участниками бизнес-процесса нужно договариваться заранее.
Иногда, чтобы зарезать пользу от внедрения или обновления модели, другое подразделение не нужно. Достаточно плохо договориться о границах допустимого с собственным менеджером. Возможно, он готов начать одобрять клиентов, выбранных моделью, но только если у них не более одного активного кредита, никогда не было просрочек, несколько успешно закрытых кредитов, и есть двойное подтверждение дохода. Если почти весь описанный сегмент мы и так уже одобряем, то модель мало что изменит.
Впрочем, при грамотном использовании модели человеческий фактор может быть полезен. Допустим, мы разработали модель, подсказывающую сотруднику магазина одежды, что ещё можно предложить клиенту, на основе уже имеющегося заказа. Такая модель может очень эффективно пользоваться большими данными (особенно если магазинов — целая сеть). Но частью релевантной информации, например, о внешнем виде клиентов, модель не обладает. Поэтому точность угадывания ровно-того-наряда-что-хочет-клиент остаётся невысокой. Однако можно очень просто объединить искусственный интеллект с человеческим: модель подсказывает продавцу три предмета, а он выбирает из них самое подходящее. Если правильно объяснить задачу всем продавцам, можно прийти к успеху.
Заключение
Я прошёлся по некоторым из основных провалов, с которыми сталкивался при создании и встраивании в бизнес предсказательных моделей. Чаще всего это проблемы не математического, а организационного характера: модель вообще не нужна, или построена по кривой выборке, или есть сложности со встраиванием её в имеющиеся процессы и системы. Снизить риск таких провалов можно, если придерживаться простых принципов:
- Используйте разумные и измеримые меры точности прогноза и экономического эффекта
- Начиная с первого прототипа, тестируйтесь на упорядоченном по времени потоке данных
- Тестируйте весь процесс, от подготовки данных до принятия решения, а не только прогноз
Надеюсь, кому-то этот текст поможет получше присмотреться к своему проекту и избежать глупых ошибок.
Высоких вам ROC-AUC и Эр-квадратов!
Комментарии (5)

comratvlad
12.09.2017 14:55+6Бывает весело, когда заказчику охота «крутую нейронную сеть» для специфичной задачи, но убедить его потратиться на сбор данных можно, только предоставив работающий прототип (создание которого невозможно без сбора данных (сбор которых невозможен без работающего прототипа (...))).


McSimEst
12.09.2017 19:44+2Спасибо за статью! Очень нам не хватало такой информации при прохождении курса от Яндекса и МФТИ. Такой опыт, как описан здесь, сильно повышает понимание, как выглядеть будет процесс на практике. Это необходимые для целостного понимания пазлы!
Tremere
13.09.2017 10:20+2хороший материал, с теми или иными моментами сталкивался в работе, но без такой методички конечно терял много времени
fireSparrow
Я не занимаюсь ML, поэтому, возможно, вопрос глупый.
Имеет ли смысл брать этот 1% не путём случайной выборки, а оценивать, насколько заявка похожа на типичные, и выбирать самые нетипичные? Или это даст какое-то смещение результатов?
cointegrated Автор
Вопрос на самом деле очень хороший :)
Бывают ситуации, когда так делать можно — можно погуглить «importance sampling» и «active learning». Но в тех задачах, с которыми я сталкивался, обычно не было универсальной, очевидной, да и вообще качественной меры сходства между заявками.
Имеет смысл вероятностный подход: более «подходящие» заявки имеют более высокий шанс попасть в лотерею (скажем, 3%), менее интересные — скажем, 0.1%. Но ненулевой шанс стоит давать почти всем, потому что потом можно будет перевзвесить наблюдения и получить репрезентативную (стратифицированную) выборку, на которой можно оценить что угодно.