

Сергей Семёнов считает, что это происходит в основном по двум причинам.
- Нет инструментов и стандартов для оценки работы программистов. Менеджерам приходится прибегать к субъективной оценке, что в свою очередь приводит к ошибкам.
- Не используются средства автоматического контроля за процессами в команде. Без должного контроля процессы в командах разработки перестают выполнять свои функции, так как начинают исполняться частично или попросту игнорироваться.
И предлагает подход к оценке и контролю процессов на основе объективных данных.
Ниже видео и текстовая версия доклада Сергея, который по результатам зрительского голосования занял второе место на Saint TeamLead Conf.
О спикере: Сергей Семёнов (sss0791) работает в IT 9 лет, был разработчиком, тимлидом, продакт менеджером, сейчас CEO компании GitLean. GitLean — это аналитический продукт для менеджеров, технических директоров и тимлидов, предназначенный для того, чтобы принимать объективные управленческие решения. Большая часть примеров в этом рассказе опирается не только на личный опыт, но и на опыт компаний-клиентов со штатом разработки от 6 до 200 человек.
Про оценку разработчиков мы уже с моим коллегой Александром Киселевым рассказывали в феврале на предыдущей TeamLead Conf. Я не буду на этом подробно останавливаться, а буду ссылаться на статью по некоторым метрикам. Сегодня поговорим о процессах и о том, как их контролировать и измерять.
Источники данных
Если мы говорим об измерениях, хорошо бы понять, откуда брать данные. Прежде всего у нас есть:
- Git с информацией о коде;
- Jira или любой другой task tracker c информацией о задачах;
- GitHub, Bitbucket, Gitlab с информацией о код-ревью.
Кроме того, есть такой крутой механизм, как сбор различных субъективных оценок. Оговорюсь, что его нужно использовать систематически, если мы хотим опираться на эти данные.

Конечно, в данных вас ждет грязь и боль — ничего с этим не поделать, но это еще не так страшно. Самое неприятное, что данных о работе ваших процессов в этих источниках часто может просто не быть. Это может быть потому, что процессы строились так, что никаких артефактов в данных они не оставляют.
Первое правило, которому мы рекомендуем следовать при проектировании и построении процессов, это делать их так, чтобы они оставляли артефакты в данных. Нужно строить не просто Agile, а делать его измеримым (Measurable Agile).
Расскажу страшилку, которую мы встретили у одного из клиентов, который пришел к нам с запросом на улучшение качества продукта. Чтобы вы понимали масштаб — на команду из 15 разработчиков в неделю прилетало примерно 30-40 багов с продакшена. Начали разбираться в причинах, и обнаружили, что 30% задач не попадает в статус «testing». Сначала мы подумали, что это просто ошибка в данных, или тестировщики не обновляют статус задачи. Но оказалось, что действительно 30% задач просто не тестируются. Когда-то была проблема в инфраструктуре, из-за которой 1-2 задачки в итерации не попадали в тестирование. Потом про эту проблему все забыли, тестировщики перестали про неё говорить, и со временем это переросло в 30%. В итоге это привело к более глобальным проблемам.
Поэтому первая важная метрика для любого процесса — это то, что он оставляет данные. За этим обязательно нужно следить.

Иногда ради измеримости приходится жертвовать частью принципов Agile и, например, где-то предпочитать письменную коммуникацию устной.
Очень хорошо себя показала практика Due date, которую мы внедрили в несколько команд ради улучшения прогнозируемости. Суть ее в следующем: когда разработчик берет задачу и перетаскивает ее в «in progress», он должен поставить due date, когда задача будет либо выпущена, либо готова к релизу. Эта практика учит разработчика быть условным микро проджект менеджером своих собственных задач, то есть учитывать внешние зависимости и понимать, что задача готова, только когда клиент может использовать ее результат.
Чтобы происходило обучение, после due date разработчику нужно заходить в Jira и ставить новый due date и оставлять комментарии в специально заданной форме, почему это произошло. Казалось бы, зачем нужна такая бюрократии. Но на самом деле через две недели такой практики мы простым скриптом выгружаем из Jira все такие комментарии и с этой фактурой проводим ретроспективу. Получается куча инсайтов о том, почему срываются сроки. Очень круто работает, рекомендую использовать.
Подход от проблем
В измерении процессов мы исповедуем следующий подход: нужно исходить из проблем. Представляем себе некие идеальные практики и процессы, а дальше креативим, какими способами они могут не работать.
Мониторить нужно нарушение процессов, а не то, как мы следуем какой-то практике. Процессы часто не работают не потому, что люди злонамеренно их нарушают, а потому, что у разработчика и менеджера не хватает контроля и памяти на то, чтобы все их соблюдать. Отслеживая нарушения регламента, мы автоматически можем напоминать людям о том, что нужно делать, и получаем автоматические средства контроля.
Чтобы понять какие процессы и практики нужно внедрять, нужно понимать, зачем это делать в команде разработки, что нужно бизнесу от разработки. Все прекрасно понимают, что нужно не так уж и много:
- чтобы продукт поставлялся за адекватный прогнозируемый срок;
- чтобы продукт был должного качества, не обязательно идеального;
- чтобы всё это было достаточно быстро.
То есть важны прогнозируемость, качество и скорость. Поэтому на все проблемы и метрики мы будем смотреть именно с учетом того, как они влияют на прогнозируемость и качество. Скорость обсуждать почти не будем, потому что из почти 50 команд, с которыми мы так или иначе работали, со скоростью можно было работать только в двух. Для того чтобы повысить скорость, нужно уметь ее измерять, и чтобы она была хоть немного предсказуемой, а это и есть прогнозируемость и качество.
Дополнительно к прогнозируемости и качеству, введем такое направление как дисциплина. Дисциплиной будем называть всё, что обеспечивает базовое функционирование процессов и сбор данных, на основе которых проводится анализ проблем с прогнозируемостью и качеством.
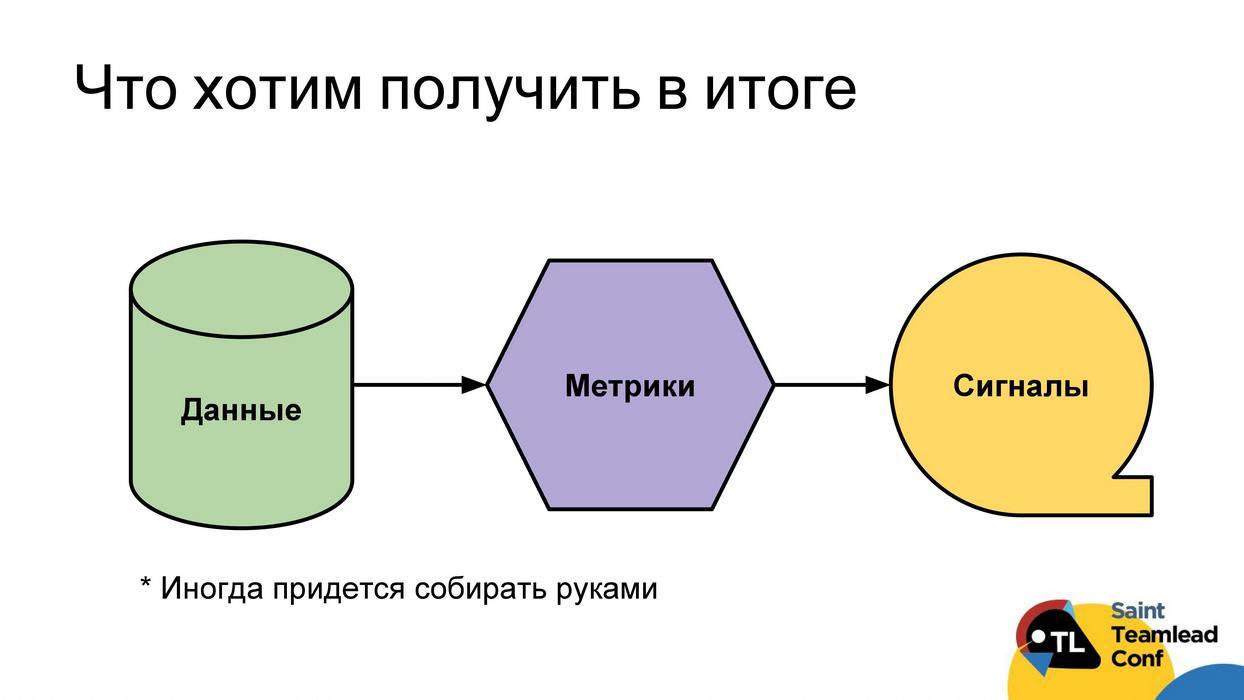
В идеале мы хотим построить следующую схему работы: чтобы у нас был автоматический сбор данных; по этим данным мы могли бы построить метрики; с помощью метрик находить проблемы; сигнализировать о проблемах напрямую разработчику, тимлиду или команде. Тогда все смогут своевременно на них реагировать и справляться с обнаруженными проблемами. Сразу скажу, что дойти до понятных сигналов не всегда получится. Иногда метрики останутся просто метриками, которые придется анализировать, смотреть на значения, тренды и так далее. Даже с данными иногда будет проблема, иногда их нельзя собрать автоматически и приходится делать это руками (буду отдельно уточнять такие случаи).
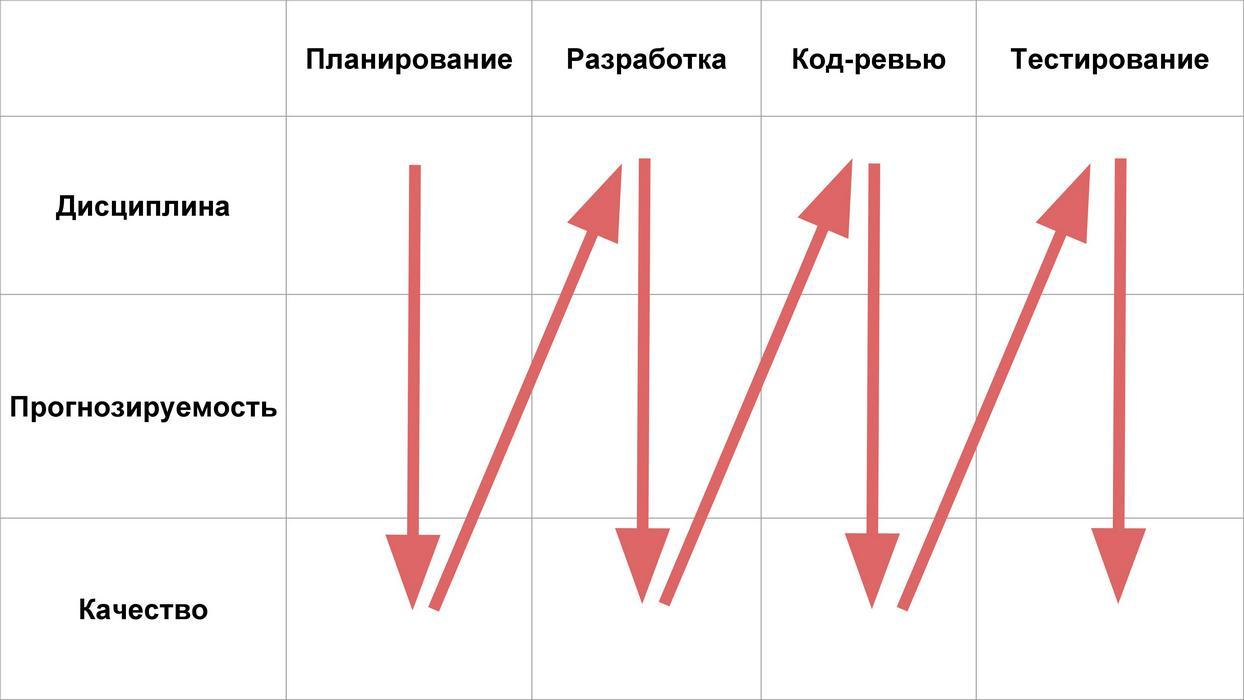
Далее мы рассмотри 4 стадии жизни фичей:
И разберем, какие на каждой из этих стадий могут быть проблемы с дисциплиной, прогнозируемостью и качеством.
Проблемы с дисциплиной на стадии планирования
Информации очень много, но я уделяю внимание самым основным моментам. Они могут показаться достаточно простыми, но с ними сталкивается очень большое количество команд.

Первая проблема, которая часто возникает при планировании, это банально организационная проблема — на митинге планирования присутствуют не все, кто там должен быть.
Пример: команда жалуется, что тестировщик что-то не так тестирует. Выясняется, что тестировщики в этой команде вообще никогда не ходят на планирование. Или вместо того, чтобы сидеть и что-то планировать, команда судорожно ищет место, где присесть, потому что забыла забронировать переговорку.
Метрики и сигналы настраивать не нужно, просто, пожалуйста, убедитесь в том, что у вас нет этих проблем. Митинг отмечен в календаре, на него все приглашены, занято место проведения. Как бы смешно это не звучало, с этим сталкиваются в разных командах.
Теперь обсудим ситуации, в которых сигналы и метрики нужны. На стадии планирования большинство сигналов, о которых я буду говорить, стоит отправлять в команду где-то через час после окончания митинга планирования, чтобы не отвлекать команду в процессе, но чтобы при этом еще сохранялся фокус.
Первая дисциплинарная проблема — у задач нет описания, или они плохо описаны. Это контролируется элементарно. Есть формат, которому должны соответствовать задачи, — проверяем, так ли это. Например, следим, что заданы критерии приемки, или для фронтендовых задач есть ссылка на макет. Еще нужно следить за расставленными компонентами, потому что формат описания часто привязан к компоненту. Для бэкэндовой задачи релевантно одно описание, для фронтендовой — другое.

Следующая частая проблема — приоритеты проговариваются устно или вообще не проговариваются и в данных не отражаются. В результате к концу итерации выясняется, что самые важные задачи так и не были сделаны. Нужно следить за тем, что команда использует приоритеты и использует их адекватно. Если у команды 90% задач в итерации имеют high priority, это всё равно, что приоритетов нет совсем.
Мы стараемся приходить к такому распределению: 20% high priority задач (нельзя не зарелизить); 60% — medium priority; 20% — низкий приоритет (не страшно, если не зарелизим). Навешиваем на всё это сигналы.

Последняя проблема с дисциплиной, которая бывает на стадии планирования — не хватает данных, для последующих метрик в том числе. Базовые из них: у задач нет оценок (следует завести сигнал) или типы задач проставлены неадекватно. То есть баги заводятся как задачи, а задачи технического долга вообще не отследить. К сожалению, автоматически проконтролировать второй тип проблем не получается. Советуем просто раз в пару месяцев, особенно если вы CTO и у вас несколько команд, проглядывать backlog и убеждаться, что люди заводят баги как баги, стори как стори, техдолговые задачи как техдолговые.
Проблемы с прогнозируемостью на стадии планирования
Переходим к проблемам с прогнозируемостью.

Базовая проблема — не попадаем в сроки и оценки, неправильно оцениваем. К сожалению, найти какой-то волшебный сигнал или метрику, которые решат эту проблему, нельзя. Единственный способ — это побуждать команду лучше обучаться, разбирать на примерах причины ошибок с той или иной оценкой. И вот этот процесс обучения можно облегчить при помощи автоматических средств.
Первое, что можно сделать, это разобраться с заведомо проблемными задачами с высокой оценкой времени исполнения. Навешиваем SLA и контролируем, чтобы все задачи были достаточно хорошо декомпозированы. Мы рекомендуем ограничение в максимум два дня на исполнение для начала, а потом можно перейти и к однодневному.
Следующим пунктом можно облегчить сбор артефактов, на которых можно будет проводить обучение и разбирать с командой, почему произошла ошибка с оценкой. Мы рекомендуем для этого использовать практику Due date. Она очень круто себя здесь зарекомендовала.
Еще один способ — это метрика, которая называется Churn кода в рамках задачи. Суть ее в том, что мы смотрим, какой процент кода в рамках задачи был написан, но не дожил до релиза (подробнее в прошлом докладе). Эта метрика показывает, насколько хорошо продумываются задачи. Соответственно, неплохо бы обращать внимание на задачи со скачками Churn и на них разбираться, что мы не учли и почему ошиблись в оценке.

Следующая история стандартная: команда что-то планировала, спринт заполнила, но в итоге делала совсем не то, что запланировала. Настраивать сигналы на вбросы, изменения приоритетов можно, но для большинства команд, с которыми мы так делали, они были нерелевантны. Зачастую это легальные операции со стороны продакт-менеджера что-то вбросить в спринт, изменить приоритет, поэтому будет много ложных срабатываний.
Что тут можно сделать? Посчитать довольно стандартные базовые метрики: закрываемость начального скоупа спринта, количество вбросов в спринт, закрываемость самих вбросов, смены приоритетов, посмотреть структуру вбросов. После этого оценить, сколько у вас обычно вбрасывается задач и багов в итерацию. Далее, с помощью сигнала контролировать то, что вы эту квоту закладываете на этапе планирования.
Проблемы с качеством на этапе планирования
Первая проблема: команда не додумывает функциональность выпускаемых фич. Я буду говорить про качество в общем смысле — проблема с качеством, это если клиент говорит, что она есть. Это могут быть какие-то продуктовые недодумки, а могут быть технические вещи.
Касательно продуктовых недодумок, хорошо работает такая метрика как 3-week churn, выявляющая, что спустя 3 недели после релиза задачи churn выше нормы. Суть простая: задачу зарелизили, а потом в течение трех недель достаточно высокий процент ее кода был удалён. Видимо, задача была не очень хорошо реализована. Такие кейсы мы вылавливаем и разбираем с командой.

Вторая метрика нужна для команд, у которых есть проблемы с багами, крэшами и с качеством. Предлагаем строить график баланса багов и крэшей: сколько багов есть прямо сейчас, сколько прилетело за вчерашний день, сколько за вчерашний день сделали. Можно повесить такой Real Time Monitor прямо перед командой, чтобы она видела его каждый день. Это здорово акцентирует внимание команды на проблемах с качеством. Мы с двумя командами так делали, и они действительно стали лучше продумывать задачи.

Следующая очень стандартная проблема — у команды нет времени на технический долг. Эта история легко мониторится, если вы соблюдаете работу с типами, то есть техдолговые задачи оцениваются и заводятся в Jira как техдолговые. Мы можем посчитать какую квоту распределения времени давали команде на техдолг в течение квартала. Если мы договаривались с бизнесом о том, что это 20%, а потратили только 10%, это можно учесть и в следующем квартале уделить техническому долгу больше времени.
Проблемы с дисциплиной на стадии разработки
Теперь перейдем к стадии разработки. Какие тут могут проблемы с дисциплиной.
К сожалению, бывает так, что разработчики ничего не делают или мы не можем понять, делают ли они хоть что-нибудь. Отследить это легко по двум банальным признакам:
- частота коммитов — хотя бы раз в день;
- хотя бы одна активная задача в Jira.
Если этого нет, то не факт, что надо бить по рукам разработчика, но надо знать об этом.
Вторая проблема, которая может подкосить даже самых сильных людей и мозг даже очень крутого разработчика, это постоянные переработки. Хорошо бы, чтобы вы как тимлид знали о том, что человек перерабатывает: пишет код или делает код-ревью в нерабочее время.
Также могут нарушаться различные правила работы с Git. Первое, чему мы призываем следовать все команды, это указывать в commit messages task-префиксы из трекера, потому что только в этом случае мы можем связать задачу и код к ней. Тут лучше даже не сигналы строить, а прямо настроить git hook. На любые дополнительные git-правила, которые у вас есть, например, нельзя коммитить в master, тоже настраиваем git hooks.
Это же относится и к оговоренным практикам. На этапе разработки бывает много практик, которым должен следовать разработчик. Например, в случае Due date будет три сигнала:
- задачи, у которых due date не проставлен;
- задачи, у которых есть просроченый due date;
- задачи, у которых due date был изменён, но нет комментария.
На всё на это настраиваются сигналы. На любую другую практику тоже можно настроить подобные вещи.
Проблемы с прогнозируемостью на этапе разработки
Много чего может пойти не так в прогнозах на этапе разработки.
Задача может просто долго висеть в разработке. Мы уже попытались решить эту проблему на этапе планирования — декомпозировать задачи достаточно мелко. К сожалению, это не всегда помогает, и бывают задачи, которые зависают. Мы рекомендуем для начала просто настроить SLA на статус «in progress», чтобы был сигнал о том, что этот SLA нарушается. Это не позволит прямо сейчас начать выпускать задачи быстрее, но это позволит опять-таки собирать фактуру, на это реагировать и обсуждать с командой, что произошло, почему задача долго висит.
Прогнозируемость может пострадать, если на одном разработчике слишком много задач. Количество параллельных задач, которые делает разработчик, желательно проверять по коду, а не по Jira, потому что Jira не всегда отражает релевантную информацию. Все мы люди, и если мы делаем много параллельных задач, то риск того, что где-то что-то пойдет не так, увеличивается.

У разработчика могут быть какие-то проблемы, про которые он не говорит, но которые легко выявить на основе данных. Например, вчера у разработчика было мало активности по коду. Это не обязательно означает, что есть проблема, но вы, как тимлид, можете подойти и узнать это. Возможно, он застрял и ему нужна помощь, но он стесняется её попросить.
Другой пример, у разработчика, наоборот, какая-то большая задача, которая всё разрастается и разрастается по коду. Это тоже можно выявить и, возможно, декомпозировать, чтобы в итоге не возникло проблем на код-ревью или стадии тестирования.
Имеет смысл настроить сигнал и на то, что в ходе работы над задачей многократно переписывается код. Возможно, по ней постоянно меняются требования, или разработчик не знает какое архитектурное решение выбрать. На данных это легко обнаружить и обсудить с разработчиком.
Проблемы с качеством на этапе разработки
Разработка напрямую влияет на качество. Вопрос в том, как понять, кто из разработчиков больше всего влияет на снижение качества.
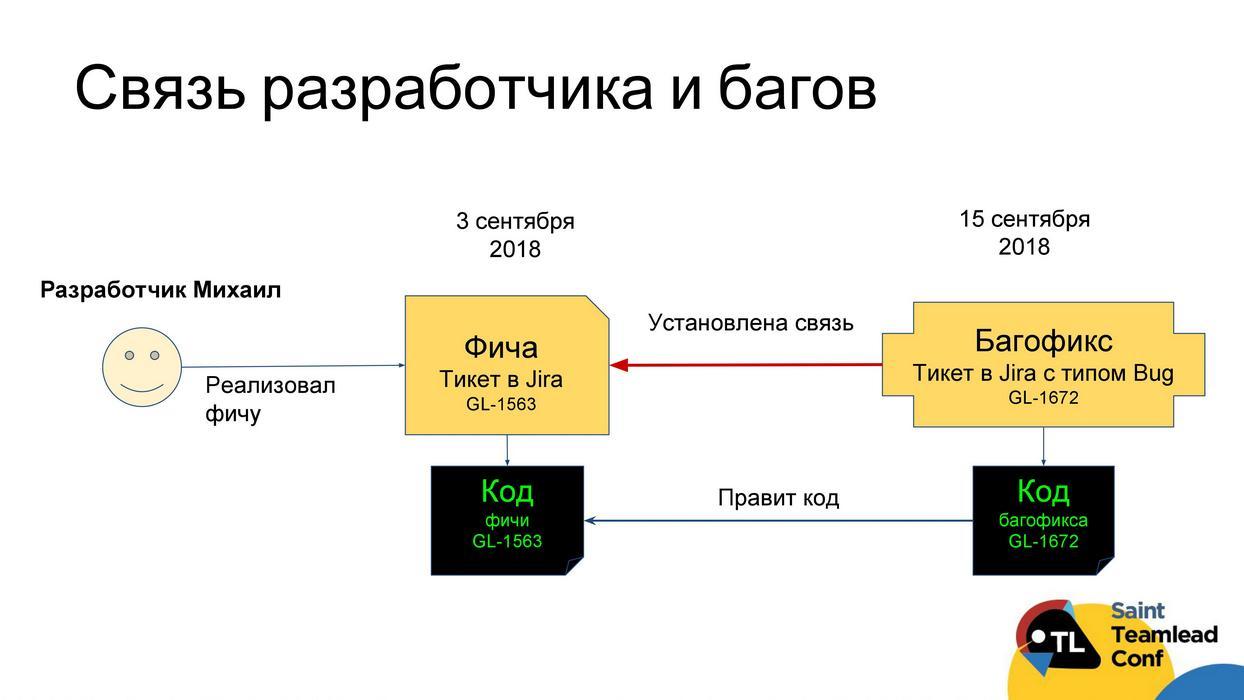
Мы предлагаем делать это следующим образом. Можно рассчитать критерий «бажности» разработчика: берем все задачи, которые были в трекере за три месяца; находим среди всех задач задачи типа «баг»; смотрим код этих задач типа «баг»; смотрим, код каких задач исправлял этот bug fix. Соответственно, можем понять соотношение задач, в которых потом были обнаружены дефекты, ко всем задачам, которые делал разработчик, — это и будет «критерий бажности».
Если дополнить эту историю статистикой по возвратам из тестирования, то есть долю задач разработчика, которые возвращались тестированием на доработки, то получится оценить, у кого из разработчиков больше всего проблем с качеством. В результате поймем, под кого стоит подстроить процессы код-ревью и тестирования, чей код нужно тщательнее ревьюить и чьи задачи желательно отдавать более въедливым тестировщикам.
Следующая проблема, которая может быть с качеством на этапе разработки, это то, что мы пишем сложно поддерживаемый код, такую «слоеную» архитектуру. Не буду здесь останавливаться подробно, я подробно рассказывал об этом в прошлый раз. Есть метрика, которая называется Legacy Refactoring, которая как раз показывает, как много времени тратится на встраивание нового кода в существующий, как много старого кода удаляется и меняется при написании нового.
Наверное, один из самых важных критериев при оценке качества именно на стадии разработки — это контроль SLA для high-priority-багов. Я надеюсь, что вы за этим уже следите. Если нет, то рекомендую начать, потому что это зачастую один из самых важных показателей для бизнеса: high-priority и critical баги команда разработки обязуется закрывать в определенное время.
Последнее, с чем часто приходится сталкиваться — нет автотестов. Во-первых, их нужно писать. Во-вторых, нужно мониторить, что покрытие держится на определенном уровне и не падает ниже порога. Многие пишут автотесты, но забывают следить за покрытием.
Проблемы с дисциплиной на этапе код-ревью
Переходим к стадии Code review. Какие тут могут быть проблемы с дисциплиной? Начнем с, наверное, самых дурацкой причины — забытых pull requests. Во-первых, автор может просто не назначить ревьюера для pull request, который в результате будет забыт. Или, например, тикет забыли передвинуть в статус «in review», а разработчики проверяют, какие задачи нужно ревьюить именно в Jira. Нужно не забывать за этим следить, для чего настраиваем простые сигналы. Если у вас есть практика, что должно быть больше 2-3 ревьюеров на задачу, то это также легко контролируется с помощью простого сигнала.

Следующая история о том, что ревьюер раскрывает задачу, не может быстро понять, к какой задаче относится pull request, ему лень спросить и он ее откладывает. Тут тоже делаем сигнал — убеждаемся, что в pull request всегда есть ссылка на ticket в Jira и ревьюер может легко с ним ознакомиться.

Следующая проблема, которую, к сожалению, не получается исключить. Всегда бывают огромный pull requests, в которых много всего сделано. Соответственно, ревьюер их открывает, смотрит и думает: «Нет, лучше я потом это проверю, что-то тут слишком много». В этом случае автор может помочь ревьюеру с онбордингом, а мы можем этот процесс проконтролировать. Большие pull requests обязательно должны иметь хорошее понятное описание, которое соответствует определенному формату, и этот формат отличается от тикета в Jira.
Второй вид практик для больший pull request, которые тоже можно мониторить, — это, когда автор сам заранее в коде расставляет комментарии в тех местах, где что-то нужно обсудить, где какое-то неочевидное решение, тем самым, как бы приглашая ревьюера в дискуссию. На это тоже легко настраиваются сигналы.
Далее проблема, с которой тоже очень часто сталкиваемся, — автор говорит, что просто не знает, когда ему можно начинать всё исправлять, потому что он не знает, закончено ли ревью. Для этого внедряется элементарная дисциплинарная практика: ревьюер должен в конце ревью обязательно отписаться специальным комментарием о том, что «я закончил, можно фиксить». Соответственно, можно настроить автоматические уведомления об этом автору.

Настройте, пожалуйста, linter. В половине команд, с которыми мы работаем, почему-то не настроен linter, и они сами занимаются таким синтаксическим код-ревью и зачем-то делают работу, с которой машина справится намного лучше.
Проблемы с прогнозируемостью на стадии код-ревью
Если задачи продолжают зависать, рекомендуем настроить SLA на то, что задача либо долго ждет фиксов, либо же долго ждет ревью. Соответственно, обязательно пингуем и автора, и ревьюера.
Если SLA не помогают, рекомендую внедрить в практику утренний "час код-ревью" или вечерний — как удобно. Это время, когда вся команда садится и занимается чисто код-ревью. Внедрение этой метрики очень легко мониторить по смещению времени активности в pull request к нужному часу.

Бывает, что есть люди перегруженные код-ревью, и это тоже не очень хорошо. Например, в одной из команд CTO стоял у самых истоков системы, всю ее написал, и так уж получилось, что всегда был главным ревьюером. Все разработчики постоянно навешивали на него задачи на код-ревью. В какой-то момент всё пришло к тому, что в команде из 6 человек на нём висело больше 50% код-ревью и продолжало копиться и копиться. В результате, как несложно догадаться, итерации у них закрывались на те же самые 50%, потому что CTO не успевал всё проверить. Когда ввели элементарно дисциплинарную практику о том, что на CTO нельзя теперь было навесить больше двух-трех задач в итерацию, в следующую же итерацию команда показала закрытие спринта почти на 100%.
Следующая история, которая легко мониторится с помощью метрик — это то, что в код-ревью начался холивар. Триггеры могут быть такими:
- есть тред, в котором больше двух ответов от каждого из участников;
- большое количество участников в код-ревью;
- нет активности по коммитам, а по комментариям активность есть.
Все это повод проверить, нет ли холивара в этом код-ревью.
Проблемы с качеством на стадии код-ревью
Прежде всего, проблема может быть в просто очень поверхностном код-ревью. Для того чтобы это мониторить, есть две неплохие метрики. Можно измерить активность ревьюера как количество комментариев на каждые 100 строк кода. Кто-то ревьюит каждые 10 строчек кода, а кто-то целые экраны пролистывает и оставляет 1-2 комментария. Конечно, не все комментарии одинаково полезны. Поэтому можно уточнить эту метрику измерив влияние ревьюера — процент комментариев, которые указывали на строку кода, которая потом была изменена в рамках ревью. Тем самым мы понимаем, кто самый въедливый, и самый эффективный в том смысле, что его комментарии чаще всего приводят к изменениям кода.

С теми, кто подходит к ревью очень формально, можно поговорить и мониторить их далее, смотреть, начинают ли они ревьюить более тщательно.
Следующая проблема — автор выносит на ревью очень сырой код и ревью превращается в исправление самых очевидных багов вместо того, чтобы уделить внимание чему-то более сложному, или просто затягивается. Метрика здесь — высокий churn кода после код-ревью, т.е. процент изменения кода в pull request после того, как начался ревью.
Случай, когда ничего непонятно из-за рефакторинга, к сожалению, стоит контролировать руками, автоматически это делать достаточно проблемно. Проверяем, чтобы стилистический рефакторинг был выделен либо в отдельный commit, либо в идеале вообще в отдельную ветку, чтобы не мешать проводить качественный код-ревью.

Качество на код ревью можно еще контролировать с помощью такой практики, как анонимный опрос после код-ревью (когда pull request успешно закрыт), в котором ревьюер и автор оценили бы качество кода и качество код-ревью соответственно. И один из критериев может быть как раз, выделен ли стилистический рефакторинг в отдельный commit, в том числе. Такие субъективные оценки позволяют находить скрытые конфликты, проблемы в команде.
Проблемы с дисциплиной на этапе тестирования
Переходим к этапу тестирования и проблемам с дисциплиной на этом этапе. Самая частая, с которой мы сталкиваемся — нет информации о тестировщиках в Jira. То люди экономят на лицензиях и не добавляют тестировщиков в Jira. То задачи, которые просто не попадают в статус «testing». То мы не можем определить возврат задачи на доработки по task-tracker. Рекомендуем на все это настроить сигналы и смотреть, чтобы данные копились, иначе о тестировщике сказать что-то будет крайне сложно.

Проблемы с прогнозируемостью на стадии тестирования
В части прогнозируемости на стадии тестирования опять рекомендую навешивать SLA на время тестирования и на время ожидания тестирования. А все случаи невыполнения SLA проговаривать с командой, в том числе навесить сигнал на время фикса после возврата задачи из тестирования в разработку.
Как и с код-ревью, в тестировании может быть проблема перегруза тестировщиков, особенно в командах, где тестировщики — это общекомандный ресурс. Рекомендуем просто посмотреть распределение задач по тестировщикам. Даже если у вас тестировщик выполняет задачи от нескольких команд, то нужно по нескольким командам посмотреть распределение задач по тестерам, чтобы понять, кто прямо сейчас является бутылочным горлышком.

Сложный pipeline test-окружения — суперчастая проблема, но, к сожалению, не все на это строят метрики. То время сборки build’а очень большое, то время раскатки системы, то время прогона автотестов — если можете настроить на это метрики, рекомендуем это сделать. Если нет, то хотя бы раз в 1-2 месяца рекомендуем садиться рядом со своим тестировщиком на целый день, чтобы понять, что иногда ему живется очень непросто. Если вы этого ни разу не делали, то вам откроется много инсайтов.
Проблемы с качеством на этапе тестирования
Целевая функция тестирования — не пропускать баги на продакшен. Хорошо бы понять, кто из тестировщиков с этой функцией справляется хорошо. Тут ровно такая же схема, как была с разработчиками, просто теперь мы оцениваем критерий «бажности» тестировщика, как количество задач, которые тестировщик тестировал, а потом в них были исправлены баги, по отношению ко всем задачам, которые тестировал тестировщик.
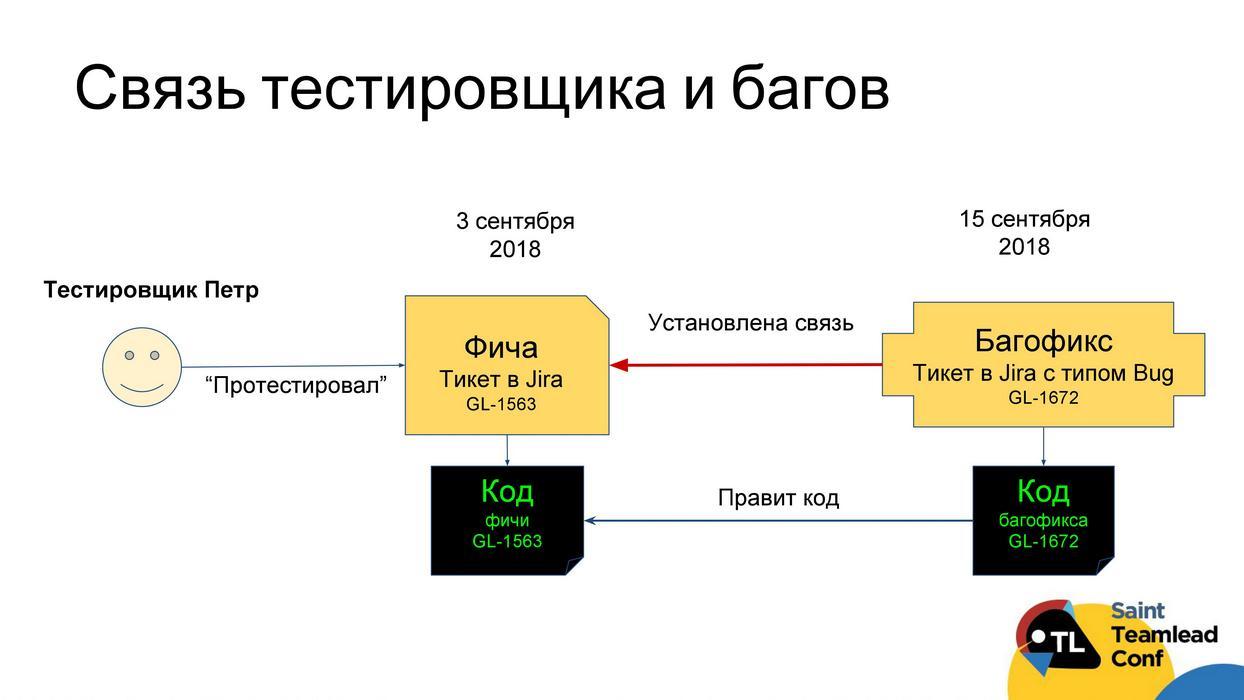
Дальше мы ещё можем посмотреть, сколько всего этот тестировщик тестирует задач, как часто он возвращает задачи, и тем самым построить некий рейтинг тестировщиков. Очень часто на этой стадии нас ждали удивительные открытия. Оказывалось, что тестировщики, которых все любят, потому что они целыми пачками очень быстро тестируют задачи, делают это наименее качественно. А тестировщик, которого прямо недолюбливали, оказался самым въедливым, просто не очень быстрым. Суть здесь очень простая: самым въедливым тестировщикам, которые тестируют качественнее всего, нужно давать самые важные, сложные или потенциально самые рискованные задачи.

Касательно потенциально самых рискованных задач, можно такую же историю с «бажностью» построить для файлов, то есть посмотреть на файлы, в которых находят больше всего багов. Соответственно, задачи, которые эти файлы затрагивают, доверять наиболее ответственному тестировщику.

Еще одна история, которая сказывается на качестве этапа тестирования — это такой постоянный пинг-понг между тестированием и разработкой. Тестировщик просто возвращает задачу разработчику, а тот в свою очередь ничего не меняя, возвращает ее обратно тестировщику. На это можно смотреть либо в качестве метрики, либо настроить сигнал на такие задачи и присматриваться, что там происходит и нет ли проблем.
Методология работы с метриками
Про метрики мы поговорили, и теперь вопрос — как со всем этим работать? Я рассказал только самые базовые вещи, но даже их довольно много. Что со всем этим делать и как это использовать?
Мы рекомендуем по максимуму автоматизировать этот процесс и все сигналы доставлять в команду посредством бота в мессенджерах. Мы пробовали разные каналы коммуникации: и e-mail, и dashboard — не очень хорошо работает. Бот зарекомендовал себя лучше всего. Бота вы можете написать сами, можете взять у кого-нибудь OpenSource, можете купить у нас.
Суть тут очень простая: на сигналы от бота команда реагирует намного спокойнее, чем на менеджера, который указывает на проблемы. Большинство сигналов по возможности доставляйте напрямую сначала разработчику, потом уже в команду, если разработчик не реагирует, например, в течение одного-двух дней.

Не нужно пытаться строить сразу все сигналы. Большинство из них просто не будут работать, потому что у вас не будет данных, из-за банальных проблем с дисциплиной. Поэтому сначала налаживаем дисциплину и настраиваем сигналы на дисциплинарные практики. По опыту команд, с которыми мы общались, на простое выстраивание дисциплины в команде разработки без автоматизации уходило год-полтора. С автоматизацией, с помощью постоянных сигналов команда начинает нормально дисциплинированно работать где-то через пару месяцев, то есть намного быстрее.
Любые сигналы, которые вы делаете публичными, или направляете напрямую разработчику, ни в коем случае нельзя просто взять и включить. Вначале надо обязательно согласовать это с разработчиком, проговорить с ним и с командой. Желательно в письменном виде занести в Team Agreement все пороговые значения, причины почему вы это делаете, какие будут следующие шаги и так далее.

Надо иметь в виду, что все процессы имеют исключения, и учитывать это на этапе проектирования. Мы не строим концлагерь для разработчиков, где нельзя сделать шаг вправо, шаг влево. Все процессы имеют исключение, просто мы хотим о них знать. Если бот постоянно ругается по какой-то задаче, которую действительно нельзя декомпозировать, и работа над которой займет 5 дней, надо поставить метку «no-tracking», чтобы бот это учитывал и всё. Вы, как менеджер, можете отдельно мониторить количество таких «no-tracking» задач, и тем самым понимать, насколько хороши и те процессы, и те сигналы, которые вы выстраиваете. Если количество задач с меткой «no-tracking» стабильно растет, то, к сожалению, это значит, что те сигналы и процессы, которые вы придумали, тяжелы для команды, она не может их соблюдать, и ей легче их обходить.

Ручной контроль всё равно остаётся. Не получится включить бота и уехать куда-нибудь на Бали — всё равно придётся в каждой ситуации разбираться. Вы получили какой-то сигнал, человек на него не отреагировал — вам придется через день-два узнать, в чём причина, проговорить проблему и выработать решение.
Для оптимизации этого процесса мы рекомендуем ввести такую практику, как дежурный по процессам. Это переходящая должность человека (раз в неделю), который разбирается с проблемами, о которых сигнализирует бот. А вы как тимлид помогаете дежурному разбираться с этими проблемами, то есть курируете его. Тем самым у разработчика повышается мотивация работать с этим продуктом. Он понимает его пользу, потому что видит, как эти проблемы можно решать и как на них реагировать. Тем самым вы снижаете свою уникальность команде и приближаете тот момент, когда команда станет автономной, и вы таки сможете поехать на Бали.
Выводы
Собирайте данные. Стройте процессы таким образом, чтобы у вас собирались данные. Даже если вы сейчас не хотите строить метрики и сигналы, вы сможете сделать крутой, ретроспективный анализ в будущем, если сейчас начнете их собирать.
Автоматически контролируйте процессы. Когда проектируете процессы, всегда думайте о том, как можно их хакнуть, и как можно такие хаки распознать по данным.
Когда сигналов мало уже несколько недель — вы молодец! Мы сталкивались с тем что, когда команда видит, что сигналов становится мало, и вроде ситуация налаживается, она начинает судорожно придумывать еще какие-то практики, начинает что-то внедрять, чтобы снова увидеть эти пачки сигналов. Это не всегда нужно, возможно, если сигналов стало мало — у вас всё хорошо, команда начала работать так, как вы с самого начала хотели, и вы молодец :)
Приходите делиться своими тимлидскими находками на TeamLead Conf. Конференция в феврале пройдет в Москве и Call for Papers уже открыт.
Хотите еще понабраться чужого опыта? Подпишитесь на нашу рассылку по управлению, чтобы получать новости программы и не пропустить время выгодной покупки билетов на конференцию.
Комментарии (26)

sergof
16.11.2018 17:41+2Ребята, а вас не удивляет как много людей заботится о том как бы половчее впрячь нас (айтишников, в частности программистов) в бизнес-процесс. Как бы так покрепче нахлобучить на нас упряжь чтоб программист физически не мог делать ничего кроме пользы для бизнеса. Затянуть до упора, до треска в сухожилиях все подпруги, так что пусть у программистов хоть глаза на лоб лезут, лишь-бы они от ужаса еще шибче шевелили своими тощими булками во славу великого бизнеса! Да взнуздать нас чтоб пар валил, чтоб капли пота летели в стороны, чтобы блин вообще в голове не осталось никаких мыслей кроме команд, функций, шаблонов, синглтонов, вот этого всего. А если кто вдруг удумает передохнуть, того по загривку, на карандаш! Для кого вот это все, спрашивается, все эти менеджменты, эджайлы, все эти дежурные по процессам, трехэтжные архитектуры управления персоналом. Фидбэки, ага. На страже каждой минуты рабочего дня — электроника. Хочешь перекур? Карточкой проведи вот здесь, твои минуты остановятся, больше трех с половиной минут не отдыхать ай-ая-ай, плохой пример коллективу! Ты же ответственный, правда? Тыж командный игрок! Заскучал, теряешь мотивацию? Сейчас погоди, эйчары скажут нам как тебя промотивировать, может штраф для начала? Или вздрючить тебя чтоб у всех остальных глупых мыслей в головах не появлялось? Ой нет, наоборот, ты хорошо работал? Ну премия там, туда сюда, все честь по чести, торт на день рождения, а как же! Только не забывай что там где надо теперь знают как ты можешь на самом деле впахивать. Так что влазь на велосипед и крути педали, понял, жопа?
Вот скажите мне — в этом году сколько раз лично тебя, коллега, спросили — чего тебе хочется, родной? Как дела твои, о чем мечтаешь, к чему стремишься? Напишите мне кто ни будь статью о том как кто-то заботится о программистах, если вам не трудно. Можо без картинок. Заранее спасибо пожалуйста.powerman
16.11.2018 20:29-1Вы смешиваете в одну кучу очень разные вещи.
Сидя на работе, за которую бизнес деньги платит, надо заниматься тем, что нужно бизнесу, а не тем, чего программисту хочется/интересно. Если программист хочет заниматься тем, что ему интересно — пусть подбирает проект, на котором бизнесу нужно чтобы он занимался именно этим, либо учится доносить до бизнеса идею того, чем интересное лично ему поможет бизнесу и проекту, и почему стоит этим заниматься, либо делает то, что ему интересно, в опенсорс и в свободное время. Если плохо на текущей работе/проекте — меняйте работу, благо с нашей профессией и текущим состоянием рынка это не так уж и сложно.
Все описанные в статье метрики — вполне здравые и полезные, равно как и описанный в статье подход по их применению. И там нет абсолютно ничего про поминутный контроль перекуров или про подсчёт строк кода — такие метрики действительно причиняют больше вреда, но это не значит что любые метрики враждебны к программистам.
И да, действительно есть отчётливая тенденция попыток "перевалить" на программистов управленческие задачи, чтобы они сами про себя собирали метрики, сами реагировали на сигналы, сами контролировали исполнение этих процессов… И относится к этому можно по-разному. Можно так: "моё дело просто писать код какой попросили, а работа менеджера контролировать чтобы я это делал то, что нужно, и так, как нужно, и нечего на меня переваливать его работу". А можно так: "моё дело решить проблему бизнеса, написав нужный код в нужные сроки с нужным качеством, и любые инструменты которые автоматизируют и облегчают для меня достижение этой цели — полезны, даже если из-за них мой менеджер останется без работы". Лично мне больше нравится последний вариант, потому что он делает меня более эффективным разработчиком в глазах бизнеса, что очень положительно сказывается на том, какой у меня выбор интересных проектов и зарплаты.
sergof
16.11.2018 21:55+3Сидя на работе, за которую...
Вот тут людям кто на работе работает а не сидит наверное обидно.
Если плохо на текущей работе — меняйте
Я с этим согласный двумя руками.
моё дело решить проблему бизнеса, написав нужный код в нужные сроки с нужным качеством
И с этим я однозначно согласен.
любые инструменты которые автоматизируют и облегчают для меня достижение этой цели — полезны
А вот с эти совсем не согласен. Поясняю: подвох состоит в том что, во-первых за тебя пытаются другие люди решить что для тебя есть благо а что нет. Кроме того, по условиям игры отказываться от блага запрещено. Это важно! Во-вторых, когда весь стек контроля уже запущен ты можешь решить устраивает тебя это или нет. Соответственно принимаешь ты условия работы или нет. Но когда этот стек внедряется постепенно, то трудно определить где же та размытая граница когда атмосфера перестала быть вдохновляющей. Собственно про это я и старался написать, но похоже выбрал не те слова. Если образно выражаться, то проблема в следующем — есть море проектов, курсов, программных решений, ориетнированных на то чтобы усилить контроль, повысить эффективность, увеличить продуктивность. Их можно прорекламировать, посетить или скачать и запустить. Но назовите мне такой проект который можно скачать (да-да, я тоже умею утрировать) и развернув в офисе сделать работу, ну что ли менее напряжной или стрессовой. Поимаете? В данном случае важен вектор. Сейчас можно легко найти технологию про «запрячь» и «взнуздать», но попробуйте найти хоть одну публикацию, эссе, даже простой камент в обсуждениях где будет написано о том, как в фирме Икс взяли и внедрили технологию, главная цель и профит которой в том чтобы повысить комфорт работы, поднять удовлетворенность или хотябы сбить накопившийся стресс? Причем я прошу не рекламу услуг тамады или интересных конкурсов, а описание свершившегося факта с перманентным эффектом. Сможете найти? Боюсь что такого нет. Всех эти вещей мы достигаем сами, причем зачастую не благодаря а вопреки. Вот как то так.
П.с.мне больше нравится последний вариант, потому что он делает меня более эффективным
замечательная эпитафия для Терминатора. Но вы же это не серьезно, правда?powerman
16.11.2018 23:00Хм. Думаю, мы друг друга сильно не поняли. Возможно, это связано с тем, что я уже почти 20 лет на фултайм-фрилансе, и очень далёк от офисных проблем. И нет, про эффективность я абсолютно серьёзно, на фрилансе, по крайней мере, это вполне работает.
algotrader2013
16.11.2018 21:40+5Ребята, а вас не удивляет как много людей заботится о том как бы половчее впрячь нас (айтишников, в частности программистов) в бизнес-процесс. Как бы так покрепче нахлобучить на нас упряжь...
Нет, не удивляет. Программисты и тестировщики, дорвавшиеся до управления процессами, привыкли, что система работает четко. Если написан код без багов, сервер исправен, понятны все переменные окружения, и входящие данные корректны, то код работает. Но вот система, в которой участвуют люди, не работает так, как надо. Это вызывает когнитивный диссонанс и фрустрацию. Решение, которое подсказывает опыт, тоже кажется очевидным — надо усилить контроль над системой, лучше собирая метрики, как этот делает докладчик, введя формальные performance review и one-to-one, анализируя переписку в слаке, заставляя заполнять таймшиты (для привычных программистам системам это решение имеет свои аналогии — добавить логгирование на каждый запрос, прикрутить мониторинги, запускать под дебагом). Когда эти решения не работают, либо ухудшают положение, то закручивание гаек заходит на второй круг, и когнитивный диссонанс только усиливается. Поэтому, нет, не удивляет ни разу.
PS: и да, все эти люди игнорируют один нюанс, который не вывести умозаключительно из практик работы ЭВМ — сам факт контроля над программистами (точнее, знания программистов о том, что их контролируют) сильно модифицирует их поведение — почти квантовая физика выходит. Программист, который чувствовал себя партнером бизнеса, который решает проблемы, становится конвейерным рабочим. Но об этом уже можно целую статью написать…sergof
16.11.2018 22:00Совершенно верно. Мы о своих данных и технологиях заботимся лучше чем о себе. Плохо то что это принято считать нормой.
ankh1989
17.11.2018 06:59Кстати, известный сторонник метрик это же Безос вроде. У него метрики поставлены чётко и даже программистов довольно неплохо строит. Работать в его компании идея как правило так себе, но судя по его доходам он всё делает правильно.
algotrader2013
17.11.2018 15:17Тоже слышал от знакомого программиста, который собирался переехать на ПМЖ в Германию, что работать программистом в Амазоне это дно — людей выжимают, и относятся, как к скоту, и читал соответсвующие вещи на форумах. Самому многие годы было интересно, как при таком отношении к людям можно захватывать рынок. Но узнав поглубже, как работают, и получают прибыль (да, несравнимую с Амазоном, но тоже значительную) одни из самых зашкварных IT компаний в Украине — Terrasoft, Playtech, и Paymentwall, пазл у меня сложился.
Да, можно получать прибыль, превращая программистов в конвеерных рабочих, придерживаясь ряда омерзительных правил
1) Должен быть костяк (ядро, отцы-основатели) — команда людей, которые жестко регламентируют инфраструктуру, домен, тулинг, библиотеки, подходы, документирование. Также они создают свои API, ORM, а некоторых самых запущенных случаях и IDE. Все, кто не входит в костяк, должны быть лишены права решать что-либо из этого, и должны иметь минимальный импакт на бизнес — этих людей никто даже не пытается удерживать при попытке уйти. Костяк, понятное дело, должен иметь особые права и привилегии, ЗП выше рынка, либо долю, и понимать свою исключительность — с ними так, как со всеми, нельзя.
2) Задачи должны быть шаблонные и однотипные. На каждую задачу должен быть готовый подход, бест практис, и понимание сложности в человекоднях. Если надо что-то принцпиально новое, то пока товарищи из пункта 1 не подумают, и не научат, как, никто этого делать не будет.
3) Бизнес должен быть устоявшимся и крепким, и должен прекрасно осознавать все ограничения и побочные эффекты такого подхода.
Если хоть одно из правил не соблюдается, то скотское отношение к людям на основе метрик заканчивается очень плохо для собственника.
По факту, если все правила соблюдены, то такой подход все равно приводит к снижению гибкости и удорожанию разработки (продукты и услуги по кастомизации мелких конкурентов со стартаперским мировозрением выходят в разы дешевле), но добавляет стабильности и снижает риски в выполнении шаблонных задач (что часто бывает приоритетным для бизнеса). Не обладаю информацией, как это работает у Безоса, но могу предположить, что схема подобная.
FYR
17.11.2018 21:24-1А зачем? все эти «метрики» «бизнес-процессы» они для получения прибыли. Бизнесу не нужен «довольный программист» бизнесу нужны деньги. Если довольный программист приносит денег на Х больше, чем недовольный, причем Х должен быть больше чем надо потратить чтобы сделать довольного программиста из недовольного — это хорошо и бизнес будет строить красивые офисы, приносить печеньки и прочая «нематериальная мотивация».
Бизнесмены они не меценаты — поэтому мы, программеры — ресурс который надо доить.
Вот и появляется больше различных методик как поменьше кормить и побольше доить. Только программеры больно умные: на лапшу про «командный игрок» не сильно ведутся, да творческие: не понимая как создают что-то из воздуха. Поэтому обычные не подходят — придумывают необычные.
enjoykaz
17.11.2018 11:31Спасибо за материал, очень крутой. Для многих сигналов инструменты внедрили уже, а для остальных на подходе.
Обидно только, что сейчас набегут скулящие разработчики, которые в любом порядке видят посягательство на их нелегкую судьбу.difference
17.11.2018 16:17+1комментарий странный.
я думал что хороший менеджер понимает психологию наёмного работника и подходит к этому трезво.
Каждый заботится о своих интересах, и глупо обвинять работника в том что он хочет работать в хороших условиях.
Некоторые из методик, описанных в статье, действительно полезные (тесты, например). А некоторые — ничто иное как способ давление, способ заставить девелоперов работать больше, быстрее но при этом ещё и без потери качества.
Слишком много КПИ и контролля — это антипаттерн управления.
Глупо таже ожидать что наёмный работник будет действительно болеть за проблемы бизнеса, учитывая что наёмный работник в любом случае не получит ни процента от прибыли проекта, а премия не перекроет уйму потраченного личного времени.
Я был на таких проектах, и могу сказать что талантливые или сколько-нибудь толковые разработчики просто ушли от такого менеджера. Почему бы и нет? Они были вполне в состоянии реализовать себя на рынке труда, даже прибавку получить. Менеджер этого не понимал, он думал что повышаешь давление — повышаешь результат. Со временем способные и толковые ушли — важности опытного дева он тоже не понимал, и потом проект развалился, конечно же. Сроки были сорваны, тендер потерян.
Если же менеджер смотри на работников исключительно как на ресурс, который вечно скулит, ленив, работает мало а получает много — это человек который живёт в своей выдуманной реальности, не понимая что людьми движут их собственные интересы и мотивы, а не то чтобы они хотели превозмогать и соответствовать выдуманной планке какого-то манагера в его «внутренней монголии»
romas1982 Автор
18.11.2018 12:47некоторые — ничто иное как способ давление, способ заставить девелоперов работать больше, быстрее но при этом ещё и без потери качества.
Заставить работать? Ну и много ли примеров, когда кого-то заставляли кодить больше, и действительно стали кодить больше? Не смешите меня. В этой профессии можно заставить быть на работе больше, но заставить работать больше, к сожалению, нельзя. И метрики тут никак не помогут. А вот поправить процесс, чтобы избавиться от издержек и лишней работы — вполне себе решаемая задача, и в большинстве случаев мне известных, меряют исключительно для этого.
Но. Есть две категории сотрудников — те, которые работают, и те, которые делают вид, что работают, попутно на каждом углу крича о том, их бедных несчастных прижимает кровавый бизнес. Если ты нормально работаешь и решаешь те задачи, которые тебе поручили — любая метрика скажет об этом. А вот если ты строишь ферму по полдня, ссылаясь на какие-то мифические сложности, о которых никто не знает, то это будет видно и будут приняты меры. Потому как пока ты пинаешь орган, рядом твои коллеги отдуваются в том числе и за тебя. А это не совсем честно.
Бизнес платит зарплату. Если бизнес идёт плохо, то зарплату в моменте будет нечем платить. И если ты наёмник (мы ведь в массе своей наёмники, да?), то будь любезен исполнять возложенные на тебя обязанности.
Еще раз повторюсь — метрики применяются для поиска неисправностей и улучшения процессов горздо чаще, чем для поиска способа напрячь кого-то ещё сильнее. В условиях дефицита кадров на рынке — это стрельба по ногам. Надавили — встали и ушли. Благо есть места, где платят и не давят вообще:)difference
18.11.2018 17:43а Due date — это не инструмет давления? К тому же, это и не по Скраму, где задачи набираются в спринт и не оцениваются в абсолютных единицах.
Можно сделать вид будто бы это тоже просто «метрика, которая позволяет улучшить процессы» или «избавиться от лишних издержек» но это будет лукавство. Это давит и висит как мечь на плечом, что вот я должен это закончить, т.к. я написал дату, и это значит что я подписался что я это сделаю.
Ещё про то что метрики покажут кто хорошо работает а кто плохо. Думаю, это возможно, но вряд ли это хорошо обобщается на все случаи. Например, ПМ смотрит — ага, много строчек кода изменённых в гите. Это точная и адекватная метрика, или может не совсем? Ведь хороший код — это лаконичный код, к тому же Вася, который пишет много, может ходить к за советом к Пете, который пишет мало кода, но он эксперт, и может делать то что могут не все.
>Бизнес платит зарплату. Если бизнес идёт плохо, то зарплату в моменте будет нечем платить.
сотрудник может просто перейти в другую компанию если чей-то бизнес накрылся. Вряд ли надрываться ради бизнеса — это умная стратегия для наёмного рабочего. Умная — это вкачать скилл насколько возможно, а потом перейти на следующий левел. Иногда скиллап совпадает с задачами бизнеса — ок, а если нет — ну уж…
Любая компания строит с сотрудником отношения по типу «утром стулья, вечером деньги». Т.е. ты типа поперформи, а мы потом оценим. Может быть [нет]. При этом эффорты, нужные для повышения, нужны в объёме, скажем, 150 %, а прибавка к зп произойдёт спустя год после усиленного вкалывания, и, например, на 10%. В общем, рентабельности никакой.
>Надавили — встали и ушли.
в крупных солидных компаниях сидят умные люди, которые целыми отделами годами вырабатывали эти схемы и стратегии. Никто напрямую не давит, скорее давят, но не признавая этого явно, и делая это, прикрываясь правдоподобными поводами, вот как «это нужно для порядка»romas1982 Автор
18.11.2018 17:58Due date — инструмент планирования. В скраме инструмент планирования — велосити и капасити, что само по себе чистейшей воды метрики. А выход фич из спринта — метрика для ПМ, по ним он ориентируется на завершение проекта. ПМ в код вообще не должен смотреть. Для него важны проектные и процессные метрики, а не инструментальные. Инструментальные метрики важны для того, кто отвечает за разработку, для СТО, например. Точность и адекватность метрик — это сложный процесс, которым надо заниматься постоянно и калибровать, например, в случае, если сильно изменилась команда. Если подходить к процессу с умом, то кучу пользы можно извлечь от измерений. Причём для всех, а не только для кровавого бизнеса.
Мы на конференции про измерения говорили очень много именно для того, чтобы показать пользу, а не разрекламировать очередной инструмент для пыток.
difference
18.11.2018 18:25«мы не строим концлагерь» — ну так все говорят. Можно подумать, что кто-то бы открыто признался что «да, я пытаюсь обойтись минимумом ресурсов и выжать те кто есть»
>Причём для всех, а не только для кровавого бизнеса.
звучит не слишком-то убедительно. :)
какая конкретно польза для наёмного рабочего?
>Точность и адекватность метрик — это сложный процесс, которым надо заниматься постоянно и калибровать, например, в случае, если сильно изменилась команда.
дело не в адекватности метрик и «сложном процессе калибровки», а в том что некоторые вещи нельзя извлечь в принципе и слишком много метрик — это антипаттерн.
Управленцы часто живут иллюзией, будто они чем-то управляют, глядя на свои бёрндаун чарты. На деле управляет всем грамотный архитектор, и только он понимает какие вещи за сколько могут быть сделаны, что реально, а что нет. А роль управленцев сводится к тому что они не мытьём так катанием — просто делая это в меру «тонко», пришкоривают команду аки лошадку.
А работнику, если он профессионал (а набрать именно таких — какраз и есть задача управленцев, в чем они часто ошибаются, думая что три джуна = один синьор), 100500 метрик, когда он там должен отписать что у него дата задерживается, да ещё причину указать, чтобы не выглядеть лузером, а там надо протрэкать другую метрику, а там третью, все эти вещи (повторяю — из-за обилия), будут раздражать и мешать работать. Я знаю случай когда ПМ много тыкал бёрндаун чарты мало не каждый день, так ему об этом сказали, и он тыкать перестал. Вот и всё метрики. А перестал потому, что если бы не перестал, некоторые ключевые фигуры могли бы психануть и просто уйти.
Так что это тоже надо учитывать — человеческий фактор. Люди, они, знаете ли, не подопытные кролики для экспериментов, а если они профи, то обычно знают себе цену, и могут просто послать куда подальше с этой пачкой метрик таких «инноваторов-затейников»
Если допустим вы нашли специалиста, который мотивирован, и хорошо квалифицирован — лучшее что можно сделать, это дать просто делать своё дело, а не мешать.
Потому что хороший профессионал… представьте себе врача, который делает операцию. Вы бы хотели чтобы он был собран, сосредотечен и уверен в своих действиях, или чтобы он нервничал, потому что его задолбали дёргать?romas1982 Автор
18.11.2018 18:38+1Звучит так, что вас не повезло с руководителем и, возможно, компанией.
Я готов открыто признаться — я хочу получать максимум пользы при минимуме затрат. Чтобы кроме проектов можно было позаниматься развитием технологического стека, поработать с техдолгом и всем тем, что не приносит прибыль в явном виде, не работать сверх положенного, или в выходные, когда внезапно выяснится, что проект просрали, а никто не в курсе.
И выжимать при этом я никого не хочу, пооому что разбегутся или начнут хачить систему по закону, который коллега привёл ниже.
Работник вообще ничего не знает про бОльшую часть метрик. Они нужны для калибровки процесса. И комит в код это лишь одна из метрик для оценки!!! процесса!!.. Если у вас в этот конкретный модуль идут комиты сотнями, значит важность тестов возрастает. Если у вас Вася делает следующим комитом откат предыдущего с завидным постоянством — это повод понять, откуда растут ноги. Может ему требования меняют регулярно и надо дать по голове тому, кто требования носит, а может он тупо не может с первого раза прочитать корректно и его надо научить читать правильно. А может от затрахался и ему надо в отпуск.
Откуда такое маниакальное стремление во всем увидеть желание работодателя выжать все соки??? Инженер без соков больше ошибается и приносит меньше пользы. Если руководит адекватный менеджер, который умеет адекватно читать результаты измерений — все хорошо и все счастливы. А сдуру, как известно, можно сломать что-угодно.
difference
18.11.2018 18:52может и так — может я не встречал одновременно адекватных и при этом эффективных (в хорошем смысле) менеджеров
enjoykaz
19.11.2018 00:02Вот тут браво просто. Адекватный менеджер это для вас неэффективный значит :)? Который заваривает кофе и развлекает всех в паузах? Это называется секретарша.
difference
19.11.2018 16:55адекватность и эффективность — это качества которые находятся в противоречии, как минимум частичном. Хороший менеджер — это розовый единорог, потому что каждый вкладывает в этом понятие что-то своё. А адекватных действительно мало, хотя бы потому что понятия «адекватный» и «считающий себя адекватным» — не одно и то же. Может кто-то и считает себя адекватным, при этом считая что программисты — это смерды скулящие, которые мешают Великому и могучему менеджеру навести порядок, но то что он так считает, не говорит ни о чем кроме самого факта что «кто-то там что-то там считает». Считать он может что-угодно, хоть править миром, пока не видят санитары, другое дело — как это воспринимают другие.
Throwable
18.11.2018 16:38Существует достаточно известный Закон Гудхарта, который имеет много формулировок, но как никогда лучше применим к IT-менеджменту:
ЗАКОН ГУДХАРТА
(Goodhart’s Law) Экономический закон, в соответствии с которым любая попытка правительства контролировать экономическую переменную может исказить эту переменную настолько, что сделает правительственный контроль неэффективным. Сформулированный экономистом-монетаристом Ч.А.Э. Гудхартом (род. 1936), он был впервые использован для измерения денежной массы (money supply) М0, М1 и М3 в фунтах стерлингов, которую монетаристские правительства (cм.: монетаризм (monetarism) пытались контролировать в целях снижения инфляции.
Гудхарт считает, что, как только люди узнают о попытках правительства контролировать какую-то экономическую переменную, они начинают всячески уклоняться от этого контроля, что ведет к нарушению правительственных планов.
Впринципе это все, что нужно знать о всякого рода метриках.
romas1982 Автор
18.11.2018 19:11Если ТОЛЬКО на основе метрик делаются решения, касающиеся социальной и экономической составляющей исполнителя (например, премия, зарплата, повышение в должности, прочие материальные и нематериальные блага конкретного сотрудника) — однозначно да. Выше неоднократно говорил и скажу ещё раз. Меряются не люди. Меряется процесс.
Три года назад я читал доклад на тему тёмной стороны метрик. В нём в том числе я говорил о том, то крайне опасно делать выводы исключительно на цифрах и приводил синтетические, но показательные примеры. www.youtube.com/watch?v=89Xn99ZzZoY
nckma
Мне кажется, что иногда разработчики слишком ленивы и умны, чтобы хакнуть метрики — делать больше или меньше коментов в коде, делать больше мелких комитов и т.д.
Оставлять артифакты везде, где можно, чтобы показать свою активность, но на самом деле не делать ничего или мало.
romas1982 Автор
Хакнут обязательно, если захотят. Но оставленные артефакты можно проверить, например, тимлидом или руководителем разработки и попросить больше так не делать. Метрики — это лишь часть большого процесса.
KoCMoHaBT61
Как их проверить?
Например: есть опытный программист A и неопытный программист B.
Тимлид смотрит бэклог и говорит: «вот тут есть баг, он непонятен, отдадим его A. А следующий баг очевиден и мы отдадим его B».
В результате A садится на задницу пытаясь найти руткос проблемы. Он не оставляет артефактов, у него нет коммитов. Он постоянно двигает due-date с мыслью «ну на этой-то неделе точно сделаю»
За время работы А программист B делает 10 мелких задач создавая много артефактов.
В конце концов у программиста А образуется 1 строка кода в правильном месте и его лишают премии за низкий рейт. Программист В получает почётную грамоту за великую производительность.
На следующей итерации всё повторяется.
powerman
Это решается разными способами. Можно анализировать метрики по опытным и неопытным разработчикам раздельно. Можно исключать из анализа такие "исследовательские" таски (для которых значительная часть используемых метрик явно не применима). Можно прибегать к анализу метрик только в тех случаях, когда традиционным (как обычно делается без метрик) способом понять что происходит не получается.
Тот кейс, который Вы описали — это банальный пример использования инструмента не по назначению. Это происходит прямо сейчас и без всяких метрик — почитайте как происходит продвижение в гугле, например. Навык сделать хорошо работу и навык донести факт важности/сложности/качества выполненной работы до того, кто должен оценивать тебя и твою работу — это два совершенно разных навыка. А учитывая, что первый навык (в случае программистов) относится к техническим, а второй к софт-скилам, то нет ничего удивительного в том, что мало у кого присутствуют оба сразу.
И адекватную и неадекватную оценку своей работы можно получить любым способом, хоть с метриками, хоть без метрик. От применения некоторых метрик (напр. подсчёт строк кода или частота нажатий на клавиши) намного больше вреда, чем пользы. Но это не значит, что полезных метрик не существует, и единственный доступный способ оценки — субъективное мнение непосредственного начальника и/или коллег.
Описанные в статье метрики — это просто инструмент. Им можно пользоваться адекватно, и он принесёт немало пользы. А можно пользоваться неадекватно, и он принесёт немало вреда.
Механически привязывать метрики к штрафам/премиям/повышениям/увольнениям, безусловно, нельзя — вреда от этого будет намного больше, чем пользы. Может лет через 20 метрики разовьются настолько, что подключенный к ним ИИ будет в состоянии автоматически принимать такие решения адекватно. А пока все эти метрики выполняют скорее роль утилиты-линтера, механически сигнализируя о типичных проблемах — такие сигналы полезны, но они не всегда корректны, и поэтому оценивать их адекватность всё равно пока что должен квалифицированный специалист.