
В небольшой команде тимлид может попытаться судить обо всем происходящем на основе субъективных ощущений, но, чем больше компания, тем важнее использовать объективные данные и метрики. Александр Киселев (AleksandrKiselev) и Сергей Семенов в своем докладе на TeamLead Conf показали, как использовать данные, которые вы уже накопили, где взять дополнительные, и что они все вместе могут помочь определить неочевидные проблемы. И даже, аккумулировав опыт многих коллег, предложили варианты решения.
О спикерах: Александр Киселев и Сергей Семенов в IT мы уже больше 8 лет. Оба прошли путь от разработчика до тимлида и далее до product-менеджера. Сейчас работают над аналитическим сервисом GitLean, который автоматически собирает аналитику у команд разработки для тимлидов и CTO. Задача этого сервиса в том, чтобы технические менеджеры могли принимать свои решения на основе объективных данных.
Постановка проблемы
Мы оба работали тимлидами и нередко сталкивались с проблемой неопределенности и неоднозначности в нашей работе.

В итоге приходилось достаточно часто принимать решения вслепую, и порой не было понятно, стало лучше или хуже. Поэтому мы посмотрели на существующие на рынке решения, исследовали методологии по оценке перформанса разработчиков, и поняли, что сервиса, который удовлетворял бы нашим потребностям, не существует. Поэтому мы решили создать его сами.
Сегодня мы поговорим о том, что вам могут рассказать данные, которые вы уже накопили, но, скорее всего, не используете.

Это нужно в двух основных случаях.
Перформанс ревью — достаточно сложный и субъективный процесс. Было бы здорово, собирать факты о работе разработчика автоматически.
Мы разговаривали с представителями одной крупной немецкой компании с большим штатом разработки. Они примерно раз в год останавливали вообще всю работу разработки на 2 недели, и только и делали, что всей компанией проводили перформанс ревью — разработчики целый день писали анонимные доносы на коллег, с которыми они поработали за год. Если бы у этой компании была возможность собирать факты автоматически, они бы сэкономили себе кучу времени.
Второй аспект — мониторинг текущей ситуации в команде. Хочется быстро понимать проблемы, которые возникают, и оперативно на них реагировать.
Варианты решений
Может быть несколько вариантов решения.

Во-первых, можно вообще не пользоваться никакой аналитикой, а только своей субъективной оценкой. Это работает, если вы тимлид в небольшой команде. Но если вы уже CTO, и у вас достаточно много команд, то своей субъективной оценкой воспользоваться не получится, потому что вы не все знаете. Вам придется прибегнуть к субъективной оценке своих тимлидов, а это проблема, так как достаточно часто тимлиды совершенно по-разному подходят к субъективной оценке.

Это следующее, что можно сделать. Поскольку субъективной оценки часто бывает недостаточно, можно заморочиться и собирать факты руками.
Например, один CTO, с которым мы разговаривали, как-то заподозрил команду в том, что они делают код-ревью слишком медленно, но предъявить им было нечего. Поскольку у него было лишь смутное ощущение, он решил пособирать факты, просто пару недель понаблюдать за командой. CTO заносил в табличку время прохождения ревью команды, и то, что он обнаружил в итоге, просто его шокировало. Оказалось, что 2 сеньора достаточно долгое время конфликтовали в код-ревью, при этом они вообще никак не выносили это вовне. Они сидели как мышки, никто ни на кого не кричал — команда вообще не была в курсе. Единственное, что они делали, это периодически шли до кулера, наливали себе еще водички и бежали писать остроумные ответы в код-ревью своему врагу в pull-request.
Когда CTO это узнал, оказалось, что проблема настолько застаревшая, что cделать уже ничего было нельзя, и в итоге вообще пришлось уволить одного из программистов.

Статистика по Jira — вариант, который достаточно часто используется. Это очень полезный инструмент, в котором есть информация о задачах, но он достаточно высокоуровневый. Часто сложно понять, что происходит в команде конкретно.
Простой пример — разработчик в предыдущем спринте сделал 5 задач, в этом — 10. Можно ли сказать, что он стал работать лучше? Нельзя, потому что задачи бывают совершенно разные.

Последний вариант решения, который есть — просто засучить рукава и написать свой скрипт для автоматического сбора данных. Это путь, к которому более-менее приходят все CTO в крупных компаниях. Он самый результативный, но, естественно, самый сложный. Именно о нем мы будем сегодня говорить.
Выбранное решение
Итак, выбранное решение — запилить свои скрипты для сбора аналитики. Главные вопросы при этом, откуда брать данные и что измерять.
Источники данных
Основные источники данных, в которых накапливается информация о работе разработчика, это:
- Git — основные сущности: коммиты, ветки и код внутри них.
- Инструменты код-ревью — git-хостинги, в которых проводится код-ревью, хранят информацию о pull-request, которую можно использовать.
- Таск-трекеры — информация о задачах и их жизненным циклом.
Вспомогательные источники данных:
- Мессенджеры — там можно, например, проводить сентимент-анализ, считать среднее время отклика разработчика на запрос на информацию.
- CI сервисы, которые хранят информацию о сборках и релизах.
- Опросы команды.
Поскольку все источники, о которых я рассказал выше, более-менее стандартные, а последний — не такой стандартный, расскажу о нем чуть побольше.
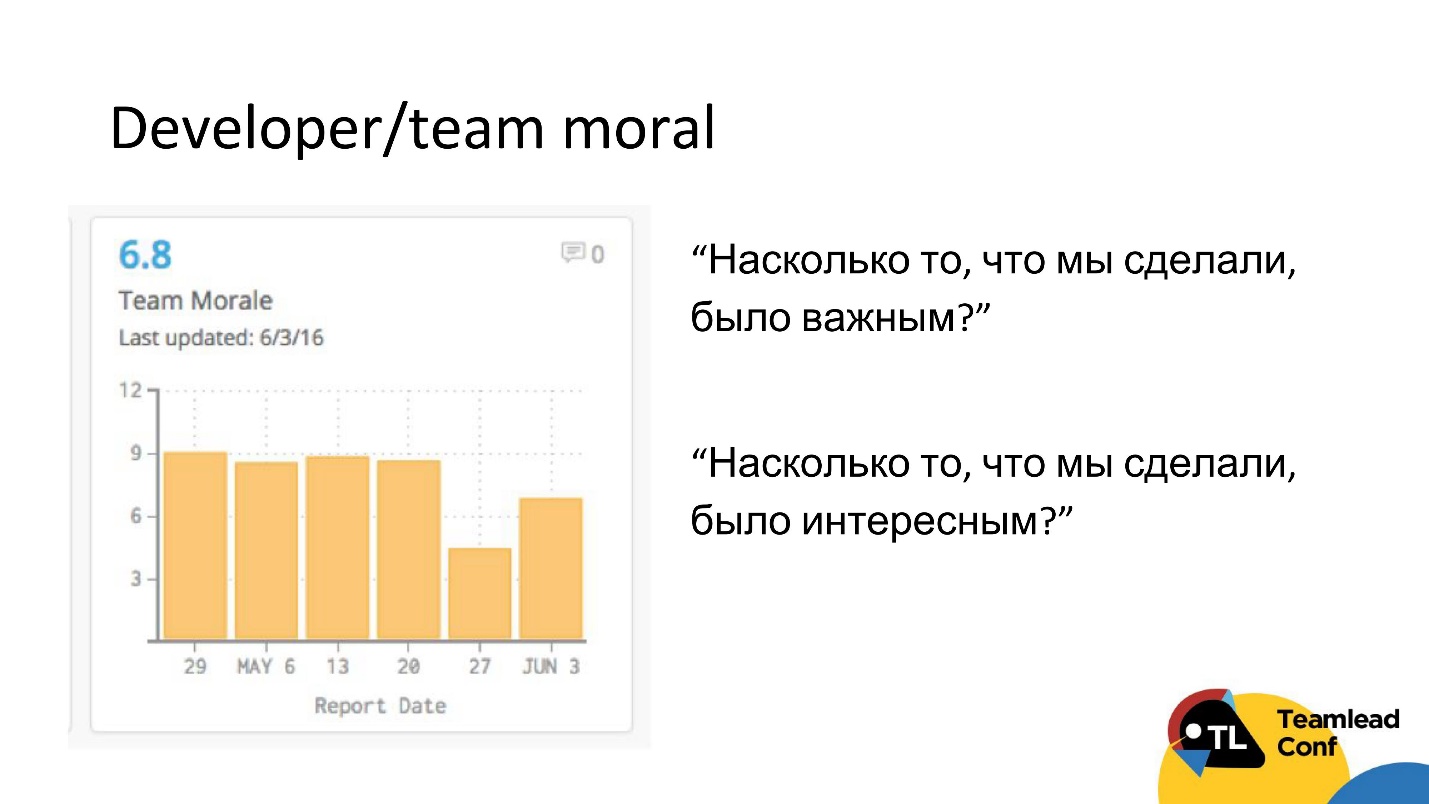
Этим методом с нами поделился другой CTO. В конце каждой итерации он рассылал команде автоматически опрос, в котором было всего 2 вопроса:
- Как вы считаете, насколько то, что мы сделали в этой итерации, было важным?
- Как вы считаете, было ли интересным то, что мы делаем?
Этот достаточно дешевый способ измерить настроение в команде и, может быть, поймать какие-то проблемы с мотивацией.
Что и как мерить
Прежде всего обсудим методологию измерений. Хорошая метрика должна отвечать на 3 вопроса:
- Важно ли это? Нужно измерять только то, что сигнализирует о чем-то существенном для компании.
- Стало хуже/лучше/так же? По метрике должно быть кристально понятно, стало ли лучше или хуже.
- Что делать? Из метрики должно быть понятно, что делать для того, чтобы исправить ситуацию.
В общем, стоит руководствоваться принципом:
Измеряйте то, что хотите и можете изменить.
Стоит сразу оговориться, что универсальной метрики нет, и мы об универсальной метрике говорить сегодня не будем по следующим причинам:
- У разработчика много аспектов деятельности — он работает с требованиями, пишет код, тесты, проводит код-ревью, делает деплой — и все это запихнуть в одну-единственную универсальную метрику невозможно. Поэтому лучше сфокусироваться на отдельных кейсах, которые можно детектировать.
- Вторая причина, по которой единственной метрики не стоит делать — одну метрику легко обойти, потому что разработчики достаточно умные люди, и они придумают, как одну это сделать.

Новый подход
Поэтому мы сформулировали подход, в котором идем от проблем: пытаемся выявить конкретные проблемы и подбираем под них набор метрик, которые будут их детектировать. Хорошим разработчиком будем называть разработчика с наименьшим количеством проблем.

На чем основан наш выбор проблем? Все просто: мы провели интервью с 37 CTO и тимлидами, которые рассказали о проблемах, которые есть у них в командах, и о том, как они эти проблемы решают.
Получившийся огромный список мы приоритезировали и собрали лайфхаки и метрики под эти проблемы. Все проблемы мы разбили на 2 группы:
- Проблемы индивидуального разработчика (за эти проблемы ответственен именно разработчик).

- Проблемы команды. За эти проблемы ответственна команда, соответственно, чтобы их разрешить, нужно работать в целом с командой и изменять именно процессные решения.

Рассмотрим подробно каждую проблему, какой ключик из метрик к ней можно подобрать. Начнем с самых простых проблем и потихоньку будем двигаться по градиенту сложности к наиболее сложно измеримым.
Проблемы разработчика
Разработчик мало перформит

Причем под «мало перформит» обычно подразумевается, что разработчик почти ничего не делает. Условно на нем висит тикет в Jira, он как-то по нему отчитывается, но реально никакой работы не происходит. Понятно, что эта проблема рано или поздно всплывет, вы ее обнаружите, но было бы круто делать это автоматически.
Как это можно измерить?
Первое, что приходит в голову — просто посмотреть на количество активных дней у разработчика. Активным днем будем называть день, когда разработчик сделал хоть один коммит. Для фултайм-разработчиков на самом деле характерное количество активных дней в неделю не меньше 3. Если меньше, то мы начинаем подозревать разработчика в том, что он мало перформит.
Очевидно, что только количества активных дней недостаточно. Разработчик мог просто писать код и не коммитить его — писал, писал, а потом в один прекрасный день закоммитил кучу кода.
Поэтому следующее ограничение, которое мы накладываем — это то, что у разработчика должно быть еще и мало кода. Как определить порог «мало кода»? Мы рекомендуем ставить его достаточно маленьким, чтобы любой, хоть сколько перформящий разработчик мог его легко преодолеть. Например, в нашем сервисе для JS это в районе 150 строк кода, а для Clojure — 100 строчек кода.
Почему такой маленький порог? Идея в том, что мы хотим отделить не круто работающих разработчиков от средне работающих, а тех, кто почти ничего не делает, от тех, кто делает хоть какой-то вменяемый объем работы.
Но даже если у разработчика мало активных дней и мало кода, это совсем не значит, что он не работал. Он мог, например, делать bug fixes, которые требуют малого количества кода. В результате человек вроде бы сделал много задач, но кода и активных дней у него может быть мало. То есть мы учитываем и количество задач.
Следующее, за чем стоит наблюдать — это количество код-ревью, который он делал, потому что человек мог не делать задачи и не писать кода, но при этом быть весь погружен в код-ревью. Такое бывает.
Поэтому если по всем из этих метрик — и только так! — разработчик не дотягивает до каких-то порогов, то можно заподозрить его в том, что он мало перформит.
Что с этим делать?
Во-первых, если вы знаете легитимную причину, то вообще ничего делать не нужно — например, разработчик проходит обучение или у него day off. Если вы легитимную причину не знаете, то, наверное, стоит поговорить с человеком. Если легитимная причина не появится, то стоит дальше его мониторить, и, если эта проблема продолжает иногда повторяться, то, наверное, с таким разработчиком стоит попрощаться.
Это была самая простая и самая провокационная проблема. Перейдем к более тяжелым.
Разработчик перерабатывает

Это тоже частая история. Если человек перерабатывает, он выгорает, в итоге демотивируется и, как следствие, может уйти из компании. Один из технических менеджеров, с которым мы общались, рассказал такую историю. Он работал в американской компании, в которой дико была развита культура митингов. В результате все разработчики, приходя на работу, только и делали, что митинговали, а код они писали в нерабочее время и по выходным. В результате ежегодная текучка разработчиков в компании достигала 30%, хотя по индустрии норма — 6%.
В итоге из этой конторы был уволен вообще весь технический менеджмент в составе 30 человек. Чтобы до такого не доводить, хочется эту проблему вовремя обнаружить.
Как это можно измерить?
На самом деле тоже ничего сложного — давайте посмотрим на количество кода, который разработчик пишет в нерабочее время. Если это количества кода условно сравнимо или больше, чем то, что он делает в рабочее время, то разработчик явно перерабатывает.
Очевидно, что не кодом единым живут разработчики. Частая проблема, что на код — основную работу — времени хватает, а на код-ревью уже нет. В результате код-ревью переносится на вечера или на выходные. Это можно отслеживать просто по количеству комментариев в pull-request в нерабочее время.
Последний явный триггер — это большое количество параллельных задач. Есть какое-то разумное ограничение в 3-4 задачи у разработчика. Трекать их можно по git или по Jira — как вам угодно. Это неплохо работает.
Что с этим делать?
Если вы обнаружили перерабатывающего разработчика, стоит прежде всего проверить его календарь, чтобы понять, не перегружен ли он бесполезными митингами. Если перегружен, желательно их сократить, а в идеале сделать meeting day — выделенный день, когда у разработчика будет сконцентрировано большинство его самых долгих митингов, чтобы в остальные дни он мог нормально работать.
Если этого сделать не получается, надо перераспределять нагрузку. Это на самом деле довольно сложный вопрос — как это делать. Существует большое количество разных способов. Не будем углубляться, но отмети крутой доклад на HighLoad 2017 от Антона Потапова, в котором эта тема очень плотно рассматривалась.
У разработчика нет фокуса на выпуске задач
Хочется понимать, сколько таких разработчиков в твоей команде и сколько это стоит по времени.

Довольно частая ситуация, что разработчик берет задачу, доводит ее до статуса in review, testing — и забывает про нее. Потом она возвращается на доработку и висит там непонятно сколько времени. У меня у самого в команде был такой разработчик в свое время. Я долго недооценивал проблему, пока однажды не посчитал количество времени, которое в среднем уходит на различные простои. В итоге получилось, что задачки этого разработчика в среднем от времени выпуска простаивали 60%.
Как это можно измерить?
Во-первых, надо померить все простои, которые зависят от разработчика. Это время внесения фиксов после код-ревью и тестирования. Если у вас есть continuous delivery, это время ожидания релиза. На каждое из этих времен стоит навесить разумное ограничение — типа не больше суток.
Причина в следующем. Когда разработчик приходит с утра на работу, было бы круто, чтобы он сначала разбирал самые приоритетные задачи. Самые приоритетные задачи, если нет каких-то bug fixes или чего-то очень важного — это задачи, которые наиболее близки к релизу и к выпуску.
Другой крутой триггер на эту тему — это количество код-ревью, которое висит на разработчике, как на ревьюере. Если человек забывает про свои задачи, то, скорее всего, он так же будет относиться к задачам своих коллег.
Что с этим делать?
Если вы такого разработчика обнаружили, явно стоит с цифрами на руках подойти к нему и сказать: «Смотри, у тебя 30—40% времени уходит на простои!" Обычно это очень круто работает. В моем случае, например, это возымело такой эффект, что проблема почти полностью ушла. Если нет, надо продолжать мониторить, периодически говорить, но главное тут не свалиться в микроменеджмент, потому что так будет еще хуже.
Поэтому по возможности стоит заниматься сразу процессными решениями. Это могут быть, например, лимиты на количество активных задач, или, если у вас позволяет бюджет и время, то можно написать бота или воспользоваться сервисом, который будет автоматически пинговать разработчика, если задача слишком долго находится в определенном статусе. Наверное, это самое крутое решение здесь.
Разработчик недостаточно продумывает задачи
Думаю, симптомы вы знаете — это непонятные оценки времени выполнения задач, в которые мы не попадаем, растянутые сроки в итоге, увеличение количества багов в задачах — в общем, ничего хорошего.

Как это можно измерить?
Думаю, симптомы вы знаете — это непонятные оценки времени выполнения задач, в которые мы не попадаем, растянутые сроки в итоге, увеличение количества багов в задачах — в общем, ничего хорошего.
Как это можно измерить?
Для этого нам потребуется ввести 2 метрики, первая из которых Churn кода.

Churn — это мера того, насколько много кода разработчик условно пишет напрасно.
Представим ситуацию. В понедельник разработчик начал делать новую задачу, и написал 100 строчек кода. Потом наступил вторник, он написал еще 100 новых строчек кода в этой задаче. Но, к сожалению, так получилось, что 50 строчек кода, которые были написаны в понедельник, он удаляет, и релизит задачу. В результате в задаче вроде бы было создано 200 строчек кода, но до релиза дожили только 150, а 50 были написаны напрасно. Эти 50 мы и называем Churn. И таким образом в этом примере Churn разработчика составил 25%.
На наш взгляд, высокий уровень Churn — это крутой триггер того, что разработчик не додумал задачу.
Есть исследование одной американской компании, в котором они измерили уровень Churn у 20 000 разработчиков и пришли к выводу, что хороший показатель Churn кода должен находиться в пределах 10–20 %.
Но тут есть 2 важных условия:
- Высокий Churn — нормально, если вы, например, делаете прототип или какой-то новый проект. Тогда он может быть равен 50-60% в течении нескольких месяцев. В этом нет ничего страшного. Грубо говоря, Churn зависит от этапа продукта — чем продукт стабильнее, тем он должен быть ниже.
- Ни в коем случае не стоит стремиться к нулевому уровню Churn — это абсолютно бессмысленный перфекционизм. Не надо заставлять разработчиков писать с чистого листа идеальный код. Они будут тратить очень много времени на продумывание или пытаться как-то хакать эту историю. В результате время delivery только увеличится.

Следующая метрика, которая понадобится для того, чтобы уточнить наличие того, что разработчик недостаточно продумывает таски, это так называемый Fixed Tasks, или количество исправленных задач. Это попытка измерить то, насколько много багов привносит задача разработчика.
Давайте посмотрим на то, какие bug fixes делают разработчики, и код каких задач эти bug fixes меняют. Если время между релизом таски и bug fixes меньше 3 недель, будем считать, что этот баг привнесла эта задача. Чем больше у разработчика пофикшенных задач, то есть чем больше он привносит багов, тем вероятнее про него можно сказать, что он недостаточно обдумывает таски.
Последний триггер — это среднее количество возвратов из тестирования. Если в среднем у разработчика больше одного возврата из тестирования на задачу, то, скорее всего, у него что-то не так в плане продумывания тасок.
Что с этим делать?
Если вы обнаружили у себя такого разработчика, возможно, стоит либо для него персонально, либо для всей команды увеличить время на планирование или поменять его процесс. Можно ввести процессные улучшения, например, ввести лимиты на размер таски, максимально допустимый размер estimation и т.д.
У одного CTO, с которым мы общались, был довольно крутой workflow, который нам очень нравится, всем его советуем. Если во время планирования выясняется, что оценка времени реализации задачи больше одного дня, или задача затрагивает больше одной компоненты в системе, то на нее в обязательном порядке пишется дизайн-документ, который отдельно ревьюится до реализации.
Условия для использования Churn и Fixed Tasks
Для того, чтобы эти метрики можно было измерять и отслеживать, нужно:
- Указывать номер таски в commit message, без этого вы не сможете их померить. Причем именно в commit message, а не в ветке, потому что git историю веток не хранит.
- Не делать git-squash commit’ов таски в один, потому что тогда Churn априори будет равен нулю.
- Должна быть возможность определять релиз по git. То есть релизы можно считать в merge в master, или merge в определенную ветку, или тэг на худой конец. Но возможность определить должна быть — иначе мы не можем понять, когда таска закончилась, и когда насчитывать Churn и Fixed Tasks.
Проблемы команды

Первая и одна из самых частых историй, про которую нам приходилось слышать — это неравномерное распределение знания кодовой базы в команде и то, что на сам деле хочется видеть людей условно с низким автобусным числом. Потому что плохо, когда есть незаменимые люди, которые умеют делать работу, которую больше не может делать никто. Если такого человека сбивает автобус, то разработка всей системы на какое-то время может остановиться.
Например, в моей практике был случай, когда из-за увольнения сеньора важный релиз был отложен на 3-4 недели. Это очень большой срок, и бизнес это не обрадовало.
Как это можно измерить?
Идея очень простая — надо каким-то образом померить, насколько уникальны знания того или иного разработчика, и насколько разработчики в целом осведомлены о работе соседей.
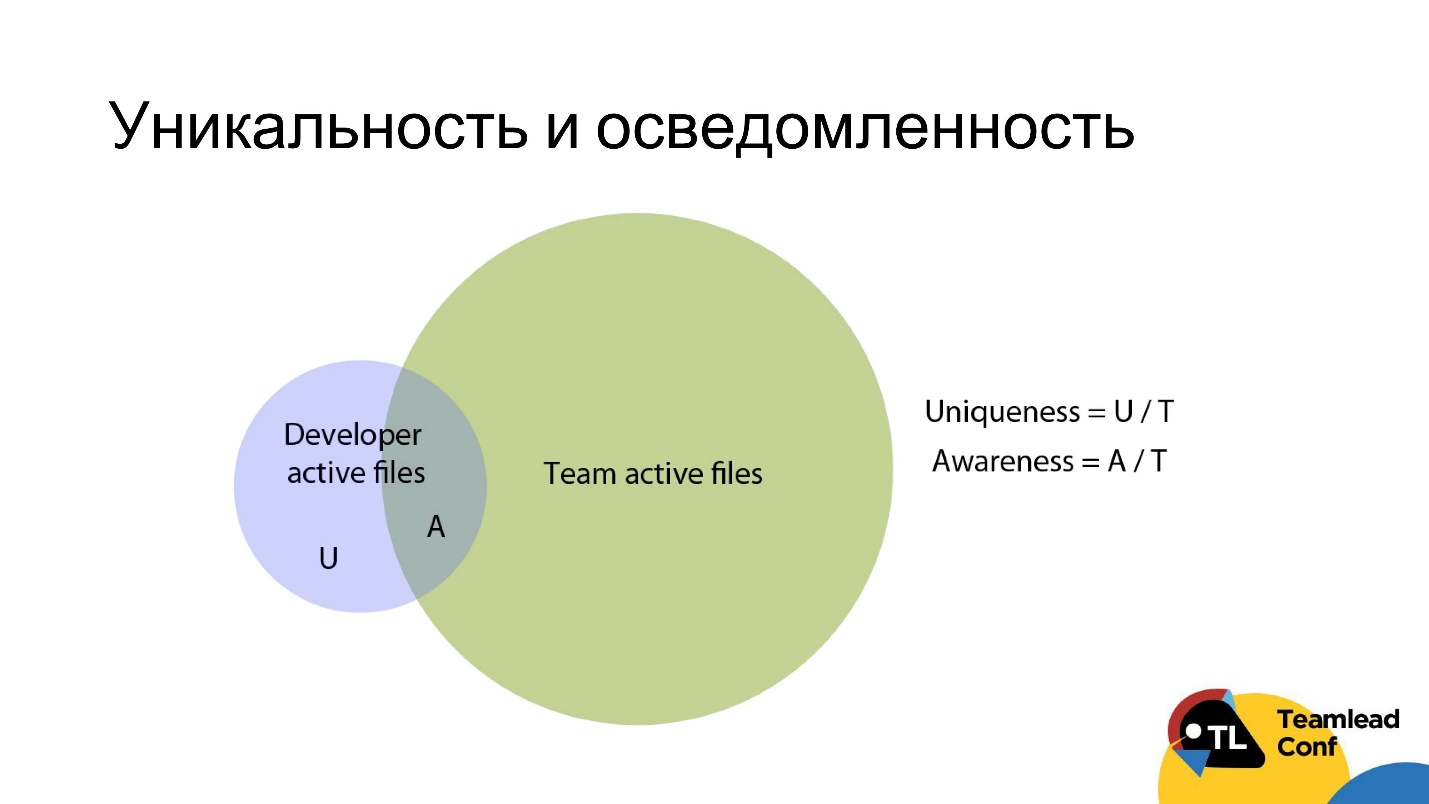
Для этого можно взять все файлы разработчика, с которыми он поработал за последние 3 месяца, и все файлы команды, над которыми работало сразу несколько разработчиков за этот же период (соответственно синий и зеленый круг на диаграмме), и пересечь эти два множества.
Уникальностью будем называть долю уникальных файлов разработчика, которые знает только он, от всех файлов команды. Осведомленностью — наоборот, долю неуникальных файлов от всех файлов команды.
Правило простое — если вы видите, что у вас разработчики с высокой долей уникальности или с низкой осведомленностью — как угодно — то, скорее всего, у вас есть проблема с неравномерностью распределения знаний кодовой базы.
Как с этим бороться?
На самом деле довольно легко. Можно просто зафиксировать порог уникальности, выше которого вы не хотите, чтобы появлялись разработчики. Тимлид или кто-то еще должен ротировать задачи среди разработчиков, чтобы никто из них выше этого порога не переходил.
Выбор порога — вопрос, конечно, не очень простой. Все зависит от ваших приоритетов. Чем выше перекрытие разработчиками, тем соответственно ниже скорость работы команды в краткосрочной перспективе, потому что они дублируют компетенции друг друга. Но зато тем меньше риски и тем выше прогнозируемость работы в долгосрочной перспективе.
Мы рекомендуем для компаний со штатом 30-50 человек порог уникальности в районе 50-60 %. Это вполне нормально, ничего в нем страшного нет.
Еще один лайфхак о том, что можно делать с автобусными числами, мы узнали от одной компании. Они просто завели таблицу, где перечислили все компоненты системы, и разработчики раз в квартал проставляют в этой таблице то, насколько они с каждой компонентой знакомы и насколько много они с ней работали за этот период. В результате у них получается регулярно обновляемая таблица знаний по разработчикам.

Вторая по распространенности проблема, про которую мы слышали от людей — плохие продуктовые требования. Условно product-менеджер отдает в работу задачи, которые плохо проработаны. Потом в середине итерации он прибегает, меняет их, а в результате большое количество времени команды просто выбрасывается в мусорку.
Как это можно измерить?
Как изловить такого product-менеджера и объяснить ему, сколько стоят такие его решения для команды?
Скорее всего, product-менеджер приложил руку к этой проблеме, если мы видим у команды:
- высокий уровень Churn, то есть суммарно по всей команде высокий процент выбрасываемого кода;
- в среднем большие задачи, причем как по количеству кода, так и просто по estimation;
- описания задач меняются после попадания в статус in progress или появляется много комментариев к задачам от product-менеджера.
Что с этим делать?
Можно подойти с цифрами на руках к product-менеджеру и сказать: «Смотри, в нашей команде уровень Churn выше нормы на столько-то — вот сколько нам стоят твои постоянно меняющиеся продуктовые требования».
Скорее всего цифра «сколько стоит команде доля выброшенного кода» будет сильно выше, чем плюс 1-2 дня на проработку продуктовых требований. Одному из наших клиентов эта цифра очень помогла, и этот аргумент по факту разрулил конфликт с product-менеджером, который длился несколько месяцев.

Плохой онбординг нового разработчика более распространена для больших компаний. В разных командах внедрение новых сотрудников происходит с разной степенью, скажем так, эффективности.
В команду наняли джуниора, к нему приставили сеньора, который должен был его наставлять и обучать, как быть разработчиком. Но сеньор, вместо того, чтобы делать глубокое код-ревью джуниора и объяснять ему, как и что надо исправлять, просто переписывал код за него. В результате джуниор ничему не учился, и ни к чему хорошему это не привело. Это яркий пример плохого онбординга.
Как это можно измерить?
Скорее всего существует проблема плохого онбординга, если мы видим, что у вновь прибывших в команду:
- малое количество кода;
- малое количество уникальных файлов и медленно растет;
- низкий процент редактирования старого кода;
- поверхностное код-ревью, то есть мало комментариев и время на код-ревью в среднем меньше, чем у команды;
- большие таски.
Что с этим делать?
Во-первых, можно и нужно объяснить команде, как надо проводить внедрение новых сотрудников, что сначала новому человеку надо давать маленькие задачи из разных частей системы и баги, пусть даже не самые приоритетные.
Во-вторых, тем, кто будет ревьюить код джуниора, нужно объяснить, чтобы они делали достаточно глубокое ревью и придирались, может быть, даже не к самым значительным вещам.
Из нашего опыта — в какой-то момент в команде к двум тимлидам пришло по одному новому разработчику, причем почти одновременно. Один тимлид следовал этим best practise, пытался ротировать задачи для этого разработчика, провести его по всему коду, а второй просто давал задачи, какие были. В результате на приемлемый уровень перформанса второй разработчик вышел на 3 месяца позже первого, то есть онбординг занял больше времени на 3 месяца.

Последняя проблема, про которую сегодня поговорим — накопление технического долга. Все мы знаем, чем это плохо. Мы постоянно впиливаем в код какие-то костыли по требованию бизнеса, поддерживаемость системы все ухудшается и ухудшается, и в итоге все может дойти фактически до полной остановки разработки бизнес-задач. Я долгое время думал, что это страшилка из книжек, пока мы недавно не пообщались с реальным CTO, у которого в компании технического долга стало настолько много, что они на целый квартал остановили разработку бизнеса почти на 100%. Чтобы этого не допустить, надо как-то это отслеживать.
Как это можно измерить?
Для этого надо ввести одну метрику, которая называется legacy refactoring. Это процент удаления старых строк кода, и тем самым снижение сложности системы. Сложность системы можно измерять разными способами. Мы рекомендуем просто обычную цикломатическую сложность, благо существует куча библиотек, которые это делают, причем почти для любого языка.

Если мы видим, что у нас низкий процент legacy refactoring, то есть мы мало внимания уделяем упрощению старого кода, и у нас уже высокая complexity кода, то это явный индикатор того, что накапливается технический долг.
Что с этим делать?
Делать с этим можно разные вещи, про то, как с этим работать тоже можно очень много говорить. Нам нравятся две истории, которые нам рассказали CTO. Их подходы позволяют не просто формализовано работать с техническим долгом, но еще и очень классно измерять его уровень.
Первый CTO просто научил своих разработчиков, когда они впиливают в код костыль, в обязательном порядке заводить в Jira тикет с типом «Костыль». В результате у него в трекере всегда есть относительно актуальный список всех костылей в системе, с какими-то estimation и с уровнем приоритетов. Он постоянно за ними следит, выставляя уровень нормы — сколько максимум может быть у него таких тикетов, и т.д.
Второй CTO пошел еще дальше и использовал более элегантный подход. Когда разработчики впиливают костыль в систему, они обязаны вставить в код, где они это делают, комментарий с типом «Hack». Если другой разработчик обнаружил какой-то подозрительный код на код-ревью, то он говорил: «Ставь здесь слово Hack — потом поправим», например. В результате он мониторит уровень технического долга банальным grep’ом по репозиторию по слову «Hack» и всегда получает актуальный список и динамику, сколько у него на данный момент таких недоработок в системе.
На самом деле с метриками на этом все. Мы постарались рассказать про самые простые и самые понятные для измерения.
Подводные камни
У нашего подхода есть подводные камни:
- Некоторые вещи все равно не очень просто измерить. Это касается, например, Churn или legacy refactoring. Требуется инвестировать некоторое время, чтобы научиться их считать.
- Данные нужно очищать и немного подстраивать под команду. Например, банальная вещь, с которой вы столкнетесь, если попытаетесь это реализовать — в git вы увидите, что одному и тому же человеку соответствует несколько git-аккаунтов. Вам придется учитывать их оба — это тривиальный пример очистки данных, который требуется делать.
- Нужно следить за пороговыми значениями и выбирать их с умом, потому что они зависят от этапа жизни компании и от типа компании тоже. То, что хорошо для аутсорсера, может быть не очень хорошо для продуктовой компании.
- Большинство метрик, которые мы здесь перечислили, работают только для фултайм-разработчиков, потому что только деятельность фултайм-разработчиков хорошо отражается в доступных источниках данных: git, Jira, GitHub, мессенджеры и т.д.
Выводы
Мы хотели до вас донести следующее:
- Разработчиков и команду можно и нужно измерять. Это бывает сложно, но это можно делать.
- Нет универсального небольшого набора KPI. Под каждую проблему надо подбирать свой узкоспециализированный набор метрик. Нужно помнить, что не стоит пренебрегать даже самыми простыми метриками. Вместе они могут неплохо сработать.
- Git может рассказать много всего интересного про разработку и про разработчиков, но нужно следовать определенным практикам, чтобы данные из него можно было удобно доставать, в том числе:
- номер задач в коммитах;
- нет сквошей;
- можно определить время релиза: merge в master, теги.
Полезные ссылки и контакты:
- В презентации выступления есть несколько бонусных проблем и метрик для них.
- Блог авторов с полезными статьями для менеджеров разработки
- Telegram контакты: @avkiselev (Александр Киселев) и sss0791 (Сергей Семенов).
На TeamLead Conf обсуждают очень много разных проблем управления командой разработчиков и ищут их решения. Если вы уже прошли часть пути, набили не одну шишку, наступая на грабли, попробовали разные подходы и готовы сделать выводы и поделиться своим опытом — мы вас ждем. Подать заявку на выступление можно до 10 августа.
От участников тоже ожидается большая вовлеченность, начните с бронирования билета, а потом постарайтесь сформулировать, что волнует вас больше всего — тогда сможете обсудить свою боль и получить от конференции максимум.
Комментарии (16)

corr256
31.07.2018 23:58+4А зачем вам разработчики? Нанимайте роботов!
Я долгое время думал, что это страшилка из книжек, пока мы недавно не пообщались с реальным CTO, у которого в компании технического долга стало настолько много, что они на целый квартал остановили разработку бизнеса почти на 100%.
Оба дошли до тим-лида и всё ещё думали что тех.долг — это страшилка? Отличные тимлиды.romas1982 Автор
01.08.2018 06:15+1Здесь акцент стоит сделать на «целый квартал» и «почти 100%». Для небольших проектов — это и правда часто страшилка из книжек, а для больших — суровая правда жизни.
Lexicon
01.08.2018 08:40Качество кода, архитектуры, качество документации, качество планирования — без малого исчерпывающий список, отвечающий на вопрос о оптимизации расходов на разработку.
На мой взгляд, гораздо легче и важнее оценивать тех, кто строит архитектуру, тех, кто дает обещания и тех, кто контролирует процессы — т.е. тех, кого можно оценить объективно.
Люди очень разные. Компании об этом забывают еще на этапе собеседований, а с жестким подходом к необъективной оценке труда можно доиграться. Вот пишешь себе скажем REST и на тебе, "темная" — сбить показатели, а то сидит тут, с простым, объемным и планируемым кодом.
Можно конечно забыть про производительность людей в работе с однотипными задачами, раздавать их "рулеткой", но контроль ценой эффективности дискредитирует сам себя.
romas1982 Автор
01.08.2018 09:40Тут важно с умом подходить к измерениям и к выбору метрик. Если метрика будет «точность попадания в оценку», например, то с рестом уже не будет такой ситуации. То, что люди разные, ещё Дедушка Брукс доказал и показал, когда деревья были сильно меньше. Это факт. Принимать решения только на основе цифр, которые тебе дала спец.тулза или экселька — путь в ад. Но мерять однозначно нужно и анализировать результаты тоже.
e_finkel
01.08.2018 10:10Речь не о KPI или сравнении разработчиков друг с другом. Предлагается определять совсем проблемные ситуации.
Как определить порог «мало кода»? Мы рекомендуем ставить его достаточно маленьким, чтобы любой, хоть сколько перформящий разработчик мог его легко преодолеть.
Результат не «точно плохой разработчик», а «надо бы разобраться, все ли в порядке».
Так что никакой категоричности, всё с оговорками.
Femistoklov
01.08.2018 08:57Боюсь, не всем это надо. В большинстве мест «перформанс» рядового разработчика оценивается: «Быстро задачи сделал, хорошо работает.» Или «долго задачу делает, хотя по описанию в трекере вроде несложная, значит плохо работает».
romas1982 Автор
01.08.2018 09:36Все так. Но с определенного момента такой метод перестаёт давать ответы на интересующие вопросы, либо даёт большую погрешность. И вот здесь уже приходится подбирать измерения под себя и свою команду.
dlop
01.08.2018 12:17+1" то, что на сам деле хочется видеть людей условно с низким автобусным числом." Посмотрел в вики, там смысл скорее обратный — сколько человек нужно сбить автобусом, чтобы проект встал, соответственно чем больше число, тем лучше.
mapron
01.08.2018 18:16Наверное это обратное автобусное число: сколько модулей останется без знания о том как оно работает, когда конкретного человека сбивает автобус.
0 — очень хорошо.
MrVasily
01.08.2018 12:17+1Из собственного опыта скажу, что такими вещами можно и нужно заниматься, когда проект технически не представляет интереса или компании приходится набирать «кого попало». В остальных случаях достаточно, как сказал Femistoklov «Быстро задачи сделал, хорошо работает.»
romas1982 Автор
01.08.2018 12:21Ну т.е. если у вас 100 инженеров, которые пишут кучу кода в день, нет смысла смотерть и считать метрики? «Быстро сделал» без предварительной оценки — субъективная оценка, можно ведь оценивать по схеме «очень быстро сделал»? Такая же история с «Хорошо работает». Если в это «Хорошо работает» после запуска было два десятка коммитов с исправлениями и улучшениями — изначальное «хорошо работает» — это дейтвительно хорошо?
Цифрами начинают заниматься тогда, когда что-то идёт не так, а оно не так идёт почти всегда. Просто кто-то не верит своим ощущениям и проверяет измерениями, а кто-то верит и в итоге загоняет проект туда, откуда цифрами и измерениями его уже не достать.MrVasily
01.08.2018 18:00Если у вас 100 инженеров и вы хотите оценить каждого в терминах кол-ва коммитов/пофикшенных багов/..., то тут уже что-то идет не так и очень запущенно, потому что я не знаю ни одной компании которая производит коммиты или меряется кол-вом пофикшенных багов. На каждом уровне есть свои показатели эффективности работы, которые нужно отслеживать и на уровне руководителя 100 инженеров — это явно не коммиты и т.п.
romas1982 Автор
01.08.2018 18:14Все зависит от представления. В точных цифрах конечно не про уровень руководителя всей сотни, это не надо, но может быть полезно лиду, например. А в относительных цифрах и в виде динамики при наличие хорошего инструмента все видно замечательно и очень полезно. Гитлин по сути это и делает. Собирает кучу данных — хочешь — смотри детали, хочешь смотри динамику.
Баг багу рознь. Баг с прода меряют очень многие. Число зафейденых ревью коммитов также очень частая метрика.
MrVasily
01.08.2018 19:51+3Я не против метрик и они могут быть полезны лиду небольшой группы, но еще раз повторюсь с чего начал (из личного опыта, т.к. сам собирал такие метрики): в интересных проектах с высоким уровнем специалистов такой ерундой не занимаются. Ищите корень проблемы — если люди занимаются неинтересной или ненужной работой, то приходится за ними следить, чтобы никто не отлынивал.
romas1982 Автор
01.08.2018 20:03Всегда есть место неинтересной и порой ненужной работе. Согласен с вами, что для спецов высокого уровня на интересных проектах наверняка это не нужно, но таких случаев куда меньше, чем других.
PerlPower
Тимлиды, которых мы заслужили.