
Задача
В тестовом заданий от компании Wheely мне предстояло реализовать аутентификацю через код в смс-сообщении. Суть процесса в следующем:
- Пользователь совершаете какое-либо действие.
- Для подтверждения этого действия генерируется код.
- Код отправляется в СМС-сообщении.
- Пользователь указывает ключ.
- Ключ проверяется на соответствие.
Результатом должно было стать самостоятельное приложение, которое выполняет задачи, обозначенные в пунктах 2, 3 (только имитация), 5. Пины становятся не актуальны через 2 минуты после генерации. Все остальное на мое усмотрение.

Я выполнял подобную задачу (с разной степенью проработки) уже дважды, однако оба раза в качестве монолитного сервиса, стараясь использовать те технологии, которые уже были в проекте. В этом же задании было указано, что особое внимание при проверке будет уделено именно моему выбору инструментов.
Набросок
Итак, я пишу микросервис, который будет взаимодействовать с основным приложением клиента через API. В основе сервиса два главных компонента: создание пина и его проверка.
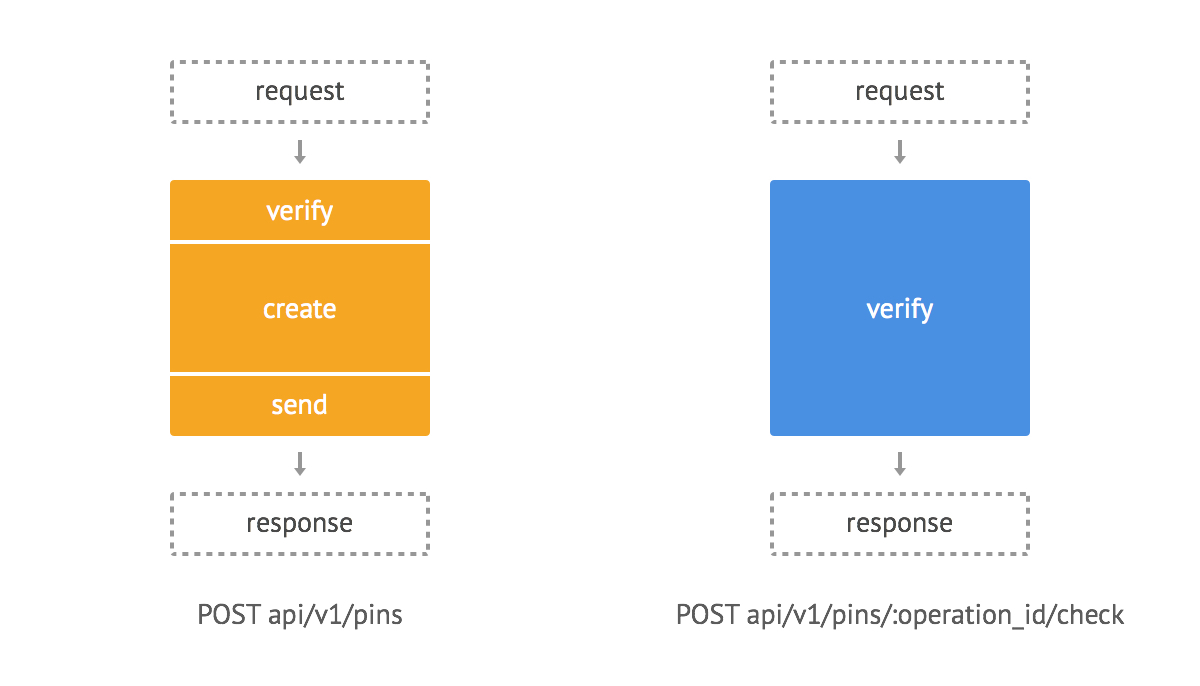
Пунктирной рамкой выделены компоненты, отвечающие за взаимодействие сервиса с основным приложением.
Инструменты
База данных
Здесь стоит обратить внимание на малый вес и непродолжительность хранения записи пина. Также стоит ориентироваться на обработку большого количества кодов.
Идеально под эти условиях подходит супербыстрая БД REDIS, так как кроме скорости у нее есть еще и замечательная опция expire, которая задает срок хранения записи. Благодаря этой маленькой опции мы избавляемся от кода, обслуживающего функцию «просрочки», а также не загружаем дорогую память нашей БД бесполезной информацией.
Веб-приложение
Нам нужен REST, не нужны вьюхи и избыточный (в данном случае) набор «хелперов», который предлагают многие фреймворки. Sinatra в данном случае очень хороший вариант: легковесный DSL под веб.
Проект
В данной главе я расскажу именно о микросервисных особенностях разработки и очень поверхностно опишу принцип работы компонентов приложения. Если у читателей возникнет интерес к процессу разработки самого сервиса, то я постараюсь подготовить для этого отдельную публикацию.
Сначала определимся, какие параметры будут бегать внутри нашего сервиса:
- api_token — ключ приложения;
- operation_id — уникальный код операции;
- phone — номер телефона;
- code — n-значный код подтверждения.
Теперь пропишем алгоритм работы компонентов.
Создаем пин
- Отправляем запрос:
POST 'https://test.dev/api/v1/pins', api_token: 'zx..d', operation_id: 'cs12', phone: '79..1'
- Проверяем доступ по api_token.
- Генерируем уникальный код и добавляем запись в базу (SET pins:$operation_id $code).
- Отправляем сообщение с кодом.
- Возвращаем ответ.
Проверяем
- Отправляем запрос:
POST 'https://test.dev/api/v1/pins/cs12/check', api_token: 'zx..d', code: '2213'
- Проверяем доступ по api_token.
- Сверяем полученный код и код, который хранится в связке с операцией -> в случае успеха удаляем запись из базы.
- Возвращаем ответ.
Генерируем ответы
В данном случае оба наших компонента будут возвращать одинаковые по структуре ответы. При успехе STATUS 200, в противном случае STATUS 403.
Итоги
Отлично, наше приложение принимает данные, обрабатывает их и возвращает ответ. Можно считать, что оно состоялось как микросервис :)
Плюсы:
- Основное приложение остается компактным.
- Оптимально для внедрения (меньше часа).
- Всю систему проще обслуживать и покрывать тестами.
- Гипотеза: повышается стабильность. Уход микросервиса в оффлайн никак не влияет на работу нашего продукта, так как он просто переключается на запасной сервис.
Минусы:
- Задержка при общении через API.
- Дополнительные ресурсы на деплой.
Закончить эту публикацию мне хочется на положительной ноте, так как в данном случае результат оправдал все ожидания. Однако, сразу хочу предупредить читателя, что микросервисная архитектура подходит далеко не для всего. Но это уже совсем другая история.
UPD.1. Перевел формат ответов с джейсона на статус-коды. За рекомендации и пояснения спасибо f0rk и smileonl.
Комментарии (61)

smileonl
29.06.2015 15:36+5Ещё вопрос. При формировании ответов REST вы предлогаете использовать такие варианты:
Успех:
{ 'result' => 0, 'message' => 'success' }
Неудача:
{ 'result' => 1, 'message' => 'fail', 'errors' => ['string_1', 'string_2'] }
Собственно почему вы не используете HTTP status codes www.restapitutorial.com/httpstatuscodes.html в ответах.
doniv Автор
29.06.2015 15:51-7Это хорошее замечание, возможно если бы это было не тестовое задание, то в следующей итерации поддержка ХТТП-кодов была бы реализована.
В данном случае мне было удобно именно так разбирать ответ.

f0rk
29.06.2015 15:59+8Предложенный API не имеет ничего общего с REST, но в данном случае, это не играет роли, как мне кажется. Такой формат общения с сервисом вполне решает задачу.
doniv Автор
29.06.2015 16:04-7Я понимаю о чем вы говорите и частично согласен. В терминологии отталкивался от этого ru.wikipedia.org/wiki/REST.

MadMac
29.06.2015 16:31+4Также уход микросервиса в оффлайн никак не влияет на работу нашего продукта, так как он просто переключается на запасной аналогичный сервис.
Если главный микросервис не пингуется, то пропускаем все процессы через вспомогательный.
Так всё-таки, как конкретно ваш продукт переключается (failover) на запасной инстанс микросервиса?
Ваш продукт на этапе деплоя знает местонахождение обоих микросервисов или используется балансировщик?
Что значит «пингуется»? ICMP Echo-Request? Кастомные heartbeats домашней выделки?doniv Автор
29.06.2015 16:37-8Это единственный момент в публикации, который я хотел бы реализовать, но на практике пока не столкнулся с такой необходимостью. Сейчас получил неплохие вычислительные мощности от азура, так что постараюсь и на этот вопрос сделать обзор.
Если у вас найдется время, то, пожалуйста, скиньте ссылки на статьи с описанием хорошего решения подобной задачи.MadMac
29.06.2015 17:00+5За облака не скажу, но в классическом энтерпрайзе ваш случай выглядел бы так (возможны вариаты):
— 2 HTTP балансировщика. Например NGINX установленных на виртуалки. Например RHEL 6-7. Hostnames: HOST1 и HOST2. IP: IP1 и IP2.
— на HOST1 поднят сетевой интерфейс c IP1 и также есть dummy интерфейс с IP2. на HOST2, соответственно — наоборот.
— на обеих машинах крутятся keepalived и пингуют друг-друга. Если keepalived на HOST1 теряет связь с HOST2, то он поднимает второй интерфейс (который dummy) c IP2 и HOST1 начинает обслуживать два IP адреса. То же самое для HOST2.
— в копроративных DNS серверах (а их должно быть несколько. и все должны быть прописаны на машине) делается A-запись типа balancer.mycompany.com
— для записи balancer.mycompany.com на DNS выставляется TTL по вкусу и настраивается round-robin балансировка на IP1 и IP2
— для A-записи содаётся CNAME типа http-balancer-prod
Отказоустойчивая инфраструктура для балансировки и динамического управления capacity ваших микросервисов готова.
Создана единая точка входа для всех микросервисов, использующих HTTP транспорт.
Балансировщик будет разруливать весь трафик на бэкенды анализируя HTTP-заголовок HOST.
Начните с ruhighload.com
grossws
30.06.2015 05:20+1на обеих машинах крутятся keepalived и пингуют друг-друга. Если keepalived на HOST1 теряет связь с HOST2, то он поднимает второй интерфейс (который dummy) c IP2 и HOST1 начинает обслуживать два IP адреса. То же самое для HOST2.
Интересно, часто ли бывают такие сплиты, когда эти keepalived друг друга не видят, но для остальной сети видны оба… И количество WTF/min у админов, когда маршрутизация начинает пытаться «угадать», куда дальше гнать трафик.MadMac
30.06.2015 10:30+1Если
для остальной сети видны оба
, то у keepalived, скорее всего не получится поднять в сети интерфейс с уже существующим в ней IP (тут тоже возможны варианты. зависит от архитектуры сети).
Вообще, multipathing в сети и добросовестное соблюдение процедур change management нивелируют риски возникновение таких ситуаций.
Если в вашей практике был подобный случай с VRRP расскажите, пожалуйста, как и почему это произошло и как решали проблему.grossws
30.06.2015 14:04А keepalived использует внешний арбитраж? Если нет, то как оно узнает, что второй IP занят, если оно не видит с него трафика (в предположении о возможности возникновения описанной мной ситуации)?
Я не админ, но как разработчик интересуюсь такими вещами. Таких хитрых сплитов не ловил. Обычно было достаточно обезьяны, которая воткнёт провод не в тот порт и сделает кольцо (после чего STP вырубит сегмент), или доброго свитча в blade enclosure, который свой oob ip светит через oob port и через обычный порт, которые случайно оказались в одном широковещательном домене выше (из-за того, что выше свели out-of-band и in-band в одном широковещательном домене).MadMac
30.06.2015 15:55+1Арбитра, кворума ничего такого нет. Сервисы общаются по IP multicast.
Keepalived — это реализация широкоизвестного VRRP на Linux.
Думаю, у меня не получится сказать лучше чем в rfc3768
По второй части Вашего вопроса могу ответить словами классика — все хорошие инфраструктуры счастливы одинаково, каждая плохая инфраструктура несчастлива по-своему :)grossws
30.06.2015 23:32+1Спасибо, в rfc загляну. Благо, после некоторого привыкания, они обычно читаются легко.

vba
30.06.2015 09:43+2Задержка при общении через REST API.
Здесь позвольте заметить, задержка имеется не из за самого REST а из за того подхода с которым вы используете стэк HTTP.

InteractiveTechnology
30.06.2015 12:45+1Почитайте руководство перед тем как писать API
doniv Автор
30.06.2015 12:58-1Спасибо, я прочитал.
Подскажите, пожалуйста, допустимо ли в моем случае будет применить DELETE для проверки совпадения кода (при условии, что при успехе запись будет удалена)? Ведь с одной стороны это действие, которое действительно совершается, с другой получается, что роут становится не читабельным, то есть по его названию нельзя определить его назначение.InteractiveTechnology
30.06.2015 13:15+1нет, так называемый verb это действительно относится к действию, но в вашем случаи действие — проверка, а удаление это результат.
f0rk
30.06.2015 15:54+3Я думаю, что для этой задачи вообще неуместно применять REST. REST хорошо подходит для работы с коллекциями, элементы которых реализуют CRUD интерфейс, и предполагает stateless взаимодействие, а тут состояние размазано по всем участникам процесса, клиент хранит свою сессию авторизации, какие-то действия на бэкенде тригерят посылку sms, sms-сервис что-то делает и помнит при этом, что через 2 минуты надо произвести еще какие-то действия. В общем, сама задача не укладывается в концепцию REST.
Я бы делал какой-то такой интерфейс
создание кода:
req: POST /api/session
res: 200 {session_id}
проверка:
req: GET /api/{session_id}/{code}
res: 200 (успех)
либо
res: 403 (неуспех)
имхо, тут даже json излишенdoniv Автор
30.06.2015 20:02-4Все таки на практике тип ошибки оказался важен.
Скажите, а насколько передавать данные в методе GET безопасно?f0rk
30.06.2015 20:30+2> Все таки на практике тип ошибки оказался важен.
Я вижу следующие возможные ошибки при проверке кода:
200 — код подошел
400 — что-то не так с запросом
401 — не получилось аутентифицировать клиента по его Api-Key
403 — сессия на месте, но код не подходит
404 — сессии нет, либо никогда и не было, либо уже просрочилась
500 — все плохо, все сломалось
Вроде бы те кейсы которые мне пришли в голову покрываются стандартными кодами.
> Скажите, а насколько передавать данные в методе GET безопасно?
Ровно настолько же как и другими методами. Если сервис доступен извне и возможна mitm атака, то нужно прикручивать https.doniv Автор
01.07.2015 00:05-1Еще такой затык появился: иногда нужно отдавать больше одного сообщения об ошибке, а также при появлении новых ошибок трудно вместить их в ответы статусами. Вы настоятельно рекомендуете ограничиться только статусами? Поясните, пожалуйста, для меня этот момент.
Кстати, идентификатор сессии задается извне, это связано с решением основного сервиса. Поэтому в первом случае можно ничего кроме статуса не возвращать.f0rk
01.07.2015 11:43+2> иногда нужно отдавать больше одного сообщения об ошибке
Приведите пожалуйста пример. Обычно ошибки отдавать списком приходится при валидации данных, в данном случае мне что-то ничего в голову не приходит.
> а также при появлении новых ошибок трудно вместить их в ответы статусами. Вы настоятельно рекомендуете ограничиться только статусами? Поясните, пожалуйста, для меня этот момент.
Мы же говорим о микросервисах? Это какая-то очень простая, маленькая штука которая делает что-то одно хорошо? Если сервис требует развесистого API, то конечно придется смотреть в направлении каких-то стандартов расширяющих возможности HTTP, но если можно обойтись, забить на парсинг тела запроса, не гонять лишних данных по сети и не жечь уголь в котлах дата-центров, то лучше так и сделать.
> Кстати, идентификатор сессии задается извне, это связано с решением основного сервиса.
Под сессией я понимал некий идентификатор связанный именно с процессом работы с кодом, то есть создание, отправка, хранение и удаление. Без привязки к внешним факторам типа авторизации пользователя и т.п… В такой ситуации задание сессии извне не выглядит правильным архитектурным решением, получается что сервис не самодостаточен и без помощи извне не знает как выполнять свою функцию.doniv Автор
01.07.2015 11:52-1По первому и второму пункту уже проработал варианты и большой набор ответов действительно оказался неправильным решением.
> Под сессией я понимал некий идентификатор связанный именно с процессом работ…
Тут есть тонкость, что авторизуются именно процессы внешнего приложения, поэтому оно и инициирует идентификатор сессии. Например для авторизации привязки банковской карты session_id: createcard32 (action + model + id). В этом есть плюс, так как внешнему приложению не нужно хранить новую информацию о номере сессии, которую стоит проверить.
Однако, вы правы в том, что сервис не самодостаточен, это еще стоит продумать.
doniv Автор
01.07.2015 11:31-2Отредактировал публикацию. Решил использовать первый вариант с парой 200/403. А сообщения уже записывать в лог, так как они нужны больше для мониторинга работы сервиса. Спасибо за ваши советы.
smileonl
Что вы под этим имеете ввиду?
Invision70
балансировщик по всей видимости
doniv Автор
Есть основное приложение и два микросервиса по генерации пинкодов. Если главный микросервис не пингуется, то пропускаем все процессы через вспомогательный.
smileonl
Ок, пара вопросов тогда:
1. Если в вашем варианте упадет редис, как нам поможет тот факт что у нас 2 микросервиса?
2. Если у нас запущено 2 микросервиса, зачем ждать пока отвалиться один а не раскидывать запросы по 2-м сразу (зачем ему простаивать)?
3. Если предположить что во фронтенде стоит loadbalancer и один сервис «отваливается» из-за нагрузки, то не вижу причин не отвалиться второму каскадно.
BupycNet
Вы не поняли. Можно услугу брать у нескольких провайдеров как бы. Один не работает — используете другой.
smileonl
О провайдерах в статье не слова, я поэтому и интересуюсь как бы что нам этот самый запасной сервис дает )
Да и в комментарии автора выше речь идет именно о пинге микросервиса а не провайдера услуги по рассылке смс.
Так что я думаю все верно понял.
doniv Автор
Есть всегда шанс, что что-то сломается. Нужно просто стараться минимизировать риски. БД-репликации, сервисы — рэббитМК и т.д.
В контексте публикации: в случае, если краш происходит в монолите, то чаще всего падает все приложение. В миросервисном варианте есть множество вариантов «спастись». Каким образом вы будете работать по этим рискам еще один вопрос.
smileonl
Так вот я и спрашиваю как тот факт что у вас 2 одинаковых микросервиса — при этом один обрабатывает запросы а второй просто висит и ждет, минимизирует наши риски?
doniv Автор
Да, потому что если сервер с одним сервисом по какой-то причине уйдет в офф, то второй сервис это риск закроет. Я не говорю, что второй сервис должен просто сидеть и ждать, я говорю о том, что он снижает риск.
smileonl
Ок, причина того что первый сервис ушел в офф — упал редис, как второй такой же микросервис закроет этот риск.
doniv Автор
smileonl
Вы не ответили как второй микросервис закрывает риск :)
Мы сейчас не говорим о репликации редиса и вариантах размещения приложения.
Выше вы сказали о том что второй микросервис при падении перового закрывает риск, я спросил про то каким образом вы себе это представляете при падении редиса, вы мне рассказываете про репликацию.
Так при репликации именно она снимает риск а не второй микросервис.
doniv Автор
Риск: отказ сервера.
Защита: второй сервер с аналогичным микросервисом.
Процесс: перенаправление потока на рабочий микросервис.
Я не писал в основной статье, что такой подход снижает риск при падении редис? Вы спросили, как с таким риском работать, я дал свою рекомендацию.
smileonl
А в чем тут разница с тем что у нас находится на этом сервере, набор микросервисов или обычное полнофункциональное приложение?
doniv Автор
Хотелось бы не верить в то, что вы занимаетесь троллингом. Возможно суть в том, что вы стараетесь не минимизировать риски, а полностью их избежать — чего в принципе добиться невозможно.
Три сервера: основное приложение, +2 микросервиса.
Данным комментарием или вашим ответом предлагаю всем участникам закрыть эту ветку.
smileonl
Троллингом не в коем случае. Я вроде по существу пишу, в любом случае не принимайте на свой счет, мы здесь обсуждаем сугубо техническую сторону решения.
Я надеюсь вы тут пошутили :) Вы предлагаете 3 виртуалки, докера-контейнера, поддерживать, деплоить только на этапе регистрации нового пользователя?
difiso
второй сервис может быть завязан на другой инстанс редиса или вообще другой тип хранилища.
smileonl
Ближе к телу, но тогда есть вероятность возникновения ситуации когда пользователь сформировал смс посредством перовго инстанса а проверить уже пытается по средствам второго.
Естественно это можно решить посредством реплики(в случае инстансов одинаковых СХД) в случае разных — непонятна правильность такого решения.
+ напоминаю мы решали проблемму отправки смсок при регистрации :)
doniv Автор
С кем вы ее решали? Может быть стоит вернуться к тексту публикации?
smileonl
«мы» — я использовал в контексте вашей публикации )
difiso
когда у вас что-то падает на продакшене, то вопрос эстетики в выборе провайдера проверки кодов вас должен волновать меньше всего.
Ещё вы забыли, наверное, но по условию, время жизни кода — 2 минуты.
smileonl
Вы это мне написали? Я провайдеров кодов не упоминал в этом сообщении.
Про 2 минуты не забыл, и привел пример где такой вариант при выборе разных СХД — сомнителен.
BupycNet
Провайдер микросервиса скорее я имел в виду. Вы можете подключить 2 провайдера проверки пин-кодов и даже если один упадет — у вас будет все работать.
smileonl
Провайдер микросервиса — что вы под этим имеете ввиду?
difiso
тут имеется в виду скорее всего, что можно коды посылать через sms или через email (например), и в случае падения шлюза sms все автоматом переключается на почту.
smileonl
Это решение в определенной доле мне нравится, правда всеравно мне непонятно зачем тут 2 микросервиса.
В общем контексте микросервис (если мы отталкиваемся от SOA) выполняет одну задачу отправка кода подтверждения, я не уверен что в зависимости от типа подтверждения верно плодить отдельные микросервисы.
doniv Автор
В данном случае задача сервиса — аутентификация процесса, а не отправка кода. Пожалуйста, ознакомьтесь с публикацией.
smileonl
Я ознакомился и на основе вашей публикаци и задаю вопросы.
Мы говорим о микросервисах. У вашего микросервиса какая задача? Отправка кода на этапе регистрации не больше не меньше.
Или я не прав?
doniv Автор
Я написал задачу микросервиса в комментарии выше и в описании задачи. Она не соответсвует вашей интерпретации. В следующий раз я постараюсь выражаться как можно менее двусмысленно.
smileonl
Ок, а почему она не соответсвует моей интерпритации?
В примере выше было предложено 2микросервиса для одного и того же процесса просто с разными провайдерами отправки сообщений.
Я написал что в контексте микросервисов это не самое верное решение иначем можно было бы создавать по одному микросервису для каждого типа загружаемых фотографий (jpg,png и т.п.), надеюсь понятно донес мысль.