
Прим перев.: Автор оригинальной статьи — испанский Open Source-энтузиаст nachoparker, развивающий проект NextCloudPlus (ранее известен как NextCloudPi), — делится своими знаниями об устройстве дисковой подсистемы в Linux, делая важные уточнения в ответах на простые, казалось бы, вопросы…
Сколько пространства занимает этот файл на жёстком диске? Сколько свободного места у меня есть? Сколько ещё файлов я смогу вместить в оставшееся пространство?

Ответы на эти вопросы кажутся очевидными. У всех нас есть инстинктивное понимание работы файловых систем и зачастую мы представляем хранение файлов на диске аналогично заполнению корзины яблоками.
Однако в современных Linux-системах такая интуиция может вводить в заблуждение. Давайте разберёмся, почему.
Что такое размер файла? Ответ вроде бы прост: совокупность всех байтов его содержимого, от начала до конца файла.
Зачастую всё содержимое файла представляется как расположенное байт за байтом:

Так же мы воспринимаем и понятие размер файла. Чтобы его узнать, выполняем
В ядре Linux структурой памяти, представляющей файл, является inode. И метаданные, к которым мы обращаемся с помощью команды
Фрагмент
Здесь можно увидеть знакомые атрибуты, такие как время доступа и модификации, а также
Размышлять в терминах размера файла интуитивно понятно, но больше нас интересует, как в действительности используется пространство.
Для внутреннего хранения файла файловая система разбивает хранилище на блоки. Традиционным размером блока были 512 байт, но более актуальное значение — 4 килобайта. Вообще же при выборе этого значения руководствуются поддерживаемым размером страницы на типовом оборудовании MMU (memory management unit, «устройство управления памятью» — прим. перев.).
Файловая система вставляет порезанный на части (chunks) файл в эти блоки и следит за ними в метаданных. В идеале всё выглядит так:

… но в действительности файлы постоянно создаются, изменяются в размере, удаляются, поэтому реальная картина такова:
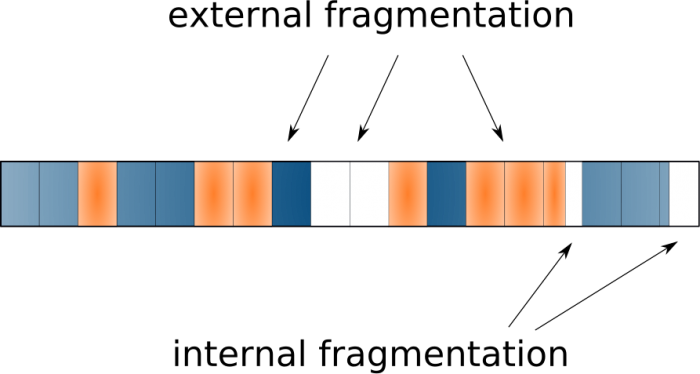
Это называется внешней фрагментацией (external fragmentation) и обычно приводит к падению производительности. Причина — вращающейся головке жёсткого диска приходится переходить с места на место, чтобы собрать все фрагменты, а это медленная операция. Решением данной проблемы занимаются классические инструменты дефрагментации.
Что происходит с файлами меньше 4 КБ? Что происходит с содержимым последнего блока после того, как файл был порезан на части? Естественным образом будет возникать неиспользуемое пространство — это называется внутренней фрагментацией (internal fragmentation). Очевидно, этот побочный эффект нежелателен и может привести к тому, что многое свободное пространство не будет использоваться, особенно если у нас большое количество очень маленьких файлов.
Итак, реальное использование диска файлом можно увидеть с помощью
Таким образом, мы смотрим на две величины: размер файла и использованные блоки. Мы привыкли думать в терминах первого, однако должны — в терминах последнего.
Помимо актуального содержимого файла ядру также необходимо хранить все виды метаданных. Метаданные inode'а мы уже видели, но есть и другие данные, с которыми знаком каждый пользователь UNIX: права доступа, владелец, uid, gid, флаги, ACL.
Наконец, существуют ещё и другие структуры — вроде суперблока (superblock) с представлением самой файловой системы, vfsmount с представлением точки монтирования, а также информация об избыточности, именные пространства и т.п. Как мы увидим далее, некоторые из этих метаданных также могут занимать значительное место.
Эти данные сильно зависят от используемой файловой системы — в каждой из них по-своему реализовано сопоставление блоков с файлами. Традиционный подход ext2 — таблица
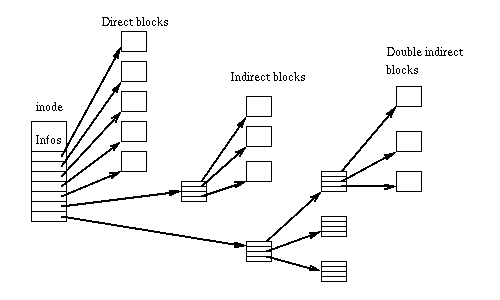
Эту же таблицу можно увидеть в структуре памяти (фрагмент из
Для больших файлов такая схема приводит к большим накладным расходам, поскольку единственный (большой) файл требует сопоставления тысяч блоков. Кроме того, есть ограничение на размер файла: используя такой метод, 32-битная файловая система ext3 поддерживает файлы не более 8 ТБ. Разработчики ext3 спасали ситуацию поддержкой 48 бит и добавлением extents:
Идея по-настоящему проста: занимать соседние блоки на диске и просто объявлять, где extent начинается и каков его размер. Таким образом мы можем выделять файлу большие группы блоков, минимизируя количество метаданных и заодно используя более быстрый последовательный доступ.
Примечание для любопытных: у ext4 предусмотрена обратная совместимость, то есть в ней поддерживаются оба метода: непрямой (indirect) и extents. Увидеть, как распределено пространство, можно на примере операции записи. Запись не идёт напрямую в хранилище — из соображений производительности данные сначала попадают в файловый кэш. После этого в определённый момент кэш записывает информацию на постоянное хранилище.
Кэш файловой системы представлен структурой
… где
Файловые системы последнего поколения хранят также контрольные суммы (checksums) для блоков данных во избежание незаметного повреждения данных. Эта возможность позволяет обнаруживать и корректировать случайные ошибки и, конечно, ведёт к дополнительным накладным расходам в использовании диска пропорционально размеру файлов.
Более современные системы вроде BTRFS и ZFS поддерживают контрольные суммы для данных, а у более старых, таких как ext4, реализованы контрольные суммы для метаданных.
Возможности журналирования для ext2 появились в ext3. Журнал — циклический лог, записывающий обрабатываемые транзакции с целью улучшить устойчивость к сбоям питания. По умолчанию он применяется только к метаданным, однако можно его активировать и для данных с помощью опции
Это специальный скрытый файл, обычно с номером inode 8 и размером 128 МБ, объяснение про который можно найти в официальной документации:
Возможность tail packing, ещё называемая блочным перераспределением (block suballocation), позволяет файловым системам использовать пустое пространство в конце последнего блока («хвосты») и распределять его среди различных файлов, эффективно упаковывая «хвосты» в единый блок.
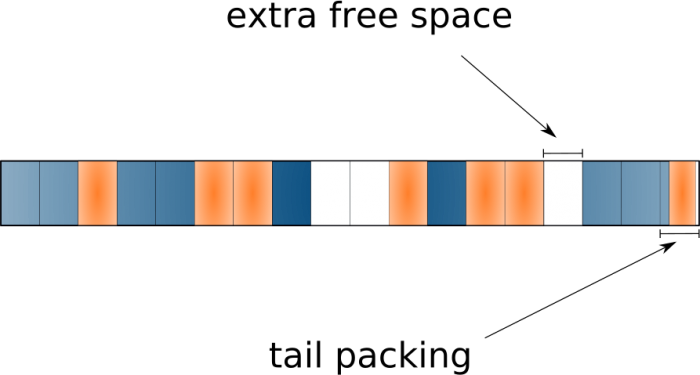
Замечательно иметь такую возможность, что позволяет сохранить много пространства, особенно если у вас большое количество маленьких файлов… Однако она приводит к тому, что существующие инструменты неточно сообщают об используемом пространстве. Потому что с ней мы не можем просто добавить все занятые блоки всех файлов для получения реальных данных по использованию диска. Эту фичу поддерживают файловые системы BTRFS и ReiserFS.
Большинство современных файловых систем поддерживают разрежённые файлы (sparse files). У таких файлов могут быть дыры, которые в действительности не записаны на диск (не занимают дисковое пространство). На этот раз реальный размер файла будет больше, чем используемые блоки.
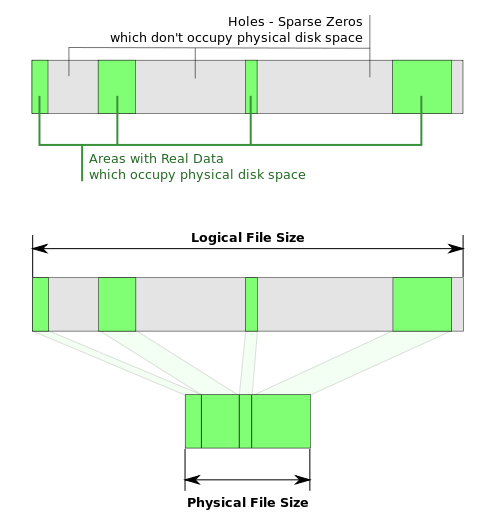
Такая особенность может оказаться очень полезной, например, для быстрой генерации больших файлов или для предоставления свободного пространства виртуальному жёсткому диску виртуальной машины по запросу.
Чтобы медленно создать 10-гигабайтный файл, который занимает около 10 ГБ дискового пространства, можно выполнить:
Чтобы создать такой же большой файл мгновенно, достаточно лишь записать последний байт… или даже сделать:
Или же воспользоваться командой
Дисковое пространство, выделенное файлу, можно изменить командой
Например, создать дыры в файле, превратив его в разрежённый, можно так:
Команда
… а обратное действие (сделать «плотную» копию разрежённого файла) выглядит так:
Таким образом, если вам нравится работать с разрежёнными файлами, можете добавить следующий алиас в окружение своего терминала (
Когда процессы читают байты в секциях дыр файловая система предоставляет им страницы с нулями. Например, можно посмотреть, что происходит, когда файловый кэш читает из файловой системы в области дыр в ext4. В этом случае последовательность в
После этого сегмент памяти, к которому процесс пытается обратиться с помощью системного вызова
Следующее (после семейства ext) поколение файловых систем принесло очень интересные возможности. Пожалуй, наибольшего внимания среди фич файловых систем вроде ZFS и BTRFS заслуживает их COW (copy-on-write, «копирование при записи»).
Когда мы выполняем операцию copy-on-write или клонирования, или копии reflink, или поверхностной (shallow) копии, на самом деле никакого дублирования extent'ов не происходит. Просто создаётся аннотация в метаданных для нового файла, которая отсылает к тем же самым extents оригинального файла, а сам extent помечается как разделяемый (shared). При этом в пользовательском пространстве создаётся иллюзия, что существуют два отдельных файла, которые можно отдельно модифицировать. Когда какой-то процесс захочет написать в разделяемый extent, ядро сначала создаст его копию и аннотацию, что этот extent принадлежит единственному файлу (по крайней мере, на данный момент). После этого у двух файлов появляется больше отличий, однако они все ещё могут разделять многие extents. Другими словами, extents в файловых системах с поддержкой COW можно делить между файлами, а ФС обеспечит создание новых extents только в случае необходимости.
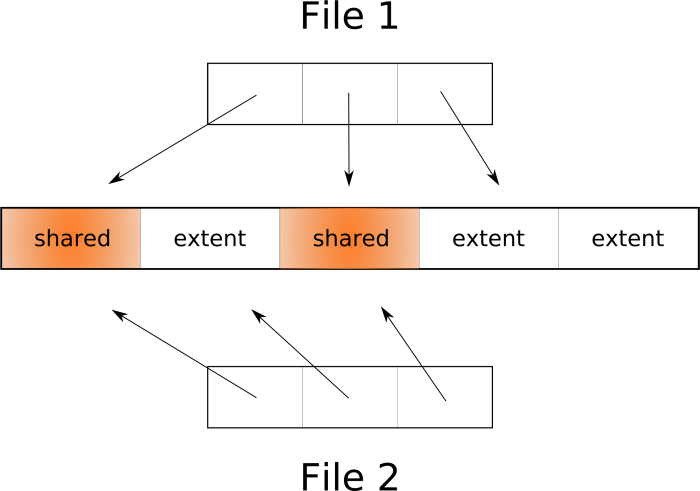
Как видно, клонирование — очень быстрая операция, не требующая удваивания пространства, которое используется в случае обычной копии. Именно эта технология и стоит за возможностью создания мгновенных снапшотов в BTRFS и ZFS. Вы можете буквально клонировать (или сделать снапшот) всей корневой файловой системы меньше чем за секунду. Очень полезно, например, перед обновлением пакетов на случай, если что-то сломается.
BTRFS поддерживает два метода создания shallow-копий. Первый относится к подтомам (subvolumes) и использует команду
Следующий шаг — если есть не-shallow-копии или файл, или даже файлы, с дублирующимися extents, можно дедуплицировать их, чтобы они использовали (через reflink) общие extents и освободили пространство. Один из инструментов для этого — duperemove, однако учтите, что это естественным образом приводит к более высокой фрагментации файлов.
Если мы попытаемся теперь разобраться, как дисковое пространство используется файлами, всё будет не так просто. Утилиты вроде
Аналогичным образом, в случае BTRFS стоит избегать команды
К сожалению, я не знаю простых способов отслеживания занятого пространства отдельными файлами в файловых системах с COW. На уровне подтома с помощью утилит вроде btrfs-du мы можем получить приблизительное представление о количестве данных, которые уникальны для снапшота и которые разделяются между снапшотами.
Читайте также в нашем блоге:
Сколько пространства занимает этот файл на жёстком диске? Сколько свободного места у меня есть? Сколько ещё файлов я смогу вместить в оставшееся пространство?
Ответы на эти вопросы кажутся очевидными. У всех нас есть инстинктивное понимание работы файловых систем и зачастую мы представляем хранение файлов на диске аналогично заполнению корзины яблоками.
Однако в современных Linux-системах такая интуиция может вводить в заблуждение. Давайте разберёмся, почему.
Размер файла
Что такое размер файла? Ответ вроде бы прост: совокупность всех байтов его содержимого, от начала до конца файла.
Зачастую всё содержимое файла представляется как расположенное байт за байтом:
Так же мы воспринимаем и понятие размер файла. Чтобы его узнать, выполняем
ls -l file.c или команду stat (т.е. stat file.c), которая делает системный вызов stat().В ядре Linux структурой памяти, представляющей файл, является inode. И метаданные, к которым мы обращаемся с помощью команды
stat, находятся именно в inode.Фрагмент
include/linux/fs.h:struct inode {
/* excluded content */
loff_t i_size; /* file size */
struct timespec i_atime; /* access time */
struct timespec i_mtime; /* modification time */
struct timespec i_ctime; /* change time */
unsigned short i_bytes; /* bytes used (for quota) */
unsigned int i_blkbits; /* block size = 1 << i_blkbits */
blkcnt_t i_blocks; /* number of blocks used */
/* excluded content */
}Здесь можно увидеть знакомые атрибуты, такие как время доступа и модификации, а также
i_size — это и есть размер файла, как он был определён выше.Размышлять в терминах размера файла интуитивно понятно, но больше нас интересует, как в действительности используется пространство.
Блоки и размер блока
Для внутреннего хранения файла файловая система разбивает хранилище на блоки. Традиционным размером блока были 512 байт, но более актуальное значение — 4 килобайта. Вообще же при выборе этого значения руководствуются поддерживаемым размером страницы на типовом оборудовании MMU (memory management unit, «устройство управления памятью» — прим. перев.).
Файловая система вставляет порезанный на части (chunks) файл в эти блоки и следит за ними в метаданных. В идеале всё выглядит так:
… но в действительности файлы постоянно создаются, изменяются в размере, удаляются, поэтому реальная картина такова:
Это называется внешней фрагментацией (external fragmentation) и обычно приводит к падению производительности. Причина — вращающейся головке жёсткого диска приходится переходить с места на место, чтобы собрать все фрагменты, а это медленная операция. Решением данной проблемы занимаются классические инструменты дефрагментации.
Что происходит с файлами меньше 4 КБ? Что происходит с содержимым последнего блока после того, как файл был порезан на части? Естественным образом будет возникать неиспользуемое пространство — это называется внутренней фрагментацией (internal fragmentation). Очевидно, этот побочный эффект нежелателен и может привести к тому, что многое свободное пространство не будет использоваться, особенно если у нас большое количество очень маленьких файлов.
Итак, реальное использование диска файлом можно увидеть с помощью
stat, ls -ls file.c или du file.c. Например, содержимое 1-байтового файла всё равно занимает 4 КБ дискового пространства:$ echo "" > file.c
$ ls -l file.c
-rw-r--r-- 1 nacho nacho 1 Apr 30 20:42 file.c
$ ls -ls file.c
4 -rw-r--r-- 1 nacho nacho 1 Apr 30 20:42 file.c
$ du file.c
4 file.c
$ dutree file.c
[ file.c 1 B ]
$ dutree -u file.c
[ file.c 4.00 KiB ]
$ stat file.c
File: file.c
Size: 1 Blocks: 8 IO Block: 4096 regular file
Device: 2fh/47d Inode: 2185244 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 1000/ nacho) Gid: ( 1000/ nacho)
Access: 2018-04-30 20:41:58.002124411 +0200
Modify: 2018-04-30 20:42:24.835458383 +0200
Change: 2018-04-30 20:42:24.835458383 +0200
Birth: -Таким образом, мы смотрим на две величины: размер файла и использованные блоки. Мы привыкли думать в терминах первого, однако должны — в терминах последнего.
Специфичные для файловой системы возможности
Помимо актуального содержимого файла ядру также необходимо хранить все виды метаданных. Метаданные inode'а мы уже видели, но есть и другие данные, с которыми знаком каждый пользователь UNIX: права доступа, владелец, uid, gid, флаги, ACL.
struct inode {
/* excluded content */
struct fown_struct f_owner;
umode_t i_mode;
unsigned short i_opflags;
kuid_t i_uid;
kgid_t i_gid;
unsigned int i_flags;
/* excluded content */
}Наконец, существуют ещё и другие структуры — вроде суперблока (superblock) с представлением самой файловой системы, vfsmount с представлением точки монтирования, а также информация об избыточности, именные пространства и т.п. Как мы увидим далее, некоторые из этих метаданных также могут занимать значительное место.
Метаданные размещения блоков
Эти данные сильно зависят от используемой файловой системы — в каждой из них по-своему реализовано сопоставление блоков с файлами. Традиционный подход ext2 — таблица
i_block с прямыми и непрямыми блоками (direct/indirect blocks).Эту же таблицу можно увидеть в структуре памяти (фрагмент из
fs/ext2/ext2.h):/*
* Structure of an inode on the disk
*/
struct ext2_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Creation time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks; /* Blocks count */
__le32 i_flags; /* File flags */
/* excluded content */
__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */
/* excluded content */
}Для больших файлов такая схема приводит к большим накладным расходам, поскольку единственный (большой) файл требует сопоставления тысяч блоков. Кроме того, есть ограничение на размер файла: используя такой метод, 32-битная файловая система ext3 поддерживает файлы не более 8 ТБ. Разработчики ext3 спасали ситуацию поддержкой 48 бит и добавлением extents:
struct ext3_extent {
__le32 ee_block; /* first logical block extent covers */
__le16 ee_len; /* number of blocks covered by extent */
__le16 ee_start_hi; /* high 16 bits of physical block */
__le32 ee_start; /* low 32 bits of physical block */
};Идея по-настоящему проста: занимать соседние блоки на диске и просто объявлять, где extent начинается и каков его размер. Таким образом мы можем выделять файлу большие группы блоков, минимизируя количество метаданных и заодно используя более быстрый последовательный доступ.
Примечание для любопытных: у ext4 предусмотрена обратная совместимость, то есть в ней поддерживаются оба метода: непрямой (indirect) и extents. Увидеть, как распределено пространство, можно на примере операции записи. Запись не идёт напрямую в хранилище — из соображений производительности данные сначала попадают в файловый кэш. После этого в определённый момент кэш записывает информацию на постоянное хранилище.
Кэш файловой системы представлен структурой
address_space, в которой вызывается операция writepages. Вся последовательность выглядит так:(cache writeback) ext4_aops-> ext4_writepages() -> ... -> ext4_map_blocks()… где
ext4_map_blocks() вызовет функцию ext4_ext_map_blocks() или ext4_ind_map_blocks() в зависимости от того, используются ли extents. Если взглянуть на первую в extents.c, можно увидеть упоминания дыр (holes), о которых будет рассказано ниже.Контрольные суммы
Файловые системы последнего поколения хранят также контрольные суммы (checksums) для блоков данных во избежание незаметного повреждения данных. Эта возможность позволяет обнаруживать и корректировать случайные ошибки и, конечно, ведёт к дополнительным накладным расходам в использовании диска пропорционально размеру файлов.
Более современные системы вроде BTRFS и ZFS поддерживают контрольные суммы для данных, а у более старых, таких как ext4, реализованы контрольные суммы для метаданных.
Журналирование
Возможности журналирования для ext2 появились в ext3. Журнал — циклический лог, записывающий обрабатываемые транзакции с целью улучшить устойчивость к сбоям питания. По умолчанию он применяется только к метаданным, однако можно его активировать и для данных с помощью опции
data=journal, что повлияет на производительность.Это специальный скрытый файл, обычно с номером inode 8 и размером 128 МБ, объяснение про который можно найти в официальной документации:
Журнал, представленный в файловой системе ext3, используется в ext4 для защиты ФС от повреждений в случае системных сбоев. Небольшой последовательный фрагмент диска (по умолчанию это 128 МБ) зарезервирован внутри ФС как место для сбрасывания «важных» операций записи на диск настолько быстро, насколько это возможно. Когда транзакция с важными данными полностью записана на диск и сброшена с кэша (disk write cache), запись о данных также записывается в журнал. Позже код журнала запишет транзакции в их конечные позиции на диске (операция может приводить к продолжительному поиску или большому числу операций чтения-удаления-стирания) перед тем, как запись об этих данных будет стёрта. В случае системного сбоя во время второй медленной операции записи журнал позволяет воспроизвести все операции вплоть до последней записи, гарантируя атомарность всего, что пишется на диск через журнал. Результатом является гарантия, что файловая система не застрянет на полпути обновления метаданных.
«Упаковка хвостов»
Возможность tail packing, ещё называемая блочным перераспределением (block suballocation), позволяет файловым системам использовать пустое пространство в конце последнего блока («хвосты») и распределять его среди различных файлов, эффективно упаковывая «хвосты» в единый блок.
Замечательно иметь такую возможность, что позволяет сохранить много пространства, особенно если у вас большое количество маленьких файлов… Однако она приводит к тому, что существующие инструменты неточно сообщают об используемом пространстве. Потому что с ней мы не можем просто добавить все занятые блоки всех файлов для получения реальных данных по использованию диска. Эту фичу поддерживают файловые системы BTRFS и ReiserFS.
Разрежённые файлы
Большинство современных файловых систем поддерживают разрежённые файлы (sparse files). У таких файлов могут быть дыры, которые в действительности не записаны на диск (не занимают дисковое пространство). На этот раз реальный размер файла будет больше, чем используемые блоки.
Такая особенность может оказаться очень полезной, например, для быстрой генерации больших файлов или для предоставления свободного пространства виртуальному жёсткому диску виртуальной машины по запросу.
Чтобы медленно создать 10-гигабайтный файл, который занимает около 10 ГБ дискового пространства, можно выполнить:
$ dd if=/dev/zero of=file bs=2M count=5120Чтобы создать такой же большой файл мгновенно, достаточно лишь записать последний байт… или даже сделать:
$ dd of=file-sparse bs=2M seek=5120 count=0Или же воспользоваться командой
truncate:$ truncate -s 10GДисковое пространство, выделенное файлу, можно изменить командой
fallocate, которая делает системный вызов fallocate(). С этим вызовом доступны и более продвинутые операции — например:- Предварительно выделить пространство для файла вставкой нулей. Такая операция увеличивает и использование дискового пространства, и размер файла.
- Освободить пространство. Операция создаст дыру в файле, делая его разрежённым и уменьшая использование пространства без влияния на размер файла.
- Оптимизировать пространство, уменьшив размер файла и использование диска.
- Увеличить пространство файла, вставив дыру в его конец. Размер файла увеличивается, а использование диска не меняется.
- Обнулить дыры. Дыры станут не записанными на диск extents, которые будут читаться как нули, не влияя на дисковое пространство и его использование.
Например, создать дыры в файле, превратив его в разрежённый, можно так:
$ fallocate -d fileКоманда
cp поддерживает работу с разрежёнными файлами. С помощью простой эвристики она пытается определить, является ли исходный файл разрежённым: если это так, то результирующий файл тоже будет разрежённым. Скопировать же неразрежённый файл в разрежённый можно так:$ cp --sparse=always file file_sparse… а обратное действие (сделать «плотную» копию разрежённого файла) выглядит так:
$ cp --sparse=never file_sparse fileТаким образом, если вам нравится работать с разрежёнными файлами, можете добавить следующий алиас в окружение своего терминала (
~/.zshrc или ~/.bashrc):alias cp='cp --sparse=always'Когда процессы читают байты в секциях дыр файловая система предоставляет им страницы с нулями. Например, можно посмотреть, что происходит, когда файловый кэш читает из файловой системы в области дыр в ext4. В этом случае последовательность в
readpage.c будет выглядеть примерно так:(cache read miss) ext4_aops-> ext4_readpages() -> ... -> zero_user_segment()После этого сегмент памяти, к которому процесс пытается обратиться с помощью системного вызова
read(), получит нули напрямую из быстрой памяти.Файловые системы COW (copy-on-write)
Следующее (после семейства ext) поколение файловых систем принесло очень интересные возможности. Пожалуй, наибольшего внимания среди фич файловых систем вроде ZFS и BTRFS заслуживает их COW (copy-on-write, «копирование при записи»).
Когда мы выполняем операцию copy-on-write или клонирования, или копии reflink, или поверхностной (shallow) копии, на самом деле никакого дублирования extent'ов не происходит. Просто создаётся аннотация в метаданных для нового файла, которая отсылает к тем же самым extents оригинального файла, а сам extent помечается как разделяемый (shared). При этом в пользовательском пространстве создаётся иллюзия, что существуют два отдельных файла, которые можно отдельно модифицировать. Когда какой-то процесс захочет написать в разделяемый extent, ядро сначала создаст его копию и аннотацию, что этот extent принадлежит единственному файлу (по крайней мере, на данный момент). После этого у двух файлов появляется больше отличий, однако они все ещё могут разделять многие extents. Другими словами, extents в файловых системах с поддержкой COW можно делить между файлами, а ФС обеспечит создание новых extents только в случае необходимости.
Как видно, клонирование — очень быстрая операция, не требующая удваивания пространства, которое используется в случае обычной копии. Именно эта технология и стоит за возможностью создания мгновенных снапшотов в BTRFS и ZFS. Вы можете буквально клонировать (или сделать снапшот) всей корневой файловой системы меньше чем за секунду. Очень полезно, например, перед обновлением пакетов на случай, если что-то сломается.
BTRFS поддерживает два метода создания shallow-копий. Первый относится к подтомам (subvolumes) и использует команду
btrfs subvolume snapshot. Второй — к отдельным файлам и использует cp --reflink. Такой алиас (опять же, для ~/.zshrc или ~/.bashrc) может пригодиться, если вы хотите по умолчанию делать быстрые shallow-копии:cp='cp --reflink=auto --sparse=always'Следующий шаг — если есть не-shallow-копии или файл, или даже файлы, с дублирующимися extents, можно дедуплицировать их, чтобы они использовали (через reflink) общие extents и освободили пространство. Один из инструментов для этого — duperemove, однако учтите, что это естественным образом приводит к более высокой фрагментации файлов.
Если мы попытаемся теперь разобраться, как дисковое пространство используется файлами, всё будет не так просто. Утилиты вроде
du или dutree всего лишь считают используемые блоки, не учитывая, что некоторые из них могут быть разделяемыми, поэтому они покажут больше занятого места, чем на самом деле используется.Аналогичным образом, в случае BTRFS стоит избегать команды
df, поскольку пространство, занятое файловой системой BTRFS, она покажет как свободное. Лучше пользоваться btrfs filesystem usage:$ sudo btrfs filesystem usage /media/disk1
Overall:
Device size: 2.64TiB
Device allocated: 1.34TiB
Device unallocated: 1.29TiB
Device missing: 0.00B
Used: 1.27TiB
Free (estimated): 1.36TiB (min: 731.10GiB)
Data ratio: 1.00
Metadata ratio: 2.00
Global reserve: 512.00MiB (used: 0.00B)
Data,single: Size:1.33TiB, Used:1.26TiB
/dev/sdb2 1.33TiB
Metadata,DUP: Size:6.00GiB, Used:3.48GiB
/dev/sdb2 12.00GiB
System,DUP: Size:8.00MiB, Used:192.00KiB
/dev/sdb2 16.00MiB
Unallocated:
/dev/sdb2 1.29TiB
$ sudo btrfs filesystem usage /media/disk1
Overall:
Device size: 2.64TiB
Device allocated: 1.34TiB
Device unallocated: 1.29TiB
Device missing: 0.00B
Used: 1.27TiB
Free (estimated): 1.36TiB (min: 731.10GiB)
Data ratio: 1.00
Metadata ratio: 2.00
Global reserve: 512.00MiB (used: 0.00B)
Data,single: Size:1.33TiB, Used:1.26TiB
/dev/sdb2 1.33TiB
Metadata,DUP: Size:6.00GiB, Used:3.48GiB
/dev/sdb2 12.00GiB
System,DUP: Size:8.00MiB, Used:192.00KiB
/dev/sdb2 16.00MiB
Unallocated:
/dev/sdb2 1.29TiBК сожалению, я не знаю простых способов отслеживания занятого пространства отдельными файлами в файловых системах с COW. На уровне подтома с помощью утилит вроде btrfs-du мы можем получить приблизительное представление о количестве данных, которые уникальны для снапшота и которые разделяются между снапшотами.
Ссылки
P.S. от переводчика
Читайте также в нашем блоге:
Комментарии (13)

mwambanatanga
10.05.2018 12:25> Понимая, как используется дисковое пространство в Linux
Деепричастие в заголовке выглядит дико.scarab
10.05.2018 14:50Думается, это калька с английского Understanding…, так многие книги/статьи начинаются.
shurup
10.05.2018 15:29Всё относительно. Даже среди рекламных слоганов есть популярная разновидность с деепричастием в начале («Управляя мечтой» и т.п.). Можно просто опустить глагол, оставив вопросительную форму, но это просто дело вкуса, а не дикости.
DeadikGudwin
Что за тулза на первом изображении? В самом посте не увидел(
vesper-bot
В заголовке написано dutree. Не знаю, может и есть у неё более красивый вывод на консоль, помимо простого дампа текста.
Samouvazhektra
https://github.com/nachoparker/dutree
polearnik
на самом скрине вверху написано. dutree. судя по скринам в гугле это как раз та самая прога