
В этой статье речь пойдёт о некоторых алгоритмах поиска и описания особых точек изображений. Здесь эта тема уже поднималась, и не раз. Буду считать, что основные определения читателю уже знакомы, рассмотрим детально эвристические алгоритмы FAST, FAST-9, FAST-ER, BRIEF, rBRIEF, ORB, обсудим искромётные идеи, лежащие в их основе. Частично это будет вольный перевод сути нескольких статей [1,2,3,4,5], будет немного кода для «попробовать».

FAST, впервые предложенный в 2005 году в работе [1], был одним из первых эвристических методов поиска особых точек, который завоевал большую популярность из-за своей вычислительной эффективности. Для принятия решения о том, считать заданную точку С особой или нет, в этом методе рассматривается яркость пикселов на окружности с центром в точке С и радиусом 3:

Сравнивая яркости пикселов окружности с яркостью центра C, получаем для каждого три возможных исхода (светлее, темнее, похоже):
Здесь I – яркость пикселов, t – некоторый заранее фиксированный порог по яркости.
Точка помечается как особая, если на круге существует подряд n=12 пикселов, которые темнее, или 12 пикселов, которые светлее, чем центр.
Как показала практика, в среднем для принятия решения нужно было проверить около 9 точек. Для того, чтобы ускорить процесс, авторы предложили сначала проверить только четыре пиксела под номерами: 1, 5, 9, 13. Если среди них есть 3 пиксела светлее или темнее, то выполняется полная проверка по 16 точкам, иначе – точка сразу помечается как «не особая». Это сильно сокращает время работы, для принятия решения в среднем достаточно опросить всего лишь около 4 точек окружности.
Немного наивного кода лежит тут
Изменяемые параметры (описаны в коде): радиус окружности (приимает значения 1,2,3), параметр n (в оригинале n=12), параметр t. Код открывает файл in.bmp, обрабатывает картинку, сохраняет в out.bmp. Картинки обычные 24-битные.
В 2006 году в работе [2] удалось развить оригинальную идею с использованием машинного обучения и деревьев решений.
У оригинального FAST есть следующие недостатки:
Вместо использования каскада из двух тестов из 4 и 16 точек предлагается всё делать за один проход по дереву решений. Аналогично оригинальному методу будем сравнивать яркость центральной точки с точками на окружности, но в таком порядке, чтобы принять решение как можно быстрее. И оказывается, что можно принимать решение всего лишь за ~2 (!!!) сравнения в среднем.
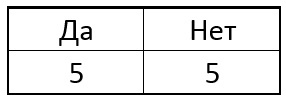
Самая соль в том, как найти нужный порядок для сравнения точек. Найти при помощи машинного обучения. Предположим, кто-то отметил для нас на картинке множество особых точек. Будем использовать их как набор обучающих примеров и идея состоит в том, чтобы в качестве следующей точки жадно выбирать такую, которая даст наибольшее число информации на данном шаге. Например, пусть изначально в нашей выборке было 5 особых точек и 5 НЕособых точек. В виде таблички вот так:
Выберем теперь один из пикселов р окружности и для всех особых точек проведём сравнение центрального пиксела с выбранным. В зависимости от яркости выбранного пиксела около каждой особой точки, в таблице может быть такой результат:
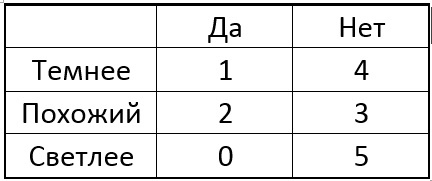
Идея в том, чтобы выбрать такую точку p, чтобы цифры в столбцах таблицы максимально отличались. И если теперь для новой неизвестной точки мы получим результат сравнения «Светлее», то уже можем сразу сказать, что точка «не особая» (см. таблицу). Процесс продолжается рекурсивно до тех пор, пока в каждую группу после разделения на «темнее-похожий-светлее» не будут попадать точки только одного из классов. Получается дерево следующего вида:
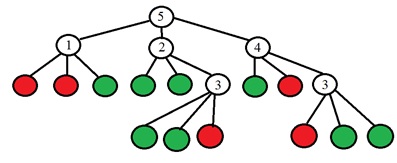
В листьях дерева находится бинарное значение (красный – особая, зелёный – не особая), а в остальных вершинах дерева находится номер точки, которую нужно анализировать. Более конкретно, в оригинальной статье предлагают делать выбор номера точки по изменению энтропии. Энтропия множества точек вычисляется:
с – число особых точек, – число не особых точек множества
Изменение энтропии после обработки точки p:
Соответственно, выбирается точка, для которой изменение энтропии будет максимально. Процесс разбиения прекращается, когда энтропия равна нулю, это означает, что все точки либо особые, либо наоборот – все не особые. При программной реализации после всего этого найденное дерево решений преобразуется в набор конструкций типа «if-else».
Последним этапом алгоритма является операция подавления немаксимумов, чтобы получить из нескольких рядом расположенных точек одну. Разработчики предлагают использовать оригинальную меру на основе суммы абсолютных разностей между центральной точкой и точками окружности в таком виде:
Здесь и соответственно группы пикселов светлее и темнее, t – пороговое значение яркости, – яркость центрального пиксела, – яркость пиксела на круге. Попробовать алгоритм можно следующим кодом. Код взят из OpenCV и освобождён от всех зависимостей, просто запускайте.
FAST-ER [3] – алгоритм тех же авторов, что и предыдущий, аналогично строится быстрый детектор, тоже ищется оптимальная последовательность точек для сравнения, тоже строится дерево решений, но другим методом – методом оптимизации.
Мы уже понимаем, что детектор можно представить в виде дерева решений. Если бы у нас был какой-нибудь критерий для сравнения производительности разных деревьев, то можно максимизировать этот критерий, перебирая разные варианты деревьев. И вот в качестве такого критерия предложено использовать «Повторяемость».
Повторяемость показывает, насколько хорошо особые точки сцены детектируются с разных ракурсов. Для пары картинок точка называется «полезной» (useful), если найдена на одном кадре и теоретически может быть найдена на другом, т.е. не загораживается элементами сцены. И точка называется «повторяемой» (repeated), если она найдена на втором кадре тоже. Поскольку оптика камеры неидеальна, то точка на втором кадре может находиться не в расчётном пикселе, а где-то рядом в его окрестности. Разработчики взяли окрестность в 5 пикселов. Определим повторяемость как отношение числа повторяемых точек к числу полезных:
Для поиска наилучшего детектора используется метод имитации отжига. На Хабре уже есть прекрасная статья про него. Кратко, суть метода в следующем:
Кроме этого, в построении детектора теперь участвуют не 16 точек окружности, как раньше, а 47, но смысл от этого совершенно не меняется:

Согласно методу имитации отжига, определим три функции:
• Функцию стоимости k. В нашем случае в качестве стоимости мы используем повторяемость. Но тут есть одна проблема. Представим, что все точки на каждом из двух изображений детектированы как особые. Тогда получается, что повторяемость равна 100 % – абсурд. С другой стороны, пусть у нас на двух картинках найдено по одной особой точке, и эти точки совпали – повторяемость также 100 %, но это тоже нас не интересует. И поэтому авторы предложили в качестве критерия качества использовать такой:
r – повторяемость, – число детектированных углов на кадре i, N – число кадров и s – размер дерева (число вершин). W – настраиваемые параметры метода.]
• Функцию изменения температуры со временем:
где – коэффициенты, Imax – число итераций.
• Функцию, порождающую новое решение. Алгоритм делает случайные модификации дерева. Сначала выбирается некоторая вершина. Если выбранная вершина это лист дерева, то с равной вероятностью делаем следующее:
Если это НЕ лист:
Вероятность P принятия изменения на итерации I это:
k – функция стоимости, T – температура, i – номер итерации.
Эти модификации к дереву позволяют как рост дерева, так и его сокращение. Метод случайный, он не гарантирует, что получится наилучшее дерево. Запускают метод много раз, выбирая наилучшее решение. В оригинальной статье, например, запускают 100 раз на 100000 итераций каждый, что занимает 200 часов времени процессора. Как показывают результаты, получается в итоге лучше, чем Tree FAST, особенно на зашумлённых картинках.
После того, как особые точки найдены, вычисляют их дескрипторы, т.е. наборы признаков, характеризующие окрестность каждой особой точки. BRIEF [4] – быстрый эвристический дескриптор, строится из 256 бинарных сравнений между яркостями пикселов на размытом изображении. Бинарный тест между точками х и у определяется так:

В оригинальной статье было рассмотрено несколько способов выбора точек для бинарных сравнений. Как оказалось, один из лучших способов – выбирать точки случайным образом Гауссовским распределением вокруг центрального пиксела. Эта случайная последовательность точек выбирается один раз и в дальнейшем не меняется. Размер рассматриваемой окрестности точки равен 31х31 пиксел, а апертура размытия равна 5.
Полученный бинарный дескриптор оказывается устойчив к сменам освещения, перспективному искажению, быстро вычисляется и сравнивается, но очень неустойчив к вращению в плоскости изображения.
Развитием всех этих идей стал алгоритм ORB (Oriented FAST and Rotated BRIEF) [5], в котором сделана попытка улучшить производительноть BRIEF при повороте изображения. Предложено сначала вычислять ориентацию особой точки и затем проводить бинарные сравнения уже в соответствие с этой ориентацией. Работает алгоритм так:
1) Особые точки обнаруживаются при помощи быстрого древовидного FAST на исходном изображении и на нескольких изображениях из пирамиды уменьшенных изображений.
2) Для обнаруженных точек вычисляется мера Харриса, кандидаты с низким значением меры Харриса отбрасываются.
3) Вычисляется угол ориентации особой точки. Для этого, сначала вычисляются моменты яркости для окрестности особой точки:
x,y – пиксельные координаты, I – яркость. И затем угол ориентации особой точки:
Всё это авторы назвали «центроид ориентации». В итоге получаем некоторое направление для окрестности особой точки.
4) Имея угол ориентации особой точки, последовательность точек для бинарных сравнений в дескрипторе BRIEF поворачивается в соответствие с этим углом, например:
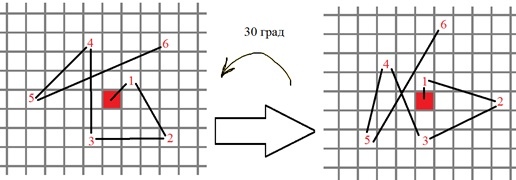
Если более формально, новые положения для точек бинарных тестов вычисляются так:
5) По полученным точкам вычисляется бинарный дескриптор BRIEF
И на этом… не всё! Есть в ORB ещё одна интересная деталь, которая требует отдельных пояснений. Дело в том, что в тот момент, когда мы «доворачиваем» все особые точки до нулевого угла, случайный выбор бинарных сравнений в дескрипторе перестаёт быть случайным. Это приводит к тому, что, во-первых, некоторые бинарные сравнения оказываются зависимыми между собой, во-вторых, их среднее уже не равно 0.5 (1 – светлее, 0 – темнее, когда выбор был случайным, то в среднем было 0.5) и всё это существенно уменьшает способность дескриптора различать особые точки между собой.
Решение — нужно выбрать «правильные» бинарные тесты в процессе обучения, эта идея веет тем же ароматом, что и обучение дерева для алгоритма FAST-9. Предположим, у нас есть куча уже найденных особых точек. Рассмотрим все возможные варианты бинарных тестов. Если окрестность 31 х 31, а бинарный тест представляет собой пару подмножеств 5 х 5 (из-за размытия), то всего вариантов выбора N=(31-5)^2 – очень много. Алгоритм поиска «хороших» тестов такой:
Получается, что тесты отбираются так, чтобы, с одной стороны, среднее значение этих тестов было как можно ближе к 0.5, с другой стороны, чтобы корреляция между разными тестами была минимальна. А это нам и нужно. Сравните, как было и как стало:
К счастью, алгоритм ORB реализован в библиотеке OpenCV в классе cv::ORB. Я использую версию 2.4.13. Конструктор класса принимает следующие параметры:
nfeatures – максимальное число особых точек
scaleFactor – множитель для пирамиды изображений, больше единицы. Значение 2 реализует классическую пирамиду.
nlevels – число уровней в пирамиде изображений.
edgeThreshold – число пикселов у границы изображения, где особые точки не детектируются.
firstLevel – оставить нулём.
WTA_K – число точек, которое требуется для одного элемента дескриптора. Если равно 2, то сравнивается яркость двух случайно выбранных пикселов. Это и нужно.
scoreType – если 0, то в качестве меры особенности используется харрис, иначе – мера FAST (на основе суммы модулей разностей яркостей в точках окружности). Мера FAST чуть менее стабильная, но быстрее работает.
patchSize – размер окрестности, из которой выбираются случайные пикселы для сравнения. Код производит поиск и сравнение особых точек на двух картинках, «templ.bmp» и «img.bmp»
Если кому-то помогло разобраться в сути алгоритмов, то всё не зря. Всем Хабра.
Литература:
1. Fusing Points and Lines for High Performance Tracking
2. Machine learning for high-speed corner detection
3. Faster and better: a machine learning approach to corner detection
4. BRIEF: Binary Robust Independent Elementary Features
5. ORB: an ef?cient alternative to SIFT or SURF
Алгоритм FAST
FAST, впервые предложенный в 2005 году в работе [1], был одним из первых эвристических методов поиска особых точек, который завоевал большую популярность из-за своей вычислительной эффективности. Для принятия решения о том, считать заданную точку С особой или нет, в этом методе рассматривается яркость пикселов на окружности с центром в точке С и радиусом 3:
Сравнивая яркости пикселов окружности с яркостью центра C, получаем для каждого три возможных исхода (светлее, темнее, похоже):
Здесь I – яркость пикселов, t – некоторый заранее фиксированный порог по яркости.
Точка помечается как особая, если на круге существует подряд n=12 пикселов, которые темнее, или 12 пикселов, которые светлее, чем центр.
Как показала практика, в среднем для принятия решения нужно было проверить около 9 точек. Для того, чтобы ускорить процесс, авторы предложили сначала проверить только четыре пиксела под номерами: 1, 5, 9, 13. Если среди них есть 3 пиксела светлее или темнее, то выполняется полная проверка по 16 точкам, иначе – точка сразу помечается как «не особая». Это сильно сокращает время работы, для принятия решения в среднем достаточно опросить всего лишь около 4 точек окружности.
Немного наивного кода лежит тут
Изменяемые параметры (описаны в коде): радиус окружности (приимает значения 1,2,3), параметр n (в оригинале n=12), параметр t. Код открывает файл in.bmp, обрабатывает картинку, сохраняет в out.bmp. Картинки обычные 24-битные.
Строим дерево решений, Tree FAST, FAST-9
В 2006 году в работе [2] удалось развить оригинальную идею с использованием машинного обучения и деревьев решений.
У оригинального FAST есть следующие недостатки:
- Несколько рядом расположенных пикселов могут быть помечены как особые точки. Нужна какая-то мера «силы» особенности. Одна из первых предложенных мер — максимальное значение t, при котором точка всё ещё принимается как особая.
- Быстрый 4-точечный тест не обобщается для n меньше 12. Так, например, визуально наилучшие результаты метода достигаются при n=9, а не 12.
- Хотелось бы ещё ускорить алгоритм!
Вместо использования каскада из двух тестов из 4 и 16 точек предлагается всё делать за один проход по дереву решений. Аналогично оригинальному методу будем сравнивать яркость центральной точки с точками на окружности, но в таком порядке, чтобы принять решение как можно быстрее. И оказывается, что можно принимать решение всего лишь за ~2 (!!!) сравнения в среднем.
Самая соль в том, как найти нужный порядок для сравнения точек. Найти при помощи машинного обучения. Предположим, кто-то отметил для нас на картинке множество особых точек. Будем использовать их как набор обучающих примеров и идея состоит в том, чтобы в качестве следующей точки жадно выбирать такую, которая даст наибольшее число информации на данном шаге. Например, пусть изначально в нашей выборке было 5 особых точек и 5 НЕособых точек. В виде таблички вот так:
Выберем теперь один из пикселов р окружности и для всех особых точек проведём сравнение центрального пиксела с выбранным. В зависимости от яркости выбранного пиксела около каждой особой точки, в таблице может быть такой результат:
Идея в том, чтобы выбрать такую точку p, чтобы цифры в столбцах таблицы максимально отличались. И если теперь для новой неизвестной точки мы получим результат сравнения «Светлее», то уже можем сразу сказать, что точка «не особая» (см. таблицу). Процесс продолжается рекурсивно до тех пор, пока в каждую группу после разделения на «темнее-похожий-светлее» не будут попадать точки только одного из классов. Получается дерево следующего вида:
В листьях дерева находится бинарное значение (красный – особая, зелёный – не особая), а в остальных вершинах дерева находится номер точки, которую нужно анализировать. Более конкретно, в оригинальной статье предлагают делать выбор номера точки по изменению энтропии. Энтропия множества точек вычисляется:
с – число особых точек, – число не особых точек множества
Изменение энтропии после обработки точки p:
Соответственно, выбирается точка, для которой изменение энтропии будет максимально. Процесс разбиения прекращается, когда энтропия равна нулю, это означает, что все точки либо особые, либо наоборот – все не особые. При программной реализации после всего этого найденное дерево решений преобразуется в набор конструкций типа «if-else».
Последним этапом алгоритма является операция подавления немаксимумов, чтобы получить из нескольких рядом расположенных точек одну. Разработчики предлагают использовать оригинальную меру на основе суммы абсолютных разностей между центральной точкой и точками окружности в таком виде:
Здесь и соответственно группы пикселов светлее и темнее, t – пороговое значение яркости, – яркость центрального пиксела, – яркость пиксела на круге. Попробовать алгоритм можно следующим кодом. Код взят из OpenCV и освобождён от всех зависимостей, просто запускайте.
Оптимизируем дерево решений — FAST-ER
FAST-ER [3] – алгоритм тех же авторов, что и предыдущий, аналогично строится быстрый детектор, тоже ищется оптимальная последовательность точек для сравнения, тоже строится дерево решений, но другим методом – методом оптимизации.
Мы уже понимаем, что детектор можно представить в виде дерева решений. Если бы у нас был какой-нибудь критерий для сравнения производительности разных деревьев, то можно максимизировать этот критерий, перебирая разные варианты деревьев. И вот в качестве такого критерия предложено использовать «Повторяемость».
Повторяемость показывает, насколько хорошо особые точки сцены детектируются с разных ракурсов. Для пары картинок точка называется «полезной» (useful), если найдена на одном кадре и теоретически может быть найдена на другом, т.е. не загораживается элементами сцены. И точка называется «повторяемой» (repeated), если она найдена на втором кадре тоже. Поскольку оптика камеры неидеальна, то точка на втором кадре может находиться не в расчётном пикселе, а где-то рядом в его окрестности. Разработчики взяли окрестность в 5 пикселов. Определим повторяемость как отношение числа повторяемых точек к числу полезных:
Для поиска наилучшего детектора используется метод имитации отжига. На Хабре уже есть прекрасная статья про него. Кратко, суть метода в следующем:
- Выбирается какое-то начальное решение задачи (в нашем случае это какое-то дерево детектора).
- Считается повторяемость.
- Дерево случайным образом модифицируется.
- Если модифицированный вариант лучше по критерию повторяемости, то модификация принимается, а если хуже, то может либо приняться, либо нет, с некоторой вероятностью, которая зависит от вещественного числа, называемого «температура». С увеличением числа итераций температура падает до нуля.
Кроме этого, в построении детектора теперь участвуют не 16 точек окружности, как раньше, а 47, но смысл от этого совершенно не меняется:
Согласно методу имитации отжига, определим три функции:
• Функцию стоимости k. В нашем случае в качестве стоимости мы используем повторяемость. Но тут есть одна проблема. Представим, что все точки на каждом из двух изображений детектированы как особые. Тогда получается, что повторяемость равна 100 % – абсурд. С другой стороны, пусть у нас на двух картинках найдено по одной особой точке, и эти точки совпали – повторяемость также 100 %, но это тоже нас не интересует. И поэтому авторы предложили в качестве критерия качества использовать такой:
r – повторяемость, – число детектированных углов на кадре i, N – число кадров и s – размер дерева (число вершин). W – настраиваемые параметры метода.]
• Функцию изменения температуры со временем:
где – коэффициенты, Imax – число итераций.
• Функцию, порождающую новое решение. Алгоритм делает случайные модификации дерева. Сначала выбирается некоторая вершина. Если выбранная вершина это лист дерева, то с равной вероятностью делаем следующее:
- Заменим вершину случайным поддеревом с глубиной 1
- Изменить класс этого листа (особая-неособая точки)
Если это НЕ лист:
- Заменить номер тестируемой точки случайным числом от 0 до 47
- Заменить вершину листом со случайным классом
- Поменять местами два поддерева из этой вершины
Вероятность P принятия изменения на итерации I это:
k – функция стоимости, T – температура, i – номер итерации.
Эти модификации к дереву позволяют как рост дерева, так и его сокращение. Метод случайный, он не гарантирует, что получится наилучшее дерево. Запускают метод много раз, выбирая наилучшее решение. В оригинальной статье, например, запускают 100 раз на 100000 итераций каждый, что занимает 200 часов времени процессора. Как показывают результаты, получается в итоге лучше, чем Tree FAST, особенно на зашумлённых картинках.
Дескриптор BRIEF
После того, как особые точки найдены, вычисляют их дескрипторы, т.е. наборы признаков, характеризующие окрестность каждой особой точки. BRIEF [4] – быстрый эвристический дескриптор, строится из 256 бинарных сравнений между яркостями пикселов на размытом изображении. Бинарный тест между точками х и у определяется так:
В оригинальной статье было рассмотрено несколько способов выбора точек для бинарных сравнений. Как оказалось, один из лучших способов – выбирать точки случайным образом Гауссовским распределением вокруг центрального пиксела. Эта случайная последовательность точек выбирается один раз и в дальнейшем не меняется. Размер рассматриваемой окрестности точки равен 31х31 пиксел, а апертура размытия равна 5.
Полученный бинарный дескриптор оказывается устойчив к сменам освещения, перспективному искажению, быстро вычисляется и сравнивается, но очень неустойчив к вращению в плоскости изображения.
ORB — быстрый и эффективный
Развитием всех этих идей стал алгоритм ORB (Oriented FAST and Rotated BRIEF) [5], в котором сделана попытка улучшить производительноть BRIEF при повороте изображения. Предложено сначала вычислять ориентацию особой точки и затем проводить бинарные сравнения уже в соответствие с этой ориентацией. Работает алгоритм так:
1) Особые точки обнаруживаются при помощи быстрого древовидного FAST на исходном изображении и на нескольких изображениях из пирамиды уменьшенных изображений.
2) Для обнаруженных точек вычисляется мера Харриса, кандидаты с низким значением меры Харриса отбрасываются.
3) Вычисляется угол ориентации особой точки. Для этого, сначала вычисляются моменты яркости для окрестности особой точки:
x,y – пиксельные координаты, I – яркость. И затем угол ориентации особой точки:
Всё это авторы назвали «центроид ориентации». В итоге получаем некоторое направление для окрестности особой точки.
4) Имея угол ориентации особой точки, последовательность точек для бинарных сравнений в дескрипторе BRIEF поворачивается в соответствие с этим углом, например:
Если более формально, новые положения для точек бинарных тестов вычисляются так:
5) По полученным точкам вычисляется бинарный дескриптор BRIEF
И на этом… не всё! Есть в ORB ещё одна интересная деталь, которая требует отдельных пояснений. Дело в том, что в тот момент, когда мы «доворачиваем» все особые точки до нулевого угла, случайный выбор бинарных сравнений в дескрипторе перестаёт быть случайным. Это приводит к тому, что, во-первых, некоторые бинарные сравнения оказываются зависимыми между собой, во-вторых, их среднее уже не равно 0.5 (1 – светлее, 0 – темнее, когда выбор был случайным, то в среднем было 0.5) и всё это существенно уменьшает способность дескриптора различать особые точки между собой.
Решение — нужно выбрать «правильные» бинарные тесты в процессе обучения, эта идея веет тем же ароматом, что и обучение дерева для алгоритма FAST-9. Предположим, у нас есть куча уже найденных особых точек. Рассмотрим все возможные варианты бинарных тестов. Если окрестность 31 х 31, а бинарный тест представляет собой пару подмножеств 5 х 5 (из-за размытия), то всего вариантов выбора N=(31-5)^2 – очень много. Алгоритм поиска «хороших» тестов такой:
- Вычисляем результат всех тестов для всех особых точек
- Упорядочим всё множество тестов по их дистанции от среднего 0.5
- Создадим список, который будет содержать отобранные «хорошие» тесты, назовём список R.
- Добавим в R первый тест из отсортированного множества
- Берём следующий тест и сравниваем его со всеми тестами в R. Если корреляция больше пороговой, то отбрасываем новый тест, иначе – добавляем.
- Повторяем п. 5 пока не наберём нужное число тестов.
Получается, что тесты отбираются так, чтобы, с одной стороны, среднее значение этих тестов было как можно ближе к 0.5, с другой стороны, чтобы корреляция между разными тестами была минимальна. А это нам и нужно. Сравните, как было и как стало:
К счастью, алгоритм ORB реализован в библиотеке OpenCV в классе cv::ORB. Я использую версию 2.4.13. Конструктор класса принимает следующие параметры:
nfeatures – максимальное число особых точек
scaleFactor – множитель для пирамиды изображений, больше единицы. Значение 2 реализует классическую пирамиду.
nlevels – число уровней в пирамиде изображений.
edgeThreshold – число пикселов у границы изображения, где особые точки не детектируются.
firstLevel – оставить нулём.
WTA_K – число точек, которое требуется для одного элемента дескриптора. Если равно 2, то сравнивается яркость двух случайно выбранных пикселов. Это и нужно.
scoreType – если 0, то в качестве меры особенности используется харрис, иначе – мера FAST (на основе суммы модулей разностей яркостей в точках окружности). Мера FAST чуть менее стабильная, но быстрее работает.
patchSize – размер окрестности, из которой выбираются случайные пикселы для сравнения. Код производит поиск и сравнение особых точек на двух картинках, «templ.bmp» и «img.bmp»
Код
cv::Mat img_object=cv::imread("templ.bmp", 0);
std::vector<cv::KeyPoint> keypoints_object, keypoints_scene;
cv::Mat descriptors_object, descriptors_scene;
cv::ORB orb(500, 1.2, 4, 31, 0, 2, 0, 31);
// особые точки объекта
orb.detect(img_object, keypoints_object);
orb.compute(img_object, keypoints_object, descriptors_object);
// особые точки картинки
cv::Mat img = cv::imread("img.bmp", 1);
cv::Mat img_scene = cv::Mat(img.size(), CV_8UC1);
orb.detect(img, keypoints_scene);
orb.compute(img, keypoints_scene, descriptors_scene);
cv::imshow("desrs", descriptors_scene);
cvWaitKey();
int test[10];
for (int q = 0; q<10 ; q++) test[q]=descriptors_scene.data[q];
//-- matching descriptor vectors using FLANN matcher
cv::BFMatcher matcher;
std::vector<cv::DMatch> matches;
cv::Mat img_matches;
if(!descriptors_object.empty() && !descriptors_scene.empty()) {
matcher.match (descriptors_object, descriptors_scene, matches);
double max_dist = 0; double min_dist = 100;
// calculation of max and min idstance between keypoints
for( int i = 0; i < descriptors_object.rows; i++)
{ double dist = matches[i].distance;
if( dist < min_dist ) min_dist = dist;
if( dist > max_dist ) max_dist = dist;
}
//-- Draw only good matches (i.e. whose distance is less than 3*min_dist)
std::vector< cv::DMatch >good_matches;
for( int i = 0; i < descriptors_object.rows; i++ ) if( matches[i].distance < (max_dist/1.6) ) good_matches.push_back(matches[i]);
cv::drawMatches(img_object, keypoints_object, img_scene, keypoints_scene, good_matches, img_matches, cv::Scalar::all(-1), cv::Scalar::all(-1),
std::vector<char>(), cv::DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS);
}
cv::imshow("match result", img_matches );
cv::waitKey();
return 0;Если кому-то помогло разобраться в сути алгоритмов, то всё не зря. Всем Хабра.
Литература:
1. Fusing Points and Lines for High Performance Tracking
2. Machine learning for high-speed corner detection
3. Faster and better: a machine learning approach to corner detection
4. BRIEF: Binary Robust Independent Elementary Features
5. ORB: an ef?cient alternative to SIFT or SURF
Sdima1357
У FAST есть проблема., точность локализации не субпиксельная. В большинстве приложений как раз требуется субпиксельная точность. Например DoG или Hessian и быстрее и точнее. Кроме того узкое место место-это вычисление дескриптора, а не нахождение особых точек.впрочем для некоторых приложений fast- вполне себе, когда смещение(парралакс например) не слишком велико. Получилось немного однобоко, стоило упомянуть и другие методы. Получилось что специалистам это не интересно, а не специалистам не нужно