
Как поднять High-Availability Kubernetes кластер и не взорвать мозг? Использовать Kubespray, конечно же.
Kubespray — это набор Ansible ролей для установки и конфигурации системы оркестрации контейнерами Kubernetes.
Kubernetes является проектом с открытым исходным кодом, предназначенным для управления кластером контейнеров Linux как единой системой. Kubernetes управляет и запускает контейнеры на большом количестве хостов, а так же обеспечивает совместное размещение и репликацию большого количества контейнеров.
Осторожно, под катом 4 скриншота elasticsearch и 9 скриншотов prometheus!
Подготовка
Имеется 3 ноды Centos 7 с 8ГБ памяти.
На каждой ноде выполняем следующее.
Подключаем диски, размеры которых нам нужны.
Для elastic нужны 3 PV больше 30ГБ (data.persistence.size) и 2 PV больше 4ГБ (master.persistence.size).
Для этого на каждой ноде создадим 2 диска нужных нам размеров.
Размеры диска зависит от кол-ва ваших данных — нужно проверять экспериментально.
Disk /dev/vdb: 21.5 GB
Disk /dev/vdc: 53.7 GBЧерез fdisk создаем на каждом 1 раздел
В /mnt/disks создаем папку с названием нашего нового диска
mkdir -p /mnt/disks/vdb1
mkdir -p /mnt/disks/vdc1Создаем ФС на этих дисках
mkfs.xfs -f /dev/vdb1
mkfs.xfs -f /dev/vdc1Примонтируем диски в эту папки
mount /dev/vdb1 /mnt/disks/vdb1
mount /dev/vdc1 /mnt/disks/vdc1Проверяем
mount | grep mnt
/dev/vdb1 on /mnt/disks/vdb1 type xfs (rw,relatime,attr2,inode64,noquota)
/dev/vdc1 on /mnt/disks/vdc1 type xfs (rw,relatime,attr2,inode64,noquota)Скачиваем kubespray и запускаем установку kubernetes
git clone https://github.com/kubernetes-incubator/kubespray.git
cd kubespray
pip install -r requirements.txtПриводим inventory/sample/hosts.ini к следующему виду (названия нод замените на свои)
[k8s-cluster:children]
kube-master
kube-node
[all]
test-tools-kuber-apatsev-1 ansible_host=ip-первой-ноды ip=ip-первой-ноды
test-tools-kuber-apatsev-2 ansible_host=ip-второй-ноды ip=ip-второй-ноды
test-tools-kuber-apatsev-3 ansible_host=ip-третьей-ноды ip=ip-третьей-ноды
[kube-master]
test-tools-kuber-apatsev-1
test-tools-kuber-apatsev-2
test-tools-kuber-apatsev-3
[kube-node]
test-tools-kuber-apatsev-1
test-tools-kuber-apatsev-2
test-tools-kuber-apatsev-3
[etcd]
test-tools-kuber-apatsev-1
test-tools-kuber-apatsev-2
test-tools-kuber-apatsev-3
[calico-rr]
[vault]
test-tools-kuber-apatsev-1
test-tools-kuber-apatsev-2
test-tools-kuber-apatsev-3Меняем значения ниже в файле inventory/sample/group_vars/k8s-cluster/addons.yml
helm_enabled: true # устанавливаем helm на ноды
local_volume_provisioner_enabled: true # активируем local volume provisioner
ingress_nginx_enabled: true # активируем ingress controllerДобавляем в конец файла inventory/sample/group_vars/k8s-cluster.yml
docker_dns_servers_strict: no # устанавливаем в 'no', если число DNS серверов больше 3Запускаем установку
Перед установкой читаем документацию kubespray https://github.com/kubernetes-incubator/kubespray
ansible-playbook -u 'пользователь, который имеет sudo на нодах' -i inventory/sample/hosts.ini cluster.yml -b
Проверяем наличие StorageClass
kubectl get storageclass
NAME PROVISIONER AGE
local-storage kubernetes.io/no-provisioner 18mПроверяем PV
kubectl get pv
local-pv-26b51a64 49Gi RWO Delete Available local-storage 11m
local-pv-5bec36e4 19Gi RWO Delete Available local-storage 14m
local-pv-81c889eb 49Gi RWO Delete Available local-storage 13m
local-pv-aa880f42 19Gi RWO Delete Available local-storage 10m
local-pv-b6ffa66b 19Gi RWO Delete Available local-storage 11m
local-pv-d465b035 49Gi RWO Delete Available local-storage 10mИнициилизируем Helm
helm init --service-account tillerЗапускаем установку elasticsearch
helm install stable/elasticsearch --namespace logging --name elasticsearch --set data.persistence.storageClass=local-storage,master.persistence.storageClass=local-storageПодождите 5 минут пока установиться elasticsearch
Находим сервис, которому будет подключаться kibana и fluentd. В своем названии обычно имеет elasticsearch-client
kubectl get services --namespace logging | grep elasticsearch
elasticsearch-client ClusterIP 10.233.60.173 <none> 9200/TCP 19s
elasticsearch-discovery ClusterIP None <none> 9300/TCP 19sНазвание elasticsearch-client указываем при установке fluentd-elasticsearch
helm install stable/fluentd-elasticsearch --namespace logging --set elasticsearch.host=elasticsearch-clientНазвание elasticsearch-client указываем при установке kibana
helm install --namespace logging --set ingress.enabled=true,ingress.hosts[0]=kibana.mydomain.io --set env.ELASTICSEARCH_URL=http://elasticsearch-client:9200 stable/kibanaСмотрим что все поды имеют статус running
kubectl get pod --namespace=loggingЕсли есть ошибка — смотрим логи.
kubectl logs имя-пода --namespace loggingДобавляем в DNS или в файл /etc/hosts
IP-первой-ноды kibana.mydomain.io
IP-второй-ноды kibana.mydomain.io
IP-третьей-ноды kibana.mydomain.ioПримечание: если вы хотите отправлять логи на внешний Elasticsearch, то следует запускает установку с elasticsearch.host=dns-имя-вашего-внешнего-elasticsearch
Переходим по адресу kibana.mydomain.io
Нажимаем Index Pattern
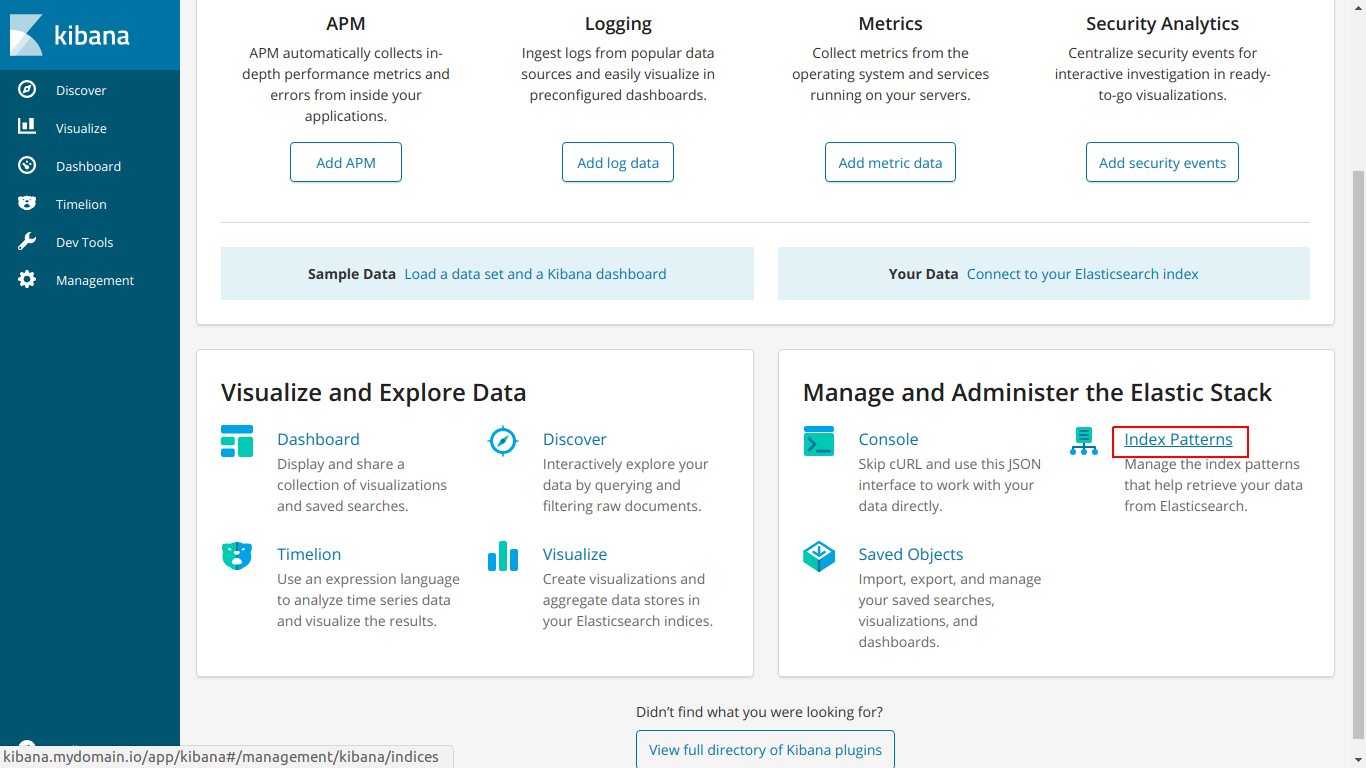
Вводим название index, чтобы он совпадал с index ниже
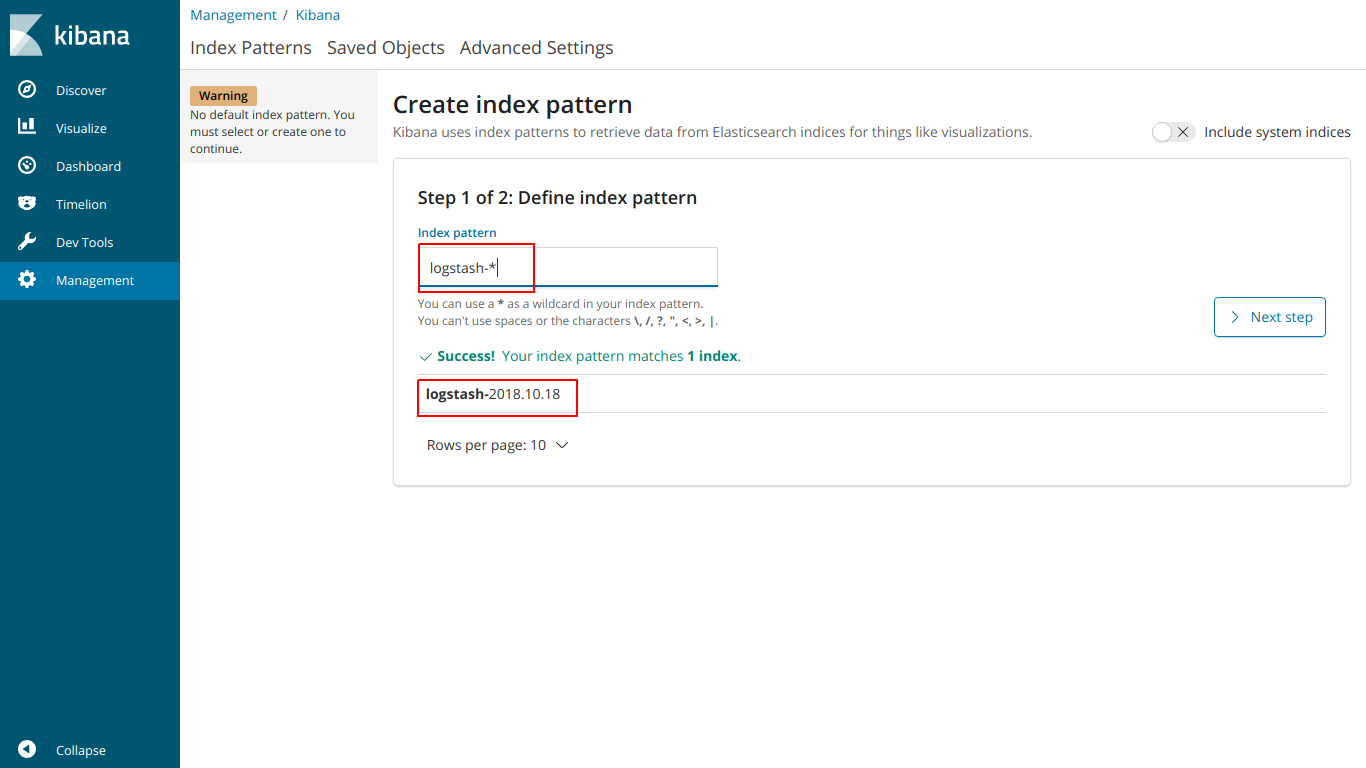
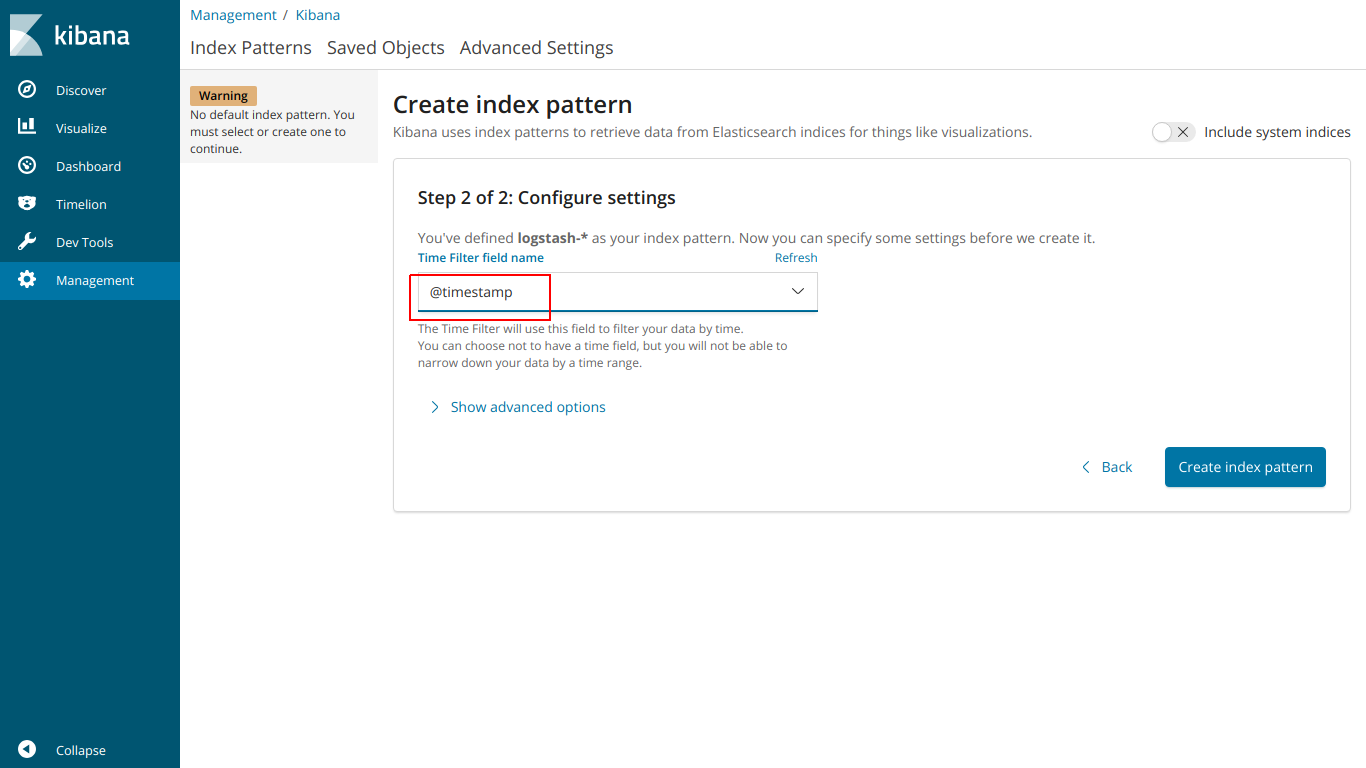
выбираем @ timestamp
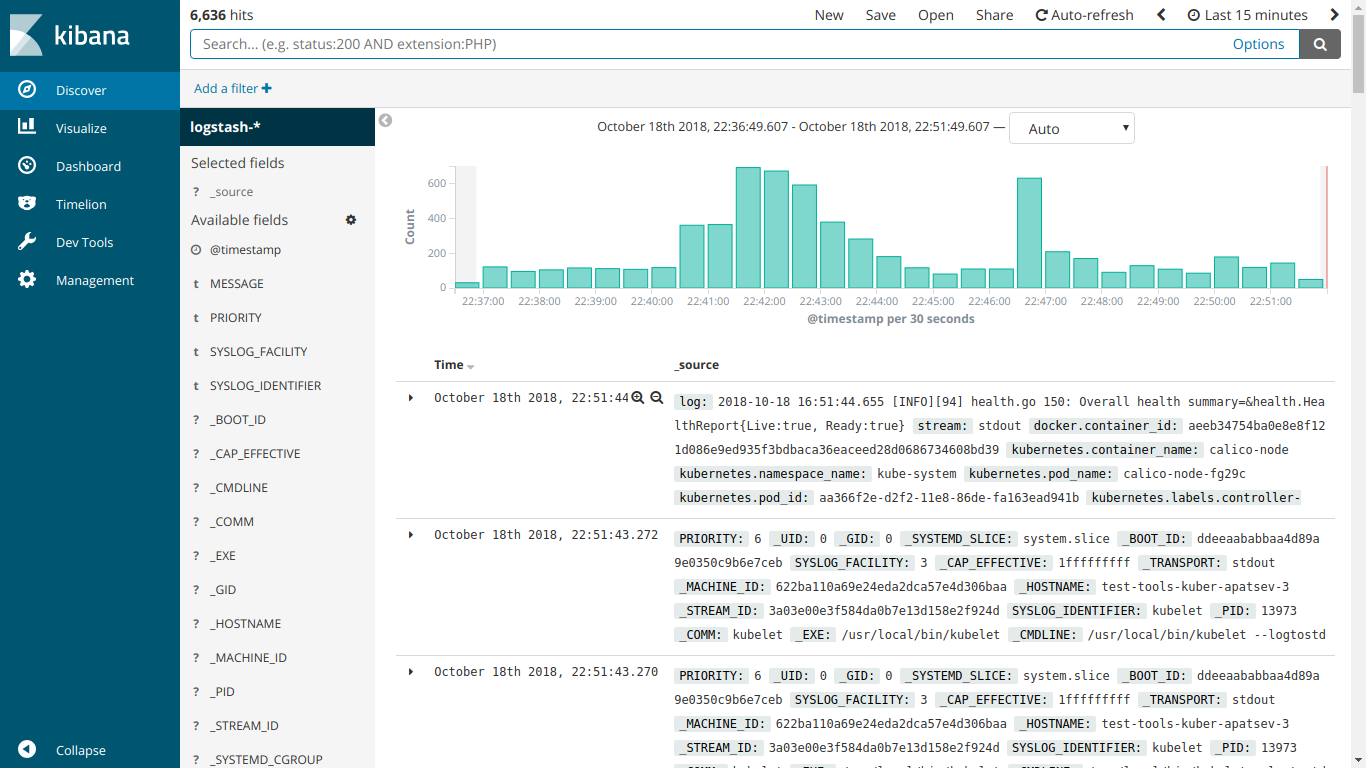
И вот EFK работает
Запускаем установку kube-prometheus
Скачиваем prometheus-operator
git clone https://github.com/coreos/prometheus-operator.gitПереходим в папку kube-prometheus
cd prometheus-operator/contrib/kube-prometheusЗапускаем установку согласно инструкции на сайте
kubectl create -f manifests/ || true
until kubectl get customresourcedefinitions servicemonitors.monitoring.coreos.com ; do date; sleep 1; echo ""; done
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl create -f manifests/ 2>/dev/null || trueСоздаем файл ingress-grafana-prometheus.yml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test
namespace: monitoring
spec:
rules:
- host: grafana.mydomain.io
http:
paths:
- backend:
serviceName: grafana
servicePort: 3000Создаем ingress ресурс
kubectl create -f ingress-grafana-prometheus.ymlдобавляем в DNS или в файл /etc/hosts
IP-первой-ноды grafana.mydomain.io
IP-второй-ноды grafana.mydomain.io
IP-третьей-ноды grafana.mydomain.ioПереходим по адресу grafana.mydomain.io. Вводим стандартные логин/пароль: admin/admin
Скриншоты prometheus:
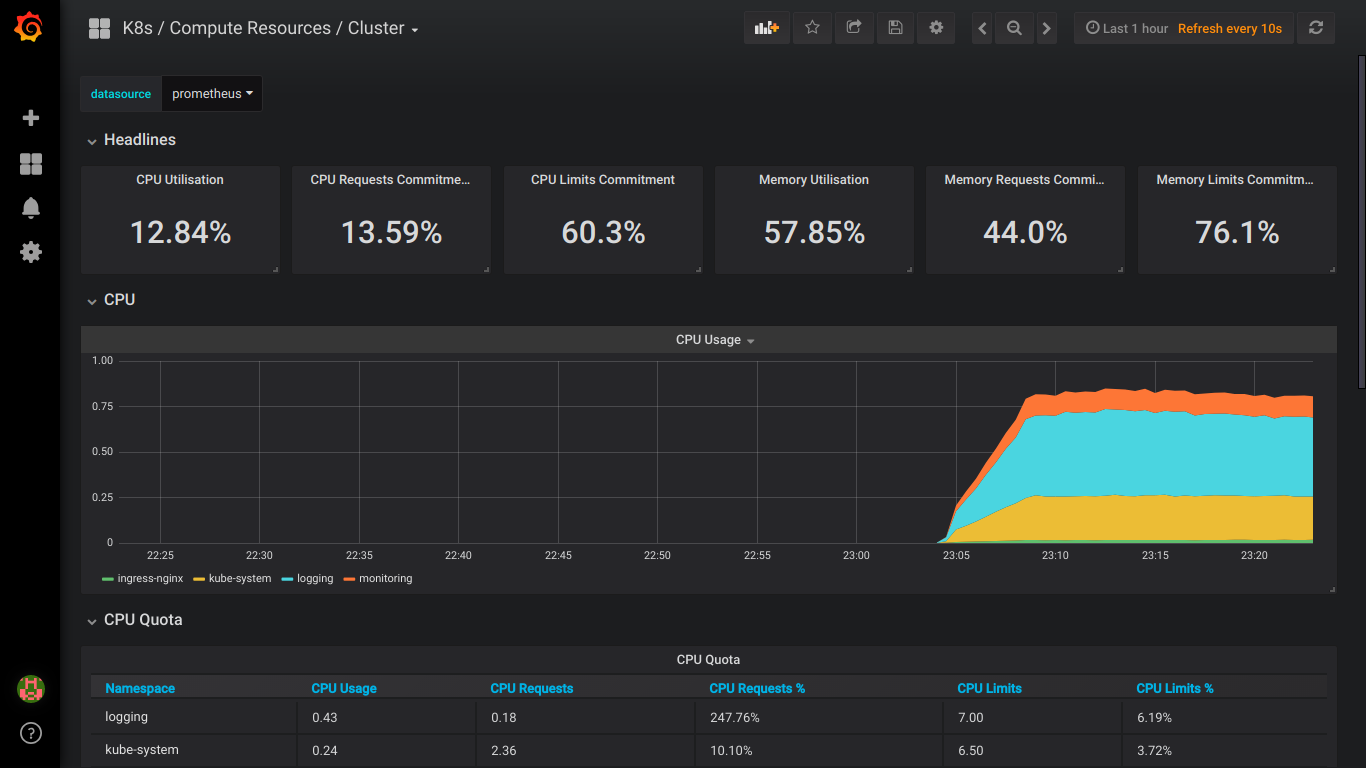
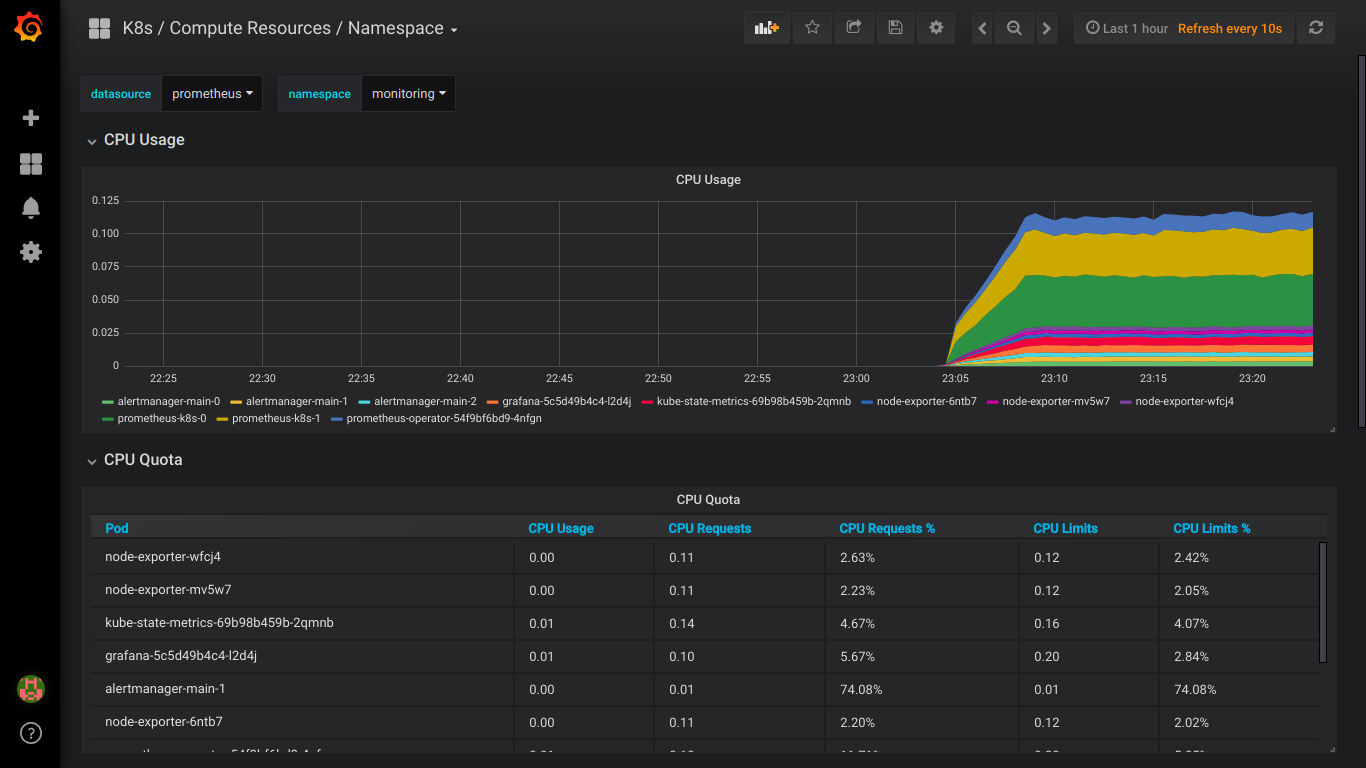
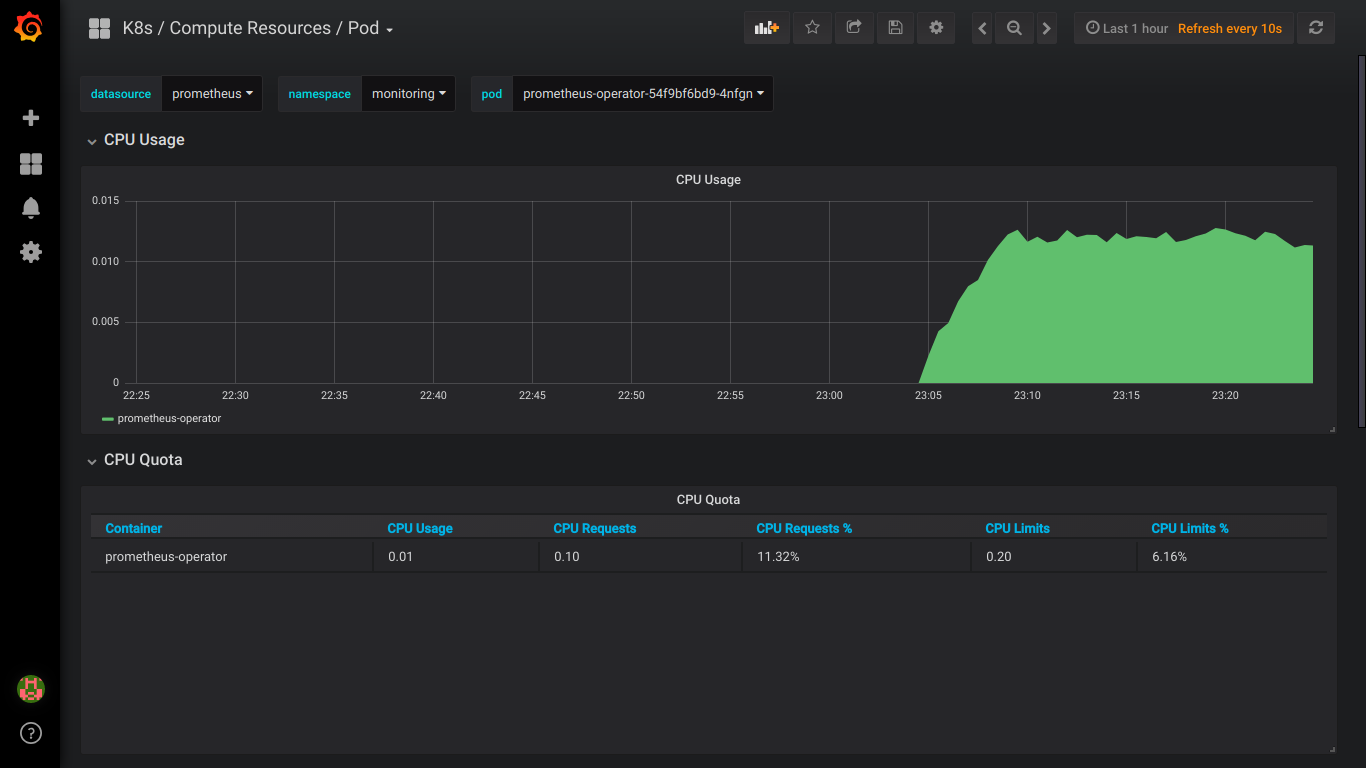
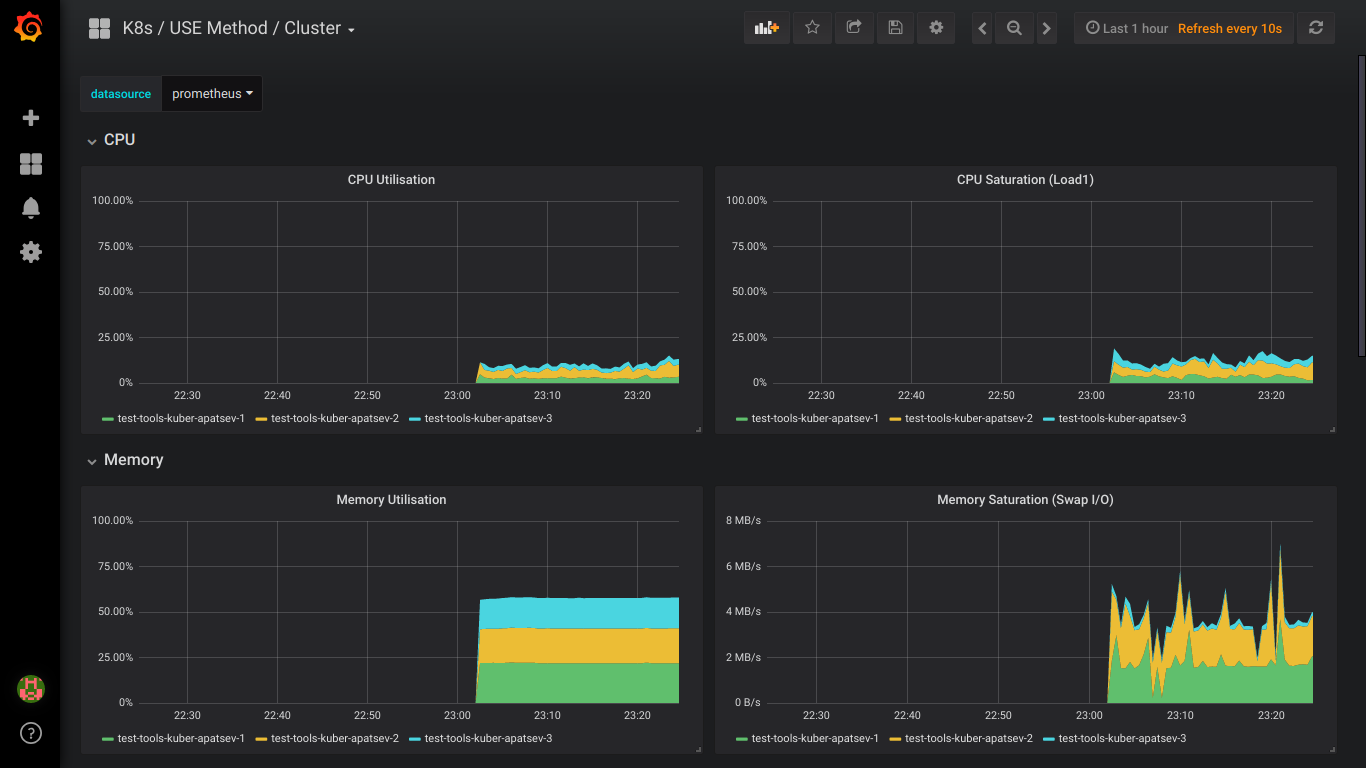
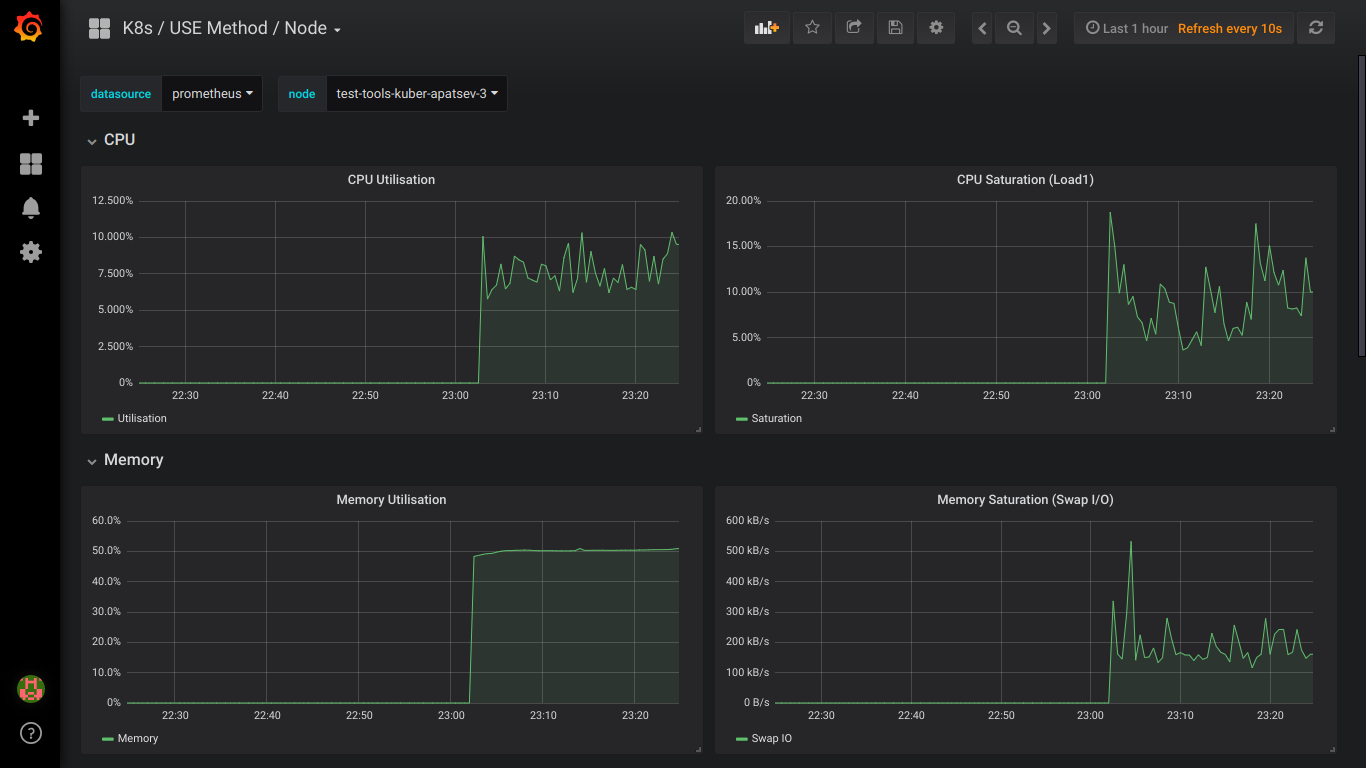
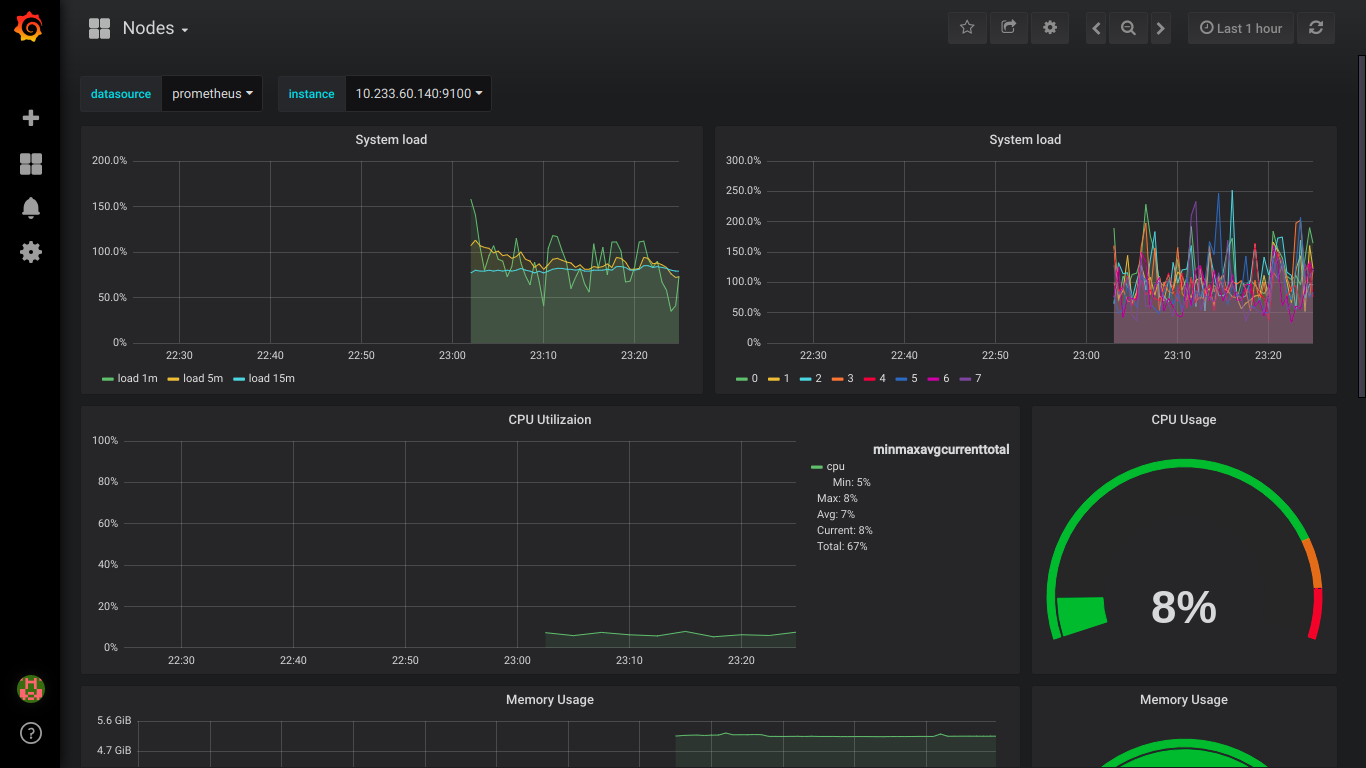
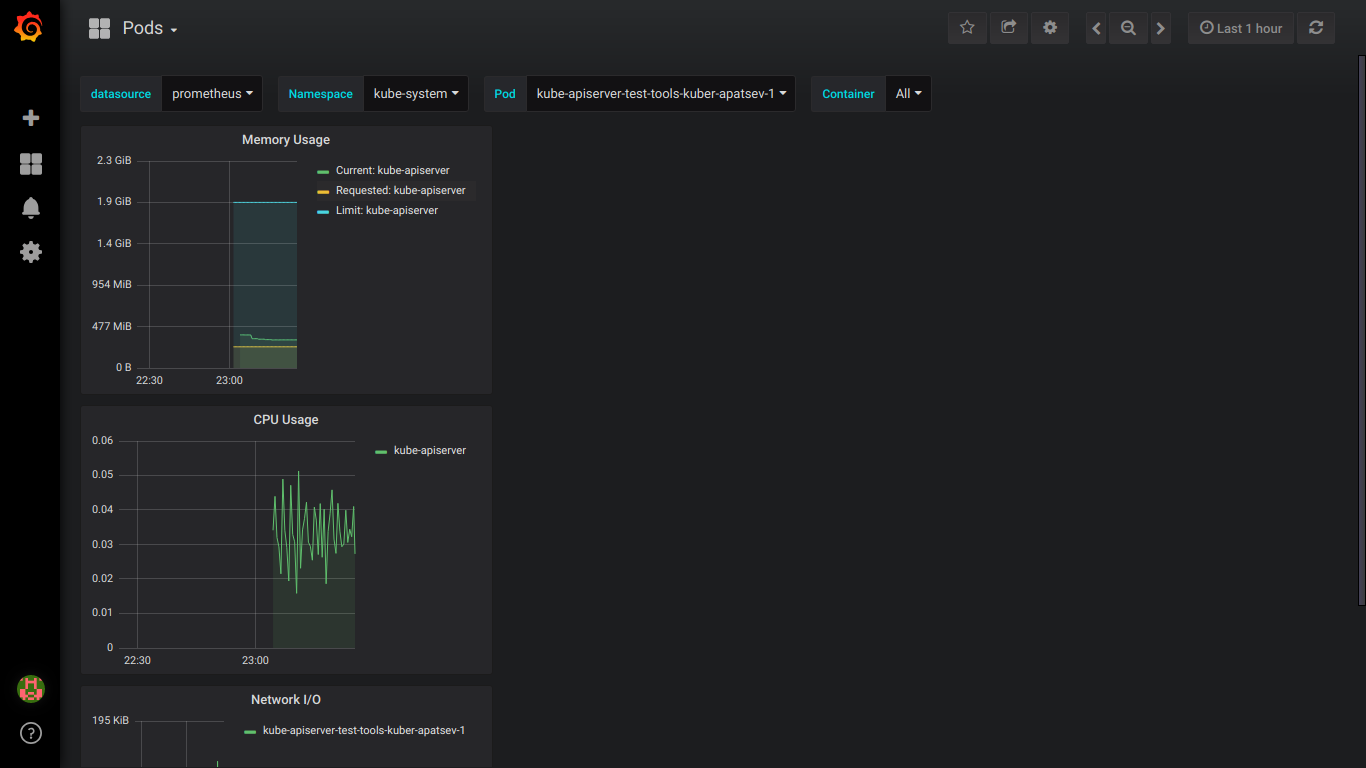
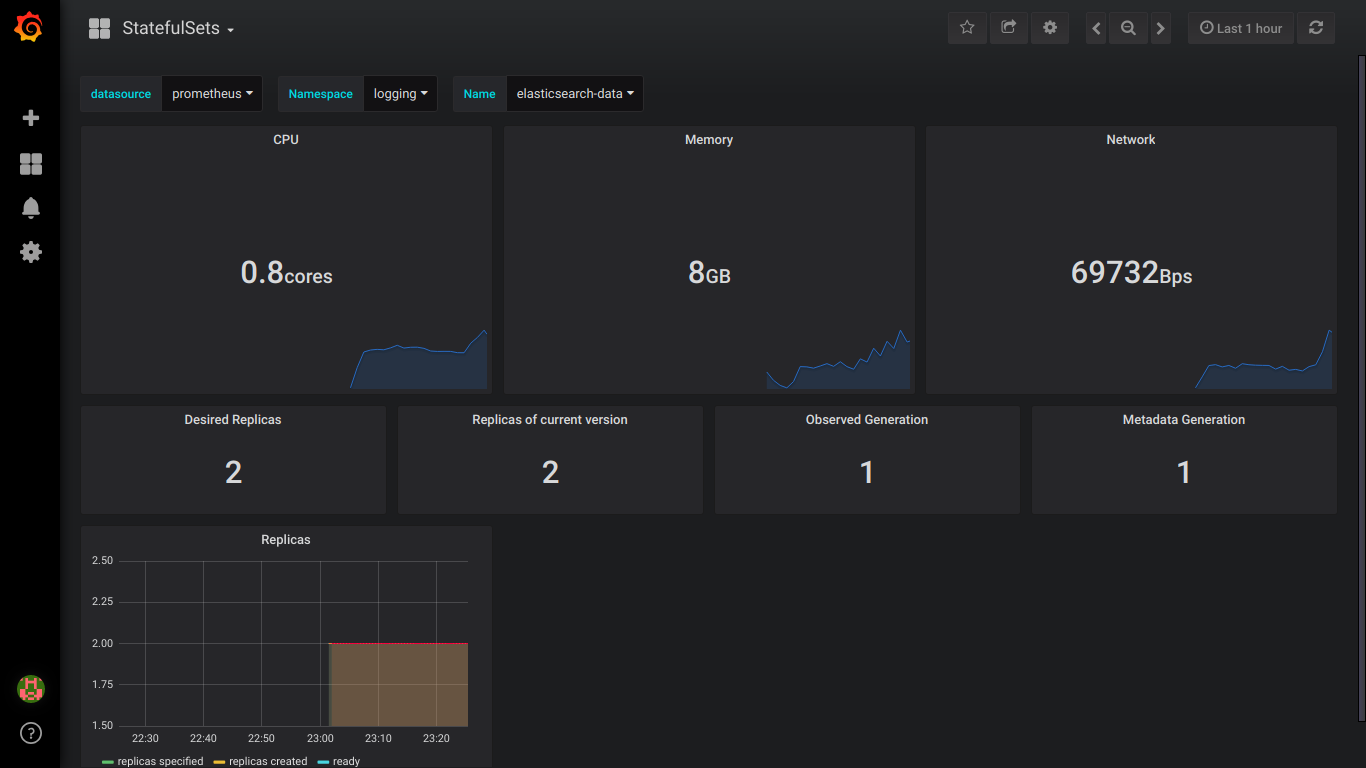
P.S.: Обо всех ошибках лучше сразу писать в приват.
gre
А локальные диски вы предлагаете руками создавать или провиженер ставить?
И какого размера они должны быть?
Ну и кибану лучше бы назвать более понятно при установке.
Прометеус-оператор почему-то не видит ServiceMonitor, похоже, нужно ставить всё же по инструкции на гите:
unable to recognize "manifests/0prometheus-operator-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "manifests/alertmanager-alertmanager.yaml": no matches for kind "Alertmanager" in version "monitoring.coreos.com/v1"
unable to recognize "manifests/alertmanager-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "manifests/kube-state-metrics-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "manifests/node-exporter-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "manifests/prometheus-prometheus.yaml": no matches for kind "Prometheus" in version "monitoring.coreos.com/v1"
unable to recognize "manifests/prometheus-rules.yaml": no matches for kind "PrometheusRule" in version "monitoring.coreos.com/v1"
unable to recognize "manifests/prometheus-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "manifests/prometheus-serviceMonitorApiserver.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "manifests/prometheus-serviceMonitorCoreDNS.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "manifests/prometheus-serviceMonitorKubeControllerManager.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "manifests/prometheus-serviceMonitorKubeScheduler.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "manifests/prometheus-serviceMonitorKubelet.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
chemtech Автор
Переписал текст.
«Для этого на каждой ноде создадим 2 диска нужных нам размеров.
Размеры диска зависит от кол-ва ваших данных — нужно проверять экспериментально.»
Название kibana устанавливать при установке. Но это же всего лишь название пода.
По поводу Prometeus — инструкция с github: запускал несколько раз эту команду
kubectl create -f manifests/ 2>/dev/null || trueи тогда начинает работать — у них там не сразу все работает.
Надеюсь они поправят.
celebrate
Скорее все же не ELK, а EFK.
chemtech Автор
Да, поправил. Спасибо