

Использование подходящих словарей во время проведения тестирования на проникновение во многом определяет успех подбора учетных данных. В данной публикации я расскажу, какие современные инструменты можно использовать для создания словарей, их оптимизации для конкретного случая и как не тратить время на перебор тысяч заведомо ложных комбинации.
Инструменты
crunch
Пожалуй, один из самых известных инструментов для быстрого создания словарей. Он по умолчанию входит в популярный дистрибутив для проведения пентеста Kali Linux.
Инструмент работает в нескольких режимах:
Создание словаря, состоящего из перечисленных символов, например чисел
crunch 4 5 1234567890 -o all_numbers_from_4_to_5.txt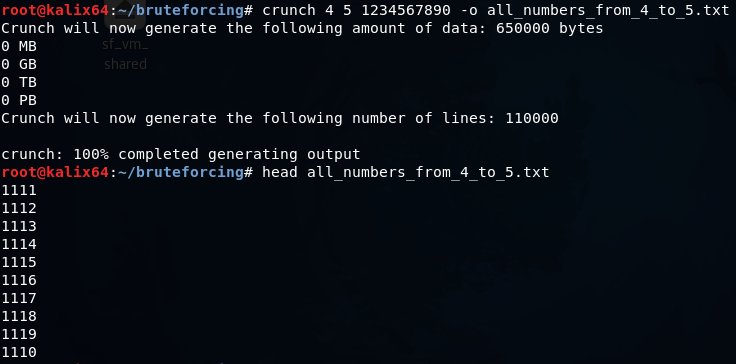
Создается словарь длиной от четырех до пяти цифр.
Создание словаря по шаблону
crunch 10 10 qwe RTY 123 \#\@ -t P^@@,ord%% -o Password_template.txt

Сперва указывается длина пароля — 10 символов. Затем перечисляются наборы символов: буквы в нижнем регистре, буквы в верхнем регистре, цифры и спецсимволы. Ключ -t задает шаблон, где
- ^ — спецсимволы
- @ — буквы в нижнем регистре
- , — буквы в верхнем регистре
- % — цифры
И третий режим работы crunch — перестановки.
crunch 1 1 -p Alex Company Position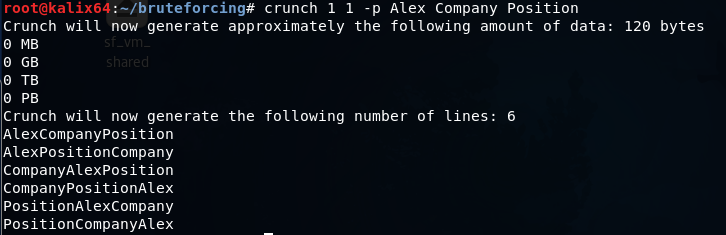
Словарь состоит из всех возможных комбинаций слов Alex, Company и Position.
Подробнее изучить инструмент можно через стандартные man страницы, они достаточно подробные.
maskprocessor
Иногда требуется указать не только наборы под конкретный тип символов, а вообще свой набор, включающий и буквы, и цифры, и спецсимволы. В этом случае можно воспользоваться утилитой maskprocessor от брутфорсера hashcat. Скачать ее можно с официального гитхаба hashcat.
Вы можете задать до четырех собственных наборов символов и использовать готовые наборы
?l = abcdefghijklmnopqrstuvwxyz
?u = ABCDEFGHIJKLMNOPQRSTUVWXYZ
?d = 0123456789
?s = !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
?a = ?l?u?d?s
?b = 0x00 - 0xffПример использования
mp64.bin -1 Pp -2 \@\#\$ ?1assw?2r?d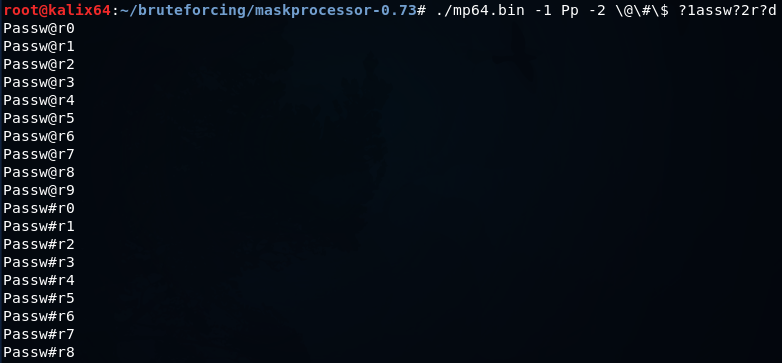
Или можно задать набор из цифр, но добавить к нему еще несколько спецсимволов так
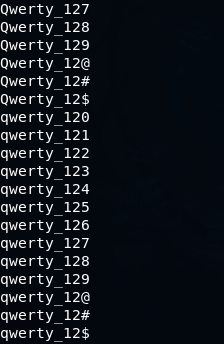
mp64.bin -1 Qq -2 ?d\@\#\$ ?1werty_12?2Получаем такой результат
John the Ripper
Популярный брутфорсер John the Ripper (JTR) тоже позволяет генерировать словари на основе правил. Делается это при помощи ключа --rules, а сами правила описываются в файле john.conf
Вот так выглядит стандартное правило, используемое для взлома NTLM хэша
[List.Rules:NT]
:
-c T0Q
-c T1QT[z0]
-c T2QT[z0]T[z1]
-c T3QT[z0]T[z1]T[z2]
-c T4QT[z0]T[z1]T[z2]T[z3]
-c T5QT[z0]T[z1]T[z2]T[z3]T[z4]
-c T6QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]
-c T7QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]
-c T8QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]
-c T9QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]
-c TAQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]
-c TBQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA]
-c TCQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA]T[zB]
-c TDQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA]T[zB]T[zC]В первой строчке сказано, что нужно изменить регистр символа на нулевой позиции (T0), символ Q позволяет не допустить дубликатов в результирующем словаре. Во второй строке символ на первой позиции меняет свой регистр, затем скобки задают препроцессор, чтобы были сгенерированы пароли и с измененным нулевым символом и так далее.
Предположим, вы успешно провели брутфорс LM хэша и получили значение QWERTY123, так как для LM регистр не важен.
Но для авторизации вам нужно провести брутфорс NTLM хэша, где регистр имеет значение. Воспользовавшись правилом, описанным выше, можно получить следующий словарь
john -w:QWERTY123.dict --stdout --rules:NT
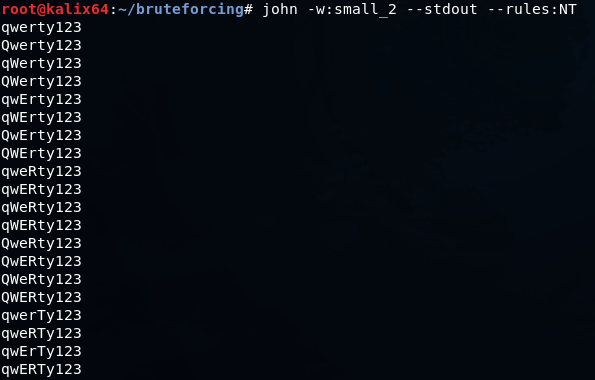
JTR по умолчанию содержит множество готовых правил, но можно написать и свои, либо взять за основу уже написанное и скорректировать под текущую ситуацию.
Подробно про синтаксис правил можно почитать здесь.
hashcat-tools
Еще одним полезным инструментом является набор утилит от популярного брутфорсера hashcat.
Скачать их можно с официального сайта.
Рассмотрим некоторые их них. Описания всех утилит на английском языке можно найти тут.
combinanor.bin — позволяет генерировать словарь из слов, входящих в два других словаря.
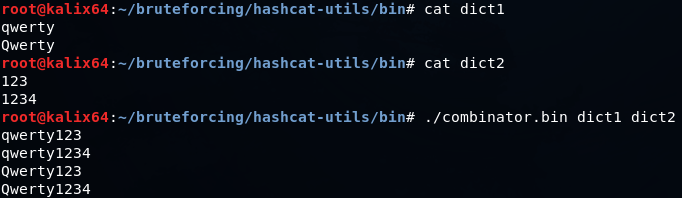
combinanor3.bin делает то же самое, но на вход принимает три файла, вместо двух.
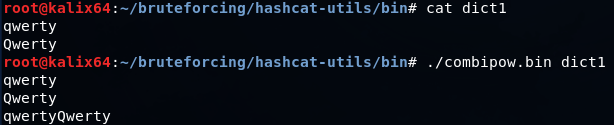
combipow.bin — создает все возможные комбинации из слов, перечисленных в файле (похоже на ключ -p в crunch)
cutb.bin — обрезает слова в словаре до указанной длины. Можно указывать смещение (offset)

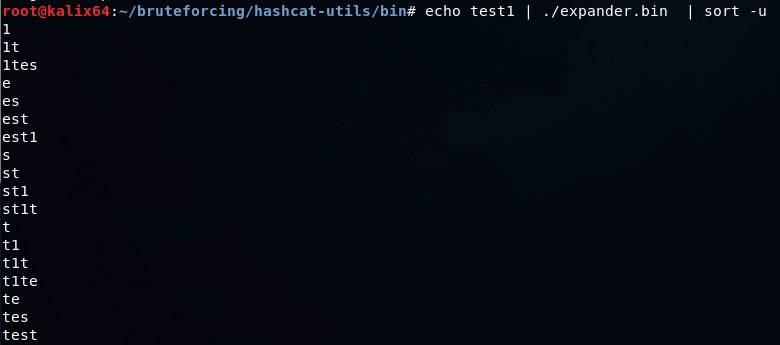
expander.bin — получает на ввод слова, разбирает их на символы, комбинирует и отправляет в STDOUT
permute.bin — создает словарь, который используется hashcat при атаке типа Permutation attack. Перед использованием словарь нужно пропустить через утилиту prepare.
gate.bin — разбивает словарь на несколько частей для параллельной обработки несколькими ядрами или несколькими машинами. В примере ниже мы разбиваем стандартный словарь JTR на две части. В первую часть попадают слова под номером 0, 2, 4, 6,…. Во вторую 1, 3, 5, 7,…
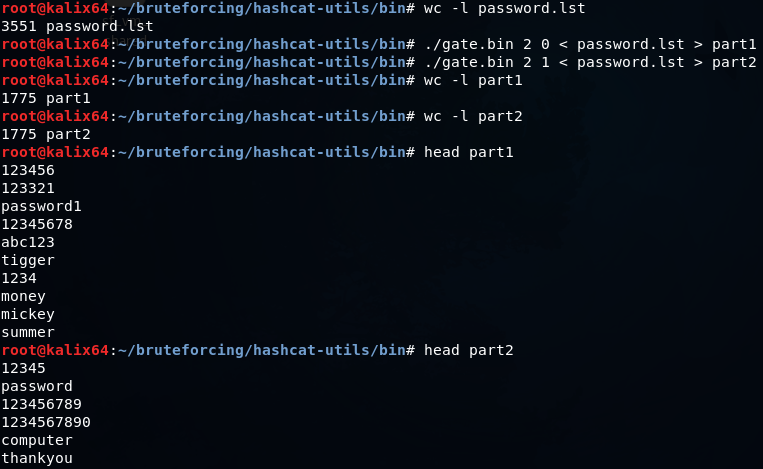
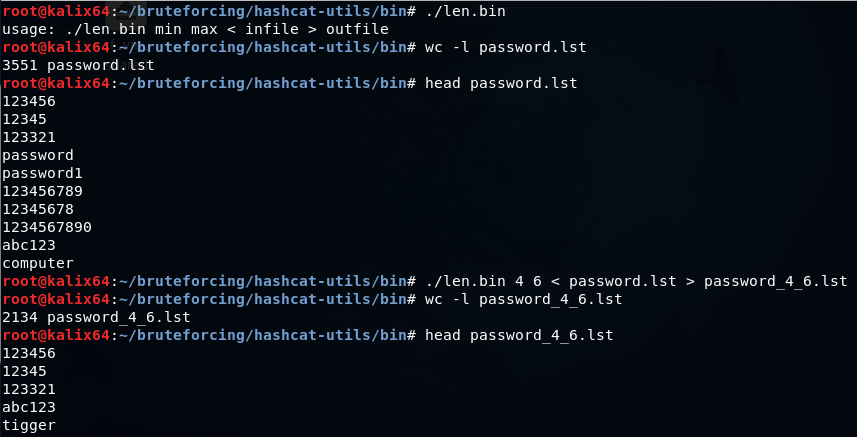
len.bin — оставляет в словаре только слова определенной длины от min до max
mli2.bin — объединяет два словаря.
req-include.bin — крайне полезный инструмент, который убирает из словаря все, что не подходит под заданные правила. Например, вы знаете, что по парольной политике в пароле обязательно присутствует буква в верхнем регистре, цифра и спецсимвол.

Число выбрано исходя из таблицы

Если таким образом нормализовать известный словарь rockyou, то можно сократить его размер в 270 раз! и не тратить ресурсы на заведомо ложные комбинации.

req-exclude.bin делает то же самое, что req-include, но с точностью до наоборот.
rli.bin — эта утилита удаляет значения из первого словаря, если они встречаются во втором. Полезно использовать, если вы создаете один словарь из нескольких.
Когда под рукой нет утилит
Может оказаться так, что воспользоваться набором hashcat-utils или crunch нет возможности, а нужно срочно создать словарь или нормализовать его. Некоторые алгоритмы довольно сложны в реализации, но базовые операции можно выполнить просто в командной строке.
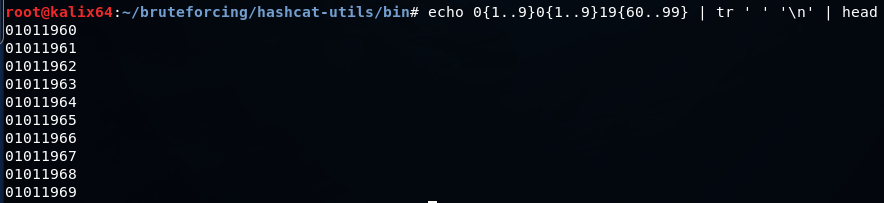
Простой словарь с датами можно создать серией подобных команд
echo 0{1..9}0{1..9}19{60..99} | tr ' ' '\n' >> dates
Если нужно разбить словарь на части для параллельной обработки, можно воспользоваться командой split
split -d -l 1000 password.lst splitted_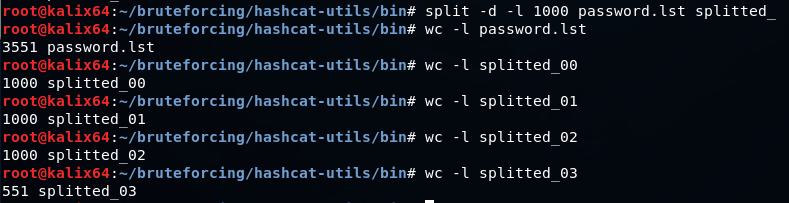
Быстро объединить два словаря можно так
cat dict1 dict2 > combined_dict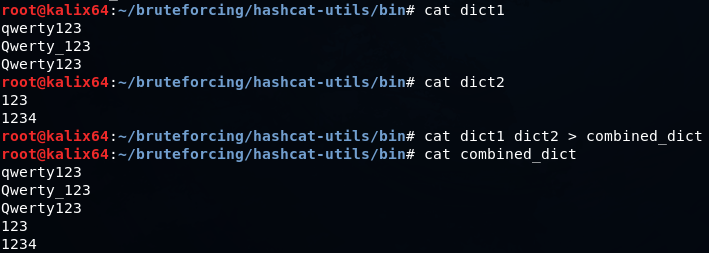
Чтобы сделать заглавной первую или последнюю буквы в каждом слове, нужно выполнить, соответственно, команды
sed 's/^./\u&/' dict_file
sed 's/.$/\u&/' dict_fileДля перевода регистра в нижний нужно заметить «u» на «l»
Дописать что-то в начало каждого слова из словаря можно так
sed 's/^./word/' dict_fileА так можно дописать слово в конец
sed 's/.$/word/' dict_file
Следующей командой можно добавить в начало число от 0 до 99 к каждому слову в словаре
for i in $(cat dict_file) ; do seq -f %02.0f$i 0 99 ; done > numbers_dict_file
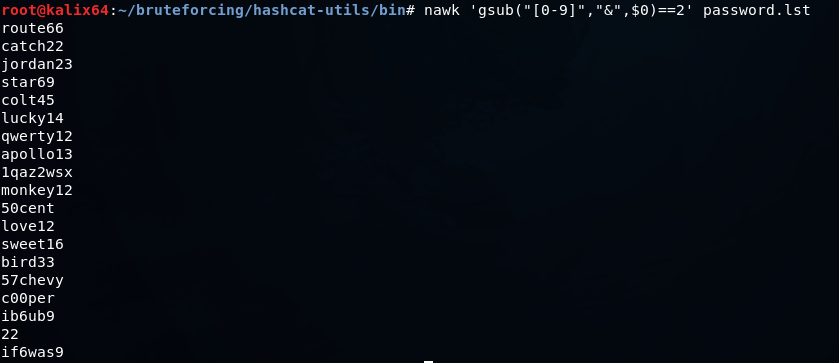
Можно очистить словарь от значений, в которых не присутствует хотя бы 2 числа так
nawk 'gsub("[0-9]","&",$0)==2' password.lstПолучаем
Это лишь некоторые примеры. Можно писать более сложные обработки на Python и других скриптовых языках. Но всегда нужно помнить, что создание качественного словаря и его нормализация под целевой протокол — важный этап при проведении тестирования на проникновение.