

В последние несколько лет тема искусственного интеллекта и машинного обучения перестала быть для людей чем-то из области фантастики и прочно вошла в повседневную жизнь. Социальные сети предлагают посетить интересные нам мероприятия, автомобили на дорогах научились передвигаться без участия водителя, а голосовой помощник в телефоне подсказывает, когда лучше выходить из дома, чтобы избежать пробок, и нужно ли брать с собой зонт.
В данной статье мы рассмотрим инструменты для машинного обучения, которые предлагает разработчикам Apple, разберем, что нового в этой области компания показала на WWDC18, и попробуем понять, как можно применить это все на практике.
Машинное обучение
Итак, машинное обучение — это процесс, в ходе которого система, используя определенные алгоритмы анализа данных и обрабатывая огромное количество примеров, выявляет закономерности и использует их, чтобы прогнозировать характеристики новых данных.
Машинное обучение родилось из теории о том, что компьютеры могут учиться самостоятельно, будучи еще не запрограммированными на выполнение определенных действий. Другими словами, в отличие от обычных программ с заранее введенными инструкциями для решения конкретных задач, машинное обучение позволяет системе научиться самостоятельно распознавать шаблоны и делать прогнозы.
BNNS и CNN
Apple использует технологии машинного обучения на своих устройствах уже довольно давно: Mail определяет письма, содержащие спам, Siri помогает быстро узнать ответы на интересующие вопросы, Photos распознает лица на изображениях.
На WWDC16 компания представила два API на базе нейронных сетей — Basic Neural Network Subroutines (BNNS) и Convolutional Neural Networks (CNN). BNNS — часть системы Accelerate, которая является основой для выполнения быстрых вычислений на CPU, а CNN — библиотеки Metal Performance Shaders, использующей GPU. Подробнее об этих технологиях можно узнать, к примеру, здесь.
Core ML и Turi Create
В прошлом же году Apple анонсировала фреймворк, значительно облегающий работу с технологиями машинного обучения — Core ML. В его основе идея о том, чтобы взять заранее предобученную модель данных, и буквально в несколько строк кода интегрировать ее в свое приложение.
С помощью Core ML можно реализовать множество функций:
- определение объектов на фото и видео;
- предиктивный ввод текста;
- отслеживание и распознавание лиц;
- анализ движений;
- определение штрихкодов;
- понимание и распознавание текста;
- распознавание изображений в реальном времени;
- стилизация изображений;
- и многое другое.
Core ML, в свою очередь, использует низкоуровневые Metal, Accelerate и BNNS, и поэтому результаты вычислений происходят очень быстро.
Ядро поддерживает нейронные сети, обобщенные линейные модели (generalized linear models), генерацию признаков (feature engineering), древовидные алгоритмы принятия решений (tree ensembles), метод опорных векторов (support vector machines), пайплайн модели (pipeline models).
Но Apple изначально не показала собственных технологий для создания и обучения моделей, а лишь сделала конвертер для других популярных фреймворков: Caffe, Keras, scikit-learn, XGBoost, LIBSVM.
Использование сторонних инструментов зачастую являлось не самой простой задачей, обученные модели имели довольно большой объем, а само обучение занимало немало времени.
В конце года компания представила Turi Create — фреймворк для обучения моделей, основной идеей которого была простота в использовании и поддержка большого числа сценариев — классификация изображений, определение объектов, рекомендательные системы, и множество других. Но Turi Create, несмотря на свою относительную простоту в использовании, поддерживал только Python.
Create ML
И вот в этом году Apple, помимо Core ML 2, наконец показала собственный инструмент для обучения моделей — фреймворк Create ML, использующий нативные технологии Apple — Xcode и Swift.
Он работает быстро, а создание типовых моделей с помощью Create ML становится по-настоящему простым.
На WWDC были озвучены впечатляющие показатели Create ML и Core ML 2 на примере приложения Memrise. Если раньше на обучение одной модели с использованием 20 тысяч изображений требовалось 24 часа, то Create ML сокращает это время до 48 минут на MacBook Pro и до 18 минут — на iMac Pro. Размер обученной модели уменьшился с 90MB до 3MB.
Create ML позволяет использовать в качестве исходных данных изображения, тексты и структурированные объекты — например, таблицы.
Классификация изображений
Посмотрим для начала, как работает классификация изображений. Для обучения модели нам нужен исходный набор данных: возьмем три группы фотографий животных: собак, кошек и птиц и распределим их по папкам с соответствующими названиями, которые и станут названиями категорий модели. Каждая группа содержит по 100 изображений с разрешением до 1920х1080 пикселей и размером до 1Mb. Фотографии должны по возможности максимально отличаться, чтобы обученная модель не полагалась на такие признаки, как цвет на изображении или окружающее пространство.
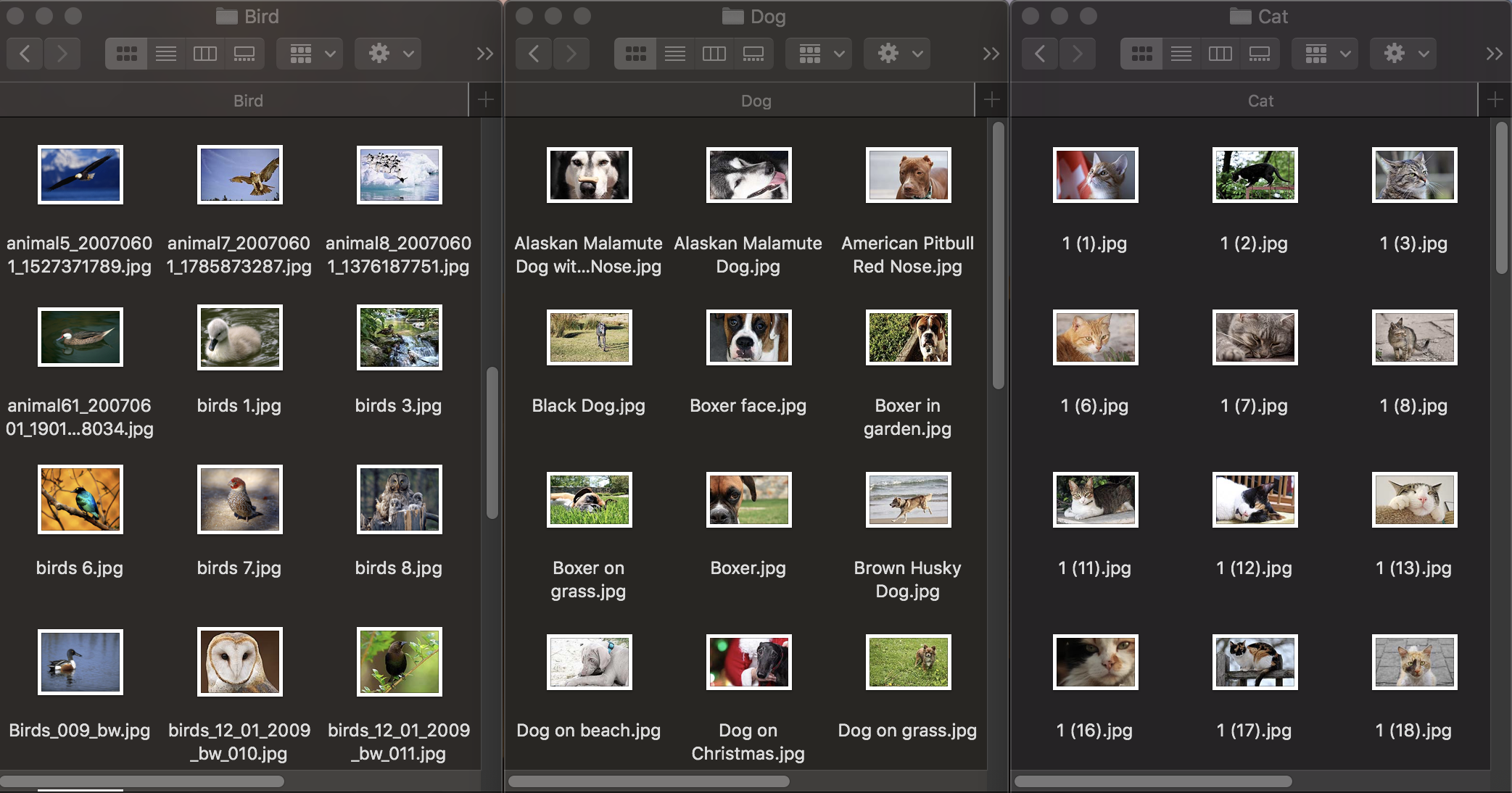
Также для проверки, насколько хорошо обученная модель справляется с распознаванием объектов, необходим тестовый набор данных — изображения, не входящие в изначальный датасет.
Apple предоставляет два способа взаимодействия с Create ML: с помощью UI в MacOS Playground’е Xcode и программно — с CreateMLUI.framework и CreateML.framework. Используя первый способ, достаточно написать пару строк кода, перенести выбранные изображения в указанную область, и подождать, пока обучится модель.

На Macbook Pro 2017 в максимальной комплектации обучение заняло 29 секунд для 10 итераций, а размер обученной модели составил 33Kb. Выглядит впечатляюще.
Попробуем разобраться, как удалось достичь таких показателей и что «под капотом».
Задача классификации изображений — один из самых популярных вариантов использования сверточных нейронных сетей. Для начала стоит пояснить, что они из себя представляют.
Человек, видя изображение животного, может быстро отнести его к определенному классу на основе каких-либо отличительных признаков. Нейронная сеть действует аналогично, проводя поиск базовых характеристик. Принимая на вход изначальный массив пикселей, она последовательно пропускает информацию через группы сверточных слоев и строит все более сложные абстракции. На каждом последующем слое она учится выделять определенные признаки — сначала это линии, затем наборы линий, геометрические фигуры, части тела, и так далее. На последнем слое мы получаем вывод класса или группы вероятных классов.
В случае же Create ML обучение нейронной сети не производится с нуля. Фреймворк использует предварительно обученную на огромном наборе данных нейронную сеть, которая уже включает большое количество слоев и обладает высокой точностью.
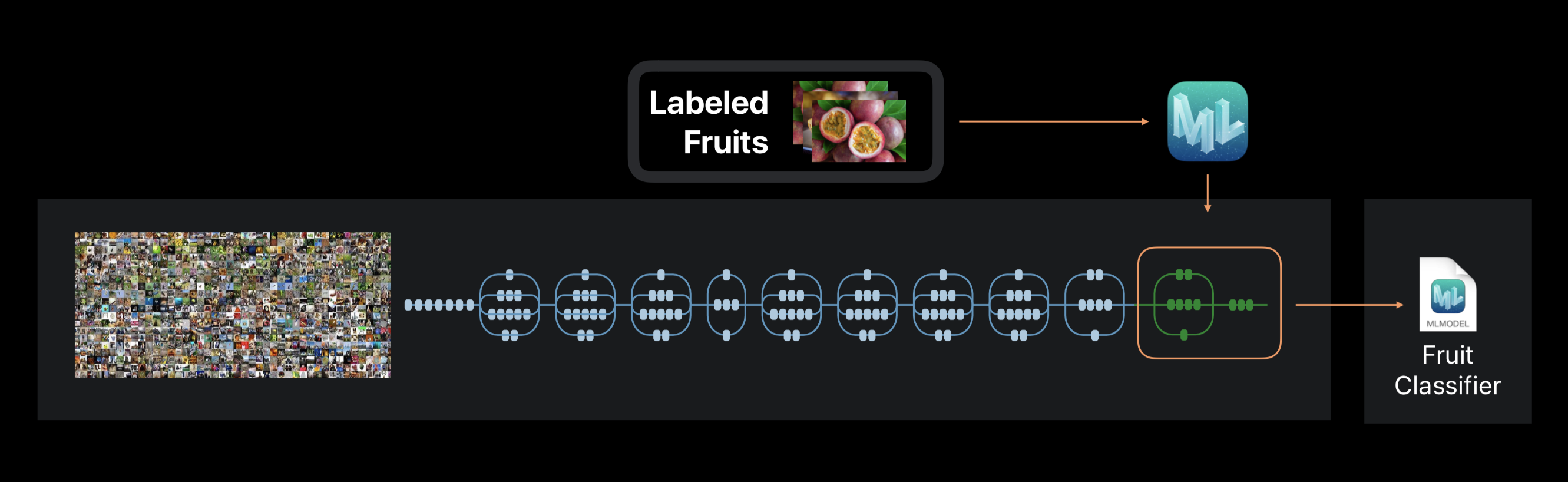
Эта технология называется transfer learning (перенос обучения). С ее помощью можно изменить архитектуру предварительно обученной сети так, чтобы она подходила для решения новой задачи. Измененная сеть затем обучается на новом наборе данных.
Create ML во время обучения извлекает из фото около 1000 отличительных признаков. Это могут быть формы объектов, цвет текстур, расположение глаз, размеры, и множество других.
Следует отметить, что исходный набор данных, на котором обучена используемая нейронная сеть, как и наш, может содержать фотографии кошек, собак и птиц, но в нем не выделяются конкретно именно эти категории. Все категории образуют иерархию. Поэтому и просто применить в чистом виде эту сеть нельзя — необходимо дообучить ее на наших данных.
По окончании процесса мы видим, насколько точно была обучена и проверена наша модель после нескольких итераций. Чтобы повысить результаты, мы можем увеличить количество изображений в исходном наборе данных или изменить количество итераций.
Далее мы можем сами проверить модель на тестовом наборе данных. Изображения в нем должны быть уникальны, т.е. не входить в исходный набор.
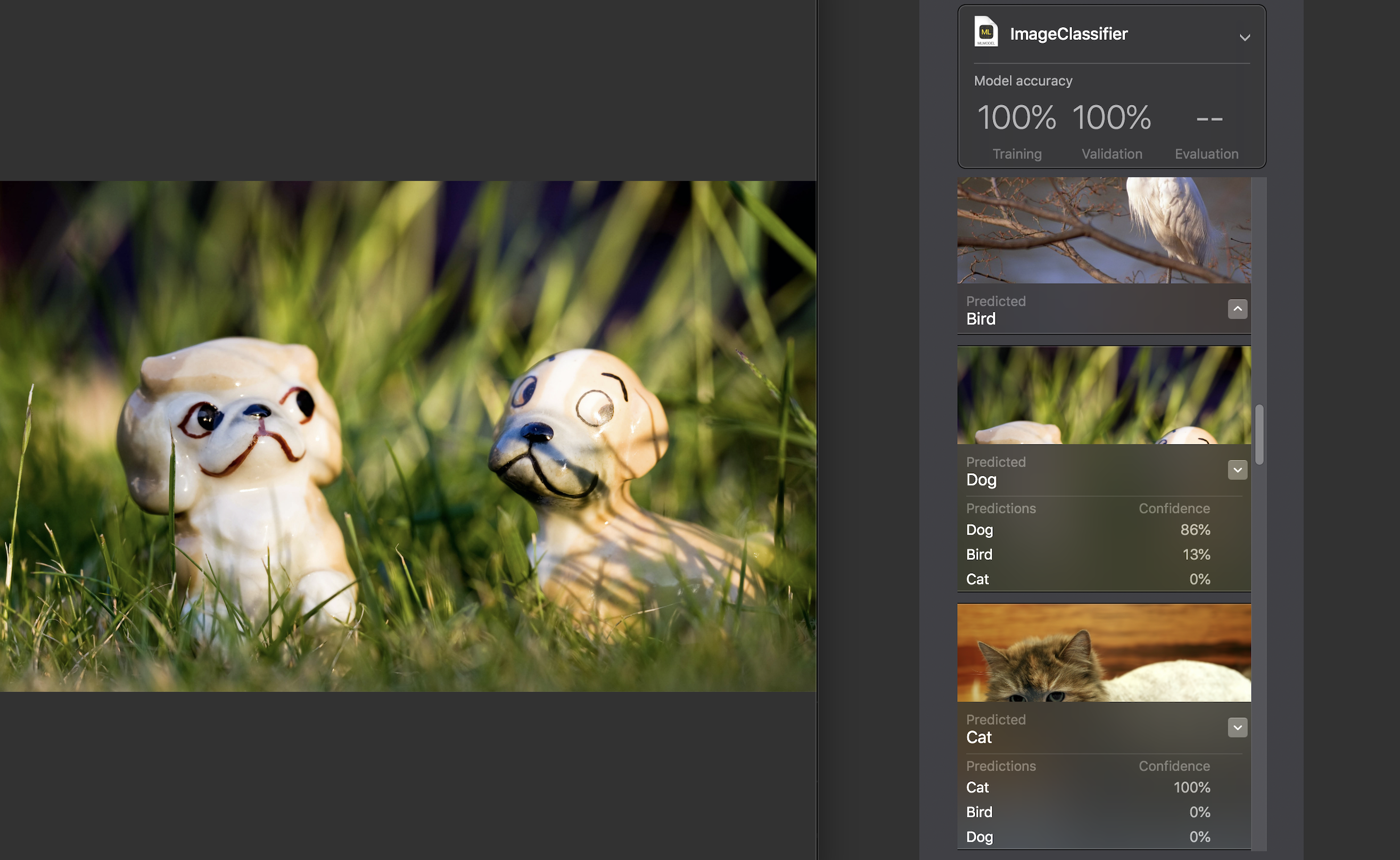
Для каждого изображения отображается показатель confidence — насколько точно с помощью нашей модели была распознана категория.
Практически для всех фотографий, за редким исключением, этот показатель составил 100%. Я специально добавил в тестовый датасет изображение, которое вы видите выше, и, как можно заметить, Create ML распознал в нем на 86% собаку и на 13% птицу.
Обучение модели завершено, и все, что нам остается, сохранить файл *.mlmodel и добавить его в свой проект.
Для тестирования модели я написал простое приложение, использующее фреймворк Vision. Он позволяет работать с моделями Core ML и решать с их помощью такие задачи, как классификация изображений или обнаружение объектов.
Наше приложение будет распознавать картинку с камеры устройства и выводить на экран категорию и процент уверенности в правильности классификации.
Инициализируем Core ML модель для работы с Vision и настроим запрос:
func setupVision() {
guard let visionModel = try? VNCoreMLModel(for: AnimalsClassifier().model)
else { fatalError("Can't load VisionML model") }
let request = VNCoreMLRequest(model: visionModel) { (request, error) in
guard let results = request.results else { return }
self.handleRequestResults(results)
}
requests = [request]
}
Добавим метод, который будет обрабатывать полученные результаты VNCoreMLRequest. Отобразим только те, у которых показатель confidence больше 70%:
func handleRequestResults(_ results: [Any]) {
let categoryText: String?
defer {
DispatchQueue.main.async {
self.categoryLabel.text = categoryText
}
}
guard let foundObject = results
.compactMap({ $0 as? VNClassificationObservation })
.first(where: { $0.confidence > 0.7 })
else {
categoryText = nil
return
}
let category = categoryTitle(identifier: foundObject.identifier)
let confidence = "\(round(foundObject.confidence * 100 * 100) / 100)%"
categoryText = "\(category) \(confidence)"
}
И последнее — добавим метод делегата AVCaptureVideoDataOutputSampleBufferDelegate, который будет вызываться при каждом новом кадре с камеры и выполнять запрос:
func captureOutput(
_ output: AVCaptureOutput,
didOutput sampleBuffer: CMSampleBuffer,
from connection: AVCaptureConnection) {
guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else {
return
}
var requestOptions: [VNImageOption: Any] = [:]
if let cameraIntrinsicData = CMGetAttachment(
sampleBuffer,
key: kCMSampleBufferAttachmentKey_CameraIntrinsicMatrix,
attachmentModeOut: nil) {
requestOptions = [.cameraIntrinsics:cameraIntrinsicData]
}
let imageRequestHandler = VNImageRequestHandler(
cvPixelBuffer: pixelBuffer,
options: requestOptions)
do {
try imageRequestHandler.perform(requests)
} catch {
print(error)
}
}Проверим, насколько хорошо справляется со своей задачей модель:

Категория определяется с довольно высокой точностью, и это особенно удивительно, если учесть, насколько быстро прошло обучение и насколько мал был исходный датасет. Периодически на темном фоне модель выявляет птиц, но думаю, это легко решается увеличением количества изображений в исходном наборе данных или повышением минимально допустимого уровня confidence.
Если мы захотим дообучить модель для классификации еще какой-либо категории, достаточно добавить новую группу изображений и повторить процесс — это займет считанные минуты.
В качестве эксперимента я сделал другой набор данных, в котором поменял все фотографии кошек на фото одного кота с разных ракурсов, но на одном и том же фоне и в одном и том же окружении. В этом случае модель начала практически всегда ошибаться и распознавать категорию в пустой комнате, видимо, в качестве ключевого признака положившись на цвет.
Еще одна интересная функция, представленная в Vision только в этом году — возможность распознавания объектов на изображении в реальном времени. Она представлена классом VNRecognizedObjectObservation, позволяющим получить категорию объекта и его расположение — boundingBox.

Сейчас Create ML не позволяет создавать модели для реализации этого функционала. Apple предлагает в этом случае воспользоваться Turi Create. Процесс не сильно сложнее вышеописанного: необходимо подготовить папки-категории с фотографиями и файл, в котором для каждого изображения будут указаны координаты прямоугольника, где находится объект.
Natural Language Processing
Cледующая функция Create ML — обучение моделей для классификации текстов на естественном языке — например, для определения эмоциональной окраски предложений или выявления спама.
Для создания модели мы должны собрать таблицу с исходным набором данных — предложениями или целыми текстами, отнесенными к определенной категории, и обучить с помощью нее модель, используя объект MLTextClassifier:
let data = try MLDataTable(contentsOf: URL(fileURLWithPath: "/Users/CreateMLTest/texts.json"))
let (trainingData, testingData) = data.randomSplit(by: 0.8, seed: 5)
let textClassifier = try MLTextClassifier(trainingData: trainingData, textColumn: "text", labelColumn: "label")
try textClassifier.write(to: URL(fileURLWithPath: "/Users/CreateMLTest/TextClassifier.mlmodel"))В данном случае обученная модель имеет тип Text Classifier:
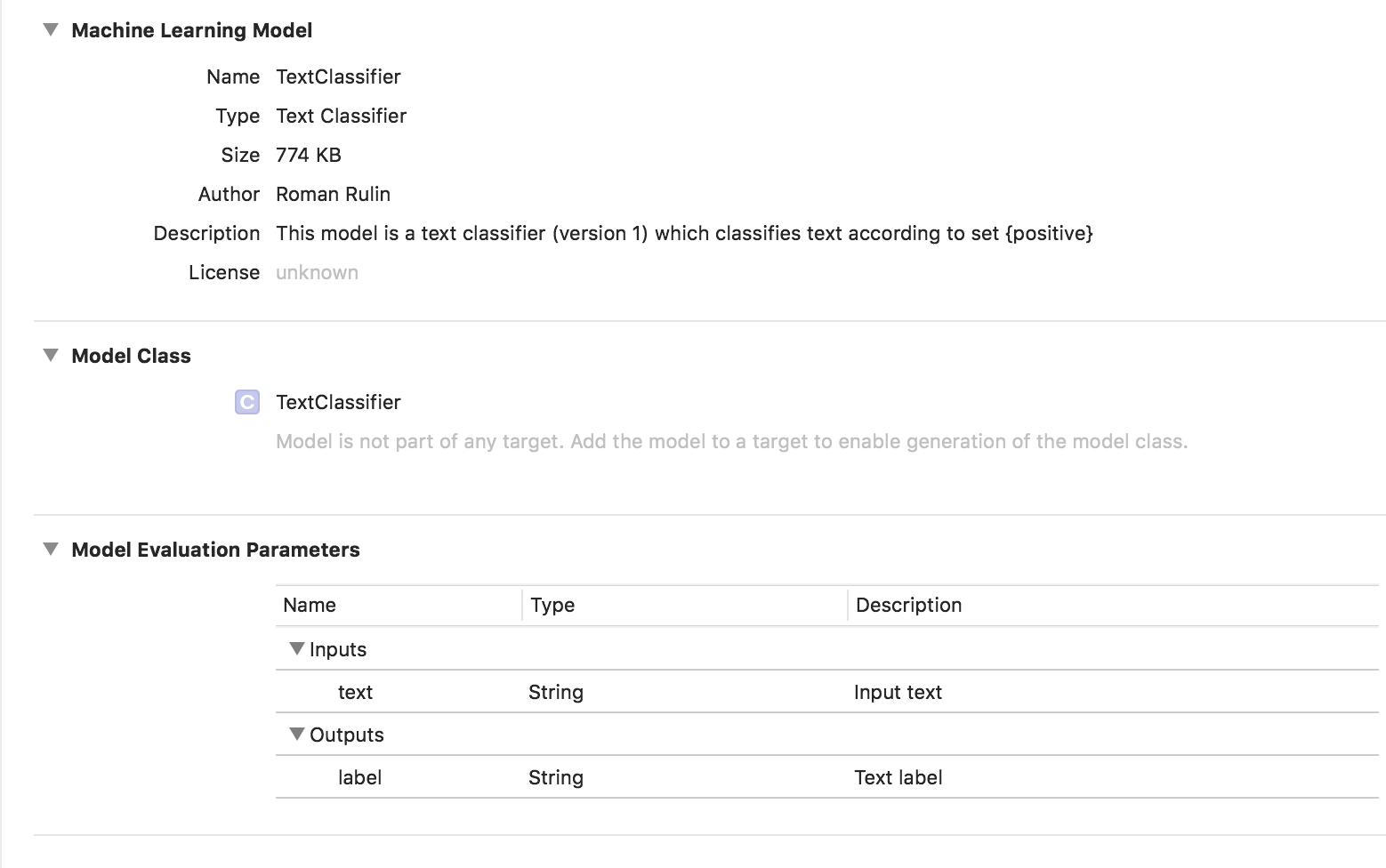
Табличные данные
Рассмотрим подробнее другую особенность Create ML — обучение модели с помощью структурированных данных (таблиц).
Напишем тестовое приложение, предсказывающее цену на квартиру исходя из ее расположения на карте и других заданных параметров.
Итак, у нас есть таблица с абстрактными данными о квартирах в Москве в виде csv-файла: известна площадь каждой квартиры, этаж, количество комнат и координаты (широта и долгота). Помимо этого, известна стоимость каждой квартиры. Чем ближе к центру или чем больше площадь, тем выше цена.
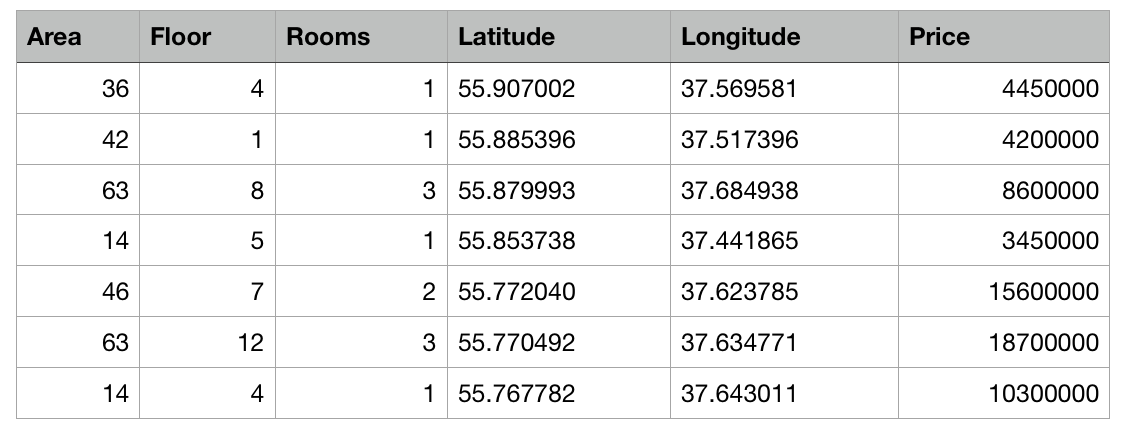
Задачей Create ML будет построение модели, способной на основе указанных признаков предсказать цену квартиры. Такая задача в машинном обучении называется задачей регрессии и является классическим примером обучения с учителем.
Create ML поддерживает множество моделей — Linear Regression, Decision Tree Regression, Tree Classifier, Logistic Regression, Random Forest Classifier, Boosted Trees Regression, и др.
Мы воспользуемся объектом MLRegressor, который на основе входных данных сам подберет оптимальный вариант.
Сначала инициализируем объект MLDataTable содержимым нашего csv-файла:
let trainingFile = URL(fileURLWithPath: "/Users/CreateMLTest/Apartments.csv")
let apartmentsData = try MLDataTable(contentsOf: trainingFile)Разделяем исходный набор данных на данные для обучения модели и тестирования в процентном соотношении 80/20:
let (trainingData, testData) = apartmentsData.randomSplit(by: 0.8, seed: 0)Создаем модель MLRegressor, указывая данные для обучения и название колонки, значения которой хотим предсказывать. Специфичный для задачи тип регрессора (linear, decision tree, boosted tree или random forest) будет выбран автоматически на основе исследования входных данных. Также мы можем указать feature columns — конкретные колонки-параметры для анализа, но в данном примере в этом нет необходимости, будем использовать все параметры. В конце сохраним обученную модель и добавим в проект:
let model = try MLRegressor(trainingData: apartmentsData, targetColumn: "Price")
let modelPath = URL(fileURLWithPath: "/Users/CreateMLTest/ApartmentsPricer.mlmodel")
try model.write(to: modelPath, metadata: nil)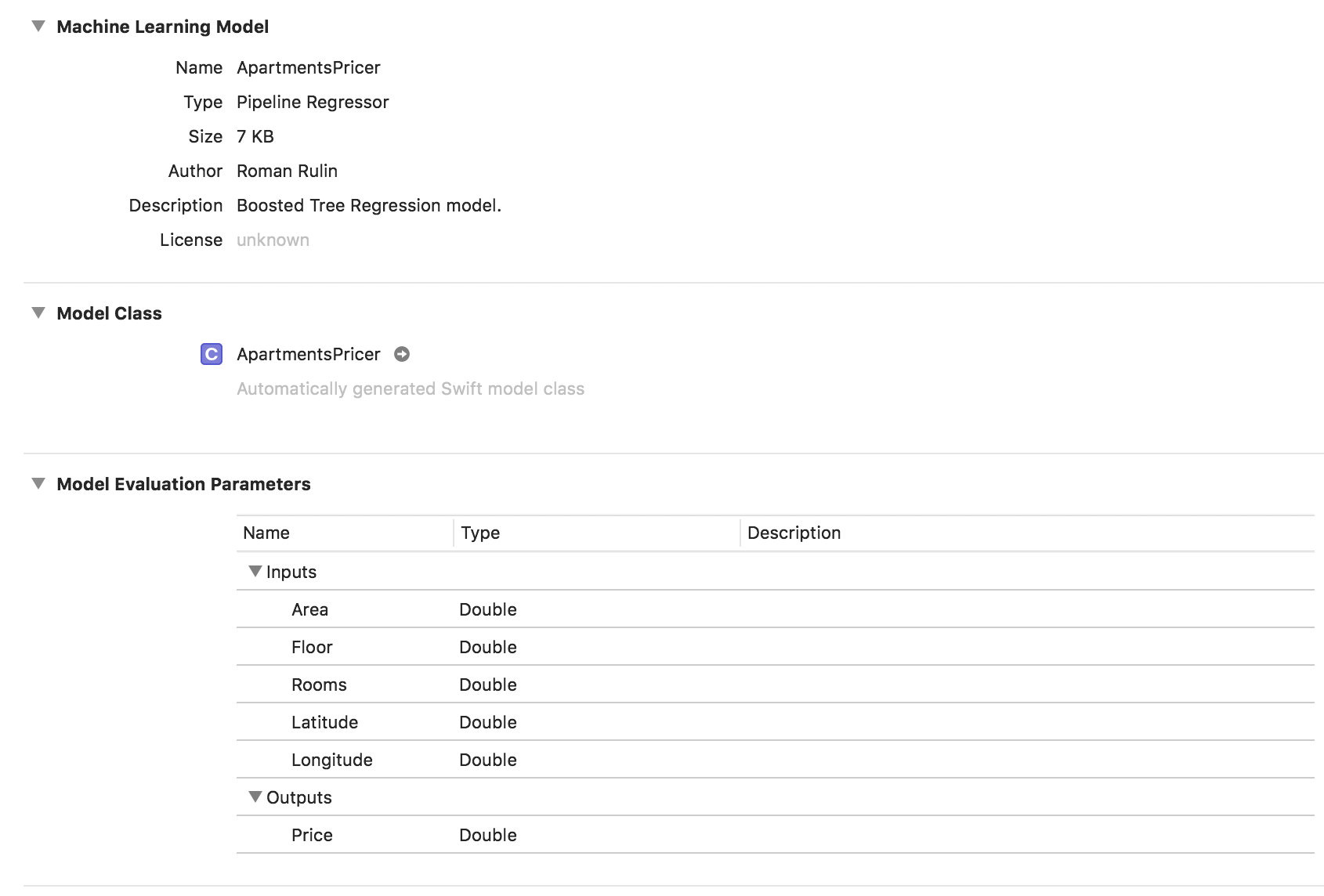
В этом примере мы видим, что тип модели уже Pipeline Regressor, а в поле Description указан выбранный автоматически тип регрессора — Boosted Tree Regression Model. Параметры Inputs и Outputs соответствуют колонкам таблицы, но тип данных у них стал Double.
Теперь проверим получившийся результат.
Инициализируем объект модели:
let model = ApartmentsPricer()Вызываем метод prediction, передавая в него указанные параметры:
let area = Double(areaSlider.value)
let floor = Double(floorSlider.value)
let rooms = Double(roomsSlider.value)
let latitude = annotation.coordinate.latitude
let longitude = annotation.coordinate.longitude
let prediction = try? model.prediction(
area: area,
floor: floor,
rooms: rooms,
latitude: latitude,
longitude: longitude)
Отображаем предсказанное значение стоимости:
let price = prediction?.price
priceLabel.text = formattedPrice(price)Меняя точку на карте или значения параметров, получаем довольно близкую к нашим тестовым данным стоимость квартиры:
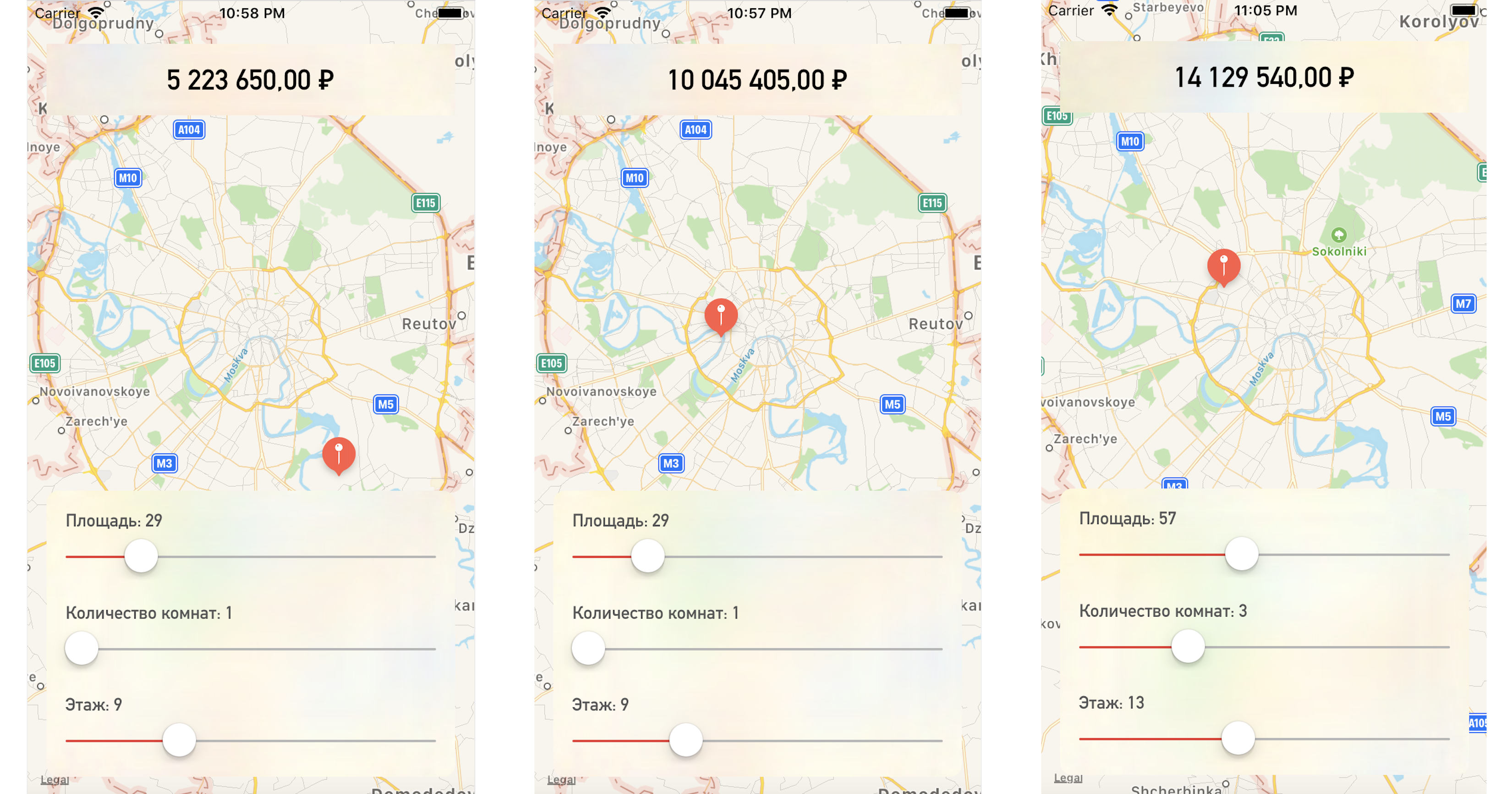
Заключение
Сейчас фреймворк Create ML — один из самых простых способов работы с технологиями машинного обучения. Он пока не позволяет создавать модели для решения некоторых задач: распознавания объектов на изображении, стилизации фото, определения похожих изображений, распознавания физических действий на основе данных акселерометра или гироскопа, с чем, например, справляется Turi Create.
Но стоит отметить, что Apple довольно серьезно продвинулась в данной сфере за прошедший год, и, наверняка, вскоре мы увидим развитие описанных технологий.
Комментарии (25)

ZloyKishechnik
26.07.2018 20:15Очень интересно. Пойду ставить Mojave (по второму разу) и пробовать ML. Спасибо за гайд/статью)
roryorangepants
Можно, пожалуйста, описание эксперимента? Какие модели и сеттинги обучения сравнивались? Описанные цифры звучат фантастически.
mc_murphy
Посмотрите сессии с WWDC на тему CreateML. Вкратце — они обучали не всю модель, а только дообучали последние слои. Собственно, эта возможность и есть нововведение.
roryorangepants
Нововведение по сравнению с чем? Это обычная практика transfer learning, придуманная кучу лет назад.
Почему стандартная вещь, которую все и так делают, подаётся как какая-то невероятная киллер фича CreateML?
mc_murphy
Плюс в том, что они вшили много предобученных моделей в систему, которые можно частично реиспользовать, не поставляя с приложением все 200–300МБ. Для мобильных устройств и подгрузки на ходу это довольно актуально.
Киллер-фича это или нет — вопрос в сторону Apple :)
roryorangepants
MobileNet-ы весят по 20 Мб. Прунинг есть, опять же. Квантификация. Всё же лучше, чем заниматься deep learning на внутреннем фреймворке от Apple.
Инфраструктура глубокого обучения движется в сторону того, что на embedded девайсах и на мобильных всё делается на TF, а при серверной разработке — на TF/Keras или PyTorch. Но нет, Apple пытается перетянуть на себя одеяло.
Ну вообще это вопрос в сторону автора, который с восторгом пишет про сокращение времени на обучение с 24 часов на 48 минут.
vics001
Если линейная экстраполяция работает, то сократить время обучения с 24 дней до 20 часов, несомненно киллер-фича, но не теоретическая, так как все знают как это было, а практическая!
Несомненно это расширит сферу применений, а вот полезные они будут или нет, покажет время.
roryorangepants
Так я не говорю, что это бесполезно. Я говорю, что все, кроме iOS-разработчиков по всей видимости, это и так делают уже несколько лет, и тут приходит Эппл и преподносит это как чудо.
Flux
Это, собственно говоря, стандартная практика в яблочном мире.
yarric
Вы говорите, что Эппл зря выкатила собственную реализацию машинного обучения в прошлом году, вместо того, чтобы остановиться на гугловской, которую Гугл тоже выкатил в прошлом году?
roryorangepants
Я говорю, что Apple зря хвастаются «прорывными» достижениями, потому что на самом деле в гонке технологий ML/DL они являются абсолютными аутсайдерами среди крупных компаний.
CreateML вышел в июне 2018. Tensorflow for mobile появился несколько лет назад. У вас проблемы с таймлайнами.
Ну, если бы Apple развивали CoreML как обёртку над нормальными ML-фреймворками, а не выдумывали очередное «машинное обучение через GUI мышкой», то это было бы лучше и для ML инженеров, и для юзеров, которые бы получали потенциально более качественные алгоритмы, но, очевидно, для Apple это хуже.
yarric
В каком месте они хвастаются и вообще где написано что-то про «прорывность» достижений?
А юзабельный Face ID на кастомном нейронном сопроцессоре они, тем не менее, первыми запилили...
CoreML вышел в июне 2017-го, TF Mobile — в феврале 2017-го.
В чем «ненормальность» эппловского фреймворка? Алгоритмы обучения нейронных сетей не Гугл изобрёл, если что.
В MATLAB машинное обучение аналогично выглядит, даже аналог playgrounds есть. Просто Гуглу, как обычно, лень допиливать свои инструменты, поэтому в туториалах по TF юзается консолька и brew. Логично, что Apple запилила свой фреймворк с нормальной интеграцией в свои инструменты.
roryorangepants
В том отрывке статьи, к которому я изначально прикопался, и в демо на WWDC собственно.
Сейчас бы называть CoreML фреймворком машинного обучения…
Breaking news! Apple представили первую в мире идентификацию лица!
Ох, стоп. Они же всего лишь навсего стали первыми, кто смог достаточно хорошо распиарить эту фичу и имели свои телефоны, в которые это можно было засунуть.
А так face recognition в том или ином виде был раньше и у Samsung, и у Microsoft.
В том, что это high-level blackbox фреймворк, который позволяет делать очень ограниченный набор вещей и работает только для нескольких стандартных задач. Сделать на нём что-то кастомное — задача для любителей жёстких извращений.
Также этот фреймворк не является кроссплатформенным. Т.е. если у вас веб, iOS и Android-приложения, то вам придется делать ML-часть отдельно, что не особо логично. И в конце концов он на свифте, который является мягко говоря не самым подходящим языком для ML (для начала потому что большинство дата саентистов его не знают).
Во-первых, лол, нет. Во-вторых, никто сейчас Matlab-ом не пользуется.
Не поверите, в реальности юзается не «консолька», а Python, и не потому, что «Гуглу лень допиливать инструменты», а потому что для чего-то большего, чем «Ну вот стандартная архитектура с выходным слоем под классификацию, вот папка картинок — обучайся», нужно реально кодить, а не в менюшке выбирать аугментацию из чекбокса.
olegi
лицорука.
заслуга эппла в том, что была бесшовная миграция с touchid -> faceid. и банковские апп спокойно используют его для подтверждения операций. А на ведре и винде и face recognition только и служит для анлока девайса.
прям смешно стало за пользователя самсунга.
yarric
И где в статье говорится про прорывность достижений? В статье говорится про прорывность для данного конкретного фреймворка. Кстати интересно бы сравнить его с питонскими — что-то мне подсказывает, что нативный Swift в сравнении с ними вполне может быть прорывным по скорости.
В том или ином виде face recognition был ещё до появления MS и Samsung. Apple сделали из него юзабельный продукт, а не маркетинговый buzzword.
Между Create ML и гугловским ML Kit существенных различий не обнаружено так-то.
Традиционная дилемма "сделать медленно и криво, но кроссплатформенно" или "сделать быстро и красиво, но под конкретную платформу".
Сильный аргумент, нечего сказать даже.
MATLAB в топ-10 PYPL, в топ-15 TIOBE — нормально пользуются, особенно в США и Европе. На аутсорсе Python с его тулзами более популярен — из-за дороговизны MATLAB и наличия дешевых code monkey, времени которых не жалко.
Удобные инструменты для создания базовых вещей никак не мешают кодить. Разработка превращается в треш, если для того, чтобы поставить тулзу, тебе нужно тащить левую приблуду вместо штатных средств разработки.
Flux
Ну, так-то что свифт что питон являются только обертками для кода на нормальном языке, мерять скорость интеропа с плюсам — такая себе прорывность.
И да, эпплу бы сначала язык стабилизировать, а уж потом использовать его для «новых и революционных» ML библиотек. Но яблоку это нафиг не надо, яблоку надо намертво заковать разработчика в кандалы своих проприетарных тулзов, как и в случае с тем же xcode.
olegi
swift пилят мужики из комитета по с++
en.wikipedia.org/wiki/David_Abrahams_(computer_programmer)
Возможно, что Swift будет улучшенной версией C++
yarric
Да пользуйтесь любыми
колхозными«свободными» тулзами, кто вам мешает. Только опенсоурс-сообщество ниасилило даже годную среду разработки на свет произвести, не говоря уже обо всем остальном, потому как его участникам больше нравится проповедовать высокие идеалы в комментах, чем кодить. А потому имеем, что имеем: хочешь нормально работать и ценишь своё время — юзай проприеритарщину, хочешь ковырять консоль, конфы и исходники вместо выходных с друзьями или с семьёй — юзать опенсорс.olegi
как я понимаю:
1) CreateML — набор тулзов для обучения на десктопе, а TFM/TFL — работать с моделями на мобилке. — это разные вещи. CoreML как раз и появился раньше TFM\TLM в iOS из коробки.
2) «если бы Apple развивали CoreML как обёртку над нормальными ML-фреймворками» — Apple использует Turi, разработчиков которых они купили несколько лет назад, афаик Turi появилась раньше ТФ.
Отсюда вопрос — сфигали ТФ единственное правильные тулзы для МЛ-ДЛ?
Flux
Разумеется ТФ не единственная правильная тула для ML/DL. Есть же еще PyTorch, CNTK, Caffe, LightGBM, CatBoost, XGBoost, libSVM и великое множество других нормальных библиотек.
Их отличительной особенностью является то что они открытые, расширяемые, кроссплатформенные и не пытаются замкнуть пользователя в своей экосистеме и ограничить создание моделей до «press X to train model».
olegi
1) тури — опенсоурсное.
2) кроссплатформеность — это сказка в пользу бедных. или как пишет Стивен Синофски — если вы используете кроссплатформенность, значит вы решаете свои проблемы, а не проблемы пользователя.
Эппловое решение хорошо тем, что на эппловом устройстве оно будет работать эффективнее, чем фигзнаеткак оптимизированный тензорфлоу.
и будет смешно смотреть, если тензорфлоу аппы будут сваливаться на CPU вместо GPU на каких нить сяоми с МТК.
papercuter
Потому что это политика Apple, они всегда так делают :)
olegi
потому что эпплове решения уже используются в проде, а у конкурентов всё только в виде research papers
Flux
Использую tf + keras + tf lite в проде.
И да, мне показалось или вы утверждаете что у того же гугла в проде не используется ML пайплайны на их же тулах?
olegi
я о том, что есть ли аналог createml у других фреймворков. выше писали, что сама идея не нова, окей, но где gui тулза, а не ковыряние в консоли с питоном.