
 Перевод любопытной статьи Стюарта Рейнса, дающей обзор некоторых подходов и техник поиска причин инцидентов и проблем. Обзор поверхностный, но и такого уровня погружения достаточно, чтобы зародить интерес к затронутой теме.
Перевод любопытной статьи Стюарта Рейнса, дающей обзор некоторых подходов и техник поиска причин инцидентов и проблем. Обзор поверхностный, но и такого уровня погружения достаточно, чтобы зародить интерес к затронутой теме.Автор: Стюарт Рейнс (Stuart Rance)
Опубликовано 31.10.2017 в блоге SysAid раздел ITSM
Ссылка на оригинал: 7 Ways to Diagnose IT Incidents and Problems
Необходимо обучать сотрудников службы поддержки и остальной ИТ персонал техникам диагностики инцидентов и проблем, а также сопровождать их применение. Наличие достаточных технических знаний и навыков работы в ITSM процессах без навыков этих техник не достаточно для результативного выполнения задач диагностики.
Диагностика ИТ инцидентов и проблем
В каждой ИТ организации есть процессы для управления инцидентами и проблемами. Часто они основаны на идеях из ITIL, чьи описания лучших практик управлениями ИТ услугами сейчас наиболее часто применяются в мире. В соответствии с ITIL, инцидент — это “незапланированное прерывание ИТ услуги или ухудшение ее качества...”, а проблема — это “любая причина, вызывающая один или более инцидентов...”. Цель управления инцидентами — восстановить плановое состояние услуги, а управление проблемами помогает уменьшить последствия от будущих инцидентов.
Процессы управления инцидентами и проблемами определяют шаги, выполняемые сотрудниками для планирования и реализации решения задач. В составе этих шагов почти всегда есть один, называемый “Обследование и Диагностика” (или что-нибудь очень на это похожее), в ходе которого свершается магия обнаружения причины.
Для людей, чья работа заключается в исправлении ситуации, когда что-то идёт не так, наиболее важным является выявление причин ошибок и определение в результате способа их устранения. Конечно, в рамках самого процесса выполняется много других действий, таких как поддержание в актуальном состоянии информации в записи обращения и информирование пользователя, когда имеется решение, но большая часть времени тратится именно на “Обследование и Диагностику”.
Когда мы обучаем сотрудников ИТ поддержки и другой ИТ персонал, то часто отправляем их на технические курсы, чтобы быть уверенными, что они понимают технологии, с которыми работают, потом мы их отправляем на курсы по ITIL (или по другим лучшим отраслевым практикам) для уверенности, что они понимают работу процессов и как они согласовываются с остальной деятельностью в ИТ. Но мы очень редко действительно учим людей, как обследовать и диагностировать инциденты и проблемы. Часто даже не предоставляется наставник, чтобы дать навыки работы выявления причин неисправностей. Мы считаем, что они и так знают, как это делать. А крайне прискорбный факт заключается в том, что на самом деле неопытный персонал с большой вероятностью понятия не имеет, как подойти к этим обследованию и диагностике, и действительно знающих, что делать, специалистов практически не имеем.
И так, выполняете ли Вы сами диагностику инцидентов и проблем или управляете теми, кто их делает, читайте далее, где я расскажу об особенностях подходов, которые позволяют решать эти задачи. Изучите эти подходы и Вы сможете при необходимости их применять. Будут приведены наиболее полезные практики, но текущий их перечень не исчерпывает все возможные варианты.
Подходы для диагностики Инцидентов и Проблем
Часть описываемых подходов позволяют выполнить только диагностику, остальные же могут решать более широкий спектр задач. Понимание всех их особенностей позволит Вам самим решать какой именно подход лучше всего подойдет в конкретной ситуации.
1 Подход Ричарда Фейнмана
Известный физик Ричард Фейнман предложил процесс решения физических проблем, который выглядит следующим образом:
- Описать задачу
- Очень сильно подумать
- Написать ответ
Этот метод прекрасен в своей простоте, но, возможно, он не будет работать у тех, кто не достаточно умён, чтобы получить Нобелевскую премию. Так что, я уверен, что это подход можно использовать, если Вы ОЧЕНЬ умный или работаете с простой задачей и имеете доступ ко всем знаниям и информации, которые только могут потребоваться. Стоит использовать этот подход в купе с другими, о которых будет рассказано ниже, но сильно подумать прежде, чем делать выводы — это всегда хорошая практика.
2. Анализ истории наблюдений
Это настолько простой способ обследования инцидента или проблемы, что едва ли стоит о нем рассказывать. Нужно просто на временную шкалу поместить список всего случившегося с объектом анализа и изучить полученный список. Важно, чтобы все полученные записи содержали вне зависимости от источника данных дату и время, когда событие произошло, и были отсортированы по ним. Ваша временная шкала может содержать данные из логов систем, писем, записей в базе обращений пользователей и множества других источников. Этот подход на удивление эффективен для построения общей картины происходившего.
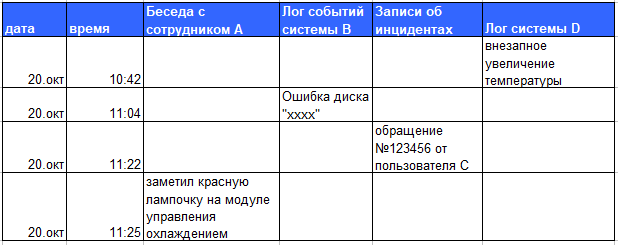
Рисунок 1 — Пример анализа истории наблюдений
Я сам почти всегда начинаю обследование с анализа истории событий, т.к. это часто позволяет понять, что именно случилось, а также это позволяет получить всю требуемую информацию для применения более изощрённых подходов, если их применение необходимо.
3. Решение проблем по методу Кепнера-Трего
Несмотря на то, что я искренне считаю, что это подход чрезвычайно эффективен, по лицензионному соглашению при использовании этого проприетарного подхода для обучения я обязан озвучивать свой интерес к нему.
Это структурированный подход для решения проблем, в котором проблема определяется через ряд различных аспектов (что, где, когда, насколько) и также связать проблему с аспектами, при которых сбои не происходили. И затем можно посмотреть разницу этими определенными возможными ситуациями.

Рисунок 2 — Упрощённый пример использования решения проблем методом Кепнера-Трего
4 Диаграмма Ишикавы или скелет рыбы
Диаграмма Ишикавы — это путь постепенно уничтожать потенциальные причины проблем. Причины группируются по категориям и позволяют понять и визуализировать их взаимосвязи. Можно создать такие диаграммы для упрощения выявления всех потенциальных причин, вызывающих проблемы, в течении диагностики. А ещё они могут создаваться, как часть документации на продукт, что даёт возможность сразу их использовать в решении любых возникающих вопросов.

Рисунок 3 — Упрощённый пример диаграммы Ишикавы для услуги электронной почты.
5. Знаниеориентированная поддержка
Это в первую очередь методология для сбора и управления информацией, которая обеспечивает потребности ИТ персонала и сотрудников Service Desk. Если запрашиваемая информация становится доступной тому, кто в ней нуждается в требуемое им время, то и это может привести к быстрому осознанию происходившего и быстрому решению инцидентов и проблем. А люди обладающие доступом к правильным знаниями с гораздо большей вероятностью смогут воспользоваться методом решения проблем Ричарда Фейнмана!
6. “Муравейник” (Swarming)
Это коллективный подход, отличный от классического управления инцидентами не только в фазе диагностики, но и во многих других аспектах. Отсутствует эскалация на более высокие уровни поддержки, и взамен конкретного человека, способного помочь, включается участие в “муравейнике”, что означает наличие множества людей из различных частей организации, обладающих обширным диапазоном актуальных знаний и навыков для совместного решения вопроса. “Муравейник” может применять также часть описанных в этом блоге подходов, но ключевая его особенность в сотрудничестве между многими людьми с разнообразными навыками, дающая в результате более быструю и точную диагностику, а также решение инцидентов и проблем.
Подробнее о “муравейнике” можно почитать в этом блоге Джона Холла
7. Как всегда + по случаю (Standard+Case)
Это ещё один подход, в котором заменены многие привычные аспекты управления инцидентами. Он был разработан Робом Ингландом (Rob England) и описан в этой статье и других публикациях, которые можно найти по названию метода. Основная идея подхода в том, что типовые активности должны управляться за счёт четко определенных процессов, а более редкие и сложные (комплексные) — требуют ситуационного управления, с применением техник, разработанных в таких областях, как здравоохранение, социальная сфера, законодательство и охрана порядка. Эта техника обладает высокой результативностью при управлении инцидентами и одновременно даёт возможность гибкого подхода к решению сложных (комплексных) инцидентов.
Заключение.
Необходимо не только обучать сотрудников службы поддержки и остальной ИТ персонал способам диагностики инцидентов и проблем, но и сопровождать их применение. Оно не станет результативным только от того, что исполнители владеют достаточными техническими знаниями и навыками работы в ITSM процессах.
Существует множество техник и методологий, которые можно использовать, и Ваша задача попытаться оценить все многообразие различных подходов. Часть будет просто не применима для вашей среды, но чем больше разнообразных подходов Вы знаете, тем с большей вероятностью сможете выбрать оптимальный, когда потребуется.