
Предисловие
Изучать что-то новое всегда интересно, это захватывает тебя полностью, по крайней мере у меня так. Вот и в этот раз, увлёкшись изучением программирования на языке Python, задался вопросом, где его можно применить, кроме как при создании фотосепаратора (статья про него будет чуть позже) и программы учета продаж, и натолкнулся на статью про большие данные (Big Data). Изучив материалы по Big Data, понял, что направление это весьма перспективно и стоит потратить время на его изучение.
После этого приступил к изучению невообразимого количество статей и просмотрев пару десятков обучающих видео роликов достиг точки, в которой новая информация категорически не воспринималась, требовалось использование полученных навыков и знаний на практике. Конечно в сети есть готовые наборы данных, где тебе полностью разжуют что и как делать, но по мне удовольствия от такого занятия мало, хотя знания и опыт безусловно получишь. Но, если начать путь с нуля, т.е. со сбора данных (привет Web scrapping) до структурирования полученных данных для последующего анализа, думаю это более полезно с точки зрения обучения и практического применения.
Начало пути
Начался поиск подходящего кандидата (т.е. сайта). После недолгих поисков остановился на Market, OLX, Kolesa и Krisha. Дальнейшим критерием для отбора сайта было практическое применение результатов, полученных в ходе анализа.
Под этот критерий подходил только один сайт Krisha.kz. Cайт Krisha.kz является популярным сайтом, где люди со всего Казахстана подают объявления по продаже, покупке или аренде квартир, домов и офисов, и на этом сайте самое большое количество объявлений. Бегло изучив объявления на сайте, решил сконцентрироваться на объявлениях по продаже квартир в городе Астана с целью определения следующего:
- Проблемные дома, признак — количество объявлений превышает среднее количество объявлений на дом;
- Успешные риэлтерские компании, признак — количество опубликованных объявлений;
- Скрытые предприниматели, которые перепродают квартиры. Думаю, это было бы полезным для налоговых органов;
- Недобросовестные риелторы, которые используют чужие фотографии квартир для привлечения клиентов. Скажу сразу, пришлось отказаться от этой идеи, ввиду ограниченности ресурсов, так как пришлось бы хранить у себя огромное количество фотографий, а я располагаю только ноутбуком и домашним интернетом.
Сбор информации
Определив основные направления анализа, приступил к сбору информации при помощи Web scrapping. Так как ранее не сталкивался с задачей по сбору данных с сайта, обратился к незаменимому помощнику — Google.com. Для языка программирования Python предлагается куча разных библиотек — BeutifulSoup, Urllib, Selenium и т.д., но в какой-то статье на Habrahabr или github (полезные сайты для русскоговорящих, занимающихся программированием) наткнулся на рекомендацию, что для Web Scrapping лучше подойдет Selenium. Благо установка библиотек на Python до удивления проста и заключается в наборе команд на командной строке “pip install selenium” и все, библиотека установлена.
После двух дней танцев с бубнами и поисков в гугле, удалось создать скрипт, который собирал объявления, где отражаются: дата объявления, цена квартиры, количество комнат, адрес дома, этаж, кто подал объявление (хозяин или агентство), описательная часть (тип ремонта, наименование жилого комплекса) и количество просмотров.
Этой информации было достаточно для задач 1 и 2, но для задачи 3 требовался номер телефона, который можно получить, только если открыть объявление и нажать на кнопку “Показать телефон”, что усложняло задачу. Эта проблема была решена с помощью просмотра дополнительного материала в инете и документации selenium.
Время, необходимое для сбора информации
Если собирать только основную информацию, без номера телефона (порядка 23 000 — 27 000 объявлений только по г. Астана), то это занимает от 1 до 2 часов в зависимости от скорости интернет провайдера, а вот с получением номера телефона требуется куда больше времени — от 24 часов.
Запуск скрипта заключался в сборе информации с основной страницы и открытии отдельной вкладки для каждого объявления квартиры, при этом пока не будут открыты и получены номера телефонов со всех объявлений на текущий странице, переключения на следующую страницу не происходило. После десятков запусков скрипта, программа зачастую экстренно закрывалась и приходилось начинать поиск сначала. В связи с этим назрела необходимость разделения этапа сбора информации на два подэтапа:
- Сбор информации без номера телефона, но где указывается отдельная ссылка на объявление.
- Получение номера телефона по ссылке на объявление, полученного на первом этапе.
После всех этих работ получаем excel файл следующего содержания:

Как видно, имеем не структурированные данные. Далее для анализа требуется структурировать данные таким образом, чтобы каждый столбец содержал только одну информацию:
- столбец “RSS” необходимо разбить на 4 столбца: количество комнат, площадь квартиры, этаж квартиры, этажность дома;
- столбец “Advertiser” разбить на: кто подал объявление, и если это агентство, то указать название агентства;
- столбец Street: убрать лишнюю информацию о пересечении улиц и обработать таким образом, чтобы получить 2 столбца: название улицы и номер дома
- столбец “Description” выделить отдельные столбцы для: года постройки, района и названия жилого комплекса.
Анализ
Обзор объявлений
Имея более структурированную информацию, переходим к анализу данных. Вначале определяем основные лица, подающие объявления на сайте. Ниже представлена диаграмма по объявлениям с 14 апр. по 19 апр. 2018 г.
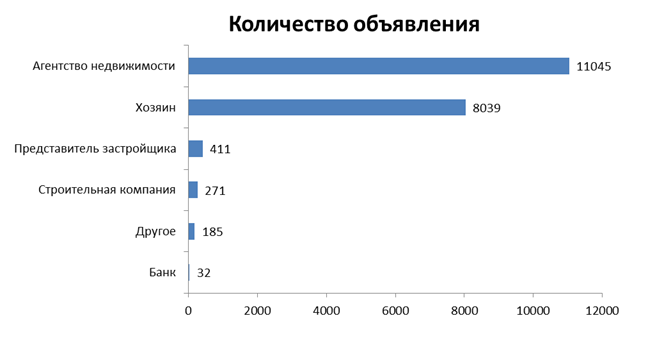
До этого анализа я предполагал, что объявления подают только риэлтерские агентства и владельцы квартир, но не ожидал присутствия на сайте представителей застройщиков и строительных компаний, хотя их доля составляет менее 4% от всех объявлении.
Интересно, что даже банки начали подавать объявления на сайте. Видимо, реализуют залоговые квартиры.
Более половины объявлений – от риэлтерских агентств. Так как в основной массе они дублируют объявления владельцев квартир, уже представленных на сайте, то в целях дальнейшего анализа эти данные будут исключены. Однако, эта информация будет использована для определения успешного риэлтерского агентства на основе количества объявлений.
Проблемные дома
Для определения проблемного дома необходимо определить соотношение количества объявлений по дому к количеству квартир в доме или в ЖК, и сравнить это соотношение со средним показателем по рынку. Но, если данные по количеству объявлений по продаже квартир в конкретном доме доступны в нашей базе, то общее количество квартир в доме надо искать на других сайтах. Данная работа требует дополнительного времени, поэтому пришлось отложить эту работу на потом, в связи с отсутствием времени.
Риэлтерские агентства
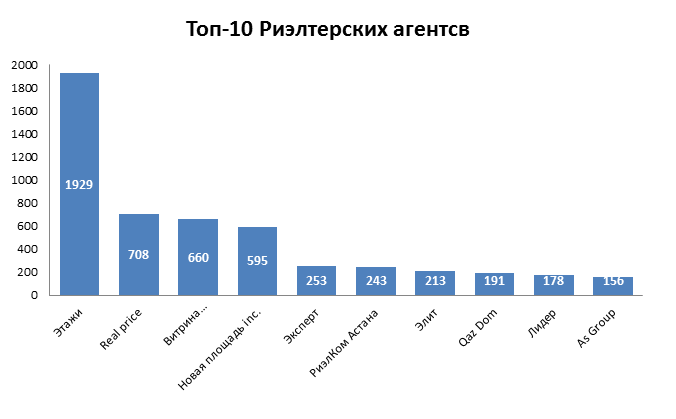
Эта гистограмма отражает количество поданных объявлений по продаже квартир риэлтерскими агентствами в период с 14 апр по 19 апр 2018 г.
Больше всего объявлений опубликовано от риэлтерского агентства “Этаж”, за указанный период количество объявлений составило — 1 929. Далее по убыванию количества объявлений идут такие риэлтерские агентства как “Real Price ”, “Витрина”, ”Новая площадь Inc.”, у них более 500 объявлений.
Если допустить, что критерием успешности на рынке недвижимости в сфере риэлтерских услуг является количество подданных объявлений (чем больше объявлений, тем больше шансов, что клиент их увидит и обратится в агентство), то бесспорный лидер — риэлтерское агентство «Этаж» .
Риэлторы или скрытые предприниматели?
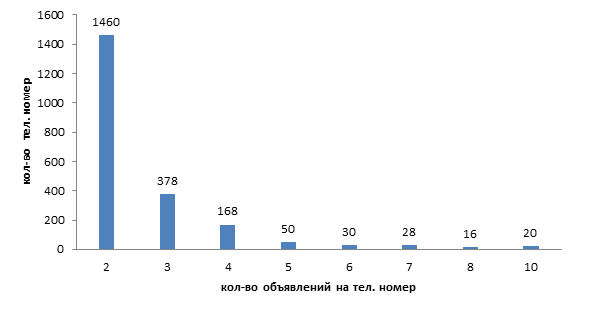
На этой гистограмме показано количество объявлений, опубликованных с одного номера телефона. Так на первом столбце с цифрой “2” показано, что более 1460 человек подали более 2 объявлений на сайте.
Многие риэлторы, зная про негативное отношение к ним, зачастую подают рекламу как владельцы, о чем может свидетельствовать количество и частота таких объявлений.
Если бы я был налоговым органом, то сначала определил бы ИНН владельцев номеров, проверил бы по базе сколько имущества на него было зарегистрировано и средний срок владения имуществом, если срок владения меньше 1-2 лет или он в течение короткого времени часто покупает и продает квартиры по одной и той же цене (то есть якобы без экономической выгоды), то необходимо более пристально приглядеться к данному владельцу.
Вывод
Необходимо отметить, что в данной статье анализ данных был поверхностным, и я больше стремился понять с какими сложностями и подводными камнями можно столкнуться при получении и обработке данных, например:
- Недостаточность информации для достижения изначальных целей, как к примеру в случае с идентификацией проблемных домов.
- Ограниченное время.
- Необходимо точно определить задачу и следовать ей. Во время проведения этого анализа приходилось бороться с безудержным желанием рассмотреть все со всех сторон, и в конечном итоге в голове проходила своеобразная борьба идей.
Каждый рассмотренный вопрос можно рассмотреть еще более детально, к примеру, те же проблемные дома определять не по количеству объявлений, а по частоте их подачи, но это оставим для более пытливых и имеющих свободное время людей.
Комментарии (8)

remzalp
28.05.2018 06:36Очередная история "как я не осилил эмуляцию AJAX и привинтил имитатор браузера"?
https://krisha.kz/a/ajaxPhones?id=$ID$
В заголовках:
cookie: ... referer: https://krisha.kz/a/show/$ID$ x-requested-with: XMLHttpRequest
Я только что сэкономил Вам больше 100 мегабайт на каждый поток
faiwer
28.05.2018 08:05Прочитав заголовок я подумал, что в Колёса-Крыша-Маркет решили поделиться тем, как они
big-data готовят. А увидел… Это правда называется BigData? Просто сграбить Selenium-ом страницы объявлений и подвести простейшую статистику?
SSSerg
28.05.2018 10:23Интересно. За Казахстан + )
Хочу попробовать что-то такое же, но с использованием BeautifulSoup
xmaster83
28.05.2018 11:53Я раньше тоже ресурсы серверов насиловал по 50 селениумов многопоточности, а потом перебрался на более лёгкие решения celery + request + beutifulsoup + regular и получил прирост в сотни раз по кпд
5erg
28.05.2018 13:43«Проблемные дома, признак — количество объявлений превышает среднее количество объявлений на дом;»
очень интересная бигдата у вас. следуя логике, 12-подъездный дом на 400 квартир должен аннигилировать через фемтосекунду? А двух этажные бараки на 8 квартир — образец благополучия
Mogost
По правде говоря, даже если собрать все данные по всем объявлениям на krisha, едва ли объем тянет на «Big Data». А время загрузки данных можно значительно ускорить, запустив селениум в несколько потоков.
sshikov
По правде говоря, даже если собрать все объявления скажем по России, уникальных в любом случае будет всего-лишь десятки или сотни миллионов, или примерно сотни гигабайт. Просто потому, что у нас населения порядка 150 миллионов, и совершенно не от куда взяться хотя бы по одной квартире или офису на каждого жителя. Bigdata тут относительная, но интересных задач в области ML тут можно нарыть множество. Причем задач вполне продающихся.