

Задача по созданию тетрис-процессора размером 2 940 928 x 10 295 296
Этот проект стал кульминацией труда множества пользователей в течение последних полутора лет. Хотя состав команды со временем менялся, в написании этой статьи принимали участие следующие авторы:
- PhiNotPi
- El'endia Starman
- K Zhang
- Muddyfish
- Kritixi Lithos
- Mego
- Quartata
Также мы хотим поблагодарить 7H3_H4CK3R, Conor O'Brien и многих других пользователей, вложивших свои труд в решение этой задачи.
Из-за беспрецедентного масштаба этой задачи, статья разделена на несколько частей, написанных членами команды. Каждый участник писал о своей отдельной подтеме, приблизительно соответствующей тем областям проекта, в которых был задействован.
Стоит также заглянуть в GitHub нашей организации, в котором мы выложили весь код, написанный для решения задачи. Вопросы можно задавать в нашем чате разработки.
Часть 1: обзор
Этот проект начался как ответ на вопрос со Stackexchange:
Это теоретическая задача — она не имеет ни простого, ни тривиального ответа.
В игре «Жизнь» Конвея существуют такие конструкции, как метапиксели, которые позволяют игре «Жизнь» симулировать любую систему правил, похожую на «Жизнь». Кроме того, известно, что игра «Жизнь» Тьюринг-полная.
Ваша задача заключается в создании клеточного автомата, использующего правила игры «Жизнь» Конвея, который позволяет играть в «Тетрис».
Программа должна получать ввод ручным изменением состояния автомата в определённом поколении, представляющим собой прерывание (т.е. перемещение фигуры влево или вправо, поворот, бросание вниз или случайная генерация новой фигуры для размещения на поле). Определённое количество поколений считается временем ожидания. Результат игры показывается где-нибудь в автомате. Полученный результат должен визуально напоминать поле для настоящего «Тетриса».
Ваша программа будет оцениваться по следующим критериям, в следующем порядке (нижние критерии являются допольнительными по отношению к более высоким):
- Размер граничного прямоугольника — выигрывает прямоугольное поле с наименьшей площадью, полностью содержащее решение.
- Наименьшее количество изменений для ввода — выигрывает решение с наименьшим количеством ячеек (в худшем для вашего автомата случая), необходимых для ручной настройки в качестве прерывания.
- Самое быстрое выполнение — выигрывает решение с наименьшим количеством поколений для продвижения вперёд на один такт симуляции.
- Начальное количество живых клеток — выигрывает наименьшее количество.
- Первое опубликованное — выигрывает самый первый пост с решением.
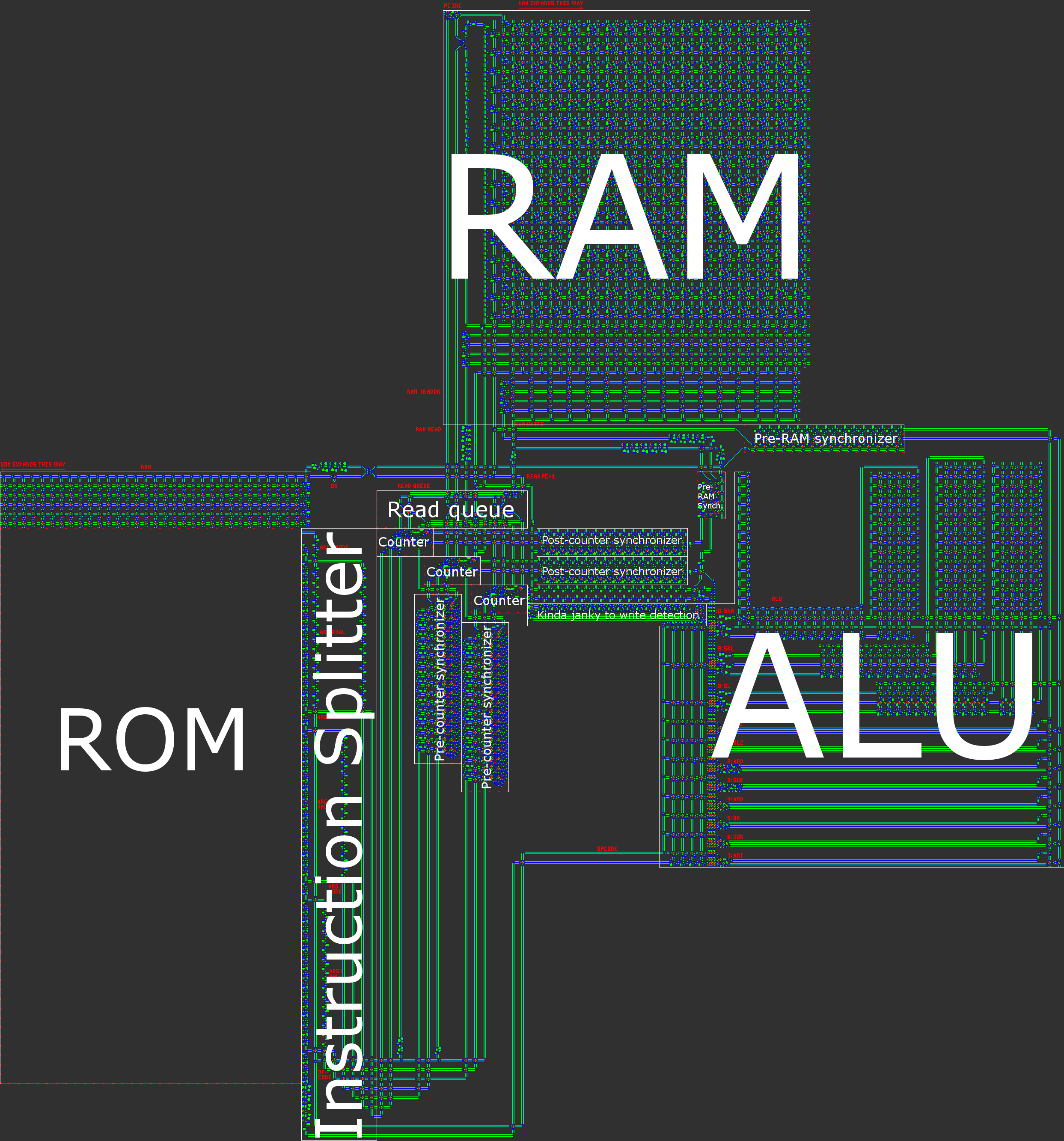
Основопологающей идеей этого проекта стало абстрагирование. Вместо непосредственной разработки «Тетриса» в игре «Жизнь», мы пошагово расширяли создаваемую абстракцию. На каждом слое мы всё дальше уходили от сложностей «Жизни» и приближались к созданию компьютера, программировать который было бы так же просто, как любой другой.
Во-первых, в качестве основы для компьютера мы использовали OTCA-метапиксели. Эти метапиксели могут эмулировать любые правила игры, похожей на «Жизнь». Важными источниками вдохновения для этого проекта стали Wireworld и компьютер Wireworld, мы стремились создать похожую конструкцию на основе метапикселей. Хотя эмулировать Wireworld с помощью OTCA-метапикселей невозможно, можно установить для разных метапикселей разные правила и создать конструкции из метапикселей, работающие подобно проводам Wireworld.
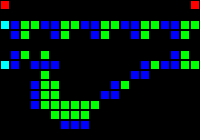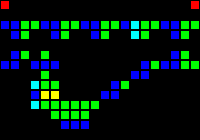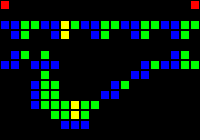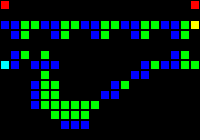
Следующим шагом стало создание множества фундаментальных логических вентилей, которые можно использовать в качестве основы компьютера. На этом этапе мы уже имеем дело с концепциями, похожими на концепции дизайна процессоров реального мира. Вот пример вентиля OR, каждая ячейка этого изображения на самом деле является целым OTCA-метапикселем. Вы видите, как «электроны» (каждый из которых представляет собой единичный бит данных) входят и выходят из вентиля. Также видны все типы метапикселей, использованные нами для создания компьютера: B/S — чёрный фон, B1/S — синий, B2/S — зелёный, B12/S1 — красный.
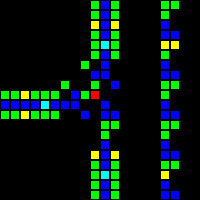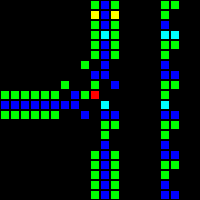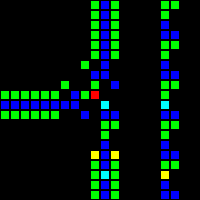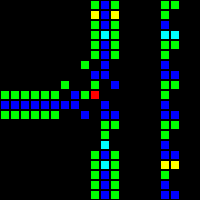
Из этого мы разработали архитектуру процессора. Мы потратили много времени на разработку архитектуры, которая была бы одновременно и понятной, и простой в реализации. Компьютер Wireworld использует рудиментарную transport-triggered architecture, в нашем же проекте используется гораздо более гибкая архитектура RISC, имеющая множественные опкоды и режимы адресации. Мы создали язык ассемблера QFTASM (Quest for Tetris Assembly), который управлял изготовлением процессора.
Также наш компьютер является асинхронным, это значит, что он не управляется глобальными часами. В процессе передачи внутри компьютера данные сопровождаются сигналом синхронизации. Это значит, что нам нужно отслеживать только локальные, а не глобальные тайминги компьютера.
Вот иллюстрация архитектуры нашего процессора:
С этого момента нам остаётся только реализовать «Тетрис» в компьютере. Чтобы упростить задачу, мы разработали несколько способов компилирования высокоуровневого языка в QFTASM. У нас есть базовый язык Cogol, второй, более совершенный язык находится в процессе разработки, и, наконец, мы создаём бэкенд GCC. Сейчас программа «Тетриса» пишется на Cogol и компилируется из него.
После того, как конечный код QFTASM «Тетриса» был сгенерирован, следующими шагами были сборка из этого кода в соответствующее ПЗУ, а затем из метапикселей в лежащую в основе игру «Жизнь», на чём наша работа будет закончена.
Запуск «Тетриса»
Те, кто хочет поиграть в «Тетрис» без возни с компилятором, могут запустить исходный код «Тетриса» в интерпретаторе QFTASM. Для просмотра всей игры укажите отображаемые адреса ОЗУ 3-32. Вот постоянная ссылка для удобства: Tetris in QFTASM.
Характеристики игры:
- Все 7 тетромино
- Движение, вращение, плавное опускание фигур
- Очистка линий и подсчёт очков
- Показ следующей фигуры
- Ввод игрока добавляет случайности
Дисплей
Наш компьютер представляет поле «Тетриса» как сетку в памяти. Адреса 10-31 отображают поле, адреса 5-8 — следующую фигуру, адрес 3 содержит счёт.
Ввод
Ввод в игре осуществляется ручным редактированием содержимого адреса 1 в ОЗУ. При использовании интерпретатора QFTASM это означает прямую запись по адресу 1. См. «Direct write to RAM» на странице интепретатора. Каждый ход требует изменения только одного бита ОЗУ, и этот регистр ввода автоматически сбрасывается после считывания события ввода.
value motion
1 вращение против часовой стрелки
2 влево
4 вниз (плавное опускание)
8 вправо
16 вращение по часовой стрелкеСистема подсчёта очков
Игрок получает бонус за удаление нескольких линий за один ход.
1 ряд = 1 очко
2 ряда = 2 очка
3 ряда = 4 очка
4 ряда = 8 очковЧасть 2: OTCA-метапиксель и VarLife
OTCA-метапиксель

OTCA-метапиксель — это структура в конвеевской игре «Жизнь», которую можно использовать для симуляции любого клеточного автомата, похожего на «Жизнь». Процитирую LifeWiki (ссылка ниже):
OTCA-метапиксель — это ячейка 2048 ? 2048 из 35328 клеток, созданная Брайсом Дью… Она имеет множество преимуществ… в том числе способность эмулировать любой клеточный автомат, похожий на «Жизнь», и очень заметные при уменьшении масштаба клетки в состоянии ON и OFF...
Клеточный автомат, похожий на «Жизнь», в сущности, означает то, что клетки рождаются и выживают на основании того, сколько из восьми соседних с ними клеток живо. Эти правила имеют следующий синтаксис: буква B, за которой следует количество живых соседей, приводящее к рождению, косая черта, буква S, за которой следует количество живых соседей, поддерживающих жизнь клетки. Немного запутанно, так что, думаю, лучше привести пример. Каноничную игру «Жизнь» можно представить в виде правила B3/S23, которое гласит, что мёртвая клетка, окружённая тремя соседями, становится живой, а любая живая клетка с двумя или тремя живыми соседями остаётся живой. В противном случае клетка умирает.
Несмотря на то, что OTCA-метапиксель — это клетка 2048 x 2048, на самом деле он имеет ограничивающий прямоугольник в 2058 x 2058 клеток, потому что он перекрывается своими диагональными соседями пятью клетками во всех направлениях. Перекрывающие клетки необходимы для перехвата «глайдеров», которые излучаются, чтобы сообщать соседям-метаклеткам, что он включен. Благодаря этому они не будут влиять на другие метапиксели или бесконтрольно перемещаться. Правила рождения и выживания закодированы в специальной секции клеток в левой части метапикселя присутствием или отсутствием «едоков» в определённых позициях вдоль двух столбцов (один для рождения, другой для выживания). Что касается распознавания состояния соседних клеток, то вот что происходит:
Поток 9-LWSS затем обходит по часовой стрелке вокруг ячейки, теряя LWSS на каждой соседней «включённой» клетке, запускающей ячейку памяти honeybit reaction. Количество отсутствующих LWSS подсчитывается распознаванием положения переднего LWSS с помощью сталкивания с другим LWSS с противоположного направления. Это столкновение выпускает глайдеры, которые запускают ещё одну или две honeybit reaction, если «едоки», определяющие состояние рождения/выживания отсутствуют.
Более подробная схема каждого аспекта OTCA-метапикселя представлена на его веб-сайте: How Does It Work?.
VarLife
Я создал онлайн-симулятор правил Life-подобных игр, в котором можно задать поведение любой клетки в соответствии с любыми правилами, схожими с правилами «Жизни». Я назвал симулятор «Variations of Life». Для краткости потом это название сменилось на «VarLife». Вот его скриншот (ссылка на симулятор: http://play.starmaninnovations.com/varlife/BeeHkfCpNR):

Примечательные особенности:
- Переключает клетки между состояниями «живая»/«мёртвая» и раскрашивает поле по различным правилам.
- Способность запускать и останавливать симуляцию, выполнять по одному шагу за раз. Также возможно выполнять заданное количество шагов с максимальной скоростью или более медленно, со скоростью, устанавливаемой в тактах/с и мс/такт.
- Имеет возможность удалять все живые клетки или полностью сбрасывать поле в пустое состояние.
- Может менять размер поля и клеток, а также включать горизонтальную и/или вертикальную тороидальную свёртку.
- Постоянные ссылки (которые кодируют всю информацию url) и короткие url (потому что иногда бывает слишком много информации, но они всё равно полезны).
- Наборы правил с заданием B/S, цветов и опциональной случайности.
- И последнее — рендеринг gif!
Функция render-to-gif — моя любимая, потому что на её реализацию ушла куча времени. Было очень здорово, когда я наконец доделал её в семь часов утра. С её помощью можно запросто делиться конструкциями VarLife с другими людьми.
Основная схема VarLife
В целом компьютеру VarLife требуется всего четыре типа клеток! Всего восемь состояний, с учётом состояний «мёртвый»/«живой»:
- B/S (чёрный/белый), которое служит в качестве буфера мжеду всеми компонентами, потому что клетки B/S никогда не могут быть живыми.
- B1/S (синие/голубые) — основной тип клеток, используемый для распространения сигналов.
- B2/S (зелёный/жёлтый) — в основном используется для управления сигналами, защищая их от обратного распространения.
- B12/S1 (красный/оранжевый) — используется в некоторых особых ситуациях, например, при пересечении сигналов и хранении бита данных.
Воспользуйтесь этим коротким url, чтобы открыть VarLife с уже закодированными правилами: http://play.starmaninnovations.com/varlife/BeeHkfCpNR.
Проводники
Существует несколько различных конструкций проводников с отличающимися характеристиками.
Это простейший и основной проводник в VarLife, полоса синего, ограниченная полосами зелёного.

Короткий url: http://play.starmaninnovations.com/varlife/WcsGmjLiBF
Это однонаправленный проводник. То есть он будет уничтожать все сигналы, пытающиеся пройти в противоположном направлении. Кроме того, он на одну клетку у?же основного проводника.

Короткий url: http://play.starmaninnovations.com/varlife/ARWgUgPTEJ
Существуют также диагональные проводники, но они почти не используются.
Короткий url: http://play.starmaninnovations.com/varlife/kJotsdSXIj
Шлюзы
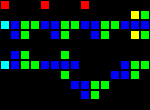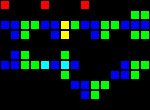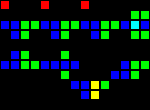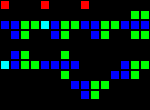
На самом деле есть множество способов создания каждого отдельного шлюза, поэтому я покажу только по одному примеру каждого типа. На первом gif показаны, соответственно, шлюзы AND, XOR и OR. Основная идея заключается в том, что зелёная клетка действует как AND, синяя — как XOR, а красная — как OR, а все остальные клетки вокруг них просто обеспечивают правильную передачу.
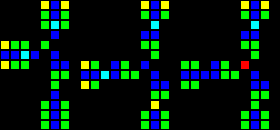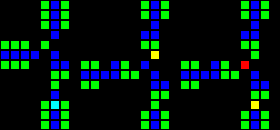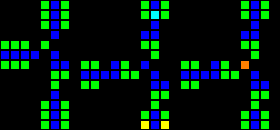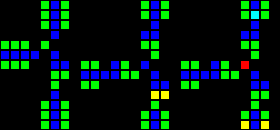
Короткий url: http://play.starmaninnovations.com/varlife/EGTlKktmeI
Шлюз AND-NOT (сокращённо ANT) оказался жизненно необходимым компонентом. Этот шлюз передаёт сигнал от A тогда и только тогда, когда нет сигнала от B. То есть «A AND NOT B».
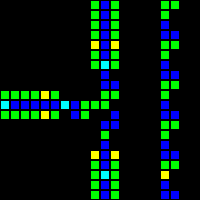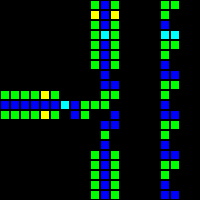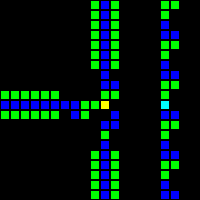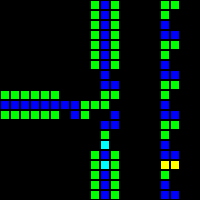
Короткий url: http://play.starmaninnovations.com/varlife/RsZBiNqIUy
Хотя это не совсем шлюз, но тайл пересечения проводников очень важен и полезен.
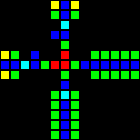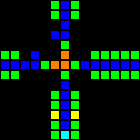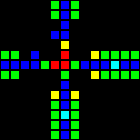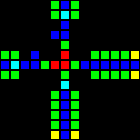
Короткий url: http://play.starmaninnovations.com/varlife/OXMsPyaNTC
Между прочим, здесь нет шлюза NOT. Так получилось потому, что без входящего сигнала должен создаваться постоянный вывод, который не очень хорошо себя проявляет со множеством таймингов, требуемых современным компьютерным оборудованием. Но нам в любом случае удалось обойтись без него.
Кроме того, многие компоненты намеренно создавались таким образом, чтобы умещаться в ограничивающий прямоугольник 11 на 11 (тайл), в котором от момента входа в тайл до выхода из тайла сигналам требуется 11 тактов. Это делает компоненты более модульными и их легче соединять вместе без необходимости регулировки проводников для обеспечения пространства или таймингов.
О других шлюзах, исследованных/созданных в процессе изучения компонентов схем, можно прочитать в посте PhiNotPi: Building Blocks: Logic Gates.
Компоненты задержки
В процессе разработки оборудования компьютера KZhang придумал множество компонентов задержки, показанных ниже.
Задержка на 4 такта:
Короткий url: http://play.starmaninnovations.com/varlife/gebOMIXxdh
Задержка на 5 тактов:
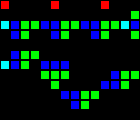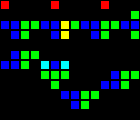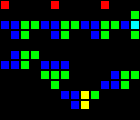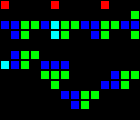
Короткий url: http://play.starmaninnovations.com/varlife/JItNjJvnUB
Задержка на 8 тактов (три отдельных точки входа):
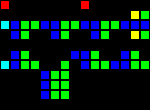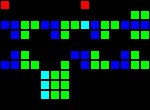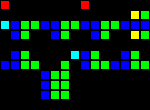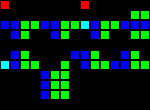
Короткий url: http://play.starmaninnovations.com/varlife/nSTRaVEDvA
Задержка на 11 тактов:
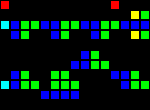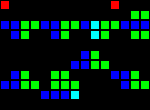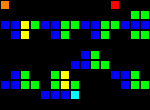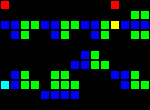
Короткий url: http://play.starmaninnovations.com/varlife/kfoADussXA
Задержка на 12 тактов:
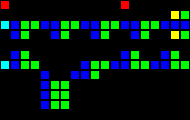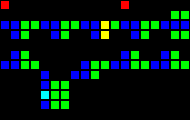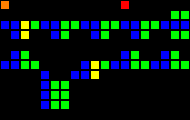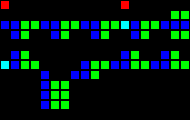
Короткий url: http://play.starmaninnovations.com/varlife/bkamAfUfud
Задержка на 14 тактов:
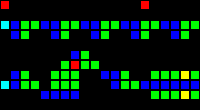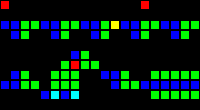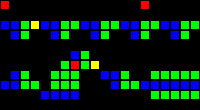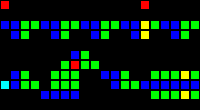
Короткий url: http://play.starmaninnovations.com/varlife/TkwzYIBWln
Задержка на 15 тактов (проверятся сравнением с этим):
Короткий url: http://play.starmaninnovations.com/varlife/jmgpehYlpT
Итак, вот каковы основные компоненты схем VarLife! Описания основных схем компьютера см. в следующей части, написанной KZhang!
Часть 3: оборудование
Благодаря нашим знаниям логических шлюзов и общей структуры процессора, мы можем начать разработку всех компонентов компьютера.
Демультиплексор
Демультиплексор, или demux — критически важный компонент ПЗУ, ОЗУ и АЛУ. В зависимости от заданных данных селектора он направляет входной сигнал на один из нескольких выходных сигналов. Он состоит из трёх основных частей: последовательно-параллельный преобразователь, устройство контроля сигнала и разделитель тактовых сигналов.
Мы начинаем с преобразования последовательных данных селектора в «параллельные». Это выполняется стратегическим разделением и задержкой данных, чтобы самый левый бит данных пересекал тактовый сигна в самом левом квадрате 11x11, следующий бит данных пересекал тактовый сигнал в следующем квадрате 11x11, и так далее.
Хотя каждый бит данных будет выводиться в каждый квадрат 11x11, каждый бит данных будет пересекаться с тактовым сигналом только один раз.
Далее мы проверяем, соответствуют ли параллельные данные заданному адресу.
Мы осуществляем это с помощью шлюзов AND и ANT, применяемыми для тактовых и параллельных данных. Однако нам нужно убедиться, что параллельные данные тоже выводятся, чтобы их можно было снова сравнить. Вот шлюзы, которые в результате создал я:

Наконец, мы просто разделяем тактовый сигнал, соединяем несколько устройств проверки сигнала (по одному для каждого адреса/вывода), в результате получая мультиплексор!

ПЗУ
ПЗУ должно получать в качестве входных данных адрес, а в качестве вывода отправлять инструкцию по этому адресу. Мы начинаем с того, что используем мультиплексор для направления тактового сигнала на одну из инструкций. Затем нам нужно сгенерировать сигнал с помощью касаний нескольких проводников и шлюзов OR. Касания проводников позволяют тактовому сигналу пройти по всем 58 битам инструкции, а также обеспечивают перемещение сгенерированного сигнала (пока параллельного) по ПЗУ на выход.
Затем нам нужно просто преобразовать параллельный сигнал в последовательный, и на этом ПЗУ будет готово.
В настоящее время ПЗУ генерируется выполнением скрипта на Golly, передающего ассемблерный код из буфера обмена в ПЗУ.
SRL, SL, SRA
Эти три логических шлюза используются для битового сдвига, и они более сложны, чем обычные AND, OR, XOR, и т.п. Чтобы эти шлюзы работали, нам нужно сначала выполнить задержку тактового сигнала на соответствующее время, чтобы выполнить «сдвиг» данных.
Второй аргумент, передаваемый этим шлюзам, сообщает, на столько бит нужно выполнить смещение.
Для SL и SRL нам нужно
- Убедиться, что 12 самых значимых битов не включены (иначе вывод будет равен 0), и
- Выполнить задержку данных на нужное время на основании 4 менее значимых битов.
Это можно реализовать с помощью нескольких шлюзов AND/ANT и мультиплексора.

SRA немного отличается, потому что при сдвиге нам нужно копировать знаковый бит. Мы выполняем это, применив AND к тактовому сигналу со знаковым битом, а затем скопировав вывод несколько раз с помощью разделителей проводников и шлюзов OR.

Триггер Set-Reset (SR)
Многие функции процессора зависят от способности хранить данные. Мы можем реализовать её с помощью двух красных клеток B12/S1. Две клетки могут поддерживать друг друга во включенном состоянии или же вместе быть выключенными. С помощью дополнительных схем включения, сброса и чтения мы можем создать простой SR-триггер.
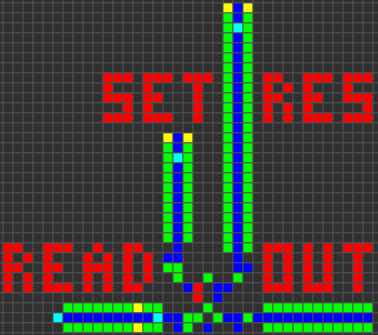
Синхронизатор
Преобразовав последовательные данные в параллельные, а затем включив несколько SR-триггеров, мы можем хранить целое слово данных. Затем, чтобы снова извлечь данные, мы можем просто считать и сбросить все триггеры, и соответствующим образом выполнить задержку данных. Это позволит нам хранить одно (или несколько) слов данных, пока мы ждём другое. Благодаря этому мы сможем синхронизировать два слова данных, полученных в разное время.

Счётчик считывания
Это устройство отслеживает, сколько раз оно должно выполнять адресацию из ОЗУ. Оно решает эту задачу с помощью устройства, похожего на SR-триггер: T-триггера. Каждый раз, когда T-триггер получает входные данные, он меняет состояние: если он был включен, то отключается, и наоборот. Когда T-триггер изменяет своё состояние, он отправляет выходной импульс, который можно передать в другой T-триггер, создав двухбитный счётчик.

Для создания счётчика считывания нам нужно перевести счётчик в подходящий режим адресации с помощью двух шлюзов ANT, и использовать выходной сигнал счётчика для определения того, куда направлять тактовый сигнал: в АЛУ или в ОЗУ.

Очередь считывания
Очередь считывания должна отслеживать, какой из счётчиков считывания отправил входные данные в ОЗУ, чтобы он мог отправить вывод ОЗУ в нужное место. Для этого мы используем несколько SR-триггеров: по одному триггеру на каждый вход. Когда из счётчика считывания передаётся сигнал в ОЗУ, тактовый сигнал разделяется и включает SR-триггер счётчика. Затем вывод ОЗУ проходит вмести с SR-триггером через шлюз AND, а тактовый сигнал из ОЗУ сбрасывает SR-триггер.

АЛУ
АЛУ похожа в работе на очередь считывания в том, что она оно тоже использует SR-триггер для отслеживания того, куда отправлять сигнал. Сначала с помощью мультиплексора включается SR-триггер логической цепи, соответствующей опкоду инструкции. Затем значения первого и второго аргумента вместе с SR-триггером проходят через шлюз AND, а потом передаются в логические цепи. При прохождении тактовый сигнал сбрасывает триггер, так что АЛУ можно использовать снова.

ОЗУ
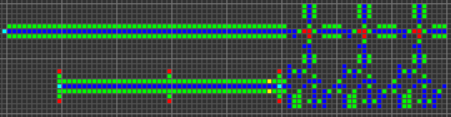
ОЗУ стало самой сложной частью этого проекта. Оно требовало очень специфического управления каждым SR-триггером, хранящим данные. Для считывания адрес передаётся в мультиплексор и передаётся в сегменты ОЗУ. Сегменты ОЗУ параллельно выводят хранящиеся данные, которые преобразуются в последовательный вид и выводятся. Для записи адрес передаётся в другой мультиплексор, записываемые данные преобразуются из последовательной в параллельную форму, а сегменты ОЗУ распространяют сигнал по ОЗУ.
Метапиксель 22x22 каждого сегмента ОЗУ имеет такую структуру:
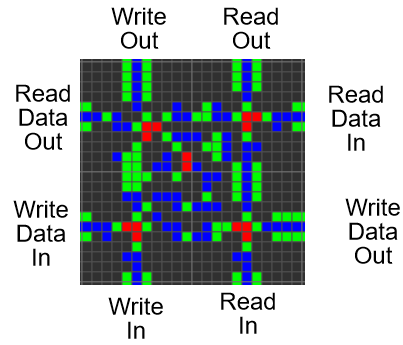
Соединив всё ОЗУ, мы получим что-то подобное:

Соединяем всё вместе
С помощью всех этих компонентов и общей архитектуре компьютера, описанной в Части 1, мы можем построить работающий компьютер!
Скачиваемые файлы:
— Готовый компьютер для «Тетриса»
— Скрипт создания ПЗУ, пустой компьютер и компьютер для нахождения простых чисел
Часть 4: QFTASM и Cogol
Обзор архитектуры
Если вкратце, то наш компьютер имеет 16-битную асинхронную гарвардскую архитектуру RISC. При создании процессора вручную архитектура RISC (компьютер с сокращённым набором команд) является практически обязательным требованием. В нашем случае это означает, что количество опкодов мало, и, что гораздо более важно — все инструкции обрабатываются очень похожим образом.
Для справки — компьютер Wireworld использует transport-triggered architecture, в которой единственной инструкцией является
MOV, а вычисления выполняются записью/считыванием специальных регистров. Хотя эта парадигма позволяет создать очень простую в реализации архитектуру, результат оказывается на грани применимости: все арифметические/логические/условные операции требуют трёх инструкций. Было очевидно, что мы хотим создать более понятную архитектуру.Чтобы оставить наш процессор простым, в то же время повысив удобство его использования, мы приняли несколько важных решений относительно его конструкции:
- Никаких регистров. Каждый адрес в ОЗУ считается равным и может использоваться как аргумент в любой операции. В каком-то смысле это значит, что всё ОЗУ можно считать регистрами. Это означает отсутствие специальных инструкций загрузки/хранения.
- То же самое касается распределения памяти. Всё, что может записываться или считываться, имеет общую унифицированную схему адресации. Это значит, что счётчик команд (program counter, PC) является адресом 0, а единственная разница между обычными и управляющими инструкциями заключается в том, что управляющие используют адрес 0.
- Данные последовательны при передаче и параллельны при хранении. Из-за «электронной» природы нашего компьютера, сложение и вычитание реализовать значительно проще, когда данные передаются последовательно в порядке little-endian (первым идёт наименее значимый бит). Более того, последовательные данные позволяют избавиться от громоздких шин данных, которые очень широки и неудобны для правильной работы со временем (чтобы данные находились вместе, все «полосы» шины должны иметь одинаковую временную задержку).
- Гарвардская архитектура, то есть существует разделение между памятью программ (ПЗУ) и памятью данных (ОЗУ). Хоть это и снижает гибкость процессора, но помогает оптимизировать размер: длина программы намного больше, чем нужное нам количество ОЗУ, поэтому мы можем разделить программу в ПЗУ и затем сосредоточиться на сжатии ПЗУ, что гораздо проще выполнить, когда она «только для чтения».
- 16-битная разрядность данных. Это наименьшая степень двойки, которая шире стандартного поля для «Тетриса» (10 блоков). Это даёт нам диапазон данных от -32768 до +32767 и максимальную длину программы в 65536 инструкций. (2^8=256 инструкций достаточно для большинства простых вещей, которые можно реализовать в выдуманном процессоре, но никак не для «Тетриса».)
- Асинхронный дизайн. Вместо центрального тактового генератора (или, что аналогично, нескольких генераторов), задающего время компьютера, все данные сопровождаются «тактовым сигналом», передающимся параллельно с данными при их перемещении в компьютере. Некоторые пути могут быть короче других, и это может вызывать сложности в дизайне с центральным тактовым генератором, но асинхронная конструкция может запросто справляться с операциями с переменным временем.
- Все инструкции имеют одинаковый размер. Мы посчитали, что архитектура, в которой каждая инструкция имеет 1 опкод с тремя операндами (значание, значение, целевой адрес) будет наиболее гибким вариантом. Они включают в себя операции с двоичными данными, а также условные переходы.
- Прострая система режимов адресации. Наличие множества режимов адресации очень полезно для поддержки таких вещей, как массивы или рекурсия. Нам удалось с помощью относительно простой системы реализовать несколько важных режимов адресации.
Иллюстрация нашей архитектуры приведена в Части 1.
Работа и операции АЛУ
После этого нужно было определиться, какие функции должен иметь наш процессор. Особое внимание стоило уделить простоте реализации и универсальности каждой команды.
Условные перемещения
Условные перемещения очень важны, они служат для маломасштабного и крупномасштабного управления. «Маломасштабное» — это способность управлять выполнением конкретным перемещением данных, а «крупномасштабное» относится к их использованию в качестве операции условного перехода для передачи управления любому произвольному фрагменту кода. У процессора нет специальных операций перехода, потому что из-за распределения памяти условное перемещение может и копировать данные в обычную ОЗУ, и копировать адрес назначения в счётчик команд (PC). Также мы решили отказаться и от безусловных перемещений, и от безусловных переходов по схожей причине: обе эти операции могут быть реализованы как условные перемещения, в котором условие всегда имеет значение TRUE.
Мы решили использовать два типа условных перемещений: «переместиться, если не ноль» (
MNZ) и «переместиться, если меньше ноля» (MLZ). Функционально MNZ сводится к проверке, является ли любой бит данных равным 1, а MLZ — к проверке, имеет ли знаковый бит значение 1. Соответственно, они полезны для проверок равенства и сравнений. Мы выбрали эти два перемещения потому, что «переместиться, если ноль» (MEZ) должен был создавать из пустого сигнала сигнал TRUE, а «переместиться, если больше ноля» (MGZ) — это более сложная проверка, требующая, чтобы знаковый бит был равен 0 и при этом хотя бы один другой бит был равен 1.Арифметика
Следующими по важности инструкциями при принятии решения о дизайне процессора стали основные арифметические операции. Как упомянуто выше, мы используем последовательные данные little-endian, а выбор endian определялся простотой операций сложения/вычитания. При получении первым наименее значимого бита арифметические устройства могут легче отслеживать бит переноса.
Мы решили использовать для отрицательных чисел вид с дополнительным кодом, чтобы сделать сложение и вычитание более целостными. Стоит заметить, что в компьютере Wireworld используется обратный код.
Сложение и вычитание — удел нативной поддержки арифметики нашего процессора (кроме битовых сдвигов, которые мы рассмотрим позже). Другие операции, например, умножение, слишком сложны и не могут выполняться в нашей архитектуре, и должны реализовываться программно.
Битовые операции
Как можно догадаться, у нашего процессора есть инструкции
AND, OR и XOR. Вместо инструкции NOT мы решили использовать инструкцию «and-not» (ANT). Сложность с инструкцией NOT снова в том, что она должна создавать сигнал при его отсутствии, что сложно для клеточных автоматов. Инструкция ANT возвращает 1 только если первый битовый аргумент 1, а первый битовый аргумент — 0. То есть NOT x аналогично ANT -1 x (а также XOR -1 x). Более того, ANT универсальней и имеет основное преимущество при наложении маски: в случае программы для «Тетриса» мы будем использовать её для удаления тетромино.Битовый сдвиг
Операции битового сдвига — это самые сложные операции, обрабатываемые АЛУ. Они получают два входных значения: сдвигаемое значение и величину сдвига. Несмотря на их сложность (из-за переменной величины сдвига), эти операции критичны для многих важных задач, в том числе для «графических» операций, используемых в «Тетрисе». Битовые сдвиги также служат основой эффективных алгоритмов умножения/деления.
У нашего процессора есть три операции битового сдвига — «сдвиг влево» (
SL), «логический сдвиг влево» (SRL) и «арифметический сдвиг вправо» (SRA). Два первых битовых сдвига (SL и SRL) заполняют новые биты нолями (это значит, что сдвинутое вправо отрицательное число больше не будет отрицательным). Если второй аргумент сдвига находится вне интервала от 0 до 15, то, как можно догадаться, результатом будут одни ноли. Для последнего битового сдвига, SRA, битовый сдвиг сохраняет знак входных данных, а потому действует как истинное деление на два.Конвейер инструкций
Настало время поговорить о некоторых базовых подробностях архитектуры. Каждый цикл ЦП состоит из следующих пяти этапов:
1. Получение текущей инструкции из ПЗУ
Текущее значение PC используется для получения соответствующей инструкции из ПЗУ. Каждая инструкция имеет один опкод и три операнда. Каждый операнд состоит из одного слова данных и одного режима адресации. Эти части при считывании из ПЗУ отделяются друг от друга.
Опкод — это 4 бита, чтобы была возможность поддерживать 16 уникальных опкодов, 11 из которых назначены:
0000 MNZ Move if Not Zero
0001 MLZ Move if Less than Zero
0010 ADD ADDition
0011 SUB SUBtraction
0100 AND bitwise AND
0101 OR bitwise OR
0110 XOR bitwise eXclusive OR
0111 ANT bitwise And-NoT
1000 SL Shift Left
1001 SRL Shift Right Logical
1010 SRA Shift Right Arithmetic
1011 unassigned
1100 unassigned
1101 unassigned
1110 unassigned
1111 unassigned2. Запись результата (при необходимости) предыдущей инструкции в ОЗУ
Выполнение записи зависит от состояния предыдущей инструкции (например, от значения первого аргумента условного перемещения). Адрес записи определяется третьим операндом предыдущей инструкции.
Важно заметить, что запись выполняется после получения инструкции. Это приводит к созданию слота задержки перехода, в котором инструкция выполняется сразу после инструкции ветвления (любой операции, выполняющей запись в PC) вместо первой инструкции целевого адреса ветвления.
В некоторых случаях (например, при безусловных переходах), от слота задержки перехода можно избавиться оптимизацией. В других случаях это невозможно и инструкцию после ветвления нужно оставить пустой. Более того, такой тип слота задержки должен использовать целевой адрес ветвления, который на 1 адрес меньше самой целевой инструкции, чтобы учесть выполняемый инкремент PC.
Если вкратце, то поскольку вывод предыдущей инструкции записывается в ОЗУ после получения следующей инструкции, после условных переходов должна идти пустая инструкция. В противном случае PC не обновится для перехода правильно.
3. Считывание данных для аргументов текущей инструкции из ОЗУ
Как упомянуто выше, каждый из трёх операндов состоит и из слова данных, и из режима адресации. Слово данных равно 16 битам, той же разрядности, что и ОЗУ. Режим адресации занимает 2 бита.
Режимы адресации могут быть источником значительного усложнения для таких процессоров, потому что во многих режимах адресации в реальном мире требуются многоэтапные вычисления (например, прибавление смещений). В то же самое время гибкие режимы адресации играют важную роль в удобстве пользования процессором.
Мы стремились унифицировать концепции использования жёстко заданных чисел в качестве операндов и применения в качестве операндов адресов данных. Это привело к созданию режимов адресации на основе счётчиков: режим адресации операнда — это просто число, определяющее, сколько раз данные должны передаваться в цикле считывания ОЗУ. В них входят непосредственная, прямая, непрямая и двойная непрямая адресация.
00 непосредственная: жёстко заданное значение. (нет считывания из ОЗУ)
01 прямая: считывает данные из этого адреса ОЗУ. (одно считывание из ОЗУ)
10 непрямая: считывает данные из адреса, заданного в этом адресе. (два считывания из ОЗУ)
11 двойная непрямая: считывает данные из адреса, заданного в адресе, заданного этим адресом. (три считывания из ОЗУ)После выполнения расшифровки ссылки три операнда инструкции получают различные роли. Первый операнд — обычно первый аргумент для двоичного оператора, но также он служит условием, когда текущая инструкция является условным перемещением. Второй операнд служит вторым аргументом двоичного оператора. Третий оператор служит адресом назначения для результата инструкции.
Поскольку две первых инструкции служат данными, а третий — адресом, режимы адресации имеют слегка отличающиеся интерпретации в зависимости от позиции, в которой они используются. Например, прямой режим используется для считывания данных из фиксированного адреса ОЗУ (потому что требуется одно считывание из ОЗУ), но непосредственный режим используется для записи данных в фиксированный адрес ОЗУ (потому что не требуется ни одного считывания из ОЗУ).
4. Вычисление результат
Опкод и два его первых операнда отправляются в АЛУ для выполнения двоичной операции. Для арифметических, битовых и сдвиговых операций это означает выполнение соответствующей операции. Для условных перемещений это означает простой возврат второго операнда.
Опкод и первый операнд используются для вычисления условия, определяющего, нужно ли записывать результат в память. В случае условных перемещений это означает, что либо нужно определить, равен ли какой-нибудь из битов операнда 1 (для
MNZ), либо нужно определить, равен ли знаковый бит 1 (для MLZ). Если опкод не является условным перемещением, то запись выполняется всегда (условие всегда истинно).5. Инкремент счётчика команд
Затем, наконец, считывается, увеличивается и записывается значение счётчика команд.
Из-за того, что инкремент PC расположен между считыванием инструкции и записью инструкции, инструкция, увеличивающая значение PC на 1 является пустой (no-op). Инструкция, копирующая PC в самого себя, приводит к выполнению следующей инструкции два раза подряд. Но стоит учитывать, что если не уделять внимание конвейеру инструкций, то несколько инструкций PC подряд могут привести к комплексным эффектам, в том числе бесконечному зацикливанию.
Одиссея по созданию ассемблера для «Тетриса»
Мы создали для нашего процессора новый язык ассемблера QFTASM. Этот ассемблерный язык один в один соответствует машинному коду в ПЗУ компьютера.
Любая программа на QFTASM записывается построчной серией инструкций. Каждая строка форматируется следующим образом:
[номер строки] [опкод] [арг1] [арг2] [арг3]; [необязательный комментарий]Список опкодов
Как сказано выше, компьютером поддерживаются одиннадцать опкодов, каждый из которых имеет три операнда:
MNZ [проверка] [значение] [адрес назначения] – перемещение, если не ноль; задаёт [адрес назначения] для [значения], если [проверка] не равна нолю.
MLZ [проверка] [значение] [адрес назначения] – перемещение, если меньше ноля; задаёт [адрес назначения] [значению], если [проверка] не меньше ноля.
ADD [значение1] [значение2] [адрес назначения] – сложение; сохраняет [значение1] + [значение2] в [адресе назначения].
SUB [значение1] [значение2] [адрес назначения] – вычитание; сохраняет [значение1] - [значение2] в [адресе назначения].
AND [значение1] [значение2] [адрес назначения] – битовое И; сохраняет [значение1] & [значение] в [адресе назначения].
OR [значение1] [значение2] [адрес назначения] – битовое ИЛИ; сохраняет [значение1] | [значение2] в [адресе назначения].
XOR [значение1] [значение2] [адрес назначения] – битовое XOR; сохраняет [значение1] ^ [значение2] в [адресе назначения].
ANT [значение1] [значение2] [адрес назначения] – битовое И-НЕ; сохраняет [значение1] & (![значение2]) в [адресе назначения].
SL [значение1] [значение2] [адрес назначения] – сдвиг влево; сохраняет [значение1] << [значение2] в [адресе назначения].
SRL [значение1] [значение2] [адрес назначения] – логический сдвиг вправо; сохраняет [значение1] >>> [значение2] в [адресе назначения]. Не сохраняет знак.
SRA [значение1] [значение2] [адрес назначения] – арифметический сдвиг вправо; сохраняет [значение1] >> [значение2] в [адресе назначения] с сохранением знака.Режимы адресации
Каждый из операндов содержит и значение данных, и режим адресации. Значение данных описывается десятичным числом в интервале от -32768 до 65536. Режим адресации описывается однобуквенным префиксом к значению данных.
режим название префикс
0 непосредственный (нет)
1 прямой A
2 непрямой B
3 двойной непрямой CПример кода
Числа Фибоначчи в пяти строках:
0. MLZ -1 1 1; начальное значение
1. MLZ -1 A2 3; начало цикла, сдвиг данных
2. MLZ -1 A1 2; сдвиг данных
3. MLZ -1 0 0; конец цикла
4. ADD A2 A3 1; слот задержки перехода, вычисление следующего членаЭтот код вычисляет ряд чисел Фибоначчи, в адресе ОЗУ 1 содержится текущий член. После 28657 он быстро переполняется.
Код Грея:
0. MLZ -1 5 1; начальное значение адреса ОЗУ для записи
1. SUB A1 5 2; начало цикла, определение двоичного числа для преобразования в код Грея
2. SRL A2 1 3; сдвиг вправо на 1
3. XOR A2 A3 A1; XOR и сохранение кода Грея в адресе назначения
4. SUB B1 42 4; берём код Грея и вычитаем 42 (101010)
5. MNZ A4 0 0; если результат не равен нолю (код Грея != 101010), повторить цикл
6. ADD A1 1 1; слот задержки перехода, инкремент адреса назначенияЭта программа вычисляет код Грея и хранит код в последовательных адресах, начиная с адреса 5. В программе используется несколько полезных особенностей, например, непрямая адресация и условный переход. Она прекращается только когда получившийся код Грея равен
101010, что происходит при вводе 51 по адресу 56.Онлайн-интерпретатор
El'endia Starman создал очень полезный онлайн-интерпретатор. В нём можно пошагово выполнять код, устанавливать контрольные точки, вручную выполнять запись в ОЗУ и визуализировать состояние ОЗУ на экране.
Cogol
После выбора архитектуры и языка ассемблера следующим шагом в «программной» стороне проекта будет создание высокоуровневого языка, подходящего для «Тетриса». Поэтому я создал Cogol. Название является и каламбуром от «COBOL», и аббревиатурой «C of Game of Life», хотя и стоит заметить, что Cogol по сравнению с C — то же самое, что наш компьютер по сравнению с реальным.
Cogol существует всего на один уровень выше языка ассемблера. В целом, большинство строк программы на Cogol соответствуют строкам на ассемблере, но у языка есть несколько важных особенностей:
- Основные возможности включают в себя именованные переменные с присвоением и операторы с более читаемым синтаксисом. Например,
ADD A1 A2 3превращается вz = x + y;. Компилятор привязывает переменные к адресам. - Конструкции циклов, такие как
if(){},while(){}иdo{}while();позволяют компилятору обрабатывать ветвление. - Одномерные массивы (с арифметикой указателей), которые используются для поля «Тетриса».
- Подпрограммы и стек вызовов. Они используются, чтобы избежать дублироания больших фрагментов кода и для поддержки рекурсии.
Компилятор (который я написал с нуля) очень прост/наивен, но я постарался вручную оптимизировать некоторые конструкции языка, чтобы достичь малой длины скомпилированных программ.
Вот краткий обзор работы различных особенностей языка:
Токенизация
Исходный код линейно токенизируется (за один проход) на основании простых правил о том, какие символы могут соседствовать в токене. Когда обнаруживается символ, который не может быть соседним с последним символом текущего токена, текущий токен считается завершённым, а новый символ начинает новый токен. Некоторые символы (например,
{ или ,) не могут соседствовать ни с какими другими, потому сами являются отдельными токенами. Другие (например, > или =) могут соседствовать только сами с собой, то есть могут создавать такие токены, как >>> или ==. Символы пробелов принудительно выставляют границы между токенами, но сами в результат не включаются. Самый сложный для токенизации символ — это -, потому что он может обозначать и вычитание, и унарное отрицание, а потому требует особой обработки.Парсинг
Парсинг тоже выполняется за один проход. В компиляторе есть методы обработки каждой из конструкций языка, и после передачи различным методам компилятора токены извлекаются из глобального списка токенов. Если компилятор обнаруживает неожиданный токен, то выдаёт синтаксическую ошибку.
Распределение глобальной памяти
Компилятор назначает каждой глобальной переменной (слову или массиву) собственный адрес (адреса) в ОЗУ. Все переменные необходимо объявлять с помощью ключевого слова
my, чтобы компилятор знал, что нужно выделить для них место. Гораздо круче, чем именованные глобальные перменные — это управление памятью временных адресов. Многим инструкциям (в частности условным операторам и многим операциям доступа к массивам) требуются «временные» адреса для хранения промежуточных вычислений. В процессе компиляции компилятор при необходимости выделяет и освобождает временные адреса. Если компилятору нужно больше временных адресов, он выделят под них больше ОЗУ. Полагаю, что обычно программы используют всего несколько временных адресов, при этом каждый адрес используется много раз…Конструкции
IF-ELSEКонструкции
if-else имеют стандартный для C синтаксис:другой код
if (cond) {
первое тело
} else {
второе тело
}
другой кодПри преобразовании в QFTASM код получает следующую структуру:
другой код
проверка условия
условный переход
первое тело
безусловный переход
второе тело (место условного перехода)
другой код (место безусловного перехода)Если выполняется первое тело, то второе пропускается. Если первое тело пропускается, то выполняется второе.
В ассемблере «проверка условия» обычно бывает обычным вычитанием, и знак результата определяет, нужно ли совершить переход или выполнить тело. Для обработки таких неравенств, как
> или <= используется инструкция MLZ. Инструкция MNZ используется для обработки ==, потому что она выполняет переход через тело, когда разность не равна нулю (то есть когда аргументы неравны). Условия с несколькими выражениями пока не поддерживаются.Если конструкция
else отсутствует, то безусловный переход тоже опускается, и код на QFTASM выглядит так:другой код
проверка условия
условный переход
тело
другой код (место условного перехода)Конструкции
WHILEКонструкции
while тоже имеют стандартный для C синтаксис:другой код
while (условие) {
тело
}
другой кодПри преобразовании в QFTASM код имеет такую схему:
другой код
безусловный переход
тело (место условного перехода)
проверка условия (место безусловного перехода)
условный переход
другой кодПроверка условия и условный переход находятся в конце блока, и это значит, что они заново выполняются после каждого выполнения блока. Когда условие возвращает false, тело не выполняется и цикл заканчивается. Во время начала выполнения цикла поток управления перескакивает через тело цикла к коду условия, поэтому если в первый раз условие ложно, то тело никогда не выполняется.
Инструкция
MLZ используется для обработки неравенств вида > или <=. В отличие от выполнения конструкций if, инструкция MNZ используется для обработки !=, потому что она переходит к телу, когда разность не равна нулю (то есть когда аргументы неравны).Конструкции
DO-WHILEЕдинственная разница между
while и do-while заключается в том, что тело цикла do-while в первый раз не обходится, поэтому оно всегда выполняется хотя бы один раз. Обычно я использую конструкции do-while для экономии пары строк ассемблерного кода, когда точно знаю, что цикл никогда не придётся пропускать полностью.Массивы
Одномерные массивы реализованы как смежные блоки памяти. Все массивы имеют фиксированную длину, зависящую от объявления. Массивы объявляются следующим образом:
my alpha[3]; # пустой массив
my beta[11] = {3,2,7,8}; # в первые четыре элемента заранее записываются эти значенияВот возможное распределение ОЗУ для массива, показывающее, что для него зарезервированы адреса 15-18:
15: alpha
16: alpha[0]
17: alpha[1]
18: alpha[2]Адреса, помеченные как
alpha, заполняются указателем на местонахождение alpha[0], так что в этом случае адрес 15 содержит значение 16. Переменную alpha возможно использовать внутри кода Cogol как указатель стека, если необходимо использовать этот массив как стек.Доступ к элементам массива выполняется с помощью стандартной записи
array[index]. Если значение index является константой, то эта ссылка автоматически заполняется абсолютным адресом элемента. В противном случае она выполняет арифметику указателей (просто сложение) для нахождения нужного абсолютного адреса. Возможно также встроенное индексирование, например alpha[beta[1]].Подпрограммы и вызовы
Подпрограммы — это блоки кода, которые можно вызывать из различных контекстов, они позволяют избежать дублирования кода и создавать рекурсивные программы. Вот пример программы с рекурсивной подпрограммой для генерирования чисел Фибоначчи (самый медленный алгоритм):
# рекурсивное вычисление десятого числа Фибоначчи
call display = fib(10).sum;
sub fib(cur,sum) {
if (cur <= 2) {
sum = 1;
return;
}
cur--;
call sum = fib(cur).sum;
cur--;
call sum += fib(cur).sum;
}Подпрограмма объявляется ключевым словом
sub и может быть расположена в любом месте программы. В каждой подпрограмме может быть несколько локальных переменных, каждая из которых объявляется как часть её списка аргументов. Таким аргументам также задаются значения по умолчанию.Для обработки рекурсивных вызовов локальные переменные подпрограммы хранятся в стеке. Последняя статичная переменная в ОЗУ является указателем стека вызовов, а вся память после неё служит стеком вызовов. При вызове подпрограммы она создаёт в стеке вызовов новый кадр, в который включаются все локальные переменные и адрес возврата (ПЗУ). Каждой подпрограмме в программе передаётся один статичный адрес ОЗУ, служащий указателем. Этот указатель задаёт местоположение «текущего» вызова подпрограммы в стеке вызовов. Выполнение ссылок на локальную переменную выполняется с помощью значения этого статичного указателя плюс смещения, чтобы задать адрес этой конкретной локальной переменной. Также в стеке вызовов содержится предыдущее значение статичного указателя. Вот распределение переменных для статичной ОЗУ и кадра вызовов подпрограммы для приведённой выше программы:
RAM map:
0: pc
1: display
2: scratch0
3: fib
4: scratch1
5: scratch2
6: scratch3
7: call
fib map:
0: return
1: previous_call
2: cur
3: sum
Интересный аспект подпрограмм заключается в том, что они не возвращают никаких конкретных значений. После выполнения подпрограммы можно считывать все её локальные переменные, поэтому из вызова подпрограммы можно извлечь множество данных. Это реализуется хранением указателя для этого конкретного вызова подпрограммы, который можно затем использовать для восстановления всех локальных переменных из (недавно освобождённого) кадра стека.
Подпрограмму можно вызвать несколькими способами, все они используют ключевое слово
call:call fib(10); # выполняется подпрограмма, никакого возвращаемого значения не сохраняется
call pointer = fib(10); # выполняется подпрограмма и возвращается указатель
display = pointer.sum; # доступ к локальной переменной и её присвоение глобальной переменной
call display = fib(10).sum; # немедленное сохранение возвращаемого значения
call display += fib(10).sum; # с возвращаемым значением можно также использовать другие виды операторов присвоенияДля вызова подпрограммы можно задать в качестве аргументов любое количество значений. Все неуказанные аргументы будут заполнены их значениями по умолчанию (если они есть). Если аргумент не указан и не имеет очищенного значения по умолчанию (для экономии инструкций/временит), то может получить в начале подпрограммы любое значение.
Указатели — это способ доступа к нескольким локальным переменным подпрограммы, однако важно заметить, что этот указатель не только является временным: при выполнении другого вызова подпрограммы данные, на которые указывает указатель, будут уничтожены.
Метки отладки
Любому блоку
{...} в программе на Cogol может предшествовать метка описания из нескольких слов. Эта метка присоединяется к скомпилированному ассемблерному коду в качестве комментария, и может быть очень полезной для отладки, потому что она упрощает поиск нужных фрагментов кода.Оптимизация слотов задержки перехода
Для повышения скорости скомпилированного кода компилятор Cogol выполняет в качестве последнего прохода по коду QFTASM очень простую оптимизацию слотов задержки перехода. Для любого безусловного перехода с пустым слотом задержки перехода слот задержки может быть заполнен первой инструкцией адрес перехода, а адрес перехода увеличивается на единиц, чтобы указывать на следующую инструкцию. Обычно это экономит один цикл при каждом выполнении безусловного перехода.
Написание кода «Тетриса» на Cogol
Готовая программа «Тетриса» была написана на Cogol, и её исходный код доступен здесь. Скомпилированный код QFTASM доступен здесь. Для удобства постоянная ссылка указана здесь: Tetris in QFTASM. Поскольку нашей целью было создание ассемблерного кода (а не кода на Cogol), получившийся код на Cogol довольно громоздок. Многие части программы должны быть расположены в подпрограммах, но эти подпрограммы на самом деле так коротки, что дублирование кода экономит больше инструкций, чем конструкции
call. Готовый код в дополнение к основному коду содержит всего одну подпрограмму. Кроме того, многие массивы были удалены и заменены либо на список отдельных переменных аналогичной длины, или на множество жёстко заданных в программе чисел. Готовый скомпилированный код на QFTASM содержит менее 300 инструкций, хотя он и немного длиннее, чем сам исходник на Cogol.Часть 5: сборка, трансляция и будущее
Получив от компилятора ассемблерную программу, мы можем приступить к сборке ПЗУ для компьютера Varlife и трансляции всего в большой паттерн игры «Жизнь»!
Сборка
Сборка ассемблерной программы в ПЗУ выполняется почти так же, как в традиционном программировании: каждая инструкция транслируется в двоичный аналог, а затем все они конкатенируются в один большой двоичный объект, называемый исполняемым файлом. Для нас единственная разница заключается в том, что двоичный объект должен транслироваться в цепи и подсоединиться к компьютеру.
K Zhang написал CreateROM.py, скрипт на Python для Golly, который выполняет сборку и трансляцию. Он довольно прост: скрипт получает из буфера обмена ассемблерную программу, собирает её в двоичный файл и транслирует его в цепь. Вот пример программы проверки простоты, включённой в состав скрипта:
#0. MLZ -1 3 3;
#1. MLZ -1 7 6; preloadCallStack
#2. MLZ -1 2 1; beginDoWhile0_infinite_loop
#3. MLZ -1 1 4; beginDoWhile1_trials
#4. ADD A4 2 4;
#5. MLZ -1 A3 5; beginDoWhile2_repeated_subtraction
#6. SUB A5 A4 5;
#7. SUB 0 A5 2;
#8. MLZ A2 5 0;
#9. MLZ 0 0 0; endDoWhile2_repeated_subtraction
#10. MLZ A5 3 0;
#11. MNZ 0 0 0; endDoWhile1_trials
#12. SUB A4 A3 2;
#13. MNZ A2 15 0; beginIf3_prime_found
#14. MNZ 0 0 0;
#15. MLZ -1 A3 1; endIf3_prime_found
#16. ADD A3 2 3;
#17. MLZ -1 3 0;
#18. MLZ -1 1 4; endDoWhile0_infinite_loopОна преобразуется в следующий двоичный файл:
0000000000000001000000000000000000010011111111111111110001
0000000000000000000000000000000000110011111111111111110001
0000000000000000110000000000000000100100000000000000110010
0000000000000000010100000000000000110011111111111111110001
0000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000011110100000000000000100000
0000000000000000100100000000000000110100000000000001000011
0000000000000000000000000000000000000000000000000000000000
0000000000000000000000000000000000110100000000000001010001
0000000000000000000000000000000000000000000000000000000001
0000000000000000000000000000000001010100000000000000100001
0000000000000000100100000000000001010000000000000000000011
0000000000000001010100000000000001000100000000000001010011
0000000000000001010100000000000000110011111111111111110001
0000000000000001000000000000000000100100000000000001000010
0000000000000001000000000000000000010011111111111111110001
0000000000000000010000000000000000100011111111111111110001
0000000000000001100000000000000001110011111111111111110001
0000000000000000110000000000000000110011111111111111110001При трансляции в цепи Varlife он выглядит вот так:


Затем ПЗУ соединяется с компьютером, в результате чего получается полностью функциональная программа в Varlife. Но мы ещё не закончили…
Трансляция в игру «Жизнь»
Всё это время мы работали над различными слоями абстракции поверх игры «Жизнь». Но теперь настала пора стянуть занавес абстракции и транслировать нашу работу в паттерн игры «Жизнь». Как сказано ранее, мы используем в качестве основы Varlife OTCA-метапиксель. Поэтому последним шагом будет преобразование каждой клетки Varlife в метапиксель игры «Жизнь».
К счастью, в Golly есть скрипт (metafier.py), который может преобразовывать с помощью OTCA-метапикселей паттерны из различных правил в паттерны игры «Жизнь». К сожалению, он способен только преобразовывать паттерны с одним глобальным набором правил, поэтому не работает в Varlife. Для решения этой проблемы я написал модифицированную версию, поэтому правило для каждого метапикселя генерируется для Varlife на поклеточном основании.
Итак, наш компьютер (с ПЗУ «Тетриса») имеет граничный прямоугольник 1 436 x 5 082. Из 7 297 752 клеток этого прямоугольника 6 075 811 пусты, то есть популяция составляет 1 221 941 клеток. Каждая из этих клеток должна быть транслирована в OTCA-метапиксель, имеющий граничный прямоугольник 2048 x 2048 с популяцией, равной или 64 691 (для метапикселя в состоянии «включено») или 23 920 (для состояния «выключено»). Это значит, что конечный результат будет иметь граничный прямоугольник 2 940 928 x 10 407 936 (плюс несколько тысяч для границ метапикселей) с популяцией в пределах от 29 228 828 720 до 79 048 585 231. При 1 бите на одну живую клетку для представления всего компьютера и ПЗУ требуется 27-74 гибибайт.
Я изложил эти вычисления только потому, что пренебрёг ими перед запуском скрипта, и очень быстро столкнулся с нехваткой памяти на своём компьютере. После панического выполнения команды
kill я внёс модификацию в скрипт metafier. Через каждые 10 строк метапикселей паттерн сохраняется на диск (как сжатый gzip файл RLE), после чего сетка очищается. Это увеличивает время выполнения трансляции и занимает больше места на диске, зато уровень использования памяти остаётся в приемлемых границах. Golly использует расширенный формат RLE, в который включено расположение паттерна, поэтому это не добавляет сложности к загрузке паттерна — просто нужно открыть все файлы паттернов в одном слое.На основе моей работы K Zhang создал улучшенный скрипт metafier, в котором используется формат файлов MacroCell, более эффективный при загрузке больших паттернов, чем RLE. Этот скрипт работает значительно быстрее (всего несколько секунд, в отличие от нескольких часов исходного скрипта metafier), создаёт гораздо меньше выходных данных (121 КБ вместо 1,7 ГБ), и может преобразовать весь компьютер и ПЗУ в метапиксели одним махом, не занимая огромный объём памяти. В нём используется тот факт, что файлы MacroCell кодируют описывающие паттерны деревья. Метапиксели с помощью специального файла шаблона загружаются в дерево и после определённых вычислений и модификаций к нему можно просто присоединить паттерн Varlife.
Файл паттернов всего компьютера и ПЗУ в игре «Жизнь» можно взять здесь.
Будущее проекта
Итак, мы сделали «Тетрис», и на этом всё закончено, правда? Ничего подобного. У нас есть для этого проекта и другие цели, над которыми мы работаем:
- muddyfish и Kritixi Lithos продолжают работу над высокоуровневым языком, компилируемым в QFTASM.
- El'endia Starman работает над обновлениями онлайн-интерпретатора QFTASM.
- quartata работает над GCC-бэкендом, который позволить с помощью GCC выполнять компиляцию независимого кода на C и C++ (а возможно и на других языках, например, Fortran, D или Objective-C) в QFTASM. Это позволит создавать более сложные программы на более знакомом языке, хоть и без стандартной библиотеки.
- Одно из самых серьёзных препятствий, которые нам нужно преодолеть, чтобы двигаться дальше, заключается в том, что наши инструменты не могут создавать позиционно-независимый код (PIC) (т.е. относительные переходы). Без PIC мы не можем использовать ссылки, то есть не можем воспользоваться преимуществами компоновки с готовыми библиотеками. Мы работаем над поиском способа правильной реализации PIC.
- Мы размышляем над следующей программой, которую стоит написать для компьютера QFT. Пока хорошей целью для нас выглядит Pong.
Часть 6: новый компилятор для QFTASM
Хотя языка Cogol и достаточно рудиментарной реализации «Тетриса», он слишком простой и низкоуровневый для программирования широкого назначения на хорошо читаемом уровне.
Мы начали работу над новым языком в сентябре 2016 года. Процесс развития языка шёл медленно из-за трудно понимаемых, как и в реальной жизни, ошибок.
Мы создали низкоуровневый язык с похожим на Python синтаксисом, включая простую систему типов, подпрограммы с поддержкой рекурсии и операторы встраивания.
Компилятор из текста в QFTASM был создан на четыре этапа: токенизатор, дерево грамматики, высокоуровневый компилятор и низкоуровневый компилятор.
Токенизатор
Разработка на Python началась с использования встроенное библиотеки токенизатора, то есть этот этап был довольно простым.
Необходимо было внести только небольшие изменения в выводимые по умолчанию данных, в том числе вырезание комментариев (но не
#include).Дерево грамматики
Дерево грамматики создавалось с расчётом на удобную расширяемость без необходимости изменения исходного кода.
Структура дерева хранится в файле XML, который содержит структуру составляющих дерево узлов и их соединений с другими узлами и токенами.
Грамматика должна была поддерживать повторяющиеся узлы, а также необязательные узлы. Мы решили эту задачу добавлением метатегов, описывающих способ считывания токенов.
Генерируемые токены затем парсятся по правилам грамматики таким образом, что выходные данные формируют дерево элементов грамматики, например,
sub и generic_variables, которые в свою очередь содержат другие элементы грамматики и токены.Компиляция в высокоуровневый код
Каждая функция языка должна компилироваться в высокоуровневые конструкции. Например,
assign(a, 12) и call_subroutine(is_prime, call_variable=12, return_variable=temp_var). В этом сегменте выполняются такие функции, как встраивание элементов. Они определяются как operator, их особенность в том, что они встраиваются каждый раз, когда используется такой оператор, как + или %. Поэтому они более ограничены, чем обычный код — они не могут использовать собственный оператор и любой другой оператор, зависящий от определённого.В процессе встраивания внутренние переменные заменяются на те, которые были вызваны. Таким образом это:
operator(int a + int b) -> int c
return __ADD__(a, b)
int i = 3+3превращается в
int i = __ADD__(3, 3)Однако такое поведение может быть вредоносным и подверженным ошибкам, если входная и выходная переменные указывают на одно место в памяти. Для использования более «безопасного» поведения ключевое слово
unsafe регулирует процесс компиляции таким образом, чтобы эти дополнительные переменные при необходимости создавались и копировались из подстановки.Временные переменные (scratch variable) и сложные операции
Математические операции вида
a += (b + c) * 4 невозможно вычислить без использования дополнительных ячеек памяти. Высокоуровневый компилятор справляется с этой проблемой, разделяя операции на различные части:scratch_1 = b + c
scratch_1 = scratch_1 * 4
a = a + scratch_1Таким образом вводится концепция временных переменных, используемых для хранения промежуточной информации вычислений. Они выделяются при необходимости и освобождаются после завершения работы в общий пул. Это позволяет снизить количество требуемых для работы временных участков памяти. Временные переменные считаются глобальными.
Каждая подпрограмма имеет собственный VariableStore для хранения ссылок на все используемые подпрограммой переменные и их типов. В конце компиляции они транслируются в относительные смещения от начала хранилища, а затем им даются действительные адреса в ОЗУ.
Структура ОЗУ
Счётчик команд
Локальные переменные подпрограммы
Локальные переменные операторов (используются повторно)
Временные переменные
Переменная результата
Указатель стека
Стек
...Низкоуровневая компиляция
Единственное, с чем приходится работать низкоуровневому компилятору — это
sub, call_sub, return, assign, if и while. Это сильно уменьшенный список задач, который более удобно транслировать в инструкции QFTASM.sub
Она задаёт начало и конец именованной подпрограммы. Низкоуровневый компилятор добавляет метки, а в случае подпрограммы
main добавляет инструкцию выхода (переход к концу ПЗУ).if и while
Низкоуровневые интерпретаторы
while и if довольно просты: они получают указатели на их условия и зависящий от них переход. Циклы while немного отличаются в том, что они компилируются как...
условие
переход к проверке
код
условие
если условие: переход к коду
...call_sub и return
В отличие от большинства архитектур, компьютер, для которого мы выполняем компилирование, не имеет аппаратной поддержки добавления и извлечения из стека. Это значит, что добавление и извлечение из стека занимают по две инструкции. В случае извлечения мы выполняем декремент указателя стека и копируем значение по адресу. В случае добавления мы копируем значение из адреса в адрес текущего указателя стека, а затем выполняем инкремент.
Все локальные переменные подпрограммы хранятся в постоянном месте ОЗУ, задаваемом во время компиляции. Для реализации рекурсии все локальные переменные для функции в начале вызова помещаются в стек. Затем аргументы подпрограммы копируются в их позицию в хранилище локальных переменных. Значение адреса возврата добавляется в стек и подпрограмма выполняется.
Когда встречается конструкция
return, вершина стека извлекается и счётчик команд устанавливается на это значение. Значения для локальных переменных вызывающей подпрограммы извлекаются из вершины стека и возвращаются в их предыдущую позицию.assign
Присвоение переменных компилировать легче всего: нужно взять переменную и значение и скомпилировать их в одну строку:
MLZ -1 VALUE VARIABLEНазначение адресов перехода
Наконец, компилятор создаёт адреса перехода для добавленных к инструкциям меток. Определяется абсолютная позиция меток, после чего ссылки на эти метки заменяются этими значениями. Сами метки удаляются из кода, после чего, наконец, к скомпилированному коду добавляются номера инструкций.
Поэтапный пример компиляции
Мы прошли по всем этапам, теперь давайте пошагово пройдём по процессу компиляции настоящей программы.
#include stdint
sub main
int a = 8
int b = 12
int c = a * bОтлично, всё довольно просто. Очевидно, что в конце программы
a = 8, b = 12, c = 96. Для начала давайте вставим соответствующие части из stdint.txt:operator (int a + int b) -> int
return __ADD__(a, b)
operator (int a - int b) -> int
return __SUB__(a, b)
operator (int a < int b) -> bool
bool rtn = 0
rtn = __MLZ__(a-b, 1)
return rtn
unsafe operator (int a * int b) -> int
int rtn = 0
for (int i = 0; i < b; i+=1)
rtn += a
return rtn
sub main
int a = 8
int b = 12
int c = a * bТак, всё стало немного сложнее. Давайте перейдём к токенизатору и посмотрим, что получится. На этом этапе у нас есть только линейный поток токенов без какой-либо структуры
NAME NAME operator
LPAR OP (
NAME NAME int
NAME NAME a
PLUS OP +
NAME NAME int
NAME NAME b
RPAR OP )
OP OP ->
NAME NAME int
NEWLINE NEWLINE
INDENT INDENT
NAME NAME return
NAME NAME __ADD__
LPAR OP (
NAME NAME a
COMMA OP ,
NAME NAME b
RPAR OP )
...Теперь все токены будут пропущены через грамматический парсер, который выведет дерево с названием каждой из частей. Оно демонстрирует высокоуровневую структуру считанного кода.
GrammarTree file
'stmts': [GrammarTree stmts_0
'_block_name': 'inline'
'inline': GrammarTree inline
'_block_name': 'two_op'
'type_var': GrammarTree type_var
'_block_name': 'type'
'type': 'int'
'name': 'a'
'_global': False
'operator': GrammarTree operator
'_block_name': '+'
'type_var_2': GrammarTree type_var
'_block_name': 'type'
'type': 'int'
'name': 'b'
'_global': False
'rtn_type': 'int'
'stmts': GrammarTree stmts
...Это дерево грамматики задаёт информацию для парсинга высокоуровневым компилятором. В неё входит информация о типах структур и атрибутах переменных. Затем дерево грамматики берёт эту информацию и назначает переменные, необходимые для подпрограмм. Дерево также вставляет все подстановки.
('sub', 'start', 'main')
('assign', int main_a, 8)
('assign', int main_b, 12)
('assign', int op(*:rtn), 0)
('assign', int op(*:i), 0)
('assign', global bool scratch_2, 0)
('call_sub', '__SUB__', [int op(*:i), int main_b], global int scratch_3)
('call_sub', '__MLZ__', [global int scratch_3, 1], global bool scratch_2)
('while', 'start', 1, 'for')
('call_sub', '__ADD__', [int op(*:rtn), int main_a], int op(*:rtn))
('call_sub', '__ADD__', [int op(*:i), 1], int op(*:i))
('assign', global bool scratch_2, 0)
('call_sub', '__SUB__', [int op(*:i), int main_b], global int scratch_3)
('call_sub', '__MLZ__', [global int scratch_3, 1], global bool scratch_2)
('while', 'end', 1, global bool scratch_2)
('assign', int main_c, int op(*:rtn))
('sub', 'end', 'main')Затем низкоуровневый компилятор должен преобразовать этот высокоуровневый вид в код QFTASM. Переменным назначается место в ОЗУ следующим образом:
int program_counter
int op(*:i)
int main_a
int op(*:rtn)
int main_c
int main_b
global int scratch_1
global bool scratch_2
global int scratch_3
global int scratch_4
global int <result>
global int <stack>Затем простые инструкции компилируются. Наконец, добавляются номера инструкций, и в результате получается исполняемый код QFTASM.
0. MLZ 0 0 0;
1. MLZ -1 12 11;
2. MLZ -1 8 2;
3. MLZ -1 12 5;
4. MLZ -1 0 3;
5. MLZ -1 0 1;
6. MLZ -1 0 7;
7. SUB A1 A5 8;
8. MLZ A8 1 7;
9. MLZ -1 15 0;
10. MLZ 0 0 0;
11. ADD A3 A2 3;
12. ADD A1 1 1;
13. MLZ -1 0 7;
14. SUB A1 A5 8;
15. MLZ A8 1 7;
16. MNZ A7 10 0;
17. MLZ 0 0 0;
18. MLZ -1 A3 4;
19. MLZ -1 -2 0;
20. MLZ 0 0 0;Синтаксис
Итак, у нас есть простой язык, и нам нужно написать на нём небольшую программу. Мы используем отступы как в Python, разделяя логические блоки и поток команд. Это значит, что в наших программах важны пробелы. Каждая готовая программа имеет подпрограмму
main, которая действует как функция main() C-подобных языках. Функция выполняется в начале программы.Переменные и типы
Когда переменная задаётся впервые, ей нужен связанный с ней тип. Пока у нас есть заданные типы
int и bool с заданным для массивов, но не для компилятора синтаксисом.Библиотеки и операторы
Имеется библиотека
stdint.txt, задающая основные операторы. Если она не встроена в программу, то даже простейшие операторы не будут определены. Можно использовать эту библиотеку с помощью #include stdint. stdint определяет такие операторы, как +, >> и даже * с %, ни один из которых не имеет непосредственного опкода QFTASM.Кроме того, язык позволяет выполнять прямой вызов опкодов QFTASM с помощью
__OPCODENAME__.В
stdint сложение определяется следующим образомoperator (int a + int b) -> int
return __ADD__(a, b)Эта запись определяет, что оператор
+ должен делать, когда ему передают два числа int. Комментарии (41)

miga
31.10.2017 15:19Дивись, Микола, як они наш NAND называют — ANT!
Поправочка, NAND это все-таки другое
Pentoxide
31.10.2017 16:14Ждем веб-сервера на qftasm?
vesper-bot
31.10.2017 17:48+2Вначале нужен интерфейс между полем игры "Жизнь" и ПК, исполняющим код. Сейчас у них интерфейс однонаправленный, через остановку эволюции и перезапись поля, а читается вообще глазами. А так вообще, если уж ждать чего-то, то Дума.




Petrenuk
31.10.2017 19:08+2Фантастика на самом деле, такие исследования открывают глаза на истинную природу вещей, показывая как из простейших правил вырастают структуры неограниченной сложности. Представляете сознательного наблюдателя внутри такой Вселенной из метапикселей, который гадает почему пространство и время квантовано? :)
Если кому интересно, этот вопрос обсуждается в замечательной книге Грега Игана «Permutation City». Такая вот Вселенная из элементарных кирпичиков там называется Autoverse.
WinPooh73
31.10.2017 20:39Вы меня опередили, мне тоже при чтении статьи захотелось перечитать "Город перестановок" :)
Интересно было бы посчитать оценку, с какой скоростью будут падать фигуры в этой реализации тетриса на современном оборудовании. В упомянутой книге соотношения скорости модели и реального мира — важная часть сюжета.
WinPooh73
31.10.2017 20:42Там рассматривается два подхода, если я правильно помню. Autoverse — это моделирование из первых принципов, на основе клеточных автоматов. А вторая линия шла от феноменологических копий организма человека. Интересно, что сознание впервые удалось воссоздать именно в ней.



jaiprakash
31.10.2017 22:25Зашёл прочитать комментарий о запуске игры «Жизнь» на этом компьютере.
ripatti
01.11.2017 01:29Игру «Жизнь» так-то можно прямо на метаклетках запустить

TheShock
01.11.2017 03:44А реально запустить «Жизнь» на этой версии «Жизни», которая запущена на «Жизни»?
Если да — насколько мощнее комп должен быть? Какие там порядки?
zagayevskiy
01.11.2017 10:53Очевидно, что да. Каждая метаклетка это 2048*2048. Вот и считайте. Очень мощный, грубо говоря.
TheShock
01.11.2017 13:05Чтобы запустить глайдер необходимо, допустим 23 клеток по высоте и 24 клеток по ширине.
Каждая мета-мета-клетка состоит из 211*211 метаклеток, каждая из которых из 211*211.
Следовательно, необходимо 23*24*211*211*211*211 = 251 бит = 248 байт = 256 терабайт памяти. Лет через 20 можно будет поиграться.
Я нигде не ошибся?
Кстати, а сколько поколений необходимо на смену одного мета-поколения?

mikhanoid
31.10.2017 22:29Оно, конечно, очень круто всё. И мне всегда было крайне интересно, откуда у людей берутся ресурсы времени и деньги на разработку подобных проектов?

bogolt
31.10.2017 23:28Вероятно оттуда же откуда у других людей находится время на просмотр фильмов, чтение книг, компьютерные игры, спорт и тд…
WerewolfPrankster
01.11.2017 01:17Я слепой или не нашел как посмотреть, как это непосредственно работает в самой игре жизнь?

PatientZero Автор
01.11.2017 11:38См. раздел Запуск «Тетриса». Там есть ссылка с онлайн-интерпретатором программы, и можно даже в сам «Тетрис» поиграть.

alhimik45
01.11.2017 11:56Это интерпретатор высокоуровневой проги, так неинтересно) Хотя сейчас запустить это в самой "Жизни" ресурсов не хватит)
WerewolfPrankster
01.11.2017 17:46Я все таки нашел. Если скачать файл для Golly из статьи, можно в нем запустить. Поиграть правда не получится. Но оно работает!
Jamdaze
01.11.2017 06:59Не нашел ничего на ютубе по вашему проекту, хотелось бы посмотреть на это всё в движении.
zagayevskiy
01.11.2017 10:58конечный результат будет иметь граничный прямоугольник 2 940 928 x 10 407 936 (плюс несколько тысяч для границ метапикселей) с популяцией в пределах от 29 228 828 720 до 79 048 585 231. При 1 бите на одну живую клетку для представления всего компьютера и ПЗУ требуется 27-74 гибибайт.
Кажется довольно очевидным, что видео не будет. Обсчитывать такое поле с приемлемой частотой нереально на пк.

rumkin
01.11.2017 11:57Но ведь можно сделать игру жизнь распределенной...
zagayevskiy
01.11.2017 12:02Судя по статья они этого не сделали, и непонятно, будут ли. И, кажется, что при распределённой игре всё равно будет затруднительно сделать видео процесса.
rumkin
01.11.2017 12:15Но можно будет снять видео по частям, а потом собрать в более-менее наглядном виде.
zagayevskiy
01.11.2017 12:23Итак, наш компьютер (с ПЗУ «Тетриса») имеет граничный прямоугольник 1 436 x 5 082.
Даже на метаклетках не влезает в 4К. Элементов Жизни видно не будет ни при каких условиях. Конечно, можно зумиться, но это уже не то, имхо.
rumkin
01.11.2017 12:31Снять видео как в комментарии https://habrahabr.ru/post/338584/#comment_10500928 можно будет. Думаю, это вполе подойдет для составления общей картины.
mayorovp
01.11.2017 12:49Так ведь метаклетки OTCA очень хорошо дружат с алгоритмом HashLife. Надо только соединить этот алгоритм с алгоритмом отрисовки чтобы не перерисовывать каждый кадр все 20 квадрилионов клеток каждый шаг.
WerewolfPrankster
01.11.2017 23:04А он и так уже в HashLife формате github.com/QuestForTetris/QFT/blob/master/TetrisOTCAMP.mc.gz
Jamdaze
02.11.2017 12:49128Гб и более это вполне реально для современных рабочих станций, совершенно необязательно рендерить сие в реальном времени.

Deosis
03.11.2017 09:49Есть большой простор для миниатюризации.
Наверняка многие компоненты можно реализовать в меньшей площади.
napa3um
Использовались ли какие-нибудь эволюционные/генетические алгоритмы для выращивания логических вентилей и других узлов компьютера, или всё подбиралось руками?
napa3um
Не очень понял минусы без пояснений, мой комментарий оскорбительный, или он кажется глупым? Мне думается, что подобрать содержимое клеточного поля, реализующего, например, тактовый генератор или логический вентиль, задав краевые условия (входы-выходы) и ограничив площадь, генетическим алгоритмом вполне возможно. Другой вопрос, что скорость сходимости может оказаться за пределами практической применимости, хотелось бы узнать, пробовали ли на практике такой вариант.
Ugrum
Это перевод. Соответственно ваш вопрос адресован переводчику, который больше чем изложено в статье, вам ничего не расскажет (скорее всего).
napa3um
Этот вопрос адресуется любому, кто на него способен ответить, не обязательно авторам или переводчикам статьи. Или вопросительные знаки в комментариях к переводам на Хабре являются моветоном сами по себе?
perfect_genius
Можно начинать с «Интересно, использовались ли какие-нибудь эволюционные...»
napa3um
Мне кажется, всё-таки, что и мой формат вопроса вполне приемлем (недвусмысленен и вежлив). Но спасибо за совет :).
arandomic
Нет, это отдельное удовольствие — разработка вентилей под клеточные автоматы.
Для жизни вентили довольно давно. В данном случае они подобрали клеточные правила (VarLife), чтобы логику максимально упростить и уменьшить в площади.