
Однако мир меняется, технологии становятся доступны и для простых смертных. Возможно, я кого-то удивлю, но сегодня любой бизнес-аналитик в состоянии освоить технологии машинного обучения и добиться результатов, конкурирующих с профессиональными математиками, и, возможно, даже лучших.
Дабы не быть голословным, я расскажу вам свою историю — как из экономиста я стал дата-аналитиком, получив необходимые знания через онлайн-курсы и участвуя в соревнованиях по машинному обучению.

Сейчас я ведущий аналитик в группе больших данных в QIWI, но еще три года назад я был довольно далек от датасайнс и об искусственном интеллекте слышал только из новостей. Но потом все изменилось, во многом благодаря Coursera и Kaggle.
Итак, обо всем по порядку.
О себе
Я экономист, довольно долго работал бизнес-консультантом. Моя специализация — разработка методологии бюджетирования и отчетности для последующей автоматизации. Если по-простому — это про то, чтобы сначала нормально выстроить процесс, чтобы потом от автоматизации был результат.
3 года назад, в 42 года, когда почувствовал, что от успехов в консалтинге я начинаю бронзоветь, и стал задумываться о необходимости перемен. О следующей карьере. У меня уже был опыт, как начать карьеру с нуля (в 30 лет я поменял спокойную жизнь экономиста на консалтинг), поэтому перемены меня не пугали.
Это не приходит в голову сразу, но когда задумываешься, становится очевидно, что несмотря на то, что я уже проработал 20 лет, впереди еще примерно 25 лет до пенсии (уже давно пришло понимание, что надо ориентироваться на пенсию в 70 лет или даже позже). В общем, впереди дорога, длиннее, чем та, что уже прошел, и хорошо бы ее пройти с актуальной специальностью. А значит, стоило поучиться. В тот период я фрилансил, и ради будущего я сократил число проектов и смог выделить достаточно времени на учёбу.
Пока я думал, куда дальше двигать, я открыл для себя Coursera. Западный подход к образованию, когда тебе в первую очередь объясняют смысл, общую идею, а уже потом детали, мне оказался близок. В отличие от брутальной советской системы образования, предполагающей, что выплывут только достойные, тут дают шанс таким, как я, у кого есть пробелы в базовом образовании.
Начинал я с курсов бизнес-аналитики. Это было крайне полезно для меня как консультанта. Эти же курсы помогли мне лучше понять роль AI-технологий для развития бизнеса и, самое главное, увидеть свою роль в этом. Это так же, как и с другими технологиями — совсем не обязательно, что те, кто разрабатывают новые технологии, будут лучшими в их применении. Чтобы технологии реально помогали бизнесу, важно этот бизнес понимать. Экспертиза в бизнес-процессах не менее важна, чем понимание самих технологий машинного обучения, обработки больших данных и тд.
И я погрузился в курсы по датасайнс, статистике, программированию.
С перерывами, я за год освоил более 30 курсов на Coursera и уже не чувствовал себя инопланетянином в мире бигдаты и машинного обучения.
Kaggle
Некоторые курсы рекомендовали Kaggle как отличную площадку для практики. Не повторяйте моей ошибки — я пришел туда, только когда уже чувствовал, что накопил достаточно знаний. А стоило сделать это на полгода раньше, когда появилось первое понимание, что и как. Был бы на полгода круче. Ведь это не просто одна из площадок для соревнований, это лучшая (в настоящее время) площадка для освоения машинного обучения на практике, которая полезна как начинающим, так и супергуру. И там ты растешь, что называется, день за два — только курсы без практики на дадут такого эффекта.
Моим первым соревнованием был конкурс от банка Santander — предсказание уровня удовлетворенности клиентов. Я был новичком и хотел проверить уровень своих знаний в деле. Я совместил свой опыт как клиента банка, навыки анализа бизнес-кейсов и технологии машинного обучения и сделал довольно неплохую модель, с которой я забрался в топ-50 на public leaderbord. Это было куда выше моих ожиданий от первого конкурса, учитывая, что в нем участвовало более 5 тысяч человек.
Но не все было так просто. На хэппиэнд я тогда не заработал. Есть такая распространенная среди новичков проблема, как «переобучение модели», с которой я познакомился на практике. Локальная валидация была организована слабо, я слишком сильно ориентировался на паблик, и как результат — на закрытой части теста я улетел на 500+ позиций вниз. Конечно, я был расстроен, но урок пошел впрок: хорошая валидация — основа машинного обучения, и ей надо заниматься серьезно. Сейчас этот компонент — одна из сильных сторон моих моделей.
Несмотря на слабый первый результат, появилась уверенность, что попасть в топ реально, надо больше практики и дополнительных знаний.
Для тех, кто не знает, чем хорош Кэггл — сообщество готово помогать новичкам с преодолением каких-то затыков, обсуждает идеи, делится примерами “как работает”. Ну и не менее важно — по окончании соревнований есть возможность изучить решения лидеров. Учась на чужом опыте, можно добиться быстрого прогресса. Не обязательно на все грабли наступать самому.
Тут же не могу не вспомнить об ОпенДатаСайнс (ods.ai) — русскоязычном сообществе датасайентистов. Тренировки по машинному обучению, которые организует ods — еще один способ глубже узнать предмет. Ну и как площадка для общения по любым вопросам также очень помогает. Если вы думаете о своем будущем в датасайнс, и вы еще не зарегались на ods — это серьезная ошибка.
Поскольку в вакансиях на позиции датасайентистов довольно часто упоминались ожидания высоких результатов на Кэггле, я увидел в этом для себя шанс — помимо того, что я набираюсь опыта, есть возможность заполнить пустое резюме более-менее релевантным опытом. Я стал относиться к Кэггл как к работе, где бонусом может стать начало карьеры.
Как только появлялось свободное время, я строил модели на Кэггле, и с каждым соревнованием результат становился лучше.
У меня было то, чего не было у большинства участников — умение анализировать бизнес-кейсы и мой опыт в консалтинге, это очень помогало при построении моделей. Через полгода я занял 7 место в очередном конкурсе от банка Santander и заработал свою первую золотую медаль.
Если настойчиво стремиться к определенной цели, ты ее достигнешь — в июне 2017 года, через год с небольшим моих битв на Кэггле, мы вместе с разработчиком из Латвии Агнисом Люкисом выиграли конкурс от Сбербанка по предсказанию цен на квартиры в Москве.

Нашими сильными сторонами было понимание кейса (это комплексная задача, к решению которой не стоило подходить в лоб, как делало большинство) и сильная локальная валидация. Мы закончили конкурс вторыми на паблике, но наша модель почти не пострадала от переобучения и не сильно просела на закрытых данных — в финале мы оказались первыми с гигантским отрывом.
Эта победа забросила меня в топ-50 глобального рейтинга Kaggle, что вылилось в предложения о работе. Изучив варианты, я выбрал банк, как место, где много задач, на которых можно прокачать скиллы, а также прочувствовать всю правду жизни при разработке моделей — все же в соревнованиях условия скорее тепличные.
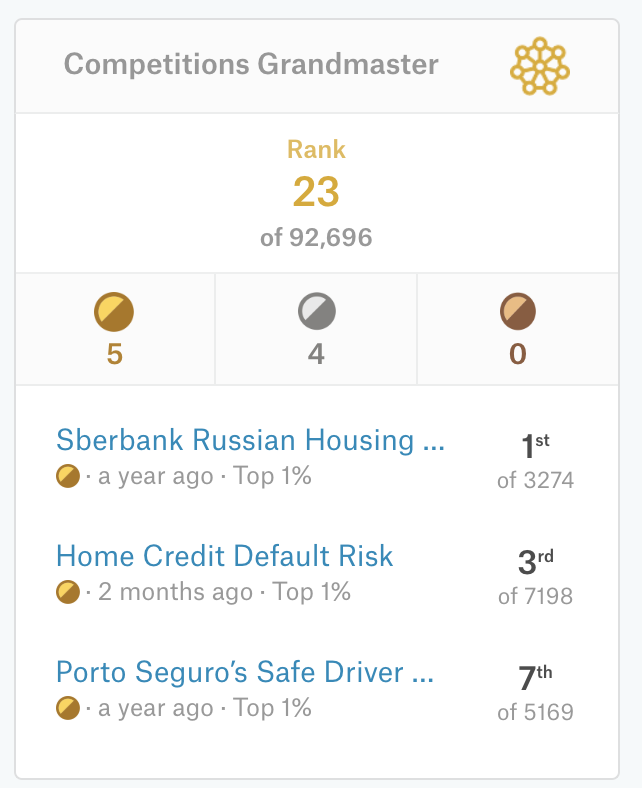
Планы на карьерный рост у меня были амбициозными и вариант «не торопясь поработать несколько лет, чтобы дорасти до следующей ступени» не рассматривался. Надо было впахивать и на работе, и во вторую смену не забывать о Кэггле. Непросто, но кому нынче легко? И это дало результаты — еще 3 золотые медали и я заработал погоны Грандмастера на Кэггле плюс закрепился в глобальном топе (сейчас 23-й).
Как вишенка на торте — 3 призовое место в соревнованиях по банковскому скорингу, то, чем я профессионально занимался последний год. И, как видно, занимался хорошо.
Увы, но правда жизни в банке — это еще и очень консервативный и небыстрый процесс принятия решений. Внедрение моих моделей двигалось медленно. Перестраивать работу всего банка планов не было, поэтому проще было, хоть и с сожалением, но сменить работу.
Это оказалось совсем не сложно — благодаря результатам на Кэггле, поиск не занял много времени, и уже несколько месяцев я копаю миллиардные таблицы в QIWI. У нас куча интересных задач, уверен, что довольно скоро мы сможем превратить наши данные в прибыль для компании — бэкграунд экономиста в этом очень помогает. Кэгглоопыт здесь также оказался в кассу по нескольким кейсам.
А теперь о том, как добиться успеха в соревнованиях
Самая важная часть — понять задачу и найти все драйверы, которые могут влиять на результат. Чем лучше вы разберетесь в кейсе, тем больше шансов выступить круто. Нагенерить сотни или даже тысячи стат фич может каждый, а вот придумать такие, которые заточены именно под эту задачу и хорошо объясняют таргет, куда сложнее. Вложитесь в это, и быстро окажетесь в топе. Стоит применять любой релевантный опыт (бизнесовый, бытовой и тд) — это сильно помогает.
Затем — локальная валидация. Ваш главный враг — переообучение, особенно если вы используете такую сильную технологию, как градиентный бустинг. Знаю, насколько психологически сложно перестать ориентироваться на public leaderboard, но если не хотите разочарований, правильный ответ — используйте кросс-валидацию, скажите «Нет» отложенной выборке. Конечно, есть исключения, но даже в задачах с временными рядами можно прикрутить кросс-валидацию, сильно повысив надежность модели. Не всегда схема локальной валидации будет простой, но стоит потратить на нее время — и в соревнованиях, и в реальной жизни. Наградой будут стабильные модели.
Само собой, надо хорошо изучить основные инструменты. Зная принципы разных технологий, вы сможете адекватно выбирать наилучший инструмент для решения конкретной задачи. Для табличных данных сейчас лидер градиентный бустинг, а конкретно — Lightgbm. Но важно уметь использовать и другие методы, от логрега до нейросетей — и в жизни, и в соревнованиях лишними не будут.
Кстати, лучший способ понять, какие технологии рулят сейчас, когда все меняется стремительно — посмотреть, какие библиотеки используют лидеры соревнований. В последние годы многие стоящие технологии прорвались в мир через Кэггл.
Гиперпараметры. Важно знать ключевые гиперпараметры используемых инструментов. Обычно не так много параметров надо менять. Мое убеждение — не стоит тратить много времени на подбор гиперпараметров. Конечно, найти хорошие гиперпараметры необходимо, но зацикливаться на этом не стоит.
Обычно, когда модель обозначилась, я подбираю более или менее стабильный сет параметров и возвращаюсь к их тюнингу только ближе к концу, когда другие идеи иссякли. Здравый смысл подсказывает, что время, потраченное на создание и тестирование новых переменных, библиотек, нестандартных идей, может дать куда больший прирост модели, чем улучшение от перехода от хорошего набора гиперпараметров к идеальному.
Если вы делаете ставку на Kaggle как на фичу, которая прокачает ваше резюме — рассматривайте это именно как работу, не пожалеете. Мне это помогло, поможет и вам.
Ну и еще раз о конкуренции. Она тут очень высока, поэтому в одиночку побеждать весьма и весьма сложно. Командная работа очень полезна, синергия идей позволяет прыгнуть выше головы. Не стесняйтесь этим пользоваться.
Итого
Ну и немного мотивации под конец. В первую очередь я доказал сам себе, что могу стать датасайнтистом в свои 44 года. Рецепт оказался на удивление прост — онлайн-образование, бизнес-ориентированное мышление, работоспособность и целеустремленность.
Теперь я всячески подбиваю своих друзей проделать тот же путь. Новая цифровая экономика нуждается (и будет нуждаться) в высококлассных специалистах. Coursera + Kaggle — это просто отличные возможности для старта.
Когда-то ведь и Excel был новым и непонятным инструментом (я даже помню, как непросто проходили первые бои с традиционным калькулятором). А сейчас ведь ни у кого нет сомнений, что специалист, разбирающийся в своем бизнесе, может выжать из Excel куда больше реальной пользы, чем сами разработчики Excel.
Пройдет немного времени, и владение инструментами машинного обучения станет таким же обязательным, как владение Excel, так почему бы не подготовиться к этому заранее и выиграть конкуренцию на рынке труда уже сейчас?
Тем более, конкуренции бояться не стоит. Чем больше людей со стороны бизнеса придет в датасайнс — тем больше денег. Внедрение новых технологий в традиционных отраслях экономики может ускорить именно бизнес, а для этого бизнес должен начать понимать возможности, которые открывают новые технологии уже сегодня. По сути любой бизнес-аналитик, освоив несколько курсов, может оказаться на передовой прогресса и помочь своей компании обогнать консервативных конкурентов.
Надеюсь, мой опыт поможет кому-то принять важное решение.
Если у вас есть какие-то вопросы о Kaggle, пишите, я с радостью отвечу в комментариях.
Комментарии (93)

Tantrido
24.10.2018 15:14С перерывами, я за год освоил более 30 курсов на Coursera
Круто! Я за год 1-2 курса на степике прохожу, а если интенсивно с дедлайнами — 2-3 месяца на курс, правда времени свободного не так много. Или на курсере курсы маленькие? ;) Получается на курс у Вас уходило неделя-полторы. Что это были за курсы?johnpateha Автор
24.10.2018 16:07Курсы там разные. Как правило от 4 недель при занятиях 2-6 часов в неделю. Были и те что можно было за день освоить и те, что пару месяцев надо было покопать с дымом из ушей.
Стоит самому посмотреть — подача западных курсов на голову лучше (имхо). Я раньше был совсем далек от образования, но от первого же курса вштырило.
Заодно и английский выучил :)
Rusllan
24.10.2018 16:07Присоединяюсь к вопросу о курсах. Интересно было бы посмотреть, если не на полный список, то хотя бы на те курсы, которые показались автору наиболее полезными.
johnpateha Автор
24.10.2018 16:13В теме машинного обучения номер один — классический Machine learning by Andrew Ng
Ему много лет, но это системное погружение в тему на достаточную глубину.
Также хорошо зашел Mining massive datasets, game theory
Еще я слушал цикл Data science — тоже полезный, но он на R ориентирован, а сейчас более популярен питон. По статистике слушал много курсов но идеального не нашел (пришлось брать числом)
Могу смело рекомендовать цикл курсов по аналитике от Wharton — но это уже не датасайнс, а бизнес-аналитика.
bulavin
25.10.2018 05:33Книги читали по бизнес-аналитике? Что порекомендуете почитать по пути на работу и обратно? Гугл выдает массу книг среди которых трудно выбрать лучшие, так как тема хайповая и среди годных книг много мусора.
NihilSherrKhaine
25.10.2018 07:38+2Сделаю выжимку из парочки курсов, что проходил:
1) Deep Learning от Ынга
Я бы сказал, имеет краткую выжимку(с большего) ML от него же в первых 2 из 5 частей, к тому же рассчитана больше на технически подкованных ребят. (Там нет «можете не знать, что такое производная, и так поймёте»), 3 часть — всякие фичи-советы от Ынга насчёт обучения, 4 и 5 — некоторые попсовые технологии вплоть до 2016 года.
2) Machine Learning от Ынга (Hardcore edition)
На сайте engineering everywhere stanford есть курс по МЛу от Ынга в Стэнфорде. Со всеми их заданиями, тензорными вычислениями и всем-всем-всем. По сложности и полноте не сопоставимо.
3) Convex optimization от Stephan Boyd
На том же engineering everywhere, есть книга. Один из лучших курсов по оптимизации, который рекомендуют просто все, кому не лень, даже жуткие любители исконно русской литературы в математике.
Game theory, mining massive datasets — определённо стоит того, первое ближе к reinforcement learning, второе — к анализу данных непосредственно.
Наверное, закончу небольшой подборкой наиболее годных книг, а то выйдет целый пост, а не комментарий:
Computer Vision — Adrian Rosebrock (Хочет кто запиратить все 3 бандла — обращайтесь)
General — Yan Goodfellow (Классика, но она больше для тех, кто уже в теме и в математике хорош, не для новичков), как и Kevin Murphy (более подробно, всё ещё довольно хардкорно)
Существует книга на русском, я удивлён: «Погружение в мир нейронных сетей», 2018 год.
Reinforcement Learning — Richard Sutton, абсолютно всеми рекомендуется.
Vilaine
26.10.2018 07:4030 курсов за год — это с заданиями/сертификатами, платные? Или часть только прослушали?
johnpateha Автор
26.10.2018 07:43Мне сертификаты не были нужны, но раньше и в бесплатном варианте были доступны все задания.
aPiks
25.10.2018 12:00+1Stepik такое дно… Я как-то решил подтянуть знания по алгоритмам и посмотреть курсы. Уснул на третьей минуте вступления, потом проснулся посмотрел первый урок и больше никогда не открывал. Просто работник Мейла без перерыва рассказывает что, куда и как, иногда прерываясь на «Выполните вот эту практику». Ни реального применения, ни как лучше подойти к обучению, ничего. И практику на самостоятельное выполнение дают без объяснения что и как использовать.
После курсов от Stepik, курсы Udemy кажутся идеальной площадкой для обучения. Тебе сначала рассказывают для чего это применить, потом рассказывают как применить, а потом показывают реализацию. И на самостоятельное выносят задания для закрепления. Видео по 10 минут. Не устаешь и учить интересно.johnpateha Автор
25.10.2018 12:38+1Про Stepik не скажу — не смотрел, но в целом всеми руками за — западные курсы на голову круче по подаче — и интереснее и лучше структурированы. Круто сначала понять зачем сабж, а уже потом погружаться в детали. А в советской школе преподавания часто наоборот.
Ну и важно закреплять курсы практикой на кэггле — это добавит куда больше. Решая конкретные кейсы приходится читать кучу статей и это уже не абстрактное чтение, а то, что потом применяешь и оно хорошо откладывается в голове. Ну и идеи других участников — не обязательно все велосипеды изобретать самому
Apatic
25.10.2018 12:53+1Причем тут степик в целом, если вы описываете отдельный курс?
Там есть шикарные курсы по статистике от Института Биоинформатики, например (лучше, чем многие курсы на курсере из тех, что я видел).aPiks
25.10.2018 19:24Согласен, не стоило выражаться за весь ресурс в целом.
Но я думаю. что они должны как-то контролировать что у них там. По подаче, ни Java EE, ни алгоритмы ни многие другие курсы, которые я пытался смотреть, до Udemy не дотягивают. Там ребята какие-то более живые, начинают с основ и дают много практики, при этом объясняют как её правильно делать.
GreenElephant
25.10.2018 18:40На Stepik есть замечательные курсы по алгоритмам от Computer Science Center
ded_Sergei
24.10.2018 15:27+1По ощущениям, выиграли при переходе в новую область знаний и работы? В мотивации, в деньгах, в интересных проектах?
tonyvolcano
24.10.2018 16:13Кстати да, интересно какая цель преследовалась. Занятие для души, или попытка нажить, то чего не было нажито за прошлые годы.
johnpateha Автор
24.10.2018 16:18Определенно выиграл. С деньгами и до этого проблемы не было. А вот по мотивации и пониманию фронта работ лет на 10 вперед это явный прорыв. Круто когда работа совпадает с хобби и ты видишь ее практическую пользу и перспективы
marsdenden
25.10.2018 05:30Это да. Я только в 46 наконец-то совместил работу с хобби и уже два года наслаждаюсь работой и осваиваю новые хобби :)
Papasol
26.10.2018 12:16А если бы вы работали только удалённо, именно по теме машинного обучения, получилось бы у вас иметь тот же доход, что и сейчас?
johnpateha Автор
26.10.2018 12:18Думаю, что пока нет — сначала надо наработать практики и авторитета, чтобы кто-то отдавал стоить модели на удаленный аутсорс. Хотя возможно, такое тоже есть
NihilSherrKhaine
26.10.2018 12:50Так-то на том же upwork среднестатистический МЛ парень получает около 50-60 долларов в час, т.е. 8000 в месяц. (Но это ребята, у которых в профиле 3+ лет опыта, возможно выдуманного.)
Kutak
25.10.2018 04:42Сколько платят дата-саентисту? Любопытно.
river-fall
25.10.2018 11:25300к/cек,
Карлсон не даст соврать :)
Kutak
25.10.2018 17:18Забавно, конечно. Ну а всё-таки? Просто для меня что «дата-саентист», что «шаман» — одно и то же. Что это вообще такое? Кросс-валидация какая-то, переобучение модели, градиентный бустинг. Такими словами только Ктулху вызывать, так вот и пытаюсь понять, сколько платят освоившим эти заклинания.
xgbaggins
25.10.2018 23:31Конкретные цифры очевидно же зависят от локации. В Долине $100k не деньги, а где нибудь за мкадом предел всех мечтаний
Но в целом по моим ощущениям, меньше чем программистам. В крупных корпорациях data scientist чаще просто эвфемизм для тех кого раньше называли аналитиками.Kutak
26.10.2018 03:27Что-то больно мало для такого серьёзного термина, как «дата-саентист». По его внушительному звучанию оно тянет на побольше…
В Долине я не жил, но из общей эрудиции знаю, что 100к там — это очень мало. С учётом налогов и съёма жилья — просто нищенство.
За мкадом, будь ты хоть трижды ведущий дата-саентист, сомнительно, чтобы платили 100к. Да и в Москве тоже сомнительно.xgbaggins
26.10.2018 06:13А я разве сказал что им $100k платят? Наоборот.
Тем не менее, по тому что я в своей конторе вижу, платят чуть похуже чем программистам, потому что это по сути просто аналитики. А программистов которые пилят data science нынче вроде модно называть скорее ML Engineer или как-то так. Зарплата соответственно повыше, но и требования тоже — не только sql гонять и модели графики презентации рисовать, но и уметь допиливать все благополучно до продакшна, например
uSasha
26.10.2018 10:11В мск 80К джуну, до 250-300К сильному синиору, дальше уже надо менеджить.
Но сильных спецов гораздо меньше чем сильных программистов, тк отрасль молодая.xgbaggins
26.10.2018 13:55>дальше уже надо менеджить
Или просто свалить в страну где нормально ценят человеческий труд и получать 250-300K уже твёрдой валюты (в год), сеньёрам индивидуалам в фангах и безо всякого MLа еще больше платят
Sergey55
25.10.2018 06:43Вот если б вы еще расписали какие курсы вы просмотрели, в каком порядке и ваши комментарии (стоит или не стоит смотреть). Был бы очень благодарен.
johnpateha Автор
25.10.2018 07:44про курсы ответил чуть выше. Но одних курсов мало — дальше Кэггл — эти и практика и школа молодого бойца и обмен опытом
yanchick
25.10.2018 07:14Поддерживаю вопрос по курсам и книгам. Список того что проходили/читали и свои комментарии.

expertykt
25.10.2018 07:39По плану неизбежно придется встать на этот путь через год, в 50. Правда, бэк некоторый в статистике и программировании есть. Регаюсь на ОДС :)
Очень интересно и познавательно посмотреть ваш подход в задаче оценки московских квартир, моя специальность.johnpateha Автор
25.10.2018 07:42на форуме соревнование есть описание нашего решения
вот выступление на тренировке youtu.be/Eo4WMlcT7uo
Jahak
25.10.2018 07:45Было бы прекрасно, если бы вы поделились материалами. Что читали и читаете, какие курсы проходили. Спасибо!
johnpateha Автор
25.10.2018 07:45про курсы ответил чуть выше. Но одних курсов мало — дальше Кэггл — эти и практика и школа молодого бойца и обмен опытом
GolosCD
25.10.2018 10:15Хотел бы я почитать статью с таким же заголовком, но с припиской, и ты не программист и не математик
johnpateha Автор
25.10.2018 10:19Это был первый вариант названия :) Решил, что слишком тяжеловесно.
Моя математика закончилась на 2 курсе экономфака в 1992г. В жизни она практически не требуется, поэтому к текущему моменту мало что осталось — даже перемножение матриц пришлось осваивать заново. А производные и интегралы уже совсем не умею. Но жить без этого можно.
В датасайнс куда важнее статистика, а ее можно вспомнить/изучить в базовом объеме за 2-3 онлайн курса.
Feland
25.10.2018 10:20-1Признайтесь честно, что вы о многом недоговариваете, такой слаженный сладкий текст с грандиозными результатами, для человека за 40 не знакомого с программированием, это нечто впечатляющее.
«С перерывами, я за год освоил более 30 курсов на Coursera и уже не чувствовал себя инопланетянином в мире бигдаты и машинного обучения.», т.е. почти экстерном 2-3 курса в месяц, тут просто нет слов, вашей гиниальности позавидовали бы самые умные люди планеты.
А х да вопрос, где вы взяли более 24 часов в сутках, чтобы работать, заниматься семьей, отдыхать и проходить эти курсы.
Весь этот пост похож на пиар QIWi, какие гениальные сотрудники там работают.johnpateha Автор
25.10.2018 10:33+2Про пиар QIWI — эта статья переложение на русский моего выступления в Варшаве на кэгглконфе за 3 месяца до начала моей работы в QIWI. пруф — youtu.be/X3ljF4kAQ8Y
Это выступление послушало 100 человек в зале и неск сот в ютубе. А тут прочитало куда больше, поэтому спасибо компании, что помогла разместить пост. И да — QIWI действительно хорошая компания — мне есть с чем сравнивать.
Вы правы — время это серьезная проблема. Я был оч. дорогим консультантом и мог себе позволить выбирать проекты и работать не фуллтайм. А когда появились первые результаты и стало понятно, что шансы на работу есть, то проектов стало совсем мало, и работой стал кэггл. Для примера — на конкурсе по Сбербанку, где мы победили, мой режим работы — проснулся в 8 — включил комп, погнал копать данные, после полуночи выключил. И так месяц по 6-7 дней в неделю. Семья хоть и роптала, но в целом поддерживала, за что ей большое спасибо. Это не просто, но была цель. Я не гениальный, просто выбрал адекватную цель и ее добился.
Ну и еще пруф — мой профиль в линкдин — ru.linkedin.com/in/epatekha
Kamenevdn
25.10.2018 10:57Это многое объясняет. Я со своим графиком с трудом осилил первые 4 курса машинного обучения от Яндекса на курсере, а потом ушел на Udemy и далее довольно лениво и безрезультатно ковырял Kaggle. Поэтому 30 курсов на курсере за год и несколько соревнований — для меня прозвучали как художественная фантастика. Но да, во время обучения для себя отметил, что если бы можно было выделить хотя бы 3 полных дня в неделю на обучение, то результат был бы непропорционально больше. Ваш опыт это подтвердил. Спасибо за мотивационный пост.
johnpateha Автор
25.10.2018 11:27Курс Яндекс+МФТИ построен как и все наше образование по принципу — выживут сильнейшие. Подача тяжелая, если бы я начинал с него, ничего бы не вышло. Западные курсы сильно отличаются подачей. И даже то, что английский в исполнении китайцев и индусов не оч. просто разобрвть, все равно их курсы заходили сильно лучше.
На курсере почти всегда есть субтитры — вначале оч. помогают. А потом втягиваешься и через неск месяцев обнаруживаешь, что можешь понимать многое без субтитров.Kamenevdn
25.10.2018 11:48+2Да, про сильное отличие западных курсов я тоже, к сожалению, узнал на собственном опыте. Хотя сначала думал, что это я такой тугодум, что еле тянул курс яндекса… Потом уже понял, что ряд лекций там сделаны ну просто «наотвали» типа тех же нейронных сетей или обработки текста.
Но к сожалению, в моем случае, нескольких курсов и книг все равно не хватило для качественного перехода на Kaggle от Титаника и прочих новичковских датасетов до полноценного участия в актуальных соревнованиях. Но это, почти уверен, вопрос собственной лени и нехватки времени.johnpateha Автор
25.10.2018 12:34+2Совет — не стоит тратить время на учебные соревнования на Кэггле — надо сразу боевые. И не важно, что вначале будет слабый резалт — за это никто не осудит.
Зато там есть живое обсуждение, много советов от др. участников.
И куча бэйзлайнов — примеров кода, которые позволяют стартовать. Когда не знаешь за что хвататься, это отличная возможность начать, а дальше начинаешь улучшать ту часть, где есть идеи-знания.
И через какое-то время уже будет собственный пайплайн, который от соревнования к соревнованию будет становиться все лучше.
Это прокачивает круче любых курсов — базовые знания важны, но развивать их лучше на конкретных кейсах
Tsimur_S
25.10.2018 10:57Какие у вас были знания о machine learning до того как вы начали изучать? Какого уровня были познания в математике? Что пришлось вспоминать/изучать?
С какого курса на coursera вы начинали? Я так понимаю andrew ng, а потом цикл Data science? Какие были полезны какие нет. В общем столько вопросов и так мало ответов, а в статье, в основном, описывается kaggle.johnpateha Автор
25.10.2018 11:31+3Знаний не было никаких. Слышал про принцип — кормим черный ящик данными и ответами и он строит зависимости. И это наверное все. С математикой плохо — даже перемножение матриц пришлось вспоминать. Мне кажется, глубокое знание математики сейчас требуется, только если развивать технологии. Если же их просто использовать, то в них можно хорошо разобраться и без математики.
Я не смогу написать даже простой градиентный бустинг, но разорался как правильно с ним работать — этого достаточно для хороших результатов
SaM1808
25.10.2018 12:47+1мой режим работы — проснулся в 8 — включил комп, погнал копать данные, после полуночи выключил. И так месяц по 6-7 дней в неделю. Семья хоть и роптала, но в целом поддерживала, за что ей большое спасибо.
Извините за офф, но я не перестаю удивляться, как авторам подобных постов (не только вам) удается все-таки воплощать в жизнь подобный график.
Ведь начало дня и у меня похоже… Проснулся в 6, на работе в 8-мь, а в 17:00, когда появляешься дома, обе мелкие дочери виснут мне на ноги и очень четко объясняют, что дальше папа будет жить по _их_ графику. :)neyronius
25.10.2018 13:40В 40 лет, после 10 лет дорогого консалтинга дочери могут уже заканчивать элитную школу, а ты уже сможешь понять, что твоё время — это твоё время и ты никому ничего не должен.
SaM1808
25.10.2018 14:45Мне 38… :) Дети в школу пока только играют… так сложилось...:)
neyronius
25.10.2018 14:59Я всегда думал, что два ребёнка должны как-то больше хотеть играть друг с другом, а не с родителями. Наверно, это вопрос воспитания. Если играют в школу, то уже могут понять, что у папы тоже есть личное время. И время, потраченное на обучение вас — это инвестиция в будущее ваших детей. А так — час-два после работы через день задержаться, плюс видео-лекции в транспорте. Вариантов много.
mixaly4
25.10.2018 16:22> Я всегда думал, что два ребёнка должны как-то больше хотеть играть друг с другом, а не с родителями.
Тоже так думал в своё время. Сейчас у меня трое и оказалось, что всё совсем не так :-) Но возможно это мой частный случай.
DmitrySpb79
25.10.2018 11:37+1>> Признайтесь честно, что вы о многом недоговариваете
Это было и так ясно «между строк», понятно что уделить столько времени обучению можно было лишь имея достаточно и времени и денег. Ну так и автор не новичок уже. А опыт в смежной области значительно помогает при изучении других дисциплин. Но это все не просто, да, хотя дорогу осилит идущий.
Ведь проблема любого обучения не в том, что это непостижимый rocket science, а в том что учиться сложно чисто технически (деньги, семья, время), когда тебе 42 а не 22.
Но автору респект что поделился, для меня например это хорошая мотивация, пора наконец зарегистрироваться на coursera :)))
NihilSherrKhaine
26.10.2018 13:27Лично у меня выходило за день проходить курсы Imperial College London по математике для машинного обучения. То есть всю специализацию за 3 дня. Тратило часов 8 в день, при том, что к математике у меня только чрезвычайный талант, но знаний толком не было по приближенным темам.
Аналогичное +- распространяется на все прочие курсы кроме Яндекса\Мэйлру\МФТИ, я бы сказал, что их курсы на курсере самые времязатратные и зачастую лучше аналогов. (По плюсам от Яндекса — очень хорош, ВШЭ + Сан Диего алгоритмы — более полная версия того, что даёт Стэнфорд)
Так что за неделю вечерком по часику в день вполне возможно пройти целый курсик.

lyssenkoalex
25.10.2018 10:44не подскажите в какой последовательности лучше проходит курсы на Coursera новичку?
johnpateha Автор
25.10.2018 10:47Начать стоит с Machine learning by Andrew Ng — отличный обзор мира машинного обучения. А дальше — искать, что лучше подойдет. Обычно курсы от топовых вузов типа стэнфорда оч. хороши
Все курсы можно смотреть бесплатно, если не нужен сертификат. Что-то не понравится, можно взять другой.aavoron
26.10.2018 01:41а если с математикой слабо, так же, как у Вас тогда примерно?
johnpateha Автор
26.10.2018 07:50Machine learning by Andrew Ng доступен и в этом случае. Там есть неск видео с мат обоснованиями, вполне подъемные, но автор сам предупреждает, что их можно пропустить.
Что-то из математики придется вспомнить/изучить, но если не задаваться целью создать новый алгоритм машинного обучения, то многое не требуется.
Больше надо упираться в статистику и изучать уже готовые библиотеки по ML
DES3
25.10.2018 10:49+1Привет с предыдущей работы! Все удивляются твоему возрасту: не выглядишь ты на 40+.
Коллеги тут говорят, что John — это больше Иван, чем Женя. А какое у тебя мнение?johnpateha Автор
25.10.2018 10:51Молодость — она в голове. Я себя на 40+ и не ощущаю, но паспорт не обмануть :)
640509-040147
25.10.2018 11:13На самом деле лично у меня создалось несколько демотивирующее настроение после прочтения поста. Хорошие соревновательные успехи, топовый ранг, позволяющие получать предложения де-факто без поиска оных, и при всем этом как разультат — трудоустройство в QIWI и уверенность, «что довольно скоро мы сможем превратить наши данные в прибыль для компании».
Ничего плохого о компании QIWI сказать не хочу. Однако это всего-лишь QIWI. И судя по процитированной фразе дата саенс им нужен «потому что у всех есть», а как есть использовать понимания еще нет.DmitrySpb79
25.10.2018 11:32Чего же тут демотивирующего. Я думаю, для автора работа в Qiwi не последний этап, и будучи в топе разных конкурсов можно иметь хорошие предложения о работе :)
Я сам планирую переход в data science, просто потому что всю жизнь клепать формы и get-запросы банально скучно. Нужно двигаться дальше, и деньги тут не самоцель.
Все упирается в свободное время, разумеется.
johnpateha Автор
25.10.2018 11:59+2В России не так много компаний, которые лучше QIWI как работодателя — эт я не как сотрудник говорю, а как консультант, который поработал на многие из топа российских компаний. Есть что сравнить. Помимо многого другого даже пиво с пиццей выставляют по пятницам :)
В QIWI просто море данных. Раньше их юзали меньше, теперь тема стала более важной.
Я не могу раскрывать наши проекты, но это реальная гора денег в совсем недалеком будущем.
Профессионально для меня просто рай — возможность сделать с нуля из сырых данных готовые продукты, которые будут конкурировать на рынке. Возможность и учиться на практике и делать что-то реально полезное, что можно пощупать.wildraid
26.10.2018 00:01А сколько сейчас примерно данных в QIWI в терабайтах? Есть ли какие-то наработки, чтобы считать модели параллельно на большом количестве ядер или серверов? Есть ли в этом необходимость?
Спасибо.johnpateha Автор
26.10.2018 07:58Данных оч. много, никто тотал не считал.
сырые данные агрегируются, фильтруются под задачу и в модель заходит куда меньший объем, который можно провернуть и на одном сервере. Хотя у того же бустинга есть вариант распараллеливания на неск серверов.
А для обработки исходных данных используем спарк-хадуп — тут как раз куча серверов параллельно лопатит сырую инфу.
QQsha
25.10.2018 12:54+1А каким железом вы пользовались во время первых своих соревнований?
johnpateha Автор
25.10.2018 12:59+1Поначалу — ноутбук средней производительности (i5, 12 гб памяти)
Потом освоил гугл клауд — там на старте дают 300 баксов, которых при правильном подходе легко хватит на год соревнований (если без гпу)
В вытесняемом режиме машина с 4 ядрами и 26G оперативы стоит 5 центов в час — хватает на глаза почти для любой задачи. И всегда можно добавить
anonymous
25.10.2018 13:20Меня всегда интересовал практический аспект применения знаний.
Как ваши знания помогли решить конкретные проблемы, конкретной компании?
Последние год — два все пишут, о том насколько это круто, как это здорого.
Но нет никого кто может конкретно сказать в бабле(на реализацию затратили столько, в результате внедрения компания получила бабла столько)johnpateha Автор
25.10.2018 13:51+1Я — экономист и все меряю через бабло и эк эффект.
В банк я принес градиентный бустинг, эта технология позволяет построить модели с лучшим качеством, чем логрег. Построил несколько скоринговых моделей. В скоринге — лучшая модель — меньше дефолтов, больше выдач кредитов — и то и другое конкретное бабло
В QIWI также есть как заработать на больших данных. Первые прикидки показывают, что мой текущий проект окупится через неск месяцев после выхода на рынок — есть понятный эффект и от экономии тек. расходов и увеличение доходов. Детали увы не могу раскрыть.
arturpanteleev
25.10.2018 13:48+1Извините
gotz
25.10.2018 13:51Хороший кейс. Вы в итоге освоили какой то стек для программирования дата-задачек вроде Python / Pandas?
johnpateha Автор
25.10.2018 13:53Так вышло, что я начал с R и до сих пор он мне ближе, чем питон. Кажется, что для ресеча он лучше.
Но по работе, как и везде, больше востребован питон, поэтому осваиваю и его потихоньку.
khrisanfov
25.10.2018 15:21Вы предлагаете отказаться от отложенной выборки в пользу кросс-валидации. На Kaggle это может отлично работает, но когда данных много все начинает работать медленно, особенно в бустингах типа LightGBM. Еще минус кросс-валидации в том что в конечном обучении на всех данных не факт что вы получите хорошую модель, алгоритм может как переобучиться так и не сойтись (недообучиться). Как вы в итоге отбираете модель на данных QIWI? Неужели кросс-валидация? Поделитесь пожалуйста опытом.
johnpateha Автор
25.10.2018 19:06Тюнить модель с градиентным бустингом на отложенной выборке — прямая дорога к переобучению. Для других методов еще можно как-то надеяться, что переобучение будет несильным, но не в случае с бустингом. Либо сильно недоучивать модель.
Если данных безумно много, лучший вариант — сделать сэмпл на этапе отбора переменных и подбора параметров, и уже более-менее финальный вариант доводить на полной, хотя если мы говорим о сотнях миллионов записей, то не факт, что от увеличения выборки качество модели существенно вырастет.
В QIWI я прививаю этот же подход — пока получается.
Недавно было соревнование на выявление фрода в кликах — там трейн был 350 млн записей.
Подход — тюнинг на сэмпле, финальная модель на полном, вместе с кросс-валидацией отлично зашли — наша команда заняла 8 местоkhrisanfov
25.10.2018 19:19johnpateha Как определяете силу переобучения? По разнице целевой метрики на трейне и валидации?
johnpateha Автор
25.10.2018 21:20В кэггле с этим просто — насколько изменился (как правило просел) результат на прайвате по сравнению с пабликом в сравнении с остальными. Собственно кэггл это во многом про правильную валидацию — когда оч. часто отличия между командами находятся в пределах 4 знака после запятой, довольно непростая задача улучшать модель на такие крохи без переобучения.
В банке иначе — там распределение более-менее стабильное, поэтому можно мерить проседание на новых временных периодах, либо ранних просрочках. Много раз слышал в банке тезис, что бустинг круто, но переобучается. Именно в силу того, что продолжают как и для логрега использовать отложенную выборку. Моей первой банковской модели пришлось вылежаться неск. месяцев, на которых затем проверили предикты, убедились, что результат стабилен и только потом пустили в пром.
ustas33
25.10.2018 15:39Спасибо за мотивационный пост.
Сейчас примерно в таком же положении. Учу GCP+AWS со специализацией в AI.
От себя могу порекомендовать подписку на http://www.safaribooksonline.com с подпиской на книги и курсы. Скидка на подписку первая строка в google.
SOSISKA13
25.10.2018 18:40Отменный пост!
Спасибо огроменное!
Единственное — перекосило, когда про Сантандер банк прочитал. Они мне закинули за тачку 18.79% годовых на шесть лет, потому что кредитной истории не было :)khrisanfov
26.10.2018 02:12И ты взял? :) Я даже про такой банк не слышал.
SOSISKA13
26.10.2018 12:07Да. Это во Флориде. Жажда камаро, первая машина, новая… конечно взял) уже выплатил и поменял)) Щас уже умнее)
razielvamp
26.10.2018 08:47Как стать датасайнтистом, если тебе за 40 и ты не программист
пробежавшись глазами по статье так и не понял, где связь между датасайнтистом и программистом/математиком. Для меня, человека несведущего, представленные в статье термины больше на термины маркетологов похожи. Ожидал увидеть что-то типа «матожидание», «медиана», «среднеквадратическое отклонение», но похоже, что в современном мире статистики и анализа это атавизмы.
Ну ваша предыдущая деятельность, как мне кажется, к новой работе ближе чем деятельность программиста/инженера/математика. Так что, есть ли здесь коренной перелом?johnpateha Автор
26.10.2018 10:31Я и хотел донести мысль, что использование новых технологий работы с большими данными, машинного обучения и тд — это уже не поляна только математиков и пришло время аналитикам ее осваивать. Отрасль пока считает иначе, но она ошибается.
И для меня это серьезный перелом — раньше моя поляна была только бумажки, теперь же я своими руками создаю модели. И то и другое направлено на повышение эффективности бизнеса, но характер работы отличается.
Не менее важно — я поменял рынок для своих услуг — раньше это были крупные компании, на деятельность которых так или иначе влияют текущие проблемы нашего государства, что в конечном итоге сказывалось и на проектах (больше бюрократии, избегание ответственности и тд). Теперь же я более независим от влияния госполитики.
Ну и вопрос развития — в пред. статусе я добился оч. многого и проектов с большой новизной становилось все меньше и меньше, а работа по шаблону драйвит куда меньше. Пока для меня построение моделей еще и хобби — это и крутое упражнение для мозга и стимул постоянно учиться. Когда-то это пройдет, но на несколько лет вперед драйв обеспечен.
REPISOT
Misaka10032
А мне мозг «саентистом» подменил на «саентологом». Что, в принципе, почти то же самое.
sterling239
Это уже баян. Дата-сатанисты уже уходят, дата-сталинисты не все поймут. А в одс на новый год обещали подарки от дата-санта-клауса
Vlad_fox
я же прочитал как датасаентологом :-)