
Меня зовут Андрей Поляков, я руководитель группы документирования API и SDK в Яндексе. Сегодня я хотел бы поделиться с вами докладом, который я и моя коллега, старший разработчик документации Юлия Пивоварова, прочитали несколько недель назад на шестом Гипербатоне.
Светлана Каюшина, руководитель отдела документирования и локализации:
— Объемы программного кода в мире в последние годы сильно выросли, продолжают расти, и это влияет на работу технических писателей, которым приходит все больше задач на разработку программной документации и документирования кода. Мы не могли обойти стороной эту тему, посвятили ей целую секцию. Это три взаимосвязанных доклада, посвященных унификации разработки программной документации. Я приглашаю наших специалистов по документированию программных интерфейсов и библиотек Андрея Полякова и Юлию Пивоварову. Передаю им слово.
— Всем привет! Сегодня мы с Юлей расскажем, как в Яндексе у нас появился новый взгляд на документирование API и SDK. Доклад будет состоять из четырех частей, доклад часовой, подискутируем, поговорим.
Поговорим про унификацию API и SDK, о том, как мы к ней пришли, что мы там делали. Мы поделимся опытом использования универсального генератора, одного для всех языков, и расскажем, почему нам это не подошло, какие были подводные камни, и почему мы перешли на генерацию документации нативными генераторами.
В конце расскажем, как были построены наши процессы.
Начнем с унификации. Об унификации задумываются все, когда в команде становится больше, чем два человека: все пишут по-разному, у всех свои подходы, и это логично. Лучше все правила обговорить на берегу, до того, как вы начали писать документацию, но не у всех это получается.
Мы собрались экспертной группой, чтобы проанализировать нашу документацию. Мы это сделали чтобы систематизировать наши подходы. Все пишут по-разному, и давайте договоримся, чтобы писать в одном стиле. Это второй поинт, для чего мы собирались, чтобы постараться сделать документацию единой, чтобы у пользователя был один user experience во всей документации Яндекса, именно технической.
Работа разделилась на три этапа. Мы собрали описание технологий, которые есть в Яндексе, которые мы используем, постарались выделить из них те, которые мы можем как-то унифицировать. А также составили общую структуру типовых документов и шаблоны.

Перейдем к описанию технологий. Мы начали изучать, какие в Яндексе используются технологии. Их так много, что мы устали записывать их в какой-то блокнот, и в итоге выбрали только самые основные, которые чаще всего используются, с которыми чаще всего сталкиваются технические писатели, и начали их описывать.
Что подразумевается под описанием технологий? Мы выделили основные тезисы и сущности каждой технологии. Если мы говорим про языки программирования, то это описание таких сущностей как класс, свойство, интерфейсы и т. д. Если мы говорим про протоколы, то мы описываем методы HTTP, говорим про формат кода ошибок, кода ответов и т. д. Мы составили глоссарий, где содержались следующие вещи: термины на русском, термины на английском, нюансы использования. Например, мы не говорим про какой-то метод SDK, что он ПОЗВОЛЯЕТ что-то делать. Он что-то ДЕЛАЕТ, если программист дергает какую-то ручку, она дает какой-то ответ.
Кроме нюансов в описании также содержались стандартные структуры, стандартные речевые обороты, которые мы используем в документации, чтобы техписатель мог взять конкретную формулировку и использовать ее дальше.
Кроме того, технические писатели часто пишут куски кода, сниппеты, семплы, и для этого мы также описали для каждой технологии свой стайлгайд. Мы обратились к гайдам разработчиков, которые есть в Яндексе. Обратили внимание на оформление код, описание комментариев, отступы и все подобное. Мы это делаем чтобы, когда технический писатель приходит с куском кода или написанным семплом к программисту, программист смотрел суть, а не на то, как это оформлено, и это сокращает время. И когда технический писатель умеет писать по стайлгайдам Яндекса, это очень круто, может, он захочет потом программистом стать. Предыдущий доклад был про различные экспертизы. Вот, например, можно двигаться в программисты.
Для техписателей мы также разработали быстрый старт: как установить среду разработки, когда он знакомится с новой технологией. Например, если у техписателя SDK написан на C#, то он приходит, настраивает среду разработки, читает мануалы, знакомится с терминологией. Также мы оставили ссылки на официальную документацию и RFC, если таковые были. Мы сделали точку входа для технических писателей, и выглядит она примерно так.
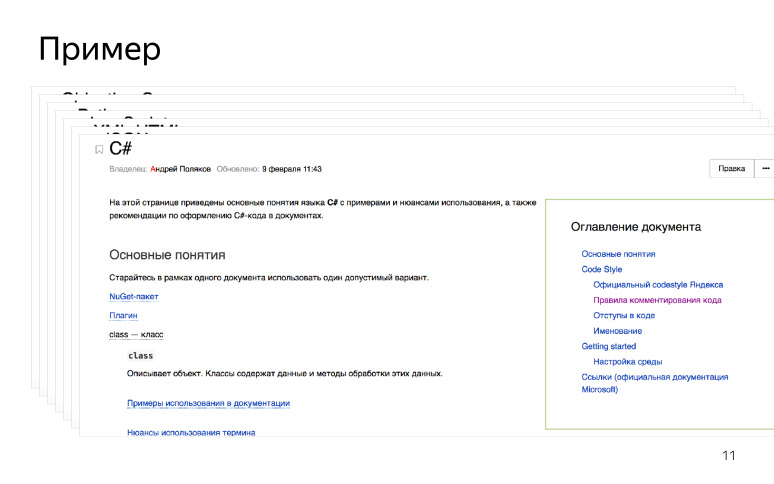
Когда технический писатель приходит, он изучает новую технологию и начинает ее документировать.
После того, как мы описали технологии, мы перешли к описанию структуры HTTP API.
У нас много различных HTTP API, и все описаны по-разному. Давайте договоримся и сделаем одинаково!
Мы выделили основные разделы, которые будут в каждом HTTP API:

«Обзор» или «Введение»: для чего нужен этот API, что он позволяет делать, к какому хосту надо обращаться, чтобы получить какой-то ответ.
«Быстрый старт», когда человек проходит по каким-то шагам и получает успешный результат в конце, чтобы понять, как работает этот API.
«Подключение / Авторизация». Для многих API необходим токен авторизации или API-ключ. Это важный поинт, поэтому мы решили, что это обязательная часть всех API.
«Ограничения / Лимиты», когда мы говорим о лимитах на количество запросов или на размер тела запроса и т. д.
«Справочник», референс. Очень большая часть, где содержатся все HTTP ручки, которые пользователь может дернуть и получить какой-то результат.
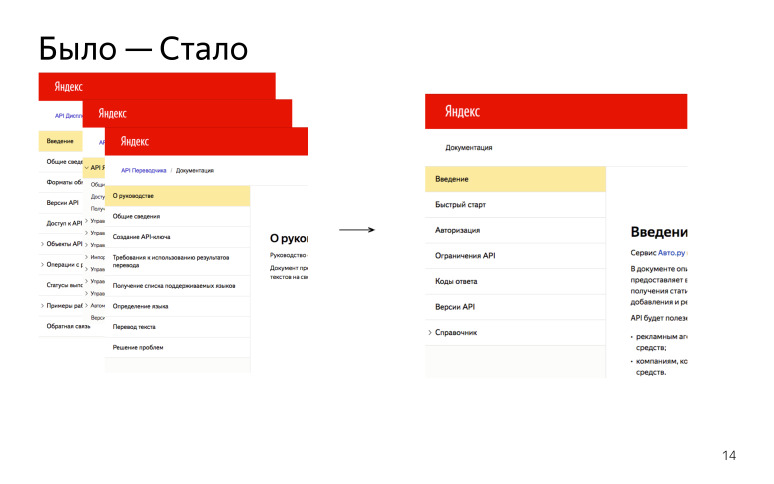
В итоге у нас было много разных API, описаны они были по-разному, стараемся теперь писать все одинаково. Такой профит.
Углубляясь в справочники, мы поняли, что HTTP ручка практически всегда одинаковая. Ты ее дергаешь, то есть делаешь запрос, сервер возвращает ответ — вуаля. Давайте попробуем это унифицировать. Мы написали некий шаблон, который постарался покрывать все кейсы. Технический писатель берет шаблон, и, если у него PUT-запрос, он оставляет нужные части в шаблоне. Если у него GET-запрос, он использует только те части, которые для необходимы для GET-запроса. Общий шаблон для всех запросов, который можно переиспользовать. Теперь не надо создавать структуру документа с нуля, а можно просто взять готовый шаблон.

В каждой ручке описано, для чего она нужна, что она делает. Есть раздел «Формат запроса», где содержатся path-параметры, query-параметры, все, что приходит в теле запроса, если оно отправляется. Также выделили раздел «Формат ответа»: мы пишем его, если есть тело ответа. Отдельным разделом мы выделили «Коды ответов», потому что ответ от сервера приходит независимо от тела. И оставил раздел «Пример». Если мы поставляем с этим API какой-то SDK, то мы говорим, что этим SDK пользуйтесь так, дергайте такую ручку, вызывайте такой метод. Обычно мы оставляем какой-то пример с cURL, где пользователь просто вставляет свой токен. А если у нас есть тестовый стенд, то просто берет запрос и выполняет его. И получает какой-то результат.

Получается, было много ручек, описаны были по-разному, а теперь хотим привести это все к единой форме.
После того, как мы закончили с HTTP API, мы перешли к мобильным SDK.
Есть общая структура документа, она примерно одинаковая:
— «Введение», где мы говорим, что вот, этот SDK используется для таких целей, интегрируйте себе его для таких целей, для таких ОС он подойдет, у нас такие-то версии есть и т. д.
— «Подключение». В отличие от HTTP API мы не просто говорим, как получить ключ для использования SDK, если он нужен, мы говорим о том, как интегрировать библиотеку себе в проект.
— «Примеры использования». Самый большой по объему раздел. Чаще всего разработчики хотят прийти в документацию и не читать много информации, они хотят скопировать кусок, вставить себе, и у них все заработает. Поэтому эту часть мы посчитали очень важной и выделили ее в обязательный раздел.

— «Справочник», референс, но в отличие от референса HTTP API, мы не можем здесь все унифицировать, так как справочники мы в основном генерируем и дальше в докладе мы об этом поговорим.
— «Релизы», или история изменений, changelog. У мобильных SDK обычно короткий релизный цикл, где-то каждые две недели выпускается новая версия. И лучше бы пользователю говорить о том, что изменилось, стоит ему обновляться или нет.
У API при этом у нас есть как обязательные разделы, которые мы видим, так и разделы, которые мы рекомендуем использовать. Если API часто обновляется, мы говорим, что тогда вставляйте себе тоже историю изменений, что изменилось в API. А зачастую у нас API редко обновляемые, и как обязательный раздел это указывать бессмысленно.

Итак, у нас было много SDK, которые были описаны по-разному, мы постарались превратить примерно в один стиль. Естественно, имеются дополнительные различия, присущие только этому SDK или этому HTTP API. Здесь у нас есть свобода выбора. Мы не говорим, что кроме этих разделов никаких делать нельзя. Конечно, можно, просто перечисленные разделы мы стараемся сделать везде, чтобы было понятно, что, если пользователь перешел в документации к другому SDK, он знает, что будет описано в разделе «Подключение».
Итак, мы придумали шаблоны, составили гайды, какой теперь у нас план действий? Мы решили, что если мы масштабно изменяем API, меняем ручки или меняем SDK, мы берем новые шаблоны, берем новую структуру и начинаем по ней работать.
Если мы пишем документацию с нуля то, конечно, мы опять берем новую структуру, берем новые шаблоны и работаем по ним.
А если API устаревший, редко обновляется или никто его не поддерживает, но он существует, то немного ресурсозатратно его махом переделывать. Просто решили оставить, пока пусть будет так, но затем, когда появятся ресурсы, мы к ним обязательно вернемся, все это сделаем хорошо и красиво.
Какие плюсы от унификации? Они всем должны быть очевидны:
«UX», мы думаем о том, чтобы пользователь в нашей документации чувствовал себя как дома. Он пришел, и знает, что описано в разделах, где ему найти авторизацию, примеры использования, описание ручки. Это здорово.
Для техписателей описание технологии позволяет определить некую точку входа, куда он приходит, и начинает знакомиться с этой технологией, если он ее не знал, начинает разбираться в терминологии, погружаться в нее.
Следующий момент — взаимозаменяемость. Если техписатель ушел в отпуск или просто перестал писать, то другой техписатель при входе в документ знает, как он устроен внутри. Сразу понятно, что описано в подключении, где искать информацию по интеграции SDK. Понять и сделать небольшую правку в документе становится легче. Понятно, у каждого проекта есть своя специфика, нельзя просто прийти и документировать какой-то проект, не зная его полностью. Но при этом структура, то есть навигация по файлам, примерно будет одинаковая.
И, конечно, общая терминология. Ту терминологию, которую мы составляли для языков, мы ее согласовали с разработчиками и с переводчиками. Мы говорим, что у нас есть C#, есть такой-то термин, мы его так используем. Мы спрашивали у разработчиков, какую они используют терминологию и хотели добиться в этом месте синхронизации. У нас есть договоренности, и следующий раз, когда приходим с документацией, разработчики знают, что мы с ними согласовали термины, гайды, мы используем эти шаблоны, учитываем нюансы их использования. А переводчики в свою очередь знают, что мы описываем SDK на C# или Objective-C, значит эта терминология будет соответствовать тому, что описано в гайде.
Гайды были написаны в вики-страницах, поэтому если происходит обновление языков, технологий, протоколов — это все легко добавляется в существующий документ. Идиллия.
Чем раньше вы начинаете унифицировать и договариваться, тем лучше. Лучше, что потом не остается легаси документации, которая написана в другом стиле, который ломает флоу пользователя в документации. Лучше сделать это все раньше.
Привлекать разработчиков. Это те люди, для которых вы пишете документацию. Если вы сами написали себе каких-то гайдов, возможно, им это не понравится. Лучше с ними договориться, чтобы у вас было единое понимание терминологии: что вы пишете в документации, как вы это пишете.
И также договаривайтесь с переводчиками, им это все переводить. Если они будут переводить не так, как привыкли разработчики, опять будут конфликты. (Вот ссылка на фрагмент видео с вопросами и ответами — прим. ред.) Идем дальше.
Юлия:
— Привет, меня зовут Юля, я работаю в Яндексе уже пять лет и занимаюсь документированием API и SDK в группе Андрея. Обычно все рассказывают о хорошем опыте, как все здорово получается. Я расскажу, как мы выбрали не совсем удачную стратегию. На тот момент она казалась удачной, но потом наступила суровая реальность, и нам немного не повезло.
У нас изначально было несколько мобильных SDK, и они были написаны в основном на двух языках: Objective-C и Java. Мы писали к ним документацию вручную. Со временем разрастались классы, протоколы, интерфейсы. Их становилось все больше, и мы поняли, что нужно автоматизировать это дело, посмотрели, какие есть технологии.
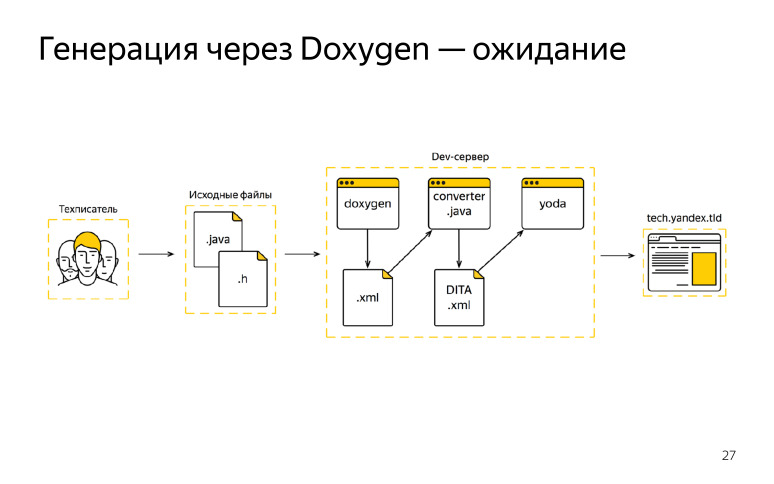
На тот момент нам понравился Doxygen, он удовлетворял нашим потребностям, как нам казалось, и мы его выбрали в качестве единого генератора. И нарисовали такую схему, которую мы рассчитывали получить, хотели по ней работать как-то.
Что у нас было? Техписатель приходил на работу, получал от разработчика исходный код, начинал писать свои комментарии, правки, после этого документация должна была отправляться на наш девсервер, там мы запускали Doxygen, получали XML формат, но под наш стандарт DITA XML он не подходил. Мы об этом знали заранее, написали некий конвертер.
После того, как мы получили выход от Doxygen, мы все это через конвертер пропускали, и получали уже наш формат. Дальше подключался сборщик документации, и мы публиковали все это на внешний домен. Пару итераций нам даже повезло, у нас все получилось, мы обрадовались. Но потом что-то пошло не так. Техписатель все также ходил на работу, получал от разработчика задачки и исходники кода, вносил там свои правки. После этого он пошел на девсервер, запустил Doxygen и случился пожар.
Мы решили разобраться, в чем дело. Тогда мы поняли, что Doxygen не совсем подходит под все языки. Нам пришлось анализировать код, на чем он спотыкался, мы находили конструкции, которые Doxygen не поддерживал и не планировал поддерживать.
Мы решили, раз уж мы работаем в этой схеме, мы напишем скрипт препроцессинга, и будем эти конструкции каким-то образом заменять на то, что Doxygen принимает, или каким-то образом их игнорировать.

Наш цикл стал выглядеть так. Мы получали исходники, заключали их на девсервер, потом подключали скрипт препроцессинга, он все лишнее из кода вырезал, дальше в дело вступал Doxygen, мы получали выходной формат Doxygen, также запускали конвертер, получали наши конечные файлы DITA XML, потом подключался сборщик документации, и мы публиковали нашу документацию на внешний домен. Вроде все выглядит неплохо. Добавили скрипт, что там такого? Изначально было все ничего. В скрипте было три строчки, потом пять, десять, и все это разрослось до сотен строк. Мы поняли, что мы начинаем тратить основное время не на написание документации, а на анализ кода, ищем, что где не пролезает, и просто дописываем скрипт бесконечными регулярками, сидим до безумия и думаем, в чем дело.
Мы поняли, что нужно что-то менять, как-то останавливаться, пока не поздно, и пока наш релизный цикл не завалился до конца.
В качестве примера, как-то так вначале выглядел скрипт препроцессинга, и был безобидным.

Почему мы изначально выбрали этот путь? Почему он показался хорошим?

Один генератор — это здорово, взял его, один раз подключил, настроил и он работает. Казалось, что это неплохой подход. К тому же можно использовать единый синтаксис комментариев сразу для всех языков. Ты написал какой-то гайд, им пользуешься один раз, сразу вставляешь все эти конструкции в код и занимаешься своей работой, пишешь комментарии, а не как-то зацикливаешься на синтаксисе.

Но это оказалось и одним из больших минусов. Наш единый синтаксис не поддержали разработчики, они привыкли пользоваться своими IDE, там есть уже нативные генераторы, и их синтаксис не совпал с нашим. Это было точкой преткновения.
Также Doxygen плохо поддерживал новые функции в языках. У него избирательный подход, поскольку он сам написан на С++, он С-подобные языки в основном поддерживает, а остальные по остаточному принципу. А языки совершенствуются, Doxygen не совсем за ними поспевает, и нам стало совсем неудобно.
Потом случилась совсем беда. К нам пришла новая команда и сказала, что мы на Swift пишем, а Doxygen с ним вообще не дружит. Мы поняли, что все, пора останавливаться и придумывать что-то новое. Потом пришли еще пара команд, и мы поняли, что нашу схему нельзя масштабировать вообще никак. И мы постоянно что-то дописываем, у нас несколько этих скриптов, они живут в разных ветках и всё. Мы поняли, что нужно принять, что нам не повезло, попробовать новые подходы и решения найти. Про них вам расскажет Андрей.
— Мы поняли, что в нашем случае где-то универсальный генератор подошел, но по большей части, когда мы начали все это масштабировать, план не сработал. Придумали классно, договорились со всеми, что давайте будем делать, но не получилось.
В итоге мы начали придумывать новую схему. Она была с нативными генераторами. Что у нас теперь в схеме? Техписатель также приходил на работу (его даже не уволили за то, что он такую штуку сделал), комментировал исходный код, но теперь он комментировал не только Objective-C и Java, а вообще все, что мы можем генерировать.
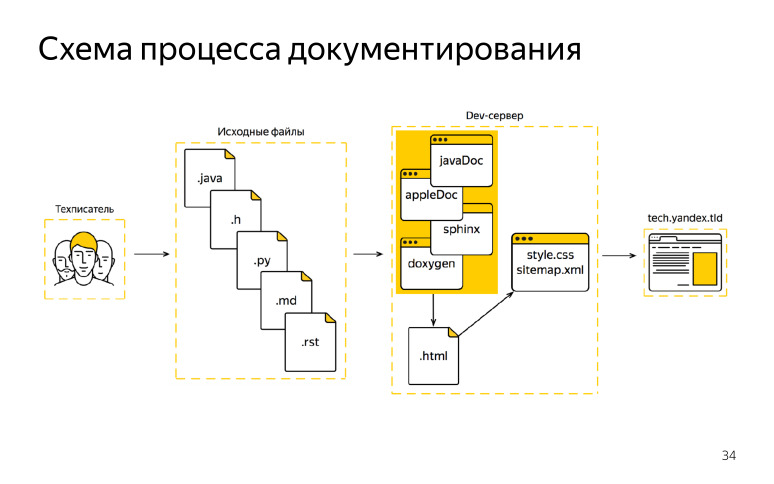
Все это произошло, потому что раньше у нас сервер документации был настроен только на DITA XML, мы хорошо умели его переводить, и вообще, у нас было много аспектов, почему мы использовали XML. Здесь инфраструктуру мы поменяли и научили наш центр документации принимать HTML, и это нам сильно помогло. Теперь мы готовы работать с любым конвертером — JavaDoc, AppleDoc, Jazzy. Любой из них дает нам на выходе HTML, в котором привыкли видеть разработчики документацию. Мы делаем небольшой постпроцессинг HTML, чтобы он влез в нашу верстку, пролез к нам. И зачастую многие генераторы можно настроить еще на этапе генерации, какой выход HTML ты хочешь. Также можно настроить скоуп, что ты хочешь забирать, какие файлы, так и особенности HTML, которые он выдает. И минуя XML сборку, мы сразу публикуем документацию на внешнем домене. Такая схема показалась нам классной.
Мы решили посмотреть все плюсы относительно универсального генератора.
Первый плюс — мы документируем в нативном синтаксисе. Для Doxygen у нас был единый синтаксис, а здесь мы документируем в синтаксисе, который нравится разработчикам. Если Objective-C, у них есть свой синтаксис, для Java свой и т. д. Они нас готовы пускать в свой репозиторий, забирать наши изменения в свою документацию в коде, и эту документацию потом уже можно смотреть в IDE в виде подсказок, в виде IntelliSense, это очень большой поинт, хороший плюс для разработчиков, что они могли интегрировать нашу библиотеку, наш мобильный SDK, и потом в коде видеть документацию на методы, на классы и т. д.
Если мы не хотим нашу документации еще отдавать в паблик, а хотим отдать другой команде внутри Яндексе, если SDK используется, допустим, другой командой, и они хотят себе его интегрировать, мы просто можем отдать им локальный HTML, который был сгенерирован. Он будет не в нашей верстке, а как есть, но там уже есть и дерево, и все, что душе угодно, этой документацией можно пользоваться.
Все нативные генераторы идут в ногу со временем. Если появляется новая языковая конструкция, если что-то изменяется в языке, то большое комьюнити оперативно поддерживает все нововведения. С XML была проблема, что XML на выходе предоставляют не все генераторы. Doxygen умеет, но при этом XML считается форматом побочным. Поэтому коммьюнити поддерживало HTML, а XML поддерживался по остаточному принципу. В новой схеме этой проблемы не будет. Выходит новая функция — мы готовы практически сразу его поддерживать.
И как выяснилось, постпроцессить намного легче, чем препроцессить. Если препроцессинг у нас разросся до 1500 строк код, то постпроцессинг не является таким большим: необходимо немного поправить HTML, посмотреть CSS, или настроить это в генераторе.
Все круто, но надо говориться с остальными участниками процесса, кто участвует в генерации.
Про генерацию прервемся и подискутируем. (Вот ссылка на фрагмент видео с вопросами и ответами — прим. ред.)
Идем дальше, Юля расскажет про организацию процессов, как мы все делали.
— Мы у себя все решили и пошли договариваться со всеми. Для этого мы подготовили свои требования, что бы мы хотели получить. Во-первых, мы хотели бы получить доступ к репозиторию разработчика. Также хотели общие гайды по написанию комментариев в коде и согласованную схему работы с репозиторием, а также независимость от загрузки переводчика. Зачем вообще все эти точки нам нужны? Поговорим про каждую подробнее.
Зачем нужен доступ к репозиторию? Во-первых, это погружение в проект, ты всегда с разработчиками будешь на одной волне, в тренде и вообще описывать продукт изначально легче, когда ты его понимаешь.
Также доступ помогает нам отслеживать какие-то изменения в проекте, если что-то новое вышло или наоборот, поменялось. Доступ к репозиторию нам дает редактирование и написание комментариев в коде.
Что дают общие гайды? Во-первых, единый стиль, писатель сразу берет и смотрит на наши странички, про которые рассказывал Андрей, берет эту структуру и занимается документированием.
Общий гайд позволяет снизить порог входа для нового технического писателя. Писателю не нужно разбираться сильно в нюансах, в синтаксисе, он смотрит, как это нужно оформить, разметку проверяет и именно пишет, обращает внимание на то, что делает этот класс или метод, а не погрязает в синтаксисе комментариев.
Поскольку это все у нас стандартизировано, все это хорошо генерируется и переводится. Есть определенный набор дескрипторов, который мы согласовали с командой разработчиков нашей системы перевода, и когда мы отправляем комментарии на перевод, сразу понятно, что эта конструкция пришла от такого языка, и ее нужно обработать именно таким образом, а не другим.
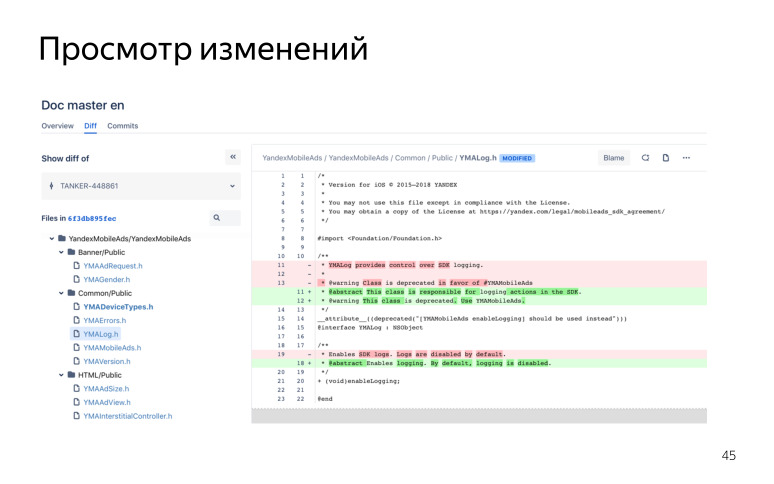
Что дает схема совместной работы? Самое важное — защита исходного кода, у нас всегда есть чистый мастер, и это защищает писателя от непредвиденных ошибок, коммитов, пушей, мержей случайных к разработчикам. Это удобная система ревью. Поскольку мы работаем в гите и используем Bitbucket, у нас это выглядит как-то так. Например, комментирование пулреквеста.

Писатель отправляет пулреквест и сразу туда призывает разработчика, и можно комментировать каждую строчку кода в режиме диалога. В дальнейшем все это сохраняется. Если у вас что-то пошло не так, возник какой-то конфликт, можно всегда обратиться к этому всему, все это хранится в репозитории, вся эта переписка, и понять, где вы отошли от темы, что сделали не так. Все это очень удобно просматривать, изменения, где что поменялось, удалилось, добавилось.
Еще один поинт, который мы хотели получить, это независимость от загрузки переводчика.
Основная наша цель, что релизный цикл у SDK короткий, одна-две недели, а переводчик бывает один на несколько проектов, он просто физически может не успевать переводить. А разработчики пишут обычно на таком разработчетском английском хоть каком-то, и если нужен релиз срочно сегодня и сейчас, то мы уже релизим библиотеку, собираем ее как есть, а потом отдаем на поствычитку редактору или переводчику.
После этого мы решили определиться, у кого какие будут роли и сценарии. Выделили две команды. Первая — разработчик, техписатель и переводчик, в этом случае есть разные писатели с разными скилами.
Есть техписатель, который пишет на русском языке и может переводить с разработческого английского на русский. Но сам на чистом английском не будет писать. Он входит в первую команду.
И есть вторая команда, где разработчик, техписатель и уже редактор, здесь техписатель пишет на английском, ревьюит комментарии от разработчиков, публикует документацию, а дальше редактор периодически его вычитывает.

В первой команде разработчик отдает исходный код, ставит нам задачки и уже ревьюит дальнейшие наши комментарии.
Техписатель переводит с разработческого английского на русский. Если каких-то комментариев не хватает, он их дописывает на русском языке. И дальше отдает это переводчику на перевод.

Второй вариант, когда техписатель пишет на английском, разработчик делает то же самое, он отдает исходный код, ставит задачи и уже ревьюит наши правки. Техписатель здесь делает немного другую работу. Если есть комментарии на английском, он их исправляет на более нормальный английский язык лингвистически, и добавляет еще свои комментарии, если описано что-то не очень хорошо или мало. И потом все свои английские комментарии переводит на русский язык, чтобы была и русская версия документации. Здесь уже редактор идет вместо переводчика, он это вычитывает, и мы обновляем релиз.
Мы работаем с гитом, поэтому там поддерживается несколько вариантов работы.
Это работа с форками и бранчами. У нас есть команды, которые любят один и другой вариант. Но поскольку у нас не диктатура, мы решили поддержать все эти варианты и договориться, как будем их использовать.
У нас получается два сценария, но мы их немного расширили с учетом того, что некоторые техписатели пишут на английском, а некоторые — на русском. Мы рассмотрим схему с форком, когда писатели пишут на русском языке, и схему с бранчем, когда писатели пишут на английском языке.
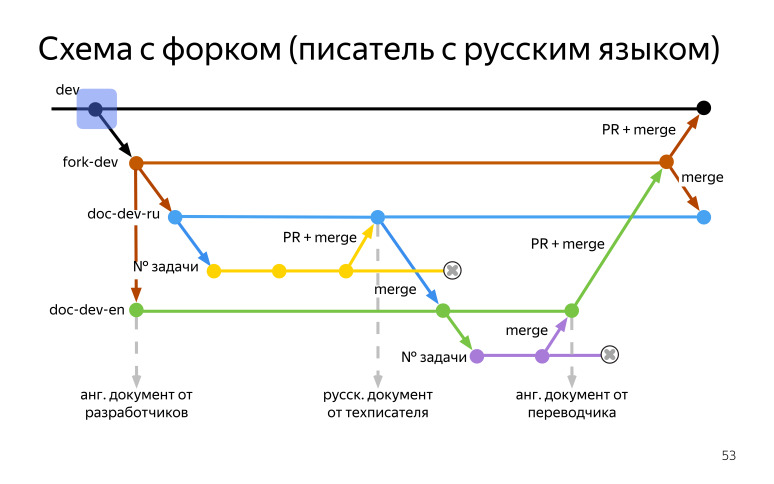
Есть dev от разработчиков, от него мы берем форк (fork-dev) и настраиваем синхронизацию, чтобы к нам релизы приезжали. После этого делаем бранч с английским языком, называем doc-dev-en, кому как нравится. Если есть что генерировать, и если нечего, чтобы была какая-то калька, мы берем и собираем сразу английский вариант документации, что есть из исходников.
После этого от форка (fork-dev) мы откалываем русский бранч (doc-dev-ru) и бранч с номером задачки. Начинаем с ним работать, писать недостающие комментарии или делать какие-то правки. Коммитим это. После того, как мы готовы к окончательному шагу, мы делаем пулреквест в нашу ветку doc-dev-ru, призываем туда разработчиков. Разработчики все это ревьюят, смотрят, мы как-то это обсуждаем с помощью того же пулреквеста, и в конце концов апрувят его.
После этого наступает мерж, мы готовы собрать русский вариант документации. После код с правками мержим в английскую ветку (doc-dev-en). Дальше ставим задачку на переводчика, он это переводит, мы делаем мерж в нашу английскую ветку (doc-dev-en), которая существует всегда, и собираем английскую документацию. После этого мы готовы к решительному шагу, и мы делаем пулреквест в наш форк (fork-dev). Туда мы призываем разработчиков, чтобы посмотреть, что нигде ничего не нарушилось, что мы только комментарии поправили в коде, и больше ничего не сломали. Разработчики это смотрят все, апрувят, и мы делаем мерж. И дальше поднимаемся на совсем высокий уровень, делаем пулреквест в dev к разработчикам. Они смотрят это, проверяют его, также апрувят, и мы делаем мерж.
После этого мы возвращаемся в наш форк (fork-dev), и поскольку писатель пишет на русском, у него основная ветка русская. Нам нужно сделать мерж из нашего форка (fork-dev), в котором английские комментарии, в нашу русскую ветку (doc-dev-en), где русский. Именно на этом этапе у нас будут конфликты, и нам нужно будет принять русские комментарии вместо английских, чтобы при следующем релизе у нас не затерлись наши правки, и только прилетели бы новые комментарии от разработчиков. После этого надо за собой убрать, мы удаляем наши ветки с номерами задач.

Схема с форком, когда писатель пишет на английском, выглядит похоже. Есть dev, будет форк (fork-dev) с автосинхронизацией, русская (doc-dev-ru) и английская (doc-dev-en) ветка. Но теперь писатель будет работать в основном в английской ветке (doc-dev-en), а русская (doc-dev-ru) ветка будет побочной. И здесь мы призываем уже редактора, а не переводчика.
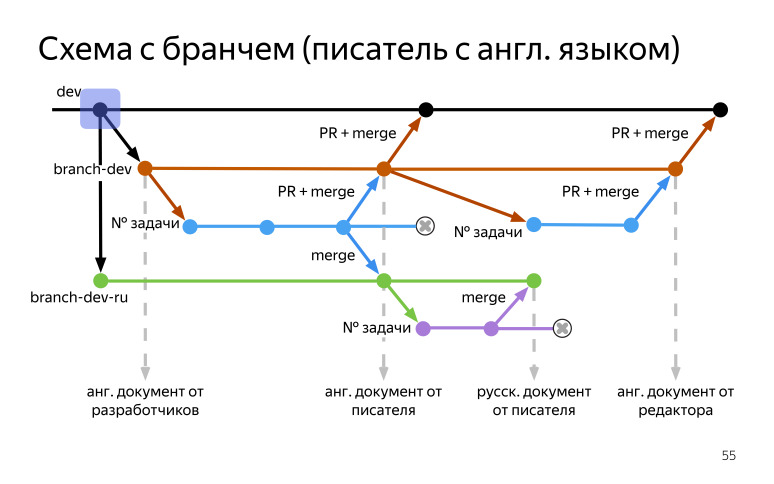
В схеме с бранчем писатель будет писать на английском языке. У нас также есть dev от разработчиков, но теперь мы пользуемся не форком, а бранчем (branch-dev). Мы создаем от него бранч на русском языке (branch-dev-ru), и после этого создаем бранч на английском языке (branch-dev). В нем мы будем работать, потому что мы пишем на английском. Мы собираем документацию из того, что есть. Если там есть — отлично, если нет — будет хотя бы какая-то калька, скелет, чтобы можно было посмотреть, где какой метод используется, какие у него параметры.
От него делаем бранч с номером задачки, в него вносим правки, все это редактируем. После того, как мы готовы, мы отправляем пулреквест в наш основной бранч (branch-dev) и призываем туда разработчика. Разработчик все это дело проверяет, снова ревьюит и апрувит в конце, и мы собираем английскую документацию и публикуем ее.
После этого мы уже готовы сделать пулреквест к разработчикам в dev. Мы его сделали, они посмотрели, что все хорошо, и снова заапрувили его, мы его смержили. И дальше можно поставить себе задачку на перевод.
Мы делаем мерж наших английских комментариев в русскую ветку (branch-dev-ru), после этого их оперативно переводим в бранче с номером задачи, делаем мерж в русскую ветку (branch-dev-ru), чтобы там был перевод. Собираем русскую документацию.
Дальше можно поставить задачу уже на вычитку. Мы перешли в английский бранч (branch-dev), от него сделали бранч с номером задачки и отдали редакторам. Редактор все почитал, поправил, и чтобы обезопасить себя и редактора, мы делаем пулреквест, призываем туда разработчиков, они смотрят, что все хорошо, апрувят его, мы мержим и собираем уже вычитанный английский документ от редактора. После этого делаем пулреквест к разработчикам, они это смотрят, апрувят и делают мерж. И после того, как мы завершили этот релизный цикл, мы удаляем свои ветки с номерами задач.

Схема с бранчем, когда писатель пишет на русском языке, выглядит похожим образом, но здесь приоритетной и основной веткой для работы будет русская, английская будет побочная. Здесь будет переводчик вместо редактора.
Как понять, что кому нужно и что кому больше нравится? Вам нужен форк, если вы используете гит, конечно. Также если вы хотите всегда иметь актуальный мастер. Форк помогает с автосинхронизацией. В основном она всегда проходит безболезненно, но если какие-то серьезные модули затронуты, то потребуется сделать ручной мерж с конфликтами. Но в основном там все хорошо подливается само. Ну и вы не очень любите решать конфликты, тогда это ваш случай.
И вам нужен бранч, если вы также используете гит, вы любите все контролировать, потому что когда придет новый релиз, он сам не подтянется в ваш основной бранч, вам нужно будет его вручную смержить туда.
И вы любите решать конфликты, потому что здесь их может быть больше. Эти схемы со стороны выглядят громоздкими. Но стандартный релизный цикл занимает примерно неделю. И ты сразу привыкаешь быстро к этой схеме работы. И вообще визуализация у нас выглядит примерно так, когда ты работаешь с репозиторием, красиво и похоже на фейерверк.
— Каждая точка — это коммит. Если идет ответвление — это бранчи.
Перейдем к основным выводам по всему докладу. Унификация. Чем раньше начинаете унифицировать, тем лучше. Понятно, если вы договорились заранее, обговорили все на берегу, дальше процесс пойдет намного быстрее, вам не надо будет возвращаться и думать о том, как исправить документацию, как ее привести к вашему новому шаблону и т. д.
Не стоит забывать, что серебряных пуль не бывает. Это касается и генератора. Не всегда универсальный генератор подойдет для всего. То же самое касается и некоторых процессов. Нельзя придумать один процесс, чтобы он легко натянулся на всё что угодно у вас в отделе или группе. Всегда стоит думать, что есть место для расширения. Где-то надо будет отойти вбок, расшириться. Если вы об этом думаете заранее — хорошо. Не забывайте об этом.
Процессы должны быть одинаково удобными для всех. Поэтому у нас не диктатура, мы приходим к разработчикам и говорим: давайте поработаем через бранч. А они говорят, что работают через форки. Мы говорим: хорошо, но давайте договоримся, чтобы мы тоже работали через форки. Надо договариваться так, чтобы у всех задействованных в этом процессе — в локализации, написании кода и документации в коде — была согласованная позиция. Удобно, когда все понимают свою зону ответственности — а не так, что техписатель работает с закрытыми глазами и не видит код или не имеет доступа к репозиторию. На этом всё.
Светлана Каюшина, руководитель отдела документирования и локализации:
— Объемы программного кода в мире в последние годы сильно выросли, продолжают расти, и это влияет на работу технических писателей, которым приходит все больше задач на разработку программной документации и документирования кода. Мы не могли обойти стороной эту тему, посвятили ей целую секцию. Это три взаимосвязанных доклада, посвященных унификации разработки программной документации. Я приглашаю наших специалистов по документированию программных интерфейсов и библиотек Андрея Полякова и Юлию Пивоварову. Передаю им слово.
— Всем привет! Сегодня мы с Юлей расскажем, как в Яндексе у нас появился новый взгляд на документирование API и SDK. Доклад будет состоять из четырех частей, доклад часовой, подискутируем, поговорим.
Поговорим про унификацию API и SDK, о том, как мы к ней пришли, что мы там делали. Мы поделимся опытом использования универсального генератора, одного для всех языков, и расскажем, почему нам это не подошло, какие были подводные камни, и почему мы перешли на генерацию документации нативными генераторами.
В конце расскажем, как были построены наши процессы.
Начнем с унификации. Об унификации задумываются все, когда в команде становится больше, чем два человека: все пишут по-разному, у всех свои подходы, и это логично. Лучше все правила обговорить на берегу, до того, как вы начали писать документацию, но не у всех это получается.
Мы собрались экспертной группой, чтобы проанализировать нашу документацию. Мы это сделали чтобы систематизировать наши подходы. Все пишут по-разному, и давайте договоримся, чтобы писать в одном стиле. Это второй поинт, для чего мы собирались, чтобы постараться сделать документацию единой, чтобы у пользователя был один user experience во всей документации Яндекса, именно технической.
Работа разделилась на три этапа. Мы собрали описание технологий, которые есть в Яндексе, которые мы используем, постарались выделить из них те, которые мы можем как-то унифицировать. А также составили общую структуру типовых документов и шаблоны.
Перейдем к описанию технологий. Мы начали изучать, какие в Яндексе используются технологии. Их так много, что мы устали записывать их в какой-то блокнот, и в итоге выбрали только самые основные, которые чаще всего используются, с которыми чаще всего сталкиваются технические писатели, и начали их описывать.
Что подразумевается под описанием технологий? Мы выделили основные тезисы и сущности каждой технологии. Если мы говорим про языки программирования, то это описание таких сущностей как класс, свойство, интерфейсы и т. д. Если мы говорим про протоколы, то мы описываем методы HTTP, говорим про формат кода ошибок, кода ответов и т. д. Мы составили глоссарий, где содержались следующие вещи: термины на русском, термины на английском, нюансы использования. Например, мы не говорим про какой-то метод SDK, что он ПОЗВОЛЯЕТ что-то делать. Он что-то ДЕЛАЕТ, если программист дергает какую-то ручку, она дает какой-то ответ.
Кроме нюансов в описании также содержались стандартные структуры, стандартные речевые обороты, которые мы используем в документации, чтобы техписатель мог взять конкретную формулировку и использовать ее дальше.
Кроме того, технические писатели часто пишут куски кода, сниппеты, семплы, и для этого мы также описали для каждой технологии свой стайлгайд. Мы обратились к гайдам разработчиков, которые есть в Яндексе. Обратили внимание на оформление код, описание комментариев, отступы и все подобное. Мы это делаем чтобы, когда технический писатель приходит с куском кода или написанным семплом к программисту, программист смотрел суть, а не на то, как это оформлено, и это сокращает время. И когда технический писатель умеет писать по стайлгайдам Яндекса, это очень круто, может, он захочет потом программистом стать. Предыдущий доклад был про различные экспертизы. Вот, например, можно двигаться в программисты.
Для техписателей мы также разработали быстрый старт: как установить среду разработки, когда он знакомится с новой технологией. Например, если у техписателя SDK написан на C#, то он приходит, настраивает среду разработки, читает мануалы, знакомится с терминологией. Также мы оставили ссылки на официальную документацию и RFC, если таковые были. Мы сделали точку входа для технических писателей, и выглядит она примерно так.
Когда технический писатель приходит, он изучает новую технологию и начинает ее документировать.
После того, как мы описали технологии, мы перешли к описанию структуры HTTP API.
У нас много различных HTTP API, и все описаны по-разному. Давайте договоримся и сделаем одинаково!
Мы выделили основные разделы, которые будут в каждом HTTP API:
«Обзор» или «Введение»: для чего нужен этот API, что он позволяет делать, к какому хосту надо обращаться, чтобы получить какой-то ответ.
«Быстрый старт», когда человек проходит по каким-то шагам и получает успешный результат в конце, чтобы понять, как работает этот API.
«Подключение / Авторизация». Для многих API необходим токен авторизации или API-ключ. Это важный поинт, поэтому мы решили, что это обязательная часть всех API.
«Ограничения / Лимиты», когда мы говорим о лимитах на количество запросов или на размер тела запроса и т. д.
«Справочник», референс. Очень большая часть, где содержатся все HTTP ручки, которые пользователь может дернуть и получить какой-то результат.
В итоге у нас было много разных API, описаны они были по-разному, стараемся теперь писать все одинаково. Такой профит.
Углубляясь в справочники, мы поняли, что HTTP ручка практически всегда одинаковая. Ты ее дергаешь, то есть делаешь запрос, сервер возвращает ответ — вуаля. Давайте попробуем это унифицировать. Мы написали некий шаблон, который постарался покрывать все кейсы. Технический писатель берет шаблон, и, если у него PUT-запрос, он оставляет нужные части в шаблоне. Если у него GET-запрос, он использует только те части, которые для необходимы для GET-запроса. Общий шаблон для всех запросов, который можно переиспользовать. Теперь не надо создавать структуру документа с нуля, а можно просто взять готовый шаблон.
В каждой ручке описано, для чего она нужна, что она делает. Есть раздел «Формат запроса», где содержатся path-параметры, query-параметры, все, что приходит в теле запроса, если оно отправляется. Также выделили раздел «Формат ответа»: мы пишем его, если есть тело ответа. Отдельным разделом мы выделили «Коды ответов», потому что ответ от сервера приходит независимо от тела. И оставил раздел «Пример». Если мы поставляем с этим API какой-то SDK, то мы говорим, что этим SDK пользуйтесь так, дергайте такую ручку, вызывайте такой метод. Обычно мы оставляем какой-то пример с cURL, где пользователь просто вставляет свой токен. А если у нас есть тестовый стенд, то просто берет запрос и выполняет его. И получает какой-то результат.
Получается, было много ручек, описаны были по-разному, а теперь хотим привести это все к единой форме.
После того, как мы закончили с HTTP API, мы перешли к мобильным SDK.
Есть общая структура документа, она примерно одинаковая:
— «Введение», где мы говорим, что вот, этот SDK используется для таких целей, интегрируйте себе его для таких целей, для таких ОС он подойдет, у нас такие-то версии есть и т. д.
— «Подключение». В отличие от HTTP API мы не просто говорим, как получить ключ для использования SDK, если он нужен, мы говорим о том, как интегрировать библиотеку себе в проект.
— «Примеры использования». Самый большой по объему раздел. Чаще всего разработчики хотят прийти в документацию и не читать много информации, они хотят скопировать кусок, вставить себе, и у них все заработает. Поэтому эту часть мы посчитали очень важной и выделили ее в обязательный раздел.
— «Справочник», референс, но в отличие от референса HTTP API, мы не можем здесь все унифицировать, так как справочники мы в основном генерируем и дальше в докладе мы об этом поговорим.
— «Релизы», или история изменений, changelog. У мобильных SDK обычно короткий релизный цикл, где-то каждые две недели выпускается новая версия. И лучше бы пользователю говорить о том, что изменилось, стоит ему обновляться или нет.
У API при этом у нас есть как обязательные разделы, которые мы видим, так и разделы, которые мы рекомендуем использовать. Если API часто обновляется, мы говорим, что тогда вставляйте себе тоже историю изменений, что изменилось в API. А зачастую у нас API редко обновляемые, и как обязательный раздел это указывать бессмысленно.
Итак, у нас было много SDK, которые были описаны по-разному, мы постарались превратить примерно в один стиль. Естественно, имеются дополнительные различия, присущие только этому SDK или этому HTTP API. Здесь у нас есть свобода выбора. Мы не говорим, что кроме этих разделов никаких делать нельзя. Конечно, можно, просто перечисленные разделы мы стараемся сделать везде, чтобы было понятно, что, если пользователь перешел в документации к другому SDK, он знает, что будет описано в разделе «Подключение».
Итак, мы придумали шаблоны, составили гайды, какой теперь у нас план действий? Мы решили, что если мы масштабно изменяем API, меняем ручки или меняем SDK, мы берем новые шаблоны, берем новую структуру и начинаем по ней работать.
Если мы пишем документацию с нуля то, конечно, мы опять берем новую структуру, берем новые шаблоны и работаем по ним.
А если API устаревший, редко обновляется или никто его не поддерживает, но он существует, то немного ресурсозатратно его махом переделывать. Просто решили оставить, пока пусть будет так, но затем, когда появятся ресурсы, мы к ним обязательно вернемся, все это сделаем хорошо и красиво.
Какие плюсы от унификации? Они всем должны быть очевидны:
«UX», мы думаем о том, чтобы пользователь в нашей документации чувствовал себя как дома. Он пришел, и знает, что описано в разделах, где ему найти авторизацию, примеры использования, описание ручки. Это здорово.
Для техписателей описание технологии позволяет определить некую точку входа, куда он приходит, и начинает знакомиться с этой технологией, если он ее не знал, начинает разбираться в терминологии, погружаться в нее.
Следующий момент — взаимозаменяемость. Если техписатель ушел в отпуск или просто перестал писать, то другой техписатель при входе в документ знает, как он устроен внутри. Сразу понятно, что описано в подключении, где искать информацию по интеграции SDK. Понять и сделать небольшую правку в документе становится легче. Понятно, у каждого проекта есть своя специфика, нельзя просто прийти и документировать какой-то проект, не зная его полностью. Но при этом структура, то есть навигация по файлам, примерно будет одинаковая.
И, конечно, общая терминология. Ту терминологию, которую мы составляли для языков, мы ее согласовали с разработчиками и с переводчиками. Мы говорим, что у нас есть C#, есть такой-то термин, мы его так используем. Мы спрашивали у разработчиков, какую они используют терминологию и хотели добиться в этом месте синхронизации. У нас есть договоренности, и следующий раз, когда приходим с документацией, разработчики знают, что мы с ними согласовали термины, гайды, мы используем эти шаблоны, учитываем нюансы их использования. А переводчики в свою очередь знают, что мы описываем SDK на C# или Objective-C, значит эта терминология будет соответствовать тому, что описано в гайде.
Гайды были написаны в вики-страницах, поэтому если происходит обновление языков, технологий, протоколов — это все легко добавляется в существующий документ. Идиллия.
Чем раньше вы начинаете унифицировать и договариваться, тем лучше. Лучше, что потом не остается легаси документации, которая написана в другом стиле, который ломает флоу пользователя в документации. Лучше сделать это все раньше.
Привлекать разработчиков. Это те люди, для которых вы пишете документацию. Если вы сами написали себе каких-то гайдов, возможно, им это не понравится. Лучше с ними договориться, чтобы у вас было единое понимание терминологии: что вы пишете в документации, как вы это пишете.
И также договаривайтесь с переводчиками, им это все переводить. Если они будут переводить не так, как привыкли разработчики, опять будут конфликты. (Вот ссылка на фрагмент видео с вопросами и ответами — прим. ред.) Идем дальше.
Юлия:
— Привет, меня зовут Юля, я работаю в Яндексе уже пять лет и занимаюсь документированием API и SDK в группе Андрея. Обычно все рассказывают о хорошем опыте, как все здорово получается. Я расскажу, как мы выбрали не совсем удачную стратегию. На тот момент она казалась удачной, но потом наступила суровая реальность, и нам немного не повезло.
У нас изначально было несколько мобильных SDK, и они были написаны в основном на двух языках: Objective-C и Java. Мы писали к ним документацию вручную. Со временем разрастались классы, протоколы, интерфейсы. Их становилось все больше, и мы поняли, что нужно автоматизировать это дело, посмотрели, какие есть технологии.
На тот момент нам понравился Doxygen, он удовлетворял нашим потребностям, как нам казалось, и мы его выбрали в качестве единого генератора. И нарисовали такую схему, которую мы рассчитывали получить, хотели по ней работать как-то.
Что у нас было? Техписатель приходил на работу, получал от разработчика исходный код, начинал писать свои комментарии, правки, после этого документация должна была отправляться на наш девсервер, там мы запускали Doxygen, получали XML формат, но под наш стандарт DITA XML он не подходил. Мы об этом знали заранее, написали некий конвертер.
После того, как мы получили выход от Doxygen, мы все это через конвертер пропускали, и получали уже наш формат. Дальше подключался сборщик документации, и мы публиковали все это на внешний домен. Пару итераций нам даже повезло, у нас все получилось, мы обрадовались. Но потом что-то пошло не так. Техписатель все также ходил на работу, получал от разработчика задачки и исходники кода, вносил там свои правки. После этого он пошел на девсервер, запустил Doxygen и случился пожар.
Мы решили разобраться, в чем дело. Тогда мы поняли, что Doxygen не совсем подходит под все языки. Нам пришлось анализировать код, на чем он спотыкался, мы находили конструкции, которые Doxygen не поддерживал и не планировал поддерживать.
Мы решили, раз уж мы работаем в этой схеме, мы напишем скрипт препроцессинга, и будем эти конструкции каким-то образом заменять на то, что Doxygen принимает, или каким-то образом их игнорировать.
Наш цикл стал выглядеть так. Мы получали исходники, заключали их на девсервер, потом подключали скрипт препроцессинга, он все лишнее из кода вырезал, дальше в дело вступал Doxygen, мы получали выходной формат Doxygen, также запускали конвертер, получали наши конечные файлы DITA XML, потом подключался сборщик документации, и мы публиковали нашу документацию на внешний домен. Вроде все выглядит неплохо. Добавили скрипт, что там такого? Изначально было все ничего. В скрипте было три строчки, потом пять, десять, и все это разрослось до сотен строк. Мы поняли, что мы начинаем тратить основное время не на написание документации, а на анализ кода, ищем, что где не пролезает, и просто дописываем скрипт бесконечными регулярками, сидим до безумия и думаем, в чем дело.
Мы поняли, что нужно что-то менять, как-то останавливаться, пока не поздно, и пока наш релизный цикл не завалился до конца.
В качестве примера, как-то так вначале выглядел скрипт препроцессинга, и был безобидным.
Почему мы изначально выбрали этот путь? Почему он показался хорошим?
Один генератор — это здорово, взял его, один раз подключил, настроил и он работает. Казалось, что это неплохой подход. К тому же можно использовать единый синтаксис комментариев сразу для всех языков. Ты написал какой-то гайд, им пользуешься один раз, сразу вставляешь все эти конструкции в код и занимаешься своей работой, пишешь комментарии, а не как-то зацикливаешься на синтаксисе.
Но это оказалось и одним из больших минусов. Наш единый синтаксис не поддержали разработчики, они привыкли пользоваться своими IDE, там есть уже нативные генераторы, и их синтаксис не совпал с нашим. Это было точкой преткновения.
Также Doxygen плохо поддерживал новые функции в языках. У него избирательный подход, поскольку он сам написан на С++, он С-подобные языки в основном поддерживает, а остальные по остаточному принципу. А языки совершенствуются, Doxygen не совсем за ними поспевает, и нам стало совсем неудобно.
Потом случилась совсем беда. К нам пришла новая команда и сказала, что мы на Swift пишем, а Doxygen с ним вообще не дружит. Мы поняли, что все, пора останавливаться и придумывать что-то новое. Потом пришли еще пара команд, и мы поняли, что нашу схему нельзя масштабировать вообще никак. И мы постоянно что-то дописываем, у нас несколько этих скриптов, они живут в разных ветках и всё. Мы поняли, что нужно принять, что нам не повезло, попробовать новые подходы и решения найти. Про них вам расскажет Андрей.
— Мы поняли, что в нашем случае где-то универсальный генератор подошел, но по большей части, когда мы начали все это масштабировать, план не сработал. Придумали классно, договорились со всеми, что давайте будем делать, но не получилось.
В итоге мы начали придумывать новую схему. Она была с нативными генераторами. Что у нас теперь в схеме? Техписатель также приходил на работу (его даже не уволили за то, что он такую штуку сделал), комментировал исходный код, но теперь он комментировал не только Objective-C и Java, а вообще все, что мы можем генерировать.
Все это произошло, потому что раньше у нас сервер документации был настроен только на DITA XML, мы хорошо умели его переводить, и вообще, у нас было много аспектов, почему мы использовали XML. Здесь инфраструктуру мы поменяли и научили наш центр документации принимать HTML, и это нам сильно помогло. Теперь мы готовы работать с любым конвертером — JavaDoc, AppleDoc, Jazzy. Любой из них дает нам на выходе HTML, в котором привыкли видеть разработчики документацию. Мы делаем небольшой постпроцессинг HTML, чтобы он влез в нашу верстку, пролез к нам. И зачастую многие генераторы можно настроить еще на этапе генерации, какой выход HTML ты хочешь. Также можно настроить скоуп, что ты хочешь забирать, какие файлы, так и особенности HTML, которые он выдает. И минуя XML сборку, мы сразу публикуем документацию на внешнем домене. Такая схема показалась нам классной.
Мы решили посмотреть все плюсы относительно универсального генератора.
Первый плюс — мы документируем в нативном синтаксисе. Для Doxygen у нас был единый синтаксис, а здесь мы документируем в синтаксисе, который нравится разработчикам. Если Objective-C, у них есть свой синтаксис, для Java свой и т. д. Они нас готовы пускать в свой репозиторий, забирать наши изменения в свою документацию в коде, и эту документацию потом уже можно смотреть в IDE в виде подсказок, в виде IntelliSense, это очень большой поинт, хороший плюс для разработчиков, что они могли интегрировать нашу библиотеку, наш мобильный SDK, и потом в коде видеть документацию на методы, на классы и т. д.
Если мы не хотим нашу документации еще отдавать в паблик, а хотим отдать другой команде внутри Яндексе, если SDK используется, допустим, другой командой, и они хотят себе его интегрировать, мы просто можем отдать им локальный HTML, который был сгенерирован. Он будет не в нашей верстке, а как есть, но там уже есть и дерево, и все, что душе угодно, этой документацией можно пользоваться.
Все нативные генераторы идут в ногу со временем. Если появляется новая языковая конструкция, если что-то изменяется в языке, то большое комьюнити оперативно поддерживает все нововведения. С XML была проблема, что XML на выходе предоставляют не все генераторы. Doxygen умеет, но при этом XML считается форматом побочным. Поэтому коммьюнити поддерживало HTML, а XML поддерживался по остаточному принципу. В новой схеме этой проблемы не будет. Выходит новая функция — мы готовы практически сразу его поддерживать.
И как выяснилось, постпроцессить намного легче, чем препроцессить. Если препроцессинг у нас разросся до 1500 строк код, то постпроцессинг не является таким большим: необходимо немного поправить HTML, посмотреть CSS, или настроить это в генераторе.
Все круто, но надо говориться с остальными участниками процесса, кто участвует в генерации.
Про генерацию прервемся и подискутируем. (Вот ссылка на фрагмент видео с вопросами и ответами — прим. ред.)
Идем дальше, Юля расскажет про организацию процессов, как мы все делали.
— Мы у себя все решили и пошли договариваться со всеми. Для этого мы подготовили свои требования, что бы мы хотели получить. Во-первых, мы хотели бы получить доступ к репозиторию разработчика. Также хотели общие гайды по написанию комментариев в коде и согласованную схему работы с репозиторием, а также независимость от загрузки переводчика. Зачем вообще все эти точки нам нужны? Поговорим про каждую подробнее.
Зачем нужен доступ к репозиторию? Во-первых, это погружение в проект, ты всегда с разработчиками будешь на одной волне, в тренде и вообще описывать продукт изначально легче, когда ты его понимаешь.
Также доступ помогает нам отслеживать какие-то изменения в проекте, если что-то новое вышло или наоборот, поменялось. Доступ к репозиторию нам дает редактирование и написание комментариев в коде.
Что дают общие гайды? Во-первых, единый стиль, писатель сразу берет и смотрит на наши странички, про которые рассказывал Андрей, берет эту структуру и занимается документированием.
Общий гайд позволяет снизить порог входа для нового технического писателя. Писателю не нужно разбираться сильно в нюансах, в синтаксисе, он смотрит, как это нужно оформить, разметку проверяет и именно пишет, обращает внимание на то, что делает этот класс или метод, а не погрязает в синтаксисе комментариев.
Поскольку это все у нас стандартизировано, все это хорошо генерируется и переводится. Есть определенный набор дескрипторов, который мы согласовали с командой разработчиков нашей системы перевода, и когда мы отправляем комментарии на перевод, сразу понятно, что эта конструкция пришла от такого языка, и ее нужно обработать именно таким образом, а не другим.
Что дает схема совместной работы? Самое важное — защита исходного кода, у нас всегда есть чистый мастер, и это защищает писателя от непредвиденных ошибок, коммитов, пушей, мержей случайных к разработчикам. Это удобная система ревью. Поскольку мы работаем в гите и используем Bitbucket, у нас это выглядит как-то так. Например, комментирование пулреквеста.
Писатель отправляет пулреквест и сразу туда призывает разработчика, и можно комментировать каждую строчку кода в режиме диалога. В дальнейшем все это сохраняется. Если у вас что-то пошло не так, возник какой-то конфликт, можно всегда обратиться к этому всему, все это хранится в репозитории, вся эта переписка, и понять, где вы отошли от темы, что сделали не так. Все это очень удобно просматривать, изменения, где что поменялось, удалилось, добавилось.
Еще один поинт, который мы хотели получить, это независимость от загрузки переводчика.
Основная наша цель, что релизный цикл у SDK короткий, одна-две недели, а переводчик бывает один на несколько проектов, он просто физически может не успевать переводить. А разработчики пишут обычно на таком разработчетском английском хоть каком-то, и если нужен релиз срочно сегодня и сейчас, то мы уже релизим библиотеку, собираем ее как есть, а потом отдаем на поствычитку редактору или переводчику.
После этого мы решили определиться, у кого какие будут роли и сценарии. Выделили две команды. Первая — разработчик, техписатель и переводчик, в этом случае есть разные писатели с разными скилами.
Есть техписатель, который пишет на русском языке и может переводить с разработческого английского на русский. Но сам на чистом английском не будет писать. Он входит в первую команду.
И есть вторая команда, где разработчик, техписатель и уже редактор, здесь техписатель пишет на английском, ревьюит комментарии от разработчиков, публикует документацию, а дальше редактор периодически его вычитывает.
В первой команде разработчик отдает исходный код, ставит нам задачки и уже ревьюит дальнейшие наши комментарии.
Техписатель переводит с разработческого английского на русский. Если каких-то комментариев не хватает, он их дописывает на русском языке. И дальше отдает это переводчику на перевод.
Второй вариант, когда техписатель пишет на английском, разработчик делает то же самое, он отдает исходный код, ставит задачи и уже ревьюит наши правки. Техписатель здесь делает немного другую работу. Если есть комментарии на английском, он их исправляет на более нормальный английский язык лингвистически, и добавляет еще свои комментарии, если описано что-то не очень хорошо или мало. И потом все свои английские комментарии переводит на русский язык, чтобы была и русская версия документации. Здесь уже редактор идет вместо переводчика, он это вычитывает, и мы обновляем релиз.
Мы работаем с гитом, поэтому там поддерживается несколько вариантов работы.
Это работа с форками и бранчами. У нас есть команды, которые любят один и другой вариант. Но поскольку у нас не диктатура, мы решили поддержать все эти варианты и договориться, как будем их использовать.
У нас получается два сценария, но мы их немного расширили с учетом того, что некоторые техписатели пишут на английском, а некоторые — на русском. Мы рассмотрим схему с форком, когда писатели пишут на русском языке, и схему с бранчем, когда писатели пишут на английском языке.
Есть dev от разработчиков, от него мы берем форк (fork-dev) и настраиваем синхронизацию, чтобы к нам релизы приезжали. После этого делаем бранч с английским языком, называем doc-dev-en, кому как нравится. Если есть что генерировать, и если нечего, чтобы была какая-то калька, мы берем и собираем сразу английский вариант документации, что есть из исходников.
После этого от форка (fork-dev) мы откалываем русский бранч (doc-dev-ru) и бранч с номером задачки. Начинаем с ним работать, писать недостающие комментарии или делать какие-то правки. Коммитим это. После того, как мы готовы к окончательному шагу, мы делаем пулреквест в нашу ветку doc-dev-ru, призываем туда разработчиков. Разработчики все это ревьюят, смотрят, мы как-то это обсуждаем с помощью того же пулреквеста, и в конце концов апрувят его.
После этого наступает мерж, мы готовы собрать русский вариант документации. После код с правками мержим в английскую ветку (doc-dev-en). Дальше ставим задачку на переводчика, он это переводит, мы делаем мерж в нашу английскую ветку (doc-dev-en), которая существует всегда, и собираем английскую документацию. После этого мы готовы к решительному шагу, и мы делаем пулреквест в наш форк (fork-dev). Туда мы призываем разработчиков, чтобы посмотреть, что нигде ничего не нарушилось, что мы только комментарии поправили в коде, и больше ничего не сломали. Разработчики это смотрят все, апрувят, и мы делаем мерж. И дальше поднимаемся на совсем высокий уровень, делаем пулреквест в dev к разработчикам. Они смотрят это, проверяют его, также апрувят, и мы делаем мерж.
После этого мы возвращаемся в наш форк (fork-dev), и поскольку писатель пишет на русском, у него основная ветка русская. Нам нужно сделать мерж из нашего форка (fork-dev), в котором английские комментарии, в нашу русскую ветку (doc-dev-en), где русский. Именно на этом этапе у нас будут конфликты, и нам нужно будет принять русские комментарии вместо английских, чтобы при следующем релизе у нас не затерлись наши правки, и только прилетели бы новые комментарии от разработчиков. После этого надо за собой убрать, мы удаляем наши ветки с номерами задач.
Схема с форком, когда писатель пишет на английском, выглядит похоже. Есть dev, будет форк (fork-dev) с автосинхронизацией, русская (doc-dev-ru) и английская (doc-dev-en) ветка. Но теперь писатель будет работать в основном в английской ветке (doc-dev-en), а русская (doc-dev-ru) ветка будет побочной. И здесь мы призываем уже редактора, а не переводчика.
В схеме с бранчем писатель будет писать на английском языке. У нас также есть dev от разработчиков, но теперь мы пользуемся не форком, а бранчем (branch-dev). Мы создаем от него бранч на русском языке (branch-dev-ru), и после этого создаем бранч на английском языке (branch-dev). В нем мы будем работать, потому что мы пишем на английском. Мы собираем документацию из того, что есть. Если там есть — отлично, если нет — будет хотя бы какая-то калька, скелет, чтобы можно было посмотреть, где какой метод используется, какие у него параметры.
От него делаем бранч с номером задачки, в него вносим правки, все это редактируем. После того, как мы готовы, мы отправляем пулреквест в наш основной бранч (branch-dev) и призываем туда разработчика. Разработчик все это дело проверяет, снова ревьюит и апрувит в конце, и мы собираем английскую документацию и публикуем ее.
После этого мы уже готовы сделать пулреквест к разработчикам в dev. Мы его сделали, они посмотрели, что все хорошо, и снова заапрувили его, мы его смержили. И дальше можно поставить себе задачку на перевод.
Мы делаем мерж наших английских комментариев в русскую ветку (branch-dev-ru), после этого их оперативно переводим в бранче с номером задачи, делаем мерж в русскую ветку (branch-dev-ru), чтобы там был перевод. Собираем русскую документацию.
Дальше можно поставить задачу уже на вычитку. Мы перешли в английский бранч (branch-dev), от него сделали бранч с номером задачки и отдали редакторам. Редактор все почитал, поправил, и чтобы обезопасить себя и редактора, мы делаем пулреквест, призываем туда разработчиков, они смотрят, что все хорошо, апрувят его, мы мержим и собираем уже вычитанный английский документ от редактора. После этого делаем пулреквест к разработчикам, они это смотрят, апрувят и делают мерж. И после того, как мы завершили этот релизный цикл, мы удаляем свои ветки с номерами задач.
Схема с бранчем, когда писатель пишет на русском языке, выглядит похожим образом, но здесь приоритетной и основной веткой для работы будет русская, английская будет побочная. Здесь будет переводчик вместо редактора.
Как понять, что кому нужно и что кому больше нравится? Вам нужен форк, если вы используете гит, конечно. Также если вы хотите всегда иметь актуальный мастер. Форк помогает с автосинхронизацией. В основном она всегда проходит безболезненно, но если какие-то серьезные модули затронуты, то потребуется сделать ручной мерж с конфликтами. Но в основном там все хорошо подливается само. Ну и вы не очень любите решать конфликты, тогда это ваш случай.
И вам нужен бранч, если вы также используете гит, вы любите все контролировать, потому что когда придет новый релиз, он сам не подтянется в ваш основной бранч, вам нужно будет его вручную смержить туда.
И вы любите решать конфликты, потому что здесь их может быть больше. Эти схемы со стороны выглядят громоздкими. Но стандартный релизный цикл занимает примерно неделю. И ты сразу привыкаешь быстро к этой схеме работы. И вообще визуализация у нас выглядит примерно так, когда ты работаешь с репозиторием, красиво и похоже на фейерверк.
— Каждая точка — это коммит. Если идет ответвление — это бранчи.
Перейдем к основным выводам по всему докладу. Унификация. Чем раньше начинаете унифицировать, тем лучше. Понятно, если вы договорились заранее, обговорили все на берегу, дальше процесс пойдет намного быстрее, вам не надо будет возвращаться и думать о том, как исправить документацию, как ее привести к вашему новому шаблону и т. д.
Не стоит забывать, что серебряных пуль не бывает. Это касается и генератора. Не всегда универсальный генератор подойдет для всего. То же самое касается и некоторых процессов. Нельзя придумать один процесс, чтобы он легко натянулся на всё что угодно у вас в отделе или группе. Всегда стоит думать, что есть место для расширения. Где-то надо будет отойти вбок, расшириться. Если вы об этом думаете заранее — хорошо. Не забывайте об этом.
Процессы должны быть одинаково удобными для всех. Поэтому у нас не диктатура, мы приходим к разработчикам и говорим: давайте поработаем через бранч. А они говорят, что работают через форки. Мы говорим: хорошо, но давайте договоримся, чтобы мы тоже работали через форки. Надо договариваться так, чтобы у всех задействованных в этом процессе — в локализации, написании кода и документации в коде — была согласованная позиция. Удобно, когда все понимают свою зону ответственности — а не так, что техписатель работает с закрытыми глазами и не видит код или не имеет доступа к репозиторию. На этом всё.