
Подопытное приложение
Клиент просматривает список доступных квартир и бронирует их, также он может размещать на сервисе свои квартиры.
При классическом подходе для построения чаще всего выбирается фреймворк и внутри него реализуются компоненты. В случае с микросервисами для каждого компонента строится отдельное приложение и подбирается свой набор инструментов. Компоненты чаще всего взаимодействуют через REST API.
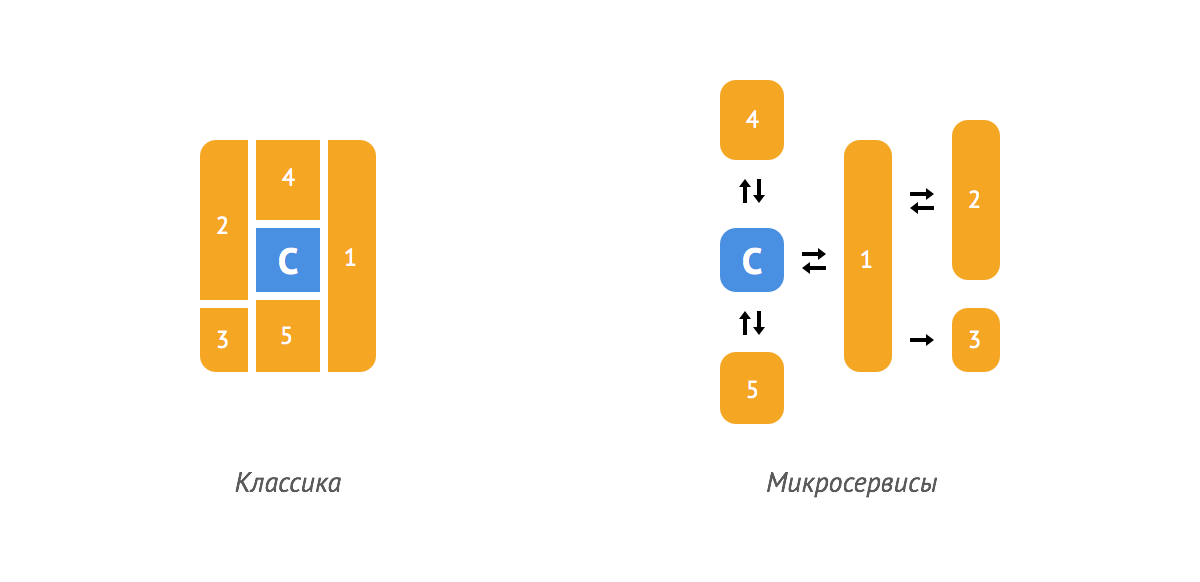
Компоненты: C — данные по квартирам (ядро), 1 — бронирование, 2 — оплата, 3 — логирование броней, 4 — размещение квартир, 5 — администрирование контента.
Обратите внимание, что перед созданием микросервисного приложения придется как следует продумать бизнес-логику и разбить приложение на самодостаточные компоненты. А теперь поговорим о том, почему микросервисы это круто.
Каждой задаче свой инструмент
Просто используйте молоток, чтобы забивать гвозди. Это применимо и в разработке ИТ-продуктов.

Для примера рассмотрим третий компонент нашего приложения — логирование. В самом базовом понимании нам нужно просто записывать текст в разные файлы.
Получается, что нам не нужен сложный фреймворк и база данных. Для реализации достаточно будет простенького модуля записи в файлы, рест-апи, и совсем немного человеко/часов на разработку и поддержку.
Незаменимых нет
На рынке ежедневно появляются десятки SaaS-решений, решающих самые различные задачи. И если мы понимаем, что легче воспользоваться таким решением, чем заниматься обслуживанием своего, то мы можем просто убрать один свой микросервис и заменить его SaaS-сервисом. При этом изменить нужно будет только взаимодействие с API.

Здесь наиболее подходящим примером будет сервис оплаты (второй компонент). Однако тут уместнее говорить о переход от SaaS-решения к своему. Например, чтобы снизить процент комиссии.
Каждому свое
В рамках одного проекта вам придется заниматься логикой взаимодействия для разных типов пользователей. Обслуживающий персонал вашего проекта (например: администраторы и модераторы) не исключение (модули 4 и 5).

Однако стоит учитывать, что потребности у этих групп разные и для каждой из них разрабатывается свой интерфейс. Будет отлично, если логика отдельного интерфейса будет соответствовать логике приложения. Это позволит работать над задачей на новом качественном уровне.
Вы маленькие, даже когда вы большие
Когда 20+ человек работают над кодом одного проекта, даже с очень хорошей архитектурой, это вызывает проблемы. Багов становится гораздо больше, тестирование превращается в пытку и т.д. В итоге продукту очень трудно развиваться и практически невозможно сделать качественный скачек через обновления.

Выделение каждого значимого компонента в отдельный микросервис позволяет не только улучшить качество разработки, но и сократить количество разработчиков в рамках существующих задач, а освободившиеся человека/часы потратить на новые разработки.
В итоге каждый из 6 компонентов будет обслуживаться 1-3 разработчиками. И в своей работе они не будут пересекаться с коллегами из параллельных микросервисов. Также стоит обратить внимание, что с микросервисами удобно будет работать в рамках версионности, которая легко реализуется в классическом API.
Итоги
Возможно это кажется вам сейчас избыточным и сложным, как будет казаться в случае любого вмешательство в вашу привычную экосистему разработки. Однако, микросервисную архитектуру обязательно стоит попробовать, хотя бы один раз, бесплатно.
А еще базовые функции каждого нового продукта можно будет собрать из уже готовых микросервисов. И это просто великолепно!

Для углубленного изучения концепции рекомендую прочитать вот эту публикацию: habrahabr.ru/post/249183.
Подолжение
Проектирование микросервиса
Комментарии (39)

artifex
26.06.2015 18:07+1Недавно рассказывал и об этом тоже на ITWeekend в Киеве. Так как по теме, оставлю слайды speakerdeck.com/semirook/api-centric-web-development-with-tornado-or-the-great-refactoring-story

ZurgInq
26.06.2015 20:36+1В последнее время всё больше плююсь от «микросервисной архитектуры» (который «частный случай soa»). Актуальные вопросы:
- Как или с помощью чего решена проблема логирования сервисов?
- Как происходит деплой?
- Версионирование компонентов. В процессе разработки может потеряться совместимость АПИ между компонентами, отслеживать какие ревизии одного компонента совместимы или не совместимы с другими сомнительное удовольствие.

doniv Автор
26.06.2015 21:01Вы на практике используете эту архитектуру? Поделитесь, пожалуйста, опытом.
- В чем заключается проблема?
- Зависит от конкретного случая. Один из простых способов с минимумом администрирования — хероку.
- Делать хорошее апи: api/v1, api/v2. Почему должна потеряться совместимость?
ZurgInq
27.06.2015 09:33+2На практике. Сразу замечу, что абсолютно все возникшие проблемы решаемы и решения известны, но на это надо потратить определённое время и усилия, особенно если не позаботиться об этом заранее.
Вначале всё начиналось именно как микросервисы, сейчас имеет тенденцию к укрупнению и ближе к стандартному SOA. Всё было хорошо, пока этих микросервисов было штук 5. Когда их количество приблизилось к десятку, оказалось, что мы объективно не справились с архитектурой. Большинство сервисов стало зависеть друг от друг друга прямо или косвенно. Например, сервис «А» может зависеть от «Б» и «В», а сервис «В» в свою очередь от «Г». Нетрудно заметить, что в этом случае, если отвалиться «Г», то вся система рискует сложиться по принципу домино. А если сбой не критичный и не проявляется сразу, то имеем фан с поиском и локализацией бага. Вот тут и всплывает, что традиционный подход, когда каждое приложение пишет в свой файл (или отдельное хранилище) тут абсолютно не подходит.
Теперь про деплой и версионирование. Сейчас деплой у нас происходит вручную на выделенный сервер. Скорей всего в итоге придём к докеру с Continuous Integration. Апи по версиям api/v1, api/v2 — хорошо для публичных АПИ. Для активно развивающихся сервисов это рискует перерасти в мешанину из устаревшего и уже не используемого кода. Сейчас стараемся сохранять обратную совместимость между компонентами без изменения версии АПИ. Но при таком подходе у нас возникла ситуация, когда надо следить в каком порядке обновлять отдельные компоненты. Например в компоненты «А» и «Б» в отдельное апи добавили одно поле, при этом «А» — посылает запросы в «Б». Если теперь вначале обновить «А», то «Б» будет сильно ругаться на неизвестное поле. Поэтому вначале обновляем «Б», а потом «А» (ситуация сильно осложняется, когда зависимостей больше). Про возможность оперативного откатывания отдельного компонента к какой либо старой версии речь даже не идёт (но и необходимости к слову не было).
В целом сейчас поддержка винегрета из отдельных сервисов (при команде из 2х-3х человек) абсолютно не проще, чем традиционный монолитный подход. А если заранее, перед внедрением микросервисов не озаботиться об необходимой инфраструктуре, то всё может сложиться очень печально.doniv Автор
27.06.2015 12:06Желательно, на мой взгляд, не делать паутину из микросервисов. В данной схеме каждый микросервис решает задачу своего родителя.
В принципе, ясно откуда появилось большинство замечаний и они вполне оправданы. В следующей статье я постараюсь рассказать как минимизировал негативные стороны. Все таки эта статья называется "Плюсы микросервисной архитектуры" :)
dezconnect
28.06.2015 00:30Очень резко может статься что появятся подзадачи между микросервисами. И да отдельный вопрос, когда надо по эвенту из сервиса А сделать что-то в сервисе бе, начинаются свистопляски с колбеками.

yamalight
27.06.2015 01:50я тут слегка вклинюсь со своими пятью рублями:
- Есть довольно много решений. У нас, например, лучше всего получилось работать с logstash
- Опять, довольно много всего. У нас лучше всего пошел Docker + Bamboo. Такая связка работает для всего вообще — от java backend'ов до фронтов, компилируемых с помощью node.js. Ну и да, без CI/CD тут никуда, руками деплоить можно рехнуться
- Это вообще отдельная тема, которая очень сильно зависит от используемого канала коммуникаций. Некоторые советуют стараться вообще избегать breaking changes и не применять versioning пока это возможно
ZurgInq
27.06.2015 09:39Спасибо. Примерно к этому сейчас и идём. И как показала практика, обо всём этом лучше задумываться до внедрения микросервисов.
yamalight
27.06.2015 11:57Ну, задумываться вообще лучше до того, как что-то делаешь :)
Но с микросервисами это действительно очень важно, если изначально все продумать, то потом проблем заметно меньше


mikhanoid
27.06.2015 10:18+3Микроядра наносят ответный удар? Видимо, старею, раз начинаю видеть рекрусию в технологиях.

HaruAtari
27.06.2015 12:02+4Сам я пока приверженец монолитных больших приложений, просто разбитых внутри на модули. И в идее микросервисов меня смущает несколько моментов. Не могли бы вы просветить меня в паре вопросов?
1. При дроблении приложения на много маленьких возрастает дублирование кода. Есть код, который должен быть в каждом проиложении (те же модели ORM) и описывать их придется везде отдельно.
2. Усложняется деплой. При изменении схемы бд, мне скорее всего придется обновить не одно приложение, а все пять. Это, конечно, автоматизируется. Но сам факт.
3. Накладные расходы на общение сервисов между собой. Если взять из примера сервисы, общающиеся между собой через rest. Получается вместо прямого вызова нужного кода, мне надо будет делать http запросы и терпеть сетевые задержки.
Объясните, пожалуйста, как решаются эти проблемы?doniv Автор
27.06.2015 12:11+2Основной посыл по всем вопросам: микросервисы это не панацея от всех проблем и не сэкономят вам время, если выносить каждую функцию в отдельный сервис сервис. Я потом напишу статью, опираясь на реальный пример выноса функционала в микросервис. Надеюсь, что это снимет большинство вопросов.

trix
27.06.2015 15:38>1. При дроблении приложения на много маленьких возрастает дублирование кода
выносим в либу
>3. Накладные расходы на общение сервисов между собой.
если это критично, не надо разделять, но в большинстве случаев это пренебрежительно малоdezconnect
28.06.2015 00:27Пренебрежительно мало может резко стать непренебрежительно большим при очередном Pivot проекта.
trix
28.06.2015 01:05а может и не стать. такие вопросы лучше решать по мере поступления, выбор той или иной архитектуры — всегда выбор между плюсами и минусами

leninlin
29.06.2015 11:57> 1. При дроблении приложения на много маленьких возрастает дублирование кода. Есть код, который должен быть в каждом проиложении (те же модели ORM) и описывать их придется везде отдельно.
Как уже было сказано выделяется в подключаемые модули и либы. Это даже становится плюсом, т.к. упрощается переиспользование кода не только в рамках текущего проекта…
> 2. Усложняется деплой. При изменении схемы бд, мне скорее всего придется обновить не одно приложение, а все пять. Это, конечно, автоматизируется. Но сам факт.
Если при изменении схемы бд приходится править все приложения, то это скорее недопонимание микросервисной архитектуры. Разделение на микросервисы это просто новая ступенька модульности и инкапсуляции.
Т.е. разделение происходит по функциональностям с соответствующим разделением ответственности. В итоге получаем что у каждого сервиса своя бд наиболее подходящая под его тип данных. Или бд общая но за определенные даные отвечает только конкретный сервис.
В таком варианте изменения схемы затронут только те сервисы чьи схемы были изменены.
> 3. Накладные расходы на общение сервисов между собой. Если взять из примера сервисы, общающиеся между собой через rest. Получается вместо прямого вызова нужного кода, мне надо будет делать http запросы и терпеть сетевые задержки.
Это один из наиболее ощутимых минусов который мы ощутили на своем проект. Но мы его решили разработкой своей серверной и клиентской либы с прямым сокетным соединением.

MadMac
29.06.2015 14:53+11. Знать о какой-то конкретной модели ORM должен только один микросервис (назовём его, например PersistenceManager). Если при изменении кода в одном микросервисе вам регулярно приходиться менять код в другом, то будет правильно объединить оба микросервиса в один.
2. Налицо сильное связывание в IT-архитектуре. Это не микросервисный подход. Если какому либо микросервису нужно пообщаться БД, то он должен делать это опосредованно с помощью PersistenceManager, который по своему усмотрению решает как и с какой базой работать (см. п 1).
3. HTTP позволяет легко, стандартными практиками организовать балансировку нагрузки и отказоусточивость микросервисов, а еще он работает через прокси. Можете использовать ZeroMQ если все-таки решите, что HTTP недостаточно быстр.
p.s.
Рекомендую ознакомиться с классическим трудом по интеграции приложений www.enterpriseintegrationpatterns.com
ksn
30.06.2015 08:331. Знать о какой-то конкретной модели ORM должен только один микросервис (назовём его, например PersistenceManager). Если при изменении кода в одном микросервисе вам регулярно приходиться менять код в другом, то будет правильно объединить оба микросервиса в один.
Расскажите, пожалуйста, подробнее про это. Вы предлагаете сделать один микросервис для всего приложения, который будет заниматься persistence'ом?MadMac
30.06.2015 10:04+1Знать о какой-то конкретной модели ORM
Иначе говоря, объекты одного класса не должны персиститься более чем одним сервисом/реализацией.
Сервисов, занимающихся ORM может быть сколь угодно много.
Polyglot Persistence опять же никто не отменял.ksn
30.06.2015 11:42Допустим у нас есть микросервис, который отвечает за менеджмент пользователей и сервис, который отвечает за каталог товаров. Обычный CRUD, ничего сверхестественного.
По Вашей логике, надо сделать ещё сервисы, которые будут отвечать за работу с БД, на каждый микросервис? Итого у нас получится такой список сервисов:
- Пользователи
- ORM Пользователи
- Каталог
- ORM Каталог
Правильно ли я Вас понял?MadMac
30.06.2015 13:01+2Я говорил о том, что не стоит использовать разные сервисы для управления ORM одного типа объектов. Это высказывание не запрещает использование одного микросервиса для нескольких ORM.
Например такой кейс — регистрация пользователя в интернет-банке:
— можно зарегистрироваться в офисе;
— можно зарегистрироваться через интернет;
В обоих случаях один и тот же сервис должен выполнить запись о пользователе в какую-то базу (LDAP каталог, SQL, NoSQL, ?). Хотя и получит запрос из разных источников.
Если разбирать Ваш пример, то я бы сгруппировал сервисы попарно:
- Пользователи (логика) + ORM Пользователи
- Каталог (логика) + ORM Каталог
В этом есть смысл если пользователи лежат в LDAP, а товары, например в MongoDB.
Но я не знаю всех деталей вашего проекта и по этому строю свои предположения со многими допущениями.

mt_
28.06.2015 14:39+1Немного прокомментирую не по теме, а по оформлению. Вот эта фразу: «Незаменимых нет» нужно иллюстрировать не той картинкой, что у вас, а этими:


В России это выражение известно как фраза И. В. Сталина, хотя в таком виде нигде в его речах или сочинениях она не встречается… Имея в виду некоторых высших партийных и советских чиновников, он сказал: «Эти зазнавшиеся вельможи думают, что они незаменимы и что они могут безнаказанно нарушать решения руководящих органов. Их надо без колебаний снимать с руководящих постов, невзирая на их заслуги в прошлом».
leninlin
29.06.2015 11:45Очень много сказано о плюсах, но минусы же тоже имеются. Почему о них ни слова?
Можете рассказать на какие грабли вы наткнулись и как решали?doniv Автор
29.06.2015 12:40В третьей публикации. Будет еще вторая по микросервисам (практическая), тоже в положительном ключе.
leninlin
29.06.2015 13:09Отлично! Тогда с нетерпением жду продолжения. Если надо будет материала подкинуть, обращайтесь. Могу еще своего опыта добавить. У нас проект специфичный: hiload, bigdata и все такое…
doniv Автор
29.06.2015 13:45Вот: habrahabr.ru/post/261267 :)
Если у вас найдется время, то расскажите о проекте в личном сообщении.
Hellsy22
Я люблю писать разнообразные логи в текстовые файлы. Это удобно. Это быстро. Их легко просмотреть или распарсить. Но это ненадежно. Можно свалить в текстовые файлы кучу отладочной информации, потеря которой некритична. Но мне представляется глубоко ошибочной идея писать туда информацию о бронировании и оплате. Если несколько процессов на одной машине пишут в один файл, то придется заморачиваться флоком. Если же пишут несколько процессов с разных машин, то сложности плавно перерастают в ранг проблемы. Можно, конечно, писать через syslog-ng, который умеет собирать логи удаленно, но тогда уж проще сразу взять СУБД и не мучиться.
Вот с этого момента поподробнее, пожалуйста. Вы предлагаете написать свою платежную систему? Или отказаться от услуг платежного агрегатора и своими силами заключить множество договоров и подключить множество платежных систем у каждой из которых свой API, поддерживать обновления и разбираться с кривыми транзакциями? Для какого-нибудь гиганта с многомиллионным оборотом — это, конечно, разумный ход, но как это сочетается с примитивизмом, описанным в первой части статьи?
Двенадцать разработчиков на постоянной основе для одного сервиса аренды недвижимости?
rinat_crone
Соль микросервисов в том, что это не обязательно должны быть разные люди. У нас при похожей схеме всего 5 разработчиков.
P.S. А логи, кстати, очень удобно хранить на внешнем сервисе, например, Logentries.
Hellsy22
Можно их хоть в Google Docs хранить и обрабатывать, но меня сам подход удивляет. Я не понимаю, в чем профит экономии на наличии СУБД, при штате из двенадцати (или из пяти) разработчиков. Да и с точки зрения разработки экономия не очевидна.
doniv Автор
Минусанули вас, мне кажется, абсолютно незаслуженно. Так как тут просто проблема в восприятии: экономить важно, еще важнее больше зарабатывать. Чтобы зарабатывать нужно быть на уровне рынка.
СУБД тут не причем, важно не стать франкенштейном.
BupycNet
Используя эту архитектуру можно почти все модули взять из сторонних решений. То есть вам придется запилить всего 2-3 модуля, а не все 5.
Даже при желании можно взять несколько сторонних сервисов и объединить в один проект, по сути так и работают различные агрегаторы. Используют API сторонних проектов как микросервисы и работают с ним, чтобы предоставить единый инструмент.
doniv Автор