

История вопроса
Uber перешел с MySQL на Postgres в 2013 году и причины, которые они перечисляют, были во-первых: PostGIS — это геоинформационное расширение для PostgreSQL и хайп. То есть, у PostgreSQL есть некий ореол серьезный, солидная СУБД, совершенный, без недостатков. По крайней мере, если сравнивать с MySQL. Они мало что знали о PostgreSQL, но повелись на весь этот хайп и перешли, а через 3 года пришлось переезжать обратно. И основные причины, если просуммировать их доклад — это плохие эксплуатационные характеристики при эксплуатации в production.
Понятно, что это был достаточно большой репутационный удар для PostgreSQL сообщества. Было очень много обсуждений на самых разных площадках, в том числе и в списках рассылки. Я прочитал все эти комментарии и постараюсь рассмотреть какие-то наиболее подробные, наиболее обстоятельные ответы.
Вот наши сегодняшние конкурсанты. Во-первых, это Robert Haas. Роберт Хаас — это один из двух ключевых разработчиков PostgreSQL. Он дал наиболее взвешенный, сбалансированный ответ. Он ни в чем не обвиняет Uber, наоборот, говорит, что, спасибо, молодцы, что рассказали про проблемы, нам есть над чем поработать, мы много уже чего сделали для PostgreSQL, но есть еще достаточно большое пространство для улучшений. Второй ответ от Christophe Pettus — это CEO какой-то компании, которая занимается консалтингом по PostgreSQL. Вот то, что я увидел в этом докладе, меня потрясло до глубины души, потому что такое ощущение, что человек даже не пытался быть объективным. Изначально ставил перед собой задачу выставить Uber дураками, а PostgreSQL белым и пушистым. Все выворачивается наизнанку и я спрашивал мнение инженеров Uber, что они думают по поводу этого доклада. Они сказали, что это какая-то ерунда. Мы совсем не это говорили. Это прямая противоположность ответу Роберта Хааса.
Так же есть Simon Riggs. Это CTO известной компании 2ndQuadrant, которая тоже делает и консалтинг, и много разрабатывают в самом PostgreSQL. Это что-то где-то между, посередине. На некоторые вопросы Саймон отвечает подробно, а на некоторые не дает никакого ответа и прячет некоторые вещи. И четвертый доклад Александра Короткова, директора по разработке российской компании PostgreSQL professional. Ожидаемый доклад, подробный и обстоятельный, но мне кажется, некоторые вещи Александр тоже заметает под ковер.
И моя минутка славы. Год назад, на прошлогоднем DevConf я делал тоже доклад про проблемы Postgres. И этот доклад был за месяц до того, как Uber опубликовал свой. Причем я рассматривал PostgreSQL исключительно с архитектурной точки зрения, не имея никакого реального опыта промышленной эксплуатации PostgreSQL, но большинство проблем, которые описывает Uber уже на основе реальной эксплуатации, я в смог определить правильно. Единственная проблема Uber, которую я вообще обошел вниманием в своем докладе — проблема с MVCC на репликах. Я видел, что там есть некоторые проблемы, что-то почитал на эту тему, но решил, что это не так важно в промышленном применении и решил все это опустить. Как выяснилось, Uber показывает, что для них тоже эта проблема была важной.
Здесь будет много картинок. Чтобы объяснить проблему Uber нужно немножко поговорить о различии в MVCC, реализации в MVCC и различии в организации данных между MySQL, конкретно InnoDB и PostgreSQL.
Организация данных

В InnoDB используют кластеризованный индекс, это значит, что пользовательские данные хранятся вместе с индексными значениями для какого-то выбранного одного индекса. В качестве такого индекса обычно выступает первичный ключ “PRIMARY KEY”. Вторичные индексы используют указатели на записи, но используют не просто какое-то смещение, они используют первичный ключ для того, чтобы указывать на записи.
В PostgreSQL другая организация данных на диске. Сами пользовательские данные хранятся отдельно от индекса в объекте, который называется “heap” или “куча”, а все индексы и первичные, и вторичные используют указатели на данные в виде номера страницы, грубо говоря, и смещения на этой странице. То есть, они используют некий физический указатель.
По сути, это значит, что все индексы в PostgreSQL вторичные. Первичный индекс это просто некий алиас для вторичного. Организационно он устроен точно так же, нет никакой разницы.
Если опуститься на уровень ниже, я здесь использую упрощенный пример доклада Uber, посмотреть как данные хранятся в страницах или в блоках. Вот допустим, у нас есть таблица с именами и фамилиями известных математиков, так же год их рождения по этой колонке с годом рождения построен вторичный индекс и есть первичный ключ по некоторому ID, просто число. Вот так это примерно выглядит в InnoDB, схематично, вот так это выглядит в PostgreSQL.

Что происходит при неиндексном обновлении? То есть, мы выполняем update, не затрагивая никакие колонки, по которым есть какие-то индексы, неиндексируемые колонки. В случае с InnoDB данные обновляются прямо в: первичном ключе, там, где они хранятся по месту, но нам нужны строчки, которые видны другим транзакциям, нужна некоторая история для строчек. Эти исторические данные, уезжают в отдельный сегмент под названием UNDO лог. Причем, уезжает не вся строка целиком, а только то, что мы поменяли. Так называемый, update вектор.
Соответственно, указатель во вторичном индексе, если он у нас есть, менять не нужно, потому что мы используем PRIMARY KEY. PRIMARY KEY не изменился, мы меняем только неиндексированные колонки, значит, ничего менять не нужно, просто старые данные переносим в UNDO лог и новые данные заносим прямо в таблицу. В PostgreSQL принципиально другой подход. если мы делаем неиндексированный update, мы вставляем другую полную копию строчки с новыми данными, но, соответственно, тогда индексы нужно тоже поменять. Указатели во всех индексах должны указывать на самую последнюю версию строчки. Соответственно, в них тоже вставляется еще одна запись, которая уже указывает не на старую версию строчки, а на новую.

Что происходит при индексированном update? Что, если мы обновляем какую-то индексированную колонку, вот год рождения здесь. В этом случае, InnoDB опять же вносит новую запись в UNDO лог и опять же указывает только те данные, которые изменились. Опять же, вторичный индекс не меняется. Ну, точнее, там вставляется новая, поскольку мы сейчас заменили индексированную колонку, вставляется новая запись — вторичный индекс, который указывает на ту же самую строчку. В PostgreSQL происходит то же самое, что и при неиндексированном update. Мы вставляем еще одну полную копию строчки и опять же обновляем все индексы. Вставляем новые записи в каждый индекс. И в первичный, и во вторичный. Если вторичных несколько, то в каждый вторичный.

И в InnoDB, и в PostgreSQL накапливается такой мультиверсионный мусор. Старые версии строчек, которые нужно со временем удалять, когда не остается транзакций, которые теоретически могут их видеть. В случае с InnoDB за эту операцию отвечает система purge (очистка). Она проходит по UNDO логу и удаляет те записи из UNDO лога, которые больше не видны ни одной транзакции.
В случае с PostgreS за это отвечает процесс под названием “vacuum”, который сканирует данные, поскульку у нас мультиверсионный мусор хранится вперемешку с самими данными, он проходит по всем данным и решает, вот эту строчку уже можно пометить как доступную для повторного использования или нет. То же самое с индексами. Из них тоже нужно удалить старые версии строчек.
Чем плох вакуум? На мой взгляд, vacuum — это самая архаичная, самая неэффективная система PostgreSQL. На это есть много причин и не потому, что она плохо написана. Нет, написана она хорошо. Это следует из того, как PostgreS организует данные на диске.
Во-первых, это решается сканированием данных. Не сканированием собственной истории, как в случае с InnoDB в UNDO логе, а сканированием данных. Там, конечно, есть некоторые оптимизации, которые позволяют, по крайней мере, избежать всего сканирования данных, а только определенных сегментов, которые обновлялись недавно, есть некоторая битовая маска, которая отмечает, что эти данные чистые, они не обновлялись с момента последнего vacuum, туда смотреть не нужно, но все эти оптимизации работают только для того случая, когда данные в основном хаотичны. Если у вас есть какой-то большой набор часто обновляемых данных, все эти оптимизации — мертвому припарки. Все равно нужно пройти по всем недавно обновленным страницам, и определить — эту запись можно выкидывать или нет, для каждой записи.Он выполняется так же в один поток. То есть, vacuum составляет список таблиц, которые нужно обновить и медленно и печально идет по одной таблице, потом по другой и так далее.
В InnoDB purge, например, можно параллелить на произвольное число потоков. По умолчанию сейчас используются 4 потока. И кроме того, на vacuum, от того, насколько эффективно и часто работает vacuum, завязана эффективность работы самого PostgreSQL. Разные оптимизации, выполнение запросов, как HOT, мы про это еще поговорим, или index-only scans, эффективность работы репликации также завязана на то, прошелся vacuum недавно или нет. Есть у нас этот мультиверсионный мусор или нет.
Если кому нужны кровавые детали, то Алексей Лесовский делал доклад “Девять кругов ада или PostgreSQL Vacuum”. Там есть такая большая огромная диаграмма, которая показывает алгоритм работы vacuum. И об нее можно сломать мозг, если захотеть.
Теперь, собственно, к проблеме Uber. Первая проблема, которую они показывают — это write amplification. Суть в том, что даже маленькое неиндексное обновление может привести к большой записи на диск. Потому что нужно, во-первых, записать новую версию строки в heap, в кучу, обновить все новые индексы, что сама по себе дорогая операция. С вычислительной точки зрения, обновление индекса — дорогая. Хорошо, если еще это btree-индекс, а это могут быть какие-нибудь gin-индексы, которые очень медленно обновляются. Добавить новые записи, все эти страницы измененные и в самом heap, и в индексах, в итоге поедут на диск, кроме того, все это нужно записать в транзакционный журнал. Очень много записей для сравнительно маленького обновления.
Тут можно поговорить еще про оптимизацию в PostgreSQL, которая существует довольно давно, она называется “Heap-Only Tuples”, НОТ updates. Uber в докладе не упоминает, не понятно, знали они про нее или, может быть, в их случае это не работало просто. Просто они про нее ничего не говорят. Но такая оптимизация есть.

Смысл в том, что если и старая, и новая версии записи при индексном обновлении находится на одной странице, вместо того, чтобы обновлять индексы, мы со старой записи делаем ссылку на новую. Индексы продолжают указывать на старую версию. Мы можем по этой ссылке прыгнуть и получить новую версию, не трогая индексы. Вроде как бы все хорошо. Если появится еще одна строчка, мы делаем еще одну ссылку и получаем вот такую вот цепочку, которая называется ”Hot chain”. На самом деле, счастья полного нет, потому что вот это все работает до первого индексного обновления. Как только у нас приезжает первый update, который затрагивает индексы для этой страницы, нужно всю эту hot chain схлопнуть, потому что все индексы должны указывать на одну и ту же запись. Мы не можем для одного индекса изменить ссылку, а для других оставить.
Соответственно, чем больше индексов, тем меньше шансов у НОТ сработать и даже Роберт Хаас, он пишет в своем отзыве, что да, действительно есть такая проблема, и многие компании от нее страдают. Многие разработчики поэтому аккуратно относятся к созданию индексов. Теоретически индекс может быть даже и полезен был бы, но если мы его добавим, то update перестанут пользоваться вот этой оптимизацией Heap-Only Tuples. Во-вторых, очевидно, что эта оптимизация работает только в том случае, если на странице есть место. Ссылку можно поставить, только если старая и новая версия записи находятся на одной странице. Если новая версия записи переезжает на другую страницу, всё, никакой Heap-Only Tuples оптимизации.
Для этого, опять же PostgreSQL сделал некий костыль, что, пока мы будем ждать, пока vacuum дойдет, освободит нам место на странице, давайте будем делать такой мини vacuum или single gauge vacuum это называется. При каждом обращении к конкретной странице, мы будем немножко еще тоже пропылесосивать. Смотреть, какие записи можно убрать, если они не видны уже другим транзакциям. Освобождать место на странице и, соответственно, увеличивать шанс того, что НОТ оптимизация будет работать.
Это все неэффективно, опять же, если у вас есть много параллельных транзакций. Тогда шанс того, что текущие версии строчек не видны никакой выполняющей транзакции, он уменьшается. Соответственно, НОТ оптимизация перестает работать. Так же это не работает, когда есть не много параллельных, а одна длинная транзакция, которая может видеть старые версий строчек на странице. Соответственно, мы не можем их удалить, тогда запись эта начинает переезжать на следующую страницу и опять же никакой НОТ оптимизации.
Что отвечает сообщество? Роберт Хаас достаточно сбалансировано говорит: “Да, есть проблема, НОТ оптимизация — не панацея, многие компании от этого страдают, не только Uber”. И вообще, по-хорошему, я давно уже об этом говорю, нам нужно делать storage engine как в MySQL. В частности, нам нужен storage engine, основанный на undo, а не то, что у нас сейчас есть. Кристоф Петус и Саймон Ригс говорят: “Есть же НОТ оптимизация. Раз Uber про нее не упоминает, значит, они ничего не знают про нее. Значит, они дураки”. Кристоф, он человек воспитанный, когда он хочет сказать, что Uber дураки, он вставлял в презентацию смайлик, пожимающий плечами. “Что с них взять”.
Александр Коротков говорит, что есть НОТ оптимизация, есть ограничения определенные, но дальше начинает перечислять список разных экспериментальных патчей, которые в десятку предстоящую mager версию не войдут и после перечисления этих экспериментальных патчей он приходит к выводу, что на самом деле, по-хорошему, нужно делать storage engine, основанный на undo. Все остальные оптимизации — это, скорее, подпорки, костыли под неэффективную систему организации данных в PostgreSQL.
Что все отвечающие упускают? Есть такое поверье, я часто его вижу, в том числе в каких-то российских сообществах, что просто Uber был какой-то специфичный случай. На самом деле, в этом нет ничего специфического. Это обычные для OLTP операции, для интернет проектов, очереди, счетчики какие-то, метрики, когда нужно обновлять не индексируемые колонки. Я ничего не вижу в этом специфического.
Во-вторых, ни один из отвечающих не сказал, что MVCC и организация данных на диске в PostgreSQL плохо подходят для OLTP нагрузок.
Так же, никто не сформулировал простой вещи, что полного решения проблемы нет и видимо будет не скоро. Даже экспериментальные патчи, они появятся, в лучшем случае, в PostgreSQL 11 и то, они скорее — это костыли и подпорки, а не радикальное решение проблемы на корню. Также, что проблема write amplification, которую описывает Uber, это некий довольно частный случай более общей проблемы. И над более общей проблемой в MySQL работают уже давно, есть оптимизированные на запись движки TokuDB/MyRocks сейчас набирают популярность. В этом плане в PostgreSQL все еще хуже. Нет каких-то даже теоретических альтернатив даже на горизонте.
MMVC и репликация
Вторая проблема, которую отмечает Uber — это репликация и проблемы с MMVC на репликах. Допустим, у нас есть репликация, мастер -> реплика. Репликация в PostgreSQL физическая, то есть она работает на файловом уровне и все изменения в файлах, которые происходят на мастере, переносятся на реплику один в один. Фактически, мы в итоге строим побайтовую копию мастера. Проблема возникает в том случае, если реплику мы также используем, для того, чтобы крутить какие-то запросы. А на read only, там изменения вносить нельзя, но можно читать. Что делать в том случае, если у нас селект на реплике, если этому селекту нужны какие-то старые версии строчек, которые на мастере уже удалены, потому что на мастере этих селектов нет. Vacuum прошелся и удалил эти старые версии не зная о том, что на реплике или на репликах выполняются какие-то запросы, которые версии еще нужны. Здесь не так много вариантов. Можно придержать репликацию, остановить репликацию на реплике, пока этот селект завершится, но поскольку репликацию нельзя задерживать бесконечное время, есть некий таймаут по умолчанию — это max_standby_streaming_delay. 30 секунд, после которого транзакции, которые используют какие-то старые версии строчек, начинают просто отстреливаться.

Uber еще замечает, что вообще у них были длинные транзакции в основном по вине разработчика. Были транзакции, которые, например, открывалась транзакция, потом открывался e-mail или совершался какой-то блокирующий ввод/вывод. Конечно, по идее, Uber говорит, что так делать нельзя, но идеальных разработчиков не бывает, к тому же, часто они используют какие-то формы, которые скрывают общий факт. Там не так просто определить, когда транзакция начинается, когда она заканчивается. Используются высокоуровневые формы.
Такие случаи все-таки возникали и для них это было большой проблемой. Либо репликация задерживалась, либо транзакции отстреливались, с точки зрения разработчика, в непредсказуемый момент. Потому что, сами понимаете, если мы, например, ждем 30 секунд и задерживаем репликацию, а после этого отстреливаем запрос, то, к тому моменту, когда запрос будет отстрелен, репликация уже отстала на 30 секунд. Соответственно, следующая транзакция может быть отстрелена практически мгновенно, потому что эти 30 секунд, этот лимит исчерпается очень быстро. С точки зрения разработчика транзакция в какой-то случайный момент… мы только начали, еще не успели ничего сделать, а уже нас перебивают.
Ответ сообщества. Все говорят, что нужно было использовать опцию hot_standby_feedback=on, нужно было ее включить. Кристоф Петус добавляет, что Uber просто дураки.
Эта опция имеет свою цену. Есть некие негативные последствия, иначе она была бы включена просто по умолчанию. В данном случае, если возвращаясь к этой картинке, что она делает. Реплика начинает передавать на мастер информацию о том, какие версии, какие транзакции открыты, какие версии строчек еще нужны. И в этом случае, мастер фактически просто придерживает vacuum, чтобы он не удалял эти версии строчек. Здесь тоже есть много всяких проблем. Например, реплики часто используются для тестирования, чтобы разработчики поигрались не на боевой машине, а не некоторой реплике. Представляете себе, разработчик, при тестировании начал какую-то транзакцию и пошел на обед, а в это время на мастере останавливается vacuum и в итоге заканчивается место и перестает работать оптимизация и в итоге мастер может просто умереть.
Или же другой случай. Реплики часто используются для какой-то аналитики, долгоиграющих запросов. Здесь тоже проблема. Мы запускаем долгоиграющий запрос с включенной опцией hot_standby_feedback=on, vacuum на мастере тоже останавливается. И тут получается, что для некоторых каких-то длинных аналитических запросов вообще нет никакой альтернативы. Либо они просто убивают мастер с включенной опцией hot_standby_feedback=on, либо, если она выключена, то они просто будут отстреливаться и никогда не завершатся.
О чем все молчат? Как я уже сказал, опция, которую все советуют, она задерживает vacuum на мастере и в PostgreSQL в свое время собирались сделать ее включенной по умолчанию, но предлагающим тут же объяснили, почему так делать не надо. Так просто советовать ее без всяких оговорок — это не очень честно, я бы сказал.
Ошибки у разработчиков случаются. Кристоф Петус говорит, что раз Uber не смог нанять правильных разработчиков, то они дураки. Ломается там, где тонко. Разработчики ошибаются там, где им позволяют ошибаться. Чего никто не сказал, так это то, что физическая репликация плохо подходит для масштабирования чтения. Если мы используем реплики для того, чтобы масштабировать чтение, крутить какие-то селекты, физическая репликация в PostgreSQL просто по архитектуре плохо подходит. Это был некий хак, который было легко реализовать, но у него есть свои пределы. И это опять же не специфический случай. Репликацию можно для разных целей использовать. Использовать эту репликацию для масштабирования чтения тоже достаточно типичный случай. Еще одна проблема, о которой сообщает Uber — это репликация и write amplification. Как мы уже обсудили, на мастере при каких-то определенных обновлениях тоже происходит write amplification. Слишком много данных пишется на диск, но поскольку репликация в PostgreSQL физическая, и все изменения в файлах едут на реплики, то все эти изменения, которые в файлах происходят на мастере, едут в сеть. Она достаточно избыточная, физическая репликация, по своей натуре. Возникают проблемы по скорости между разными дата центрами. Если мы реплицируемся с одного побережья на другое, то купить достаточно широкий канал, который бы вместил в себя весь этот поток репликации, который идет с мастера — это проблематично да и не всегда даже возможно.
Что отвечает сообщество на это. Роберт Хаас говорит, что можно было попробовать компрессию WAL, который передается в репликации по сети или SSL, там тоже можно включить на уровне сетевого соединения компрессию. А так же, можно было попробовать логическое решение репликации, которое в PostgreSQL доступно. Он упоминает Slony/Bucardo/Londiste. Саймон Ригс проводит лекцию о плюсах и минусах физической репликации, я бы тоже здесь все это написал, но за последнее время я так часто об этом говорил, что мне это уже несколько надоело, я полагаю, что все примерно представляют себе, чем логическая репликация отличается от физической. Так же, добавляют, что скоро будет pglogical — это встроенное решение для логической репликации в PostgreSQL, которое разрабатывает его компания.
Кристоф Петус говорит, что не нужно сравнивать логическую и физическую репликацию. Но это странно, потому что именно это делает Uber. Он сравнивает плюсы и минусы логической и физической репликации, говоря, что физическая репликация для них не очень подходит, а вот логическая репликация в MySQL, как раз, хорошо. Не понятно, почему не надо сравнивать. Он добавляет, что Slony, Bucardo сложно установить и сложно ими управлять, но это же Uber. Раз они не смогли это сделать, значит, они дураки. И, к тому же, в версии 9.4 есть pglogical. Это стороннее пока что расширение для PostgreSQL, которое организует логическую репликацию. Нужно сказать, что Uber использовал более старые версии PostgreSQL, 9.2, 9.3, для которых нет pglogical, а переехать на 9.4 они не могли. Я дальше расскажу почему.
Александр Коротков говорит, что Uber сравнивает логическую репликацию в MySQL и физическую. Совершенно верно. Именно это он и делает. В MySQL нет физической репликации и Alibaba работает над тем, чтобы добавить физическую репликацию в MySQL — это тоже верно, только Alibaba это делает уже для совершенно другого use case. Alibaba это делает для обеспечения high availability для своего облачного приложения внутри одного датацентра. Они не используют кросс-региональную репликацию, они не используют чтение с реплик. Это используется только для того, если у облачных клиентов упадет сервер, чтобы они быстро могли переключиться на реплику. Только и всего. То есть, этот use case отличается от того, что использует Uber.
Еще одна проблема Uber, о которой они говорят — это кросс-версионные обновления. Нужно перейти с одной мажорной версии на другую и желательно бы это сделать без остановки мастера. Вот в PostgreSQL с физической репликацией эта проблема не решается. Потому что, обычно, в MySQL делают как. Апгрейдят сначала реплики, или одну реплику, если она только одна, на более старшую версию, потом переключают на нее запросы… фактически делают ее новым мастером, а старый мастер апгрейдится на новую версию. Получается, downtime минимальный. Но с физической репликацией в PostgreSQL нельзя реплицировать с младшей версии на старшую и вообще версии должны быть одинаковые и на мастере и на реплике. Pglogical, опять же, был для них не вариант, потому что они использовали более старые версии и на 9,4, с которого pglogical доступна, они переехать не могли, потому что не было репликации. Рекурсия такая.
Некоторые их legacy сервисы, а в Ubere они до сих пор остались, они до сих пор работают на PostgreSQL 9.2 по этой простой причине.
Ответ сообщества. Роберт Хаас никак это не комментирует. Саймон Ригс говорит, что вообще-то есть pg_upgrade — это процедура собственного апгрейда и с опцией -k, когда используются хардлинки этот процесс занимает меньше времени, поэтому downtime все равно будет, мастер придется останавливать и все запросы тоже придется останавливать. Ну, не так уж это может быть и долго. Кроме того, Саймон Риггс говорит, что у них в компании есть коммерческое решение, которое позволяет интегрировать старые версии на новые.
Кристоф Петус говорит, что pg_upgrade — это не панацея, в частности PostGIS, геоинформационное расширение, из-за которого Uber перешли на PostgreSQL вызывают очень много проблем при апгрейде между мажорными версиями. Я не знаю, я ему здесь верю, потому что он консалтер по PostgreSQL. Он говорит, что Uber не осилили, опять же, Slony/Bucardo, pglogical, значит, они дураки. Александр Коротков показывает, как можно сделать апгрейд между мажорными версиями, используя pglogical.
Наш доклад называется: “Ответ Uber-у”, то для Uber это был не вариант. Ответ текущим пользователям, то там тоже есть свои нюансы.
О чем все молчат? Да, действительно есть всякие сторонние решения для PostgreSQL, которые организуют логическую репликацию Slony/Bucardo/Londiste, но все они trigger-based, все они основаны на триггерах, то есть, на каждую таблицу развешивается триггер, при любом обновлении мы берем эти изменения, которые внесли и записываем их в специальную реляционную журналируемую таблицу, а потом, когда они переезжают на реплики, все эти изменения из реляционной таблицы, мы их удаляем. И тут возникают типичные проблемы. Болячка PostgreSQL с Vacuum, когда данные часто вставляются и удаляются, очень много работы для vacuum, соответственно, куча всяких проблем. Не говоря про то, что само trigger-based решение, оно не очень эффективно, сами понимаете, а данные из таблиц вытаскиваются вообще какими-то внешними скриптами. Не в самой СУБД, а написанными на перле или на питоне, там по-разному, все зависит от решения и перекладываются уже на реплики.
С pglogical все очень странно. Все посоветовали, что pglogical может быть использован для апгрейдов с младшей версии на новую. Я прочитал документацию, разработчики не обещают, что такая кросс-версионная репликация будет работать. Они говорят, что может работать, но в будущих версиях что-то может разъехаться и, в общем, мы ничего не обещаем.
Низкая “обкатность” даже сейчас, в 2017 году. Это сравнительно новая технология, она, конечно, прогрессивная, потенциально использует какие-то встроенные вещи в PostgreSQL, а не какие-то там внешние решения, но я не очень понимаю, как это Uber можно было рекомендовать для использования в productions в 2015 году, когда pglogical вообще только начал разрабатываться. Но чем хорош pglogical, тем, что в отличие от основного PostgreSQL, можно пойти и посмотреть багтрекер, чтобы оценить стабильность проекта, взрослость проекта, насколько широко он используется. Честно говоря, меня это не впечатлило. На меня это не произвело впечатления какого-то стабильного проекта.

Активность очень низкая, есть некоторые баги, которые висят уже там годами. У кого-то проблемы с перфомансом, у кого-то проблема с потерей данных. Вот не производит впечатление какого-то стабильного проекта. У меня в хобби-проекте(sysbench) на гитхабе активность больше, чем в pglogical.
О чем все еще не говорят? Что у всех этих проблем, у всех этих решений, сторонних и встроенных pglogical есть проблемы с sequences, потому что на них нельзя повесить триггер и изменения не записываются в транзакционный журнал, а значит, приходится делать какие-то специальные сложные приседания, чтобы обеспечить репликацию sequences. DDL только через функции-обертки, потому что, опять же на DDL нельзя повесить триггеры и почему-то они в PostgreSQL не записываются в транзакционный журнал. У всех трех решений нет журнала как такового, то есть, нельзя взять какой-нибудь backup и накатить логические изменения из какого-то журнала как в MySQL. Можно только физический backup, но, чтобы сделать физический PITR, вам нужен физический backup. На логический back up вы его не накатите. Нет GTID, какие-то последние вещи, которые появились в репликации в MySQL. Я так и не понял, как с помощью этих решений сделать перепозиционирование. Скажем, переключить slave реплику с одного мастера на другой и понять какие транзакции уже были проиграны, а какие нет.
Наконец, нет никакого параллелизма. Единственный способ ускорить логическую репликацию — это ее распараллеливать. В MySQL проделана огромная работа в этом направлении. Все эти решения не поддерживают параллелизм вообще ни в каком виде. Его просто нет.
Что все упускают? Во-первых, есть только один правильный сценарий применения физической репликации в PostgreSQL или в MySQL, когда она где-нибудь появится или где-нибудь еще. Это High Availability внутри одного датацентра, когда у нас есть достаточно быстрый канал, и, когда не нужно читать с реплик. Это единственный правильный use case. Все остальное может работать, а может и нет, в зависимости от того, какая нагрузка и от многих других параметров.
На сегодня полной альтернативы репликации в MySQL PostgreSQL предложить не может. Рglogical странная вещь. Многие говорят, что в PostgreSQL 10 появится pglogical, встроенная логическая репликация, на самом деле мало кто в Postgres community знает, что войдет в 10 некий урезанный вариант рglogical. Я так и не нашел какого-то внятного описания, что же именно войдет, а что останется за бортом. Кроме того, что синтаксис в 10 будет использоваться несколько отличный от того, что использовало стороннее расширение рglogical. Не понятно, можно будет как-то их использовать совместно. Можно ли реплицировать рglogical со старых версий в PostgreSQL 10 или нет. Я нигде не нашел. Документация у рglogical тоже своеобразная.
Неэффективный кеш
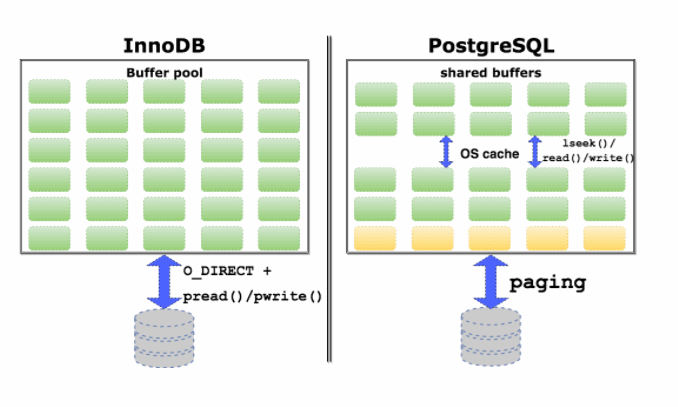
И, наконец, неэффективный кэш. В чем отличие реализации кэша в InnoDB и PostgreSQL. InnoDB использует небуферизованный ввод/вывод не полагаясь на собственный кэш операционной системы, поэтому, всю память, вся максимально доступная память на машине отводится под InnoDB кэш. InnoDB использует обыкновенные pread and pwrite системные вызовы, для того, чтобы осуществлять ввод/вывод небуферизованный. Не полагаясь на кэш операционной системы.
У PostgreSQL другая архитектура. Почему-то поддержку direct I/O небуферизованного ввода/вывода не сделали до сих пор, поэтому, PostgreSQL полагается и на свой собственный кэш и на кэш операционной системы одновременно. Кроме того, он почему-то использует не такие системные вызовы, которые позволяют сразу сместиться и прочитать что-либо и записать, а сначала отдельный системный вызов, чтобы сместиться на нужную позицию, а потом прочитать и записать. Два системных вызова на одну операцию. Тут происходит некоторое дублирование данных. Страницы памяти данных будут храниться и в собственном кэше и в кэше операционной системы.
Роберт Хаас и Саймон Ригс не отвечают на это. Кристоф Петус, что-то с ним случилось, он не называет Uber дураками здесь, согласен, что есть проблема, но не ясен эффект на практике. Александр Коротков говорит, что pread вместо lseek дает оптимизацию только 1,5 процента производительности, но это часть проблем, которые перечисляет Uber. Больше ничего не говорит.
Что все опускают? Что 1,5% были получены на одном бенчмарке на ноутбуке разработчика, который разработал этот патч. Экспериментально там было некое обсуждение в списке рассылок Postgres hackers, и патч, в итоге, застрял в обсуждениях. Роберт Хаас говорил, что этот патч нужно включить. Даже 1,5% это скорее всего на боевых системах будет больше, даже 1,5% — это уже хорошо, а Том Лэйн, другой ключевой разработчик PostgreSQL был против, говорил, что не нужно трогать стабильный код из-за каких-то 1,5%. В общем, два ключевых разработчика не нашли понимания и патч в итоге застрял. Он никуда не пошел.
Это далеко не единственная проблема в дизайне shared buffers, я в своем прошлогоднем докладе на DevConf это подробно все раскрывал. Там есть гораздо больше проблем, чем перечисляет Uber. Там есть дублирование данных, есть проблема с двойным вычислением контрольных сумм, есть проблема с “вымыванием” данных из кэша операционной системы, что InnoDB со своим кэшем может предотвратить. А в будущем, если в PostgreSQL появится компрессия и шифрование, там тоже начнутся проблемы с такой архитектурой.
Что мы видим в итоге. Uber, я разговаривал с ними, и они также делали доклады на конференциях, на Percona live. Они говорят, что: “Мы в целом довольны MySQL, мы не собираемся никуда переезжать. У нас есть старые legacy системы, которые до сих пор работают на PostgreSQL, но вся основная обработка делается в MySQL. PostGIS — это основная причина, почему мы в свое время перешли на PostgreSQL, геоинформационное расширение. Это круто, но со своими подводными камнями и кроме того, эта штука плохо масштабируется для OLTP нагрузок. Мы нашли способ, как обойтись без нее в MySQL. Да, в MySQL пока нет такой возможности”.
Я даю совет, что не верьте в этот хайп, в ореол совершенной системы, лишенной недостатков. Будьте инженерами, будьте скептиками, старайтесь делать решения на основе объективных вещей, а не на основе слухов и какой-то общей истерии. И главное — тестируйте. Перед тем, как вы собираетесь заменить СУБД в своем проекте, проведите хотя бы какие-нибудь тесты, чтобы посмотреть как на вашем конкретном случае это СУБД себя поведет. У меня на этом всё!
Вот такой вот доклад с явно выраженным стремлением показать преимущества InnoDb :) Разумеется, в скором времени мы разбавим наш хабр докладом от противоположного лагеря. Приходите 18 мая на DevConf(действуют специальные цены до 30 апреля). Алексей обещался там быть с новым докладом. Правда, теперь он будет больше про MySQL. А Иван Панченко из Postgres Professional расскажет про ту самую логическую репликацию, которую включили в PostgreSQL 10.
Комментарии (109)

mazy
18.04.2018 14:42+1Спасибо за статью.
Тоже постоянно сталкиваемся с затыками постгреса на большом количестве апдейтов.
tgz
18.04.2018 14:45> Изначально ставил перед собой задачу выставить Uber дураками, а PostgreSQL белым и пушистым
Но ведь так и есть.

KirEv
18.04.2018 15:07Они мало что знали о PostgreSQL
весело…
это точно убер? (сарказм)…
выглядит так: перестроили под то, о чем мало знали, походили по граблях, узнали больше о том как нужно было, решили «проще вернуться на то о чем знают хорошо, чем повторно перестроить на postgresql учитывая набитые шишки».Adelf Автор
18.04.2018 15:16В масштабах убера дважды за 3 года менять СУБД действительно выглядит странно :)
BTW, я это преобразовал в статью, поскольку тут подробно описаны многие низкоуровневые детали, которые интересны вне зависимости кейса с убером.

acmnu
18.04.2018 15:18При такой организации в InnoDB требуется больше логических чтений при извлечении через не праймари индекс. К слову непосредственный индекс и в Oracle используется, вроде. Т.е. здесь явно компромисная ситуация.
Вообще на мой взгляд оба варианта довольно странные в комплексе. Вот почему:
- Postgres версионный, а значит на каждый чих обновляет все индексы. Им бы как раз использовать косвенную адресацию, чтоб экономить на обновлении хоть как-то. (Разве там нет скрытой косвенной адресации через версии?)
- InnoDB не версионный, а с сегментами отката. Вот им бы прямая адресация не пила столько крови, поскольку положение строчки в куче не меняется при обновлении.
Получается идеальная комбинаци у Oracle: прямая адресация и сегменты отката.

port443
18.04.2018 22:54Вот мне показалось аналогично. Может, имеет смысл рассматривать проблемы производительности с учётом соотношения чтение/запись? У Убера, возможно, транзакций на запись значительно больше в таком соотношении?
immaculate
18.04.2018 15:21Это вроде давнишнее событие, и эксперты по PostgreSQL давно тщательно проанализировали данный доклад и сделали вывод: Uber мечется из стороны в сторону, толком не разобравшись в том, что им нужно, и как это настроить, прыгают с базы на базу, рассчитывая, что оно само магическим образом заработает так, как им хочется.
Легко найти комментарии экспертов к данному докладу, где объясняется, как Uber неправ в каждом пункте.
acmnu
18.04.2018 15:24+2Ээээ. Вы статью читали? Там собственно разбор мнений этих самых экспертов. И что-то один из главных разработчиков не так категоричен, как вы.
immaculate
18.04.2018 15:28Да, посыпаю голову пеплом, прочитал первое предложение, и подумал, что это тот самый первый доклад.
Но кстати, с того момента, как Uber перешел обратно на MySQL, PostgreSQL выпустил несколько версий, в которых исправлены некоторые из проблем, о которых говорилось в изначальном докладе Uber.
osipov_dv
18.04.2018 16:01где-то на хабре была ссылка на выступление сотрудника из танчиков (world of tanks), они аналогично мигрировали MySQL > Postgress > MySQL.

apapacy
18.04.2018 16:26В статье (первой) Uber мне было скорее интересно не то что они ушли или не ушли с MySQL/PostgreSQL а то что такая нагруженая система работала и на том и другом продукте. Сейчас зачастую призодится слышать что без NoSQL это вообще невозможно сделать. (Напр. где-то была статья от vk где в частности упоминалось что осталась ровно одна таблица на реляционной базе с названием schestnoe_slovo_posledniayja_tablitsa (или что-то вроде этого)
acmnu
18.04.2018 16:53+1Победа NoSQL это из разряда слышали акустические волны, но источник не нашли. Да, есть сферы деятельности, где NoSQL хорош. Например хранение не согласованной информации: фоточки, посты, профайлы пользователей. Все они довольно независимы друг от друга логически и могут обновляться не согласовано.
А вот например бухгалтерия, платежные или другие транзакции, и вообще все сферы, где необходимо одновременно и согласованно изменять много значений по-прежнему висят на SQL. Более того, в Big Data сейчас серьёзный откат именно в эту область, правда уже по причине тезиса, что Big Data не должны быть Bad Data.
khim
19.04.2018 01:41Сейчас зачастую призодится слышать что без NoSQL это вообще невозможно сделать.
Невозможно сделать… что? Google Adsense уехал с MySQL на свою собственную систему несколько лет назад, но на NoSQL не перешёл.
Да и есть подозрение, что 4-5 лет назад, когда они ещё на MySQL жили там нагрузка была такая, что Uber и рядом не лежал.
DenBlack
18.04.2018 16:56Ну это простая защитная реакция назвать дураками тех, кто тебя критикует. Хотя репутационный ущерб для PostgreSQL конечно есть. Но это должно их сподвигнуть усилить свои слабые места.
Miron11
18.04.2018 17:18-1«Uber еще замечает, что вообще у них были длинные транзакции в основном по вине разработчика.»
— и как это поможет исправить переход на MySQL?
Если эту фразу интерпретировать, как «Ну Uber сами дураки», то можно тушить свечи. А так… Общее ощущение что молодые ребята вкалывают, принимают волевые решения. Удачи.
Что до смены версий, разворачивать репликацию для перехода на новую версию это конечно один из подходов, но сказать чтобы это было интересно я не могу. Развертка триггеров дело вполне по плечу среднему разработчику, и сделать скрипт для перехода на обновленную версию дело не сложное. Видимо были какие — то другие приоритеты. Может им кто — то за перехода на MySQL обещал грант подкинуть на разработку робота — водителя, или помочь замять дело с недавней гибелью человека.
Постгрес как база лучше чем MySQL. Это однозначно. И кластеред индекс у неё есть. Автор лукавит. Это создаваемая по умолчанию секвенция строк. Выход на неё по бинарному древу поиска там по — моему с 7-й версии. В общем улучшение репликации пожалуй существенная вещь, но сказать, чтобы она была решающей трудно.
kalininmr
18.04.2018 18:55хм. как я понимаю у них активная работа с геоданными.
в mysql вроде бы с этим так себе.
galaxy
18.04.2018 19:45Одна проблема с этой статьей: постгрес развивается очень хорошими темпами и статья в апреле 2018 устарела (и основана на еще большем старье).
Так, pg_logical прекрасно вошел в 10 версию: www.postgresql.org/docs/10/static/logical-replication.html
C MVCC vs UNDO тоже ситуация на месте не стоит: 1, 2, 3. Опять-таки, с учетом темпов развития, глядишь уже в 12 версии появится.khim
19.04.2018 01:45+1А мы точно говорим о продукте, которому больше 20 лет?
А то разговоры о том, что «всё уже очень крута у нас, только возьмите версию, которая вышла меньше полугода назад» — это нормально для хайповой библиотечки, которая только год назад появилась.
От продукта, которому двадцать с лишним лет ожидаешь, что уж такие-то базовые вещи в нём реализованы давным-давно.Miron11
19.04.2018 06:25-1Репликация это не базовая вещь. У некоторых СУБД с мировым именем репликацию обеспечивают только пакеты от третьих производителей ПО.
blind_oracle
19.04.2018 12:41Да? Это какие-такие СУБД «с мировым именем» не имеют репликации из коробки?
Miron11
19.04.2018 15:23Разговор идет не о «сейчас/сегодня» а о «хайповой библиотечки, которая только », и как Postgres выглядит на фоне лучших производителей СУБД.
Взять эталон индустрии разработки ПО. Microsoft SQL Server — физическая репликация ( mirroring ) появилась только с Service Pack 1 SQL Server 2008, то есть в 2010-м, мульти — узловая физическая репликация с доступом для чтения резервной копии в версии 2012, ошибки, которые лишали её возможности нормально работать поправили только в SP2, выпущенного 12-го Июля 2016-го года.
Сравнивая поддержкой репликации СУБД Postgres, мне кажется критика «хайповой библиотечки, которая только » не только не обоснована, но совершенно не отражает реальность.blind_oracle
19.04.2018 16:27+1Ну, знаете ли, в том же MySQL row-based репликация появилась в версии 5.1, это 10 лет назад, а statement-based по-моему была чуть ли не с 3 версии.
А PostgreSQL до недавнего времени мучал людей всяким Slony и прочими trigger-based убожествами.Miron11
20.04.2018 17:20-110 лет или даже 20 лет назад.
После того как MySQL отдали InnoDB, коммерческий продут, а Оракл купила MySQL, примерно год — два назад MySQL выпустила новые фитчи для репликации, которые сделали её доступной. Они до сих пор глючат. Я это говорю не для того, чтобы сказать, что MySQL плох или хорош. Ваши утверждения носят характер маркетинговой рекламной кампании. Вам здесь не место. Занимайтесь этими глупостями в статьях, за которые Ваша фирма платит.blind_oracle
20.04.2018 17:35MySQL выпустила новые фитчи для репликации, которые сделали её доступной. Они до сих пор глючат
Это какие? Semi-Sync репликация? И что значит «доступной»?
Ваши утверждения носят характер маркетинговой рекламной кампании. Вам здесь не место. Занимайтесь этими глупостями в статьях, за которые Ваша фирма платит.
Ого, ничего себе, маркетологом меня еще никто не обзывал. И что же я рекламирую? MySQL? Мне наверное Oracle платит? :)
galaxy
19.04.2018 15:14А то разговоры о том, что «всё уже очень крута у нас, только возьмите версию, которая вышла меньше полугода назад» — это нормально для хайповой библиотечки, которая только год назад появилась
Да? :) Мне как раз казалось, что это универсальный ответ Mysql: возьмите 5.7, там у нас ого-го, а уж в 8… (почитайте хотя бы нашего местногоевангелистаразрушителя). Видимо, это общий тренд
Ну а вообще — смотря с чем сравнивать и что считать базовой вещью, можно же и с Ораклом (которому 40 лет). Кому суп жидкий, кому жемчуг мелкий…khim
19.04.2018 18:45Ну а вообще — смотря с чем сравнивать и что считать базовой вещью, можно же и с Ораклом (которому 40 лет).
А вот тут вы, как бы, сами указали на основную разницу: довольно естественно ожидать от продукта, которому 40 лет, большей «вылизанности», чем от продукта, которому 20. Было бы странно если бы разницы не было.
Но MySQL всего на год старше PostgreSQL, обоим проектам уже за 20, так что странно видеть, что какие-то достаточно базовые вещи, которые в MySQL были реализованы 10 лет назад в PostgreSQL появились вот-буквально-только-что.
И да, репликация-для-того-чтобы-можно-было-много-много-читать — это одна из базовых вещей для web-приложений. Потому что, блин, это нужно всем. Это в 80-90е базы данных использовались так, что клерки вбивали туда данные из всяких формочек с утра до вечера, а аналитики иногда запрашивали отчёты. С приходом интернета и, особенно, web'а тренд развернулся и количество запросов на чтение стало на порядок (а часто и на два) больше количества запросов на запись.
Если у вас нет репликации, которая это позволяет оптимизировать, то как вас вообще можно рассматривать всерьёз в этом мире? Если у вас нет возможности производить апргейд начиная с read-only реплик (с последующим переключением за минуты), то как вас можно рассаматривать как бакэнд для терабайтных баз?
То, что PostgreSQL 10 наконец-то получил эту возможность — это замечательно, но то, что её не было 20 лет — настораживает…
Kwisatz
19.04.2018 20:28так что странно видеть
А мне странно видеть как фирмы с миллиардными оборотами хаят pg и не вкладвают в него ни копейки. Причем контрибьюторы пг оперативно фиксят многие вещи, анализируют проблемы конкретных фирм итд итп.
Базовая вещ? Ну дак сделать то не проблема, правда?)khim
19.04.2018 20:52Базовая вещ? Ну дак сделать то не проблема, правда?)
Но зачем, если есть альтернатива, которая решает проблему?
Компании, вообще-то, используют open-source именно для того, чтобы «не вкладывать ни копейки».
Если потребуется вкладывать — они скорее эксклюзивно для себя фишечку сделают, благо лицензия PG это позволяет…Kwisatz
19.04.2018 22:32+1Компании, вообще-то, используют open-source именно для того, чтобы «не вкладывать ни копейки».
ну вот точно не для этого, это не free beerkhim
20.04.2018 00:05Это вы можете так считать. А 90% (если не 99%) процентов компаний рассчитывают именно на «free beer», а свобода их мало интересует…
Kwisatz
20.04.2018 00:32Дело не только в свободе. Использую СПО каждый должен отдавать себе отчет, что вам его создатели, в общем то, ничего не должны.

Hivemaster
18.04.2018 22:54Интересно, а кто-нибудь помнит, чтобы разработчики MySQL как-нибудь реагировали на критику их продукта?
ZurgInq
19.04.2018 06:44А им оно надо? Я в том числе не видел от них статей вроде «все БД говно, кроме MySql». У MySql есть куча своих проблем и куча форков, где эти проблемы просто решаются тем или иным образом.

Stas911
18.04.2018 23:17Кстати, а Амазон многое переделал в системе хранения когда свой Redshift точили?

alan008
18.04.2018 23:40+1Рискую отхватить минусов, но самый нормальный и самый стабильный во всех отношениях SQL Server — это Microsoft SQL Server. И в нем реализовано гораздо больше возможностей, чем во всех этих open source. Хочешь Row Versioning — включи одну настройку и работай. Не хочешь — работай с блокирующими апдейтами. Компрессия, репликация, отслеживание изменений таблиц, column store индексы, индексы с включенными полями, collation на каждую колонку, партиционирование, репликации, фэйловер кластер, always-on группы — возможностей хватит лет на 20 вперед. И все это доступно уже с версии 2012 как минимум (после этого уже вышли версии 2014 и 2016 и готовится очередная новая версия). MS уже не знает, что еще придумать, потому что их продукт превзошел всех конкурентов еще лет 10 назад. Ну разве что Oracle может поконкурировать.
По поводу стоимости лицензий да, все печально. Но продукт стоит того. Плюс есть Express версия, бесплатная.khim
19.04.2018 01:48В принципе вы правы, но… отсутствие поддержки Linux'а и цена ставят на нём крест в огромном проценте случаев. Тем не менее тот факт, что даже при таком гандикапе он идёт сразу после MySQL — говорит о многом…
Miron11
19.04.2018 07:45Microsoft SQL Server Поддержка Линукс
Поддерживает кластер пользуясь инфраструктурой PKI, не требуя Windows Active Directory.
groaner
19.04.2018 07:48А уведомления о событиях аналогичные постгресовским NOTIFY/LISTEN в SQL Server уже появились?
mayorovp
19.04.2018 08:01Да, давно уже, фича называется Service Broker. Но она очень тормозная.
groaner
19.04.2018 08:34Насколько я понимаю, это примерно как стрелять из пушки по воробьям. По крайней мере в SQL Server 2008 оказалось проще написать свой велосипед с long pulling хранимой процедуры.
Miron11
19.04.2018 17:37-1Какой ещё пушки, по каким воробьям. Дилетанты на выход. Пока не вынесли вперёд ногами.
Terras
19.04.2018 10:06-1Тут проблема немного в другом. Изначально у стартапов есть сомнения, что они взлетят, поэтому использовать дорогой продукт — это весьма сомнительный вариант. А когда они взлетают, то есть уже огромная база, вендор лок и прочее. В итоге, только безумный будет базу менять. А так да, весь стек майкрософта все лучше и лучше.
absurdil
19.04.2018 11:19+1Мне пришлось, реально заставили ставить MSSQL для OLAP.
И должен сказать что как-раз та часть которая OLAP целиком и полностью сделана на коленке.
А та часть которая MSSQL жрет ресурсы как-будто они бесплатны.
MS не знает что делать? Пусть займутся качеством, устойчивостью и прожорливостью. Там работы в их темпе на 10 лет хватит.

Guderian
19.04.2018 13:09Работаю с MS SQL уже лет 20, последние несколько лет экспериментирую с PostgreSQL. Небо и земля в пользу последнего. Для галочки в MSSQL огромное количество фич, но их использование — это иногда ад. В качестве примера — поддержка JSON вроде есть, но функции по работе с ним — рудиментарное уродство. CTE вроде есть, но ограничений — миллион, попробуйте использовать INSERT/UPDATE. Люди до сих пор мучаются с банальной конкатенацией строк, реализуя её через FOR XML — запросы. Да мы даже UTF-8 получить не можем, для пары спецсимволов я должен раздувать IO для всех строчных типов в два раза. Я UDF на родном для MS C# цепляю к пострелу проще, чем это делает их SQL Server. От приятных мелочей вроде DROP...CASCADE, DROP IF EXISTS до кастомных типов, индексов, языков UDF. Примеров могу привести миллион. Если их просуммировать — ну очень комфортно себя чувствую, пишу и оно работает так как надо.
mayorovp
19.04.2018 14:56В PostgreSQL ограничений не меньше. Те же CTE вроде как мощные — но при этом являются барьером оптимизатора, так что использовать их для чего-то сложного один фиг нельзя. Опять же, оптимизатор запросов в PostgreSQL порой творит какую-то дичь. А уж невозможность сделать delete top 1000 и вовсе кошмар…
Guderian
19.04.2018 15:59DELETE TOP — кошмар? Вы либо лукавите, либо работаете с очень специфичным проектом. Кошмар — это когда десятилетиями ждешь реализации OFFSET+LIMiT и пейджинг на MSSQL стал просто притчей во языцах. Уродливый полнотекстовый поиск, отсутствие deferred constraint, массивов. Регулярных выражений нет. Этож вдуматься только, в 2018 году я не могу сделать банальный creditcard/e-mail/phonenumber constrains. Вот это реально кошмар.
Остальные доводы — спекулятивные. Я миллион раз защищал оптимизатор MSSQL от нападок людей, которые просто не умели готовить годные ему запросы. Так что надо разбирать конкретные ситуации. Хотя, в плане чистого быстродействия я отдаю предпочтение MSSQL, но у Postgresql больше вариантов решений, в том числе и дающих существенный выигрыш.mayorovp
19.04.2018 16:18Там была не очень специфическая задача: раз в день переносить изменения из PostgreSQL в OLAP, для чего в PostgreSQL завели заполняемую триггером таблицу change_log. Нужно было всего-то вычитать из нее данные и почистить ее. Так вот: мне не удалось найти решение, которое бы работало за линейное время и при этом умело вычитывать эту таблицу по частям.
Получилось либо удаление всех записей в одной большой транзакции с чтением удаляемых при этом данных, либо квадратичный алгоритм (оптимизатор упрямо сует в план запроса на удаление полный проход по таблице). Итог в любом случае один и тот же: если позволить данным скопиться, то их уже никогда не удастся оттуда вычитать.Guderian
19.04.2018 21:44Сложно сказать, я попробовал топорный DELETE FROM… WHERE id = ANY(ARRAY(SELECT id… LIMIT 1000) или… WHERE id < (SELECT MIN(id) + 1000 ...), получилось Index only + Bitmap. Приблизительно то, что я в уме себе и представлял. Ради смеха попробовал вариант с отдельным VIEW на OFFSET 1000 и INSTEAD OF DELETE rule для него. Чтобы удаление выглядело просто как DELETE FROM log_batch_view. Примерно та же картина по быстродействию. В голове роилась ещё куча идей касательно использования BRIN, партиций и т.п., но из меня пока плохой укротитель слонов :) DELETE TOP, конечно, в данной задаче лучше, но я все равно склоняюсь к её специфичности. Это не то, что делаешь каждый божий день или по много раз в проекте. Даже когда набросал пример — началось с CREATE TABLE temp AS SELECT id,… FROM generate_series(1, 1000000) AS id. Попробуйте развернуть для MSSQL.
mayorovp
19.04.2018 21:49Сложно сказать, я попробовал топорный DELETE FROM… WHERE id = ANY(ARRAY(SELECT id… LIMIT 1000) или… WHERE id < (SELECT MIN(id) + 1000 ...)
Пробовал вариант похожий на первый, он почему-то давал полное сканирование таблицы и Hash Join. Но подробностей не помню уже, год назад это было...
Если задача возникнет снова — попробую ваш второй вариант, он выглядит так как будто там негде накосячить.

vintage
20.04.2018 10:05+2Справедливости ради, offset+limit — антипаттерн. Ибо:
1. Фильтровать при запросе каждой страницы — медленно
2. Между запросами выборка может измениться — привет, пропадающие записи и дубликаты
Правильное решение: выдать список идентификаторов (снепшот списка на конкретный момент времени), а потом отдельным пакетным запросом получить данные по интересующей части списка.
netch80
20.04.2018 22:18+1> offset+limit — антипаттерн
Но почему-то этот антипаттерн чуть более, чем везде.
А вот указать, от какой позиции листать дальше — я видел на FB (мобильной версии), reddit и blogspot… ой, и всё. Ну ладно, ещё кого-то я не знаю. Ну будет десяток имён на весь мир. И как это понимать?vintage
21.04.2018 09:28netch80
21.04.2018 10:55Даже() на хабре что-то вроде habrahabr.ru/all/page100 (заметьте, что page101 уже нет — то есть, задано искусственное ограничение), а не какая-нибудь /all/after1524296593/ (я взял текущий unixtime для примера, можно вместо этого по номеру статьи или как-то ещё).
Я бы понял, если бы вы сказали что-то вроде «ну ведь работает же и даже не выжирает всё, по крайней мере в 99% случаев». Но просто сослаться на AaP — «миллион мух/леммингов/etc. ничего не доказывают» это не более чем неконструктивно отмахнуться.
А меня исходно интересовало вообще, откуда берётся эта традиция листания по «страницам» вывода с непостоянной базой, что заставляет людей массово приходить к такому решению. Только традиция и примеры перед глазами, или есть ещё какой-то фактор?
Есть, кстати, ещё одно, идущее непонятно откуда, но тиражируемое чуть менее, чем всеми — это неуказание временно?го фактора в направлении листания. Опять же, хабр: «туда» это в прошлое. А почему собственно? На некоторых сайтах, кстати, наоборот. Явно «в прошлое» писал сам по себе разве что 3dnews.ru (и позже opennet.ru стал писать «раньше»/«позже», но это уже, извините, я попросил админа).vintage
21.04.2018 11:40+1Люди не любят думать, поэтому просто делают как все, пока очередной трендсеттер не повернёт хайп в другую сторону. И тогда все срочно ринутся переделывать. При этом не важно на что. Ты либо в тренде и считаешься остальными такими же профессионалом на острие технологий, либо не в тренде и делаешь странные вещи, а то и вообще назовут твой подход bad practive, так как хайп на него уже прошёл.
Обычно эволюция разработчика идёт такая:
- Херачим из базы всё, что запросили.
- Понимаем, что данных много, а нужны не все. Ага есть стандартный паттерн, который прикручивается малой кровью — паджинация.
- Огребаем багрепортов на тему странного дублирования записей. Много думаем, придумываем один из вариантов выдачи снепшота всего списка и догрузки подробной информации по части элементов.
- Огребаем багрепортов на тему экспоненциального потребления ресурсов для моделей с перекрёстными ссылками. Наконец нормализуем выдачу.
- Огребаем багрепортов на тему долгой загрузки. Ага, модели жирные, а показываются из них 1-2 поля. Прикручиваем укзазание интересующих в выдаче полей.
Сразу сделать хорошо ведь совсем не дорого (один раз реализовать универсальный мееханизм фетчинга любых коллекций, или всять уже готовое решение). Но нет, всем нужно пройти через все эти болезненные рефакторинги, потратив куда больше ресурсов.

jakobz
19.04.2018 21:40-1Вот плюс один. TSQL этот — как будто специально придумывали чтобы пытать людей. Типа где-то в MS: «я придумал! А давайте этим тварям оставим один цикл while! А чтобы по массиву строк пробежаться — чтобы строк десять надо было написать! Бугагагага!»
Постгрес на фоне — просто лапочка для программиста. А что он медленнее — да пофиг же. Замена одной SQL-базы на другую ради 2-3x ускорения — это только очень большим и богатым может отбиться, остальным проще сервер в 2 раза дороже купить.
dzsysop
19.04.2018 14:27Думаю им надо изменить лицензионную политику. Все самые крупные проекты на планете используют опенсорс ДБ на продакшн под невероятными нагрузками с миллионами а может миллиардами пользователей. Для MS просто затруднительно вообще правильно рассчитать количество лицензий необходимых для подобных решений. И даже приблизительная оценка стоимости выходит такой что отбивает желание даже у серьезных компаний даже «пробовать», как описано в данной статье. Я не слышал, может это и моя вина, ни об одном проекте, испоьзующем MS SQL Server для большого Веб Проекта из ТОП-100 сайтов. Поправьте меня если я не прав. Да MS SQL Server весьма востребован для различных бизнес решений, но когда мы говорим об экстремально высоких нагрузках, почему-то MS SQL редко всплывает в обзорах и докладах. Вполне возможно, что архитектурно в нем есть все и реализовано более менее правильно и логично. Но отсутствие реальных примеров может говорить о том, что при реальном прогоне под высокой нагрузкой повылазит большое количество не архитектурных проблем. Как кто-то уже написал тут в комментариях, например Postgres стараются быстро латать все возможные баги, которые им помогает обнаруживать огромное количество реальных и очень серьезных клиентов. Не думаю что MS реагтоуют также оперативно. В бизнес приложениях не принято так часто переходить с версии не версию. Плюс опенсорс модель позволяет общаться с клиентом на более низком уровне, в некоторых случаях изменения в коде могут быть сделаны моментально, и клиент должен просто пересобрать проект и получить изменения или даже сделать изменения самостоятельно. В случае с MS, неважно какого уровня разработчик готов вам помочь — изменения придут только с очередным пакетом обновлений. Я не противник MS. Я просто пытаюсь для себя найти объяснение, почему, если вы правы, реальность как бы это не подтверждает практикой использования.

freeart
19.04.2018 15:34Ну у mssql тоже есть минусы, я с ней работал в чистом виде и в виде сервиса azure sql в рамках проекта mapit.me Не помню деталей, давно это было, но были вещи которые бесили в mssql. На нее мы перешли как раз с postgresql. Другое дело azure sql, представим что вам дали его бесплатно (как это было в нашей компании), то можно смело ставит 10 из 10, более быстрой базы, плюс с мощным языком как t-sql сложно представить. Пропадает зависимость от операционной системы, используете его как облачный сервис. А чего стоит система рекомендаций: сама советует составные индексы, если запросы начинают просидать по из причине, или их удаление, если перестройка индекса слишком дорогая из-за частоты вставок. Плюс скорость и возможности pivot и partition by, индексы, кластеринг. partition by в postgresql работает ощутимо медленее, а про отвратительный pivot и вообще молчу, который уступает и oracle и mssql

Igelko
19.04.2018 17:03Хорошо, где у MS SQL транзакционный DDL?
Мне сильно нравится возможность Postgres в отдельной транзакции, никому не мешая (почти), накатить непростой апдейт на схему БД и откатиться, если что-то пойдёт не так.mayorovp
19.04.2018 17:07В MS SQL так тоже можно, за редкими исключениями (но лично мне они еще не попадались). С поправкой на то что это блокировщик, а не версионник.
Igelko
19.04.2018 17:17если верить этому, то изменения видны ещё до коммита
https://stackoverflow.com/a/3364466/1049821
but SQL Server does not version metadata, and so changes would be visible to others before the transaction commits.
или это поведение уже изменено в более свежих версиях?
x67
19.04.2018 00:38+1В статье так и не нашел ответа на вопрос, какая реляционная СУБД лучше?

unibasil
19.04.2018 01:55Всё зависит от задач. Скажем, если нужна интенсивная и небанальная работа с геоинформационными данными, PostgreSQL впереди планеты всей из-за упомянутого в статье расширения PostGIS.

NickyX3
19.04.2018 13:18Объясните пожалуйста более развернуто про небанальную работу с гео-данными.
unibasil
20.04.2018 03:43Под «небанальной» работой с геоданными я подразумевал всё то, что выходит за рамки отслеживания координат пользователя в реальном времени и различных алгоритмов поиска в дорожном графе, что, по идее, и является основными задачами компаний типа Uber. И что, в принципе, не требует каких-либо специализированных средств в БД и просто моделируется стандартными типами данных и стандартными операциями. PostGIS же обеспечивает более богатый функционал: работа с 2D и 3D геометриями (точками, линиями, полигонами и коллекциями геометрий), операции создания, манипулирования, сравнения, выборки и прочее, относящееся к геометрическим (и географическим) представлениям данных. Можете сами оценить мощность набора операций в справочнике PostGIS Reference. Всё это заточено и оптимизировано под свои специализированные типы данных. Не скажу насчёт современного состояния MySQL в этом вопросе (что-то там сейчас появилось из этой области), но во времена миграции Uber на PostgreSQL ничего подобного в MySQL точно не было. Собственно, и претензии Uber к PostgreSQL лежат не в области работы с геоданными, а в неоптимальной низкоуровневой обработке данных под high load. О чём и статья. ;)
NickyX3
20.04.2018 07:29Ну в MySQL пока прикрутили SPATIAL, то есть чистая классическая 2D геометрия.
Единственное что нам было нужно — гео-дистанцию мы прикрутили через UDF. Для регионов (ну там вхождения точек и вот это все) можно ES пользовать, в 6+ совсем неплохо работает
x67
19.04.2018 20:26Так я пошутил)
На мой вопрос нет правильного ответа)
Хотя мне интересно, почему многие рассматривают постгрес исключительно вместе с постгис? Без гео составляющей в ней совсем совсем смысла нет?unibasil
20.04.2018 03:54Мне лично очень нравится поддержка JSONB и довольно могучий и гибкий полнотекстовый поиск. Опять же, возможно в свежих версиях MySQL всё это появилось, но из-за отсутствия NoSQL средств работать с версией 5.5 после PostgreSQL было откровенно грустно. Вот ниже коллеги подтверждают ту же мысль. ;) Вообще, если выбирать СУБД для новых проектов, однозначно нужно брать Postgres, а не MySQL.
unibasil
20.04.2018 04:04Вот, кстати, приятные новости по теме полнотекстового поиска.
apapacy
20.04.2018 04:19Увы, все что касается полнотекстового поиска, если нет реализации fuzzy search — не имеет практической ценности (в подавляющем большинстве случаев).
Совместное с SQL использование эластики тоже проблематично т.к. не будет целостности данных.
Все мосты которые поддерживают связь эластики с другими базами — при рахрыве соединения не обспечивают согласованности данных в sql и эластике.
В этом смысле мне пока известны два решения — это orientdb в которуб встроена lucene и neo4j. При этим первая еще не очень стабильная а вторая платная.
И еще в h2 модно встроить lucene но там больше придется производить работы при индексации.
В orientdb все просто — объявляешь на поле индекс типа lucene и просто ищешь что нужно.unibasil
20.04.2018 05:06В области геокодирования и поиска адресной информации средств Postgres'овского FTS вполне достаточно, использование elasticsearch и аналогов тут будет очевидным overhead. Но всё зависит от задачи, конечно. ;)
apapacy
21.04.2018 13:48Я имею в виду конкретно fuzzy search то есть поиск в таком виде «хбрахрб»~0.6 который выдаст строки похожие но не полностью соответствующие. Эта функциональность нужна практически всюду чтобы позволить находить текст при опечатках, грамматических ошибках. Есть конечно еще и жесткие мосты которые аттачатся триггерами к mysql или postgres. Но это и минус в потере производительности и откат транзакции в случае той же самой недоступности эластики. Проблема с моей точки зрения очень неприятная и нерешенная. Хоnеось бы иметь такой мост который делал типа репликации на эластику но он пока что у всех в road map.
Ну или же встроенного индекса типа lucene как в orientdb или h2
Kwisatz
19.04.2018 02:34+1Вы уж извините меня, но выглядит все это очень странно. PG Это нормальная база данных, а MySQL это доска с гвоздями. Конечно, первый не без проблем. Но поменять кучу возможностей от CTE до функциональный индексов на ээ, что? Тот же оптимизатор MySQL это таная странная штука, по которой я знаю 100500 рецептов, но даже зная их, к ним возвращаться никакого желания нет.
И уж простите, что я не верю в тот факт, будто они действительно упираются в столь низкие уровни. Как правило глянув в любую базу есть проблемы уже на стадии архитектуры, а в запросах порой такой ад творится, что не передать.
Их метания добавляют еще больше веса моим сомнениям. Имхо разработчик, который не просто попробовал перенести текущий функционал, а вкусивший pg или oracle, на Mysql не вернется уже никогда.
OlehR
19.04.2018 09:58Чуть поправлю вкусивший oracle, работает на всем остальном с легким отвращением :). Но что поделаеш жизнь не мед.
Kwisatz
19.04.2018 16:45Я не так много работал конечно, но встретил не так много вещей изза которых мне бы хотелось испытывать отвращение к пг) Хотя БД классная, спору нет)
OlehR
19.04.2018 17:50Если поработать на Oracle несколько лет то все его богатство (SQL, PL\SQL, Администрирование ) становится нормой. И когда возвращаешся на что то другое, ето как пересесть с мерседеса на ладу калину :)
У каждой БД есть свои слабые и сильние стороны. И я считаю что PG лутшая из безплатных. Оракл — просто лутшая.
Если по сравнению pl/sql реально на порядок круче pgsql по возможностям, лаконичности, ориентации на быстодействие, и тд.
Из возможности БД — партиции явно еще не продакшин да и базових возможностей партиций на порядок меньше, такие фичи как кеш резалт — просто волшебная палочка.
Да и отсуствие merge. Оптимизатор намного круче и тд. Ето то что что пришло на ум за несколько минут. Да и скаждой новой версией Оракл не перестает удивлять.
Тут писали что t-sql крутой, для меня он реально топорний. Я с трудом представляю что кто то решится писать всю бизнес логику на t-sql или на pgsql. C ораклом на такое решится без проблем. Там управляемость и скорость, которою очень сложно достичь на высокоуровневых языках.
P.S. Неохота разводить холивар БЛ БД VS С\С+\C#\JAVA\…Kwisatz
19.04.2018 20:22Если по сравнению pl/sql реально на порядок круче pgsql по возможностям, лаконичности, ориентации на быстодействие, и тд.
не довелось так глубоко изучить, но там от версии к версии все очень таки разное даже в самом pl/pgsql
А есть еще:
PL/Java
PL/Lua
PL/Perl
PL/PHP
PL/Python
PL/R
PL/Ruby
PL/Scheme
PL/Sh
PL/Tcl
PL/V8
И глядя на этот список есть подозрение что там можно найти искомое)
По партициям в принципе согласен, хотя в 10ке уже очень все приличненько.
Я с трудом представляю что кто то решится писать всю бизнес логику на t-sql или на pgsql.
Я видел примеры реализации логики на v8 и выглядело все довольно здорово.OlehR
20.04.2018 08:36Да я знаю про весь етот зоопарк. Но ведь чтоб PL/… вызвать SQL или же наоборот в запросе обратится к процедуре на PL/… теряется очеть много ресурсов. И все ето очень не нативно(как то сбоку к БД). В оракле етому (скорости переключение контекста) уделяется огромное внимание. В плоть до того что сделали хинт процедурам указивающий что процедура специально создана для SQL. Кроме того возможможность компелировать в нативний код. + Разбор SQL делается на момент компиляции и тд. Ведь основноя задача встоеного язика работать з базой. А здесь все намного полутше в оракла.
Да 100% писать код на C# или JAVA намного удобнее чем на PL/SQL за счет GUI синтаксиса и тд. Но когда задача работать с транзакциями и даними Pl/sql действительно хорош.

wert_lex
19.04.2018 10:32+2Имхо, мне кажется тут самый главный затык именно в репликации. В реляционках оно исторически сложнее по многим причинам, и если в MySQL репликация действительно лучше, стабильнее и "правильнее" чем в Postgre, то еще очень большой вопрос что лучше -30% на ноду из-за странного оптимизатора (проценты), или невозможность распределять корректно чтения в кластер (разы).
mayorovp
19.04.2018 15:00Кривая оптимизация запроса — это не какие-то 30%, а миллион раз.
Kwisatz
19.04.2018 16:53Ну только лишь оптимизация я бы конечно не сказал что миллион. Но в совокупности очень может быть. Те же, например, функциональные индексы могут давать огромный прирост, если фунцию можно объявить immutable.
Возможностей море. Не так давно знакомые делились что перенесли обработку данных внутрь базы на v8 и получили существенный прирост скорости обработки данных. Обрадовались и засунули туда еще больше данных через FDW. Когда много возможностей это всего хорошо.mayorovp
19.04.2018 17:06Да нет, когда идет полный обход таблицы вместо обращения через индекс — то на больших базах может и чего похуже миллиона раз получиться.
Kwisatz
19.04.2018 16:4130%? Простите, вы шутите? Я могу руками, на относительно небольшом запросе, mysql прибавить работы раза в 3 как минимум вообще не раздумывая. Я в свое время когда только переходил на PG взял большой запрос: 12 джоинов, вложенные выборки, группировки, и начал его всячески изощренно гнуть. На pg базовое время выполнения оптимального для mysql запроса сразу же было лучше и изменить мне его удалось в рамках 10%, а вот на mysql время выполнения разнилось в разы.
wert_lex
19.04.2018 18:11На pg базовое время выполнения оптимального для mysql запроса
А оптимального для mysql?
Я ни в коем случае не пытаюсь похвалить mysql, я просто хочу сказать, что есть случаи, когда возможность корректного scale out (и внезапно здесь в этой роли mysql) важнее возможности scale up и перфоманса одной конкретной ноды.Kwisatz
19.04.2018 20:16А оптимального для mysql?
Таки да, я специально уточнил.
Я ни в коем случае не пытаюсь похвалить mysql, я просто хочу сказать, что есть случаи, когда возможность корректного scale out (и внезапно здесь в этой роли mysql) важнее возможности scale up и перфоманса одной конкретной ноды.
Возможно. Если действительно грамотная архитектура, вылизанные запросы и оптимальная конфигурация. В противном случае это попытка отложить проблемы костылями.

Frankenstine
19.04.2018 10:47+2Вам, пожалуй, стоит устроиться в Убер и сделать всё красиво :)
Kwisatz
19.04.2018 16:43Чтобы меня там начали спрашивать о том как устроен системный кеш линуха до того как я взгляну на базу? Нет, спасибо, я это проходил раз 5 уже.
К тому же мне не нравицо убер. А комфорт при работе для меня главное.
Kwisatz
19.04.2018 16:59Кстати, знаете, мой скептицизм не на ровном месте. Заглянешь в какой нить сайтик на битриксе со смешным количеством данных, который нормальный сервак насилует, а там таблица по принципу «все сюда» и без каких либо индексов, вешаешь индекс и сразу нагрузка падает на 95%.
В эру вап сайтов у меня в сервисах был 1 млн пользователей, более 600 млн личных сообщений (активно удаляемых) и все бегало очень шустро на IBM x346, при том тчо параллельно там был форум с десятками тысяч сообщений в темах и счетчики посещаемости, обрабатывающие сотни млн хитов в сутки. А сейчас из каждого утюга с 10 млн строк в базе раздаются рассуждения об оптимизации и неоптимальности работы пг с кортежами.
absurdil
19.04.2018 11:15+2Я наверное странную вещь спрошу, но ситуация кажется мне несуразной.
Я не понимаю почему переход MySql -> Postgres и обратно возможен, а переход на более новую версию Postgres нет.
Я не понимаю почему в том что компания выбрала продукт не проверив его виноват продукт?
Я не понимаю почему они, как пологается взрослым людям, не работали с обоими решениями паралельно, убеждаясь в надежности и правильности выбора хотя-бы пол года — год.
Не надо делать поспешных решений, продиктованых модой или давлением сверху, тогда и не будет переходов на разные базы данных раз в три года.
И не будет необходимости искать виноватых.acmnu
19.04.2018 20:18+1Я не понимаю почему переход MySql -> Postgres и обратно возможен, а переход на более новую версию Postgres нет.
Ну это им нужно было один раз сделать, а потом mysql обновлять почти без даунтайма.
absurdil
20.04.2018 10:37+1«почти без даунтайма»? — позволю себе не согласиться.
Компания такого уровня должна иметь в архитектуре запланированные простои одного или нескольких серверов баз данных. И уметь это решать на уровне общей архитектуры проекта.
Конечно, если такие вещи не запланированы вначале, их не просто сделать потом.
Но можно. И нужно.
А все остальное — отговорки. Я работал над продуктом который использовал в отдельные моменты времени 3 разных сервиса хранения информации. И имел ( да и сейчас имеет) решения для случая когда не то что сервер, когда датацентр умирает.
Весь этот плач о «прохой базе данных» — это стыдно и не профессионально. Убер никто не просил использовать решение не проверив его.
И сводить разговор к «MySql vs Postgres» это не этично.
Если я буду резать хлеб бензопилой и потеряю руку, виновата ли в этом бензопила?acmnu
20.04.2018 10:53А конкретику можно. Как вы видите такую архитектуру?
absurdil
20.04.2018 11:15Для конкретики нехватает информации о внутреннем устройстве балалайки.
Общая схема в таких случаях — любые данные аппликативно или через прокси пишутся в больше чем один мастер. В больше чем один вид баз данных. Тогда можно и проверить все перед тем как переключаться.
А чтение должно быть реализовано через серию «запасных аэродромов» типа если данных нет тут, поищем там.
То есть в начале всегда читаем из старой базы, и на фоне проверяем что в новой данные тоже есть ( а если нет — дотягиваем). Потом, после перехода, долгое время все еще пишем в обе, но читаем сначала из новой. И если чего-то нет — читаем из старой и дотягиваем отсутствующее.
Это не что-то новое. Это способ иметь работаюший продукт и не шарахаться по непровереным технологиям.
Но это все — тот этап когда база данных проверена и выбрана.
А до того надо протестировать кандидата на простых кейсах и убедиться что он подходит.
Простые кейсы разнятся от базы к базе, но если для NoSQL это проверка устойчивости кластера, скорость работы под нагрузкой и ростом данных, то для RDBM необходимо проверить скорость и способ репликации — в общем проверить теряет ли система данные в критичных ситуациях.
Пример — Mongo не выдерживает проверок, тестовый кластер из 4х машин под нагрузкой при уходе одного их серверов падает в осадок. Не всегда. Но падает. И если этого можно добиться на стенде — то в бою такой кластер сам загнется. Без вашей помощи.
Sovigod
20.04.2018 12:25>> То есть в начале всегда читаем из старой базы, и на фоне проверяем что в новой данные тоже есть ( а если нет — дотягиваем).
А если они есть везде, но разные?
mtyurin
21.04.2018 11:56+1Не нашёл на странице упоминания schemaless.
ДевКонф решил хайпануть на холиваре. Не похвально.
ky0
Отформатируйте стену текста, пожалуйста — очень тяжело читать.