

DeepMind создает поистине удивительные алгоритмы, которые способны на то, чего не могли достичь машинные системы ранее. В частности, нейросеть AlphaGo смогла обыграть в го лучших игроков мира. По мнению специалистов, сейчас возможности системы возросли настолько, что нет даже смысла пытаться ее победить — результат предопределен.
Тем не менее, компания не останавливается на достигнутом, а продолжает работу. Благодаря исследованиям ее сотрудников на свет появилась улучшенная версия AlphaGo, которая получила название AlphaZero. Как и указано в заголовке, система сама смогла научиться играть сразу в три логических игры — шахматы, сеги и го.
Отличием новой версии от всех предыдущих стало то, что система практически всему научилась сама. Она начала с нуля и быстро научилась отлично играть во все три игры. Никто AlphaZero не помогал — система до всего «дошла сама».
Шахматы были включены в комплект, скорее, по традиции — ничего сложно в том, чтобы научить компьютер играть в шахматы, нет. Впервые компьютерную систему привлекли к игре в 1950-х годах. Затем, уже в 60-х, была создана программа Mac Hack IV, которая стала обыгрывать соперников-людей. С течением времени шахматные программы постепенно совершенствовались, а в 1997 году корпорация IBM разработала «шахматный компьютер» Deep Blue, который сумел обыграть гроссмейстера и чемпиона мира Гарри Каспарова.
Как сам он указывает, в настоящее время многие приложения на смартфоне играют в шахматы лучше, чем Deep Blue. Достигнув совершенства в создании систем, которые умеют играть в шахматы, разработчики стали создавать новые варианты компьютерных соперников человека — в частности, удалось научить компьютер играть в го. Ранее эта игра с тысячелетней историей считалась одной из самых недоступных для «понимания» компьютера. Но времена изменились. Как уже говорилось выше, AlphaGo достигла настолько высокого уровня мастерства по игре в го, что человек и рядом не стоял.
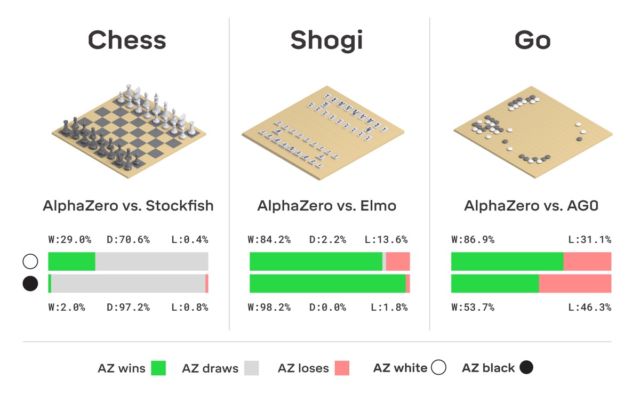
Кстати, в этом году AlphaGo получила обновление, благодаря которому теперь нейросеть может обучаться различным стратегиям игры в го без участия человека. Играя с собой снова и снова, AlphaGo совершенствуется. Именно такую систему обучения использует «потомок» AlphaGo — нейросеть AlphaZero. Всего за три дня она достигла в го такого уровня мастерства, что обыгрывает оригинальную версию AlphaGо с результатом 100 к 0. Единственное, что получает система изначально — правила игры.
Никакой фантастики здесь нет, DeepMind использует широко известную систему машинного обучения с подкреплением. Компьютер стремится выиграть, поскольку за каждую победу получает награду (очки). Причем AlphaZero проигрывает миллионы комбинаций в процессе обучения. На просчет следующего хода и оценку вероятности победы AlphaZero тратит всего 0,4 секунды. Что касается AlphaGo оригинальной версии, то нейросеть состояла из двух элементов, двух нейросетей — одна определяла следующий возможный ход, а вторая просчитывала вероятности.
Для достижения уровня мастера в Go AlphaZero нужно «прокрутить» около 4,5 млн игр при игре с собой. А вот AlphaGo на это требовалось 30 млн игр.
Стоит отметить, что AlphaZero создали специально для игры в го. Компания не забыла об этом. Но кроме го, система способна обучаться и двум другим играм, о которых упоминалось выше. Система используется та же — машинное обучение с подкреплением. Стоит отметить, что AlphaZero работает лишь с задачами, у которых есть определенное количество вариантов решения. Также системе нужна модель окружающей среды (виртуальной).
Интересно, что тот же Каспаров считает, что человек может многое получить от систем вроде AlphaGo — научиться у них можно многому.
В настоящее время перед разработчиками стоит задача обучить компьютер играть в покер лучше, чем кто-либо из людей, а также создать систему, способную побить в честном бою любого киберспортсмена. В любом случае понятно, что нейросети и AI способны на многое.
Комментарии (17)

BaLaMuTt
07.12.2018 09:31В настоящее время перед разработчиками стоит задача обучить компьютер играть в покер лучше, чем кто-либо из людей
если получится у виртуальных казино будут большие проблемы ибо невозможно обыграть в покер то что изначально от природы наделено покерфейсом)dfgwer
07.12.2018 09:52Будут анализировать время хода соперника… И блефовать с временем анализа хода, делая сверхбыстрые или долгие ходы чтобы подтолкнуть к неверным выводам бота противника.
vesper-bot
07.12.2018 10:04У казино проблем не будет — крапленые колоды всё ещё будут позволять обыгрывать нейросеть, которая по своей природе не может играть в нечестную игру. Проблемы будут у игроков-людей, которые начнут в равных условиях сливать невесть откуда взявшемуся покерботу.
Pochemuk
07.12.2018 12:11Вот поясните мне, почти что абсолютному нулю в ИНС, такой вопрос:
В одной статье про ИНС и покер (лимитный ТХ) читал, что ИНС (название не помню, может быть Cepheus) может блефовать.
Это вот мне как раз и странно. В моем понимании, ИНС это линейный классификатор. Т.е. куча параметров на входе и одна 1 на одном выходе, определяющем класс, к которому относится объект (позиция игры в данном случае). Остальные выходы — по нулям. Т.е. таким образом однозначно находится класс входного объекта (является ли он буквой «Ъ», нужно ли пасовать или брать пешкой ферзя).
Т.е. однозначно находятся чистые стратегии игровых продолжений.
Но блеф — это совсем другой иконостас… Здесь мало найти, к какому классу относится позиция, нужно еще определить, что в этой позиции нужно применять смешанную стратегию, а так же частоты принятия того или иного решения в рамках этой смешанной стратегии.
Например, пасовать 99% случаев или блефовать и поднимать в 1% случаев.
Это какая-то особая архитектура ИНС для вычисления этих частот применяется? Или достигается вообще за счет каких-то других методик?DancingOnWater
07.12.2018 12:23Но блеф — это совсем другой иконостас… Здесь мало найти, к какому классу относится позиция, нужно еще определить, что в этой позиции нужно применять смешанную стратегию, а так же частоты принятия того или иного решения в рамках этой смешанной стратегии
Сразу оговорюсь, что не являюсь специалистом в ИНС. Но оценка позиции в покер звучит как-то так: текущая позиция ведет к победе с вероятностью P. Что такое позиция: это ваша рука, карты, которые уже открывались, ваш номер в круге, кто уже вышел и кто остался в игре. Способа перехода от позиции к позиции два вы либо уходите в пас, либо остаетесь.
А блефа тут нет от слова вообще.Pochemuk
07.12.2018 14:32Способа перехода от позиции к позиции два вы либо уходите в пас, либо остаетесь.
Это как раз и есть, что называется, решением в чистых стратегиях.
Имеем вероятности, имеем значения проигрышей/выигрышей в каждом случае, оцениваем риски, находим оптимальный единственный ход.
Но Cepheus умеет как раз блефовать, т.е. в некоторых случаях следует не чистым, а смешанным стратегиям:
https://www.gipsyteam.ru/news/4362-proschay-limitnyy-holdem
Как найти численными методами смешанные стратегии- имею представление. Например, методом Брауна-Робинсон. Или более продвинутыми.
Как работает классификатор на основе ИНС тоже некое представление имею.
Но как заставить ИНС не просто проводить классификацию, а вычислять частоты различных стратегий в рамках смешанной стратегии, да еще следовать им, — это представить не могу.
Вот поэтому интересуюсь: это какие-то специальные ИНС на такое способны или сбоку к ИНС прикручена еще какая приблуда, которая этим занимается?
Peacemaker
07.12.2018 15:35Т.е. куча параметров на входе и одна 1 на одном выходе, определяющем класс, к которому относится объект (позиция игры в данном случае). Остальные выходы — по нулям
Это если используется модель «победитель получает всё».
А можно вместо бинарного порогового значения выходных нейронов (0 или 1) задавать им выходные уровни из некоторого диапазона, например, из того же [0;1]б но в виде вещественных значений, а итоговый нейрон-победитель выбирается случайным образом, где вероятность быть выбранным зависит от вещественного значения выхода нейрона.Pochemuk
07.12.2018 16:57Это, безусловно, больше соответствует реалиям карточных игр, но не отвечает на главный вопрос:
Каким образом ИНС может расчитать оптимальную смешанную стратегию?
Т.е., другими словами, каким образом заставить вещественное число на выходе нейрона быть адекватной той частоте, с которой надо выбирать именно этот ход?
Т.е., если три хода должны быть выбраны с частотами (не вероятностями, а именно частотами в данном контексте) 40%, 50% и 10%, то в результате обучения ИНС на выходе мы должны получить значения трех нейронов, из которых однозначно вычислим эти частоты.
Т.е. ИНС должна обучаться именно частотам, причем, в конце концов, подбирать их оптимальное соотношение.
ftdgoodluck
07.12.2018 15:55Со стороны покера могу немного рассказать.
Может не совсем понял, что вы имеете в виду под «чистыми стратегиями» – но современная теория покера говорит о том, что практически в любой ситуации нельзя использовать какое-то одно решение – т.е. с одними и теми же картами в одной и той же ситуации вы, условно, должны делать ставку в 30% случаев, и делать чек в 70%.
Можете погуглить «GTO Poker», чтобы в целом понять, о чем речь. Для расчета конкретных ситуаций есть специальные тулзы, которые подбирают равновесные по Нэшу стратегии в конкретных случаях.Pochemuk
07.12.2018 17:38Ну Вы верно уловили суть…
За покер не могу говорить, т.к. ривер от ретривера не отличу, поэтому поговорим за преферанс. Вернее, за такой тип игры, как «мизер».
Для тех, кто не в курсе, поясню: мизер, это такой заказ, при котором мизерящий обязуется не взять ни одной взятки. Если выполнил это обязательство — получает крупную премию. Если нет — крупный штраф за каждую взятую взятку.
Так вот, по правилам преферанса. прикупив две карты из прикупа, мизерящий скидывает две любые карты в «снос». Причем, его противники этих карт не видят.
У него после сноса может остаться такая комбинация карт, при которой он заявку «мизер» выполнит автоматом при любом раскладе у противников. В этом случае говорят, что мизер чистый.
Но чаще в одной или нескольких мастях остаются такие комбинации, которые с некоторой вероятностью могут дать ему взятку или несколько. Такие комбинации называются «дырами». В том смысле, что в них мизерящему что-то прилетит.
Так вот, допустим у мизерящего два варианта сноса, но при любом остается «дыра». Вероятность того, что на первую дыру получим взятку составляет 70%, а на вторую — 60%.
Казалось бы, оставлять вторую дыру выгоднее всегда… И это называется чистой стратегией.
Примем упрощенную модель, при которой вероятности ловли дыр являются независимыми.
Тогда с вероятностью (1-0,7)*(1-0,6)=12% не ловится ни одна дыра.
С вероятностью 0,7*(1-0,6)=28% ловится только первая дыра.
С вероятностью 0,6*(1-0,7)=18% ловится только вторая дыра.
С вероятностью 0,7*0,6=42% ловятся обе дыры.
Но давайте предположим, что мизерящий сносит случайным образом с частотами 50/50.
Тогда от 28% и от 18% останется только половина. Потому что в половине случаев будет оставлена не та дыра, которая ловится.
И от 42% останется только половина. Потому что противники будут ловить не ту дыру, которая оставлена (не угадают).
Итого, при такой стратегии сноса (случайной) мизер будет пойман всего лишь в 0,5*(0,28+0,18+0,42)=44%.
А сыграет его мизерящий с вероятностью 0,12+0,5*(0,28+0,18+0,42)=56%.
Согласитесь, что 56% сыграть мизер при смешанной стратегии сноса гораздо лучше вероятности 40% при оставлении всегда второй дыры…
Конечно, модель очень упрощена. Она не учитывает, что при некоторых раскладах карт у противников количество взяток на разные дыры может существенно отличаться. Но суть, надеюсь, описал понятно.
Так вот, какие алгоритмы должны применяться в ИНС, чтобы в конце концов мы получили именно равные частоты для обоих вариантов сноса, а не явное предпочтение оставлению второй дыры?
Я так краем глаза слышал, что метод обратного распространения ошибки здесь не подходит. Нужно применять какие-то другие методы. Но вот какие именно — не помню и не знаю… Может быть подскажете?
Pochemuk
07.12.2018 20:24Можете погуглить «GTO Poker», чтобы в целом понять, о чем речь. Для расчета конкретных ситуаций есть специальные тулзы, которые подбирают равновесные по Нэшу стратегии в конкретных случаях.
Погуглил… То что прочел про GTO в «нетях» удручило… смешались в кучу кони, люди, равновесие по Нэшу, покер.
1. Равновесие по Нэшу — это для бескоалиционных игр, в которых игроки делают ходы одновременно, т.е. не имея информации о ходах сделанных соперниками.
В покере, преферансе и многих других карточных играх ходы делаются по очереди. При этом за ход надо понимать не только выкладывание карты на стол, но и любую заявку (торговлю, заказ, вист/пас, приглашение в преферансе; торговлю, контру/реконтру в бридже; дроп/колл/рэйз в покере и т.д.).
Таким образом, после каждого хода соперника/партнера позиция игрока меняется. Поэтому такие игры принято относить к позиционным. Причем позиция (в случае покера) состоит из собственных карт, карт на столе, заявок (своих и соперника), кэша и информационного множества возможных карт на руке у соперника.
2. Нарушение равновесия по Нэшу не гарантирует того, что противники начнут выигрывать. Нэш доказал, что нарушение равновесия любым участником игры не может увеличить его выигрыш. А это совсем не то же самое.
А для того, чтобы соперники начали выигрывать, нужно не только самому нарушить равновесие, но и что бы соперники подкорректировали свои стратегии с целью эксплуатации этого нарушения.
В игре «Камень-ножницы-бумага», которой так любят объяснять равновесие по Нэшу, равновесным для каждого игрока является применение каждой чистой стратегии К, Н, Б с частотами 1/3. Тогда никто не будет систематически проигрывать.
Если кто-то из игроков нарушит равновесие и станет всегда применять стратегию К, то остальные не будут выигрывать, если будут продолжать придерживаться своих равновесных стратегий.
В самом деле… В 1/3 случаев они выбросят К и будет ничья, в 1/3 выбросят Н и проиграют и в 1/3 выбросят Б и выиграют. Т.е., как был в среднем нулевой результат, так и остался.
Чтобы начать получать выгоду от нарушения игроком своей равновесной стратегии на стратегию К, остальные игроки должны тоже нарушить свои стратегии и изменить их на Б.
В этой же теории GTA, пардон, GTO утверждается совсем обратное — мол, достаточно продолжать придерживаться своей равновесной стратегии и златые горы сами упадут в карман. Да еще Нэша приплели каким-то боком.
В общем, читать про GTO желание пропало… Лучше, погуглите про «Фундаментальную (основную) теорию покера».negasus
07.12.2018 21:50Я, конечно, извиняюсь, что не совсем по теме, но вам определенно стоит писать больше статей на хабре) Владение слогом и темой — это то, что надо и интересно
Pochemuk
07.12.2018 22:52Спасибо :)
Вот выйду на пенсию (если доживу, конечно) и займусь этим. Разработаю, наконец, теорию угадаечных мизеров, которой занимаюсь несколько лет, а все еще в самом начале; доработаю алгоритм нечеткого сравнения имен, опишу более продвинутое решение задачи Гуго Штейнгауза о кривой монетке… В общем, есть над чем трудится :)
Что касается моего поста, то тут малость эмоции возобладали.
На самом деле не во всех статьях о GTO пишется, что надо тупо продолжать придерживаться своей равновесной стратегии. В некоторых отмечается, что такой подход позволит не проиграть, но и не позволит выиграть. Поэтому надо научиться эксплуатировать нарушения равновесий противником. Но осторожно — чтобы он сам не начал эксплуатировать Ваше нарушение.
И что касается равновесия по Нэшу…
В принципе, многие (а может быть и все) позиционные игры с неполной информацией можно свести к матричному виду с одновременным выполнением ходов игроками. Только в столбцах и строках будут не чистые стратегии, а т.н. «позиционные стратегии» — действия игрока с учетом разнообразных позиций (например, соперники ловят первую дыру в позиции, в которой первая дыра ловится на 5 взяток, а вторая — на 4 взятки). Такая форма решается как обычная игра в матричной форме. А затем делается обратное преобразование с учетом различных вероятностей позиций (в данном случае — перекосов в числе взяток на разные дыры) и получаем смешанную стратегию мизерящего. А потом и смешанные стратегии его соперников с учетом конкретных позиций.
Только вся беда в том, что в отличие от чистых стратегий сноса (сносим первую/вторую дыру) или ловли (ловим первую/вторую дыру) число позиционных стратегий несоразмеримо больше, т.к. учитывает стратегии для всех возможных позиций (групп раскладов).
Даже если упростить матрицу игры за счет исключения явно противоречивых (ловим первую дыру, если ловится только вторая), невозможных (ловим вторую дыру на 2 взятки при нулевой вероятности двух взяток на нее) и мажорируемых стратегий, то все равно число строк/столбцов будет достаточно большим, чтобы отвратить от решения такой простой задачи подобным образом.
Что же касается покера, то в нем, думаю, число разнообразных позиций существенно больше. Даже без учета стола и возможных карт соперника, число собственных позиций (разных комбинаций на руке) исчисляется сотнями.
Так что, решение подобных игр в терминах равновесия по Нэшу возможно, но только чисто теоретически.
rPman
А знаете что круто?
Все это происходит не на жутком кластере где то в облаке а на небольшом количестве специализированных плат расширения. Вики говорит что там всего 4 TPUs (alphago была до 280GPU но потом хватило 4 модулей).
Victor_koly
Не знаю, на счет плат расширения, но суперкомпы на GPU могут быть такими:
rPman
об энергопотреблении и размерах вы конечно не задумываетесь?
DjSapsan
Метод Монте Карло, как ни как )
Не раз встречал этот способ поиска решенийу ИИ. Это вычислительный КПД — можно иметь точность 100% в астрономическую цену, либо в 10^10 аз дешевле потеряв при этом 10% точности