
Вопреки расхожему мнению, машинное обучение — изобретение не XXI века. За последние двадцать лет появились лишь достаточно производительные аппаратные платформы, чтобы нейросети и другие модели машинного обучения было целесообразно применять для решения каких-либо повседневных прикладных задач. Подтянулись и программные реализации алгоритмов и моделей.
Соблазн сделать так, чтобы машины сами заботились о нашей безопасности и защищали людей (довольно ленивых, но сообразительных), стал слишком велик. По оценке CB Insights почти 90 стартапов (2 из них с оценкой более миллиарда долларов США) пытаются автоматизировать хотя бы часть рутинных и однообразных задач. С переменным успехом.

Главная проблема Artificial Intelligence в безопасности сейчас — слишком много хайпа и откровенного маркетингового буллшита. Словосочетание «Искусственный интеллект» привлекает инвесторов. В отрасль приходят люди, которые готовы называть AI простейшую корреляцию событий. Покупатели решений за свои же деньги получают не то, на что надеялись (пусть даже эти ожидания и были изначально слишком завышенными).

Как видно из карты CB Insights, выделяют с десяток направлений, в которых применяется МО. Но машинное обучение пока не стало «волшебной пилюлей» кибербезопасности из-за нескольких серьёзных ограничений.
Первое ограничение — узкая применимость функциональности каждой конкретной модели. Нейросеть умеет хорошо делать что-то одно. Если она хорошо распознаёт изображения, то эта же сеть не сможет распознавать аудио. То же самое и с ИБ, если модель обучили классифицировать события с сетевых сенсоров и выявлять компьютерные атаки на сетевое оборудование, то она же не сможет работать с мобильными устройствами, например. Если заказчик — фанат ИИ, то он будет покупать, покупать и покупать.
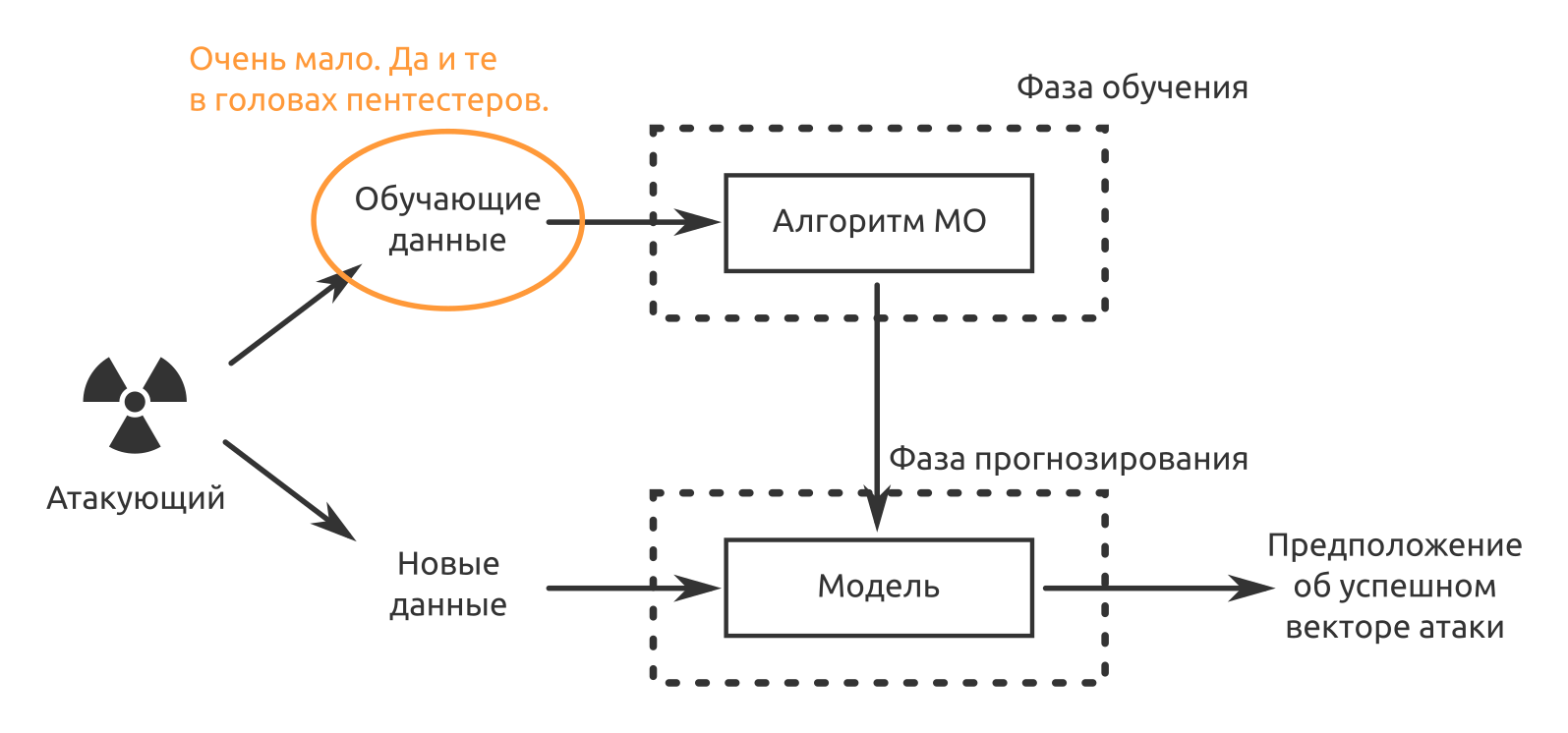
Второе ограничение — нехватка обучающих данных. Решения предобучены, но не на ваших данных. Если ситуацию «Кто же считает false-positive в первые две недели эксплуатации» ещё можно принять, то в дальнейшем «безопасников» ждёт лёгкое недоумение, ведь решение покупали, чтобы машина взяла на себя рутину, а не наоборот.

Третье и, наверное, пока главное — МО-продукты нельзя заставить отвечать за свои решения. Даже разработчик «уникального средства защиты с искусственным интеллектом» может на такие претензии ответить, «Ну а что вы хотели? Нейросеть — это же чёрный ящик! Почему она решила именно так, никто, кроме неё, и не знает». Поэтому сейчас инциденты информационной безопасности подтверждают люди. Машины помогают, но ответственность несут по-прежнему люди.
С защитой информации проблемы есть. Их рано или поздно решат. Но как дела с нападением? Могут ли МО и ИИ стать «серебряной пулей» кибератак?
Наверное, сейчас выгоднее всего использовать МО там, где:
С этими задачами МО уже отлично справляется. Но и кроме этого некоторые задачи можно ускорить. Например, мои коллеги уже писали об автоматизации атак с помощью python и metasploit.
Или же проверить осведомлённость сотрудников в вопросах информационной безопасности. Как показывает наша практика тестирования на проникновение, социнженерия работает — почти на всех проектах, где была проведена такая атака, мы добивались успеха.
Предположим, что мы уже восстановили, используя традиционные методы (сайт компании, соцсети, сайты вакансий, публикации и т.д.):
Дальше нам нужно получить данные, чтобы обучить нейросеть, которая будет имитировать голос конкретного человека. В нашем случае — кого-нибудь из руководства тестируемой компании. В этой статье говорится, что достаточно одной минуты голоса, чтобы достоверно притвориться.
Ищем записи выступлений на конференциях, сами на них ходим и записываем, пытаемся поговорить с нужным нам человеком. Если у нас получается сымитировать голос, то стрессовую ситуацию для конкретной жертвы атаки мы можем создать сами.
Кто не ответит? Кто не посмотрит вложение? Посмотрят все. И грузить в это письмо можно всё, что угодно. При этом не обязательно знать ни телефон директора, ни личный телефон продавца, не нужно подделывать адрес электронной почты на внутрикорпоративный, с которого придёт вредоносное письмо.
Кстати, подготовку атаки (сбор и анализ данных) тоже можно частично автоматизировать. Мы как раз сейчас ищем разработчика в команду, которая решает такую задачу и создаёт программный комплекс, облегчающий жизнь аналитика в области конкурентной разведки и экономической безопасности бизнеса.
Предположим, что мы можем слушать зашифрованный трафик атакуемой организации. Но нам хотелось бы знать, что именно в этом трафике. На идею меня натолкнуло вот это исследование сотрудников компании Cisco «Обнаружение вредоносного кода в защифрованном TLS-трафике (без дешифровки)». Ведь если мы можем на основании данных из NetFlow, служебных данных TLS и DNS определять присутствие вредоносных объектов, то что нам мешает использовать те же данные для идентификации коммуникаций между сотрудниками атакуемой организации и между сотрудниками и корпоративными ИТ-сервисами?
Атаковать крипту в лоб — себе дороже. Поэтому, используя данные об адресах и портах источника и получателя, числе переданных пакетов и их размере, временных параметрах, мы стараемся определить зашифрованный трафик.
Далее, определив криптошлюзы или конечные узлы в случае p2p-коммуникаций, мы начинаем их досить, вынуждая пользователей переходить на менее защищённые способы связи, которые атаковать уже проще.
Прелесть метода заключается в двух преимуществах:
Недостаток — MitM ещё надо получить.
Наверное, самая известная попытка автоматизировать поиск, эксплуатацию и исправление уязвимостей — DARPA Cyber Grand Challenge. В 2016 году в финальной CTF-подобной битве сошлись семь полностью автоматических систем, спроектированных разными командами. Конечно, цель разработок декларировалась исключительно благая — защищать инфраструктуры, iot, приложения в реальном времени и с минимальным участием людей. Но на результаты ведь можно посмотреть и под другим углом зрения.
Первое направление, в котором развивается МО в этом деле — автоматизация фаззинга. Те же участники CGC широко использовали american fuzzy lop. В зависимости от настройки фаззеры генерируют больший или меньший объём выходных данных во время работы. Там, где много структурированных и слабоструктурированных данных, модели МО отлично ищут закономерности. Если попытка «уронить» приложение сработала с какими-то входными данными, есть вероятность, что такой подход сработает где-то ещё.
То же самое и со статическим анализом кода и динамическим анализом исполняемых файлов, когда исходный код приложения недоступен. Нейросети могут искать не просто куски кода с уязвимостями, а код, похожий на уязвимый. Благо, кода с подтверждёнными (и исправленными) уязвимостями очень много. Исследователю останется проверить это подозрение. С каждым новым найденным багом такая НС будет становиться всё «умнее». Благодаря такому подходу можно уйти от использования только предварительно написанных сигнатур.
В динамическом же анализе, если нейросеть сможет «понимать» связь между входными данными (включая пользовательские), порядком выполнения, системными вызовами, распределением памяти и подтверждёнными уязвимостями, то она со временем сможет искать и новые.
Сейчас с чисто автоматической эксплуатацией есть проблема —
Решить её пытается Isao Takaesu и другие контрибуторы, которые разрабатывают Deep Exploit — «Fully automatic penetration test tool using Machine Learning». Подробно про него написано тут и тут.
Это решение может работать в двух режимах — режиме сбора данных и режиме брут-форса.
В первом режиме DE идентифицирует все открытые порты на атакуемом узле и запускает эксплойты, которые уже раньше срабатывали для такой комбинации.
Во втором режиме атакующий указывает название продукта и номер порта, а DE «бьёт по площадям», используя все доступные комбинации эксплойта, пейлоада и цели.
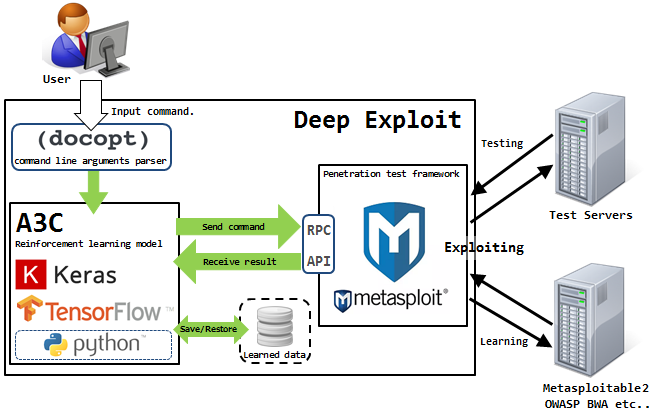
Deep Exploit может самостоятельно обучаться методам эксплуатации, используя обучение с подкреплением (благодаря обратной связи, которую DE получает от атакуемой системы).
Наверное, пока нет.
У машин есть проблемы с выстраиванием логических цепочек эксплуатации выявленных уязвимостей. А ведь именно это зачастую прямо влияет на достижение цели тестирования на проникновение. Машина может найти уязвимость, может даже самостоятельно создать эксплойт, но она не может оценить степень влияния этой уязвимости на конкретную информационную систему, информационные ресурсы или бизнес-процессы организации в целом.
Работа автоматизированных систем генерирует МНОГО шума на атакуемой системе, который легко замечается средствами защиты. Машины работают топорно. Уменьшить этот шум и получить представление о системе можно с помощью социнженерии, а с этим у машин тоже не очень.
А ещё у машин нет смекалки и «чуйки». У нас недавно был проект, где наиболее экономически выгодным способом проведения тестирования было бы использовать радиоуправлямую модель. Я не представляю, как не-человек мог бы до такого додуматься.
А вы какие идеи для автоматизации могли бы предложить?
Соблазн сделать так, чтобы машины сами заботились о нашей безопасности и защищали людей (довольно ленивых, но сообразительных), стал слишком велик. По оценке CB Insights почти 90 стартапов (2 из них с оценкой более миллиарда долларов США) пытаются автоматизировать хотя бы часть рутинных и однообразных задач. С переменным успехом.
Главная проблема Artificial Intelligence в безопасности сейчас — слишком много хайпа и откровенного маркетингового буллшита. Словосочетание «Искусственный интеллект» привлекает инвесторов. В отрасль приходят люди, которые готовы называть AI простейшую корреляцию событий. Покупатели решений за свои же деньги получают не то, на что надеялись (пусть даже эти ожидания и были изначально слишком завышенными).
Как видно из карты CB Insights, выделяют с десяток направлений, в которых применяется МО. Но машинное обучение пока не стало «волшебной пилюлей» кибербезопасности из-за нескольких серьёзных ограничений.
Первое ограничение — узкая применимость функциональности каждой конкретной модели. Нейросеть умеет хорошо делать что-то одно. Если она хорошо распознаёт изображения, то эта же сеть не сможет распознавать аудио. То же самое и с ИБ, если модель обучили классифицировать события с сетевых сенсоров и выявлять компьютерные атаки на сетевое оборудование, то она же не сможет работать с мобильными устройствами, например. Если заказчик — фанат ИИ, то он будет покупать, покупать и покупать.
Второе ограничение — нехватка обучающих данных. Решения предобучены, но не на ваших данных. Если ситуацию «Кто же считает false-positive в первые две недели эксплуатации» ещё можно принять, то в дальнейшем «безопасников» ждёт лёгкое недоумение, ведь решение покупали, чтобы машина взяла на себя рутину, а не наоборот.
Третье и, наверное, пока главное — МО-продукты нельзя заставить отвечать за свои решения. Даже разработчик «уникального средства защиты с искусственным интеллектом» может на такие претензии ответить, «Ну а что вы хотели? Нейросеть — это же чёрный ящик! Почему она решила именно так, никто, кроме неё, и не знает». Поэтому сейчас инциденты информационной безопасности подтверждают люди. Машины помогают, но ответственность несут по-прежнему люди.
С защитой информации проблемы есть. Их рано или поздно решат. Но как дела с нападением? Могут ли МО и ИИ стать «серебряной пулей» кибератак?
Варианты использования машинного обучения для повышения вероятности успеха пентеста или анализа защищённости
Наверное, сейчас выгоднее всего использовать МО там, где:
- нужно создать что-то похожее на то, с чем нейросеть уже сталкивалась;
- нужно выявлять неочевидные человеку закономерности.
С этими задачами МО уже отлично справляется. Но и кроме этого некоторые задачи можно ускорить. Например, мои коллеги уже писали об автоматизации атак с помощью python и metasploit.
Пытаемся обмануть
Или же проверить осведомлённость сотрудников в вопросах информационной безопасности. Как показывает наша практика тестирования на проникновение, социнженерия работает — почти на всех проектах, где была проведена такая атака, мы добивались успеха.
Предположим, что мы уже восстановили, используя традиционные методы (сайт компании, соцсети, сайты вакансий, публикации и т.д.):
- организационную структуру;
- список ключевых сотрудников;
- паттерны адресов электронной почты или реальные адреса;
- позвонили, прикинулись потенциальным клиентом, узнали как зовут продавца, менеджера, секретаря.
Дальше нам нужно получить данные, чтобы обучить нейросеть, которая будет имитировать голос конкретного человека. В нашем случае — кого-нибудь из руководства тестируемой компании. В этой статье говорится, что достаточно одной минуты голоса, чтобы достоверно притвориться.
Ищем записи выступлений на конференциях, сами на них ходим и записываем, пытаемся поговорить с нужным нам человеком. Если у нас получается сымитировать голос, то стрессовую ситуацию для конкретной жертвы атаки мы можем создать сами.
— Алло?
— Продавец Пресейлович, здравствуй. Это Директор Начальникович. У тебя чего-то мобильный не отвечает. Там тебе сейчас придёт письмо из ООО «Вектор-Фейк», посмотри, пожалуйста. Это срочно!
— Да, но…
— Всё, не могу больше разговаривать. Я на встрече. До связи. Ответь им!
Кто не ответит? Кто не посмотрит вложение? Посмотрят все. И грузить в это письмо можно всё, что угодно. При этом не обязательно знать ни телефон директора, ни личный телефон продавца, не нужно подделывать адрес электронной почты на внутрикорпоративный, с которого придёт вредоносное письмо.
Кстати, подготовку атаки (сбор и анализ данных) тоже можно частично автоматизировать. Мы как раз сейчас ищем разработчика в команду, которая решает такую задачу и создаёт программный комплекс, облегчающий жизнь аналитика в области конкурентной разведки и экономической безопасности бизнеса.
Атакуем реализации криптосистем
Предположим, что мы можем слушать зашифрованный трафик атакуемой организации. Но нам хотелось бы знать, что именно в этом трафике. На идею меня натолкнуло вот это исследование сотрудников компании Cisco «Обнаружение вредоносного кода в защифрованном TLS-трафике (без дешифровки)». Ведь если мы можем на основании данных из NetFlow, служебных данных TLS и DNS определять присутствие вредоносных объектов, то что нам мешает использовать те же данные для идентификации коммуникаций между сотрудниками атакуемой организации и между сотрудниками и корпоративными ИТ-сервисами?
Атаковать крипту в лоб — себе дороже. Поэтому, используя данные об адресах и портах источника и получателя, числе переданных пакетов и их размере, временных параметрах, мы стараемся определить зашифрованный трафик.
Далее, определив криптошлюзы или конечные узлы в случае p2p-коммуникаций, мы начинаем их досить, вынуждая пользователей переходить на менее защищённые способы связи, которые атаковать уже проще.
Прелесть метода заключается в двух преимуществах:
- Машину можно обучить у себя, на виртуалочках. Благо бесплатных и даже open-source продуктов для создания защищённых коммуникаций существует предостаточно. «Машина, вот это такой-то протокол, в нём такие-то размеры пакетов, такая-то энтропия. Поняла? Запомнила?». Повторить как можно больше раз на различных типах открытых данных.
- Не надо «гнать» и пропускать через модель весь трафик, достаточно только метаданных.
Недостаток — MitM ещё надо получить.
Ищем баги и уязвимости ПО
Наверное, самая известная попытка автоматизировать поиск, эксплуатацию и исправление уязвимостей — DARPA Cyber Grand Challenge. В 2016 году в финальной CTF-подобной битве сошлись семь полностью автоматических систем, спроектированных разными командами. Конечно, цель разработок декларировалась исключительно благая — защищать инфраструктуры, iot, приложения в реальном времени и с минимальным участием людей. Но на результаты ведь можно посмотреть и под другим углом зрения.
Первое направление, в котором развивается МО в этом деле — автоматизация фаззинга. Те же участники CGC широко использовали american fuzzy lop. В зависимости от настройки фаззеры генерируют больший или меньший объём выходных данных во время работы. Там, где много структурированных и слабоструктурированных данных, модели МО отлично ищут закономерности. Если попытка «уронить» приложение сработала с какими-то входными данными, есть вероятность, что такой подход сработает где-то ещё.
То же самое и со статическим анализом кода и динамическим анализом исполняемых файлов, когда исходный код приложения недоступен. Нейросети могут искать не просто куски кода с уязвимостями, а код, похожий на уязвимый. Благо, кода с подтверждёнными (и исправленными) уязвимостями очень много. Исследователю останется проверить это подозрение. С каждым новым найденным багом такая НС будет становиться всё «умнее». Благодаря такому подходу можно уйти от использования только предварительно написанных сигнатур.
В динамическом же анализе, если нейросеть сможет «понимать» связь между входными данными (включая пользовательские), порядком выполнения, системными вызовами, распределением памяти и подтверждёнными уязвимостями, то она со временем сможет искать и новые.
Автоматизируем эксплуатацию
Сейчас с чисто автоматической эксплуатацией есть проблема —
Решить её пытается Isao Takaesu и другие контрибуторы, которые разрабатывают Deep Exploit — «Fully automatic penetration test tool using Machine Learning». Подробно про него написано тут и тут.
Это решение может работать в двух режимах — режиме сбора данных и режиме брут-форса.
В первом режиме DE идентифицирует все открытые порты на атакуемом узле и запускает эксплойты, которые уже раньше срабатывали для такой комбинации.
Во втором режиме атакующий указывает название продукта и номер порта, а DE «бьёт по площадям», используя все доступные комбинации эксплойта, пейлоада и цели.
Deep Exploit может самостоятельно обучаться методам эксплуатации, используя обучение с подкреплением (благодаря обратной связи, которую DE получает от атакуемой системы).
Может ли сейчас ИИ заменить команду пентестеров?
Наверное, пока нет.
У машин есть проблемы с выстраиванием логических цепочек эксплуатации выявленных уязвимостей. А ведь именно это зачастую прямо влияет на достижение цели тестирования на проникновение. Машина может найти уязвимость, может даже самостоятельно создать эксплойт, но она не может оценить степень влияния этой уязвимости на конкретную информационную систему, информационные ресурсы или бизнес-процессы организации в целом.
Работа автоматизированных систем генерирует МНОГО шума на атакуемой системе, который легко замечается средствами защиты. Машины работают топорно. Уменьшить этот шум и получить представление о системе можно с помощью социнженерии, а с этим у машин тоже не очень.
А ещё у машин нет смекалки и «чуйки». У нас недавно был проект, где наиболее экономически выгодным способом проведения тестирования было бы использовать радиоуправлямую модель. Я не представляю, как не-человек мог бы до такого додуматься.
А вы какие идеи для автоматизации могли бы предложить?
Svbakulin
Да, совершенно верно: сейчас ML называют все что угодно. Еще вчера что то называлось statistical anomaly detection, гистограммы банальные с жестким трешолдом, теперь это внезапно стало ML. Спорить с продажниками даже непонятно как, они действительно обычно верят что это оно и есть :)
В то же время совершенно новые решения вроде Darktrace которые действительно используют ML на деле выглядят даже несколько пугающе — слишком просто и легко чтобы быть правдой. Но если разобраться и копнуть немного глубже в этот самый ML, не так все страшно. ML — не панацея, скорее новый слой, дополнение, но он радикально упрощает некоторые вещи. Толковый человек с мозгами все еще нужен, даже нужнее чем раньше и надо их даже больше, но небольшок количество нажимальщиков кнопок можно заменить алгоритмом. ML-AI имхо это что то вроде квантовых вычислений в каком то смысле- делаем все сразу, но никогда со 100% вероятностью.
Работая вместе с другими системами, ML позволяют выйти на новый уровень осведомленности и вероятно контроля над ситуацией. Но не сами по себе.
Serenevenkiy Автор
О да, так и хочется иногда спикеров притормозить!
По поводу Darktrace. Вы с ним работали или где-то видели презентацию на рабочем решении? Я посмотрел их сайт, сразу на ум приходит картинка из статьи, где «Прими своего спасителя». Наверное, я избалован (или привык к ним) всё-таки российскими сайтами с решениями по защите информации, где побольше технической информации и хотя бы становится понятно, как это всё работает. В общих чертах. У Darktrace запросил whitepapers и даташиты. Интересно будет почитать.
Svbakulin
Да, с Darktrace я работал вживую. Делал PoC на пару месяцев, довольно успешно. Честно говоря изначально я был очень скептически настроен. Как вы говорите, документации технической очень мало: даже с партнерским доступом там десятка три документов, бОльшая часть из которых маркетинговые, остальные довольно общие. Общение с техническими специалистами и пара живых демо радикально улучшают понимание того как это работает. В брощюрах выглядит все сказочно красиво, прям слишком хорошо чтобы быть правдной, потому я не ожидал ничего особенного. Но когда дошло до дела (PoC), все оказалось в общем то как они и обещали, к моему сильному удивлению. Настроек вообще никаких, кроме management IP (можно добавить LDAP и еще некоторые вещи, тогда будут появщяться фотографии пользователей из эксченджа что вообще башню срывает :) но без них тоже все прекрасно раотает) — для меня это было важно ввиду острой ограниченности ресурсов. Потом несколько дней все мелькало постоянно, переоценивалось, пока модели строились. Потом, когда модели стабилизировались, начались интересные вещи. Алерты получились довольно высококачественные. Даже когда они не malicious, они как правило ловили что то очень необычное что вполне могло быть серьезным.
Что я особо оценил так это ползунок чувствительности. Передвинул с 90 на 70% и тут же вылезает куча новых вещей, так же в обратную сторону. Это все динамически и практически мгновенно, т.е. все «старые» аномалии становятся видны или невидны в зависимости от этого ползунка, не надо ждать пока модели обновятся или переигрывать.
И ловили совершенно валидные аномалии, случайный RDP наружу (никто больше так не делал), аплоад на внешний сайт рядом по времени с доступом к файловому серверу. WIndows 10 нестандартная (разработчик поставил на коленке) творившая что то совершенно непонятное с DNS, и еще кое какие вещи. Все что мы видели могло запросто быть malicious. На мой взгляд есть продукты более точные и предсказуемые для отлова точно malicious вещей таких как malware всех сортов — напирмер Cisco AMP (network), или всякие host based AMP. Где Darktrace выстреливает — это отлов non-malware аномалий, в частности insider threats. Я не смог увидеть легкого способа отловить то, что увидел Darktrace с помощью более классических вещей как SIEM и IPS — все эти срабатывания не оставляли malware trace (т.е. ничто signature или hash-based это просто бы не увидело, в тч. AMP), все были разрешены политиками фаирволов, и не были громкими. Например data exfiltration событие не было очень большим, всего несколько сотен МБ когдв есть юзеры с сотнями ГБ, и что сработало так это то что был «редкий» дестинейшен и близкое событие по внутреннему доступу. В целом там все пляшет вокруг теоремы Байеса в итоге, так что достаточно проверенная и надежная математика.
Почему это не панацея, так просто потому что каждое такое срабатывание нужно анализировать, и для этого нужен хороший аналитик. DT покажет какая модель сработала, процентное соотношение, даст гистограммы какие есть — это все помогает. Но это все вероятности, и чтобы их превратить в подтвержденный инцидент надо нырять в PCAP и читать протоколы, пытаться распутать что же _именно_ там было, а тут уже надо знать и техники атак, и как они выглядят в packet capture, и неплохо бы понимать среду. Но наличие PCAP позволяет начать распутывать аномалии тут же, на месте без привлечения внешних инструментов, что на мой взгляд тоже критически важно.
Но это совсем не то же что копаться в алертах SIEM которые ничего особо не расскажут, если только они не настроены на очень определенное событие которое нужно точно понимать заранее и знать как оно выглядит в логах и корееляции, что все еще может бытьне достаточно чтобы поймать кого то за руку.
Ну и визуализация у DT конечно шикарная, это их WOW фактор. Не только 3D, дополнительные drill-down тоже очень юзабельные. Внутри — elasticsearch, но вокруг него действительно накручено немало математики, где действительно скрывается огромное количество интеллектуального труда который собственно и стоит тех денег которые просят за это решение.
Svbakulin
Кстати, более осведомленные коллеги тут недавно рассказали. Есть еще такие ребята, extrahop.com Они по всей видимости очень похожи на DT, но утверждают что у них больше моделей. DT мониторит порядка 200 разных переменных (измерений, как они их называют), но моделей как таковых у них не так много, что то около десятка.
extrahop утверждают что у них больше 30. Но это совсем стартапистный стратап, сам не видел и как и где его можно попробовать даже не совсем понятно.
Serenevenkiy Автор
Что касается ползунка чувствительности, это данные, которые собрал сам DT? Или к нему какой-то логколлектор прикручивается, и DT может «лезть» в прошлое?
И второй вопрос: он у вас стоял рядом с каким-то более-менее традиционным средством защиты или отдельно? Не оценивали DT на false-positive в сравнении с чем-то другим? Действительно интересно, потому что фактически ты покупаешь чёрный ящик, на который полагаешься. И есть риск, что ты даже не знаешь, что что-то пропускаешь.
Svbakulin
Не, никаких логов. DT только SPAN слушает, все оттуда но там разумеется должно быть все что нужно. В частности (и как минимум) AD траффик для айдентити, DHCP, DNS для обогащения информации. Ну и разумеется юзерский траффи или что там нужно мониторить на аномалии. В этом и прелесть — внедрение элементарное, если траффик централизован. RSPAN и прочее тоже поддерживается, так что обычно есть варианты. С логами и SIEM вообще самая большая проблема — как эти логи добывать. Типичные вещи еще худо-бедно стандартизированы, но не самые популярные приложения — там надо все самому писать а это нереально обычно. В то же время работает все как правило или на http/s или на еще чем то обычном, так что в SPAN-e это как правило можно разобрать до какой то степени.

Про ползунок — вот он на картинке.
Суть в том, что всё что мониторится в данный момент, т.е. все «модели» для отдельных хостов, юзеров или сетей, оно все имеет некую текущую вероятность. Допустию юзер вася сейчас имеет 80% вероятность по модели data exfiltration или что то такое. В зависимости от положения ползунки, интерфейс будет показывать текущие аномалии от установленного уровня и выже (это иконки с восклицательным знаком слева от позунка). И это все риал тайм, т.е. это не дискретное срабатывание модели в определенный момент времени которое уже не изменить, как в SIEM. В последнем событие генерируется при совпадении как правило довольно четких критериев, например "> X MB upload from network range a.a.a.a-b.b.b.b), примерно так же в IPS. В дарктрейсе трешолдов нет, точнее он их сам находит как и положено ML. Я видел срабатывания на считаные килобайты, потому что это выделялось; вручную так не сделать, или будет огромное количество шума.
В прошлое да, можно заглядывать. Там можно установить окно времени и работать в нем. Деталей сейчас уже не помню, но можно смотреть аналитику по этому окну точно. Так же разумеется можно сгенерировать on-demand PCAP из прошлого по определенному соединению, прямо из интерфейса. Т.е. на 3D map можно выбрать линию и оттуда будет подменю которое сразу даст PCAP по этому соединению.
Хранилище там не очень большое, на X2-10G модели было вроде 6Гиг всего, но обычно хватает на какое то время(дни). Я так понимаю он не все подряд хранит, и удаляет в первую очередь неинтересные капчи. Метадата по коннекшенам может храниться дольго — недели(т.е. разбор протокола, а не полный PCAP), и потом еще есть один уровень более обобщенной метадаты которая может храниться гораздо дольше (обещают месяцы). Детали того, как именно этот процесс работает не видно — черный ящик — но по ощущениям все примерно так и выглядело как рассказывали.
Работал он параллельно с другими контролями, но по покрытию я бы не сказал что они сильно пересекались. SIEM видит только то, что доступно в логах — это малая доля того что было в SPAN-e, и может работать только с тем на что настроены правила. Надо знать все заранее. В зрелых средах политики будут прописаны на бумаге, и только потом внедрены в SIEM, но такое редко где найдется (военные и секретные службы разьве что). IPS может ловить только эксплойты, так что тоже сравнивать нельзя.
Насчет false-positives, тут я бы немного задумался что под этим словом понимать. У IPS это просто — эксплойт\нормальный траффик. У Malware систем тоже. У аномалий и поведения — тут интереснее.
Событий будет моного, даже с ползунком на 90% будет десятки в день. Если смотреть топовые, то как правило (и все что мы видели) они будут чем то необычным как минимум, так что это как бы не совсем false-positive даже когда это в тоге определяется как нормальная активность (non-malicious). Это будет, как правило, либо что то о чем вы не знали, либо кто то что то делает не как все, либо какое то изменение в среде или очень редкая активность.
Даже кода это non-malicious, разбор таких вещей позволяет гораздо лучше понять среду. Там можно много интересного найти.
Именно в этом и фишка — этот подход позволяет ловить insider threats которые не оставят ни malware ни policy violation cледа, почти любое malware, в т.ч. неизвестно, которое остовляет след в сети (потому что это будет выделяться из общей картины траффика), и прочие пакости.
Я ума не приложу как еще можно отловить такие вещи «обычными» средствами.
В общем DT не похож, пожалуй, ни на что другое, что я видел. Эта такая «живая» система, интерактивная, которая дает хорошие подсказки и позволяет аналитику копать глубже, вполоть до PCAP, и при этом позволяет очень легки регулировать уровень «шума» (или нагрузки на аналитика) через тот самый ползунок.
-«И есть риск, что ты даже не знаешь, что что-то пропускаешь.»
Совершенно верно, такое риск есть, но он есть всегда просто под разным соусом.
Да, DT может в принципе пропустить что то, что даже банальный антивирус поймает 100% просто потому что не будет достаточно критериев чтобы поднять вероятность аномалии до видимого уровня. Но в то же время он может увидеть что то, что ничто другое увидеть не сможет в принципе пока кто то это не разберет по косточкам и не превратит в signature или правило. Поэтому я и говорю что DT не стоит видеть как замену чему либо (может быть SIEM до какой то степени, но далеко не полностью), и это скорее совершенно новый слой, который дает доселе недоступный уровень осведомленности.
Я разговаривал с парой человек из разных больших огранизаций, и отзывы от них были очень положительные.
То, что я сам видел в довольно чистой среде, было как минимум очень настораживающим, хоть и non-malicious, потому что точно такие же техники могли быть использованы для серьезной атаки.
Поскольку объяснить все это очень сложно, их стратегия продаж построена на бесплатном Proof of value который обычно занимает где то месяц. Это позволяет им показать как это работает и как правило продемонстрировать на деле. Утверждают что очень часто нахотя что то серьезнов в процессе PoV, что приводит к успешной покупке :) Видев это вживую, я понимаю почему они выбирают такой подход.
Svbakulin
Ограничение на редактирование комментариев к сожалению не позволяют исправить грамматику и логически неточности, но пару моментов из предыдущего поста стоит уточнить.
«DT может в принципе пропустить что то, что даже банальный антивирус поймает 100% просто потому что не будет достаточно критериев»
Это при условии что этот антивирус это вообще увидит, конечно. То есть он должен быть установлен, обновлен, и нормально работать. DT же работает со SPAN, так что если есть траффик — есть видимость (до какой то степени)
В моей среде полно тупого оборудования на которое нельзя ничего поставить, но которое тем не менее часто слушает на 139 и 445 и бог знает чем оно это делает. Так же много систем которые мне (как безопаснику) не доступны и неподотчетны — 3rd party всякие. Так что для меня вопрос доступности и эффективности более классических контролей стоит очень остро.
«Я разговаривал с парой человек из разных больших огранизаций, ...»
Из огранизаций, которые давно внедрили дарктрейс (3-4 года назад), разумеется. По их отзывам он однозначно окупился.
Svbakulin
Еще одно
«Событий будет моного, даже с ползунком на 90% будет десятки в день»
это я по своей ситуации сужу, это довольно большая среда, и очень разношерстная (те. куча всего разного в сети, тысячи приложений и сотни разных типов устройств)
Если среда более стабильная и предсказуемая, полагаю аномалий там будет гораздо меньше, и если что то будет — скорее всего будет интересное.
Так что false-positive, вообще говоря, в обобщенном случае должно быть немного. Обращу внимание что это без каких либо ручных настроек — подключил и забыл.