
Поддержка огромной кодовой базы с одновременным обеспечением высокой производительности большого числа разработчиков — это серьезный вызов. В течение последних 5 лет в Яндексе идет разработка особой системы непрерывной интеграции. В данной статье мы расскажем про масштаб кодовой базы Яндекса, про перенос разработки в единый репозиторий с trunk-based подходом к разработке, про то, какие задачи должна решать система непрерывной интеграции для эффективной работы в таких условиях.

Много лет назад в Яндексе никаких особенных правил в разработке сервисов не было: каждый отдел мог использовать любые языки, любые технологии, любые системы деплоя. И как показала практика, такая свобода не всегда помогала двигаться вперед быстрее. В то время для решения одних и тех же задач часто существовало несколько собственных или open-source разработок. С ростом компании такая экосистема работала всё хуже. При этом мы хотели остаться одним большим Яндексом, а не разделиться на множество независимых компаний, потому что это дает массу преимуществ: много людей делают одни похожие задачи, результаты их труда можно использовать повторно. Начиная от разнообразных структур данных, типа распределённых хеш-таблиц и lock-free очередей, и заканчивая множеством разного специализированного кода, который мы написали за 20 лет.
Многие задачи, которые мы решаем, не решают в open-source мире. Там нет MapReduce, хорошо работающего на наших объёмах (5000+ серверов) и наших задачах, там нет трекера задач, который способен обрабатывать все наши десятки миллионов тикетов. Это и привлекательно в Яндексе — можно делать по-настоящему большие вещи.
Но у нас серьёзно падает эффективность, когда мы решаем заново те же задачи, переделываем готовые решения, затрудняя интеграции между компонентами. Хорошо и удобно всё делать только для себя в своём уголке, можно не думать о других до поры до времени. Но как только сервис станет достаточно заметным, у него появятся зависимости. Только кажется, что различные сервисы слабо зависят друг от друга, на самом деле – связей между различными частями компании очень много. Многие сервисы доступны через приложение Яндекса / Браузер / и т.д., либо встраиваются друг в друга. Например, Алиса появляется в Браузере, с помощью Алисы можно заказать Такси. Все мы используем общие компоненты: YT, YQL, Нирвана.
В старой модели разработки были существенные проблемы. Из-за наличия множества репозиториев обычному разработчику, тем более новичку, трудно узнать:
- где лежит компонент?
- как он работает: нет возможности "взять и почитать"
- кто его сейчас разрабатывает и поддерживает?
- как его начать использовать?
В результате возникала проблема взаимного использования компонентов. Компоненты почти не могли использовать другие компоненты, потому что представляли друг для друга "чёрные ящики". Это негативно влияло на компанию, так как компоненты не только не переиспользовались, но и часто не улучшались. Многие компоненты дублировались, сильно рос объем кода, который приходилось поддерживать. Мы в целом двигались медленнее, чем могли бы.
Единый репозиторий и инфраструктура
5 лет назад мы начали проект по переносу разработки в единый репозиторий, с едиными системами сборки, тестирования, деплоя и мониторинга.
Основная цель, которую мы хотели достичь — убрать помехи, препятствующие интеграции чужого кода. Система должна обеспечивать простой доступ к готовому работающему коду, понятную схему его подключения и использования, собираемость: проекты всегда собираются (и проходят тесты).
В результате проекта возник единый для компании стек инфраструктурных технологий: хранение исходного кода, система code review, система сборки, система непрерывной интеграции, деплой, мониторинг.
Сейчас большая часть исходного кода проектов Яндекса хранится в едином репозитории, либо находится в процессе переезда в него:
- над проектами трудятся более 2000 разработчиков.
- более 50 000 проектов и библиотек.
- размер репозитория превышает 25 Гб.
- в репозиторий уже совершено более 3 000 000 коммитов.
Плюсы для компании:
- любой проект из репозитория получает готовую инфраструктуру:
- система для просмотра и навигации по исходному коду и система code-review.
- система сборки и распределенная сборка. Это отдельная большая тема, и мы обязательно ее раскроем в следующих статьях.
- система непрерывной интеграции.
- деплой, интеграция с системой мониторинга.
- совместное использование кода, активное взаимодействие команд.
- весь код общий, вы можете прийти в другой проект и сделать там нужные вам изменения. Это особенно важно в большой компании, поскольку у другой команды, от которой вам что-то надо, может не быть ресурсов. С общим кодом у вас появляется возможность сделать часть работы самим и «помочь случиться» нужным вам изменениям.
- появляется возможность проводить глобальный рефакторинг. Вам не надо поддерживать старые версии вашего API или библиотеки, вы можете изменить их и поменять те места, где они используются в других проектах.
- код становится менее «разнообразным». У вас есть набор способов, чтобы решать проблемы, и нет необходимости добавлять еще один способ, делающий примерно то же самое, но с небольшими отличиями.
- в соседнем с вами проекте, скорее всего, не будет совсем экзотичных языков и библиотек.
Следует также понимать, что у такой модели разработки есть недостатки, которые нужно учитывать:
- общий репозиторий требует отдельной особой инфраструктуры.
- нужной вам библиотеки может не быть в репозитории, но она есть в open-source. Есть затраты на ее добавление и обновление. Сильно зависит от языка и библиотеки, где-то почти бесплатно, где-то очень дорого.
- нужно постоянно работать над "здоровьем" кода. Это включает в себя как минимум борьбу с лишними зависимостями и с "мертвым" кодом.
Наш подход к общему репозиторию накладывает общие правила, которые всем нужно соблюдать. В случае использования единого репозитория накладываются ограничения на используемые языки, библиотеки, способы деплоя. Но зато в соседнем проекте всё будет так же или очень похоже на ваш, и вы там даже сможете что-нибудь исправить.
К модели общего репозитория тяготеют все большие компании. Монолитный репозиторий — большая и хорошо изученная и обсуждаемая тема, поэтому сейчас мы не будем в нее сильно углубляться. Если вам хочется узнать больше, то в конце статьи вы найдете несколько полезных ссылок, более подробно раскрывающих данную тему.
Условия, в которых работает система непрерывной интеграции
Разработка ведется по модели Trunk based development. Большинство пользователей работает с HEAD или наиболее свежей копией репозитория, полученной из основной ветви, называемой trunk, в которой идет разработка. Фиксация изменений в репозитории осуществляются последовательно. Сразу после коммита новый код виден и может использоваться всеми разработчиками. Разработка в отдельных ветках не приветствуется, хотя ветки могут использоваться для релизов.
Проекты зависят по исходному коду. Проекты и библиотеки образуют сложный граф зависимостей. А это означает то, что изменения, сделанные в одном проекте, потенциально влияют на весь остальной репозиторий.
В репозиторий идет большой поток коммитов:
- более 2000 коммитов в день.
- до 10 изменений в минуту в часы пик.
В кодовой базе содержится более 500 000 целей сборки и тестов.
Без особой системы непрерывной интеграции в таких условиях было бы очень сложно быстро двигаться вперед.
Система непрерывной интеграции
Система непрерывной интеграции осуществляет запуск сборок и тестов на каждое изменение:
- Прекоммитные проверки. Позволяют проверить код до коммита и избежать поломки тестов в trunk. Сборки и тесты при этом запускаются поверх HEAD. В данный момент прекоммитные проверки запускаются добровольно. Для особо важных проектов прекоммитные проверки обязательны.
- Посткоммитные проверки после коммита в репозиторий.
Сборки и тесты запускаются параллельно на больших кластерах, состоящих из сотен серверов. Сборки и тесты запускаются на разных платформах. Под основной платформой (linux) собираются все проекты и запускаются все тесты, под остальными платформами — некоторое подмножество, настраиваемое пользователями.
После получения и анализа результатов сборок и прогона тестов пользователь получает обратную связь, например, если изменения ломают какие-либо тесты.

В случае обнаружения новых поломок сборки или тестов мы отправляем уведомление владельцам тестов и автору изменений. Система также хранит и отображает результаты проверок в специальном интерфейсе. Веб-интерфейс системы интеграции отображает прогресс и результат выполнения проверки с разбиением по типам тестов. Экран с результатами проверки сейчас может выглядеть так:
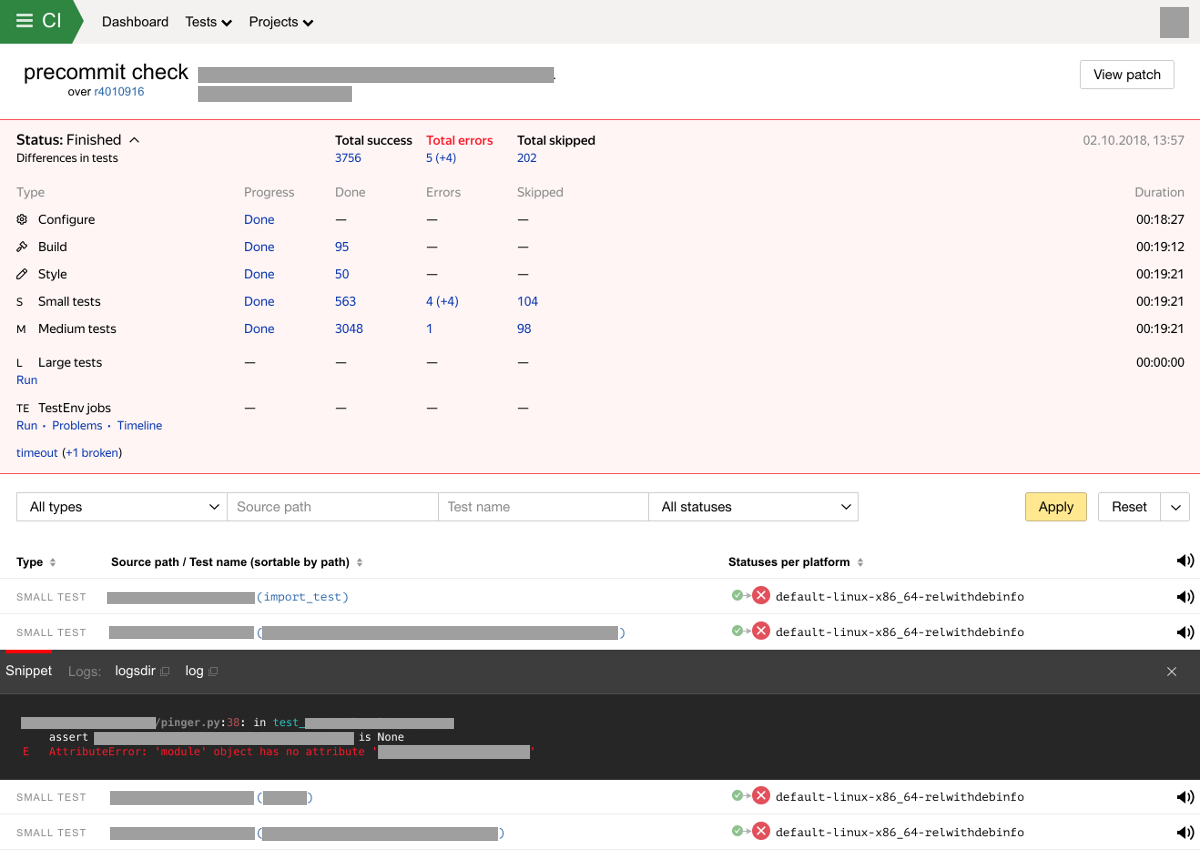
Особенности и возможности системы непрерывной интеграции
Решая различные проблемы, стоящие перед разработчиками и тестировщиками, мы развивали нашу систему непрерывной интеграции. Система уже решает множество задач, но предстоит еще многое улучшить.
Типы и размеры тестов
Существует несколько типов целей, которые может запускать система непрерывной интеграции:
- configure. Этап конфигурации, выполняемый системой сборки. Конфигурация включает в себя анализ конфигурационных файлов системы сборки, определение зависимостей между проектами и параметров сборки и запуска тестов.
- build. Сборка библиотек и проектов.
- style. На данном этапе проверяется соответствие стиля кода заданным требованиям.
- test. Тесты разбиты на стадии согласно их таймауту на время работы и требованиям к вычислительным ресурсам.
- small. < 1 мин.
- medium. < 10 мин.
- large. > 10 мин. Кроме того, могут быть особые требования к вычислительным ресурсам.
- extra large. Это особый тип тестов. Такие тесты характеризуются набором из следующих характеристик: долгое время работы, большое потребление ресурсов, большой объем входных данных, им могут требоваться особые доступы и самое главное — поддержка сложных сценариев тестирования, описанных ниже. Таких тестов намного меньше чем других типов тестов, но они очень важны.
Частота запуска тестов и бинарный поиск поломок
На тестирование в Яндексе выделяются огромные ресурсы — сотни мощных серверов. Но даже при большом количестве ресурсов, мы не можем запускать все тесты на каждое затрагивающее их изменение. Но при этом нам очень важно всегда помогать разработчику локализовать место поломки теста, особенно в таком большом репозитории.
Как мы поступаем. На каждое изменение для всех затронутых проектов запускаются сборки, проверки стиля и тесты с размером small и medium. Остальные тесты запускаются не на каждый влияющий коммит, а с некоторой периодичностью, при наличии влияющих на тесты коммитов. В некоторых случаях пользователи могут управлять периодичностью запуска, в остальных случаях периодичность запуска задается системой. При обнаружении поломки теста запускается процесс поиска ломающего тест коммита. Чем реже запускается тест, тем дольше будем искать ломающий коммит после обнаружения поломки.

При запуске прекоммитных проверок также запускаем только сборки и легкие тесты. Далее пользователь может вручную инициировать запуск тяжелых тестов, выбрав из предоставленного системой списка затронутых изменениями тестов.
Обнаружение мигающих тестов
Мигающие тесты — это такие тесты, результат запуска (Passed/Failed) которых на том же самом коде может зависеть от различных факторов. Причины возникновения мигающих тестов могут быть разными: sleep в коде теста, ошибки при работе с многопоточностью, инфраструктурные проблемы (недоступность каких-либо систем) и т.д. Мигающие тесты представляют серьезную проблему:
- Приводят к тому что система непрерывной интеграции спамит ложными уведомлениями о поломках тестов.
- Загрязняют результаты проверок. Становится сложнее принять решение об успешности результатов проверки.
- Задерживают релизы продуктов.
- Сложно детектировать. Тесты могут мигать очень редко.
Разработчики могут игнорировать мигающие тесты при анализе результатов проверки. Иногда некорректно.
Полностью устранить мигающие тесты невозможно, это должно учитываться в системе непрерывной интеграции.
На текущий момент на каждую проверку мы запускаем все тесты дважды для обнаружения мигающих тестов. Также мы учитываем жалобы от пользователей (получателей уведомлений). Если мы обнаруживаем мигание, мы помечаем тест особым флагом (muted) и информируем владельца теста. После этого уведомления о поломках теста будут получать только владельцы теста. Далее мы продолжаем запускать тест в обычном режиме, при этом анализируя историю его запусков. Если тест не мигал в определенном временном окне, автоматика может принять решение о том, что тест перестал мигать и можно сбросить флаг.
Наш текущий алгоритм достаточно простой и в этом месте планируется много улучшений. Прежде всего, мы хотим использовать гораздо больше полезных сигналов.
Автоматическое обновление входных данных тестов
При тестировании самых сложных систем Яндекса в дополнение к другим методикам тестирования часто используется тестирование по стратегии чёрного ящика + data-driven тестирование. Для обеспечения хорошего покрытия таким тестам требуется большой набор входных данных. Данные можно отобрать из production кластеров. Но возникает проблема с тем, что данные быстро устаревают. Мир не стоит на месте, наши системы постоянно развиваются. Устаревшие тестовые данные со временем не будут обеспечивать хорошее тестовое покрытие, а затем и вовсе приведут к поломке теста из-за того, что программы начинают использовать новые данные, которые отсутствуют в устаревших тестовых данных.
Для того чтобы данные не устаревали, система непрерывной интеграции умеет обновлять их автоматически. Как это работает.
- Тестовые данные хранятся в специальном хранилище ресурсов.
- Тест содержит метаданные с описанием требуемых входных данных.
- Соответствие между требуемыми входными данными теста и ресурсами хранится в системе непрерывной интеграции.
- Разработчик обеспечивает регулярную доставку свежих данных до хранилища ресурсов.
- Система непрерывной интеграции ищет новые версии тестовых данных в хранилище ресурсов и осуществляет переключение входных данных.
Важно произвести обновление данных так, чтобы при этом не произошло ложное срабатывание теста. Нельзя просто взять и, начиная с определенного коммита, начать использовать новые данные, т.к. в случае поломки теста будет непонятно, кто виноват — коммит или новые данные. Также это сделает неработоспособными diff-тесты (описаны ниже).

Поэтому мы делаем так, что есть некоторый небольшой интервал коммитов, на котором тест запускается как со старой, так и с новой версиями входных данных.

Diff-тесты
Diff-тестами мы называем особый тип data-driven тестов, которые отличаются от общепринятого подхода тем что тест не имеет эталонного результата, но при этом нам нужно находить в каких коммитах тест изменил свое поведение.
Стандартный подход в data-driven тестировании заключается в следующем. У теста есть эталонный результат, полученный при первом запуске теста. Эталонный результат может храниться в репозитории рядом с тестом. Последующие запуски теста должны приводить к одному и тому же результату.

Если результат отличается от эталонного, разработчик должен решить ожидаемое ли это изменение или ошибка. Если изменение ожидаемое, разработчик должен обновить эталонный результат одновременно с фиксацией изменений в репозитории.
Есть сложности при использовании такого подхода в большом репозитории с большим потоков коммитов:
- Тестов может быть много и тесты могут быть очень тяжелыми. У разработчика нет возможности запустить все затронутые тесты в рабочем окружении.
- После внесения изменений тест может сломаться, если эталонный результат не был обновлен одновременно с внесением изменений к код. Далее другой разработчик может внести изменения в тот же компонент и результат теста изменится еще раз. Получаем наложение одной ошибки на другую. С такими проблемами очень сложно разбираться, это отнимает время у разработчиков.
Как поступаем мы. Diff-тесты состоят из 2-х частей:
- Check-составляющая.
- Запускаем тест и сохраняем в хранилище ресурсов полученный результат.
- Не сравниваем результат с эталонным.
- Можем поймать часть ошибок, например, программа не запускается / не завершается, падения, программа не отвечает. Также может выполняться валидация результата: наличие каких-либо полей в ответе и т.д.
- Diff-составляющая.
- Сравниваем результаты, полученные на разных запусках и строим diff. В самом простом случае это функция, принимающая 2 параметра и возвращающая diff.
- Внешний вид diff'а зависит от теста, но это должно быть что-то понятное для того, кто будет смотреть на diff. Обычно diff представляет из себя html файл.
Запуском check и diff составляющих управляет система непрерывной интеграции.

Если система непрерывной интеграции обнаруживает diff, то сперва выполняется бинарный поиск вызвавшего изменения коммита. После получения уведомления у разработчика появляется возможность изучить diff и принять решение о том, что делать дальше: признать diff ожидаемым (для этого нужно выполнить специальное действие) или починить / "откатить" свои изменения.
Продолжение следует
В следующей статье мы расскажем про то, как устроена система непрерывной интеграции.
Ссылки
Монолитный репозиторий, Trunk-based development
Data-driven testing
Комментарии (78)

KevlarBeaver
08.11.2018 13:12«каждый отдел мог использовать любые языки, любые технологии, любые системы деплоя. И как показала практика, такая свобода не всегда помогала двигаться вперед быстрее»
А Гуглю помогает… habr.com/post/429018/#comment_19334662werklop
08.11.2018 14:20+2Набирают олимпиадников-хипстеров, которые пишут свои велосипеды, а потом сами же бегут от этого зоопарка. Бинго! до них дошло, что должны быть какие-то правила, переиспользование кода. Вместо того, чтобы писать свои велосипеды, лучше развивать то, что уже есть, вкладываться в опенсурсные проекты
Знание всяких заумных алгоритмов и хайповых технологий — далеко не показатель ума и качества работы потенциального сотрудника, гораздо важнее уметь писать поддерживаемый код и разрабатывать стройную архитектуру, а не «мермишель», но зато ппц какую крутую, имхоevetrov
08.11.2018 14:56+++
50 000 проектов и библиотек / 2000+ разработчиков = 25 проектов на разработчика…
Есть ощущение, что что-то идет не так.
Судя по такой статистике каждый вновь прибывший разработчик пишет свой велосипед, каждый ушедший разработчик оставляет за собой гору велосипедов, которые никто не хочет использовать и поддерживать или не знает как использовать.
Там где я работаю можно не хило по шапке получить за новую библиотеку или зависимость или за то что народ не разбирается в твоем велосипеде. А в больших компаниях наоборот… вот недавно только пост был habr.com/post/429018
А если по теме статьи, то такое ощущение что создается монолит со скоростью 10 коммитов в секунду и этот адский огромный монолит нужно прогонять по тестам в короткие промежутки времени… но тестов очень много и за секнду не прогоняется и падает всегда. Да и вообще даже внутри тестов энтропия такая, что неизвестно тест вообще рабочий или нет.
Был на гугловой конфе, там одна из команд рассказывала про международный проект, где была всего лишь одной из сотен команд по всему миру (то есть суммарно тоже тысячи разрабов). Так вот они отвечают только за свои микросервисы (а может и не микро). Каждый имеет свою документацию поддерживаему и технически не сильно зависит от остальных. Свои сервера, свои технологии. Главное что бы документация была подробной, понятной, актуальной и доступной для всех пользователей (внутренних) этого сервиса. В общем полная децентрализация и минимум зависимостей и своих велосипедов и всё у них хорошо.
amkruglov Автор
08.11.2018 22:02Вывод не совсем верный. 50 000 проектов и библиотек = 50 000 целей системы сборки. Сюда входят библиотеки, различные составные части проектов, бинарники программ, множество исходников open-source библиотек и другие артефакты.
qw1
08.11.2018 15:12+4Начиная с некоторого размера, свои велосипеды просто необходимы.
Во-первых, люди хорошо знают проект и могут очень быстро починить проблему.
Во-вторых, если писать код с оглядкой на специфику компании, а не под общий случай, с которыми обязаны работать продукты общего назначения, можно улучшить технические показатели (память, нагрузка на CPU) на порядок. Например, если известно, что в БД только целые числа, а индексы и запросы только определённого вида, код можно написать на порядок эффективнее, чем для БД общего назначения.evetrov
08.11.2018 15:35+1Во-первых, люди хорошо знают проект и могут очень быстро починить проблему.
да ладно… этож не стартаперы. Люди приходят и уходят. Среднее время работы разработчика около 3х лет. Сомневаюсь что в Яндексе по 10 лет работают в среднем.
+ Ротация между проектами наверняка имеет место быть, а то с ума сойти можно.
Так что если доки актуальной нет на велосипед (а обычно никто не поощряет документирование велосипедов) — то скорее всего проще написать еще один велосипед, получить премию и почёт. Ну или закостылять, ведь подругому то никак в старом велосипеде не разобраться.
_____
А то что необходимы — это да… но не 25 проектов на человека ведь.
gecube
08.11.2018 16:25Согласен и не согласен одновременно. Меня тоже очень удивляло желание Яндекса писать все самостоятельно, да ещё и на с++. С другой стороны, у них велосипеды получаются реально крутые (например, Кликхаус, Я.Облако)
amkruglov Автор
08.11.2018 22:01При найме проверяются в основном самые базовые знания. Подготовиться к собеседованию достаточно просто, если поставить перед собой такую цель и стремиться к ней: yandex.ru/jobs/ya-interview
werklop
08.11.2018 22:03-1Уж наслышаны о вас, тем боле в свете этой статьи… благодарю, но нет такой цели
Ошибок в вашем коде быть не должно, лучше написать неэлегантный код, но без ошибок, чем наоборот
вот так и пишутся разного рода неподдерживаемые «лисапеды» с говнокодом, зато ЧСВ у написавшего зашкаливает. И что значит не должно быть ошибок? Как вы в таком случае нанимаете сотрудников, да еще и CI/CD настраиваете, когда сами себе и противоречите?
amkruglov Автор
08.11.2018 16:25+1Речь не про неудачные проекты. Таких и у нас хватает – все иногда ошибаются. Речь про повторное использование результатов труда. Если в каждом новом проекте не нужно заново изобретать велосипед, работа пойдет гораздо быстрее. Если все же нужно сделать велосипед — поделись с коллегами, поставь его на видное место.
gecube
08.11.2018 16:22+1Очень обстоятельная статья. Спасибо. Дочитал до середины, остальное — на закуску
Сразу два вопроса.
- Безопасность. Все ли разработчики видят код всех остальных? По всем проектам? А что с секретами — реквизиты подключения к БД, сертификаты ssl и пр.?
- trunk. Это косвенно говорит об использовании svn. Я угадал? Если нет, то какая система управления версиями используется ?
amkruglov Автор
08.11.2018 16:41Sensitive данные и ключи доступа хранятся в специальных система, не в исходном коде.
Исходный код доступен всем.
Про trunk ответил тут.x2bool
08.11.2018 17:27Получается нет исходного кода, который является тайной? Я как-то читал, что то ли алгоритм ранжирования, то ли еще что-то в Яндексе хранится за семью замками. Это не правда?
amkruglov Автор
08.11.2018 21:14+1Есть очень редкие исключения. Пускай секреты остаются секретами :)
gecube
09.11.2018 00:54Ну, хорошо. А Яндекс никогда не привлекает подрядчиков для выполнения работ по написанию годного кода? Явно, что подрядчикам ни в коем случае нельзя давать доступ к общему монорепу. Можно закрыться NDA и дать доступ, но это такое себе. В этом отношении, я склонен к концепции, что репозиторий должен быть на команду(проект). А если нужно использовать кусок, написанный кем-то, то его нужно использовать как субмодуль.
tbl
08.11.2018 16:43Сколько по времени обычно длится бинарный поиск коммита, который ломает тесты?
amkruglov Автор
08.11.2018 19:25Зависит от того как часто запускается тест, сколько было влияющих на тест коммитов и сколько времени работает тест. Мы планируем работать над ускорением этого процесса. При бин. поиске можно делать несколько запусков с опережением, но это дорого. Можно пробовать предсказывать коммит, который вызывал поломку теста.
Berkof
08.11.2018 19:41Один общий репозиторий на 25 гигабайт? Это звучит так отстойно, что… ну неужели это обязательно было делать то?
yayashitoya
09.11.2018 10:39Один общий репозиторий на 25 гигабайт? Это звучит так отстойно, что… ну неужели это обязательно было делать то?
Монорепы очень любит и Google.
И самый большой в мире репозитарий — у Microsoft.
Почему так не скажу, но большие репы в организациях, серьезно занимающихся ИТ — не редкость.gecube
09.11.2018 11:11не редкость. И они решают часть проблем с версиями. Но сразу тащат за собой необходимость специализированного тулинга. В случае кучи маленьких репозиториев — можно попробовать обойтись штатными средствами git/jenkins/gitlab-ci и пр., но, как показывает практика, тулинг все равно понадобится (хотя может и не сразу).
agent10
08.11.2018 20:39+1А как из общего репозитория вытащить только код конкретного проекта? Или надо качать все 25 гбайт?
amkruglov Автор
08.11.2018 21:12У нас есть селективный checkout, который интегрирован с нашей системой сборки. При сборке определенного проекта можно выкачивать все нужные ему зависимости.
tbl
08.11.2018 22:39+1Не понял про «нужной вам библиотеки может не быть в репозитории, но она есть в open-source. Есть затраты на ее добавление и обновление. Сильно зависит от языка и библиотеки, где-то почти бесплатно, где-то очень дорого.»
Вы все внешние зависимости прямо исходниками в репу тащите? О_о
OpenSSL нужен — фигак и забрали, webkit нужен — фигак и тоже…
very
08.11.2018 23:34+1Да.
tbl
09.11.2018 00:20+2Это же в какую попоболь выливается обновление минорной версии библиотеки, не говоря уже про мажорные релизы. При таком подходе к разработке техдолг должен накапливаться только в путь.
humbug
09.11.2018 00:36Да ни в какую, если соблюдать semver. Другое дело, что на семвер обычно кладут. И в любом случае боль не больше, чем если обновится внешняя библиотека, которая лежит не в монорепе, а где-то в репозитории debian.
tbl
09.11.2018 01:00+1Если не монорепа, то обновление зависимости будет быстрым для проекта. Для устранения техдолга есть тикет в джире (состоит из подзадач: устранение костылей, обновление зависимостей, рефакторинг), как он закрывается — создается аналогичный новый и закидывается в конец очереди.
А за тем, какие дебпакеты приедут на сервера, где крутится мой сервис — я сам прослежу.
Как это выглядит в монорепе? Кто выделяет ресурс для таких общих и масштабных задач? Или какая-то одна проектная команда тратит свои драгоценные человеко-дни, чтобы всем сделать хорошо?humbug
09.11.2018 01:03Если не монорепа, то обновление зависимости будет быстрым для проекта.
Не путайте обновление зависимости и обновление зависимых. Если обновится внешняя зависимость, никому не станет от этого легче, ибо эту зависимость еще надо втянуть.
С другой стороны я бы послушал аргументы amkruglov по этому поводу.
very
09.11.2018 02:42Когда проекты зависят по исходникам – обновление зависимости подразумевает обновление всех проектов, которые от неё зависят.
С зависимостями по артефактам задача на обновление какой-либо (сильно характерно для больших) зависимости везде может утопать в куче «техдолга» или не сходиться никогда.
amkruglov Автор
09.11.2018 01:28Как это выглядит в монорепе? Кто выделяет ресурс для таких общих и масштабных задач? Или какоя-то одна проектная команда тратит свои драгоценные человеко-дни, чтобы всем сделать хорошо?
Иногда требуемую open-source зависимость может положить в репозиторий какая-либо проектная команда. Но заметную часть работы выполняет соседняя с нами команда. И всем действительно хорошо :)
gecube
09.11.2018 00:19вообще это правильная история. Дело в том, что любая внешняя зависимость может в любой момент времени взять и умереть.
Я знаю кучу брошенных репо на гитхабе.
Например, github.com/moira-alert/worker (слава Богу — это не зависимость).
funca
08.11.2018 23:15+1В большой системе вероятность поломки в любой произвольно взятый промежуток времени стремится к единице. Расскажите, что происходит во время поломанного HEAD? Каковы реакции со стороны системы и разработчиков? Сколько времени уходит в среднем на восстановление работоспособности?
amkruglov Автор
08.11.2018 23:56Не все так страшно. Прекоммитные проверки помогают ловить большую часть поломок до коммита. Прекоммитных проверок становится все больше и в самых важных местах они становятся обязательными. Это сводит кол-во крупных поломок практически к нулю.
gecube
09.11.2018 13:27прекоммитные — это локально, на стороне разработчика? Или я не правильно понял?
Не увеличивает ли это сильно время коммита и не потребляет ли этого много ресурсов на ноутбуках разрабов?amkruglov Автор
09.11.2018 14:13Запускать тесты на ноутбуке или разработческом сервере – это полезно, но при больших изменениях (рефакторинги общих библиотек и т.д.), затрагивающих много целей, локально не получится запустить все затронутые тесты. Их много. К тому же, локально разработчику не нужно иметь все исходники из-за селективного checkout'а.
Прекоммитные проверки – это процесс проверки твоих локальных изменений в CI системе. Прекоммитные проверки позволяют понять что будет если закоммитить изменения прямо сейчас. Твои изменения в виде патча/diff'а отправляются в CI систему, далее CI система определяет затронутые цели и осуществляет сборку, запуск тестов и т.д. Патч накладывается на HEAD.
AndrewSu
10.11.2018 19:35А большое количество предкоммитных проверок не затягивают время коммита? Я так понимаю, что на время предкоммитной проверки репозиторий блокируется?
amkruglov Автор
10.11.2018 21:23Репозиторий не блокируется во время проверок. Мержить все изменения по очереди, каждый раз заново проверяя поверх HEAD, при большом кол-ве проверок невозможно. Суммарное время выполнения всех проверок за день во много раз превышает длительность суток.
Продолжу мысль. Есть вероятность поломки тестов в репозитории после коммита, потому что проверка осуществляется поверх одного коммита из trunk, а коммит – спустя некоторое время. Но при осуществлении коммита после успешной прекоммитной проверки вероятность поломки стремится к нулю.AndrewSu
10.11.2018 21:46Не очень тогда понятно, как разрешаются конфликты, если я и мой сосед исправляем один и тот-же файл и коммитим одновременно.
amkruglov Автор
11.11.2018 00:32Как и во всех популярных системах контроля исходного кода. Редактирование одного и того же файла еще не гарантирует конфликт. Если все же конфликт случается, то 2-й коммит не пройдет и разработчик должен разрешить конфликт прежде можно будет коммитить.
pushforce
09.11.2018 00:54Спасибо за статью. Интересно было бы узнать, как QA занимающиеся ручным тестированием вписываются в данный процесс. Еще не очень понятно как организуются зависимости между проектами. Допускается ли между ними прямая связь на уровне исходного кода? Как часто можно делать релизы при такой схеме? Спасает ли ревью и тесты от попадания багов в релиз?
amkruglov Автор
09.11.2018 01:19Интересно было бы узнать, как QA занимающиеся ручным тестированием вписываются в данный процесс.
С описанными выше процессами наша система управления ручным тестированием сейчас не интегрирована. Но все впереди.
Еще не очень понятно как организуются зависимости между проектами. Допускается ли между ними прямая связь на уровне исходного кода?
Зависимости между проектами по исходному коду.
Как часто можно делать релизы при такой схеме?
Зависит от сложности проекта, времени выполнения тестов, наличия ручного тестирования. Несколько раз в неделю для самых сложных проектов — вполне достижимо. Про один из наших проектов рассказывали на мероприятии Яндекс изнутри: умные технологии в рекламе. Для более простых проектов — так часто как хочется, хоть покоммитно.
Спасает ли ревью и тесты от попадания багов в релиз?
100% гарантию никто не даст.
Sad_Bro
09.11.2018 09:12Интересные процессы.
Скажите а занимаются ли SDET поддержкой тестовых стендов?
Имею ввиду:
— организацию доставки нового кода на тестовый стенд;
— решением интеграционных проблем на тестовых стендах;
— обновление тестовых данных на cерверах;
— собственно написание ansible скриптов для разворачивания этих серверов.
Или же автоматизаторы занимаются только написанием автотестов?amkruglov Автор
09.11.2018 12:34Разработчики автотестов у нас есть. Но у нас все стремится к тому чтобы разработчики сами писали тесты. И мы делаем все возможное чтобы упростить им жизнь. Но тут тоже все зависит от конкретной команды. Я пишу про общий тренд.
Про деплой.
- Первый этап – пакетирование. Для этого у нас есть стандартное решение. Особый файл json описывает какие артефакты (цели в терминах системы сборки, файлы из репозитория, артефакты из хранилища ресурсов) и как нужно скомпоновать в один пакет (tarball, debian).
- Собрать пакет можно локально, но скорее в тестовых целях. Обычно собирают в распределённой системе выполнения задач общего назначения – так надежнее, т.к. там правильное и безопасное окружение.
- Далее сам деплой. Сейчас есть выбор из нескольких способов деплоя (различные системы деплоя, куда деплоить).
Тема деплоя сейчас очень активно развивается, прямо очень-очень быстро. Выработка единого и подходящего для всех решения с хорошей архитектурой, унификация. Мы верим что очень скоро все сойдется. Деплой становится простым. И мы также постараемся об этом рассказать.
Sad_Bro
09.11.2018 13:35Алексей к сожалению не ответили на вопрос.
Понял что разработчики пишут автотесты сами, хорошо. Разработчики занимаются devops делами или этим заняты соответственно отдельные люди (организацией тестовой среды, настройками интеграции и тд)?amkruglov Автор
09.11.2018 14:53У всех по разному. Где-то есть выделенные команды devops, так часто бывает в крупных проектах. В других командах разработчики могут отвечать за все процессы. Поэтому мы много инвестируем в общие инструменты.
tangro
09.11.2018 13:12-3Столько букв. Можно было написать одним предложением: и это мы тоже передрали у Гугла. И дать ссылки на их лекции об использовании единого репозитория, транк-бейс разработке, непрерывном тестировании и т.д. датированные где-то 2011-2012 годом.
amarao
09.11.2018 15:02А вы gerrit не используете? Мне кажется, это самый стабильный метод жизни в больших проектах с разной компетенций участников.
Основная идея, что в мастер мержит только робот и только после а) успешного прохода CI (можно больше одной штуки) б) +2 на code review.amkruglov Автор
09.11.2018 15:28Не используем. Но у нас также есть авто-merge с возможностью настройки требований (наличие ship it, успешные сборки, тесты, тяжелые тесты).
amarao
09.11.2018 15:37+1Т.е. в мастер у вас мержится человеком, т.е. человек определяет исполнение workflow. Моя devops часть души говорит, что workflow человеков плохой и стохастический. Must obe4 bots.
В этой ситуации любой факап деплоя превращается из дисциплинарного разговора (любого вида — сам понял, выговор — не важно) в баг, который можно исправить.amkruglov Автор
09.11.2018 15:54Ключевая фраза — возможность настройки требований. Про деплой я не писал.
NeoPhix
Понравилась статья, всегда очень любопытно посмотреть на опыт решения такого рода проблем в крупных компаниях.
Я только не совсем понял из текста:
Что значит разработка в отдельных ветках не приветствуется? Имеются в виду ветки, в которых может осуществляться долгая параллельная разработка (до недель)? Потому что по ссылке trunkbaseddevelopment.com явно написано, что каждое изменение выделяется в одну ветку (feature branch), которая существует некоторое время (короткое — дни), а потом вливается в репозиторий при помощи мержа. Это не совсем то же самое, что и «каждый отдельный коммит». Или вы заставляете обязательно делать людей squash для всех коммитов в их feature branch, а потом rebase того, что получилось, от trunk (master)? Хотелось бы конкретики :)
А еще я проглядел (или в статье этого нет): какую систему контроля версий вы используете?
amkruglov Автор
Строгих правил нет, только рекомендации, никто никого не заставляет. Некоторые команды используют подход с feature-braches. У нас есть много примеров, когда команды сами приходят к пониманию того что разработка в trunk намного удобнее. Многие проекты вели разработку в отдельных ветках, которые могли жить по несколько месяцев. Мержить изменения в trunk и обратно, отщеплять новые ветки – все это было достаточно трудоемкими задачами. Далее время жизни веток постепенно сокращалась, пока разработка полностью не переезжала в trunk. Твой вариант (про squash) почти корректный, но есть набор некоторых допущений.
В статье этого нет, для монорепозитория у нас используется несколько систем контроля версий, которые работают над одним набором данных. На текущий момент это svn, hg и некоторые внутренние разработки.
Если развернуть, то получится еще одна статья, – когда-нибудь обязательно напишем, если вам интересно.
c0f04
Теперь понятно, почему часто фигурирует слово trunk. Не проще всё перевести на git? С svn не работал, а вот с серьёзными проблемами вытягивания большого объёма данных при пропадающем соединении у hg уже успел столкнуться за единственный раз работы с ним. Догадываюсь, что у git есть преимущества по сравнению с обоими системами контроля версий.
amkruglov Автор
Про git ответил здесь.
Если вам интересно, через некоторое время мы напишем подробный пост про проблемы, которые стоят перед системой контроля версий. Про преимущества и недостатки различных решений.
antonqwerty
Тоже интересно и хотелось бы узнать детали, т.к. на прошлой работе использовался стандартный подход с N репозиториями. БОльшая часть проектов — C++ (система сборки CMake). Подход был не без проблем, со своими костылями, но жило всё хорошо. Из основных проблем были: как найти зависимости какого-то проекта, который тебе надо поправить, как обновлять каждую зависимость (к сожалению, каждая команда решала эту проблему сама: кто-то делал общий git-репозиторий с подмодулями, кто-то, как я, писал специальные скрипты и поддерживал список зависимостей), а также, если ты правишь свои проекты в нескольких версиях, то нужно либо под каждую версию держать свое дерево зависимостей, либо каждый раз все их обновлять.
Есть некоторые вопросы:
1. Каким образом разработчик взаимодействует с репозиторием? Он же не клонирует себе все 25 Гб? Отсюда же вопрос про push/pull. На следующий день придется скачивать более 2к коммитов? Полагаю, что нет и есть возможность скачать часть репозитория.
2. > любой проект из репозитория получает готовую инфраструктуру
А GitLab разве не дает все то же самое? Тот же community-edition. Если возможностей код-ревью GitLab мало, конечно, можно запилить своё, но просмотр и навигация по коду там сделаны вполне себе неплохо.
3. > система сборки и распределенная сборка. Это отдельная большая тема, и мы обязательно ее раскроем в следующих статьях.
Что имеется в виду под системой сборки? Система сборки проектов на C++? А что вообще у вас используется для сборки проектов на C++? CMake/waf/SCons? Или же имеется в виду аналог Jenkins?
4. > система непрерывной интеграции.
А чем не подошел Jenkins?
5. > совместное использование кода, активное взаимодействие команд.
В чем проблема совместно использовать код и активно взаимодействовать в подходе с множеством репозиториев?
6. > С общим кодом у вас появляется возможность сделать часть работы самим и «помочь случиться» нужным вам изменениям.
Опять непонятно каким образом то же самое не дает делать подход с N репозиториями: склонировал себе, сделал ветку, запушил, сделал pull request.
7. > появляется возможность проводить глобальный рефакторинг. Вам не надо поддерживать старые версии вашего API или библиотеки, вы можете изменить их и поменять те места, где они используются в других проектах.
Опять как-то странно. Когда N репозиториев: склонировал их себе, поправил, запушил. Сделали деплой новой версии на рабочие сервера и перестали поддерживать старую версию.
Из плюсов для себя вижу только решение проблемы dependency hell и упрощение сборки, т.к. не надо поддерживать список зависимостей с ревизиями/ветками, на которые надо обновляться. Но даже если и его надо было бы поддерживать, то это не такая и большая проблема, т.к. многое можно автоматизировать.
amkruglov Автор
Есть селективный checkout.
amkruglov Автор
Имеется в виду система автоматизации сборки.
amkruglov Автор
— Jenkins не умеет делать то что умеет делать наш CI. Стоимость доработки и адаптации под наши процессы, интеграция с другими нашими системами может легко превышать стоимость разработки своей системы с нуля.
— Тесная интеграция CI системы с нашими процессами и другими системами.
— Наша система скрывает за собой комплекс из нескольких систем. CI система, распределённая система выполнения задач общего назначения с кластером большого размера, система распределенной сборки. Обо всем этом мы будем постепенно рассказывать.
gecube
— зато стоимость поддержки может легко превышать стоимость коробки или опенсурс решения. Тем более, что коммьюнити ничего не выиграет от вашей системы сборки.
— касательно Jenkins. Мне он не очень нравится. Мне больше нравится Gitlab-ci, еще крутой concourse. Что-нибудь такое готовое используете? Потому что платформа сборки — это чуточку шире, чем какой-то отдельный продукт. И я могу представить себе систему, которая объединяет под капотом concourse/gitlab-ci/ набор сервисных докер-образов и все это работает поверх какого-нибудь менеджера ресурсов (k8s?)
amkruglov Автор
В некоторых проектах все еще используется Jenkins и не только он, но все постепенно переезжают в общий CI. Opensource и многие платные решения тут не заработают, хотя бы из-за объема обрабатываемых данных. Тут нужно полностью пересматривать архитектуру. А еще поддержка описанных выше сценариев. Подожди следующую статью про устройство системы – она будет опубликована примерно через неделю.
gecube
Да, жду. Спасибо.
marxfreedom
Не совсем понял из статьи. Подскажите пожалуйста — для feature branch так же как и для trunk автоматически будут запускаться сборки, тесты и т.п.?
amkruglov Автор
Если подключить к CI системе – да.
endemic
> какую систему контроля версий вы используете
Для хранения единой кодовой базы Яндекс использует SVN
pprometey
Про git видимо не слышали
TheKnight
Не любитель SVN, но разве git умеет комофортно работать с монорепозиторием таких размеров?
balexa
А не надо хранить все проекты в едином репозитории. Ятак и не понял, какие проблемы это решило
amkruglov Автор
Единый (монолитный) репозиторий — это довольно популярная тема, про которую написано много статей. В рамках данной статьи нет возможности раскрыть эту тему подробнее. Если хочется изучить тему подробнее, можно почитать в Википедии. Там есть очень хороший набор ссылок.
pprometey
Ребята, вы явно застряли в прошлом, в нулевых. Я понимаю что при таких масштабах сложно совершать маневры и это накладывает ограничения. Но Git изменил идеологию совместной работы с кодом. И вам давно пора внедрить корпоративный Gitlab. Ну не кошерно все хранить в одной «помойке». Аргументы больше надуманные в пользу монолитных репозиториев. Разделяй и властвуй. То же относится и к коду.
humbug
Ну на самом деле в этом есть смысл, особенно для проектов на С++, у которого отсутствует пакетный менеджер. Все равно с С++ приходишь к мысли, что надо все перекомпилировать одним компилятором, т.е. смысла держать код в разных репах нет, ибо все равно все сливается в одну.
Ну и монолитная репа помогает сразу отлавливать проблемы API, ибо при смене API в одной зависимости надо сразу же починить все зависимые куски, иначе у тебя не пройдет CI.
Другое дело, что создавать свой YMake, который типа не CMake, держать код в svn, потому что "тижило портировать" — ну это детский сад.
allburov
Пакетные менеджеры С++ довольно сильно развиваются, но с озвученные проблемы тоже пришлось решать.
К примеру — conan, crosspm
amkruglov Автор
Слышали, завести гит на монорепозитории с таким объемом кода невозможно без огромного количества дополнительных приседаний.
Microsoft gvfs на текущий момент полностью эту задачу не решает.
Каких-либо доступных снаружи решений нет.
Т.к. с git мы знакомы достаточно тесно, внутренние разработки в районе VCS базируются как раз на git.
slonopotamus
25GB — ни о чём объёмы для гита. Это я вам как бывший обладатель Git-репозитория на полтора терабайта и нынешний обладатель Git-репозитория на 70GB говорю.
amkruglov Автор
25 GB — это размер текущего полного чекаута в HEAD репозитория, без метаданных и истории. Положить такой репозиторий в git можно. Но эффективно разрабатываться в несколько тысяч разработчиков в одном таком репозитории — другая более сложная задача. Эту задачу мы уже решаем, напишем отдельно через какое-то время :)
c0f04
А как же подмодули? С ними крайне неудобно, но если заскриптовать всё по максимому, то вполне сносно.
На мой взгляд, монорепозиторий — это крайне неудобно. К тому же из подмодулей можно вполне и тот же монорепозиторий сделать, если очень захочется.