
«Цель этого курса — подготовить вас к вашему техническому будущему.»
 Привет, Хабр. Помните офигенную статью «Вы и ваша работа» (+219, 2372 в закладки, 375k прочтений)?
Привет, Хабр. Помните офигенную статью «Вы и ваша работа» (+219, 2372 в закладки, 375k прочтений)?Так вот у Хэмминга (да, да, самоконтролирующиеся и самокорректирующиеся коды Хэмминга) есть целая книга, написанная по мотивам его лекций. Мы ее переводи, ведь мужик дело говорит.
Это книга не просто про ИТ, это книга про стиль мышления невероятно крутых людей. «Это не просто заряд положительного мышления; в ней описаны условия, которые увеличивают шансы сделать великую работу.»
Мы уже перевели 16 (из 30) глав.
Глава 14. Цифровые фильтры — 1
(За перевод спасибо Максиму Лавриненко и Пахомову Андрею, которые откликнулись на мой призыв в «предыдущей главе».) Кто хочет помочь с переводом — пишите в личку или на почту magisterludi2016@yandex.ru
Теперь, когда мы изучили компьютеры и разобрались в том, как они представляют информацию, давайте обратимся к тому, как компьютеры обрабатывают информацию. Разумеется, мы сможем изучить лишь некоторые способы их применения, поэтому сосредоточимся на основных принципах.
Большая часть того, что компьютеры обрабатывают, — это сигналы из разных источников, и мы уже обсуждали, почему они часто бывают в виде потока чисел, полученного из системы дискретизации. Линейная обработка, единственная, на которую у меня хватает времени в рамках этой книги, подразумевает наличие цифровых фильтров. Чтобы продемонстрировать, как всё происходит в реальной жизни, сначала я расскажу вам о том, как я стал работать с ними, и далее о том, чем я занимался.
Во-первых, я никогда не заходил в офис моего вице-президента В. О. Бейкера; мы встречались только в коридорах, и обычно останавливались всего на несколько минут, чтобы поговорить. Однажды, примерно в 1973-1974 годах, при встрече в коридоре, я сказал ему, что помню, как в то время, когда я пришёл в Bell Telephone Laboratories в 1946 году, компания постепенно переходила от релейного к электронному центральному управлению, и многие сотрудники тогда были переведены в другие подразделения, так как не смогли перейти на осциллографы и другие новейшие электронные технологии. Для него они представляли лишь серьёзные экономические потери, но для меня это была и социальная потеря, так как эти сотрудники были как минимум недовольны тем, что их перевели (хоть это и была их собственная ошибка). Далее я упомянул, что наблюдал аналогичную ситуацию, когда мы перешли со старых аналоговых компьютеров (по которым в Bell Telephone Laboratories было много экспертов, т. к. они разрабатывали большую часть технологий во время Второй мировой войны) на более современные цифровые компьютеры, — мы снова потеряли большое количество инженеров, и снова они были как экономической, так и социальной потерей.
Затем я заметил, что мы оба знаем, что компания в кратчайшее сроки собирается полностью перейти на цифровую передачу сигналов, в результате чего мы получим еще большее количество недовольных инженеров. Таким образом, я пришел к выводу, что мы должны сейчас что-то сделать для улучшения ситуации, например, получить элементарные учебники и другие обучающие материалы, чтобы облегчить адаптацию сотрудников и потерять меньшее их количество. Он посмотрел мне прямо в глаза и сказал: «Да, Хэмминг, ты должен сделать это». И ушел! Более того, он продолжал ободрять меня через Джона Тьюки, с которым часто общался, поэтому я знал, что он следит за моими усилиями.
Что делать? Сначала я думал, что очень мало знаю о цифровых фильтрах, и, кроме того, на самом деле, меня они не интересовали. Но разумно ли игнорировать своего вице-президента, а также убедительность собственных наблюдений? Нет! Возможные социальные потери были слишком большими для меня, чтобы не придавать им значения.
Поэтому я обратился к своему другу Джиму Кайзеру, одному из мировых экспертов в области цифровых фильтров того времени, с предложением приостановить его текущее исследование и написать книгу об электронных фильтрах, аргументируя это тем, что подведение итогов — это естественный этап в развитии любого учёного. После некоторого напора он согласился написать книгу, и я подумал, что был спасён. Но наблюдение за тем, что он делал, показывало, что он ничего не писал.
Чтобы спасти свой план я сделал ему следующее предложение: если он будет обучать меня за завтраками в ресторане (там будет больше времени на то, чтобы подумать, чем в столовой), чтобы помочь написать книгу совместно (хотя бы первую часть), то мы выпустим её под авторством Кайзера и Хэмминга. Он согласился!
Спустя некоторое время я перенял от него много знаний, и у меня была готова первая часть книги, но он сам всё ещё ничего не писал. Поэтому однажды я сказал: «Если ты так ничего и не напишешь, авторство книги в конечном итоге будет указано, как Хэмминга и Кайзера». И он согласился. В итоге, когда я закончил написание книги, а он ничего так и не написал, я сказал, что могу поблагодарить его в предисловии, но автором будет указан только Хэмминг, он согласился – и, несмотря на это, мы и по сей день хорошие друзья! Так появилась книга о цифровых фильтрах, которую я написал, и которая в конечном итоге прошла через три издания, всегда с хорошими советами от Кайзера.
Также благодаря книге я посетил много интересных мест, так как много лет проводил короткие, недельные курсы. Короткие курсы я начал давать ещё в процессе написания книги, так как мне нужна была обратная связь, и я предложил Отделу расширения Университета Калифорнии в Лос-Анджелесе (УКЛА) дать мне проводить обучающие курсы, и они согласились. Это привело к годам преподавания в УКЛА, по одному разу в Париже, Англии — Лондоне и Кембридже, а также во многих других местах в США и, как минимум, дважды в Канаде. Выполнение того, что нужно было сделать, хотя я и не хотел этого делать, в конечном итоге окупилось.
Теперь перейдём к более важной части — о том, как я начал изучать новый предмет — цифровые фильтры. Изучение нового предмета — это то, что вам придётся делать много раз в своей карьере, если вы хотите быть лидером и не оставаться позади новейших разработок. Вскоре мне стало ясно, что в теории цифровых фильтров преобладают Ряды Фурье, которые я как раз изучал в колледже. Кроме того у меня было много дополнительных знаний благодаря моей работе по обработке сигналов, выполненной для Джона Тьюки, который был профессором из Принстона, гением и одним или двумя днями в неделю сотрудником Bell Telephone Laboratories. На протяжении почти десяти лет большую часть времени я был его вычислительной машиной.
Будучи математиком, я знал, как и все вы, что любая полная система функций подойдет так же хорошо для разложения произвольной функции в ряд как и любая другая полная система функций. Почему же тогда так отличаются Ряды Фурье? Я спрашивал у разных инженеров-электротехников, но не смог получить удовлетворительных ответов. Один из инженеров сказал, что переменные токи были синусоидальными, поэтому они использовали синусоиды, на что я ответил, что это не имело для меня никакого смысла. Вот тебе и обычное образование типичного инженера-электрика после окончания школы!
Поэтому я должен был подумать о базовых принципах, как я уже делал это при использовании компьютера с обнаружением ошибок. Что же на самом деле происходит? Я полагаю, многие из вас знают, что то, что мы хотим — это инвариантное во времени представление сигналов, поскольку обычно нет возможности установить начало сигнала. Поэтому в качестве инструмента представления вещей мы приходим к тригонометрическим функциям (собственным передаточным функциям) в виде, как рядов Фурье, так и интегралов Фурье.
Во-вторых, линейные системы, которые нас интересуют на этом этапе, имеют те же собственные функции — комплексные экспоненты, которые эквивалентны действительным тригонометрическим функциям. Следовательно, простое правило: если у вас есть либо система с инвариантом во времени, либо линейная система, то вы должны использовать комплексные экспоненты.
При дальнейшем углублении в тему я нашёл и третью причину для использования их в области цифровых фильтров. Существует теорема, которую часто называют «теоремой дискретизации Найквиста» (считалось, что она была известна задолго до того и даже была опубликована Уиттекером в форме, которую едва ли можно понять, даже если вы знаете теорему Найквиста), в которой говорится, что если у вас есть сигнал с ограниченным по частоте спектром и вы снимаете отсчёты через равные промежутки времени с частотой не менее чем в два раза превышающей максимальную частоту в спектре сигнала, то исходный сигнал может быть восстановлен из полученных отсчётов без потерь. Следовательно, процесс дискретизации не теряет никакой информации, когда мы заменяем непрерывный сигнал равноотстоящими отчётами, при условии, что уровни квантования охватывают всю прямую вещественных чисел. Частоту дискретизации часто называют «частотой Найквиста» в честь Гарри Найквиста, известного также за вклад в стабильность сервоприводов, а также другие вещи. Если вы дискретизируете функцию с неограниченной шириной спектра, то более высокие частоты «накладываются» на более низкие. Это термин ввёл Тьюки для описания явления, когда одна более высокая частота проявится позже в качестве более низкой частоты в диапазоне Найквиста.
То же самое неверно для любого другого набора функций, скажем степеней t. При равномерной по времени дискретизации и последующем восстановлении сигнала одна высокая степень t станет многочленом (состоящим из нескольких членов) более низких степеней t.
Таким образом, существуют три веские причины для использования функций Фурье: (1) инвариантность во времени, (2) линейность и (3) восстановление исходной функции из ее дискретного представления производится просто и понятно.
Поэтому мы будем анализировать сигналы в терминах функций Фурье, и мне не нужно обсуждать с инженерами-электротехниками, почему мы обычно используем комплексные экспоненты вместо вещественных тригонометрических функций для представления частот. У нас есть линейная операция, и когда мы помещаем сигнал (поток чисел) в фильтр, выводится другой поток чисел. Естественно, если не из курса линейной алгебры, то из других предметов, таких как курс дифференциальных уравнений, возникает вопрос, какие функции входят и выходят без изменений, кроме масштаба? Как отмечалось выше, они являются сложными экспонентами; это собственные функции линейных, инвариантных по времени, дискретных систем с равномерной во времени дискретизацией.
И вот ведь как, знаменитая передаточная функция — это собственные значения соответствующих собственных функций! Когда я спрашивал различных инженеров-электриков о том, что такое передаточная функция мне никто не сказал об этом! Да, когда им указывали, что это то же самое, им приходилось согласиться, но сами они об этом, кажется, никогда не задумывались! В их сознании была одна и та же идея, но в двух и более различных образах, и они и не подозревали о какой-либо связи между ними! Всегда начинайте с базовых принципов!
Теперь давайте обсудим «Что такое сигнал?». В природе есть много сигналов, которые являются непрерывными, и которые мы дискретизируем через равные промежутки времени и далее оцифровываем (квантуем). Обычно сигналы являются функцией времени, но любой эксперимент в лаборатории, который, например, использует изменение напряжения с одинаковым шагом и фиксирует соответствующие отклики, также является цифровым сигналом. Таким образом, цифровой сигнал является последовательностью измерений, полученных через одинаковые интервалы, представленной в виде чисел. И мы получаем на выходе цифрового фильтра еще один набор чисел, равноотстоящих друг от друга. Допускается обработка и неравномерно отстоящих данных, но я не буду рассматривать их здесь.
Квантование сигнала на один из нескольких уровней выхода часто имеет удивительно малый эффект. Вы все видели изображения, квантованные на два, четыре, восемь и более уровней, и даже изображение двух уровней обычно можно распознать. Я не буду рассматривать квантование здесь, поскольку оно обычно оказывает небольшой эффект, хотя временами это очень важно.
Следствием равномерной по времени дискретизации является наложение, частота выше частоты Найквиста (которая имеет два отсчёта в цикле) будет наложена на более низкую частоту. Это простое следствие тригонометрического тождества
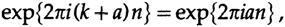
где a — положительный остаток после удаления целого числа вращений, k (мы всегда используем вращения при обсуждении результатов и используем радианы в вычислениях, так же, как мы используем десятичные и базовые натуральные логарифмы), и n — количество шагов. Если а > 1/2, то мы можем написать
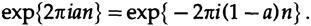
Таким образом, наложенный диапазон будет меньше 1/2 оборота, плюс-минус. Если мы используем две реальные тригонометрические функции, sin и cos, то мы получаем пару собственных функций для каждой частоты, и диапазон вращения будет от 0 до 1/2 оборотов, а при использовании комплексной экспоненциальной записи мы получим одну собственную функцию для каждой частоты, но теперь диапазон будет достигать от -1/2 до 1/2 оборотов. Такое предотвращение множественных собственных значений является одной из причин, почему комплексные частоты намного легче обрабатываются, чем действительные синусоидальные и косинусные функции. Максимальная частота дискретизации, для которой наложение не происходит, — это два отсчёта в цикле, такая частота называется частотой Найквиста. Исходный сигнал не может быть восстановлен по отсчётам в диапазоне наложенных частот, только частоты которые попадают в интервал неналоженных частот (от -1/2 до ?) могут быть однозначно определены. Сигналы от различных наложенных частот переходят на одну частоту в диапазоне и алгебраически складываются; это то, что мы получаем в результате выполнения дискретизации. Таким образом во время наложения может произойти усиление или подавление определенной частоты, и мы не можем получить исходный сигнал из сигнала с наложением. При максимальной частоте дискретизации нельзя сказать результат для 1, так как неналоженные частоты должны быть внутри диапазона.
Мы будем растягивать (сжимать) время, чтобы мы могли измерять частоту дискретизации как 1 отсчёт в единицу времени, потому что это значительно все упрощает и позволяет распространить данные от милли и микросекунд до таких интервалов, которые могут занять несколько дней или даже лет между отсчётами. Всегда разумно перенимать стандартную систему счисления и структуру мышления из одной области в другую — одна область применения может позволить найти решение задачи в другой. Я убедился, что есть большой смысл делать так везде, где это возможно, — убирайте посторонние факторы масштаба и переходите к исходным выражениям. (Но тогда я изначально обучался математике)
Наложение — это фундаментальный эффект дискретизации, и он не имеет ничего общего с обработкой сигналов. Мне было удобно думать, что как только снимаются отсчёты, все частоты находятся в диапазоне Найквиста, и, следовательно, нам не нужно рисовать периодические продолжения чего-либо, так как другие частоты больше не существуют в сигнале — после дискретизации высокие частоты переходят в нижний диапазон и перестают существовать. Как же я ошибался! Акт дискретизации производит наложенный сигнал, с которым мы должны работать.
Теперь я перехожу к трем историям, в которых используются только идеи дискретизации и наложения. В первой истории я пытался вычислить численное решение системы из 28 обыкновенных дифференциальных уравнений, и я должен был знать, какую частоту дискретизации мне нужно использовать (размер шага решения — это частота дискретизации, которую вы используете), поскольку, если бы она была вдвое меньше, чем ожидалось, то счётчик вычислений будет примерно в два раза больше. В наиболее популярных и практических методах численного решения математическая теория рассчитывает размер шага по пятой производной. Кто мог знать об этом? Никто. Но если рассматривать шаг в рамках дискретизации, наложение начинается с двух отсчётов для самой высокой частоты, при условии, что у вас есть данные от минус до плюс бесконечности. Я интуитивно понимал, что при наличии только короткого диапазона из максимум пяти точек данных, мне потребуется примерно в два раза больше, или 4 отсчёта за цикл. И, наконец, при наличии данных только с одной стороны, возможен, еще один фактор удвоения; всего 8 отсчётов за цикл.
Затем я сделал две вещи: (1) разработал теорию и (2) провел численные тесты на простом дифференциальном уравнении
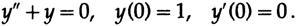
Оба они показали, что при 7 отсчётах за цикл, вы получаете приблизительную точность (за шаг), а при 10 — абсолютную. Так что я объяснил всё, как есть и запросил высшие частоты в ожидаемом решении. Справедливость моей просьбы была оценена, и через несколько дней мне сказали, что я должен беспокоиться о частотах до 10 циклов в секунду, а те, что выше не моя забота. И это было правильно, и ответы были удовлетворительными. Теорема дискретизации в действии!
Вторая история затрагивает историю, рассказанную мне случайно в залах Bell Telephone Laboratories, о том, что у какого-то субподрядчика Западного побережья возникли проблемы с имитацией запуска ракеты Nike, он использовали интервалы между отсчетами от 1/1000 до 1/10 000 секунды. Я сразу же засмеялся и сказал, что это должно быть какая-то ошибка, так как для модели, которой они пользовались, было бы достаточно от 70 до 100 отсчётов. Оказалось, что у них было двоичное число, смещённое на 7 позиций влево, в 128 раз большее! Отладка большой программы на другом конце континента при помощи теоремы дискретизации!
Третья история о том, как группа в военно-морской аспирантуре понижала частоту очень высокочастотного сигнала настолько, чтобы иметь возможность его дискретизировать, согласно теореме дискретизации, как они ее понимали. Но я понял, что если они с умом дискретизируют высокую частоту, то дискретизация сама по себе понизит частоту сигнала (наложит исходный сигнал на более низкую часть спектра). После нескольких дней споров они всё таки сняли стойку с оборудованием для понижения частоты, и тогда остальная часть оборудования стала работать лучше! И в этот раз мне понадобилось только твёрдое понимание эффекта наложения при дискретизации. Это еще один пример того, почему вам нужно хорошо знать базовые принципы; остальное вы сможете легко додумать и делать вещи о которых вам никто никогда не говорил.
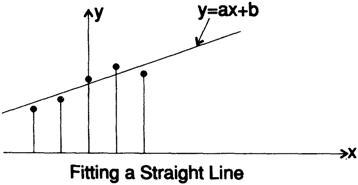
Рисунок 14.I
Дискретизация — это фундаментальный подход, который мы используем при обработке данных в процессе работы за цифровыми компьютерами. Теперь, когда мы понимаем, что такое сигнал, и что дискретизация делает с сигналом, мы можем смело переходить к более подробному рассмотрению процессов обработки сигналов.
Сначала мы обсудим не рекурсивные фильтры, целью которых является пропускание одних частот и подавление других. Впервые подобная задача возникла в телефонной компании, когда у них появилась идея, что если переместить все частоты одного голосового сообщения наверх (модулировать сигнал), за предел диапазона частот другого голосового сообщения, то эти два сигнала можно сложить и отправить вместе по одним и тем же проводам, а на другой стороне их можно будет отфильтровать и разделить, после чего перенести частоты более высокого сигнала в обычный интервал частот (демодулировать). Такое смещение частоты – это просто умножение на синусоидальную функцию и выбор одной из двух частот (однополосная модуляция), которые возникают по следующему тригонометрическому тождеству (на этот раз мы используем вещественные функции)
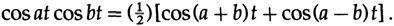
Нет ничего загадочного в изменении частоты (модуляции) сигнала, это не более чем одно из тригонометрических тождеств.
Нерекурсивные фильтры, которые мы рассмотрим в начале, в основном будут сглаживающими фильтрами, где входными значениями являются значения u(t)=u(n)=un, а выходными — yn
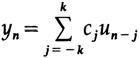
с Cj=C-j (коэффициенты симметричны относительно центрального значения C0).
Мне нужно напомнить вам о методе наименьших квадратов, поскольку он играет фундаментальную роль в том, что мы собираемся делать, для этого я разработаю сглаживающий фильтр, чтобы показать вам, как создаются фильтры. Предположим, что у нас есть сигнал с добавлением «шума» и его нужно сгладить, удалить шум. Я полагаю, что вам покажется разумным приблизить 5 последовательных значений прямой линей методом наименьших квадратов, а затем взять среднее значение на этой линии в качестве «сглаженного значения функции» в этой точке.
Для математического удобства мы выберем 5 точек при t = -2, -1,0,1,2 и проведем
прямую линию, рис. 14.I.
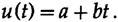
Метод наименьших квадратов говорит, что мы должны минимизировать сумму квадратов различий между данными и точками на линии, т. е. минимизировать
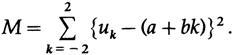
Какие параметры нужно использовать для дифференциации, чтобы найти минимум? Это a и b, а не t (теперь дискретная переменная k) и u. Линия зависит от параметров a и b, и это часто
камень преткновения для студентов; параметры уравнения являются переменными для минимизации! Следовательно, при дифференцировании по а и b и приравнивании производных к нулю для получения минимума имеем
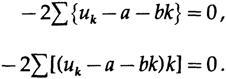
В этом случае нам нужно только a — значение линии в средней точке, следовательно, используем (некоторые суммы указаны для последующего использования),
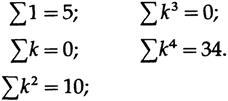
из верхнего уравнения имеем
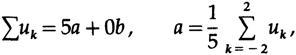
что является просто средним из пяти смежных значений. Когда вы думаете о том, как выполнять вычисление сглаженного значения для найденного a, думайте о данных в вертикальном столбце, рис. 14.II, взятых с коэффициентами 1/5, как о скользящем взвешенном значении; вы можете представить себе окно, через которое вы смотрите на данные, причем «форма» окна – это и есть коэффициенты фильтра. Рассмотренный случай сглаживания является равномерным.
Если бы мы использовали 2k+1 симметрично расположенные точки, мы бы все равно получили бы среднее из точек данных в качестве сглаженного значения, которое должно было бы устранить шум.
Предположим, что мы сгладили функцию аппроксимировав ее параболой вместо прямой, рис. 14.III:
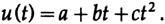
Установив разность квадратов и дифференцируя в этот раз по a, b и c, получим:
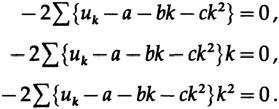
Опять же нам нужно только a. Переписывая первое и третье уравнения (среднее не включает a) и подставляя рассчитанные выше суммы мы получаем
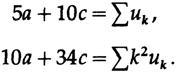
Чтобы исключить переменную c, которая нам не нужна, умножим верхнее уравнение на 17 и нижнее уравнение на -5 и сложим, чтобы получить
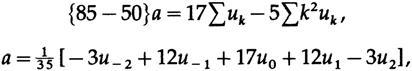
и на этот раз наше «сглаживающее окно» не имеет одинаковых коэффициентов, более того, некоторые из них являются отрицательными. Не стоит беспокоиться по этому поводу, так как мы говорим об окне метафорически, и, следовательно, возможна отрицательная передача.
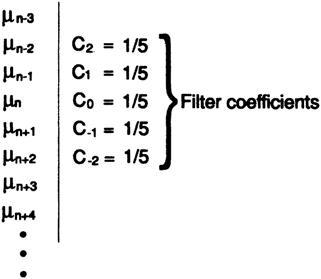
Рисунок 14.II
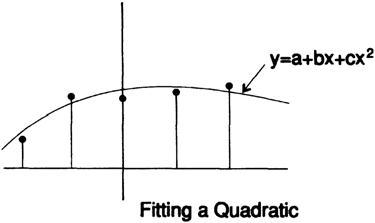
Рисунок 14.III
Если мы сейчас сместим эти полученные методом наименьших квадратов формулы сглаживания в правильное место для получения значения в точке n, то мы получим:
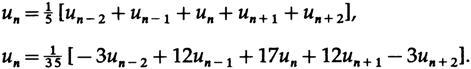
Теперь зададимся вопросом, ??что будет на выходе, если на входе мы поместим чистую собственную функцию. Мы знаем, что так как уравнения линейны, они должны возвращать собственную функцию, но умноженную на собственное значение соответствующее частоте собственной функции — значение передаточной функции на этой частоте. Взяв верхнюю часть двух формул, мы имеем
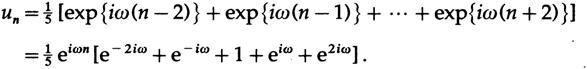
Применим элементарную тригонометрию и получим собственное значение на частоте ? (передаточную функцию):
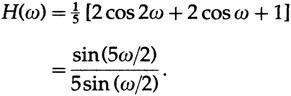
В случае параболического сглаживания мы получим:
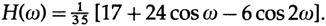
Эти передаточные характеристики для сглаживания 2к+1 значений легко зарисовать, рис. 14.IV.
Формулы сглаживания имеют центральную симметрию по своим коэффициентам, а дифференцирующие формулы имеют нечетную симметрию. Из очевидной формулы
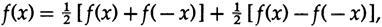
мы видим, что любая формула представляет собой сумму нечетной и четной функции, поэтому любой нерекурсивный цифровой фильтр представляет собой сумму сглаживающего фильтра и дифференцирующего фильтра. Когда мы справились с этими двумя особыми случаями, мы получили общий случай.
Для сглаживающих формул мы видим, что кривая собственных значений (передаточная функция) является разложением Фурье в косинусах, а для формулы дифференцирования — разложением в синусах. Таким образом мы пришли к тому, что задача получения желаемой дискретной передаточной характеристики сводится к задаче разложения ее непрерывного представления в ряд Фурье.
Теперь кратко переформулируем ряды Фурье. Если предположить, что произвольная функция f (t) представлена в виде

Используя условия ортогональности (их можно найти с помощью элементарной тригонометрии и простых интегрирований):
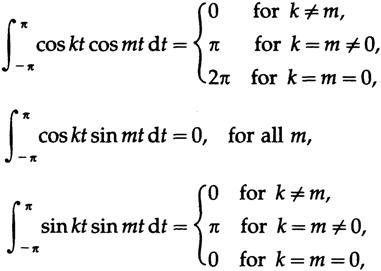
мы получаем
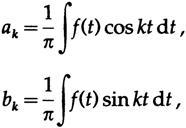
и так как мы использовали a0/2 в качестве первого коэффициента, та же формула для ak справедлива и для случая k= 0. В форме комплексных экспонент это, конечно, выглядит намного проще.
Далее нам нужно доказать, что приближение разложением по любому ортогональному множеству функций соответствует методу наименьших квадратов. Пусть множество ортогональных функций задано как {fk(t)} с весовой функцией w (t)?0. Ортогональность означает
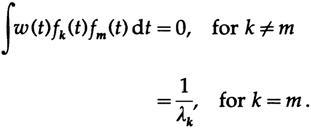
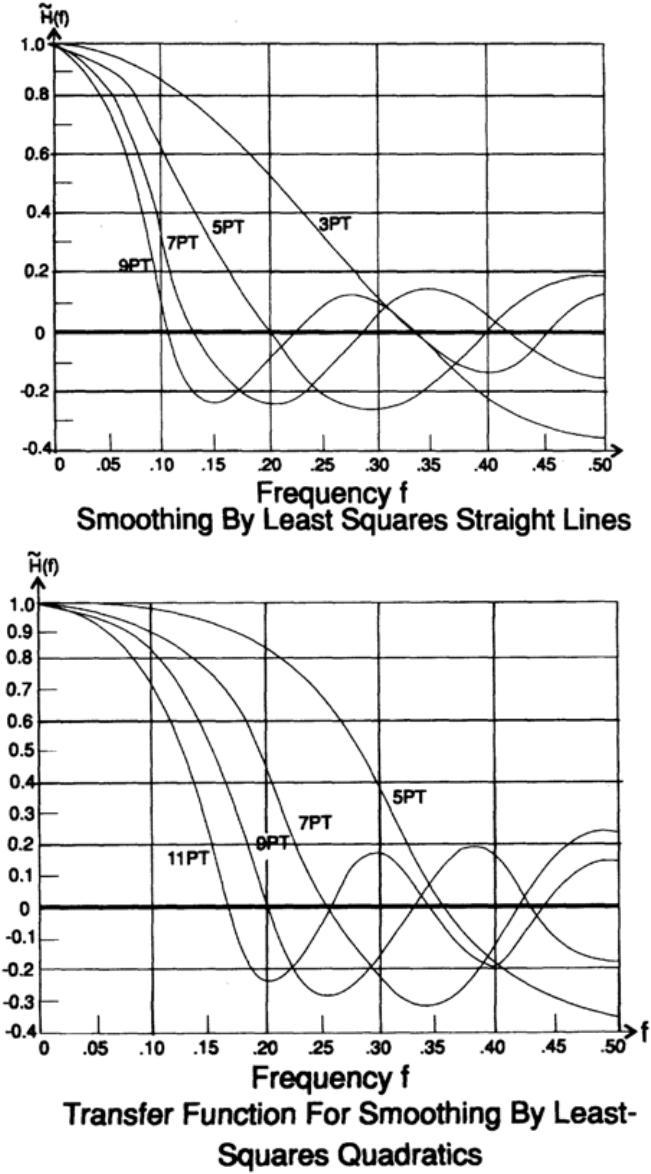
Рисунок 14.IV
Как и выше, обычное разложение даст коэффициенты
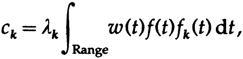
где
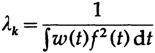
когда функции вещественны, в случае же комплексных функций мы умножаем на комплексно-сопряженную функцию.
Теперь рассмотрим аппроксимацию полным набором ортогональных функций с использованием коэффициентов Ck (заглавная C) с точки зрения метода наименьших квадратов. У нас есть
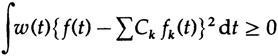
для минимизации. Дифференцируем по Cm и получаем
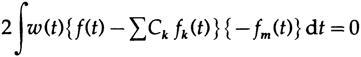
из перестановки можно заметить, что Ck=ck. Следовательно, приближение любым ортогональным набором функций является также приближением методом наименьших квдаратов.
Если мы продолжим наблюдать над неравенством полученным неравенством, то в общем случае мы получим неравенство Бесселя
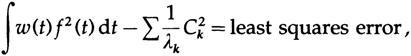
для числа коэффициентов, взятых для разложения в ряд. Это неравенство позволяет определить, достаточно ли вы взяли членов для аппроксимации разложением в конечный ряд. На практике оно зарекомендовало себя отличным ориентиром того, сколько членов разложения в ряд Фурье нужно использовать.
Продолжение следует...
Кто хочет помочь с переводом — пишите в личку или на почту magisterludi2016@yandex.ru
Кстати, мы еще запустили перевод еще одной крутейшей книги — «The Dream Machine: История компьютерной революции»)
Содержание книги и переведенные главы
Кто хочет помочь с переводом — пишите в личку или на почту magisterludi2016@yandex.ru
- Intro to The Art of Doing Science and Engineering: Learning to Learn (March 28, 1995) (в работе) Перевод: Глава 1
- «Foundations of the Digital (Discrete) Revolution» (March 30, 1995) Глава 2. Основы цифровой (дискретной) революции
- «History of Computers — Hardware» (March 31, 1995) Глава 3. История компьютеров — железо
- «History of Computers — Software» (April 4, 1995) Глава 4. История компьютеров — Софт
- «History of Computers — Applications» (April 6, 1995) Глава 5. История компьютеров — практическое применение
- «Artificial Intelligence — Part I» (April 7, 1995) (в работе)
- «Artificial Intelligence — Part II» (April 11, 1995) (в работе)
- «Artificial Intelligence III» (April 13, 1995) Глава 8. Искуственный интеллект-III
- «n-Dimensional Space» (April 14, 1995) Глава 9. N-мерное пространство
- «Coding Theory — The Representation of Information, Part I» (April 18, 1995) (в работе)
- «Coding Theory — The Representation of Information, Part II» (April 20, 1995)
- «Error-Correcting Codes» (April 21, 1995) (в работе)
- «Information Theory» (April 25, 1995) (в работе, Горгуров Алексей)
- «Digital Filters, Part I» (April 27, 1995) Глава 14. Цифровые фильтры — 1
- «Digital Filters, Part II» (April 28, 1995) в работе
- «Digital Filters, Part III» (May 2, 1995)
- «Digital Filters, Part IV» (May 4, 1995)
- «Simulation, Part I» (May 5, 1995) (в работе)
- «Simulation, Part II» (May 9, 1995) готово
- «Simulation, Part III» (May 11, 1995)
- «Fiber Optics» (May 12, 1995) в работе
- «Computer Aided Instruction» (May 16, 1995) (в работе)
- «Mathematics» (May 18, 1995) Глава 23. Математика
- «Quantum Mechanics» (May 19, 1995) Глава 24. Квантовая механика
- «Creativity» (May 23, 1995). Перевод: Глава 25. Креативность
- «Experts» (May 25, 1995) Глава 26. Эксперты
- «Unreliable Data» (May 26, 1995) (в работе)
- «Systems Engineering» (May 30, 1995) Глава 28. Системная Инженерия
- «You Get What You Measure» (June 1, 1995) Глава 29. Вы получаете то, что вы измеряете
- «How Do We Know What We Know» (June 2, 1995) в работе
- Hamming, «You and Your Research» (June 6, 1995). Перевод: Вы и ваша работа
Кто хочет помочь с переводом — пишите в личку или на почту magisterludi2016@yandex.ru
fido_max
А почему бы не на github'е перевод делать?