
Здравствуйте! В этой статье я расскажу какие шаги нужно пройти для создания простого процессора и окружения для него.
Архитектура набора команд (ISA)
Для начала нужно определиться с тем, каким будет процессор. Важны такие параметры как:
- Размер машинного слова и регистров(разрядность/"битность" процессора)
- Машинные команды (инструкции) и их размер
Архитектуры процессоров можно разделить по размеру инструкций на 2 вида (на самом деле их больше, но другие варианты менее популярны):
Основное их отличие в том, что RISC процессоры имеют одинаковый размер инструкций. Их инструкции простые и выполняются сравнительно быстро, тогда как CISC процессоры могут иметь разный размер инструкций, некоторые из которых могут выполняться достаточно продолжительное время.
Я решил сделать RISC процессор во многом похожий на MIPS.
Я это сделал по целому ряду причин:
- Довольно просто создать прототип такого процессора.
- Вся сложность такого вида процессоров перекладывается на такие программы как ассемблер и/или компилятор.
Вот основные характеристики моего процессора:
- Машинное слово и размер регистров — 32 бита
- 64 регистра (включая счетчик команд)
- 2 типа инструкций
Register type(досл. Регистровый тип) выглядит вот так:

Особенность таких инструкций заключается в том, что они оперируют с тремя регистрами.
Immediate type(досл. Немедленный тип):

Инструкции этого типа оперируют с двумя регистрами и числом.
OP — это номер инструкции, которую нужно выполнить (или же для указания, что эта инструкция Register type).
R0, R1, R2 — это номера регистров, которые служат операндами для инструкции.
Func — это дополнительное поле, которое служит для указания вида Register type инструкций.
Imm — это поле куда записывается то значение, которое мы хотим явно предоставить инструкции в качестве операнда.
- Всего 28 инструкций
Полный список инструкций можно посмотреть в github репозитории.
Вот лишь пару из них:
nor r0, r1, r2NOR это Register type инструкция, которая делает логическое ИЛИ НЕ на регистрах r1 и r2, после записывает результат в регистр r0.
Для того, чтобы использовать эту инструкцию нужно изменить поле OP на 0000 и поле Func на 0000000111 в двоичной системе счисления.
lw r0, n(r1)LW это Immediate type инструкция, которая загружает значение памяти по адресу r1 + n в регистр r0.
Для того, чтобы использовать эту инструкцию в свою очередь нужно изменить поле OP на 0111, а в поле IMM записать число n.
Написание кода процессора
После создания ISA можно приступить к написанию процессора.
Для этого нам нужно знание какого нибудь языка описания оборудования. Вот некоторые из них:
- Verilog
- VHDL (не путать с предыдущим!)
Я выбрал Verilog, т.к. программирование на нем было частью моего учебного курса в университете.
Для написания процессора нужно понимать логику его работы:
- Получение инструкции по адресу Счетчика команд (PC)
- Декодирование инструкции
- Выполнение инструкции
- Прибавление к Cчетчику команды размера выполненной инструкции
И так до бесконечности.
Получается нужно создать несколько модулей:
- Регистровый файл
- Декодер
- АЛУ
Разберем по отдельности каждый модуль.
Регистровый файл
Регистровый файл предоставляет доступ к регистрам. С его помощью нужно получать значения каких то регистров, или изменять их.
В моем случае у меня 64 регистра. В один из регистров записывается результат операции над двумя другими, так что мне нужно предоставить возможность изменять только один, а получать значения из двух других.
Декодер
Декодер это тот блок, который отвечает за декодирование инструкций. Он указывает какие операции нужно выполнить АЛУ и другим блокам.
Например, инструкция addi должна сложить значение регистра $zero(Он всегда хранит 0) и 20 и положить результат в регистр $t0.
addi $t0, $zero, 20На этом этапе декодер определяет, что эта инструкция:
- Immediate type
- Должна записать результат в регистр
И передает эти сведения следующим блокам.
АЛУ
После управление переходит в АЛУ. В нем обычно выполняются все математические, логические операции, а также операции сравнения чисел.
То есть, если рассмотреть ту же инструкцию addi, то на этом этапе происходит сложение 0 и 20.
Другие
По мимо вышеперечисленных блоков, процессор должен уметь:
- Получать и изменять значения в памяти
- Выполнять условные переходы
Тут и там можно увидеть как это выглядит в коде.
Ассемблер
После написания процессора нам нужна программа, которая бы преобразовывала текстовые команды в машинный код, чтобы не делать этого вручную. Поэтому нужно написать ассемблер.
Я решил реализовать его на языке программирования Си.
Так как мой процессор имеет RISC архитектуру, то для того, чтобы упростить себе жизнь, я решил спроектировать ассемблер так, чтобы в него можно было легко добавлять свои псевдоинструкции(комбинации из нескольких элементарных инструкций или из других псевдоинструкций).
Можно реализовать это с помощью структуры данных, хранящей в себе тип инструкции, ее формат, указатель на функцию, которая возвращает машинные коды инструкции, и ее название.
Обычная программа начинается с объявления сегмента.
Для нас достаточно двух сегментов .text — в котором будет храниться исходный код наших программ — и .data — в котором будет хранится наши данные и константы.
Инструкция может выглядеть вот так:
.text
jie $zero, $zero, $zero # Ветвление
addi $t1, $zero, 2 # $t1 = $zero + 2
lw $t1, 5($t2) # $t1 = *($t2 + 5)
syscall 0, $zero, $zero # syscall(0, 0, 0)
la $t1, label# $t1 = labelСначала указывается название инструкции, потом операнды.
В .data же указываются объявления данных.
.data
.byte 23 # Константа размером 1 байт
.half 1337 # Константа размером 2 байта
.word 69000, 25000 # Константы размером 4 байта
.asciiz "Hello World!" # Константная нуль терминируемая строка (Си строка)
.ascii "12312009" # Константная строка (без терминатора)
.space 45 # Пропуск 45 байтовОбъявление должно начинаться с точки и названия типа данных, после же идут константы или аргументы.
Удобно парсить (сканировать) ассемблер файл в таком виде:
- Сначала сканируем сегмент
- Если это .data сегмент, то мы парсим разные типы данных или .text сегмент
- Если это .text сегмент, то мы парсим команды или .data сегмент
Для работы ассемблеру нужно проходить исходный файл 2 раза. В первый раз он считает по каким смещениям находятся ссылки (они служат для), они обычно выглядят вот так:
la $s4, loop # Загружаем адрес loop в s4
loop: # Ссылка!
mul $s2, $s2, $s1 # s2 = s2 * s1
addi $s1, $s1, -1 # s1 = s1 - 1
jil $s3, $s1, $s4 # если s3 < s1 то перейди на метку А во второй проход можно уже и генерировать файл.
Итог
В дальнейшем, можно запускать выходной файл из ассемблера на нашем процессоре и оценивать результат.
Также готовый ассемблер можно использовать в Си компиляторе. Но это уже позже.
Ссылки:
- Designing Digital Computer Systems with Verilog. David J. Lilja and Sachin S. Sapatnekar
- Исходный код
- Исходный код другого процессора
Комментарии (19)

algotrader2013
21.11.2018 21:56Понимаю, что это не несет практической пользы, но интересно на каком-то простом алгоритме сравнить перфоманс на FPGA с реальными процессорами. Интересно понимать хотябы десятилетие, когда делали процы с аналогичным перфомансом)
amartology
21.11.2018 22:40Перформанс процессора, залитого в FPGA, примерно на десять лет отличается от перформанса того же процессора, сделанного как ASIC. Опять же, описанный автором код на верилоге можно синтезировать на технологии 500 нм, а можно на 28 нм. Результаты будут, сами понимаете, разные)
HDL
22.11.2018 17:47+1Софт-процессоры с оптимизированной для FPGA архитектурой, на простых алгоритмах показывают производительность на уровне ~~100МГц stm32 (даже на дешевых семействах FPGA). Так что практическая польза есть.
timdorohin
22.11.2018 03:38Складывается впечатление что у каждого второго электронщика есть своя «великая и гениальная» архитектура процессора. Обычно она лежит в голове или в заметках где-нибудь внутри «Новая папка (3)» на файлопомойке. Описать ее на verilog — уже достижение, серьезно.
Жизненный цикл процессораИдея архитектуры
Реализация на HDL
*Вы находитесь здесь*
Испытания на FPGA
Написание бэкенда к LLVM
Привлечение сообщества
Выпуск ASIC / продажи лицензии
…
PROFIT!amartology
22.11.2018 12:32+2Складывается впечатление что у каждого второго электронщика есть своя «великая и гениальная» архитектура процессора. Обычно она лежит в голове или в заметках где-нибудь внутри «Новая папка (3)» на файлопомойке.
Как у каждого второго программиста есть великая и гениальная операционка.
Юношеский максимализм и желание сдвинуть горы для студента-старшекурсника — это не только нормально, но и правильно. Главное потом эту энергию использовать в мирных целях.
Dmitriy0111
22.11.2018 13:11+1Здравствуйте, опередили однако) (сам недавно сел за описание небольшого ядра). Интересно сколько занимает Ваш проект на циклоне 4 или на любой другой ПЛИС, ибо увидел пару операций в АЛУ, которые "съедают" достаточно много ресурсов (/ и %)?
i1i1 Автор
22.11.2018 18:18Здраствуйте,
Вот так выглядит вывод quartus prime после компиляции для cyclone4. Сейчас пробую портировать на cyclone 4. Код можно найти тут.
Осторожно картинка!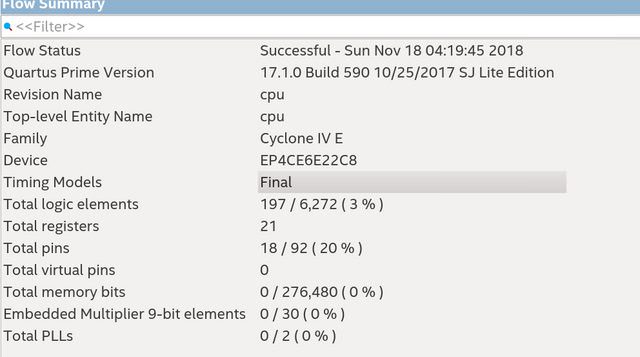
ineganov
22.11.2018 17:49+2О! Написание процессоров — дело почетное и адски полезное!
Рискну дать непрошенный совет автору:
— clock gating в стиле «assign g_clk = cond & clk»
— неблокирующие присваивания в комбинаторной логике
Обе конструкции нормально не работают нигде: ни в симуляции, ни в FPGA, ни в ASIC.
Зато они создают опасную иллюзию корректно работающей схемы и дарят часы отладки дельта-циклов. В качестве конструктива, в плане clock gating'a в ПЛИС проще (а для незамороченных проектов — лучше) использовать вход «En» в самом триггере. В таком духе: «if(condition) q <= d»i1i1 Автор
22.11.2018 18:02Здраствуйте, спасибо за советы.
Можете, пожалуйста, рассказать поподробнее, почему такие конструкции некорректно работают?
amartology
22.11.2018 18:13+1Если коротко, то потому, что таков синтаксис языка Verilog. Если не коротко, то в Харрисе и Харрисе есть подробное описание.
ineganov
22.11.2018 18:51Вот лучше «на ты», в самом-то деле. Интернет же!
По clock gating'у:
В ПЛИС есть несколько выделенных линий тактовых сигналов (6, чтоли, в недорогих циклонах?) и управлять можно только всей линией целиком.
Возможно, в новых дорогих ПЛИСах с этим проще, но в любом случае на синтезатор полагаться не стоит — нужно напрямую указывать библиотечный компонент.
Ну, или делать enable во всех интересующих последовательностных блоках (а еще, можно вообще забить: ну не потребует собственный процессор принудительного охлаждения:)
В ASIC такой gating не работает потому что enable всегда задержан относительно тактового сигнала в зависимости от температуры и напряжения. Поэтому чтобы не было просечек, что-либо переключать лучше тогда, когда clk == 0. Сделать это можно, например, комбинацией гейта и защелки.
А в симуляторе причина та же, по которой не стоит использовать неблокирующие присваивания в комбинаторной логике.
Неблокируемость означает, что конкретно в этом цикле симуляции обновлять зависимые блоки не нужно, а новое значение еще не действует.
Ну то есть, последовательностная логика, работающая от тактового сигнала увидит изменения на следующем этого тактового сигнала. С комбинационной сложнее, и тут возможны варианты, в зависимости от того, что написано в других блоках. Если их нет, то все даже будет работать. А вот если есть, могут появиться спецэффекты: в waveform'ах вы увидите правильное поведение логики, но триггеры будут защелкивать неконсистентное состояние. С синтезом — как повезет. Скорее всего, проканает :) С gating'ом тактового сигнала та же история. Если все работает от gated clock — ну так и будет работать. А вот если в тестбенч clock обычный, а в дизайне — gated, то будут точно такие же спецэффекты, что и выше.
amartology
Конвейер делали?
Харрис и Харрис читали, там куча всякого, что было бы вам интересно и помогло бы улучшить результат.
Почему MIPS-подобный RISC, а не собственная реализация RISC-V? Там было бы практически то же самое, точно без проблем с авторскими правами и потенциально с кучей поддержки, вплоть до работающего линукса.
В ПЛИС пробовали заливать? )
old_bear
Ну это же, вероятно, курсовик или диплом, тут важен факт выполнения, а не содержание. :)
amartology
Тогда надо было списать из Харриса и Харриса, там все есть уже готовое для курсовика или диплома, и даже с конвейером)
i1i1 Автор
Здравствуйте,
Пока нет.
Спасибо большое за наводку.
Не сильно знаком с RISC-V. Изучения MIPS был частью университетского курса.
Пробовал заливать в Cyclone 4. Столкнулся с некоторыми проблемами.
Dmitriy0111
По поводу конвейера, не могу не прорекламировать проект под названием SchoolMIPS (https://github.com/MIPSfpga/schoolMIPS). Кроме конвейера там имеется сопроцессор и шина AHB-lite в топовой ветке. Плюс он реализован по цифровой схемотехнике от Харрис и Харрис. И собственно из него черпаю вдохновение для своего ядра, правда на основе risc-v. И ещё по поводу ресурсов, попробуйте синтезировать только ALU, ресурсов потребуется сразу же больше.
i1i1 Автор
Спасибо за наводку :)