
У меня иногда складывается впечатление, что не он служит для нас, а мы служим для этого формата. Поэтому — сэр Markdown.
— Мы знаем, что ныне лежит на весах
И что совершается ныне.
Час мужества пробил на наших часах,
И мужество нас не покинет.
Не страшно под пулями мертвыми лечь,
Не горько остаться без крова.
И мы сохраним тебя, русская речь,
Великое русское слово.
Свободным и чистым тебя пронесем,
И внукам дадим, и от плена спасем —
Навеки.
Добрый вечер, друзья, меня зовут Сергей Бочаров. Я начал со стихотворения Анны Ахматовой «Мужество». Оно было написано в 1942 году, в период Великой Отечественной войны, и уже тогда поэтесса понимала, что вернуть, выстроить разбитые бомбежкой заводы и фабрики будет гораздо легче, чем вернуть духовное богатство, растраченное и фактически растоптанное за годы войны.
Поэзия является одним из немногих средств, которое помогает нам научиться чувствовать прекрасное. Сегодня мы говорим о технической документации — казалось бы, такой далекой области от поэзии, но сохранение прекрасного, сохранение единого стиля очень актуально, особенно при работе с данным форматом. Markdown де факто стал стандартом написания технической документации в мире открытого ПО. И объединил людей разных специальностей.
У меня тяжелая и одновременно приятная миссия. Я хочу, чтобы у вас осталось полное ощущение сборки Markdown-документации в Яндексе, а также поделюсь инструментами, которые мы разработали. Надеюсь, вы тоже будете их использовать в своих проектах.
Инструменты, которые разработаны, написаны на JS, потому что мы в Яндексе любим JavaScript. И вся разработка ведется вокруг этого языка. Тут не стоит расстраиваться, если у вас другая среда разработки или хайповый React — думаю, можно найти аналоги на GitHub.
Наверное, многие задаются вопросом, почему же Markdown стал сэром? Это метафора, и она связана с тем, что мы в Яндексе стараемся роботизировать любой процесс.
Вокруг Markdown тоже разрабатывается большое количество инструментов. На сегодняшний день мы уже разработали очень много инструментов, продолжаем разрабатывать. У меня иногда складывается впечатление, что не он служит для нас, а мы служим для этого формата. Поэтому — сэр Markdown.
В первой глобальной части мы поговорим о том, зачем мы пишем в этом формате, зачем разрабатываем для него какие-то инструменты. Во второй части поговорим более детально на примере нашей библиотеки о том, как сохранять качество контента, как переводить его и как из множества репозиториев собирать один сайт.
Markdown был создан в 2004 году Джоном Грубером и Аароном Шварцом. Идея заключалась в том, чтобы иметь простой текстовый синтаксис и затем его конвертировать в более богатый и валидный HTML.

У нас есть заголовок первого уровня, второго уровня и какой-то абзац текста.
Зачем новый формат, когда есть DITA с более богатыми тулзами? Зачем создавать новые инструменты для Markdown? Давайте попробуем ответить вместе.

У DITA более сложный синтаксис, и для работы с ней желательно иметь определенную среду разработки. Понятно, что это XML-формат, он также открывается в текстовом редакторе. Но SVG тоже в нем открывается, при этом никто там не рисует — все используют Photoshop или Sketch.
Markdown с точностью до наоборот имеет более легкий синтаксис, поэтому он так полюбился многим разработчикам. Как следствие, документация в Markdown пишется и поддерживается техническим писателем с активным участием контрибьюторов и разработчиков, а документация в DITA часто разрабатывается только техническим писателем, активного участия разработчики и контрибьюторы не принимают.
Ярким примером сайта с документацией Markdown является сайт npm, на сегодняшний день он содержит 475 тысяч модулей, и с каждым днем их становится все больше.

Вот самые популярные из них. Если зайти на сайт любого, например Gulp, и перейти в раздел документации, мы сразу попадаем на GitHub, где видим, что API gulp.js описано в Markdown.
Поэтому если вы по каким-то причинам еще не используете Markdown или обходите его стороной — пожалуйста, используйте и сделайте ваших разработчиков счастливыми.
Стиль и синтаксис. Предлагаю рассмотреть на примере нашей внутренней библиотеки Лего, суперсекретной. Сейчас продемонстрирую.

Неожиданно, правда? Все эти блоки различны. Вот блок logo, teaser и т. д. И хранятся они на GitHub, стандарт де факто.

Здесь есть общее описание библиотеки, также есть директории блоков, и в каждой директории есть описание этого блока. Документацию мы рассматриваем как часть кода, поэтому называем соответствующим именем. Это также удобно в случае замены, search & replace. Когда-то над каждым документом поработал технический писатель. Над англоязычными версиями также поработал переводчик, и в идеале документация, русская и англоязычная версии, должны быть консистентны, то есть структура и содержание у них должны быть одинаковыми.
Над документацией также активно работают сами разработчики, их очень много. Процесс, который мы стараемся выстроить в компании, выглядит следующим образом: разработчик, разработав новую функциональность или новый блок, ставит задачу техническому писателю в виде пул-реквеста или issue.
Технический писатель эту функциональность описывает, после чего отдает на перевод, если нужна языковая версия документа. И все счастливы, но это идеальный мир. А в реальном мире часто ситуация следующая: разработчик сам приходит и вносит правки в документацию.

Здесь мы сталкиваемся с первой проблемой — потерей консистентности. Следующая проблема — также изменяется стиль написания документации.

Кажется — подумаешь, главное-то, что функциональность описана. Оказывается, нет. После того, как документ написал технический писатель, разработчики были счастливы.
Потом, когда туда со своими коммитами пришли еще несколько десятков разработчиков, они уже подрасстроились и в итоге заплакали. Говорят — нужно переписать документ, он стал непонятный, его невозможно читать, там очень много различных непонятных конструкций, мертвяков, маркеров проблемного текста.
С ними нужно как-то уметь бороться. Технические писатели знают и умеют с ними бороться, а разработчики часто допускают их в документации, и такую документацию некомфортно читать.

Например, тут всем комфортно? Все понимают, о чем речь? Очевидно, речь идет о git, и такое встречается в нашей документации. Вот более понятный вариант.

Разработчики, которые имеют небольшой опыт работы с GitHub, иногда встречают сложности, когда читают документацию, которую написали гуру-разработчики. Поэтому мы добавляем следующую проблему — сохранение стиля и терминологии. Разработчики очень много коммитят, и технического писателя уже практически не видно, единство стиля нарушено.
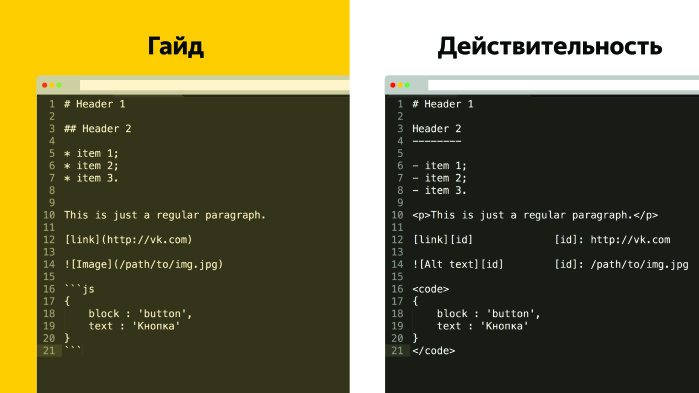
Следующая проблема при таком подходе — у нас нарушается синтаксис. Markdown позволяет писать совершенно по-разному и получать один и тот же результат. У разработчиков технической документации на каждый случай есть договоренность о том, как мы пишем заголовки, списки, вставляем скриншоты и т. д.
Действительно, реальность часто отличается от желаемого, и с этой проблемой тоже нужно уметь бороться. Казалось бы, результат ожидаемый, но если эту проблему не решить сейчас, ее придется решать на этапе сборки. Часто возникает задача — например, найти все заголовки третьего уровня с бэктиками и увеличить на два пикселя. Если мы ее не решаем на этапе линтинга, то придется решать ее на этапе сборки, писать большие скрипты.
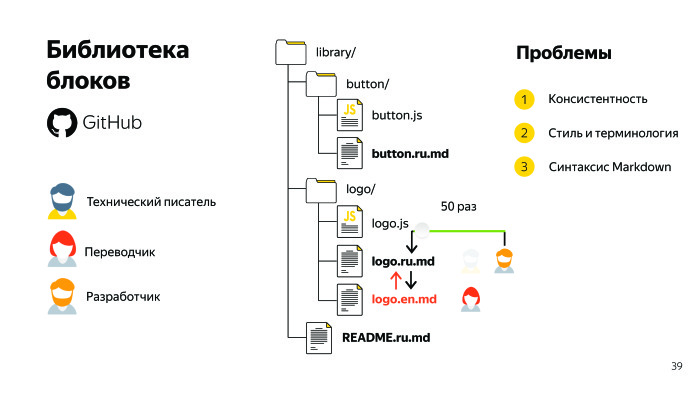
Поэтому обавляем следующую проблему — синтаксис Markdown. У нас получилось три основных вызова, с которыми мы боремся. Также у нас есть опенсорсные проекты, в частности БЭМ. У опенсорсных проектов помимо разработчиков, технических писателей и переводчиков есть еще контрибьюторы. Контрибьюторы помогают делать наши продукты лучше, за что мы им благодарны. Их очень много. Они присылают нам свои пул-реквесты, а мы с ними делимся качественным контентом. Поэтому однозначно надо как-то искать пути решения.

Следующий раздел посвящен автопроверке, линтингу. Тому, что можно сделать, чтобы как-то научиться согласованно проверять синтаксис Markdown, находить грамматические ошибки и маркеры проблемного текста. Это мой любимый раздел. Считаю, прогрессия линтинга работает на прогрессию технического писателя.
Начнем с инструмента под названием remark-lint. Он позволяет проверять синтаксис и стиль написания. Сам remark находится в открытом доступе, он разработан не нами, мы его используем, у него есть собственный набор правил, их больше 50. Поверх этих правил мы написали свои правила, внесли наш гайд в remark.

Как это работает? Допустим, есть тестовый файл с содержанием, есть заголовок первого уровня, второго и какой-то список.
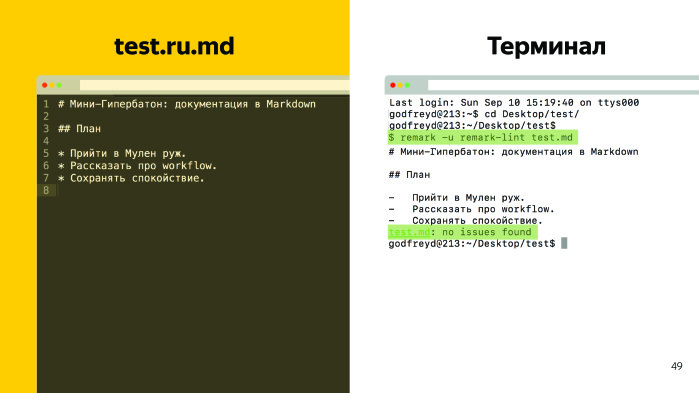
Мы вводим команду в терминале. Это команда у нас на прекоммите обрабатывается, показываю. Когда технический писатель совершает коммит на GitHub и документ в порядке, выводится сообщение, что ошибок нет. И коммит уходит на GitHub. Предположим, у нас есть ошибки — например, сделаем в первом заголовке его вторым уровнем, а во втором заголовке добавим «Привет» и восклицательный знак. Выполняем ту же команду, и у нас появляется три ошибки.
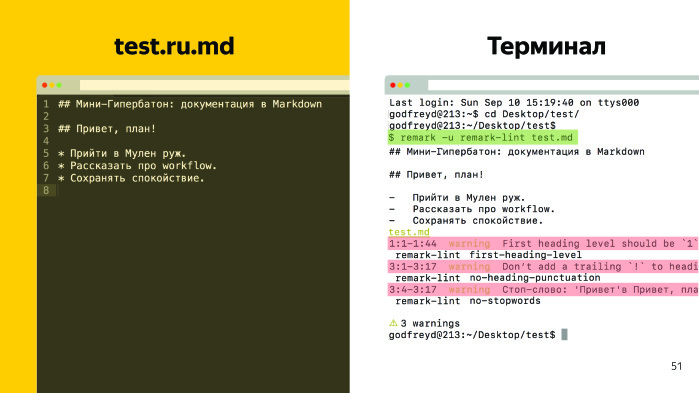
Прогрессия линтинга работает на прогрессию технического писателя. Технический писатель вспоминает, что мы договорились не ставить восклицательные знаки в заголовках, правит, все отлично. Как же подключаются эти правила? В корне проекта лежит файла remarkrc, в нем мы определяем набор собственных правил (их я сократил) и набор заимствованных правил самого remark.
Следующий инструмент — yaspeller. Он проверяет грамматику и наличие орфографических ошибок в документации. Документация есть на Яндекс.Технологиях — она, кстати, написана в git. Вы можете ее прочитать, там все работает по тому же принципу: есть орфографическая ошибка — выводится сообщение. Контрибьюторы, разработчики, которые пытаются сделать вам пул-реквест, прислать какие-то исправления, они не смогут их прислать с орфографическими ошибками или неточностями в синтаксисе Markdown. Так что эти инструменты очень удобно подключать, и отрабатывают они на прекоммите.
Следующий раздел посвящен переводу. Мы разработали инструмент md2xliff. Переводим мы очень много опенсорсной документации и чуть-чуть внутренней. В случае опенсорсной документации у нас есть контрибьюторы, которые присылают свои пул-реквесты, а чтобы им было удобнее их присылать, мы для них на нашем сайте делаем плашки, в которых предлагаем им пройти по ссылке либо через интерфейс GitHub, либо используя сервис prose.io. Например, они заходят, вносят изменения, нажимают ОК, и к нам прилетает пул-реквест.
Как же все это поддерживать? Допустим, документ написал технический писатель, переводчик его перевел, пришел пользователь — изначально в русскоязычную версию — и что-то там поправил. Как быть с английской версией? Нужно там что-то править или нет? Непонятно. Как искать опечатку, что была исправлена, тоже непонятно. Либо можно пойти на GitHub и там в diff смотреть разницу. Но это та еще задача, нужно же поставить ее переводчику. Необходимо искать решение.

Бывает вторая ситуация. Например, разработчик написал вторую версию библиотеки, и взял не весь документ, не переписал 30 страниц, а тут кусочек удалил, там добавил. И если удалил — непонятно, что делать. Надо идти и как-то сверять это в diff на GitHub.
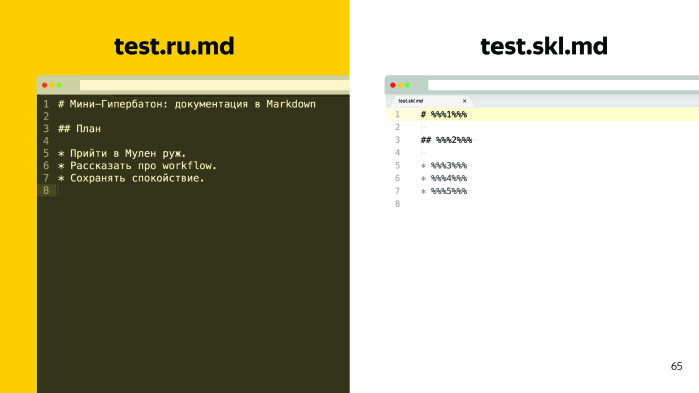
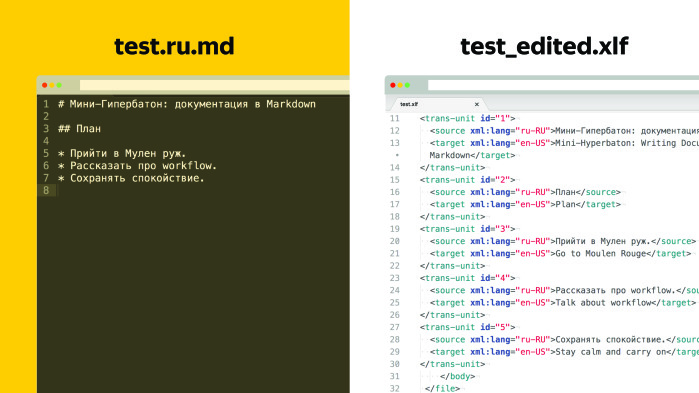
Как быть? Кажется, это сложная ситуация, при которой выхода нет. Однако если кто-то из вас работал с переводами, он наверняка знает, что есть куча стандартов, и при ближайшем рассмотрении решение выглядит примерно так: есть тестовый файл и какой-то текст документации, который лежит на GitHub. Что нужно сделать? Нужно сгенерировать из него два файла, скелет и XLIFF перевода.


Скелет представляет из себя блочное форматирование, то есть мы подменяем куски текста на такие плейсхолдеры с цифрами.
XLIFF — специальный формат, он описан, у него есть спецификация, там все просто. Самое главное, что в XLIFF есть юниты, и id юнита соответствует тому сегменту, который мы подменили в скелете.
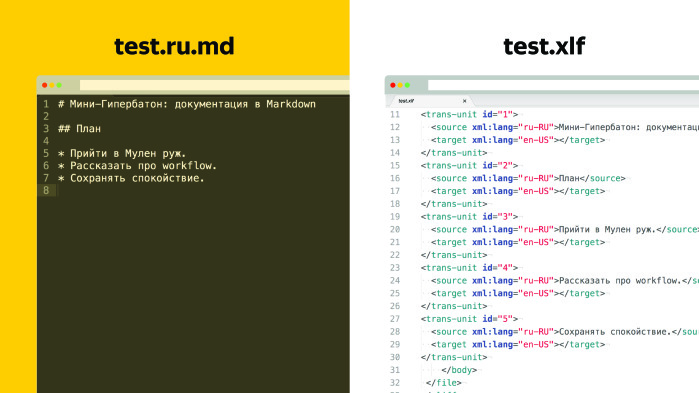
Также в каждом юните есть два тега: source и target. В теге source находится именно тот кусок текста, который мы заменили в скелете, а поле target изначально пустое. Мы отдаем этот XLIFF переводчику. Теперь поле target на выходе заполнено. После перевода делаем обратную генерацию и получаем английскую версию документа.
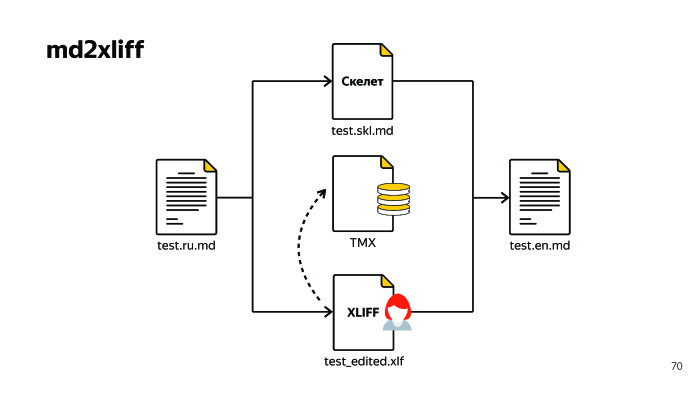
При этом перевод у нас никуда не пропадает, а сохраняется в специальном стандартизированном XML-файле TMX. Там лежат два значения: source и target. Как это нам помогает? Возвращаемся к прошлой ситуации. Пришли контрибьюторы, разработчики или другой технический писатель и что-то поправили в исходном документе. В русскоязычной версии, например.

Мы по-прежнему генерируем XLIFF, отдаем его переводчику, он применяет ту базу, которая у него сохранена в программе и переводит ровно те сегменты, которые изменились. Он не переводит строки, которые имеют стопроцентное совпадение — они сами автозаменой заменяются. Таким образом, больше нет проблемы искать, что же поменялось. Мы гарантируем, что все строки, которые хоть как-то были изменены, будут видны в переводе. Далее мы генерируем английскую версию документа, все просто. Кажется, что есть готовое решение — просто потому что наверняка они должны быть.

Есть smartcat.ai от ABBYY, есть решение от Google и есть Matecat. Но тотальные недостатки этих решений в том, что они не поддерживают Markdown, у которого нет единого стандарта того, как писать. И они обходят его стороной, поддерживают любые стандартизированные форматы. На прошлой неделе я проверял Markdown в matecat, там все краснеет. Хотя Markdown был простенький.
Возьмем, например, наш инструмент со сложной вложенностью. Если у вас код, внутри него три бэктика, и там есть JSDoc, он со всем справляется на 99%, уровень вложенности может быть любым.
Второй фатальный недостаток этих сервисов — они не интегрируются с GitHub. Мы же хотим, чтобы к нам пользователь пришел через ссылку и что-то поправил, а они не интегрируются.
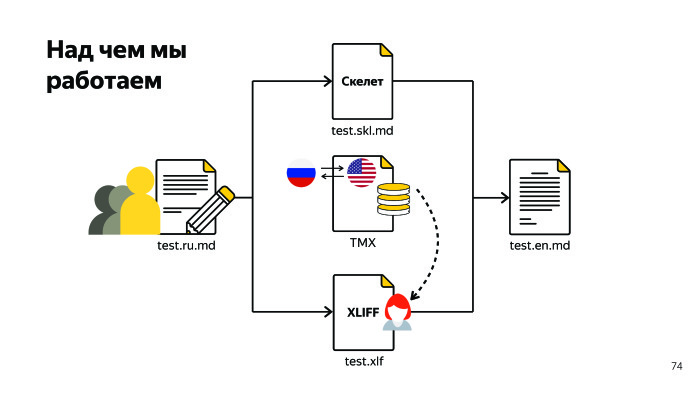
Мы все это обсуждали. Когда есть исходный документ на русском, и мы переводим на другой язык, у нас есть определенная пара, жесткая привязанность к русскому языку. Мы работаем над тем, чтобы избавиться от этой привязанности, чтобы мы могли править TMX на лету, независимо от того, куда придет пользователь. Он может прийти в русскую версию, а может в английскую, и мы должны развернуть TMX прямо при генерации. Пока это не решено.
Сборку сайта предлагаю рассмотреть в рамках общего обзора пути Markdown-документа от момента написания до момента выкладки на сайт.
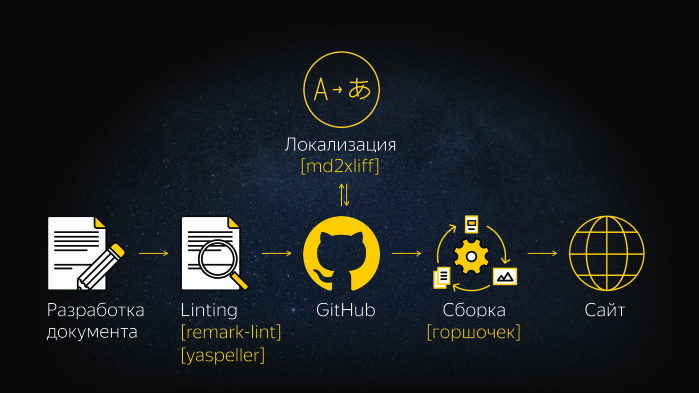
Как выглядит рабочий процесс? Предположим, план работ составлен, собрана вся информация. Если говорить о Markdown, здесь важно соблюдать договоренность о синтаксисе. После чего происходит автопроверка, она отрабатывает на прекоммите наши линтинги. Далее документ попадает на GitHub. Если нужна англоязычная версия, мы документ локализуем. После происходит сборка, и там две истории. Одна — когда документ один к одному мапится на страницу, а вторая — когда нужно построить различные инлайновые примеры. В страничку нужно встроить iframe и т. д. У нас есть инструмент, который все это умеет, горшочек. Он умеет подменять ссылки, объединять различные Markdown-документы в один, умеет строить инлайновые примеры. Затем происходит выкладка на сайт.
Зачем вообще нужен сайт? Почему, как на gulp.js, не хранить всю документацию в Markdown?

Ответ очевиден — нужна единая точка входа. У нас больше ста репозиториев, и мы хотим, чтобы эти документы были собраны в одном месте. Также нужны поиск, навигация и живые примеры. Живые примеры выглядят так.
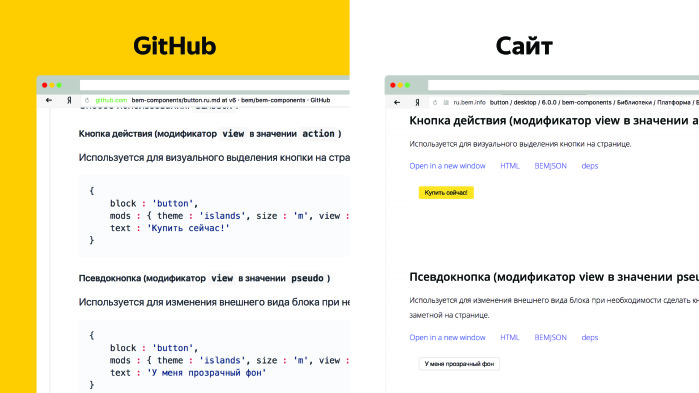
Один и тот же документ на GitHub и на сайте рендерится по-разному. Мы можем открыть его в новом окне, покликать по кнопке, посмотреть ее HTML. Это очень удобно.

Какие у нас рецепты? Что же делать вам? В первую очередь — определиться с потребностями. Если они схожи с нашими, то ввести ограничения на синтаксис Markdown, следить за терминологией, делать автоматические проверки и использовать Translation Memory. Инструменты: remark-lint, yaspeller, md2xliff. Cпасибо.
Комментарии (20)


Karpion
12.11.2017 16:39+1Как только я прочитал стихотворение, а потом про «духовное богатство» — мне стало понятно, что дальше будет бессмысленный поток сознания. И я не ошибся.

ZigFisher
12.11.2017 23:26То-же в начале пробовал Markdown, но потом перешел на Textile и меня полностью устраивает.
Потихоньку пишу микро-движок, с использованием разметки Textile, который производит обработку страниц прямо в браузере (JS). Для блогов и заметок самое то что надо.
poxvuibr
13.11.2017 00:00А я перешёл с маркдауна на org. Маркдаун он хороший, но какой-то уж совсем маленький.

ingumsky
13.11.2017 00:14Спасибо за статью, видно, что это превращённая в текст лекция, но всё равно интересно.
Интересно узнать, какие вы видите решения проблемы с внесением правок в английский текст и последующим возвращением изменений в «апстрим»? Вы вскользь упомянули, что работаете над этим. С учётом того, что процесс работы над переводной документацией обычно однонаправленный (в вашем случае это изменение русского текста и последующий перевод с использованием TM), можно предположить, что вы сейчас пользуетесь диффами, когда разработчик вносит изменения сразу в документацию на английском. Это так? При малом количестве таких правок, проблемы быть не должно (но всё равно есть неудобство), а вот когда такие правки появляются ежедневно и не по одной…

iit
13.11.2017 08:53Markdown на самом деле довольно шикарный формат когда нужно сделать например описание проекта на том-же github. Но постепенно создавая доки я обнаружил что мне не хватает некоторых фичей, тогда я открыл для себя reStructuredText (rst) и он еще более шикарен.

domix32
13.11.2017 11:12А каких фич не хватало?
iit
16.11.2017 07:28В основном возникла проблема со сборкой доков — у меня целая куча папок с md файлами, собирал я все это через MkDocs. Постепенно размер каждого файла вырос и редактировать их стало адово сложно.
reStructuredText позволяет же тупо сделать include одного файла в другой, что позволило разбить исходники доков по одному на модуль — при сборке они будут одним документом,
rst может автоматом создает оглавление на основе заголовков
(yml в MkDocs надо забивать руками) и приятные мелочи вроде создания таблицы из csv меня и подкупили.

OlegUV
13.11.2017 11:13Тоже прошёл примерно такой путь, но потом вернулся на «обычной шикарности» формат MD. Всё-таки, MD поддерживается массой тулзов, вплоть до утюгов, а с RST всё время какие-то нюансы возникают, в итоге на MD получается ощутимо и быстрее и удобнее писать.


Arris
13.11.2017 13:00Долго и упорно пытался использовать маркдаун. Для ведения блога, для написания документации, да вообще для всего.
Раз за разом — проблемы, проблемы, проблемы. Маркдаун хорош для простых текстов и ридми. Но когда нужны суперскрипты, субскрипты, подчеркивания, зачеркивания, обтекания картинок текстом или более сложные, чем "в git favored markdown" таблички — начинаются боль и страдания.
В эти моменты я с тоской вспоминаю язык разметки TiddlyWiki. И задаюсь вопросом — почему язык разметки, созданный 13 лет назад одним человеком — удовлетворяет с лихвой все мои потребности, а язык, над которым те же 13 лет страдает "прогрессивная программерская общественность" — не удовлетворяет?
А ведь я не хочу странного, я хочу записывать документацию и мысли по своим проектам (и они не в IT-сфере) в простом и удобном виде. Для меня простом и удобном. Но — нет, якобы простой и якобы удобный инструмент оказывается слишком простым для моих задач.
В такие моменты я задумываюсь — а не достать ли с полки книжку Кнута и не вспомнить ли TeX?
poxvuibr
13.11.2017 13:49И задаюсь вопросом — почему язык разметки, созданный 13 лет назад одним человеком — удовлетворяет с лихвой все мои потребности, а язык, над которым те же 13 лет страдает "прогрессивная программерская общественность" — не удовлетворяет?
Я подозреваю, что маркдаун был задуман совсем простым форматом для одностраничных текстов и ридми. И, если хочешь большего, то нужно либо радикально расширять маркдаун, либо использовать что-то другое. Радикальное расширение автор делать не хочет. Даже на попытку как-то стандартизировать формат он отреагировал очень эмоционально. А расширение руками большого количества людей чревато фрагментацией. Возможно CommonMark во что-то вырастет, но я не уверен.
В такие моменты я задумываюсь — а не достать ли с полки книжку Кнута и не вспомнить ли TeX?
Очень хорошо вас понимаю, я прошёл через что-то в этом духе. Тоже собирался делать всё в TeX, но наткнулся на org-mode. В результате пока пользуюсь этим форматом, он больше маркдауна. Возможно, если захочу писать книги, то и его не хватит.

ivan386
13.11.2017 20:46Но SVG тоже в нем открывается, при этом никто там не рисует — все используют Photoshop или Sketch.
Я пишу SVG картинки в текстовом редакторе. Так что утверждение про никто неверно.

Svetlyak
14.11.2017 11:15А почему не стали использовать формат reStructured Text? Он хотя и более странно выглядит, чем Маркдаун, но стандартизирован, и для описания документации лучше походит, так как задумывался именно с этой целью.
В reStructured Text заложены возможности для расширения и то как это делается, тоже стандартизировано, в отличии от Markdown, где разработчик каждой библиотеки городит свой велосипед.

roman_kashitsyn
14.11.2017 15:19
voe
а как дела обстоят с экспортом markdown в pdf, doc\x или в odf, какая у вас практика?
poxvuibr
Я не имею к автору никакого отношения, но с маркдауном поковыряться успел. Для экспорта в doc\x или в odf можно использовать pandoc. Он умеет конвертировать любой формат в любой другой (ну не любой, но поддерживает много форматов). Также он может работать с pdf, но нужно поставить немного дополнительного софта. Иногда проще сохранить в odf, а потом из odf сделать pdf средствами OpenOffice.