

Каждое устройство Cloud TPU состоит из четырёх «чипов TPUv2». В чипе 16 ГБ памяти и два ядра, каждое ядро с двумя юнитами для умножения матриц. Вместе два ядра выдают 45 TFLOPS, в общей сложности 180 TFLOPS и 64 ГБ памяти на один TPU
Большинство из нас осуществляет глубинное обучение на Nvidia GPU. В настоящее время практически нет альтернатив. Тензорный процессор Google (Tensor Processing Unit, TPU) — специально разработанный чип для глубинного обучения, который должен изменить ситуацию.
Через девять месяцев после первоначального анонса две недели назад Google наконец-то выпустила TPUv2 и открыла доступ первым бета-тестерам на платформе Google Cloud. Мы в компании RiseML воспользовались возможностью и прогнали парочку быстрых бенчмарков. Хотим поделиться своим опытом и предварительными результатами.
Давно мы ждали появления конкуренция на рынке оборудования для глубинного обучения. Она должна разрушить монополию Nvidia и определить, как будет выглядеть будущая инфраструктура глубинного обучения.
Имейте в виду, что TPU пока в ранней бета-версии, о чём явно и повсеместно напоминает Google — так что некоторые обсуждаемые оценки могут измениться в будущем.
TPU в облаке Google
В то время как первое поколение чипов TPUv1 ориентировалось на ускорение вывода данных, нынешнее второе поколение в первую очередь фокусируется на ускорении обучения. В основе TPUv2 — систолический массив, отвечающий за умножение матриц, которые активно используются в глубинном обучении. Согласно слайдам Джеффа Дина, каждое устройство Cloud TPU состоит из четырёх «чипов TPUv2». В чипе 16 ГБ памяти и два ядра, каждое ядро с двумя юнитами для умножения матриц. Вместе два ядра выдают 45 TFLOPS, в общей сложности 180 TFLOPS и 64 ГБ памяти на один TPU. Для сравнения, у нынешнего поколения Nvidia V100 всего 125 TFLOPS и 16 ГБ памяти.
Чтобы использовать тензорные процессоры на платформе Google Cloud, нужно запустить Cloud TPU (предварительно получив на него квоту). Нет необходимости (и возможности) назначить Cloud TPU конкретному инстансу виртуальной машины. Вместо этого доступ TPU из инстанса осуществляется по сети. Каждому Cloud TPU присваивается имя и IP-адрес, которые следует указать в коде TensorFlow.
Создание нового Cloud TPU. Обратите внимание, что у него есть IP-адрес. Анимация GIF
TPU поддерживаются только в TensorFlow версии 1.6, которая пока в статусе релиз-кандидата. Кроме того, для VM не нужны никакие драйверы, поскольку весь необходимый код включён в состав TensorFlow. Код для выполнения на TPU оптимизируется и компилируется JIT-компилятором XLA, тоже входящим в состав TensorFlow.
Чтобы эффективно использовать TPU, код должен быть основан на высокоуровневых абстракциях класса Estimator. Затем переходим к классу TPUEstimator, который выполняет множество необходимых задач для эффективного использования TPU. Например, настраивает очереди данных для TPU и распараллеливает вычисления между ядрами. Определённо есть способ обойтись без использования TPUEstimator, но нам пока не известны такие примеры или документация.
Когда всё настроено, запускайте свой код TensorFlow как обычно. TPU обнаружатся при загрузке, график расчётов скомпилируется и будет передан туда. Интересно, что TPU ещё умеет напрямую читать и записывать в облачное хранилище контрольные точки и сводки (event summaries). Для этого нужно разрешить запись в облачное хранилище в аккаунте Cloud TPU.
Бенчмарки
Конечно, самое интересное — реальная производительность тензорных процессоров. В репозитории TensorFlow на GitHub есть набор проверенных и оптимизированных моделей TPU. Ниже показаны результаты экспериментов с ResNet и Inception. Ещё мы хотели посмотреть, как обсчитывается модель, не оптимизированная для TPU, поэтому адаптировали модель для классификации текста на архитектуре долгой краткосрочной памяти (LSTM) для запуска на TPU. Вообще-то Google рекомендует использовать более крупные модели (см. раздел «Когда использовать TPU»). У нас модель поменьше, так что особенно интересно посмотреть, даст ли TPU какое-нибудь преимущество.
Для всех моделей мы сравнили скорость обучения на одном Cloud TPU с одним графическим процессором Nvidia P100 и V100. Нужно заметить, что полноценное сравнение должно включать в себя сравнение окончательного качества и сходимости моделей, а не просто пропускную способность. Наши эксперименты — это лишь поверхностные первые бенчмарки, а подробный анализ оставим на будущее.
Тесты для TPU и P100 запускались на инстансах n1-standard-16 платформы Google Cloud (16 виртуальных CPU Intel Haswell, память 60 ГБ). Для графического процессора V100 использовались инстансы p3.2xlarge на AWS (8 виртуальных CPU, 60 ГБ памяти). Все системы под Ubuntu 16.04. Для TPU установили TensorFlow 1.6.0-rc1 из репозитория PyPi. Тесты для GPU запускались из контейнеров nvidia-docker с образами TensorFlow 1.5 (tensorflow:1.5.0-gpu-py3), включающими поддержку CUDA 9.0 и cuDNN 7.0.
TPU-оптимизированные модели
Посмотрим сначала на производительность моделей, которые официально оптимизированы для TPU. Ниже показана производительность по количеству обрабатываемых изображений в секунду.
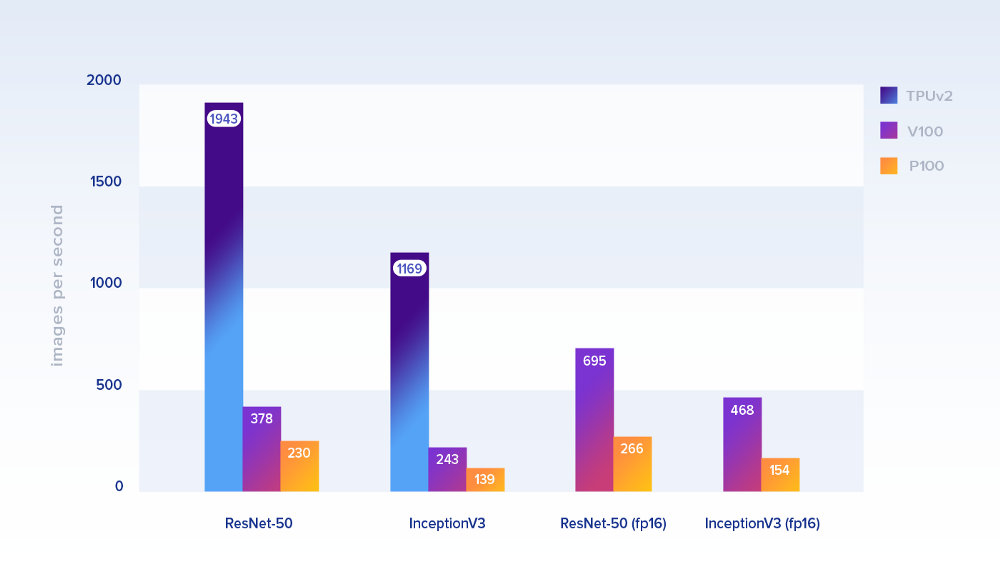
Размеры пакетов: 1024 на TPU и 128 на GPU. Для последних взяли реализацию из репозитория бенчмарков TensorFlow. В качестве данных для обучения — симуляция набора данных ImageNet от Google в облачном хранилище (для TPU) и на локальных дисках (для GPU)
На ResNet-50 один тензорный процессор Cloud TPU (8 ядер и 64 ГБ ОЗУ) были примерно в 8,4 раза быстрее, чем один P100, и примерно в 5,1 раза быстрее, чем V100. Для InceptionV3 разница в производительности почти такая же (~8,4 и ~4,8, соответственно). На вычислениях с меньшей точностью (fp16) V100 значительно прибавляет в скорости.

Понятно, что кроме скорости нужно учитывать и цену. В таблице показана производительность, нормализованная по цене с ежесекундным биллингом. TPU всё равно явно выигрывает.
Кастомные модели LSTM
Наша кастомная модель — это двунаправленная LSTM для классификации текста с 1024 скрытыми юнитами. LSTM являются основными строительными блоками в современных нейросетях, так что это хорошее дополнение для официальных моделей машинного зрения.
Оригинальный код уже использовал фреймворк Estimator, так что очень легко адаптировать его для TPUEstimator. Хотя есть одна большая оговорка: на TPU мы не смогли добиться сходимости модели, хотя та же модель (размер пакетов и прочее) на GPU работала нормально. Думаем, это из-за какого-то бага, который будет исправлен — либо в нашем коде (если найдёте его, сообщите нам!), либо в TensorFlow.
Оказалось, что TPU обеспечивает даже бoльшую прибавку в производительности на модели LSTM (21402 образца/с): в ~12,9 раза быстрее, чем Р100 (1658 образцов/с) и в ~7,7 раза быстрее, чем V100 (2778 образцов/с)! Учитывая, что модель сравнительно небольшая и никак не оптимизировалась, это очень многообещающий результат. Но пока баг не исправлен, эти результаты будем считать предварительными.
Вывод
На протестированных моделях TPU очень хорошо проявили себя как по производительности, так и с точки зрения экономии денег, по сравнению с последними поколениями GPU. Это противоречит предыдущим оценкам.
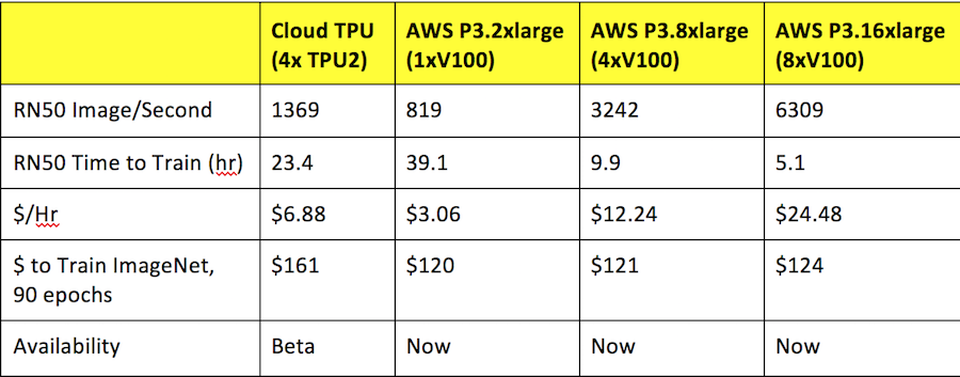
Результаты предыдущих бенчмарков. Источник: Forbes
Хотя Google продвигает TPU как оптимальное решение для масштабирования больших моделей, наши предварительные результаты на маленькой модели оказались очень многообещающими. В целом, опыт использования TPU и адаптации кода TensorFlow уже неплох для бета-версии.
Мы считаем, что когда TPU станут доступны более широкой аудитории, то могут стать реальной альтернативой Nvidia GPU.
Комментарии (13)
beduin01
27.02.2018 13:56Не могли бы пояснить на сколько этот чип быстрее топовых GPU? Просто из текста это не совсем понятно

leshabirukov
27.02.2018 15:08Вместе два ядра выдают 45 TFLOPS
ru.wikipedia.org/wiki/Список_графических_процессоров_NVIDIA#GeForce_1000_Series
GeForce GTX 1080 Ti — 10609 GFlops FMA

Akon32
27.02.2018 16:28в общей сложности 180 TFLOPS и 64 ГБ памяти на один TPU. Для сравнения, у нынешнего поколения Nvidia V100 всего 125 TFLOPS и 16 ГБ памяти.
180 TFLOPS для тензоров (там float16 multiply-add, если не ошибаюсь).
в 1080 Ti — 10 TFLOPS для FMA
т.е., разница порядка 20 раз, но задачи специфические.


eeeeep
27.02.2018 18:59+3Хотя есть одна большая оговорка: на TPU мы не смогли добиться сходимости модели, хотя та же модель (размер пакетов и прочее) на GPU работала нормально.
Напоминает анекдот:
Устраивается секретарша на работу. Директор спрашивает:
— Какая у вас скорость печати?
— 10000 знаков в минуту!
— Так много???
— Правда такая ерунда получается…

Tutufa
27.02.2018 21:13Сравнение некорректное, в 1 TPU стоит 4 чипа, а в V100 1 чип, да и RNN из тестов не сошлась

HermaMora
В идеале, чтобы эта штука еще и майнить могла, желательно лучше видеокарт.
Скрещу пальцы, чтобы последние наконец начали дешеветь.
pdima
Пусть лучше эта штука дешевеет
Mehdzor
https://www.youtube.com/embed/VMvn-26Kr94 — вместо комментария
JekaMas
Дай боже, чтобы майнить на ней было невозможно во веки вечные.