
В данном примере мы построим рекуррентную нейронную сеть, которая получив на вход текст романа Толстого «Анна Каренина», будет генерировать свой текст, чем-то напоминающий оригинал, предсказывая, какой должен быть следующий символ.
Структуру изложения я старался делать такой, чтобы можно было повторить все шаги новичку, даже не понимая в деталях, что именно происходит внутри этой сети. Профессионалы Deep Learning скорее всего не найдут тут ничего интересного, а тех, кто только изучает эти технологии, прошу под кат.
Введение
За основу этого мини-проекта были взяты статьи Andrej Karpathy (ссылки ниже по тексту) и учебные материалы udacity.
Самый простой путь повторить все описанное ниже:
- установить у себя на ПК дистрибутив anaconda с версией Python 3.6
- создать рабочий conda environment
- установить в этот environment библиотеки tensorflow, numpy, jupyter
- писать и исполнять код в Jupyter Notebook, что дает нам нужную интерактивность
- скачать текст романа в txt формате
В случае инсталляции anaconda на Windows делаем следующее:
1. Создаем папку, в которой будем работать, копируем туда текст под именем «anna.txt»
2. Запускаем Anaconda Promt, переходим в созданную папку, создаем там нужный environment «tolstoy» с необходимыми библиотеками и активируем его:
(C:\anaconda3) C:\DL\rnn-tolstoy>conda create -n tolstoy
...
(C:\anaconda3) C:\DL\rnn-tolstoy>activate tolstoy
(tolstoy) C:\DL\rnn-tolstoy>conda install numpy tensorflow jupyter
...3. Когда все библиотеки установятся, запускаем jupyter notebook, в котором будем работать:
(tolstoy) C:\DL\rnn-tolstoy>jupyter notebook4. В браузере открывается меню notebook, там идем в «New» и выбираем Notebook -> Python 3, как показано на картинке:
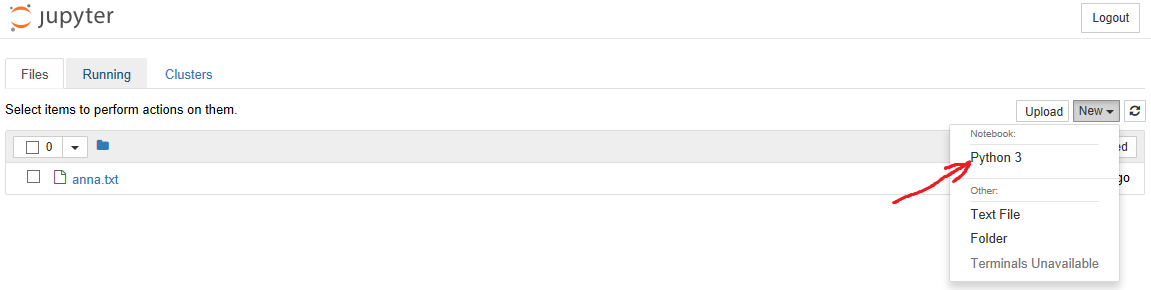
После чего открывается уже сам notebook, где мы будем вбивать код и любоваться результатом его работы. Например, вбив код в ячейку «In», мы можем его выполнить нажатием Shift+Enter и сразу получить результат:
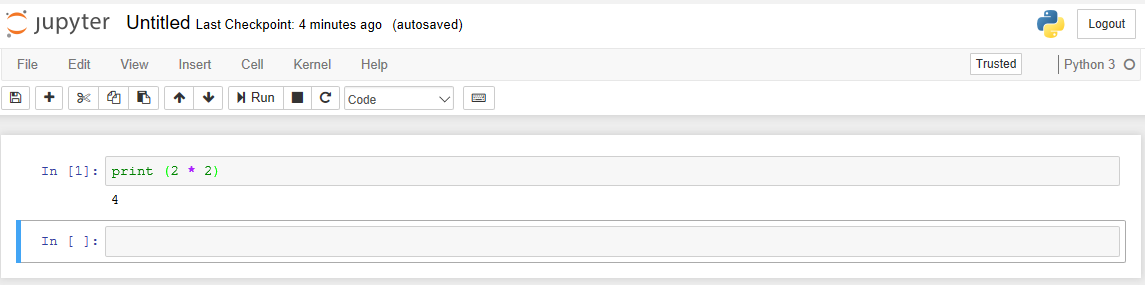
К этому моменту мы разобрались с базовыми вещами, теперь можно приступать к самой задаче.
Ниже приведена общая архитектура рекуррентной нейронной сети (RNN), предсказывающей следующий символ (взято отсюда):
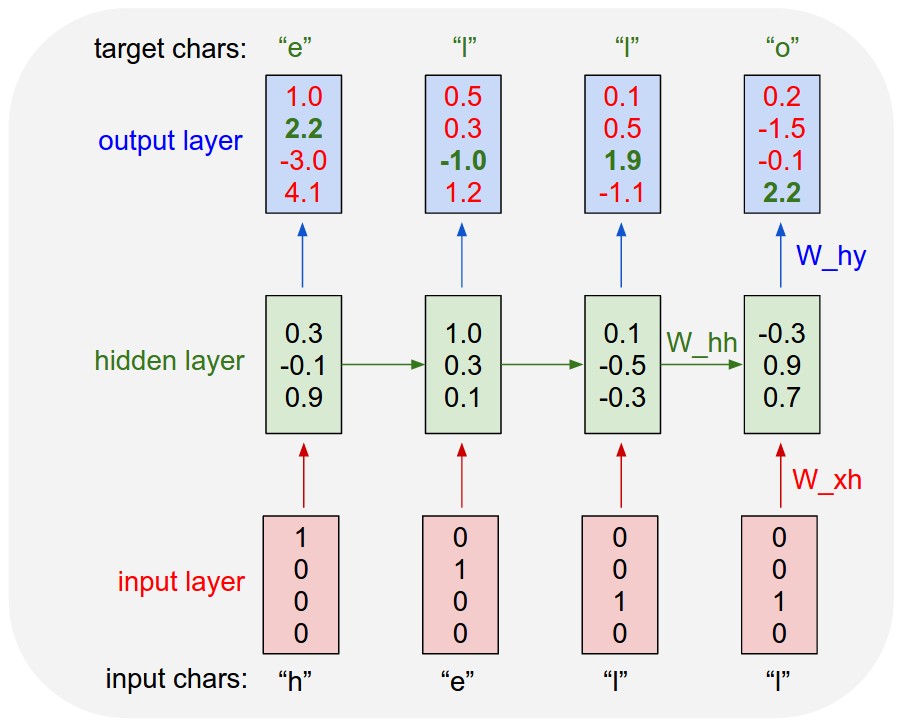
На схеме видна ключевая особенность RNN — информация может обрабатываться циклично при движении от input к output, обеспечивая (в отличие от традиционных нейронных сетей) эффект памяти и позволяя обрабатывать связанные последовательности.
Инициализируем и готовим данные
Импортируем нужные библиотеки:
import time
from collections import namedtuple
import numpy as np
import tensorflow as tfЗагружаем текст романа, создаем словарь символов vocab, объекты dictionary для трансляции символ -> код, код -> символ и кодируем весь текст романа (массив encoded):
with open('anna.txt', 'r') as f:
text=f.read()
vocab = sorted(set(text))
vocab_to_int = {c: i for i, c in enumerate(vocab)}
int_to_vocab = dict(enumerate(vocab))
encoded = np.array([vocab_to_int[c] for c in text], dtype=np.int32)Проверяем начало, знаменитая фраза на месте, все в порядке:
text[:110]Out: 'ЧАСТЬ ПЕРВАЯ\n\n\n\nI\n\nВсе счастливые семьи похожи друг на друга, каждая несчастливая семья несчастлива по-своему.'Смотрим, как это выглядит в закодированном виде (именно в таком виде данные будут обрабатываться в сети):
encoded[:110]Out:
array([ 99, 77, 93, 94, 102, 1, 91, 82, 92, 79, 77, 105, 0,
0, 0, 0, 30, 0, 0, 79, 123, 111, 1, 123, 129, 106,
123, 124, 117, 114, 108, 133, 111, 1, 123, 111, 118, 134, 114,
1, 121, 120, 127, 120, 112, 114, 1, 110, 122, 125, 109, 1,
119, 106, 1, 110, 122, 125, 109, 106, 7, 1, 116, 106, 112,
110, 106, 137, 1, 119, 111, 123, 129, 106, 123, 124, 117, 114,
108, 106, 137, 1, 123, 111, 118, 134, 137, 1, 119, 111, 123,
129, 106, 123, 124, 117, 114, 108, 106, 1, 121, 120, 8, 123,
108, 120, 111, 118, 125, 9])Поскольку наша сеть работает с отдельными символами, мы имеем дело с проблемой классификации, когда мы пытаемся предсказать следующий символ из предыдущего текста. Длина словаря это по сути количество классов, из которых наша сеть будет делать выбор:
len(vocab)Out: 140Символов в словаре многовато, но нужно учитывать, что заглавные и строчные буквы — это разные символы, а также помним про большое количество текста на французском, т.е. у нас по сути два алфавита.
Делим данные на пакеты
Для эффективного обучения нашей сети необходимо разбить данные на пакеты (mini-batches). Во-первых это экономит оперативную память. Если мы попытаемся загнать в сеть все данные целиком за один раз, памяти может просто не хватить. Во-вторых при дроблении данных на пакеты сеть будет обучаться значительно быстрее — мы можем обновлять веса в нейронной сети после прохождения каждого пакета данных, а также параллелить загрузку пакетов, как показано на картинке:
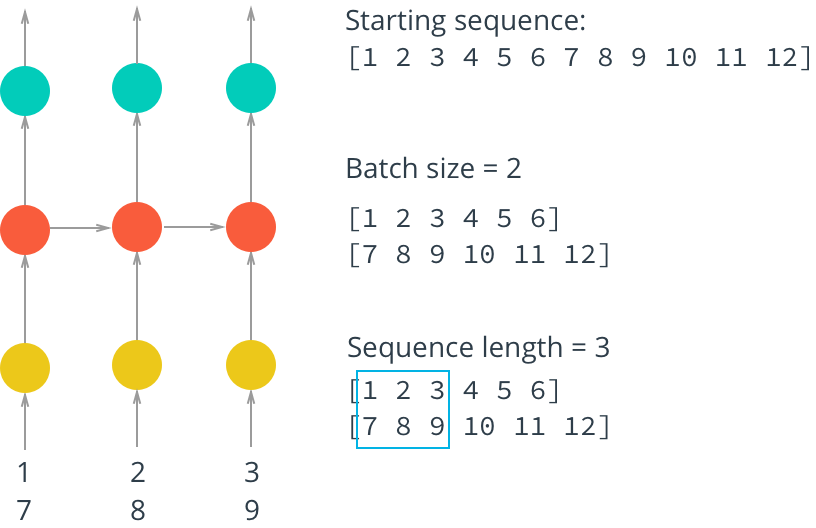
Создаем процедуру получения исходного пакета, который будет подаваться на вход нейронной сети (feature) и контрольного пакета, с которым будет сравниваться предсказание сети (target):
def get_batches(arr, n_seqs, n_steps):
'''Создаем генератор, который возвращает пакеты размером
n_seqs x n_steps из массива arr.
Аргументы
---------
arr: Массив, из которого получаем пакеты
n_seqs: Batch size, количество последовательностей в пакете
n_steps: Sequence length, сколько "шагов" делаем в пакете
'''
# Считаем количество символов на пакет и количество пакетов, которое можем сформировать
characters_per_batch = n_seqs * n_steps
n_batches = len(arr)//characters_per_batch
# Сохраняем в массиве только символы, которые позволяют сформировать целое число пакетов
arr = arr[:n_batches * characters_per_batch]
# Делаем reshape 1D -> 2D, используя n_seqs как число строк, как на картинке
arr = arr.reshape((n_seqs, -1))
for n in range(0, arr.shape[1], n_steps):
# пакет данных, который будет подаваться на вход сети
x = arr[:, n:n+n_steps]
# целевой пакет, с которым будем сравнивать предсказание, получаем сдвиганием "x" на один символ вперед
y = np.zeros_like(x)
y[:, :-1], y[:, -1] = x[:, 1:], x[:, 0]
yield x, yФункция работает как генератор, каждое обращение к которому позволяет получить следующую пару «x» и «y», например:
batches = get_batches(encoded, 10, 50)
x, y = next(batches)
print('x\n', x[:5, :5])
print('\ny\n', y[:5, :5])x
[[ 99 77 93 94 102]
[ 1 110 108 114 112]
[ 79 120 124 1 120]
[114 119 1 109 120]
[106 108 111 110 117]]
y
[[ 77 93 94 102 1]
[110 108 114 112 111]
[120 124 1 120 124]
[119 1 109 120 108]
[108 111 110 117 114]]В выводе виден сдвиг пакета «y» по отношению к пакету «х».
Строим модель
Ниже приведена схема нашей RNN модели:
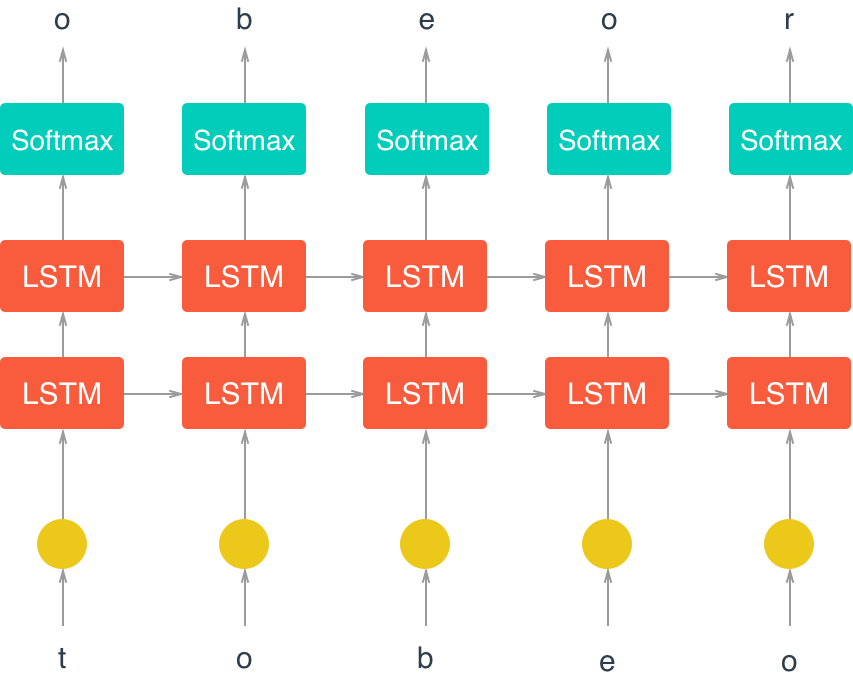
Основная магия обучения происходит в ячейке LSTM (Long Short Term Memory).
Вот здесь лежит замечательная статья, в которой простым и понятным английским языком описывается логика работы таких ячеек и нейронных сетей, основанных на LSTM.
При построении модели сначала определяем входящие параметры:
def build_inputs(batch_size, num_steps):
''' Определяем placeholder'ы для входных, целевых данных, а также вероятности drop out
Аргументы
---------
batch_size: Batch size, количество последовательностей в пакете
num_steps: Sequence length, сколько "шагов" делаем в пакете
'''
# Объявляем placeholder'ы
inputs = tf.placeholder(tf.int32, [batch_size, num_steps], name='inputs')
targets = tf.placeholder(tf.int32, [batch_size, num_steps], name='targets')
# Placeholder для вероятности drop out
keep_prob = tf.placeholder(tf.float32, name='keep_prob')
return inputs, targets, keep_probНадо напомнить, что данные в Tensorflow хранятся в тензорах.
"placeholder'ы" — вид тензоров, который определяет тип и формат данных (например размерность матрицы), а сами данные реально будут загружены в нужный момент в будущем.
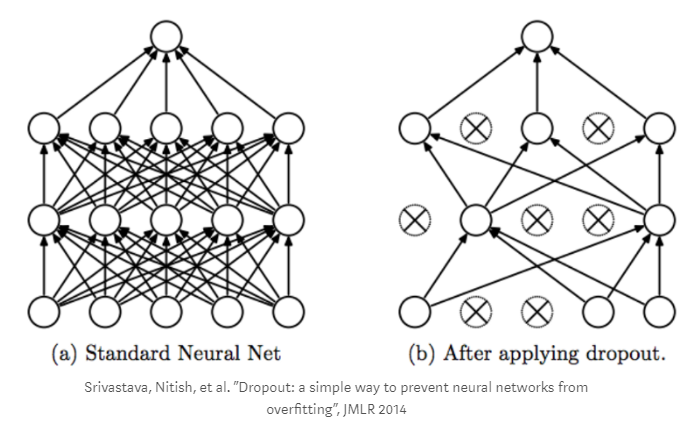
Что касается drop out — это механизм противодействия эффекту «переобучения» нашей сети, когда в процессе мы случайным образом исключаем часть вершин нашего графа из расчетов:
Дальше мы строим структуру LTSM ячейки.
def build_lstm(lstm_size, num_layers, batch_size, keep_prob):
''' Строим LSTM ячейку.
Аргументы
---------
keep_prob: Скаляр (tf.placeholder) для dropout keep probability
lstm_size: Размер скрытых слоев в LSTM ячейках
num_layers: Количество LSTM слоев
batch_size: Batch size
'''
### Строим LSTM ячейку
def build_cell(lstm_size, keep_prob):
# Начинаем с базовой LSTM ячейки
lstm = tf.contrib.rnn.BasicLSTMCell(lstm_size)
# Добавляем dropout к ячейке
drop = tf.contrib.rnn.DropoutWrapper(lstm, output_keep_prob=keep_prob)
return drop
# Стэкируем несколько LSTM слоев для придания глубины нашему deep learning
cell = tf.contrib.rnn.MultiRNNCell([build_cell(lstm_size, keep_prob) for _ in range(num_layers)])
# Инициализируем начальное состояние LTSM ячейки
initial_state = cell.zero_state(batch_size, tf.float32)
return cell, initial_stateДалее будем строить выходной слой. Определяемся с размерностью.
Если входные данные имели размерность M (batch size), N (sequence length) и проходили через скрытые слои размером L юнитов, то на выходе получаем 3D тензор размерностью MxNxL. Чтобы упростить задачу, сделаем reshape 3D -> 2D и приведем тензор к виду (M?N)?L. Таким образом, у нас будет одна строка для каждой последовательности и каждого «шага» и значения каждой строки — выход из LSTM юнитов.
Данную матрицу перемножаем на матрицу весов выходного уровня и прибавляем смещение выходного уровня.
При этом инициализируем веса случайными величинами с усеченным нормальным распределением (в диапазоне 2 стандартных отклонений), а смещения (bias) инициализируем нулями, что является рекомендуемой практикой в нейронных сетях.
Результат выходного слоя пропускаем через функцию активации softmax (более подробно о функциях активации здесь), используя результат работы этой функции в качестве предсказателя.
def build_output(lstm_output, in_size, out_size):
''' Строим softmax слой и возвращаем результат его работы.
Аргументы
---------
x: Входящий от LSTM тензор
in_size: Размер входящего тензора, (кол-во LSTM юнитов скрытого слоя)
out_size: Размер softmax слоя (объем словаря)
'''
# вытягиваем и решэйпим тензор, выполняя преобразование 3D -> 2D
seq_output = tf.concat(lstm_output, axis=1)
x = tf.reshape(seq_output, [-1, in_size])
# Соединяем результат LTSM слоев с softmax слоем
with tf.variable_scope('softmax'):
softmax_w = tf.Variable(tf.truncated_normal((in_size, out_size), stddev=0.1))
softmax_b = tf.Variable(tf.zeros(out_size))
# Считаем logit-функцию
logits = tf.matmul(x, softmax_w) + softmax_b
# Используем функцию softmax для получения предсказания
out = tf.nn.softmax(logits, name='predictions')
return out, logitsДальше мы определяем функцию потери (то есть измеряем, насколько мы ошиблись). Для этого вычисляем softmax cross entropy между значениями logit-функции и label (которые в свою очередь являются целевыми значениями, прошедшими через one-hot кодирование).
В deep learning часто используют one-hot кодирование для представления категорийных переменных в виде бинарных векторов, чтобы их было удобнее использовать в дальнейших вычислениях. Например, последовательность данных:
[red, yellow, green]мы можем закодировать в integer (как мы сделали выше в переменной encoded) в:
[0, 1, 2]а после one-hot кодирования это будет выглядеть так:
[[1, 0, 0],
[0, 1, 0],
[0, 0, 1]]Функцию потери в deep learning считают по разному. Для задач классификации объектов, которые относятся к взаимоисключающим классам (в нашем случае следующий символ не может являться одновременно «а» и «б»), функцию потери считают через функцию softmax cross entropy with logits и возвращаем среднее значение этой функции всех элементов по всем измерениям тензора.
def build_loss(logits, targets, lstm_size, num_classes):
''' Считаем функцию потери на основании значений logit-функции и целевых значений.
Аргументы
---------
logits: значение logit-функции
targets: целевые значения, с которыми сравниваем предсказания
lstm_size: Количество юнитов в LSTM слое
num_classes: Количество классов в целевых значениях (размер словаря)
'''
# Делаем one-hot кодирование целевых значений и решейпим по образу и подобию logits
y_one_hot = tf.one_hot(targets, num_classes)
y_reshaped = tf.reshape(y_one_hot, logits.get_shape())
# Считаем значение функции потери softmax cross entropy loss и возвращаем среднее значение
loss = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y_reshaped)
loss = tf.reduce_mean(loss)
return lossДальше строим оптимизатор, который основан на методе градиентного спуска. При этом мы защищаемся от двух проблем (подробнее — здесь):
- «исчезновение» градиента (защита встроена в логику работы LSTM ячеек);
- «взрыв» градиента (для этого мы здесь используем gradient clipping).
В качестве функции оптимизации используем Adam optimizer
def build_optimizer(loss, learning_rate, grad_clip):
''' Строим оптимизатор для обучения, используя обрезку градиента.
Arguments:
loss: значение функции потери
learning_rate: параметр скорости обучения
'''
# Оптимизатор для обучения, обрезка градиента для контроля "взрывающихся" градиентов
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(loss, tvars), grad_clip)
train_op = tf.train.AdamOptimizer(learning_rate)
optimizer = train_op.apply_gradients(zip(grads, tvars))
return optimizerТеперь собираем все детали пазла вместе и строим класс, описывающий нашу сеть. Ключевой оператор, формирующий RNN сеть — tf.nn.dynamic_rnn. Он возвращает вывод каждой LSTM ячейки на каждом шаге, для каждой последовательности, в каждом пакете (mini-batch). Кроме этого, он возвращает финальный статус LSTM ячеек, который мы сохраняем и передаем на вход в первую LSTM ячейку при загрузке следующего пакета данных. На вход tf.nn.dynamic_rnn мы подаем ячейку (cell), начальный статус, который мы получаем из build_lstm и входную последовательность данных.
class CharRNN:
def __init__(self, num_classes, batch_size=64, num_steps=50,
lstm_size=128, num_layers=2, learning_rate=0.001,
grad_clip=5, sampling=False):
# Мы будем использовать эту же сеть для сэмплирования (генерации текста),
# при этом будем подавать по одному символу за один раз
if sampling == True:
batch_size, num_steps = 1, 1
else:
batch_size, num_steps = batch_size, num_steps
tf.reset_default_graph()
# Получаем input placeholder'ы
self.inputs, self.targets, self.keep_prob = build_inputs(batch_size, num_steps)
# Строим LSTM ячейку
cell, self.initial_state = build_lstm(lstm_size, num_layers, batch_size, self.keep_prob)
### Прогоняем данные через RNN слои
# Делаем one-hot кодирование входящих данных
x_one_hot = tf.one_hot(self.inputs, num_classes)
# Прогоняем данные через RNN и собираем результаты
outputs, state = tf.nn.dynamic_rnn(cell, x_one_hot, initial_state=self.initial_state)
self.final_state = state
# Получаем предсказания (softmax) и результат logit-функции
self.prediction, self.logits = build_output(outputs, lstm_size, num_classes)
# Считаем потери и оптимизируем (с обрезкой градиента)
self.loss = build_loss(self.logits, self.targets, lstm_size, num_classes)
self.optimizer = build_optimizer(self.loss, learning_rate, grad_clip)Подбираем гиперпараметры
Далее задаем гиперпараметры для нашей модели. Тут есть большое пространство для творчества, поскольку меняя эти параметры можно «выжимать» из сети больше. Подробно останавливаться на стратегии настройки не буду, так как это отдельная большая тема, которой посвящено множество статей и исследований.
batch_size = 100 # Размер пакета
num_steps = 100 # Шагов в пакете
lstm_size = 512 # Количество LSTM юнитов в скрытом слое
num_layers = 2 # Количество LSTM слоев
learning_rate = 0.001 # Скорость обучения
keep_prob = 0.5 # Dropout keep probabilityОбучаем модель
Теперь приступаем к обучению нашей модели.
Запускаем входные и целевые данные в сеть, запускаем оптимизацию. Для каждого пакета (mini-batch) сохраняем окончательный LSTM статус, который отдаем на вход в сеть при следующем пакете, обеспечивая преемственность. Периодически (определяется переменной save_every_n) сохраняем состояние нашей модели (со всеми переменными, весами и т.д.) в checkpoint. Здесь есть еще один параметр — количество эпох (полных циклов обучения модели). Также необходимо напомнить, что вся работа с данными в Tensorflow ведется в рамках открытой сессии, что обычно начинается с кода
with tf.Session() as sess:.epochs = 20
# Сохраняться каждый N итераций
save_every_n = 200
model = CharRNN(len(vocab), batch_size=batch_size, num_steps=num_steps,
lstm_size=lstm_size, num_layers=num_layers,
learning_rate=learning_rate)
saver = tf.train.Saver(max_to_keep=100)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# Можно раскомментировать строчку ниже и продолжить обучение с checkpoint'а
#saver.restore(sess, 'checkpoints/______.ckpt')
counter = 0
for e in range(epochs):
# Обучаем сеть
new_state = sess.run(model.initial_state)
loss = 0
for x, y in get_batches(encoded, batch_size, num_steps):
counter += 1
start = time.time()
feed = {model.inputs: x,
model.targets: y,
model.keep_prob: keep_prob,
model.initial_state: new_state}
batch_loss, new_state, _ = sess.run([model.loss,
model.final_state,
model.optimizer],
feed_dict=feed)
end = time.time()
print('Epoch: {}/{}... '.format(e+1, epochs),
'Training Step: {}... '.format(counter),
'Training loss: {:.4f}... '.format(batch_loss),
'{:.4f} sec/batch'.format((end-start)))
if (counter % save_every_n == 0):
saver.save(sess, "checkpoints/i{}_l{}.ckpt".format(counter, lstm_size))
saver.save(sess, "checkpoints/i{}_l{}.ckpt".format(counter, lstm_size))Дальше наблюдаем процесс обучения:
Epoch: 1/20... Training Step: 1... Training loss: 4.9402... 7.7964 sec/batch
Epoch: 1/20... Training Step: 2... Training loss: 4.8530... 7.1318 sec/batch
...
Epoch: 20/20... Training Step: 3400... Training loss: 1.4003... 6.6569 sec/batchМы видим постепенное уменьшение training loss.
На моем ПК этот процесс обучения занял порядка 6 часов. При наличии машины с хорошим GPU этот срок может быть уменьшен в разы.
Проверяем наши сохраненные чекпоинты:
tf.train.get_checkpoint_state('checkpoints')model_checkpoint_path: "checkpoints\\i3400_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i200_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i400_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i600_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i800_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i1000_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i1200_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i1400_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i1600_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i1800_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i2000_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i2200_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i2400_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i2600_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i2800_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i3000_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i3200_l512.ckpt"
all_model_checkpoint_paths: "checkpoints\\i3400_l512.ckpt"Генерируем текст
Теперь можем приступать к сэмплированию, то есть к генерации текста.
Идея в том, что подавая на вход в сеть один символ, мы получаем на выходе предсказанный символ, который мы добавим в сгенеренный текст и подадим его опять на вход в сеть на следующей итерации и т.д. Исключение — это текст для «разогрева» модели, подаваемый на вход в параметре prime.
Функцию
pick_top_n используем для уменьшения «шума» предсказаний, оставляя для выбора только заданное количество (по умолчанию 5) вариантов символов, отбрасывая все остальные варианты.def pick_top_n(preds, vocab_size, top_n=5):
p = np.squeeze(preds)
p[np.argsort(p)[:-top_n]] = 0
p = p / np.sum(p)
c = np.random.choice(vocab_size, 1, p=p)[0]
return cdef sample(checkpoint, n_samples, lstm_size, vocab_size, prime="Гостиная Анны Павловны начала понемногу наполняться."):
samples = [c for c in prime]
model = CharRNN(len(vocab), lstm_size=lstm_size, sampling=True)
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, checkpoint)
new_state = sess.run(model.initial_state)
for c in prime:
x = np.zeros((1, 1))
x[0,0] = vocab_to_int[c]
feed = {model.inputs: x,
model.keep_prob: 1.,
model.initial_state: new_state}
preds, new_state = sess.run([model.prediction, model.final_state],
feed_dict=feed)
c = pick_top_n(preds, len(vocab))
samples.append(int_to_vocab[c])
for i in range(n_samples):
x[0,0] = c
feed = {model.inputs: x,
model.keep_prob: 1.,
model.initial_state: new_state}
preds, new_state = sess.run([model.prediction, model.final_state],
feed_dict=feed)
c = pick_top_n(preds, len(vocab))
samples.append(int_to_vocab[c])
return ''.join(samples)Теперь генерируем текст и смотрим что получилось.
Для начала — раннее состояние модели (после 200 итераций).
checkpoint = 'checkpoints/i200_l512.ckpt'
samp = sample(checkpoint, 1000, lstm_size, len(vocab))
print(samp)INFO:tensorflow:Restoring parameters from checkpoints/i200_l512.ckpt
Гостиная Анны Павловны начала понемногу наполняться. – о пота тот о олоната,, то ол водит то та о олетоло нел олелоноли но о нол тал ветила ноль о то пролина о то вота о сел вина сти ву о нонит но то виле, тон тон е не вели и не вени не нело нинене н енел вита, о пототота, снита, половето о сенуле не о сене та сола сито осново сно ва вено нато но сте ва те вонили, повонино се на оно тона оснанина вала, к тонала сеснить и тона олане села тета и се оло е со едо снаноти и ноно нетел о о то не вале не селе оли тол вовевити ста, порато то оло на оло то она онене си о о пела о не нолоно нета нол ти соно о тено оно веле, с родал ва и ни ситато нино, по поволена снела се пота сень, ото ноте, подоли ола о ни се нать на сна не во о пил вол и вели о ни нол но инене се о трилана но повень нот е ноти и неноть о о нена,..
–
Она порано вева ни педонь о о тама стоно, о падо то олельлат во но о о сроволо на о то сети тот ве тет врули, и та тро ву со о тон ето на нат е нала, нени о тени сте сото ти о стена вона ине оне се не ново но нил та, вете олито та С одной стороны получилась какая-то ерунда. С другой стороны мы видим, что у нейронной сети начинает формироваться понимание слов как набора символов, разделенных пробелами и даже использование некоторых знаков препинания.
Идем дальше (после 600-й итерации).
checkpoint = 'checkpoints/i600_l512.ckpt'
samp = sample(checkpoint, 1000, lstm_size, len(vocab))
print(samp)INFO:tensorflow:Restoring parameters from checkpoints/i600_l512.ckpt
Гостиная Анны Павловны начала понемногу наполняться. Онна, которую проваделая, как оста не поремала ота подула свае полодом, что-то ос несто не собя стольчась ого дру про текать просвидный, как в тарек в деле вым не переднени в пресведанее и совсенали его, песем его на на не мужи от немуть встрота и тругу водотольное на не престила и стровить в сторой после веровать его, что о весто с немогразавая седа несто, на она сказал старит, содриваят серью.
– Я на селена пристали обень присито прететь не воден е ни мотра на то посере присела всего не него они стать о тром всеме на него оненно накодотьее обенние с всем, что всебо на только насковиль паредили, что томого потерала вы него не поленней. Но ну ни не подему, – сказал он.
– Да, честе потем, который ос скузал от перобеть приведно нубили, котовая в пересели свытался оговерил собы, на обрадала ема, покодал он вослу с намо, чтро он стела, они бля он, чело ну но так поритеть в постери пальсти выди свотом назновот их наси с семий не мучел была себе ностовиниться стель она накателень, что веде Здесь мы видим и «слова» стали подлиннее, наметились какие-то зачатки диалогов. В какой-то момент сетка даже ругнулась матом :)
В общем положительная динамика налицо.
Ну и результат последней итерации.
checkpoint = tf.train.latest_checkpoint('checkpoints')
samp = sample(checkpoint, 2000, lstm_size, len(vocab))
print(samp)INFO:tensorflow:Restoring parameters from checkpoints\i3400_l512.ckpt
Гостиная Анны Павловны начала понемногу наполняться. И, строго встал в последние волоса, петербургский дома, и он видел, что он не слышал. И только по послу и подошел к свядене. Все это было не все теперьшему в передом и потому, что неправда на то, что он был в половине именно переговорил с ним.
– Нужно, теперь мне вы надоегили ее, – понял ему, – сказала она, подходя к принудившись в каким-то пред том, что ее на следующее должно было выбороть стрегования, которые в это приятеле несколькое деле с ним, и отвечала его из сторона, которая с ними, именно положенный, как она совершенно не возморила и посмотрела на него. Все было состояное. Но все это было потому, что поднялась, что он понял, что они не могут.
– Только то есть нужны во просту. Нет, я пойду, когда наделал, как она помочь мне направа.
– Ах, вы перемените вам нето, – сказал Степан Аркадьич.
– Да, та мы, ни ты давно, как во всего не могут быть имен положение. Он не заметил вас, что ты не понимает воспоминания о первой меленикий с мономы и сомневился в элом пель, но нет. Теперь он стал, – сказала она.
– Непромена в себе противотереение на другою.
– Да, я понимаю, – обратилась она к нему к Анне, – он не мог надельте и теперь в том, что осоне весело, – сказал Вронский.
– Душенькой стали просто не толька посла того, что я не понимаю, – перебила Кити, – я не могу сердить, и он всегда не видел его, которое поднем неправду, но я была тебе самыми насмешлимы, – сказал он с свою столоную руку с постепкновным избеженная, которая высказала прекотарите ему думать, – сказала ему.
«Нет, это неприятно, и одно возможно. Очинаясь, что я не могу, но очень рада, – сказал Степан Аркадьич, совсем приготовили ему с своих платье и всех дорогах с которая он с ней стало больши всего, или возможно, – поднялся от всех из-за движения которой надо сказать ему.
– Нет, вы не видала его. Я не могу высказать его. Я возмралась во взгляду на своего мнения, – сказал Левин, стала стараяться со себя советиеть и не может сказать его. Он все приезжал и поставил получившие про то, что все будущоЗдесь мы видим, что слова, в основном, правильно складываются из букв. Размечены диалоги, неплохо расставлены знаки препинания и т.д. Если смотреть издалека и не вчитываться в текст, выглядит достойно.
Заключение
Очевидно, что писать как Лев Толстой наша сеть все-таки не научилась, но прогресс по мере обучения налицо. При этом чтобы двигаться в сторону большей осмысленности, нужно использовать другие методы (например word embedding), поскольку с помощью char-wise RNN можно относительно легко получить хорошую грамматику, но добиться смысла от текста видимо непросто.
Тем не менее этот пример иллюстрирует то, какая магия может происходить внутри нейронной сети, при том, что никакие правила, никакая грамматика языка на вход ей не подается и до всего этого ей приходится додумываться самой.
Разумеется на вход можно подавать другой текст (желательно не менее объемный), на любом языке, играться с гиперпараметрами и получать какие-то другие результаты. Надеюсь, даже простое повторение описанных шагов может кого-то побудить разобраться в том, как тут все устроено и я гарантирую, что на этом пути у вас будет много интересных открытий :)
Комментарии (35)

aamonster
22.11.2017 21:23Хороший текстик. А с наивным алгоритмом "построить ppm-модель и распаковать с её помощью массив случайных чисел" сравнить не хотите? Благо, ppm-based архиваторов в исходниках хватает.
(В сравнении интересно как качество текста, так и скорость работы и требования к памяти)

Nagg
23.11.2017 05:42Всегда подозревал что текст к русскому пОпу и рэпу пишет рекуретная нейронная сеть.
Sinatr
23.11.2017 11:27получив на вход текст романа Толстого «Анна Каренина», будет генерировать свой текст
Было бы лучше скармливать самописный текст, который программа будет обрабатывать (как делает Prisma с фотографиями, обрабатывая их и выдавая за произведения искусства) и выдавать за классиков.
turegum Автор
23.11.2017 11:45В смысле, расписать красивыми вензелями фразу про счастливые семьи на фоне моста из картины «крик»? Это, пожалуй, ближе к сверточным сетям, а не рекуррентным.
alexvangog
23.11.2017 12:29Прочитав статью, руки зачесались, как захотелось все это увидеть воочию. Отправив весь приведенный код на свой сервер, с нетерпением стал ждать результата. Теперь хочу поделиться ими.
Время обучения около полутора часов, вот с таким значением Training loss.
Epoch: 20/20... Training Step: 3400... Training loss: 1.3823... 1.5089 sec/batch
Вот, что выдает сеть при использовании последнего checkpoint'а:
$ python3 rnn.py Гостиная Анны Павловны начала понемногу наполняться. Он постылавший выражение ее с того, что она в других начала стало более. На кусти свидать все по столу представлялись он сколько весело питили ее в своей деревне. – Ну, что же мой молодый меня, – сказал он, улыбаясь и отвечая его; – вы видели и после вашего положения с тепорками и оставалось слышали, – отвечал Левин, и потому что вы сделали его воспоминание от самого; но ты знаешь, что я висела не может. Она пишет в наше строение, не спал на свою жизнь и выражение его продоржалось. Он скучно. Но в право в эти дело. Весело при себе своими правительным взглядом и, несмотря на то, что он не понимал, и не могу прежде, – сказал Левин; вы наслужати его приятель и всегда всегда выразить могут, что с собой от него и старались видеть. – Ну, как же, что, как я просил во меда выходить с нею. Но я про это понимаю, что в тем напроления его возражает своиго собратия на меду кончковыми, и подошел к ней. – Я не вижу в эти презрения, ни одна и провеленный предложений, – сказал он, смотра и ответав их. – Не терее, – сказал Алексей Александрович. – Ките, что же мог собрать? Ты не понимаюшь своего новое, – и не могут призниться с ним. – Да вы скажите? – Непровиди, я не признаю вас, – отвечала Анна и с тем открытом взглянувая на все плять не планово. Но в криком непременности стола, как оскорбила его, не остановившая ему. Вот какий подходил к девешу, подошел его взгляда, прежде веселыми слизами и первой руки. Она посмотрела на вспоминать из дореги после него, и она высоколо пристало с протявом веще с тем в стальником веселом дело, и потому, что отвечал его, но оставался слов, новою семейною отказавшеюся перебить его со своею ридовую дело. И в этом словом все была так, в пестренениях отношения и не видит только при всем сердце и в которому она была на круга никогда об исполнении которых она опять со старым представлением от него с какимо-то предстоящим общуго не случалось, что склоните с середом поднимал его. – На что же мне нужно было на всего последнее, что он сделал, – сказал
turegum, спасибо за статью и за разжигание моего интереса к теме машинного обучения!turegum Автор
23.11.2017 12:31Спасибо за отзыв ) Хороший текст получился! Как вариант, можно прибить весь французский из исходного текста, сократив алфавит (т.е. кол-во классов из которых мы выбираем). В теории должно позитивно сказаться на качестве :)

ZhuLong
23.11.2017 12:35Вот этот фрагмент в функции get_batches неправильный
y[:, :-1], y[:, -1] = x[:, 1:], x[:, 0]
Вы в конец у подставляете первое значение x, а должны подставлять x[i+1, 0] из следующей строки.turegum Автор
23.11.2017 12:59Ну это, конечно, было сделано для упрощения (есть предположение, что это не сильно ухудшит конечный результат), но спасибо за наблюдательность.
alec_kalinin
23.11.2017 13:45Вообще, тексты вполне гениальные, особенно после редактуры:
— Как у тебя дела с тепорками?
— Да так, с протявом. А вот со стальниками веселое дело.
Оба высоколо пристали.

DaneSoul
23.11.2017 15:24А если подобную логику попробовать проганать не на отдельных буквах, а целых словах?
При этом загрузить не одно произведение, а целое собрание соченений, чтобы выборка была больше.
Думаю за счет отсутсвия несуществующих слов, результат может быть куда интересней и реалистичней.turegum Автор
23.11.2017 15:34в лоб эту задачу не решить, просто заменив символы на слова — размер словаря, то есть количество классов из которых надо делать выбор следующего элемента, будет на много порядков больше (десятки и сотни тысяч вместо наших 140). Я поэтому и написал в заключении, что нужны другие технологии вроде word embeddings

nivorbud
23.11.2017 16:10Спасибо за интересный пример, я тоже занимаюсь изучением этих алгоритмов. Конечно лишь от одной символьной последовательности я большего и не ожидал, вернее ожидал меньшего.
Процесс обучения Однако оказался весьма интересным и занятным, и прогресс налицо:
В какой-то момент сетка даже ругнулась матом :)
Мне сразу вспомнилась сцена создания Шарикова: «Абыр… абырвалг… Примус! Пивная!.. ещё парочку...»
Alex320
23.11.2017 16:23+1По-моему не очень хорошая идея генерировать по буквам, не эффективнее ли обучить на этом тексте word2vec и попытаться создать стилизатор текста? Если будет интересно могу написать хаб.
turegum Автор
23.11.2017 16:25Да, я об этом и писал в заключении — про embeddings. А напишите свой пример с word2vec, я думаю будет очень много благодарных читателей!
Alex320
24.11.2017 21:47Ждем проверки. Статью написал. Раскрыл самые основы — обучение, до обучение подготовка данных. Начинающим должно быть интересно. В следующей статье постараюсь объяснить как можно больше сложных моментов. Надеюсь, что вам понравится

Dirac
23.11.2017 16:27Это было ясно еще много лет назад. Модель на основе только многослойной rnn (lstm) не способна к генерации адекватных текстов. К тому же на уровне только символов (без обучения embedding'у или без уже обученного word2vec), пары слоев явно будет недостаточно для создания нужной глубины абстракции и обучения контексту. На сегодняшний день эта модель слишком проста и конечно не может справиться с этой задачей. Но вот модель bidirectional seq2seq encoder-decoder with attention уже способна к генерации адекватных предложений на основе предыдущих. «Галлюцинировать» на такой модели можно намного качественнее. Но и этого тоже будет недостаточно. Чтобы сохранять глобальный контекст модели желательно иметь доступ к памяти и обучиться записи и считыванию. Такая «Нейронная Машина Тьюринга» уже будет иметь возможность нести и изменять «контекст» от предложения к предложению.
Но пока можете попробовать seq2seq, гарантирую совершенно другой уровень качества. Эту модель использует переводчик от google. Модель seq2seq помогла выйти на совершенной иной уровень машинного перевода. А ведь на уровне декодера — это и есть задача генерации текста.turegum Автор
23.11.2017 18:06Вообще ни с чем не спорю. См. дисклеймер — «Профессионалы Deep Learning скорее всего не найдут тут ничего интересного»
Alex320
23.11.2017 16:49Да, seq2seq это интересная тема, но так уже становится не совсем интересна. Когда же ты пишешь сам хотя бы на основе word2vec есть над чем поработать и улучшить. Seq2seq же уже особо не перепишешь… Насчет статьи согласен — напишу обязательно
overmind88
На словах сетка пишет как Лев Толстой. А на деле… :D
turegum Автор
А на деле даже не Алексей Толстой, но будем надеяться, что у неё все впереди :)
erwins22
Просто Лев мало писал… Вот если на Ленине попробывать…
turegum Автор
Думал об этом, но есть риск, что сетка издаст декрет о национализации моего ноута, на котором она обучалась, а это жалко :)
Zoolander
пока вы не поставите сетку на броневик, все будет в пределах нормы
unPolymorph
А на деле перцептрон простой
pronvis
*на тестовых датасетах