
Введение
Зачастую нам нужно воспроизвести аудио-информацию, которая не была записана заранее, и извлекается из источника данных динамически: имя человека, название города, статус заказа и т.п. Особенно эта возможность востребована в колл-центрах и порталах самообслуживания.
Для этого лучше всего использовать технологию TTS (преобразование текста в речь), поскольку она динамически создает нужные аудиофайлы, а голосовое приложение, работающее на сервере 3CX, проигрывает их абоненту. Для генерации аудиофайлов используется определенный веб-сервис, после чего создается локальный WAV файл. Когда разговор с абонентом завершился, файл удаляется для освобождения места на диске.
Для данной возможности в 3CX следует зарегистрировать аккаунт на Amazon Web Services. 3CX использует веб-сервис TTS Amazon Polly. После изучения различных TTS сервисов, мы выяснили, что Amazon Polly обладает отличным качеством генерации, хорошим охватом языков, множеством разных голосов и весьма доступной ценой. Также он бесплатен в течение первого года использования! С другой стороны, в будущем мы планируем добавить поддержку TTS и от других мировых производителей.
Обратите внимание — для работы TTS генерации необходимо использовать 3CX v15.5 SP2 и выше.
Среда разработки 3CX Call Flow Designer получила новый тип аудио-сообщений Text to Speech Audio Prompt. Вы можете выбрать его в любом месте, где требуется проиграть сообщение, например, в компонентах Prompt Playback, Menu, User Input и других.
В этой статье мы расскажем, как создать аккаунт Amazon Web Services, включить Amazon Polly и начать использовать компонент Text to Speech Audio Prompt для генерации естественной речи в вашем колл-центре.
Обратите внимание — среда разработки 3CX CFD поставляется бесплатно. Но голосовые приложения будут выполняться только на 3CX редакции Pro и Enterprise. Скачать CFD можно отсюда.
Для вашего удобства, демо-проект этого голосового приложения поставляется вместе с дистрибутивом 3CX CFD и находится в папке Documents\3CX Call Flow Designer Demos.
Создание аккаунт Amazon Web Services (AWS)
Перед началом работы с CFD приложением, создайте аккаунт Amazon Web Services. Для этого ознакомьтесь с руководством от Amazon.
Создание служебного пользователя Identity and Access Management (IAM)
После создания AWS аккаунта, создайте пользователя, учетные данные которого наше голосовое приложение использует для доступа к AWS. Следуйте руководству от Amazon. Укажите тип доступа Programmatic access. При настройки прав доступа выберите Attach existing policies directly, затем найдите и отметьте AmazonPollyFullAccess.
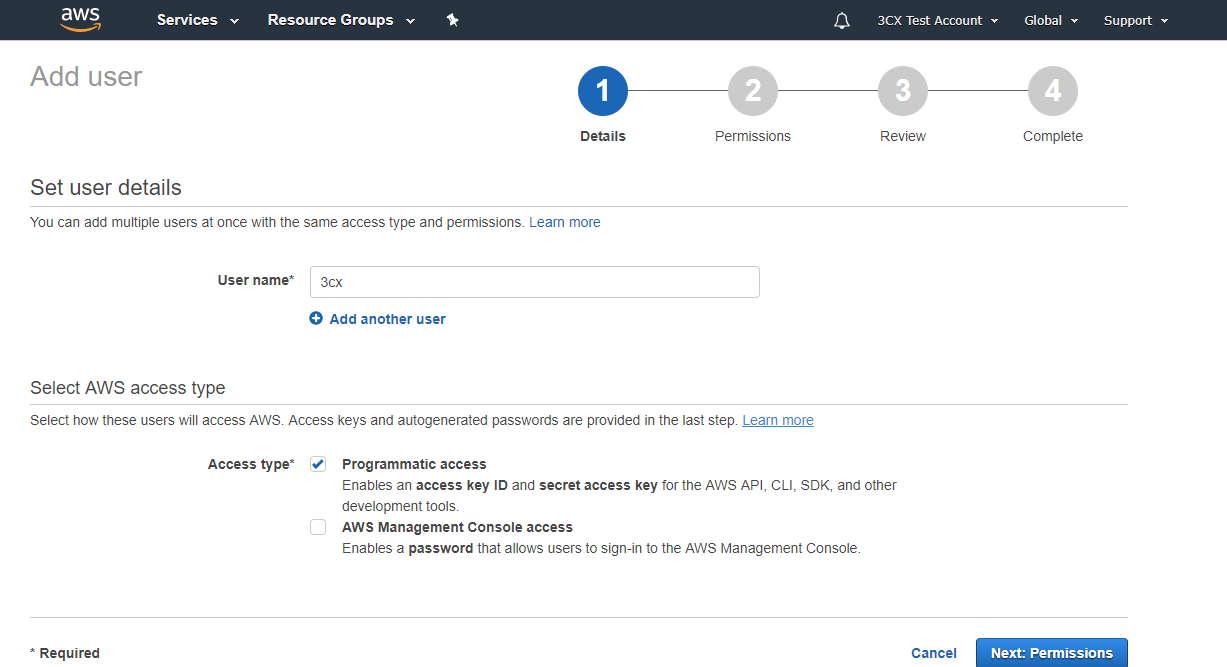
Затем перейдите в параметры пользователя в раздел Security credentials и кликните Create access key. Зафиксируйте Access key ID и Secret access key — эти данные потребуются при настройке TTS сервиса в голосовом приложении.

Внимание! Ознакомьтесь с ограничениями TTS Amazon Polly. Эти ограничения не должны создавать проблем в большинстве CFD приложений, однако имейте их ввиду.
Создание проекта
Для создания проекта CFD перейдите в File > New > Project, укажите папку размещения проекта и его имя, например, TextToSpeechDemo.
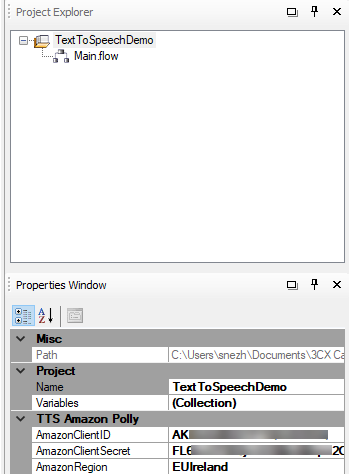
Выделите проект в разделе Project Explorer. Рассмотрим параметры проекта (раздел Properties), которые необходимо указать для работы TTS:
- AmazonClientID — Access key ID, сгенерированный выше.
- AmazonClientSecret — Secret access key, сгенерированный выше.
- AmazonRegion — выберите географический регион AWS, ближайший к расположению сервера 3CX.
Эти параметры будут использоваться в любом сообщении типа Text To Speech Audio Prompt в этом проекте.
Добавление компонента Prompt Playback
Как было сказано ранее, обычно TTS используется для генерации речи из текста, полученного из базы данных или веб-сервиса. Но для упрощения нашего примера мы подготовим короткую фразу, добавим к ней переменную из нашего голосового приложения и преобразуем все это в речь. Мы определим переменную AccountBalance и установим ее значение в 100. Затем подготовим фразу: «Баланс вашего счёта 100 долларов».
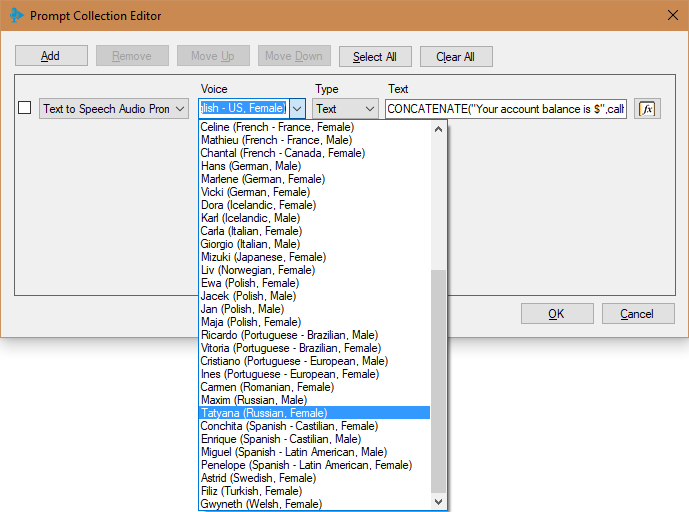
Для добавления компонента Prompt Playback:
- Переместите компонент Prompt Playback в окно разработки приложения (Main callflow). Выберите компонент и в разделе свойств переименуйте его в playPrompt.
- Там же откройте Prompt Collection Editor, нажав кнопку возле свойства Prompts.
- Нажмите Add для добавления нового в сообщении в коллекцию и измените тип сообщения на Text to Speech Audio Prompt.
- Выберите голос, который вы хотите использовать. Список голосов отсортирован по языку. Голоса, доступные для Amazon Polly, перечислены здесь. Если Amazon выпустит новый голос, не представленный в списке, вы можете начать использовать его, указав идентификатор из столбца Name/ID. Если вы хотите, чтобы определенный голос всегда был установлен в приложении по умолчанию, укажите его в меню 3CX CFD Tools > Options > Component Templates > Text To Speech. Для нашего примера будем использовать голос Joanna (English — US, Female).
- Выберите тип текста: Text и SSML (Speech Synthesis Markup Language). Как правило, вы будете использовать Text. При этом значение свойства Text — обычный набор символов (plain text), и TTS сервис будет синтезировать его как есть. Если вы укажете тип SSML, значение свойства Text — XML файл в соответствии со спецификацией SSML. SSML позволяет задавать различные параметры речи: произношение, громкость, скорость. Для дополнительной информации см. руководство Using SSML. В нашем примере используется тип Text.
- Укажите выражение для опции Text. В зависимости от типа текста, выбранного в предыдущем шаге, выражение должно вернуть простой текст для синтеза или XML данные, в соответствии с SSML спецификацией. Для нашего примера используем следующее выражение:
CONCATENATE("Your account balance is $",callflow$.AccountBalance)
Компиляция и установка приложения на сервер 3CX
Голосовое приложение готово! Теперь его следует скомпилировать и загрузить на сервер 3CX. Для этого:
- Перейдите в меню Build > Build All, и CFD создаст файл PredictiveDialerDemo.tcxvoiceapp.
- Перейдите в интерфейс управления 3CX, в раздел Очереди вызовов. Создайте новую Очередь вызовов, укажите название и добавочный номер Очереди, а затем установите опцию Голосовые приложения и загрузите скомпилированный файл.
- Сохраните изменения в очереди. Выполните вызов на добавочный номер Очереди, чтобы протестировать приложение. Обратите внимание — при самом первом звонке в приложение, TTS генерация может быть выполнена с задержкой в несколько секунд. Это связано с процессом аутентификации и происходит только один раз.
Заключение
Обычно в синтезированной речи используется несколько статических сообщений, например, приветствие для пользователей или выбор опции меню, и несколько динамических — например, баланс счёта. Желательно использовать TTS сервис Polly только для изменяемых данных — это позволит избежать дополнительных расходов на синтез повторяющихся фраз. С другой стороны, необходимо, чтобы все фразы были произнесены одинаковым голосом. Для этого лучше всего создать готовые голосовые файлы для статических фраз через консоль Amazon Polly и загрузить их как WAV файлы в голосовое приложение. Используйте эти файлы в обычных сообщениях Audio File Prompt вместо повторяющейся динамической генерации.
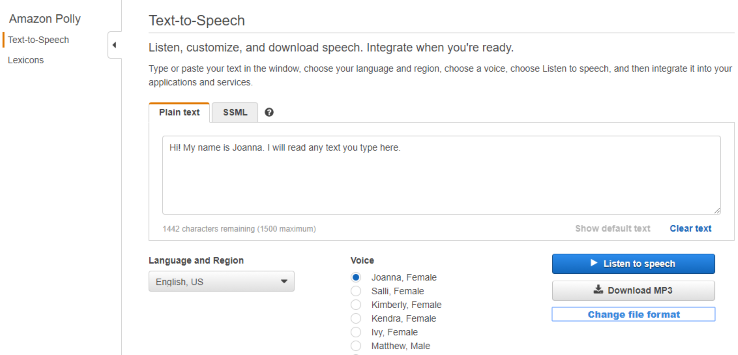
В консоли Amazon Polly выберите ваш язык, регион, желаемый голос, введите нужный текст и нажмите Download MP3. Обратите внимание, 3CX использует звуковой формат WAV, Моно, 8.000 Гц, 16 бит. Поэтому после загрузки файла сконвертируйте его в поддерживаемый формат, как указано здесь.
Комментарии (7)

EndUser
09.12.2017 11:44Это продукт Ivona, вполне неплохая говорилка. Не нейронка, не глубокое обучение. После покупки амазоном Ивона заткнулась — удалила свои моторы с гуглобазара и закрыла демо на своём сайте. Печально. И вот, через два года новость — она где-то во глубине амазонских руд, и её оттуда надо клещами вытаскивать.

LorDCA
10.12.2017 16:36Ожидал увидеть детальный разбор с подготовкой сэмплов и настройкой нейросети. А увидел инструкцию как отослать текст в амазон и получить вавку. Как это вообще относится к хабру?

snezhko Автор
10.12.2017 16:38К Хабру это относится тем образом, что его читают не только специалисты по обучению нейронных сетей, а и обычные админы или даже менеджеры колл-центров, которым нужно просто и быстро решить задачу генерации речи в своем небольшом колл-центре.
ze2n7
почему нет гендерно-нейтрального голоса?
snezhko Автор
Согласен. Это преступная халатность Amazon.