
На днях одна из баз данных MS SQL Server перешла в Suspect, в журнале было сообщение об ошибке:
Базу перевели в Emergency и попытались выполнить DBCC CHECKDB, но выполнение сразу же прерывалось:
С аналогичной же ошибкой прерывалось выполнение команды DBCC CHECKALLOC. Осложнялось всё тем, что SQL Server был версии 9.0.1399, т.е. RTM, без каких-либо обновлений.
Попытки использовать хинт TABLOCK и явным образом повысить уровень изоляции транзакций, ни к чему не привели (места на дисках с tempdb было достаточно и DBCC CHECKALLOC с WITH ESTIMATEONLY завершался с той же ошибкой). Накатывать SP на сервер с повреждённой БД крайне не хотелось, а с каким конкретно объектом проблема, было абсолютно непонятно. Кроме того, создавалось впечатление, что сообщение DBCC CHECKDB имеет мало общего с реальностью, поскольку в msdb.dbo.suspect_pages была одна запись, но номер страницы отличался от того, который выводил DBCC CHECKDB.
Для того, что последовать инструкциям DBCC CHECKDB и выполнить DBCC CHECKTABLE, нужно было узнать таблицу. И после долгих поисков, одна инструкция нашлась.
Первое, что нужно сделать, это выполнить (в контексте повреждённой базы данных) — это DBCC PAGE (database_id, file_id, page_id, printopt):
либо:
Если вам повезло (или вы играетесь на живой базе), в результате вы увидите поле Metadata: ObjectId и, собственно нужный object_id:
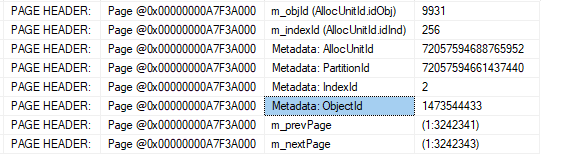
Однако, если вам, как и нам, не повезло, вы увидите следующее:
На скриншоте видно, что у меня m_objId = 9931, т.е. можно продолжать.
Теперь нужно выполнить небольшие вычисления, чтобы вычислить Allocation Unit ID (подробнее про Allocation Units можно прочитать здесь):
Итак, зная Allocation Unit ID, можно посмотреть что у нас в системном представлении sys.allocation_units:

И там, в случае, если type = 1 или 3 (IN_ROW_DATA, ROW_OVERFLOW_DATA), столбец container_id = sys.partitions.hobt_id («Heap-Or-B-Tree ID»), т.е. можно выполнить запрос:

И вот тут уже есть корректный object_id и index_id. Теперь можно посмотреть что там у нас в sys.objects и sys.indexes, да и просто выполнить:
К счастью, и в реальной ситуации, и здесь поверждённым оказался некластерный индекс, после перестройки которого всё пришло в норму (на самом деле нет, но это уже другая история).
Ссылки:
How to use DBCC PAGE
Troubleshooting and Fixing SQL Server Page Level Corruption
What Are Allocation Units?
Finding a table name from a page ID
sys.allocation_units
Msg 7105, Level 22, State 9, Line 14
Database ID 6, page (1:386499), slot 0 for LOB data type node does not exist. This is usually caused by transactions that can read uncommitted data on a data page. Run DBCC CHECKTABLE.
Базу перевели в Emergency и попытались выполнить DBCC CHECKDB, но выполнение сразу же прерывалось:
Msg 8921, Level 16, State 1, Line 13
Check terminated. A failure was detected while collecting facts. Possibly tempdb out of space or a system table is inconsistent. Check previous errors.
Msg 7105, Level 22, State 9, Line 13
Database ID 6, page (1:386499), slot 0 for LOB data type node does not exist. This is usually caused by transactions that can read uncommitted data on a data page. Run DBCC CHECKTABLE.
С аналогичной же ошибкой прерывалось выполнение команды DBCC CHECKALLOC. Осложнялось всё тем, что SQL Server был версии 9.0.1399, т.е. RTM, без каких-либо обновлений.
Попытки использовать хинт TABLOCK и явным образом повысить уровень изоляции транзакций, ни к чему не привели (места на дисках с tempdb было достаточно и DBCC CHECKALLOC с WITH ESTIMATEONLY завершался с той же ошибкой). Накатывать SP на сервер с повреждённой БД крайне не хотелось, а с каким конкретно объектом проблема, было абсолютно непонятно. Кроме того, создавалось впечатление, что сообщение DBCC CHECKDB имеет мало общего с реальностью, поскольку в msdb.dbo.suspect_pages была одна запись, но номер страницы отличался от того, который выводил DBCC CHECKDB.
Для того, что последовать инструкциям DBCC CHECKDB и выполнить DBCC CHECKTABLE, нужно было узнать таблицу. И после долгих поисков, одна инструкция нашлась.
Примечание
Я прошу прощения, что номера таблиц в сообщениях об ошибках и в коде не совпадают. Ошибки я взял из журналов, а код уже после выполняю в тестовом окружении на другой, живой базе.
Мы использовали алгоритм ниже для определения object_id обеих страниц — из DBCC CHECKDB и suspect_pages. Проблема оказалась в странице из suspect_pages
Мы использовали алгоритм ниже для определения object_id обеих страниц — из DBCC CHECKDB и suspect_pages. Проблема оказалась в странице из suspect_pages
Первое, что нужно сделать, это выполнить (в контексте повреждённой базы данных) — это DBCC PAGE (database_id, file_id, page_id, printopt):
DBCC TRACEON (3604);
DBCC PAGE(5, 1, 3242342, 0)
DBCC TRACEOFF (3604);
либо:
DBCC PAGE(5, 1, 3242342, 0) WITH TABLERESULTS.Если вам повезло (или вы играетесь на живой базе), в результате вы увидите поле Metadata: ObjectId и, собственно нужный object_id:
Однако, если вам, как и нам, не повезло, вы увидите следующее:
Metadata: = Unavailable in offline DBЕсли метаданные недоступны, ещё не всё потеряно, в этом случае, нам нужно поле m_objId (AllocUnitId.idObj). Если m_objId = 255, беда закрывайте статью и ищите что-то другое (пытайтесь заскриптовать всё что можно и утащить данные, выполнять DBCC CHECKDB с «восстановительными» параметрами вслепую и т.д.).
На скриншоте видно, что у меня m_objId = 9931, т.е. можно продолжать.
Теперь нужно выполнить небольшие вычисления, чтобы вычислить Allocation Unit ID (подробнее про Allocation Units можно прочитать здесь):
Allocation Unit ID = m_objid * 65536 + (2^56)В нашем случае:
Allocation Unit ID = 9931 * 65536 + (2^56) = 72057594688765952
Итак, зная Allocation Unit ID, можно посмотреть что у нас в системном представлении sys.allocation_units:
SELECT * FROM sys.allocation_units
WHERE allocation_unit_id = 72057594688765952И там, в случае, если type = 1 или 3 (IN_ROW_DATA, ROW_OVERFLOW_DATA), столбец container_id = sys.partitions.hobt_id («Heap-Or-B-Tree ID»), т.е. можно выполнить запрос:
SELECT * FROM sys.partitions WHERE hobt_id = 72057594661437440И вот тут уже есть корректный object_id и index_id. Теперь можно посмотреть что там у нас в sys.objects и sys.indexes, да и просто выполнить:
SELECT OBJECT_NAME(object_id)К счастью, и в реальной ситуации, и здесь поверждённым оказался некластерный индекс, после перестройки которого всё пришло в норму (на самом деле нет, но это уже другая история).
Ссылки:
How to use DBCC PAGE
Troubleshooting and Fixing SQL Server Page Level Corruption
What Are Allocation Units?
Finding a table name from a page ID
sys.allocation_units
Комментарии (5)

AlanDenton
23.11.2018 10:37Все таки люблю ваши статьи читать. Спасибо за полезный материал. Чисто из любопытства не подскажите тулы самописные, которые напрямую будут из mdf / ldf данные читать?
unfilled Автор
23.11.2018 11:15Спасибо! :)
С такими утилитами сталкиваться пока не приходилось и надеюсь (тьфу-тьфу-тьфу) не придётся, поэтому подсказать не могу.
alexhott
Причину повреждения индекса выяснили?
Просто так такая фигня у меня за 10 лет ни разу не случалась
unfilled Автор
Без меня выясняют, если узнаю — отпишусь.
Naves
Было у меня несколько случаев, за давностью лет не помню подробностей.
MSSQL+1С на одном сервере, все стандартно. Еще была самописная программа на .net, которая из базы 1с выгружала номенклатуру и отправляла на кассы. Как всегда, внезапно, в пятницу вечером номенклатура перестала отправляться. В логах программы OutOfMemoryException, с чего вдруг непонятно, новых товаров в огромных количествах никто не создавал. В логах сервера SQL также появились непонятные Exception in thread… В конце концов сделали DBCC CHECKDB, были найдены какие-то ошибки, их исправили, и отправка прейскурантов благополучно заработала.
Через полгода опять возникла такая же ошибка, и все тоже самое. Заподозрили неладное. Нашли время для проверки памяти, memtest где-то ближе к концу в последней плашке на определенном паттерне нашел несколько сбоев. Память была без ECC.
Другой сервер, бухгалтер при запуске определенного отчета в 1с за определенный период получал ошибку HRESULT 0x-что-тотам. DBCC показал ошибку в файле базе. В конечном счете выяснилось, что на диске был bad block, и попал он именно на файл базы. При этом на сервере был RAID1 на встроенном в материнку чипсете, который fakeraid. Тогда еще возник локальный мем в отделе, как 1с протерла дырку в жестком диске.