
Предлагаю переработанный вариант своего выступления на конференции разработчиков, в котором я решил отвлечься от фреймворков-технологий и порассуждать на тему сопоставимости в разработке.

Под катом слайды с пояснением.
В детстве наши восприятия особенно обманчивы. Помню, прогуливались мимо башни с часами, сильно удивился, когда отец сказал, что длина стрелки равна пяти шагам. То есть как это? Тогда казалось, что все штуки, окружающие нас, примерно одинакового размера. Тогда и мультики такие были, как Винни Пух. Действительно, сейчас трудно представить сову, размером с медведя.

Потом, когда мы подрастаем, чтоб развить любовь к естественным наукам, нам дарят книжку про планеты. Можете поверить, такого рода книги существуют на всех языках почти во всех странах.

Глядя на обложку, можно подумать, что все планеты примерно сопоставимого размера и если и отличаются друг от друга, то на проценты, а не в разы или даже в несколько порядков.
А теперь давайте посмотрим, как сопоставимы по размеру планеты в нашей системе в самом деле.

Дела обстоят так, что в едином масштабе невозможно изобразить все планеты вместе так, чтоб хотя бы был виден красный цвет Марса и было понятно, что Юпитер в 300+ раз больше Земли, при этом в 1000 раз меньше Солнца. На этой схеме не учтены расстояния от Солнца, если Землю оставить на таком расстоянии, то для Урана явно не хватит экрана, а Нептун уже будет в другой комнате.
Кстати, древние греки не знали про размеры планет, но у их была легенда, как Зевс (Юпитер по-новому) соревновался со ВСЕМИ остальными богами. Они перетягивали золотую цепь и Зевс выиграл, то есть он сильнее суммарно всех вместе, но не всесильный. Что гораздо позже физики и астрономы показали. Похоже, это и были те гиганты, на плечах которых стоял Ньютон.
Детская привычка видеть перед собой примерно сопоставимые вещи, приносит неоправданные, мягко говоря, результаты. В реальной жизни мы видим, как так же распределены население и площади стран, население городов, астрономические объекты, траты населения, доход по отраслям и многое другое. Для нас теперь самое важное, что так же распределены почти все наблюдения в нашей работе. Теперь рассмотрим пример с котиками. Найдем в инстаграме изображения с тэгом #catphoto.

Инстаграм после загрузки обрабатывает изображения, приводя их к размеру 640X640 пикселей, сжимая в формат jpeg. Кажется, после такого все изображения должны занимать примерно одинаковый размер, и если и будут отличаться, то не в разы, а на несколько процентов. А теперь, посмотрим на размер фотографий.

Видно, что размер самого большого файла отличается от самого меньшего в 2,5 раза. Еще «драматичнее» становится ситуация, когда начинаем смотреть файлы разного типа, но, например, принадлежащих одному проекту. Вот как выглядит профайлер загрузки страницы очень богатой компании.
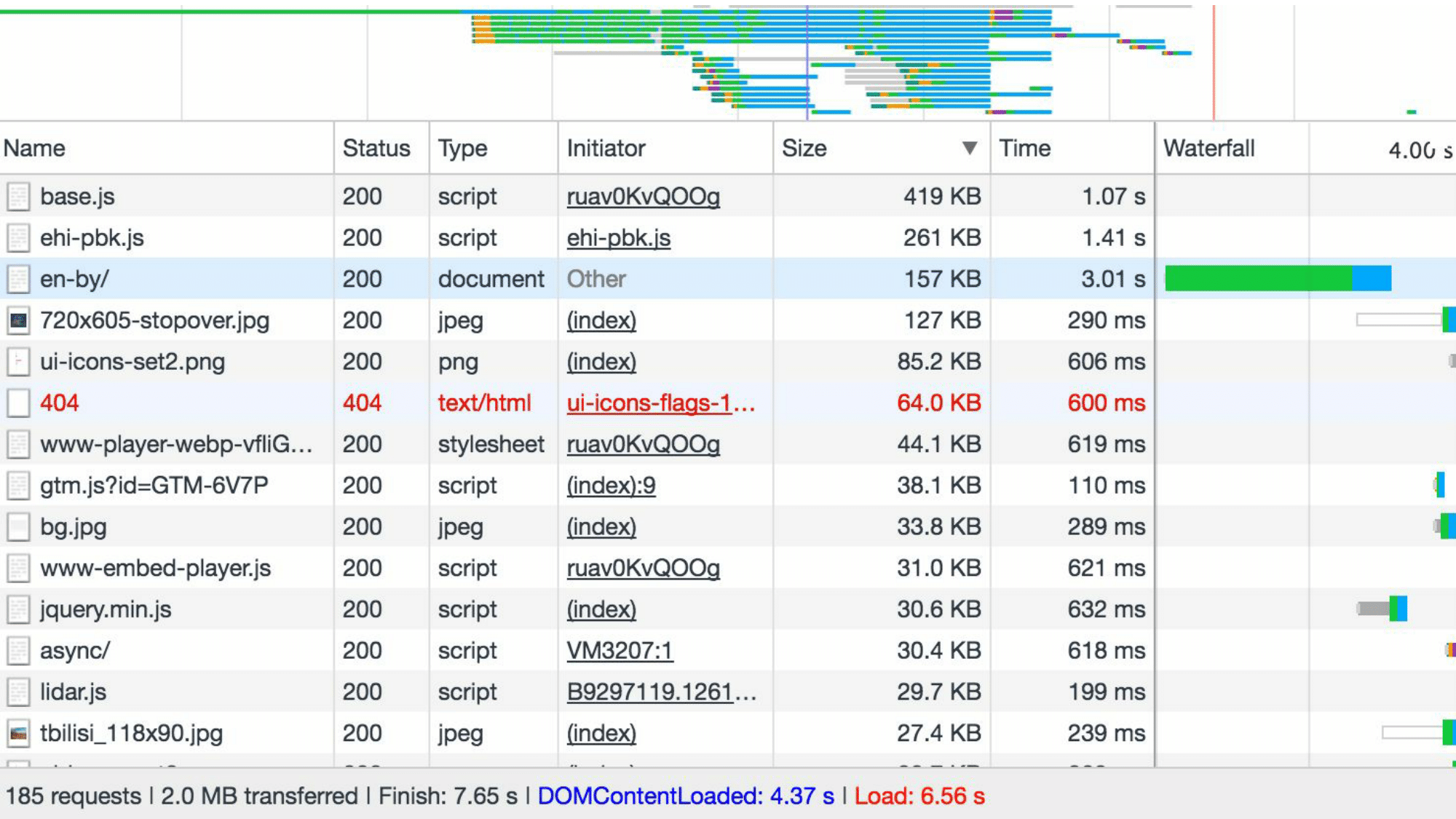
Здесь загруженные файлы отсортированы по размеру. И сразу можно заметить, что 5 файлов занимают больше размера, чем 180 оставшихся. Если вам кажется, что это особенный сайт, то попробуйте очистить кэш, загрузить любой сайт и убедиться, что 5% самых больших файлов занимает больше места, чем 50% самых маленьких практически для любого сайта.
Хотите расскажу про средний (условно ваш) проект. На проекте есть база данных, в которой 30 – 90 таблиц, в двух самых больших больше строк, чем в половине самых маленьких. В репозитории лежат тысячи файлов кода, 1% самых больших из которых занимает больше места, чем 50% самых маленьких. Есть сайт который грузится несколько секунд, и за это время подгружается 80 – 300 файлов, из которых опять 1% самых больших занимает больше места, чем 50% самых маленьких. Так же могу рассказать про файлы на вашем компьютере. В папке Downloads (если она только регулярно не чистится) два самых больших файла занимают больше места, чем половина самых маленьких.
Однако, привычки наблюдения за окружающим миром и центральная предельная теорема теории вероятностей подводятся к тому, что при работе с очень большим числом наблюдений усредненный результат не должен сойтись к какому-то значению не сильно отличающемуся от среднего. Про это даже комиксы есть, к сожалению с опущеными необходимыми условиями.

Долгие наблюдения за измеримыми данными в телекоммуникациях и разработке привели меня к выводу, что встретить нормальное распределение почти нереально. Что же бывает в самом деле.

Наблюдаемые значения имеют выбросы. Это такие наблюдения, которые явно отклоняются от общей массы (тыц). Если вспомнить статистику, то при обработке результатов эксперимента, такие значения можно отбросить. В нашем случае они слишком важны и учитывать их обязательно.
Также эти наблюдения имеют значительную асимметрию и тяжелый хвост.
Существует множество объяснений этому явлению, среди которых есть и противоречащие друг другу, так что на их выяснение не будем тратить время. Просто очевидно, что у рассматриваемых распределений нет дисперсии, а значит условие ЦПТ не выполняется.
Не воспринимайте картинку слишком серьезно. Давайте лучше сразу подумаем, что с этим можно сделать. А что делать понятно: оптимизировать. То есть надо оптимизировать размер файлов, количество вызовов функций, время загрузки страницы, то есть все то, что забирает ресурсы, которым есть лучшее применение.
И теперь самое время рассказать про ключевую и самую знаменитую фразу из информатики, связанную с оптимизацией.

Я специально нашел изображение молодого Дональда Кнута, так как эта фраза была сказана аж в далеком 1974 году и имеет уже столько толкований, что даже сам Кнут неоднократно давал объяснения (как забавно: не метод в интерфейсе, а целая фраза обладает полиморфизмом). Да, преждевременная оптимизация корень всех бед. В 97% случаев она ни к чему не приведет. Но оставшиеся 3% никак нельзя сбрасывать со счетов.
В те давние времена, когда не было удобных профайлеров, IDE, айфонов, браузеров, интернета, персональных компьютеров, ООП, а суммарная мощность всех компов в мире равнялась нескольким современным смартфонам. Еще тогда в статье-дискуссии с Дейкстрой про применимость GO TO в структурном программировании, Кнут заметил, что в абсолютном большинстве случаев оптимизация не приносит результата, а даже наоборот отбирает время и делает код менее читаемым.
А теперь более наглядный пример. Но мы уже вооружены технологиями и можем посмотреть, какую оптимизацию сайту предлагает автоматическая утилита PageSpeed от Google (я выбрал компанию sinopec group, как одну из самых богатых в мире, на сайт должно быть).

Итак, общий размер сайта при загрузке 2.1М, а утилита находит, что можно сжать стили, от чего выиграть 9.2К. Что составляет меньше полпроцента. Согласитесь, такую оптимизацию не заметит конечный пользователь, а также проблем с загрузкой и местом в транспортировки это не создаст.
А что же тогда оптимизировать? Давайте, для разнообразия, рассмотрим другую страницу профайлера.

Тут уже не размер файлов, а производительность. То есть сколько времени было потрачено на выполнение функций в приложении за короткий промежуток времени, а затем отсортировано по этому самому времени. В картинку вместилось 12 функций из 600+, с учетом крупного шрифта. Как всегда один процент самых затратных функций потребляет больше ресурсов, чем 50% самых незатратных. Так вот, при оптимизации производительности, видя такую таблицу никогда не скрольте ее дальше – не оптимизировав что-нибудь из первых 3 – 8 функций видимого улучшения не настанет. Такая простая истина, но из-за непонимание её тратится много времени.
А теперь второй важный момент, связанный с этим, который уже не так очевиден. Я к этому выводу пришел наблюдая несколько лет разные статистические данные в АйТи, подобно тому как Климент Аркадьевич Тимирязев наблюдал годами за листиками в колбах. Вам не удастся свести реальный проект к состоянию, когда распределение ресурсов будет нормальным или хоть сопоставимым. Ни за какое число итераций оптимизации. Хорошо оптимизированный проект все равно будет иметь распределение времени выполнения функций таким, как показано на картинке выше, только суммарно время их выполнения после оптимизации будет заметно ниже.
<юмор>То есть мечта Нашего Солнцеподобного нормализовать айтишников не возможна математически.</юмор>
Это всё по основному докладу. Теперь маленький бонус на тему «кто виноват», то есть теоретическая часть. Все наблюдаемые в статье распределения не удовлетворяют ЦПТ по причине отсутствия дисперсии, но всё равно общий вид законов распределения для них существует. Это устойчивые распределения, связанные с представлениями Леви – Хинчина. Теория таких распределений отлично изучена в финансах, теор физике, демографии. По моим наблюдениям, она отлично вписывается и в АйТи. Тем более, что в информатику она вошла вместе с именем Мандельброта, который был учеником вышеназванного Леви и, именно изучая процессы с бесконечной дисперсией, открыл фракталы. Заметьте, как это прекрасно, фракталом может быть не просто картинка или структура данных, как дерево папок и файлов, но и статистический набор данных. Дальше эти распределения подчиняются закону Бенфорда, знакомство с которым просто уже не даст вам спокойно смотреть на наборы чисел (как, например, в представленных выше скриншотах профалеров, где оно очевидно). И это не все, любители чистой математики в этих распределениях найдут применение дробных производных, метода характеристической функции, метода моментов (эти два Лаплас и Чебышёв открыли, изучая такие распределения), преобразование сигналов и многое другое. О чем я уже писал в предыдущих статьях или еще напишу в будущих.
Под катом слайды с пояснением.
В детстве наши восприятия особенно обманчивы. Помню, прогуливались мимо башни с часами, сильно удивился, когда отец сказал, что длина стрелки равна пяти шагам. То есть как это? Тогда казалось, что все штуки, окружающие нас, примерно одинакового размера. Тогда и мультики такие были, как Винни Пух. Действительно, сейчас трудно представить сову, размером с медведя.
Потом, когда мы подрастаем, чтоб развить любовь к естественным наукам, нам дарят книжку про планеты. Можете поверить, такого рода книги существуют на всех языках почти во всех странах.
Глядя на обложку, можно подумать, что все планеты примерно сопоставимого размера и если и отличаются друг от друга, то на проценты, а не в разы или даже в несколько порядков.
А теперь давайте посмотрим, как сопоставимы по размеру планеты в нашей системе в самом деле.
Дела обстоят так, что в едином масштабе невозможно изобразить все планеты вместе так, чтоб хотя бы был виден красный цвет Марса и было понятно, что Юпитер в 300+ раз больше Земли, при этом в 1000 раз меньше Солнца. На этой схеме не учтены расстояния от Солнца, если Землю оставить на таком расстоянии, то для Урана явно не хватит экрана, а Нептун уже будет в другой комнате.
Кстати, древние греки не знали про размеры планет, но у их была легенда, как Зевс (Юпитер по-новому) соревновался со ВСЕМИ остальными богами. Они перетягивали золотую цепь и Зевс выиграл, то есть он сильнее суммарно всех вместе, но не всесильный. Что гораздо позже физики и астрономы показали. Похоже, это и были те гиганты, на плечах которых стоял Ньютон.
Детская привычка видеть перед собой примерно сопоставимые вещи, приносит неоправданные, мягко говоря, результаты. В реальной жизни мы видим, как так же распределены население и площади стран, население городов, астрономические объекты, траты населения, доход по отраслям и многое другое. Для нас теперь самое важное, что так же распределены почти все наблюдения в нашей работе. Теперь рассмотрим пример с котиками. Найдем в инстаграме изображения с тэгом #catphoto.
Инстаграм после загрузки обрабатывает изображения, приводя их к размеру 640X640 пикселей, сжимая в формат jpeg. Кажется, после такого все изображения должны занимать примерно одинаковый размер, и если и будут отличаться, то не в разы, а на несколько процентов. А теперь, посмотрим на размер фотографий.
Видно, что размер самого большого файла отличается от самого меньшего в 2,5 раза. Еще «драматичнее» становится ситуация, когда начинаем смотреть файлы разного типа, но, например, принадлежащих одному проекту. Вот как выглядит профайлер загрузки страницы очень богатой компании.
Здесь загруженные файлы отсортированы по размеру. И сразу можно заметить, что 5 файлов занимают больше размера, чем 180 оставшихся. Если вам кажется, что это особенный сайт, то попробуйте очистить кэш, загрузить любой сайт и убедиться, что 5% самых больших файлов занимает больше места, чем 50% самых маленьких практически для любого сайта.
Хотите расскажу про средний (условно ваш) проект. На проекте есть база данных, в которой 30 – 90 таблиц, в двух самых больших больше строк, чем в половине самых маленьких. В репозитории лежат тысячи файлов кода, 1% самых больших из которых занимает больше места, чем 50% самых маленьких. Есть сайт который грузится несколько секунд, и за это время подгружается 80 – 300 файлов, из которых опять 1% самых больших занимает больше места, чем 50% самых маленьких. Так же могу рассказать про файлы на вашем компьютере. В папке Downloads (если она только регулярно не чистится) два самых больших файла занимают больше места, чем половина самых маленьких.
Однако, привычки наблюдения за окружающим миром и центральная предельная теорема теории вероятностей подводятся к тому, что при работе с очень большим числом наблюдений усредненный результат не должен сойтись к какому-то значению не сильно отличающемуся от среднего. Про это даже комиксы есть, к сожалению с опущеными необходимыми условиями.
Долгие наблюдения за измеримыми данными в телекоммуникациях и разработке привели меня к выводу, что встретить нормальное распределение почти нереально. Что же бывает в самом деле.
Наблюдаемые значения имеют выбросы. Это такие наблюдения, которые явно отклоняются от общей массы (тыц). Если вспомнить статистику, то при обработке результатов эксперимента, такие значения можно отбросить. В нашем случае они слишком важны и учитывать их обязательно.
Также эти наблюдения имеют значительную асимметрию и тяжелый хвост.
Существует множество объяснений этому явлению, среди которых есть и противоречащие друг другу, так что на их выяснение не будем тратить время. Просто очевидно, что у рассматриваемых распределений нет дисперсии, а значит условие ЦПТ не выполняется.
Не воспринимайте картинку слишком серьезно. Давайте лучше сразу подумаем, что с этим можно сделать. А что делать понятно: оптимизировать. То есть надо оптимизировать размер файлов, количество вызовов функций, время загрузки страницы, то есть все то, что забирает ресурсы, которым есть лучшее применение.
И теперь самое время рассказать про ключевую и самую знаменитую фразу из информатики, связанную с оптимизацией.
Я специально нашел изображение молодого Дональда Кнута, так как эта фраза была сказана аж в далеком 1974 году и имеет уже столько толкований, что даже сам Кнут неоднократно давал объяснения (как забавно: не метод в интерфейсе, а целая фраза обладает полиморфизмом). Да, преждевременная оптимизация корень всех бед. В 97% случаев она ни к чему не приведет. Но оставшиеся 3% никак нельзя сбрасывать со счетов.
В те давние времена, когда не было удобных профайлеров, IDE, айфонов, браузеров, интернета, персональных компьютеров, ООП, а суммарная мощность всех компов в мире равнялась нескольким современным смартфонам. Еще тогда в статье-дискуссии с Дейкстрой про применимость GO TO в структурном программировании, Кнут заметил, что в абсолютном большинстве случаев оптимизация не приносит результата, а даже наоборот отбирает время и делает код менее читаемым.
А теперь более наглядный пример. Но мы уже вооружены технологиями и можем посмотреть, какую оптимизацию сайту предлагает автоматическая утилита PageSpeed от Google (я выбрал компанию sinopec group, как одну из самых богатых в мире, на сайт должно быть).
Итак, общий размер сайта при загрузке 2.1М, а утилита находит, что можно сжать стили, от чего выиграть 9.2К. Что составляет меньше полпроцента. Согласитесь, такую оптимизацию не заметит конечный пользователь, а также проблем с загрузкой и местом в транспортировки это не создаст.
А что же тогда оптимизировать? Давайте, для разнообразия, рассмотрим другую страницу профайлера.
Тут уже не размер файлов, а производительность. То есть сколько времени было потрачено на выполнение функций в приложении за короткий промежуток времени, а затем отсортировано по этому самому времени. В картинку вместилось 12 функций из 600+, с учетом крупного шрифта. Как всегда один процент самых затратных функций потребляет больше ресурсов, чем 50% самых незатратных. Так вот, при оптимизации производительности, видя такую таблицу никогда не скрольте ее дальше – не оптимизировав что-нибудь из первых 3 – 8 функций видимого улучшения не настанет. Такая простая истина, но из-за непонимание её тратится много времени.
А теперь второй важный момент, связанный с этим, который уже не так очевиден. Я к этому выводу пришел наблюдая несколько лет разные статистические данные в АйТи, подобно тому как Климент Аркадьевич Тимирязев наблюдал годами за листиками в колбах. Вам не удастся свести реальный проект к состоянию, когда распределение ресурсов будет нормальным или хоть сопоставимым. Ни за какое число итераций оптимизации. Хорошо оптимизированный проект все равно будет иметь распределение времени выполнения функций таким, как показано на картинке выше, только суммарно время их выполнения после оптимизации будет заметно ниже.
<юмор>То есть мечта Нашего Солнцеподобного нормализовать айтишников не возможна математически.</юмор>
Это всё по основному докладу. Теперь маленький бонус на тему «кто виноват», то есть теоретическая часть. Все наблюдаемые в статье распределения не удовлетворяют ЦПТ по причине отсутствия дисперсии, но всё равно общий вид законов распределения для них существует. Это устойчивые распределения, связанные с представлениями Леви – Хинчина. Теория таких распределений отлично изучена в финансах, теор физике, демографии. По моим наблюдениям, она отлично вписывается и в АйТи. Тем более, что в информатику она вошла вместе с именем Мандельброта, который был учеником вышеназванного Леви и, именно изучая процессы с бесконечной дисперсией, открыл фракталы. Заметьте, как это прекрасно, фракталом может быть не просто картинка или структура данных, как дерево папок и файлов, но и статистический набор данных. Дальше эти распределения подчиняются закону Бенфорда, знакомство с которым просто уже не даст вам спокойно смотреть на наборы чисел (как, например, в представленных выше скриншотах профалеров, где оно очевидно). И это не все, любители чистой математики в этих распределениях найдут применение дробных производных, метода характеристической функции, метода моментов (эти два Лаплас и Чебышёв открыли, изучая такие распределения), преобразование сигналов и многое другое. О чем я уже писал в предыдущих статьях или еще напишу в будущих.

iago
В маркетинге айти в начале-середине нулевых появился термин "long tail", который довольно-таки перевернул стандартные представления о продажах цифровых данных (музыки, фильмов, игр и т.п.). Продавать и хранить информацию стало дешево, и тот же Стив Джобс обратил внимание, что продажа 90% самых непопулярных треков в айтюнс генерирует столько же прибыли, как и 10% самых коммерчески успешных. Но эти 90% раньше вообще не имели шанса увидеть свет, т.к. лейблы брались за выпуск пластинок/кассет/дисков только заранее успешных и раскрученных групп, в то время как загрузить свой трек для продажи в iTunes может практически каждый желающий.
Я думаю, примерно такое же распределение характерно и для фильмов, и для Steam, и для Appstore и Google Play. Хвост настолько длинный, что многие игровые студии неплохо живут на продажах игр, о которых 95% населения и не слышало