

В скором времени ни одна компания не сможет обойтись без Data Engineer
Давайте рассмотрим типичный рабочий день data scientist-а:
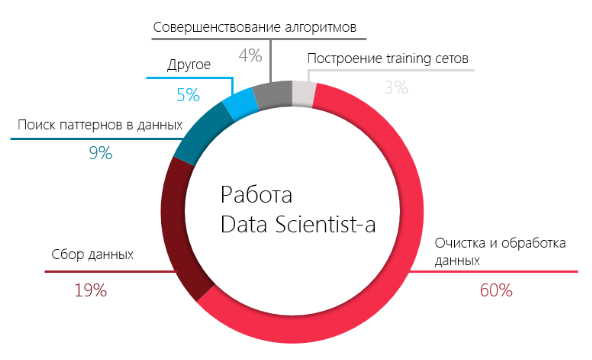
Получается, что около 80% своего времени data scientist тратит на сбор данных, их предобработку и очистку — процессы, которые напрямую не связаны с главной его обязанностью: поиском инсайтов и паттернов в данных. Конечно, подготовка данных требует высшего уровня мастерства, но это не data science, это не то, зачем тысячи людей сегодня стремятся попасть в эту отрасль.
Именно поэтому компаниям следует освобождать data scientist-ов от наименее приятной для них части работы и делегировать предобработку данных data инженеру, наличие которого в data science команде, во-первых, позволит data scientist-ам заниматься тем, что они по-настоящему любят — построением моделей, что в свою очередь предотвратит их потенциальный уход из компании и привлечет наиболее талантливых. А во-вторых, увеличится эффективность data scientist-ов, поскольку они будут проводить в разы больше времени в поисках ценных инсайтов, что естественно принесет пользу бизнесу.
Также не стоит забывать и о принципе garbage in — garbage out: если моделям на вход подаются некачественные данные, то бессмысленно ждать от них адекватного результата. Следовательно, для того, чтобы максимизировать эффективность data science отдела компании необходимо нанимать инженеров данных, которые, в отличии от data scientist-ов, специализируются на организации процесса сбора, очистки и предобработки данных.
Вот что по этому поводу думает Big Data Engineer в Mail.ru Group, Антон Пилипенко: «На текущий момент большинство компаний научились хранить большое количество данных и строить на их основе разного рода модели. Однако, зачастую, вопросам эффективного хранения и обработки накопленных данных не уделяют достаточного внимания. Как следствие постоянно то тут, то там возникают вопросы о сайзинге, масштабировании приложений, потоковой и near-realtime обработке. Как показывает опыт, деление на Data Science и Data Engineer специалистов появилось не на пустом месте. Data Engineer — в первую очередь инженер, который хорошо понимает, что и зачем он делает, как оно устроено „под капотом“ и какая архитектура „не взлетит“.
Data Engineer-у легче обратить на себя внимание работодателя
Ни для кого не секрет, что сегодня профессия data scientist становится все более и более популярной, тысячи студентов по всему миру хотят получить работу в данной отрасли, а многие зрелые специалисты из других областей меняют свою специализацию в пользу data science. Причина проста — высокие зарплаты, решение аналитических задач и растущий неудовлетворенный спрос на аналитиков данных. Все это может вылиться в большое количество неквалифицированных кадров, которые пришли в трендовую область, не обладая достаточными знаниями программирования и статистики, при этом аналитикам, действительно заинтересованным в построении моделей, будет сложно выделиться среди этой массы.
Теперь с этой же точки зрения взглянем на data engineer-ов, у которых ситуация обратная: с первого взгляда обязанности data engineer-а выглядят менее интересными, чем у data scientist-а (что естественно не так), поэтому сотни резюме не летят на почту работодателям, находящимся в поисках хорошего инженера данных, хотя зарплаты data engineer-ов и data scientist-ов находятся на примерно одном уровне (90 и 91 тыс. долларов в год соответственно в США). Людям нужно видеть результат своей работы, а лучше всего — удовлетворенность клиента и бизнеса. Легче всего получить удовольствие от своей работы, узнав о сотнях новых клиентов за счет построения модели по созданию персонализированных предложений, чем от очищенных данных, поэтому большинству трудно оценить значимость data engineer-ов, которые не меньше data scientist-ов вносят вклад в итоговый результат.
Data Engineer-ы практически незаменимы в компании
Сегодня почти повсеместно все чаще возникает вопрос о том, будут ли в скором времени те или иные профессии заменены искусственным интеллектом. Касаемо data engineering многие высказывают мнение о том, что процесс сбора, обработки и очистки данных является рутинным и может быть легко автоматизирован, поэтому профессия является бесперспективной. Однако это мнение неверно, поскольку подготовка данных к анализу является настоящим искусством, и подход, который сработал с одним датасетом, может совершенно не подойти другому набору данных. Машины пока не способны самостоятельно подстраиваться под данные, в ближайшем будущем их настройкой все еще будет заниматься человек — data engineer.
Более того, в обязанности data engineer-а входит еще более комплексная, чем предобработка данных, задача по построению стабильных пайплайнов, делающих данные доступными для всех пользователей внутри компании. Лишь благодаря инженеру данных data scientist-ы обеспечены качественными датасетами в удобном им виде и в правильное время, в этом и заключается незаменимость data engineer-а. То, как сильно он влияет на бизнес-процессы и успех компании можно увидеть невооруженным взглядом.
С этой точки зрения согласны и профессионалы: Senior Software Engineer в Agoda, Артем Москвин говорит: „Data engineer – это тот, кто делает всю ту бигдату, про которую вы слышали, возможной. Работу с данными можно условно разделить на 2 части: инжиниринг и исследования. Однако для того, чтобы сделать возможной вторую, нужно хорошо поработать над первой“, а по мнению Data Engineer-а в E-Contenta, Андрея Сутугина: „В мире анализа данных не все так радужно и красиво, как может показаться после решения “титаника» на kaggle. Для того, чтобы приступить непосредственно к самому анализу, необходимо проделать титаническую работу, но для того, чтобы «поставить на поток» сбор и трансформацию данных, требуется еще больше усилий. К сожалению, в мире «big data» нет «серебряных пуль», и обилие инструментов и фреймворков может вскружить голову”.
Data Engineering не требует глубокого знания статистики и теории вероятностей
Многие люди, которые хотят построить карьеру в IT, после 1-2 курсов технических университетов с зубодробительными курсами математического анализа и теории вероятностей опускают руки, считая, что без продвинутого математического бэкграунда они не смогут найти работу, даже несмотря на то, что пишут неплохой код. В связи с этим data engineering — это отличная возможность начать карьеру в сфере работы с данными для людей, которые имеют лишь базовое представление о машинном обучении, но при этом интересуются разработкой баз данных и их управлением. Таким образом, такая работа, конечно, больше подойдет software engineer-ам, архитекторам и администраторам баз данных.
По мнению Николая Маркова, Senior Data Science Engineer-а в Aligned Research Group LLC: «Зачем заниматься Data Engineering-ом? Я считаю, что это логичный путь в сферу анализа данных для людей, которые умеют программировать и имеют опыт работы в индустрии разработки. Дело в том, что люди крайне редко бывают глубоко заинтересованы и в том, и в другом — одновременно серьезное знание математики и глубокий computer science в одном человеке не встречается практически никогда. Поэтому давайте оставим математикам то, что они делают лучше всего — исследования, модели и графики, а сами подумаем, что нужно сделать для того, чтобы из аналитической идеи получился готовый работающий продукт?».
Newprolab 13 ноября запускает программу Data Engineer, на которой участники в течение 6-ти недель будут создавать стабильные пайплайны обработки данных от сбора до их визуализации, изучать и оттачивать навыки работы со следующими инструментами: Divolte, Kafka, ELK, Spark, Luigi, Sqoop, Druid, ClickHouse, Superset, Storm, которые будут объединять в один большой и стабильный пайплайн. Подробнее о программе Data Engineer.
Комментарии (11)

TexxTyRe
14.09.2017 23:56+3Вода. Муть. И реклама.
elena_newprolab Автор
15.09.2017 16:13+1а у вас какая должность? чем занимаетесь?
TexxTyRe
15.09.2017 18:15-1Не вижу здесь связи между моими занятиями и этой статьей. Но пусть я буду для вас тот, кто интересуется Data Science и ML. В статье одна лишь абстракция и приукрашивание данной профессии, на деле это математика и куча ее разделов, которые я устану здесь перечислять.
elena_newprolab Автор
17.09.2017 12:18Если задача собрать пайплайн из различных инструментов, правильно их отконфигурировать, то в деятельности Data Engineer доля математики всё-таки не такая большая в сравнении с data scientist.
Интересоваться и каждый день работать, как это делают авторы приведенных выше цитат, — немного разные вещи. Мы разделяем мнение Data Engineer'ов, с которыми работаем и у кого брали интервью, остаемся при нем. Ну, а вы, как и любой другой читатель, вправе иметь свое мнение, мы не настаиваем.

mezastel
15.09.2017 12:54Data Engineering не требует глубокого знания статистики и теории вероятностей
Я видел в свое время результат творчества исследователей без образования в области статистики и теорвера. И самое грустное что им очень легко затеряться в технологической компании, где и остальные-то не понимают как делать исследования. Результатом этого было одно — фееричная бушлитность и непригодность всех исследований.epee
15.09.2017 16:55так судя из написанного DE исследовательской частью и не занимается, поэтому и не требуется глубоких знаний статистики и теорвера
mezastel
15.09.2017 18:14-1А, то есть это просто люди который пишут скрипт перегона данных из одной базы в другую? Ну тогда да, наверное им это и не надо. Другой вопрос, нужно ли выделать на это отдельную роль?
roryorangepants
15.09.2017 16:54А к чьим обязанностям относится feature engineering — data engineer'а или data scientist'а?
elena_newprolab Автор
15.09.2017 16:55На самом деле, и те, и другие могут заниматься feature engineering, зависит от конкретной компании и распределения обязанностей, но чаще всё-таки этим занимается data scientist.
leshqow
Хотел написать возможно ли джуниору попасть в эту область без опыта работы, но потом увидел это
и сам ответил на свой вопросelena_newprolab Автор
У нас есть рассрочка, если вам такой вариант подходит, да и кредит никто не отменял. Есть участники программ, кто берет кредит. Проблем с его закрытием после успешного прохождения программы не было.