
Мои замечательные коллеги из отдела технической поддержки пишут не только вредные, но также и полезные советы и рекомендации по настройке Veeam Backup & Replication. С момента публикации статьи для начинающих пользователей ее автор, Евгений Иванов, продолжая трудиться вместе с румынской командой в Бухаресте, перешел с поста старшего инженера на должность тим-лида. Но технико-литературное поприще Евгений не оставил, за что ему большое спасибо!
Новая статья Жени содержит рекомендации для уже опытных специалистов по работе с Veeam Backup & Replication, перед которыми стоит задача наиболее эффективно использовать ресурсы инфраструктуры резервного копирования. Впрочем, статья будет полезна и тем, кто только планирует установку и настройку нашего продукта.

Оптимизация распределения нагрузки в теплые ламповые времена
За полезными советами добро пожаловать под кат.
Veeam Backup & Replication – это модульное ПО, состоящее из различных компонентов, каждый из которых выполняет специфические функции. Среди этих компонентов – центральный управляющий Veeam backup server, прокси-сервер, репозиторий, WAN-акселератор и другие. Ряд компонентов можно установить на одну машину (разумеется, достаточно мощную), что и делают многие пользователи. Однако у распределенной установки есть свои преимущества, а именно:
Нужно иметь в виду, что распределенные системы будут эффективными только при разумном распределении нагрузки. В противном случае могут возникать «бутылочные горла», перегрузка отдельных компонентов – а это чревато общим падением производительности и замедлением работы.
Чтобы иметь более четкое представление о том, откуда и куда передаются данные в процессе бэкапа, рассмотрим вот такую диаграмму (для примера возьмем инфраструктуру на платформе vSphere):

Как видите, данные передаются из исходного местоположения (source) в целевое (target) с помощью «транспортных агентов» (VeeamAgent.exe), работающих в обоих местоположениях. Так, при работе задания бэкапа происходит следующее:
Таким образом, в передаче данных всегда задействованы 2 компонента, даже если они фактически находятся на одной машине. Это обязательно следует учесть при планировании развертывания решения.
Сначала давайте определимся с понятием «задача». В терминологии Veeam Backup & Replication каждая задача (task) – это обработка 1 диска виртуальной машины. То есть если у вас есть задание резервного копирования (job), включающее в себя 5 ВМ по 2 диска каждая, это означает, что предстоит обработать 10 задач (а если у машины только 1 диск, то 1 задача = 1 ВМ). Veeam Backup & Replication способен вести обработку нескольких задач параллельно, но их количество, разумеется, не бесконечно.
Для каждого прокси-сервера в его свойствах можно указать максимальное количество задач для параллельного выполнения:
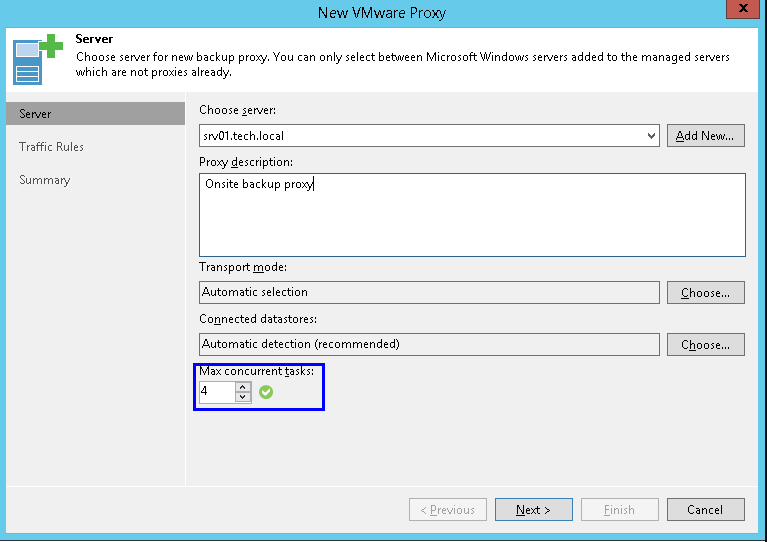
При стандартных операциях резервного копирования аналогичная трактовка будет и для репозитория: одна задача – это передача данных одного виртуального диска. В интерфейсе это выглядит очень похоже:

Здесь мы должны зафиксировать очень важное правило №1: обязательно соблюдать баланс при назначении ресурсов прокси и репозитория и при указании максимального числа задач для параллельной обработки!
Допустим, что у вас есть 3 прокси-сервера, каждый из которых может обрабатывать параллельно 4 задачи (т.е. всего получается 12 виртуальных дисков исходных ВМ). Но репозиторий настроен на параллельную обработку лишь 4 задач (это, кстати, значение по умолчанию). При таких настройках из исходного местоположения в целевое параллельно будут сохраняться данные только для 4 дисков, хотя могли бы и для всех 12. То есть ресурсы будут недозагружены.
Однако, когда речь заходит о создании синтетического полного бэкапа (и аналогичных операциях), то понятие задачи относительно репозитория приобретает несколько иной смысл. Мы помним, что такие операции не задействуют прокси-серверы, а выполняются локально на репозитории (Windows или Linux) либо (в случае CIFS share) с помощью шлюза (gateway).
В таком варианте при построении обычной цепочки бэкапов задача = задание резервного копирования. То есть лимит в 4 задачи для параллельной обработки тут будет означать, что на репозитории одновременно могут создаваться синтетические резервные копии для 4 заданий бэкапа.
При построении же цепочки бэкапов, разложенных в соответствии с исходными ВМ (т.н. «помашинное» хранение — per-VM), задача = 1 ВМ. То есть лимит в 4 задачи для параллельной обработки тут будет означать, что на репозитории одновременно могут генериться 4 файла VBK для 4 виртуальных машин.
Таким образом, мы приходим к правилу №2: В зависимости от настроек резервного копирования одно и то же число задач может означать совершенно разную нагрузку на репозиторий. Поэтому при планировании ресурсов непременно нужно проверить эти самые настройки: режим резервного копирования, расписание заданий, способ организации цепочек резервных копий.
Примечание: В отличие от настроек прокси-сервера, для репозитория можно отключить ограничение на количество задач. В этом случае репозиторий будет принимать все данные, поступающие от прокси-серверов. Но это лишь кажущаяся свобода от ограничений, поскольку есть риск перегрузки репозитория и сбоев в работе заданий бэкапа. Поэтому мы настоятельно не рекомендуем отказываться от данного лимита.
Допустим, у вас есть задание резервного копирования, включающее в себя достаточно большое количество ВМ с общим количеством виртуальных дисков в 100 штук. При этом репозиторий настроен на хранение цепочек резервных копий «помашинно» (per-VM). Настройки же параллельной обработки таковы: для прокси – 10 дисков одновременно, а для репозитория – ограничений нет. Во время инкрементального бэкапа нагрузка на репозиторий будет ограничена из-за настроек прокси, и таким образом баланс будет соблюден. Но затем наступает момент создания синтетического полного бэкапа. Такой бэкап не задействует прокси, и все операции по созданию «синтетики» проходят исключительно на репозитории. Поскольку ограничение на параллельную обработку задач для репозитория отсутствует, то сервер репозитория постарается обработать одновременно всю сотню. Это потребует значительного напряжения ресурсов и, скорее всего, приведет к чрезмерной нагрузке.
Если вы работаете с репозиторием на базе сервера Windows или Linux, то «целевой» агент стартует непосредственно на этом сервере. Однако если вы используете в качестве репозитория папку общего доступа CIFS (CIFS share), то «целевой» агент стартует на специально предназначенной для этого машине — это т.н. «шлюз» (gateway), на который будет поступать входящий поток данных от агента на стороне исходной ВМ. «Целевой» агент будет принимать эти данные и затем отправлять блоки данных на шару CIFS. Эту вспомогательную машину необходимо разместить как можно ближе к машине, предоставляющей папки общего доступа по SMB – это особенно важно для сценариев, задействующих соединение через WAN.
Правило №3: Не следует размещать вспомогательную машину (прокси\шлюз) на одной площадке, а папку общего доступа CIFS share – на другой площадке (в том числе на облачной)— в противном случае вас ждут постоянные проблемы с сетью.
К шлюзам также можно применить все вышеперечисленные соображения баланса нагрузки на систему. Кроме того, нужно иметь в виду, что у шлюза есть 2 дополнительные настройки: сервер для него можно назначить явным образом или выбирать автоматически:

В принципе, в качестве такого шлюза можно использовать любой сервер Windows, включенный в инфраструктуру Veeam backup. В зависимости от сценария развертывания вам может подойти одна из опций:
«Целевой» агент стартует на прокси-сервере, выполняющем резервное копирование.
При создании синтетических резервных копий прокси-серверы не используются, и тут машина для запуска «целевого» агента выбирается так: берется вспомогательный mount server (маунт-сервер, на который монтируются файлы, например, при операциях восстановления), ассоциированный с репозиторием, и на нем стартует агент. Если маунт-сервер по какой-то причине недоступен, то есть возможность переключиться на север Veeam backup. Как вы понимаете, распределения нагрузки в таком варианте не будет.
Поэтому повторюсь: (ВАЖНО!) не рекомендуется для подобных сценариев снимать ограничение на число параллельно обрабатываемых задач, ибо при выполнении операций с «синтетикой» это может привести к колоссальной перегрузке маунт-сервера или даже сервера Veeam backup.
Масштабируемый репозиторий. SOBR представляет собой набор стандартных репозиториев (тут они называются «extents»). Если уж вы используете SOBR, то в задании бэкапа указываете именно его, а не extent. На extent-ах же можно использовать кое-какие настройки, например, распределение нагрузки.
Все основные принципы, работающие для обычных репозиториев, работают и для SOBR. Для оптимального использования ресурсов можно посоветовать настроить SOBR с «помашинным» хранением бэкапов (per-VM – эта опция стоит по умолчанию), с политикой размещения “Performance” («оптимизировать для лучшей производительности») и распределением цепочек по репозиториям-extent-ам.
Перенос бэкапов (backup copy). Здесь «исходные» агенты (source agents) будут работать на исходном репозитории. Все, о чем говорилось выше, применимо и для исходных репозиториев (за исключением того факта, что в случае задания переноса Backup Copy Job операции с «синтетикой» на исходном репозитории не выполняются).
Примечание: Если исходный репозиторий представляет собой CIFS share, то «исходный» агент стартует на соответствующем маунт-сервере (с возможностью переключения на Veeam backup server).
Устройства со встроенной дедупликацией. Для СХД DataDomain, StoreOnce (а в будущем, вероятно, и для других), для которых настроена интеграция с Veeam, применимы те же соображения, что и для CIFS share. Для репозитория на StoreOnce с дедупликацией на стороне источника (режим Low Bandwidth) теряет актуальность лишь требование размещать шлюз как можно ближе к репозиторию — шлюз на одной площадке можно настроить на отправку данных в StoreOnce на другой площадке через WAN.
Предпочтительный прокси-сервер. Эта фича появилась, как вы помните, в релизе 9.5, и отвечает за поддержку «списка приоритетов прокси», которого программа будет придерживаться при работе с конкретным репозиторием.
Если прокси из этого списка недоступен, то задание будет работать с любым другим доступным. Однако если доступ к прокси есть, но прокси-сервер не имеет свободных слотов для процессинга задачи, то задание резервного копирования будет приостановлено в ожидании таковых. Поэтому нужно использовать данную фичу очень аккуратно (а не в стиле «включил и забыл») – у нас были пользователи, которые таким образом «подвесили» задания бэкапа. Подробнее про фичу можно почитать тут (на англ. языке).
Неважно, устанавливаете ли вы Veeam Backup & Replication впервые или являетесь его давним пользователем – хочется верить, что в этой статье вы найдете полезную для себя информацию и с ее помощью оптимизируете работу инфраструктуры резервного копирования или даже устраните потенциальные риски потери данных. Вот еще несколько полезных ссылок:
Новая статья Жени содержит рекомендации для уже опытных специалистов по работе с Veeam Backup & Replication, перед которыми стоит задача наиболее эффективно использовать ресурсы инфраструктуры резервного копирования. Впрочем, статья будет полезна и тем, кто только планирует установку и настройку нашего продукта.
Оптимизация распределения нагрузки в теплые ламповые времена
За полезными советами добро пожаловать под кат.
О плюсах распределенной установки
Veeam Backup & Replication – это модульное ПО, состоящее из различных компонентов, каждый из которых выполняет специфические функции. Среди этих компонентов – центральный управляющий Veeam backup server, прокси-сервер, репозиторий, WAN-акселератор и другие. Ряд компонентов можно установить на одну машину (разумеется, достаточно мощную), что и делают многие пользователи. Однако у распределенной установки есть свои преимущества, а именно:
- Для компаний, имеющих сеть филиалов, появляется возможность установить необходимые компоненты локально в этих филиалах. Это помогает оптимизировать трафик, организуя большую часть его опять-таки локально.
- По мере роста инфраструктуры возникает необходимость масштабировать решение для резервного копирования. Если бэкап выполняется дольше (растет «окно резервного копирования»), можно установить дополнительный прокси-сервер. Если нужно увеличить емкость репозитория резервных копий, можно настроить масштабируемый репозиторий (scale-out backup repository) и добавлять новые extents по мере необходимости.
- Для некоторых компонентов можно обеспечить постоянную доступность (High Availability) – например, если у вас развернуто несколько прокси-серверов и один из них внезапно выключится, то другие продолжат работу, и резервное копирование не пострадает.
Нужно иметь в виду, что распределенные системы будут эффективными только при разумном распределении нагрузки. В противном случае могут возникать «бутылочные горла», перегрузка отдельных компонентов – а это чревато общим падением производительности и замедлением работы.
Как передаются данные?
Чтобы иметь более четкое представление о том, откуда и куда передаются данные в процессе бэкапа, рассмотрим вот такую диаграмму (для примера возьмем инфраструктуру на платформе vSphere):
Как видите, данные передаются из исходного местоположения (source) в целевое (target) с помощью «транспортных агентов» (VeeamAgent.exe), работающих в обоих местоположениях. Так, при работе задания бэкапа происходит следующее:
- «Исходный» транспортный агент работает на прокси-сервере; он читает данные с datastore, выполняет сжатие и дедупликацию и отправляет данные в таком виде «целевому» транспортному агенту.
- «Целевой» транспортный агент работает непосредственно на репозитории (Windows/Linux) или на шлюзе (gateway server), если используется CIFS share. Этот агент, в свою очередь, также выполняет дедупликацию на своей стороне и сохраняет данные в файл резервной копии (.VBK, .VIB и др.).
Таким образом, в передаче данных всегда задействованы 2 компонента, даже если они фактически находятся на одной машине. Это обязательно следует учесть при планировании развертывания решения.
Распределение нагрузки между прокси-сервером и репозиторием
Сначала давайте определимся с понятием «задача». В терминологии Veeam Backup & Replication каждая задача (task) – это обработка 1 диска виртуальной машины. То есть если у вас есть задание резервного копирования (job), включающее в себя 5 ВМ по 2 диска каждая, это означает, что предстоит обработать 10 задач (а если у машины только 1 диск, то 1 задача = 1 ВМ). Veeam Backup & Replication способен вести обработку нескольких задач параллельно, но их количество, разумеется, не бесконечно.
Для каждого прокси-сервера в его свойствах можно указать максимальное количество задач для параллельного выполнения:
При стандартных операциях резервного копирования аналогичная трактовка будет и для репозитория: одна задача – это передача данных одного виртуального диска. В интерфейсе это выглядит очень похоже:
Здесь мы должны зафиксировать очень важное правило №1: обязательно соблюдать баланс при назначении ресурсов прокси и репозитория и при указании максимального числа задач для параллельной обработки!
Пример
Допустим, что у вас есть 3 прокси-сервера, каждый из которых может обрабатывать параллельно 4 задачи (т.е. всего получается 12 виртуальных дисков исходных ВМ). Но репозиторий настроен на параллельную обработку лишь 4 задач (это, кстати, значение по умолчанию). При таких настройках из исходного местоположения в целевое параллельно будут сохраняться данные только для 4 дисков, хотя могли бы и для всех 12. То есть ресурсы будут недозагружены.
Однако, когда речь заходит о создании синтетического полного бэкапа (и аналогичных операциях), то понятие задачи относительно репозитория приобретает несколько иной смысл. Мы помним, что такие операции не задействуют прокси-серверы, а выполняются локально на репозитории (Windows или Linux) либо (в случае CIFS share) с помощью шлюза (gateway).
В таком варианте при построении обычной цепочки бэкапов задача = задание резервного копирования. То есть лимит в 4 задачи для параллельной обработки тут будет означать, что на репозитории одновременно могут создаваться синтетические резервные копии для 4 заданий бэкапа.
При построении же цепочки бэкапов, разложенных в соответствии с исходными ВМ (т.н. «помашинное» хранение — per-VM), задача = 1 ВМ. То есть лимит в 4 задачи для параллельной обработки тут будет означать, что на репозитории одновременно могут генериться 4 файла VBK для 4 виртуальных машин.
Таким образом, мы приходим к правилу №2: В зависимости от настроек резервного копирования одно и то же число задач может означать совершенно разную нагрузку на репозиторий. Поэтому при планировании ресурсов непременно нужно проверить эти самые настройки: режим резервного копирования, расписание заданий, способ организации цепочек резервных копий.
Примечание: В отличие от настроек прокси-сервера, для репозитория можно отключить ограничение на количество задач. В этом случае репозиторий будет принимать все данные, поступающие от прокси-серверов. Но это лишь кажущаяся свобода от ограничений, поскольку есть риск перегрузки репозитория и сбоев в работе заданий бэкапа. Поэтому мы настоятельно не рекомендуем отказываться от данного лимита.
Еще пример
Допустим, у вас есть задание резервного копирования, включающее в себя достаточно большое количество ВМ с общим количеством виртуальных дисков в 100 штук. При этом репозиторий настроен на хранение цепочек резервных копий «помашинно» (per-VM). Настройки же параллельной обработки таковы: для прокси – 10 дисков одновременно, а для репозитория – ограничений нет. Во время инкрементального бэкапа нагрузка на репозиторий будет ограничена из-за настроек прокси, и таким образом баланс будет соблюден. Но затем наступает момент создания синтетического полного бэкапа. Такой бэкап не задействует прокси, и все операции по созданию «синтетики» проходят исключительно на репозитории. Поскольку ограничение на параллельную обработку задач для репозитория отсутствует, то сервер репозитория постарается обработать одновременно всю сотню. Это потребует значительного напряжения ресурсов и, скорее всего, приведет к чрезмерной нагрузке.
Особенности использования CIFS share в качестве репозитория
Если вы работаете с репозиторием на базе сервера Windows или Linux, то «целевой» агент стартует непосредственно на этом сервере. Однако если вы используете в качестве репозитория папку общего доступа CIFS (CIFS share), то «целевой» агент стартует на специально предназначенной для этого машине — это т.н. «шлюз» (gateway), на который будет поступать входящий поток данных от агента на стороне исходной ВМ. «Целевой» агент будет принимать эти данные и затем отправлять блоки данных на шару CIFS. Эту вспомогательную машину необходимо разместить как можно ближе к машине, предоставляющей папки общего доступа по SMB – это особенно важно для сценариев, задействующих соединение через WAN.
Правило №3: Не следует размещать вспомогательную машину (прокси\шлюз) на одной площадке, а папку общего доступа CIFS share – на другой площадке (в том числе на облачной)— в противном случае вас ждут постоянные проблемы с сетью.
К шлюзам также можно применить все вышеперечисленные соображения баланса нагрузки на систему. Кроме того, нужно иметь в виду, что у шлюза есть 2 дополнительные настройки: сервер для него можно назначить явным образом или выбирать автоматически:
В принципе, в качестве такого шлюза можно использовать любой сервер Windows, включенный в инфраструктуру Veeam backup. В зависимости от сценария развертывания вам может подойти одна из опций:
- Явно указанный сервер — это, конечно, многое упрощает, ведь вы точно будете знать, на какой именно машине работает «целевой» агент. Такой вариант рекомендуется, в частности, для случаев, когда доступ к шаре разрешен только с определенных серверов, а также для сценариев с распределенной инфраструктурой — вы же наверняка захотите, как разумные люди, использовать агента на машине, расположенной поблизости от файл-сервера с целевой шарой.
- Автоматически выбираемый сервер (опция Automatic selection). Тут дело принимает интересный оборот: если вы используете несколько прокси-серверов, то выбор этой опции, оказывается, приводит к тому, что программа задействует более одного шлюза, распределяя нагрузку. Замечу, что «автоматически» не значит «произвольным образом» — здесь применяются вполне конкретные правила выбора.
Как это работает?
«Целевой» агент стартует на прокси-сервере, выполняющем резервное копирование.
- В случае обычной цепочки бэкапов логика такая: если имеется несколько заданий, выполняемых одновременно, каждое своим прокси-сервером, то можно запустить несколько «целевых» агентов. Однако внутри одного задания (job) логика другая: даже если ВМ, содержащиеся в нем, обрабатываются разными прокси, «целевой» агент будет запущен только на одном – на том, который первым начнет работу.
- В случае «помашинной» цепочки бэкапов для каждой ВМ запускается отдельный «целевой» агент. Таким образом, даже внутри одного задания происходит распределение нагрузки.
При создании синтетических резервных копий прокси-серверы не используются, и тут машина для запуска «целевого» агента выбирается так: берется вспомогательный mount server (маунт-сервер, на который монтируются файлы, например, при операциях восстановления), ассоциированный с репозиторием, и на нем стартует агент. Если маунт-сервер по какой-то причине недоступен, то есть возможность переключиться на север Veeam backup. Как вы понимаете, распределения нагрузки в таком варианте не будет.
Поэтому повторюсь: (ВАЖНО!) не рекомендуется для подобных сценариев снимать ограничение на число параллельно обрабатываемых задач, ибо при выполнении операций с «синтетикой» это может привести к колоссальной перегрузке маунт-сервера или даже сервера Veeam backup.
Дополнительные возможности
Масштабируемый репозиторий. SOBR представляет собой набор стандартных репозиториев (тут они называются «extents»). Если уж вы используете SOBR, то в задании бэкапа указываете именно его, а не extent. На extent-ах же можно использовать кое-какие настройки, например, распределение нагрузки.
Все основные принципы, работающие для обычных репозиториев, работают и для SOBR. Для оптимального использования ресурсов можно посоветовать настроить SOBR с «помашинным» хранением бэкапов (per-VM – эта опция стоит по умолчанию), с политикой размещения “Performance” («оптимизировать для лучшей производительности») и распределением цепочек по репозиториям-extent-ам.
Перенос бэкапов (backup copy). Здесь «исходные» агенты (source agents) будут работать на исходном репозитории. Все, о чем говорилось выше, применимо и для исходных репозиториев (за исключением того факта, что в случае задания переноса Backup Copy Job операции с «синтетикой» на исходном репозитории не выполняются).
Примечание: Если исходный репозиторий представляет собой CIFS share, то «исходный» агент стартует на соответствующем маунт-сервере (с возможностью переключения на Veeam backup server).
Устройства со встроенной дедупликацией. Для СХД DataDomain, StoreOnce (а в будущем, вероятно, и для других), для которых настроена интеграция с Veeam, применимы те же соображения, что и для CIFS share. Для репозитория на StoreOnce с дедупликацией на стороне источника (режим Low Bandwidth) теряет актуальность лишь требование размещать шлюз как можно ближе к репозиторию — шлюз на одной площадке можно настроить на отправку данных в StoreOnce на другой площадке через WAN.
Предпочтительный прокси-сервер. Эта фича появилась, как вы помните, в релизе 9.5, и отвечает за поддержку «списка приоритетов прокси», которого программа будет придерживаться при работе с конкретным репозиторием.
Если прокси из этого списка недоступен, то задание будет работать с любым другим доступным. Однако если доступ к прокси есть, но прокси-сервер не имеет свободных слотов для процессинга задачи, то задание резервного копирования будет приостановлено в ожидании таковых. Поэтому нужно использовать данную фичу очень аккуратно (а не в стиле «включил и забыл») – у нас были пользователи, которые таким образом «подвесили» задания бэкапа. Подробнее про фичу можно почитать тут (на англ. языке).
В заключение
Неважно, устанавливаете ли вы Veeam Backup & Replication впервые или являетесь его давним пользователем – хочется верить, что в этой статье вы найдете полезную для себя информацию и с ее помощью оптимизируете работу инфраструктуры резервного копирования или даже устраните потенциальные риски потери данных. Вот еще несколько полезных ссылок: