
Привет, Хабр! Меня зовут Николай Ижиков, я работаю в компании «Сбербанк Технологии» в команде развития Open Source решений. За плечами 15 лет коммерческой разработки на Java. Я коммитер Apache Ignite и контрибьютор Apache Kafka.
Под катом вас ожидает видео и текстовая версия моего доклада на Apache Ignite Meetup о том, как использовать Apache Ignite вместе с Apache Spark и какие возможности мы для этого реализовали.
Что такое Apache Spark? Это продукт, который позволяет быстро выполнять распределенные вычисления и аналитические запросы. В основном, Apache Spark написан на Scala.
У Apache Spark богатый API для подключения к различным системам хранения или получения данных. Одна из особенностей продукта — универсальный SQL-like движок запросов к данным, получаемым из различных источников. Если у вас несколько источников информации, вы хотите их объединить и получить какие-то результаты, Apache Spark — это то, что вам нужно.
Одной из ключевых абстракций, которую предоставляет Spark, являются Data Frame, DataSet. В терминах реляционной базы — это таблица, некий источник, который предоставляет данные в структурированном виде. Известна структура, тип каждого столбца, его название и т.п. Data Frame'ы могут быть созданы из различных источников. В качестве примеров можно привести json-файлы, реляционные базы данных, различные hadoop-системы, а также Apache Ignite.
Spark поддерживает join'ы в SQL-запросах. Можно объединять данные из различных источников и получать результаты, выполнять аналитические запросы. Кроме того, есть API для сохранения данных. Когда вы выполнили запросы, провели исследование, то Spark предоставляет возможность сохранить результаты в тот приёмник, который поддерживает такую возможность, и, соответственно, решить задачу по обработке данных.
Apache Spark умеет читать данные из Apache Ignite SQL-таблиц и записывать их в виде такой таблицы. Любой DataFrame, который сформирован в Spark, можно сохранить в виде SQL-таблицы Apache Ignite.
Apache Ignite позволяет использовать все существующие SQL-таблицы Ignite в Spark Session без регистрации «руками» — с помощью IgniteCatalog внутри расширения стандартной SparkSession — IgniteSparkSession.
Тут надо немного углубиться в устройство Spark. В терминах обычной базы данных каталог — это место, в котором хранится мета-информация: какие таблицы доступны, какие в них столбцы и т.п. Когда поступает запрос, из каталога подтягивается мета-информация и SQL-движок что-то делает с таблицами, данными. По умолчанию в Spark все прочитанные таблицы (не важно, из реляционной базы данных, Ignite, Hadoop) приходится вручную регистрировать в сессии. В результате вы получаете возможность сделать SQL-запрос над этими таблицами. Spark про них узнает.
Чтобы работать с данными, которые мы загрузили в Ignite, нам нужно зарегистрировать таблицы. Но вместо регистрации каждой таблицы «руками» мы реализовали возможность автоматически получать доступ ко всем таблицам Ignite.
В чем здесь особенность? По непонятной мне причине, каталог в Spark – это internal API, т.е. сторонний человек не может прийти и создать свою имплементацию каталога. И, поскольку Spark вышел из Hadoop, он поддерживает только Hive. А все остальное вы должны регистрировать руками. Пользователи часто спрашивают, как можно это обойти и сразу делать SQL-запросы. Я реализовал каталог, который позволяет обозревать и обращаться к таблицам Ignite без регистрации ~и sms~, и первоначально предложил этот патч в Spark community, на что получил ответ: такой патч не интересен по каким-то внутренним причинам. И пробросить наружу internal API они тоже не дали.
Сейчас Ignite-каталог — это интересная фича, реализованная с использованием внутреннего API Spark'а. Чтобы использовать этот каталог, у нас есть своя имплементация сессии, Это обычная SparkSession, внутри которой можно делать запросы, обрабатывать данные. Отличия состоят в том, что мы встроили в неё ExternalCatalog для работы с таблицами Ignite, а также IgniteOptimization, о котором будет рассказано ниже.
SQL Optimization — возможность выполнять SQL-операторы внутри Ignite. По умолчанию при выполнении join, группировки, расчёта агрегатов, других сложных SQL-запросов Spark читает данные в режиме row by row. Единственное, что «умеет» источник данных, это эффективно отфильтровать строки.
Если используется join или группировка, Spark вытаскивает все данные из таблицы к себе в память на worker, применяя заданные фильтры, и только потом группирует их или выполняет другие SQL-операции. В случае Ignite это неоптимально, потому что сам Ignite имеет распределенную архитектуру и обладает знаниями о данных, которые в нём хранятся. Поэтому сам Ignite может эффективно подсчитать агрегаты, провести группировку. Кроме того, данных может быть много, и для их группировки нужно будет вычитать всё, поднять все данные в Spark, что довольно затратно.
В Spark предусмотрен API, при помощи которого можно изменять первоначальный план SQL запроса, выполнить оптимизацию и пробросить внутрь Ignite ту часть SQL-запроса, которая может быть там выполнена. Это будет эффективно с точки зрения скорости, а также расхода памяти, потому что мы не будем использовать ее, чтобы вытянуть данные, которые будут тут же сгруппированы.
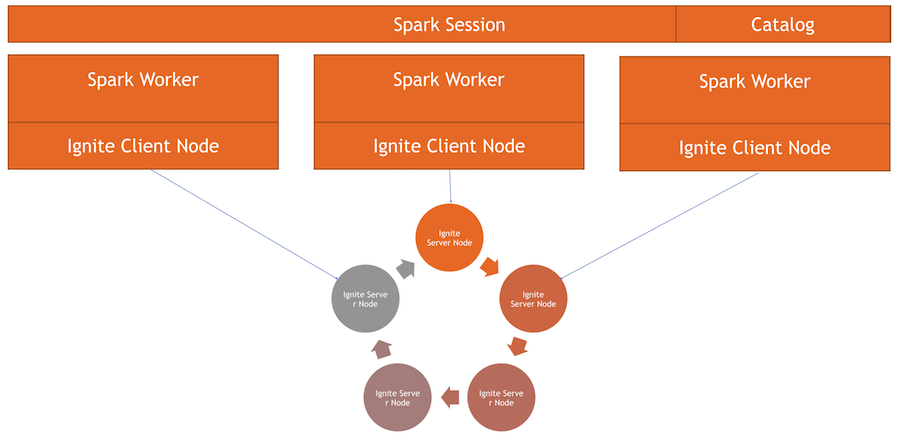
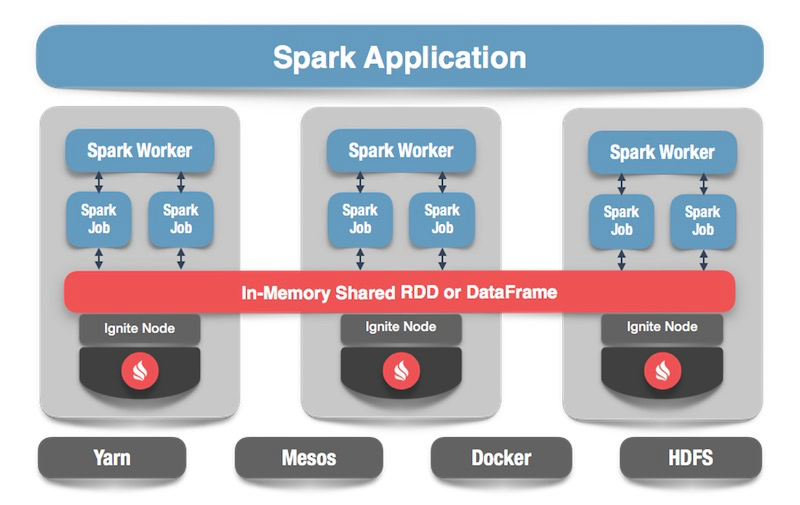
У нас есть кластер Ignite — это нижняя половина картинки. Zookeeper нет, поскольку нод всего пять. Есть спарковские worker'ы, внутри каждого worker'а поднимается клиентская нода Ignite. Через нее мы можем сделать запрос и прочитать данные, взаимодействовать с кластером. Также клиентская нода поднимается внутри IgniteSparkSession для работы каталога.
Переходим к коду: как прочитать данные из SQL-таблицы? В случае Spark все достаточно просто и хорошо: говорим, что хотим посчитать какие-то данные, указываем формат – это определенная константа. Дальше у нас есть несколько опций — путь к конфигурационному файлу для клиентской ноды, которая запускается при чтении данных. Мы указываем, какую таблицу хотим прочитать, и говорим Spark загрузить. Получаем данные и можем с ними делать, что хотим.
После того, как мы сформировали данные — необязательно из Ignite, можно из любого источника – мы можем так же просто все сохранить, указав формат и соответствующую таблицу. Командуем Spark записать, указываем формат. В конфиге прописываем, к какому кластеру коннектиться. Указываем таблицу, в которую хотим сохранить. Дополнительно можем прописать служебные опции — указать primary key, который мы на этой таблице создаем. Если данные просто апендятся без создания таблицы, то этот параметр не нужен. В конце жмем save и данные записываются.
Теперь давайте посмотрим, как это все работает.
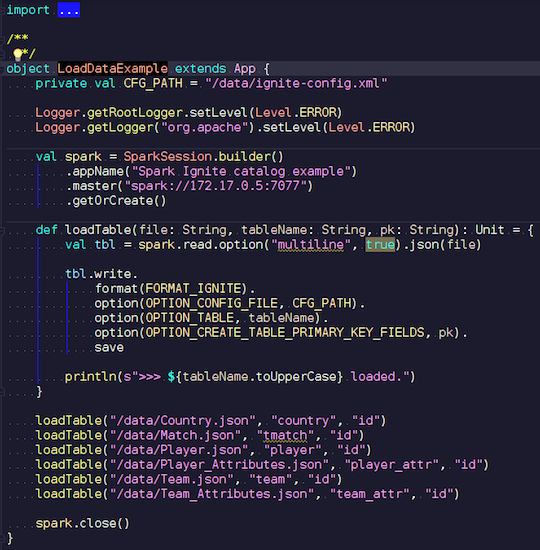
LoadDataExample.scala
Это очевидное приложение сначала продемонстрирует возможности записи. Я выбрал для примера данные по футбольным матчам, скачал статистику с известного ресурса. Тут содержится информация по турнирам: лиги, матчи, игроки, команды, атрибуты игроков, атрибуты команд — данные, которые описывают футбольные матчи в лигах европейских стран (Англия, Франция, Испании и т.п.).
Я хочу загрузить их в Ignite. Мы создаем сессию Spark, указываем адрес мастера и вызываем загрузку этих таблиц, передавая параметры. Пример на Scala, а не на Java, потому что Scala менее многословна и так лучше для примера.
Передаем имя файла, читаем его, указываем, что он мультилайн, это стандартный json-файл. Потом записываем в Ignite. Структуру нашего файла нигде не описываем — Spark сам определяет, какие данные у нас лежат и какая у них структура. Если все проходит гладко, создается таблица, в которой есть все нужные поля нужных типов данных. Вот так мы можем загрузить все внутрь Ignite.
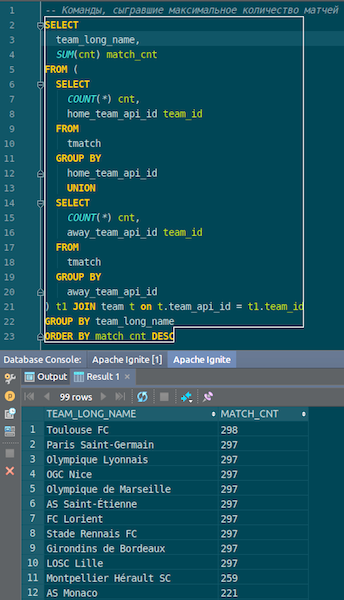
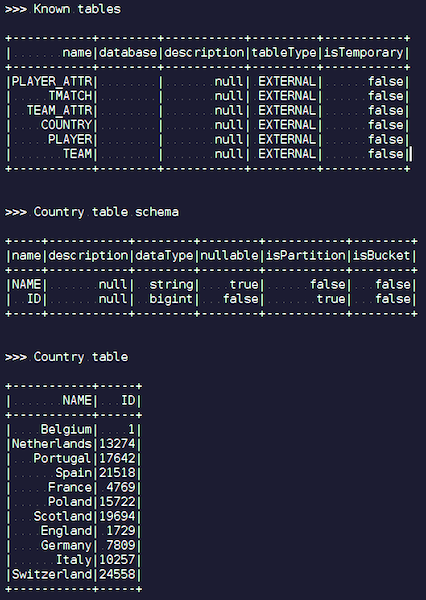
Когда данные загрузятся, мы их сможем увидеть в Ignite и сразу использовать. В качестве простого примера — запрос, который позволяет узнать, какая команда сыграла больше всех матчей. У нас есть две колонки: hometeam и awayteam, хозяева и гости. Выбираем, группируем, считаем count, суммируем и джойним с данными по команде – чтобы ввести имя команды. Та-дам – и данные с json-чиков у нас попали в Ignite. Видим Пари Сен-Жермен, Тулузу — по французским командам у нас оказалось много данных.
Резюмируем. Мы сейчас загрузили данные из источника, json-файла, в Ignite, причем достаточно быстро. Возможно, с точки зрения big data это не слишком большой объем, но для локального компьютера прилично. Схема таблицы взята из json-файла в исходном виде. Таблица создалась, названия столбцов скопировались из исходного файла, создан первичный ключ. ID везде есть, и первичный ключ является ID. Эти данные попали в Ignite, мы можем их использовать.
Посмотрим, как это работает.
CatalogExample.scala
Достаточно простым способом вы можете получить доступ и делать запросы ко всем вашим данным. В прошлом примере мы запускали стандартную спарковскую сессию. И никакой специфики Ignite там не было — кроме того, что вы должны подложить jar с нужным источником данных — совершенно стандартная работа через public API. Но, если вы хотите получить доступ к Ignite-таблицам автоматически, можно использовать наше расширение. Отличие состоит в том, что вместо SparkSession мы пишем IgniteSparkSession.
Как только вы создаете обьект IgniteSparkSession, то видите в каталоге все таблицы, которые только что загрузили в Ignite. Можете посмотреть их схему и всю информацию. Spark уже знает про таблицы, которые есть в Ignite, и вы можете легко получить все данные.
Когда вы делаете сложные запросы в Ignite с использованием JOIN, сначала Spark вытаскивает данные, и только потом JOIN их группирует. Чтобы оптимизировать процесс, мы сделали фичу IgniteOptimization — она оптимизирует план запросов Spark и позволяет пробросить внутрь Ignite те части запроса, которые могут быть выполнены внутри Ignite. Покажем оптимизацию на конкретном запросе.
Выполняем запрос. У нас есть таблица person — какие-то сотрудники, люди. У каждого сотрудника известен ID города, в котором он живет. Мы хотим узнать, сколько человек живет в каждом городе. Фильтруем – в каком городе живет больше одного человека. Вот изначальный план, который строит Spark:
Relation – это как раз Ignite-таблица. Нет никаких фильтров — мы просто выкачиваем по сети из кластера все данные из таблицы Person. Потом Spark все это агрегирует — в соответствии с запросом и вернет результат запроса.
Легко видеть, что все это поддерево с фильтром и агрегацией может быть исполнено внутри Ignite. Это будет гораздо эффективней, чем вытягивать все данные из потенциально большой таблицы в Spark — этим и занимается наша фича IgniteOptimization. После анализа и оптимизации дерева мы получаем следующий план:
В итоге, у нас получается всего один relation, так как мы оптимизировали все дерево. И внутри уже видно, что на Ignite пойдет запрос, который достаточно близок к изначальному запросу.
Предположим, мы джойнимся с разными источниками данных: например, один DataFrame у нас из Ignite, второй из json, третий опять из Ignite, а четвертый — из какой-то реляционной базы. В этом случае в плане будет оптимизировано только поддерево. Мы оптимизируем, что можем, закидываем это в Ignite, а все остальное уже будет делать Spark. За счет этого мы получаем выигрыш по скорости.
Другой пример с JOIN:
У нас есть две таблицы. Мы джойнимся по значению и выбираем из них все — ID, значения. Spark предлагает вот такой вот план:
Видим, что он будет вытаскивать все данные из одной таблицы, все данные из второй, джойнить их внутри себя и выдавать результаты. После обработки и оптимизации мы получаем ровно такой же запрос, который уходит в Ignite, где сравнительно быстро исполняется.
Покажу еще пример.
OptimizationExample.scala
Мы создаем IgniteSpark-сессию, в которую уже автоматически включены все наши возможности оптимизации. Здесь запрос такой: найти игроков с наибольшим рейтингом и вывести их имена. В таблице player — их атрибуты и данные. Мы джойнимся, фильтруем мусорные данные и выводим игроков с наибольшим рейтингом. Посмотрим, какой план у нас получился после оптимизации, и покажем результаты этого запроса.
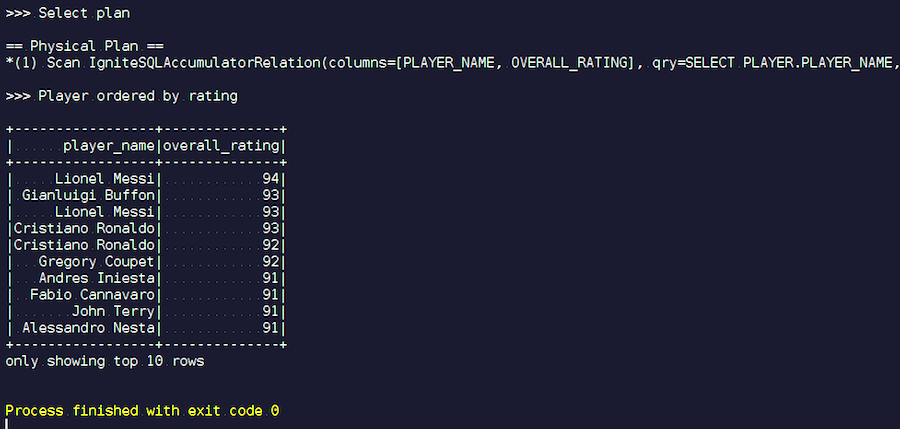
Запускаем. Видим знакомые фамилии: Месси, Буффон, Роналду и т.д. Кстати, некоторые почему-то в двух ипостасях встречаются — и Месси, и Роналду. Любителям футбола может показаться странным, что в списке фигурируют неизвестные игроки. Это вратари, игроки с довольно высокими характеристиками — на фоне других игроков. Теперь смотрим на план запроса, который был выполнен. В Spark почти ничего не выполнялось, то есть мы весь запрос отправили опять же в Ignite.
Наш проект – это open source-продукт, поэтому мы всегда рады патчам и обратной связи от разработчиков. Ваша помощь, обратная связь, патчи очень приветствуются. Мы ждем их. На 90% Ignite-комьюнити – русскоязычно. Например, для меня, пока я не начал рабоать над Apache Ignite, не самое лучшее знание английского языка было сдерживающим фактором. По-русски вряд ли стоит на dev-лист писать, но даже если вы напишите что-то не так, вам ответят и помогут.
Что можно улучшить по этой интеграции? Чем можно помочь, если у вас есть такое желание? Список ниже. Звездочки обозначают сложность.

Для проверки оптимизации нужно писать тесты со сложными запросами. Выше я показал несколько очевидных запросов. Понятно, что если написать много группировок и много джойнов, то что-то может упасть. Это совсем простой таск — приходите и делайте. Если мы найдем какие-то баги по итогам тестов, их надо будет исправить. Там уже будет сложнее.
Еще одна понятная и интересная задача – интеграция Spark с тонким клиентом. Он изначально способен указать какие-то наборы IP-адресов, и этого достаточно, чтобы присоединиться к Ignite-кластеру, что удобно в случае интеграции с внешней системой. Если вдруг захотите присоединиться к решению этой задачи, я лично буду по ней помогать.
Если вы захотели присоединиться к сообществу Apache Ignite, ниже полезные ссылки:
У нас отзывчивый дев-лист, на котором вам обязательно помогут. Он еще далек от идеала, но в сравнении с другими проектами действительно живой.
Если вы знаете Java или С++, ищете работу и хотите разрабатывать Open Source (Apache Ignite, Apache Kafka, Tarantool и т.п.) пишите сюда: join-open-source@sberbank.ru.
Под катом вас ожидает видео и текстовая версия моего доклада на Apache Ignite Meetup о том, как использовать Apache Ignite вместе с Apache Spark и какие возможности мы для этого реализовали.
Что умеет Apache Spark
Что такое Apache Spark? Это продукт, который позволяет быстро выполнять распределенные вычисления и аналитические запросы. В основном, Apache Spark написан на Scala.
У Apache Spark богатый API для подключения к различным системам хранения или получения данных. Одна из особенностей продукта — универсальный SQL-like движок запросов к данным, получаемым из различных источников. Если у вас несколько источников информации, вы хотите их объединить и получить какие-то результаты, Apache Spark — это то, что вам нужно.
Одной из ключевых абстракций, которую предоставляет Spark, являются Data Frame, DataSet. В терминах реляционной базы — это таблица, некий источник, который предоставляет данные в структурированном виде. Известна структура, тип каждого столбца, его название и т.п. Data Frame'ы могут быть созданы из различных источников. В качестве примеров можно привести json-файлы, реляционные базы данных, различные hadoop-системы, а также Apache Ignite.
Spark поддерживает join'ы в SQL-запросах. Можно объединять данные из различных источников и получать результаты, выполнять аналитические запросы. Кроме того, есть API для сохранения данных. Когда вы выполнили запросы, провели исследование, то Spark предоставляет возможность сохранить результаты в тот приёмник, который поддерживает такую возможность, и, соответственно, решить задачу по обработке данных.
Какие возможности интеграции Apache Spark с Apache Ignite мы реализовали
- Чтение данных из SQL-таблиц Apache Ignite.
- Запись данных в SQL-таблицы Apache Ignite.
- IgniteCatalog внутри IgniteSparkSession — возможность использовать все существующие SQL-таблицы Ignite'а без регистрации «руками».
- SQL Optimization — возможность выполнять SQL-операторы внутри Ignite.
Apache Spark умеет читать данные из Apache Ignite SQL-таблиц и записывать их в виде такой таблицы. Любой DataFrame, который сформирован в Spark, можно сохранить в виде SQL-таблицы Apache Ignite.
Apache Ignite позволяет использовать все существующие SQL-таблицы Ignite в Spark Session без регистрации «руками» — с помощью IgniteCatalog внутри расширения стандартной SparkSession — IgniteSparkSession.
Тут надо немного углубиться в устройство Spark. В терминах обычной базы данных каталог — это место, в котором хранится мета-информация: какие таблицы доступны, какие в них столбцы и т.п. Когда поступает запрос, из каталога подтягивается мета-информация и SQL-движок что-то делает с таблицами, данными. По умолчанию в Spark все прочитанные таблицы (не важно, из реляционной базы данных, Ignite, Hadoop) приходится вручную регистрировать в сессии. В результате вы получаете возможность сделать SQL-запрос над этими таблицами. Spark про них узнает.
Чтобы работать с данными, которые мы загрузили в Ignite, нам нужно зарегистрировать таблицы. Но вместо регистрации каждой таблицы «руками» мы реализовали возможность автоматически получать доступ ко всем таблицам Ignite.
В чем здесь особенность? По непонятной мне причине, каталог в Spark – это internal API, т.е. сторонний человек не может прийти и создать свою имплементацию каталога. И, поскольку Spark вышел из Hadoop, он поддерживает только Hive. А все остальное вы должны регистрировать руками. Пользователи часто спрашивают, как можно это обойти и сразу делать SQL-запросы. Я реализовал каталог, который позволяет обозревать и обращаться к таблицам Ignite без регистрации ~и sms~, и первоначально предложил этот патч в Spark community, на что получил ответ: такой патч не интересен по каким-то внутренним причинам. И пробросить наружу internal API они тоже не дали.
Сейчас Ignite-каталог — это интересная фича, реализованная с использованием внутреннего API Spark'а. Чтобы использовать этот каталог, у нас есть своя имплементация сессии, Это обычная SparkSession, внутри которой можно делать запросы, обрабатывать данные. Отличия состоят в том, что мы встроили в неё ExternalCatalog для работы с таблицами Ignite, а также IgniteOptimization, о котором будет рассказано ниже.
SQL Optimization — возможность выполнять SQL-операторы внутри Ignite. По умолчанию при выполнении join, группировки, расчёта агрегатов, других сложных SQL-запросов Spark читает данные в режиме row by row. Единственное, что «умеет» источник данных, это эффективно отфильтровать строки.
Если используется join или группировка, Spark вытаскивает все данные из таблицы к себе в память на worker, применяя заданные фильтры, и только потом группирует их или выполняет другие SQL-операции. В случае Ignite это неоптимально, потому что сам Ignite имеет распределенную архитектуру и обладает знаниями о данных, которые в нём хранятся. Поэтому сам Ignite может эффективно подсчитать агрегаты, провести группировку. Кроме того, данных может быть много, и для их группировки нужно будет вычитать всё, поднять все данные в Spark, что довольно затратно.
В Spark предусмотрен API, при помощи которого можно изменять первоначальный план SQL запроса, выполнить оптимизацию и пробросить внутрь Ignite ту часть SQL-запроса, которая может быть там выполнена. Это будет эффективно с точки зрения скорости, а также расхода памяти, потому что мы не будем использовать ее, чтобы вытянуть данные, которые будут тут же сгруппированы.
Как все работает
У нас есть кластер Ignite — это нижняя половина картинки. Zookeeper нет, поскольку нод всего пять. Есть спарковские worker'ы, внутри каждого worker'а поднимается клиентская нода Ignite. Через нее мы можем сделать запрос и прочитать данные, взаимодействовать с кластером. Также клиентская нода поднимается внутри IgniteSparkSession для работы каталога.
Ignite Data Frame
Переходим к коду: как прочитать данные из SQL-таблицы? В случае Spark все достаточно просто и хорошо: говорим, что хотим посчитать какие-то данные, указываем формат – это определенная константа. Дальше у нас есть несколько опций — путь к конфигурационному файлу для клиентской ноды, которая запускается при чтении данных. Мы указываем, какую таблицу хотим прочитать, и говорим Spark загрузить. Получаем данные и можем с ними делать, что хотим.
spark.read
.format(FORMAT_IGNITE)
.option(OPTION_CONFIG_FILE, TEST_CONFIG_FILE)
.option(OPTION_TABLE, "person")
.load()После того, как мы сформировали данные — необязательно из Ignite, можно из любого источника – мы можем так же просто все сохранить, указав формат и соответствующую таблицу. Командуем Spark записать, указываем формат. В конфиге прописываем, к какому кластеру коннектиться. Указываем таблицу, в которую хотим сохранить. Дополнительно можем прописать служебные опции — указать primary key, который мы на этой таблице создаем. Если данные просто апендятся без создания таблицы, то этот параметр не нужен. В конце жмем save и данные записываются.
tbl.write.
format(FORMAT_IGNITE).
option(OPTION_CONFIG_FILE, CFG_PATH).
option(OPTION_TABLE, tableName).
option(OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS, pk).
save
Теперь давайте посмотрим, как это все работает.
LoadDataExample.scala
Это очевидное приложение сначала продемонстрирует возможности записи. Я выбрал для примера данные по футбольным матчам, скачал статистику с известного ресурса. Тут содержится информация по турнирам: лиги, матчи, игроки, команды, атрибуты игроков, атрибуты команд — данные, которые описывают футбольные матчи в лигах европейских стран (Англия, Франция, Испании и т.п.).
Я хочу загрузить их в Ignite. Мы создаем сессию Spark, указываем адрес мастера и вызываем загрузку этих таблиц, передавая параметры. Пример на Scala, а не на Java, потому что Scala менее многословна и так лучше для примера.
Передаем имя файла, читаем его, указываем, что он мультилайн, это стандартный json-файл. Потом записываем в Ignite. Структуру нашего файла нигде не описываем — Spark сам определяет, какие данные у нас лежат и какая у них структура. Если все проходит гладко, создается таблица, в которой есть все нужные поля нужных типов данных. Вот так мы можем загрузить все внутрь Ignite.
Когда данные загрузятся, мы их сможем увидеть в Ignite и сразу использовать. В качестве простого примера — запрос, который позволяет узнать, какая команда сыграла больше всех матчей. У нас есть две колонки: hometeam и awayteam, хозяева и гости. Выбираем, группируем, считаем count, суммируем и джойним с данными по команде – чтобы ввести имя команды. Та-дам – и данные с json-чиков у нас попали в Ignite. Видим Пари Сен-Жермен, Тулузу — по французским командам у нас оказалось много данных.
Резюмируем. Мы сейчас загрузили данные из источника, json-файла, в Ignite, причем достаточно быстро. Возможно, с точки зрения big data это не слишком большой объем, но для локального компьютера прилично. Схема таблицы взята из json-файла в исходном виде. Таблица создалась, названия столбцов скопировались из исходного файла, создан первичный ключ. ID везде есть, и первичный ключ является ID. Эти данные попали в Ignite, мы можем их использовать.
IgniteSparkSession и IgniteCatalog
Посмотрим, как это работает.
CatalogExample.scala
Достаточно простым способом вы можете получить доступ и делать запросы ко всем вашим данным. В прошлом примере мы запускали стандартную спарковскую сессию. И никакой специфики Ignite там не было — кроме того, что вы должны подложить jar с нужным источником данных — совершенно стандартная работа через public API. Но, если вы хотите получить доступ к Ignite-таблицам автоматически, можно использовать наше расширение. Отличие состоит в том, что вместо SparkSession мы пишем IgniteSparkSession.
Как только вы создаете обьект IgniteSparkSession, то видите в каталоге все таблицы, которые только что загрузили в Ignite. Можете посмотреть их схему и всю информацию. Spark уже знает про таблицы, которые есть в Ignite, и вы можете легко получить все данные.
IgniteOptimization
Когда вы делаете сложные запросы в Ignite с использованием JOIN, сначала Spark вытаскивает данные, и только потом JOIN их группирует. Чтобы оптимизировать процесс, мы сделали фичу IgniteOptimization — она оптимизирует план запросов Spark и позволяет пробросить внутрь Ignite те части запроса, которые могут быть выполнены внутри Ignite. Покажем оптимизацию на конкретном запросе.
SQL Query:
SELECT
city_id,
count(*)
FROM
person p
GROUP BY city_id
HAVING count(*) > 1Выполняем запрос. У нас есть таблица person — какие-то сотрудники, люди. У каждого сотрудника известен ID города, в котором он живет. Мы хотим узнать, сколько человек живет в каждом городе. Фильтруем – в каком городе живет больше одного человека. Вот изначальный план, который строит Spark:
== Analyzed Logical Plan ==
city_id: bigint, count(1): bigint
Project [city_id#19L, count(1)#52L]
+- Filter (count(1)#54L > cast(1 as bigint))
+- Aggregate [city_id#19L], [city_id#19L, count(1) AS count(1)#52L, count(1) AS count(1)#54L]
+- SubqueryAlias p
+- SubqueryAlias person
+- Relation[NAME#11,BIRTH_DATE#12,IS_RESIDENT#13,SALARY#14,PENSION#15,ACCOUNT#16,AGE#17,ID#18L,CITY_ID#19L]
IgniteSQLRelation[table=PERSON]
Relation – это как раз Ignite-таблица. Нет никаких фильтров — мы просто выкачиваем по сети из кластера все данные из таблицы Person. Потом Spark все это агрегирует — в соответствии с запросом и вернет результат запроса.
Легко видеть, что все это поддерево с фильтром и агрегацией может быть исполнено внутри Ignite. Это будет гораздо эффективней, чем вытягивать все данные из потенциально большой таблицы в Spark — этим и занимается наша фича IgniteOptimization. После анализа и оптимизации дерева мы получаем следующий план:
== Optimized Logical Plan ==
Relation[CITY_ID#19L,COUNT(1)#52L]
IgniteSQLAccumulatorRelation(
columns=[CITY_ID, COUNT(1)], qry=SELECT CITY_ID, COUNT(1) FROM PERSON GROUP BY city_id HAVING count(1) > 1)В итоге, у нас получается всего один relation, так как мы оптимизировали все дерево. И внутри уже видно, что на Ignite пойдет запрос, который достаточно близок к изначальному запросу.
Предположим, мы джойнимся с разными источниками данных: например, один DataFrame у нас из Ignite, второй из json, третий опять из Ignite, а четвертый — из какой-то реляционной базы. В этом случае в плане будет оптимизировано только поддерево. Мы оптимизируем, что можем, закидываем это в Ignite, а все остальное уже будет делать Spark. За счет этого мы получаем выигрыш по скорости.
Другой пример с JOIN:
SQL Query -
SELECT
jt1.id as id1,
jt1.val1,
jt2.id as id2,
jt2.val2
FROM
jt1 JOIN
jt2 ON jt1.val1 = jt2.val2
У нас есть две таблицы. Мы джойнимся по значению и выбираем из них все — ID, значения. Spark предлагает вот такой вот план:
== Analyzed Logical Plan ==
id1: bigint, val1: string, id2: bigint, val2: string
Project [id#4L AS id1#84L, val1#3, id#6L AS id2#85L, val2#5]
+- Join Inner, (val1#3 = val2#5)
:- SubqueryAlias jt1
: +- Relation[VAL1#3,ID#4L] IgniteSQLRelation[table=JT1]
+- SubqueryAlias jt2
+- Relation[VAL2#5,ID#6L] IgniteSQLRelation[table=JT2]Видим, что он будет вытаскивать все данные из одной таблицы, все данные из второй, джойнить их внутри себя и выдавать результаты. После обработки и оптимизации мы получаем ровно такой же запрос, который уходит в Ignite, где сравнительно быстро исполняется.
== Optimized Logical Plan ==
Relation[ID#84L,VAL1#3,ID#85L,VAL2#5]
IgniteSQLAccumulatorRelation(columns=[ID, VAL1, ID, VAL2],
qry=
SELECT JT1.ID AS id1, JT1.VAL1, JT2.ID AS id2, JT2.VAL2
FROM JT1 JOIN JT2 ON JT1.val1 = JT2.val2
WHERE JT1.val1 IS NOT NULL AND JT2.val2 IS NOT NULL)Покажу еще пример.
OptimizationExample.scala
Мы создаем IgniteSpark-сессию, в которую уже автоматически включены все наши возможности оптимизации. Здесь запрос такой: найти игроков с наибольшим рейтингом и вывести их имена. В таблице player — их атрибуты и данные. Мы джойнимся, фильтруем мусорные данные и выводим игроков с наибольшим рейтингом. Посмотрим, какой план у нас получился после оптимизации, и покажем результаты этого запроса.
Запускаем. Видим знакомые фамилии: Месси, Буффон, Роналду и т.д. Кстати, некоторые почему-то в двух ипостасях встречаются — и Месси, и Роналду. Любителям футбола может показаться странным, что в списке фигурируют неизвестные игроки. Это вратари, игроки с довольно высокими характеристиками — на фоне других игроков. Теперь смотрим на план запроса, который был выполнен. В Spark почти ничего не выполнялось, то есть мы весь запрос отправили опять же в Ignite.
Развитие Apache Ignite
Наш проект – это open source-продукт, поэтому мы всегда рады патчам и обратной связи от разработчиков. Ваша помощь, обратная связь, патчи очень приветствуются. Мы ждем их. На 90% Ignite-комьюнити – русскоязычно. Например, для меня, пока я не начал рабоать над Apache Ignite, не самое лучшее знание английского языка было сдерживающим фактором. По-русски вряд ли стоит на dev-лист писать, но даже если вы напишите что-то не так, вам ответят и помогут.
Что можно улучшить по этой интеграции? Чем можно помочь, если у вас есть такое желание? Список ниже. Звездочки обозначают сложность.
Для проверки оптимизации нужно писать тесты со сложными запросами. Выше я показал несколько очевидных запросов. Понятно, что если написать много группировок и много джойнов, то что-то может упасть. Это совсем простой таск — приходите и делайте. Если мы найдем какие-то баги по итогам тестов, их надо будет исправить. Там уже будет сложнее.
Еще одна понятная и интересная задача – интеграция Spark с тонким клиентом. Он изначально способен указать какие-то наборы IP-адресов, и этого достаточно, чтобы присоединиться к Ignite-кластеру, что удобно в случае интеграции с внешней системой. Если вдруг захотите присоединиться к решению этой задачи, я лично буду по ней помогать.
Если вы захотели присоединиться к сообществу Apache Ignite, ниже полезные ссылки:
- Начать здесь — https://ignite.apache.org/community/resources.html
- Исходники здесь — https://github.com/apache/ignite/
- Доки здесь — https://apacheignite.readme.io/docs
- Баги здесь — https://issues.apache.org/jira/browse/IGNITE
- Написать можно сюда — dev@ignite.apache.org, user@ignite.apache.org
У нас отзывчивый дев-лист, на котором вам обязательно помогут. Он еще далек от идеала, но в сравнении с другими проектами действительно живой.
Если вы знаете Java или С++, ищете работу и хотите разрабатывать Open Source (Apache Ignite, Apache Kafka, Tarantool и т.п.) пишите сюда: join-open-source@sberbank.ru.
time2rfc
Спасибо за интересную статью!
В процессе чтения возник вопрос, правильно ли я понимаю что цель этой интеграции:
Очень интересно было бы узнать про прикладкное использование — кейсы из прода для такой интеграции и чуть больше про ваш отдел. Я правильно понял что вы добавляете функционал необходимый бизнессу в открытые проекты ?
NorthDragon Автор
Цель интеграции в том, что бы предоставить ещё один способ работать с данными, которые пользователи положили в Ignite. А также облегчить процесс загрузки данных, т.к. в Spark уже многое для этого сделано.
> Я правильно понял что вы добавляете функционал необходимый бизнессу в открытые проекты?
Это частично так :). Запросы от бизнеса имеют наиболее высокий приоритет, однако, довольно часто мы делаем задачи, которые нужны community. Развиваем продукт.
> кейсы из прода для такой интеграции
Если честно, детальной информации об этом у меня нет :)
Однако, на dev-лист приходили ребята с доработками этого функционала и различными баг-репортами.
Мне кажется, это говорит о том, что фичу используют.
time2rfc
Спасибо за ответы. По-доброму вам завидую, хорошая работа помогать комьюнити за счет работодателя.