
Экспрессивность — интересное свойство языков программирования. С помощью простого комбинирования выражений можно добиться впечатляющих результатов. Некоторые языки осмысленно отвергают идеи выразительности, но Kotlin точно не является таким языком.
С помощью базовых конструкций языка и небольшого количества сахара мы попытаемся воссоздать SQL в синтаксисе Kotlin настолько близко, насколько это возможно.

Ссылка на GitHub для нетерпеливых
Нашей целью будет помочь программисту отловить определенное подмножество ошибок на этапе компиляции. Kotlin, являясь строготипизованным языком, поможет нам уйти от невалидных выражений в структуре SQL запроса. Как бонус, мы получим еще защиту от опечаток и помощь от IDE в написании запросов. Исправить недостатки SQL полностью не получится, но устранить некоторые проблемные места вполне возможно.
Данная статья расскажет про библиотеку на Kotlin, которая позволяет писать SQL запросы в синтаксисе Kotlin. Также, мы немного посмотрим на внутренности библиотеки, чтобы понять как это работает.
Немного теории
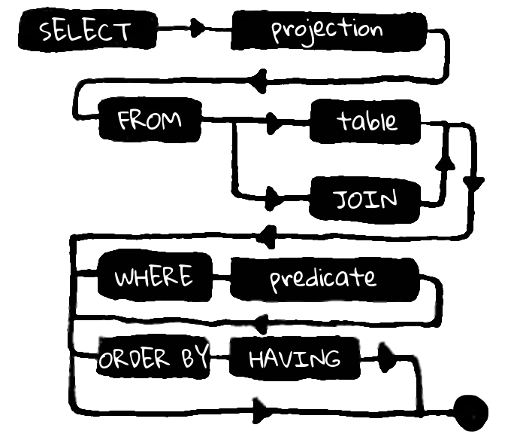
SQL расшифровывается как Structured Query Language, т.е. структура у запросов присутствует, хотя синтаксис оставляет желать лучшего — язык создавался, чтобы им мог воспользоваться любой пользователь, даже не имеющий навыков программирования.
Однако, под SQL скрывается довольно мощный фундамент в виде теории реляционных баз данных — там всё очень логично. Чтобы понять структуру запросов, обратимся к простой выборке:
SELECT id, name -- проекция (projection), ?(id, name)
FROM employees -- источник (table)
WHERE organization_id = 1 -- выборка с предикатом (predicate), ?(organization_id = 1)Что важно понять: запрос состоит из трех последовательных частей. Каждая из этих частей во-первых — зависит от предыдущей, во-вторых — подразумевает ограниченный набор выражений для продолжения запроса. На самом деле даже не совсем так: выражение FROM тут явно является первичным по отношению к SELECT, т.к. то, какой набор полей мы можем выбрать, напрямую зависит от таблицы, из которой производится выборка, но никак не наоборот.
Перенос на Kotlin
Итак, FROM первичен по отношению к любым другим конструкциям языка запросов. Именно из этого выражения возникают все возможные варианты продолжения запроса. В Kotlin мы отразим это через функцию from(T), которая будет принимать на вход объект, представляющий из себя таблицу, у которой есть набор колонок.
object Employees : Table("employees") {
val id = Column("id")
val name = Column("name")
val organizationId = Column("organization_id")
}
Функция вернет объект, который содержит в себе методы, отражающие возможное продолжение запроса. Конструкция from всегда идет самой первой, перед любыми другими выражениями, поэтому она предполагает большое количество продожений, включая завершающий SELECT (в противоположность SQL, где SELECT всегда идет перед FROM). Код, эквивалентный SQL-запросу выше будет выглядеть следующим образом:
from(Employees)
.where { e -> e.organizationId eq 1 }
.select { e -> e.id .. e.name }
Интересно, что таким образом мы можем предотвратить невалидный SQL еще во время компиляции. Каждое выражение, каждый вызов метода в цепочке предполагает ограниченное число продолжений. Мы можем контролировать валидность запроса средствами языка Kotlin. Как пример — выражение where не предполагает после себя продолжения в виде еще одного where и, тем более, from, а вот конструкции groupBy, having, orderBy, limit, offset и завершающий select все являются валидными.
Лямбды, переданные в качестве агрументов операторам where и select призваны сконструировать предикат и проекцию соответственно (мы уже упоминали их ранее). На вход лямбде передается таблица, чтобы можно было обращаться к колонкам. Важно, что типобезопасность сохраняется и на этом уровне — с помощью перегрузки операторов мы можем добиться того, что предикат в конечном итоге будет представлять из себя псевдобулевое выражение, которое не скомпилируется при наличии синтаксической ошибки или ошибки, связанной с типами. То же самое касается и проекции.
fun where(predicate: (T) -> Predicate): WhereClause<T>
fun select(projection: (T) -> Iterable<Projection>): SelectStatement<T>
JOIN
Реляционные базы данных позволяют работать с множеством таблиц и связями между ними. Было бы хорошо дать возможность разработчику работать с JOIN и в нашей библиотеке. Благо, реляционная модель хорошо ложится на всё, что было описанно ранее — нужно лишь добавить метод join, который добавит вторую таблицу в наше выражение.
fun <T2: Table> join(table2: T2): JoinClause<T, T2>
JOIN, в данном случае, будет иметь методы, аналогичные тем, что предоставляет выражение FROM, с тем лишь отличием, что лямбды проекции и предикатов будут принимать по два параметра для возможности обращения к колонкам обеих таблиц.
from(Employees)
.join(Organizations).on { e, o -> o.id eq e.organizationId }
.where { e, o -> e.organizationId eq 1 }
.select { e, o -> e.id .. e.name .. o.name }
Управление данными
Data manipulation language — средство языка SQL, которое позволяет помимо запросов к таблицам осуществлять вставку, модификацию и удаление данных. Эти конструкции хорошо вписываются в нашу модель. Для поддержки update и delete нам понадобится всего-лишь дополнить выражения from и where вариантом с вызовом соответствующих методов. Для поддержки insert, введем дополнительную функцию into.
from(Employees)
.where { e -> e.id eq 1 }
.update { e -> e.name("John Doe") }
from(Employees)
.where { e -> e.id eq 0 }
.delete()
into(Employees)
.insert { e -> e.name("John Doe") .. e.organizationId(1) }
Описание данных
SQL работает со структурированными данными в виде таблиц. Таблицы требуют описания перед началом работы с ними. Эта часть языка называется Data definition language.
Операторы CREATE TABLE и DROP TABLE реализованы аналогично — функция over будет служить стартовой точкой.
over(Employees)
.create {
integer(it.id).primaryKey(autoIncrement = true)..
text(it.name).unique().notNull()..
integer(it.organizationId).foreignKey(references = Organizations.id)
}
over(Employees).drop()
Комментарии (49)

shaggyone
19.06.2018 13:37Возможно ли с использованием данного DSL построить запрос, в котором количество join'ов зависит от внешних условий?
x2bool Автор
19.06.2018 13:42Условные джоины вполне возможны:
1) Делаете базовый запрос
2) Дополняете джоинами по условию, в зависимости от ваших потребностейshaggyone
19.06.2018 13:49«Я не настоящий сварщик», с Kotlin не работал.
Поясню, что я имею ввиду.
Вот такое как правильно написать?
x = from(Employees) .join(Organizations).on { e, o -> o.id eq e.organizationId } .where { e, o -> e.organizationId eq 1 } .select { e, o -> e.id .. e.name .. o.name } if <some external condition> x = x.join(Countries).on { e, o, c -> e.country_id = c.id } # Уже 3 переменные в роли алиасов end if if <some other external condition> x = x.join(Users).on { e, o, c, u -> e.user_id = u.id } # Уже 3 либо 4 переменные в роли алиасов end ifx2bool Автор
19.06.2018 13:55Так — нет. Можно, что-то такое:
x = from(Employees) .join(Organizations).on { e, o -> o.id eq e.organizationId } if (some external condition) y = x.join(Countries).on { e, o, c -> e.country_id = c.id } # Уже 3 переменные в роли алиасов .where { e, o, c -> e.organizationId eq 1 } .select { e, o, c -> e.id .. e.name .. o.name } else y = x.where { e, o -> e.organizationId eq 1 } .select { e, o -> e.id .. e.name .. o.name }shaggyone
19.06.2018 14:03Дублирование этого кода — сильно не комильфо.
.where { e, o, c -> e.organizationId eq 1 } .select { e, o, c -> e.id .. e.name .. o.name }
я так понимаю это ограничение языка?x2bool Автор
19.06.2018 14:16Нет, это не ограничение языка, так написана библиотека. Select, являясь завершающим вызовом в любом случае будет дублироваться. Над Where можно подумать еще.
shaggyone
19.06.2018 14:35Я бы подумал на тему явного объявления алиасов при построении запросов.
У меня примерно такие мысли появились:
# Declare aliases first val e = generate_alias val o = generate_alias val c = generate_alias val u = generate_alias # Bind e to Employee x = from(Employees, e) # bind o to Organizations x = x.join(Organizations, o).on { |o| -> o.id eq e.organizationId } # Pick columns from employees table x = x.select { e.id .. e.name } # Add column from organizations table x = x.select { o.name } if some_condition # Join countries and add countries.country_name to select x = x.join(Countries, c).on { |c| e.country_id = c.id } .select { c.country_name } if another_condition # Join countries and add users.user_name to select x = x.join(Users, u).on { |u| e.user_id = u.id } .select { u.user_name }
x.where { e.name eq… }
Тут даже параметры к лямбдам, которые передаются в on могут быть избыточными, хотя могут уменьшать риск опечатки при построении запроса.
Кстати, как и сами выражения on. Если язык позволяет, я бы их объединил с join.
zindur2
19.06.2018 14:12Вот не вижу смысла, зачем прослойка между девелопером и SQL?
SQL — не такой трудный. Потом не известно что ещё накомпайлит этот Kotlin потом ищи почему перформас упал потому что Kotlin скомпилировал неефективный запросNeikist
19.06.2018 14:17+1Это как строгая статическая vs слабая динамическая типизация. Проверки во время компиляции радуют. Плюс подозреваю что автокомплит и подсказки на таком коде работать будут, в отличие от SQL.
bano-notit
19.06.2018 15:47У JB есть автокомплит в SQL)
Neikist
19.06.2018 15:49Отрабатывает если например запрос конкатенацией строк собирается в зависимости от условий? Так то в моей IDE тоже есть, причем очень удобный, конструктор целый.
bano-notit
19.06.2018 15:54Эмм… Нет. К сожалению с конкатенацией оно работает плохо. Причём на всех встраиваемых в строки языках. Но если использовать
из JS, то работает вполне себе сносно.` .. ${some exp} .. `
mwizard
19.06.2018 17:34Первичен все-таки SELECT, а не FROM, т.к. выборки могут происходить из нескольких таблиц сразу, и SELECT в данном случае обозначает намерение и сужает список возможных действий, которые в принципе могут быть выполнены над базой данных.
x2bool Автор
19.06.2018 17:41Я бы поспорил с этим. Прежде чем производить какое-то действие, нужно знать, над чем действие будет произведено. Выборка из нескольких таблиц это всего-лишь синтаксический сахар над конструкцией JOIN.
С этим фактом, кстати, связаны множество проблем автокомплита SQL в IDE: невозможно дать подсказку по колонкам таблицы без информации о том, из какой таблицы будет выборка.
Neikist
19.06.2018 20:06Просто у вас подход получается менее декларативный а больше императивный, чем при написании запроса как обычно, тут смотря как рассматривать процесс, имхо.
speshuric
19.06.2018 21:49+1Спорно. Это вечная проблема, когда пишешь
SELECT, а автокомплиту нечего тебе предложить, потому что он еще не знает ни таблиц, ни алиасов, ни полей. И когда запросы большие, видишьti.value, и, мотая вниз, думаешь "это, блин, вообще из какой таблицы???". Чаще всего сначала пишешьselect * fromилиselect 1 from, потом лепишь "tablesource" при помощи join/apply/where, а потом возвращаешься к списку полей.
В том же linq также пошли.mwizard
19.06.2018 23:41В таком случае, что-то наподобие `SELECT FROM table1, table2 COLUMNS foo, table1.bar AS bar1, table2.bar AS bar2`… было бы логичнее.
speshuric
20.06.2018 00:01Ну тогда слово
SELECTстановится мусорным и видим то что видим в этой статье или LINQ.
А вообще, черт его знает, что логичнее :). Весь SQL — сборище исторических нелогичных костылей за 50 лет. Точнее продукт эволюции computer science, костылей для обхода текущих возможностей железа, костылей для обхода текущих кривостей реализаии, перетягиваний одеяла между вендорами СУБД и необходимости как-то работать с данными. Дедушка Дейт, вон, тоже постоянно ворчит, что SQL кривым получился.
0x1000000
19.06.2018 18:51А для C# что-нибудь подобное есть?
speshuric
19.06.2018 21:50-1Пусть он не моден, но… Linq?
0x1000000
20.06.2018 09:56Если вы имеет в виду Linq to SQL то это не совсем полноценный аналог, поскольку в нем не строится в явном виде синтаксическое дерево SQL запросов. Linq пытается преобразовать выражения на языке C# в SQL запрос, что не дает полноценного контроля над результатом.
Dansoid
20.06.2018 19:16Можете уточнить что вы имеете ввиду под «полноценным контролем над результатом»?
0x1000000
21.06.2018 11:33Допустим мне нужен LEFT JOIN. С билдером синтаксического дерева, я вызываю функцию “LeftJoin”. В случае LINQ я лезу в гугл и нахожу, что именно вот такая последовательность вызовов будет интерпретирована как Left Join:
join p in products on c.Category equals p.Category into ps
from p in ps.DefaultIfEmpty()
Идея в том, что нет однозначного отображения из LINQ в SQL
speshuric
19.06.2018 23:14+1x2bool, этот комментарий будет достаточно резкий, но досмотрите его до конца, пожалуйста.
У вас и концепция, и статья, и код получились неудачными. Я отмечу только то, что в глаза бросилось, потому что иначе комментарий будет длиннее статьи.
- В статье, например, синтаксические диаграммы некорректные и бессмысленные.
- Код абсолютно небезопасный и не продуман с точки зрения надёжности: даже прямые включения строк в SQL (привет, injection).
- DDL непонятно когда и непонятно как вызывается. В том смысле, что если есть таблица в БД, то что, её при следующем запуске снова создавать?
- Запросы возможные только совсем-совсем примитивные. Не верите? Берите какой-нибудь http://sql-ex.ru/, нарешайте там штук 20-30 примеров (это несложно) и попробуйте воспроизвести.
- Ваша модель диалектов не позволяет учесть даже базовых различий между СУБД.
- Код на котлине написан "не по-котлински". Совсем не DRY, с кучей явных лишних обработок null. То есть вот просто каждый файл проекта надо брать и почти полностью переписывать.
- Не учтена архитектура предшественников. Тот же linq для начала, ну и ORM типа Hibernate/NHibernate.
- Конечная цель — проверка на этапе компиляции — не достигнута (даже автоинкремент в рантайме проверяется), а где достигнута, то это явным хардкодом типов полей.
На самом деле это всё косметика. Главная проблема — задача просто невообразимо сложнее, чем те приемы, которыми вы её пытаетесь решить. Там прямо в каждой маленькой детали нюансов больше, чем весь проект на текущий момент. С этим подходом не то что до промышленного, до учебного качества проект не довести.
НО.
- Вы сделали прототип. Это важная стадия до которой не добирается и 10% идей, наверное. Этот прототип может быть на выброс, но он компилируется и показывает, куда вы хотите идти.
- Вы правильно сделали, что вынесли прототип на обсуждение. Местами неприятный, но единственный способ получить обратную связь и посмотреть на решение "снаружи". Каждый час, потраченный на то, чтобы идти в неправильную сторону — это в итоге несколько часов потраченных зря.
- Вы правильно заметили, что тулинг между kotlin и db далёк от совершенства. Эту тему есть куда развивать.
Насколько я понимаю, эта библиотека используется вами в другом проекте (или планировалась для этого). Сделайте паузу в развитии
kuery, попробовав его использовать. Если не сможете — не используйте, но запишите, что помешало использовать. Не тратьте времени больше, чем на фикс критичных багов. За 1-2 месяца вы будете гораздо лучше знать, что именно нужно полностью переработать вkuery. Не бросайте, возможно у вас получится то, что задумано изначально, но получится другой полезный и удобный инструмент для разработки.x2bool Автор
20.06.2018 00:23Спасибо за развернутый комментарий. Приятно, когда вникают в суть статьи. Теперь по пунктам:
1) хм???
2) Абсолютно верно. Это вообще решается плэйсхолдерами и передачей аргументов в prepared statements, т.е. хэндлиться должно уровнем ниже. Думаю стоит этот момент задокуметировать, чтобы не сбивать с толку людей.
3) Никакой магии не происходит "за кадром". Вызывать DDL нужно руками. Библиотека не является средством миграции или ORM. Сейчас цель сделать этакий билдер для SQL запросов.
4) Правда. Как доберусь до подзапросов, будет немного лучше.
5) Очень может быть. Библиотека в продакшене используется только на Android (SQLite). Может, я что-то упустил из других диалектов.
6) Очень может быть
7) Не совсем понял. С LINQ я "на ты", т.к. по основному роду деятельности я дотнетчик.
8) Согласен. Полностью проверить запросы на этапе компиляции не получится, но можно добиться некоторого улучшения по сравнению с SQL. В рантайме автоинкремент не проверяется.
Что касается ипользования — эта библиотека вытекла из реального проекта, т.е. около года она вполне себе используется. Но возможно проблема в том, что реально применяется пока только на Android, и я не могу видеть всех юзкейсов и проблем от других пользователей.
rjhdby
20.06.2018 12:57+1Полностью проверить запросы на этапе компиляции не получится
Собственно стандартный JDBC
stmt.setInt(1, someInt)
И ничего, кроме Int'а туда не передашь. Проверяется на этапе компиляции.
Собственно вам нужно:
- Не строку генерить, а PreparedStatement.
- На этапе
.where { e -> e.id eq 1 }добавлять не "1", а "?". Запоминать индекс, тип и значение. Это довольно не сложно реализовывается, даже дляIN (...) - На конечном этапе совершить подстановку всех параметров
x2bool Автор
20.06.2018 14:48А это идея! Можно сделать методы расширения для конкретных реализаций типа JDBC для преобразования в prepared statement вместо строк. Благодарю за наводку.
Tishka17
20.06.2018 20:08А можно реализовать запрос такого типа (могу ошибиться с синтаксисом, но хочу донести идею)
INSERT INTO table1 (field1) VALUES (SELECT MAX(field2)*2 FROM TABLE 2 WHERE somefield IN ("Q", "W", "E") GROUP BY someotherfield)x2bool Автор
20.06.2018 20:18Это частный случай подзапроса. Подзапросы еще не готовы, но первые в очереди на реализацию. Будет.
Tishka17
20.06.2018 22:50А функции, case и прочее? Я, конечно, утрирую, но все же
CASE WHEN (LENGTH(SUBSTR(TRIM(field1), 1, 5)) + INSTR(LOWER(field2), field3) + field4) / 2 < field5: "foo", WHEN field6 > random(): "bar" ELSE: "baz" END
ov7a
Как-то чужеродно выглядит range-оператор
..в этом dsl. Иeqтоже режет глаз.x2bool Автор
Альтернатива range это что-нибудь типа listOf, очень многословно получится. Что касается eq, то переопределить == не получится, т.к. он обязан вернуть Boolean, а для нужд библиотеки подойдет только внутренний тип Expression.
ov7a
Предпосылки-то понятны, но не уверен, что это самый лучший вариант. Какие варианты, кстати, вообще рассматривались?
x2bool Автор
Можно в методе прямо прописать, можно строкой прямо. Не уверен, что это чем-то лучше. Есть другие идеи?
speshuric
Зато можно инфиксную
==в backticks определить. В JVM, но не js, правдаx2bool Автор
Можно. Но нужно ли? Как по мне, так eq лаконичнее, плюс там все операторы придется так делать. Еще я не уверен, что DEX позволит такое имя, не хотелось бы исключать Android.
konsoletyper
В JS можно использовать аннотацию JsName:
speshuric
О, да, точно. Но там своих приколов хватает.
Shyster
очень похоже на jooq.org