
Цель — познакомить с основными концепциями реактивного программирования и показать, что не всё так сложно и страшно, как может показаться на первый взгляд.

Источник
Что такое реактивное программирование?
Чтобы ответить на этот вопрос, обратимся к сайту. На нём есть красивая картинка, на которой показаны 4 основных критерия, которым должны соответствовать реактивные приложения.

Приложение должно быть быстрым, отказоустойчивым и хорошо масштабироваться.
Выглядит как «мы за всё хорошее против всего плохого», верно?
Что подразумевается под этими словами:
- Отзывчивость
Приложение должно отдавать пользователю результат за полсекунды. Сюда же можно отнести и принцип fail fast — то есть, когда что-то идёт не так, лучше вернуть пользователю сообщение об ошибке типа «Извините, возникла проблема. Попробуйте позже», чем заставлять ждать у моря погоды. Если операция долгая, показываем пользователю прогресс-бар. Если очень долгая — «ваш запрос будет выполнен ориентировочно 18 марта 2042 года. Мы пришлём Вам уведомление на почту». - Масштабируемость — это способ обеспечить отзывчивость под нагрузкой. Представим жизненный цикл какого-либо относительно успешного сервиса:
- Запуск — поток запросов маленький, сервис крутится на виртуалке с одним ядром.
- Поток запросов увеличивается — виртуалке добавили ядер и запросы обрабатываются в несколько потоков.
- Ещё больше нагрузка — подключаем batching — запросы к базе и жёсткому диску группируются.
- Ещё больше нагрузка — нужно поднимать ещё сервера и обеспечивать работу в кластере.
В идеале система должна сама масштабироваться в большую или меньшую сторону в зависимости от нагрузки.
- Отказоустойчивость
Мы принимаем то, что живём в несовершенном мире и случается всякое. На случай, если в нашей системе что-то пойдёт не так, мы должны предусмотреть обработку ошибок и способы восстановления работоспособности - И наконец, нам предлагается всего этого добиться при помощи системы, архитектура которой основана на обмене сообщениями (message-driven)
Прежде чем продолжить, я хочу остановиться на том, чем отличаются event-driven системы от message-driven.
Event-driven:
- Event — система сообщает о том, что достигла определённого состояния.
- Подписчиков на событие может быть много.
- Цепочка событий обычно короткая, и обработчики события находятся рядом (и физически, и в коде) с источником.
- Источник события и его обработчики обычно имеют общее состояние (физически — используют один и тот же участок оперативной памяти для обмена информацией).
В противоположность event-driven, в message-driven системе:
- Каждое сообщение имеет только одного адресата.
- Сообщения неизменяемы: нельзя что-то поменять в полученном сообщении так, чтобы отправитель об этом узнал и смог прочитать информацию.
- Элементы системы реагируют (или не реагируют) на получение сообщений и могут отправлять сообщения другим элементам системы.
Всё это нам предлагает
Модель акторов
Основные вехи развития:
- Первое упоминание акторов есть в научной работе 1973 года — Carl Hewitt, Peter Bishop, and Richard Steiger, “A universal modular ACTOR formalism for artificial intelligence,”
- 1986 — появился Erlang. Компании Ericson был нужен язык для телекоммуникационного оборудования, который бы обеспечивал отказоустойчивость и нераспространение ошибок. В контексте этой статьи — его основные особенности:
- Всё является процессом
- Сообщения — единственный способ коммуникации (Erlang — функциональный язык, и сообщения в нём неизменяемые).
- .. .
- 2004 — первая версия языка Scala. Его особенности:
- Работает на JVM,
- Функциональный,
- Для многопоточности выбрана модель акторов.
- 2009 — реализация акторов выделилась в отдельную библиотеку — Akka
- 2014 — Akka.net — её портировали на .Net.
Что умеют акторы?
Акторы — это те же объекты, но:
- В отличие от обычных объектов, акторы не могут вызывать методы друг друга.
- Акторы могут передавать информацию только через неизменяемые сообщения.
- При получении сообщения актор может
- Создать новые акторы (они будут ниже в иерархии),
- Отослать сообщения другим акторам,
- Остановить акторы ниже в иерархии и себя.
Рассмотрим на примере.
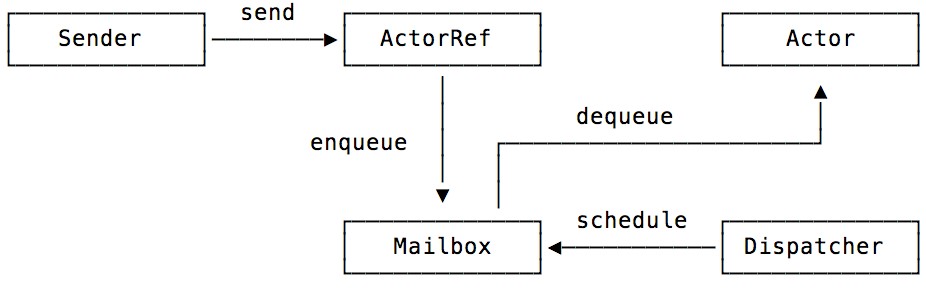
Актор А хочет отправить сообщение актору Б. Всё, что у него есть — ActorRef (некий адрес). Актор Б может находиться где угодно.
Актор А отправляет письмо Б через систему (ActorSystem). Система кладёт письмо в почтовый ящик актора Б и «будит» актор Б. Актор Б берёт письмо из ящика и что-то делает.
По сравнению с вызовом методов у другого объекта, выглядит излишне сложно, но модель акторов прекрасно ложится на реальный мир, если представить, что акторы — это люди, которые обучены что-то делать в ответ на определённые раздражители.
Представим себе отца и сына:
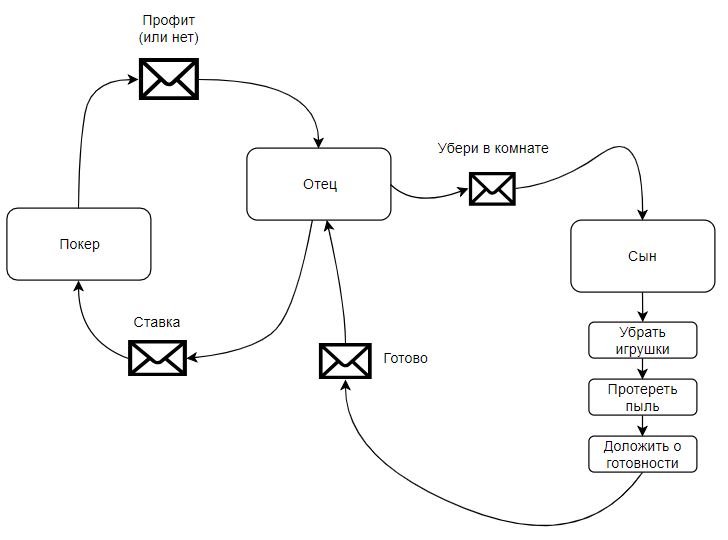
Отец шлёт сыну СМСку «Убери в комнате» и продолжает заниматься своими делами. Сын читает СМСку и начинает уборку. Отец тем временем играет в покер. Сын заканчивает уборку и шлёт СМС «Готово». Выглядит просто, верно?
Теперь представим, что отец и сын не акторы, а обычные объекты, которые могут дёргать методы друг у друга. Отец дёргает сына за метод «убери в комнате» и следует за ним по пятам, ожидая, пока сын не закончит уборку и не передаст управление обратно отцу. Играть в покер в это время отец не может. В этом контексте модель акторов становится более привлекательной.
Теперь перейдём к
Akka.NET
Всё, что написано ниже, справедливо и для оригинального Akka для JVM, но для меня C# ближе, чем Java, поэтому я буду рассказывать на примере Akka.NET.
Итак, какие преимущества есть у Akka?
- Многопоточность через обмен сообщениями. Больше не придётся мучиться со всякими локами, семафорами, мьютексами и прочими прелестями, характерными для классической многопоточности с разделяемой памятью (shared memory).
- Прозрачное общение между системой и её компонентами. Не нужно беспокоиться о сложном сетевом коде — система сама найдёт адресата сообщения и гарантирует доставку сообщения (тут можно вставить шутку про UDP vs TCP).
- Эластичная архитектура, способная автоматически масштабироваться в большую или меньшую сторону. Например, при нагрузке система может поднять дополнительные ноды кластера и равномерно распределить нагрузку.
Но тема масштабирования очень обширна и достойна отдельной публикации. Поэтому я расскажу подробнее только о фиче, которая будет полезна во всех проектах:
Обработка ошибок
У акторов есть иерархия — её можно представить в виде дерева. У каждого актора есть родитель и могут быть «дети».

Akka.NET documentation Copyright 2013-2018 Akka.NET project
Для каждого актора можно установить Supervision strategy — что делать, если у «детей» что-то пошло не так. Например, «прибить» актор, у которого возникли проблемы, а затем создать новый актор того же типа и поручить ему ту же работу.
Для примера я сделал на Akka.net CRUD приложение, в котором слой «бизнес-логики» реализован на акторах. Задачей этого проекта было узнать, стоит ли использовать акторы в немасштабируемых системах — сделают ли они жизнь лучше или добавят ещё боли.
Как может помочь встроенная обработка ошибок в Akka:
- всё хорошо, приложение работает,
- с репозиторием что-то случилось, и теперь он отдаёт результат только 1 раз из 5,
- я настроил Supervision strategy на «пробуй 10 раз за секунду»,
- приложение снова работает (хоть и медленнее), и у меня есть время разобраться в чем дело.
Тут возникает соблазн сказать: «Да ладно, я и сам такую обработку ошибок напишу, зачем какие-то акторы городить?». Справедливое замечание, но только если точек отказа мало.
И немного кода. Так выглядит инициализация системы акторов в IoC контейнере:
public Container()
{
system = ActorSystem.Create("MySystem");
var echo = system.ActorOf<EchoActor>("Echo");
//stop initialization if something is wrong with actor system
var alive = echo.Ask<bool>(true, TimeSpan.FromMilliseconds(100)).Result;
container = new WindsorContainer();
//search for dependencies
//register controllers
//register ActorSystem
propsResolver = new WindsorDependencyResolver(container, (ActorSystem)system);
system.AddDependencyResolver(propsResolver);
actorSystemWrapper = new ActorSystemWrapper(system, propsResolver);
container.Register(Component.For<IActorRefFactory>().Instance(actorSystemWrapper));
container.Register(Component.For<IDependencyResolver>().Instance(propsResolver));
}
EchoActor — самый простой актор, который возвращает значение отправителю:
public class EchoActor : ReceiveActor
{
public EchoActor()
{
Receive<bool>(flag =>
{
Sender.Tell(flag);
});
}
}
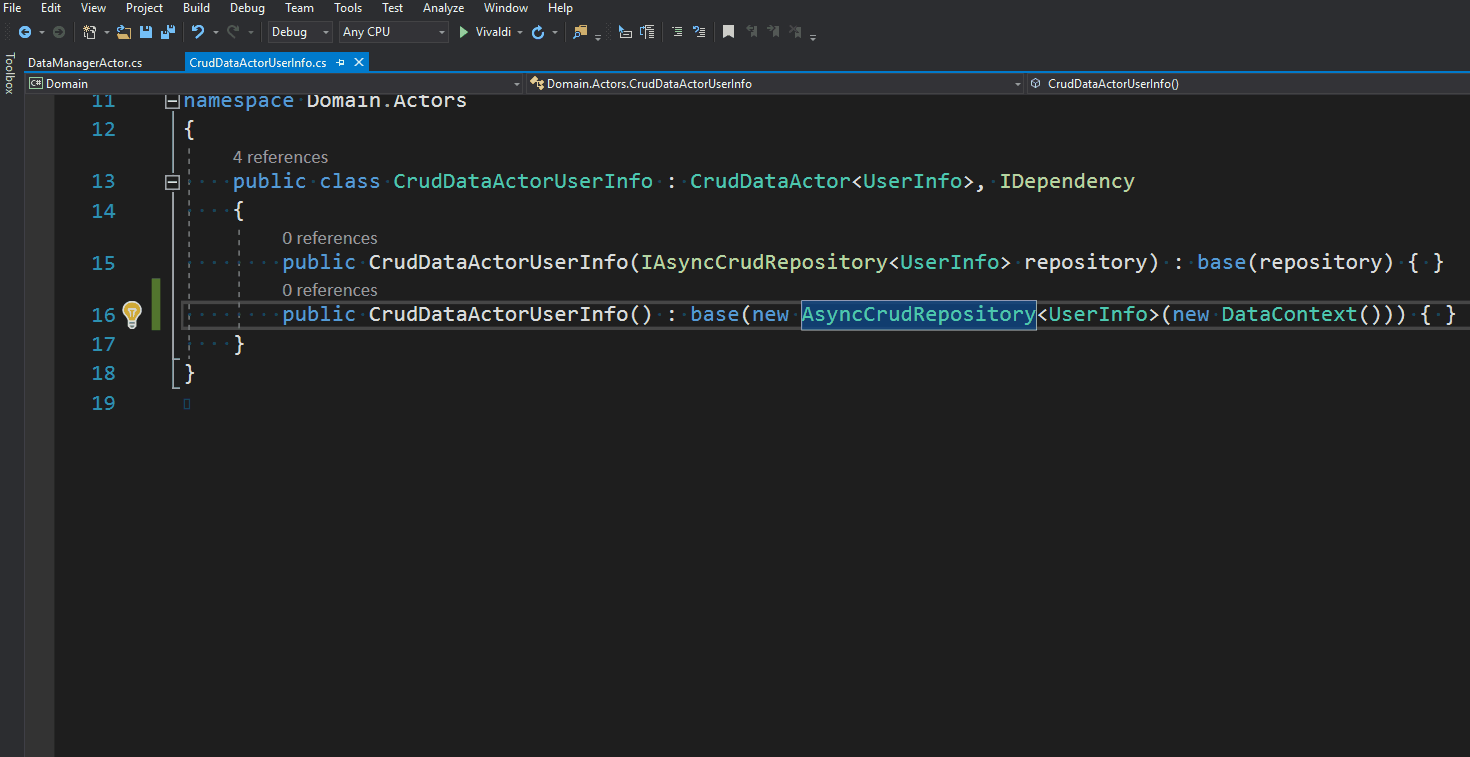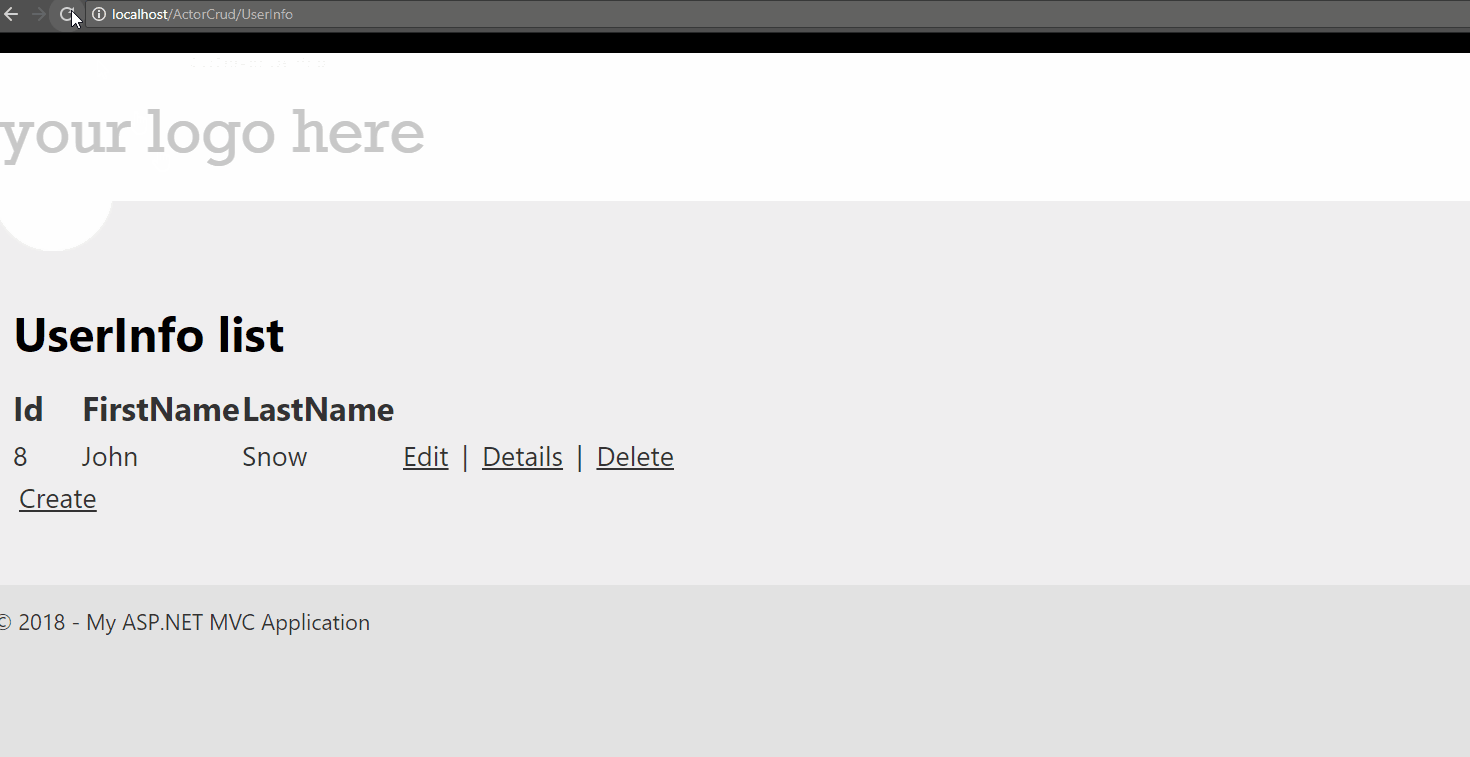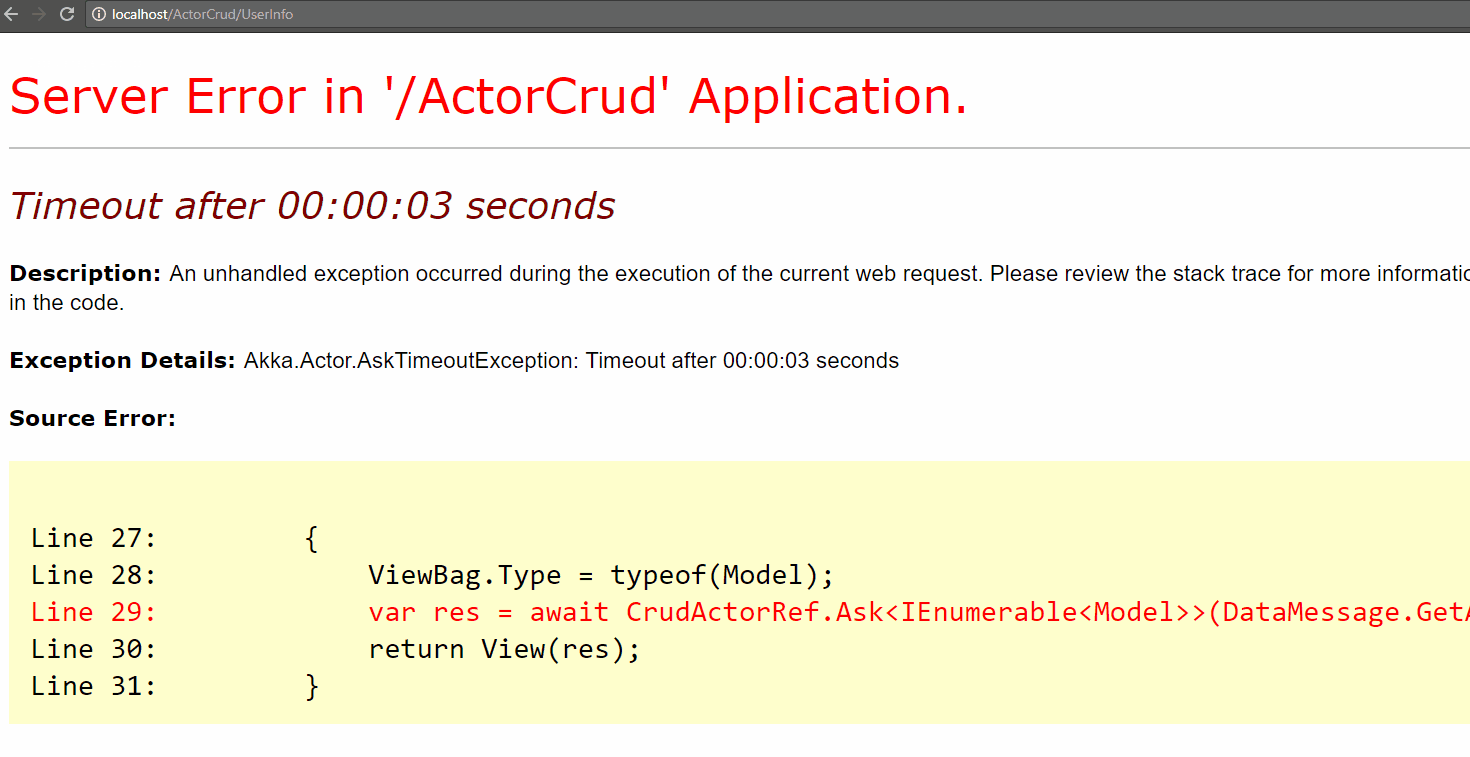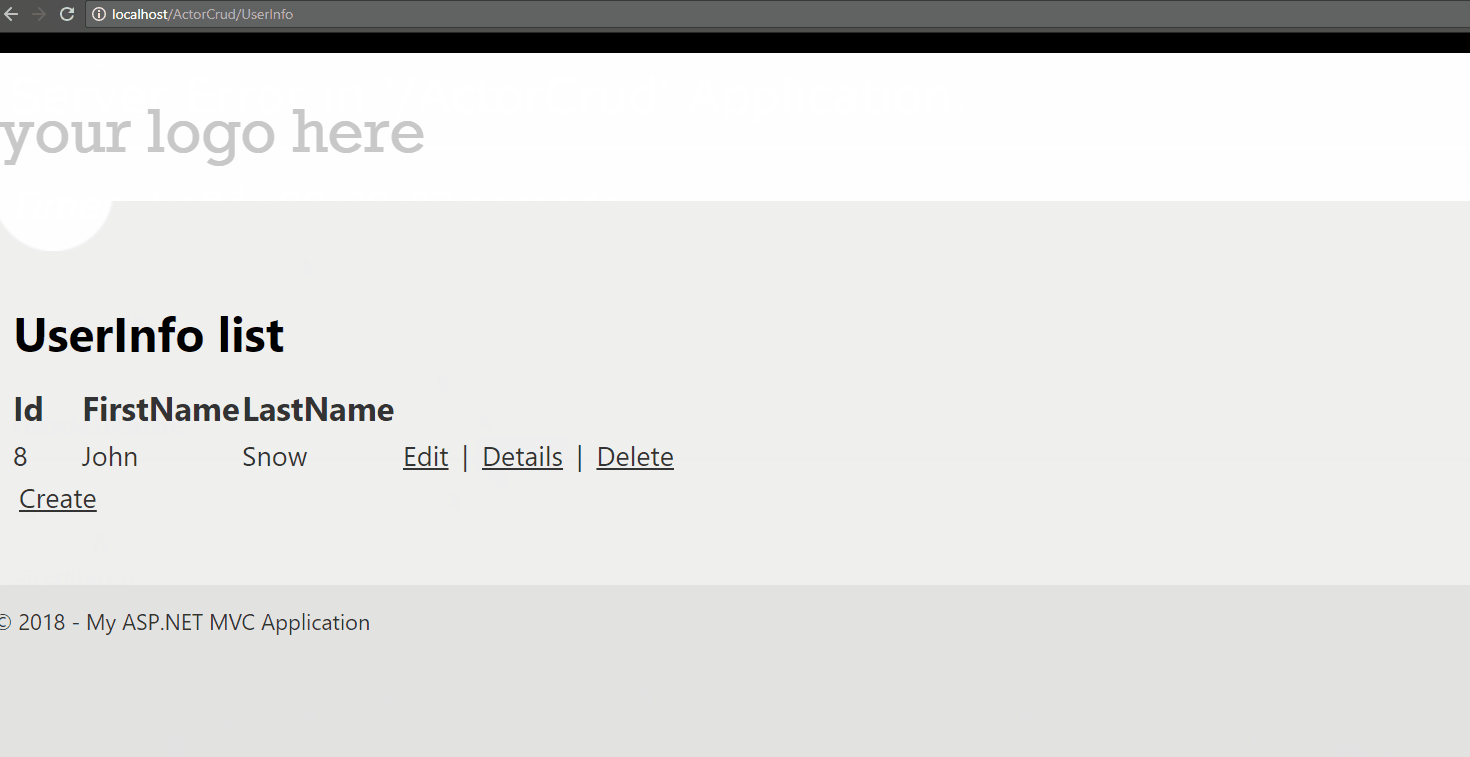
Для связи акторов с «обычным» кодом используется команда Ask:
public async Task<ActionResult> Index()
{
ViewBag.Type = typeof(Model);
var res = await CrudActorRef.Ask<IEnumerable<Model>>(DataMessage.GetAll<Model>(), maxDelay);
return View(res);
}Итого
Похимичив с акторами, могу сказать:
- К ним стоит присмотреться, если нужна масштабирумость
- Для сложной бизнес-логики лучше их не использовать из-за
- странного Dependency Injection. Для инициализации актора с нужными зависимостями нужно сначала создать объект Props, потом отдать его ActorSystem для создания актора нужного типа. Для создания Props при помощи IoC контейнеров (например Castle Windsor или Autofac) есть готовые обёртки — DependencyResolver’ы. Но я столкнулся с тем, что IoC контейнер пытался управлять временем жизни зависимостей, и через какое-то время система тихо отваливалась.
* Возможно, вместо инъекции зависимости в объект стоит эту зависимость оформить как child актор. - проблем с типизацией. ActorRef ничего не знает о типе актора, на который ссылается. То есть во время компиляции неизвестно, может актор обработать сообщение данного типа или нет.
- странного Dependency Injection. Для инициализации актора с нужными зависимостями нужно сначала создать объект Props, потом отдать его ActorSystem для создания актора нужного типа. Для создания Props при помощи IoC контейнеров (например Castle Windsor или Autofac) есть готовые обёртки — DependencyResolver’ы. Но я столкнулся с тем, что IoC контейнер пытался управлять временем жизни зависимостей, и через какое-то время система тихо отваливалась.
Часть 2: Реактивные потоки
А теперь перейдём к более популярной и полезной теме — реактивным потокам. Если с акторами в процессе работы можно никогда не повстречаться, то Rx потоки обязательно пригодятся как во фронтенде, так и в бэкенде. Их реализация есть почти во всех современных языках программирования. Я буду приводить примеры на RxJs, так как в наше время даже бэкенд программистам порой приходится что-то делать на JavaScript.

Rx-потоки есть для всех популярных языков программирования
“Introduction to Reactive Programming you've been missing” by Andre Staltz, по лицензии CC BY-NC 4.0
Чтобы объяснить, что такое реактивный поток, я начну с Pull и Push коллекций.
| Single return value | Multiple return values | |
|---|---|---|
| Pull Synchronous Interactive |
T | IEnumerable<T> |
| Push Asynchronous Reactive |
Task<T> | IObservable<T> |
Pull коллекции — это то, к чему мы все привыкли в программировании. Самый яркий пример — массив.
const arr = [1,2,3,4,5];В нём уже есть данные, сам он эти данные не поменяет, но может отдать по запросу.
arr.forEach(console.log);Также перед тем, как что-то делать с данными, можно их как-то обработать.
arr.map(i => i+1).map(I => “my number is ”+i).forEach(console.log);А теперь давайте представим, что изначально в коллекции нет данных, но она обязательно сообщит о том, что они появились (Push). И в то же время мы всё так же можем к этой коллекции применять нужные трансформации.
Например:
source.map(i => i+1).map(I => “my number is ”+i).forEach(console.log);Когда в source появится значение, например, 1, console.log выведет “my number is 1”.
Как это работает:
Появляется новая сущность — Subject (или Observable):
const observable = Rx.Observable.create(function (observer) {
observer.next(1);
observer.next(2);
observer.next(3);
setTimeout(() => {
observer.next(4);
observer.complete();
}, 1000); });Это и есть push-коллекция, которая будет рассылать уведомления об изменении своего состояния.
В данном случае в ней сразу появятся числа 1, 2 и 3, через секунду 4, а затем коллекция «завершится». Это такой особый тип события.
Вторая сущность — это Observer. Он может подписаться на события Subject’a и что-то сделать с полученными данными. Например:
observable.subscribe(x => console.log(x));
observable.subscribe({
next: x => console.log('got value ' + x),
error: err =>
console.error('something wrong occurred: ' + err),
complete: () => console.log('done'),
});
observable
.map(x => ‘This is ‘ + x)
.subscribe(x => console.log(x));Тут видно, что у одного Subject может быть много подписчиков.
Выглядит несложно, но пока не совсем понятно, для чего это нужно. Я дам ещё 2 определения, которые нужно знать, работая с реактивными потоками, а затем покажу на практике, как они работают и в каких ситуациях раскрывается весь их потенциал.
Cold observables
- Уведомляют о событиях, когда на них кто-то подписывается.
- Весь поток данных отправляется заново каждому подписчику независимо от времени подписки.
- Данные копируются для каждого подписчика.
Что это значит: допустим в компании (Subject) решили устроить раздачу подарков. Каждый сотрудник (Observer) приходит на работу и получает свою копию подарка. Никто не остаётся обделённым.
Hot observables
- Пытаются уведомлять о событии независимо от наличия подписчиков. Если на момент события не было подписчиков — данные теряются.
Пример: утром в компанию привозят горячие пирожки для сотрудников. Когда их привозят, все жаворонки летят на запах и разбирают пирожки на завтрак. А совам, пришедшим позже, пирожков уже не достаётся.
В каких ситуациях использовать реактивные потоки?
Когда есть поток данных, распределённый во времени. Например, пользовательский ввод. Или логи из какого-либо сервиса. В одном из проектов я видел самописный логгер, который собирал события за N секунд, а затем единовременно записывал всю пачку. Код аккумулятора занимал страницу. Если бы использовались Rx потоки, то это было бы намного проще:
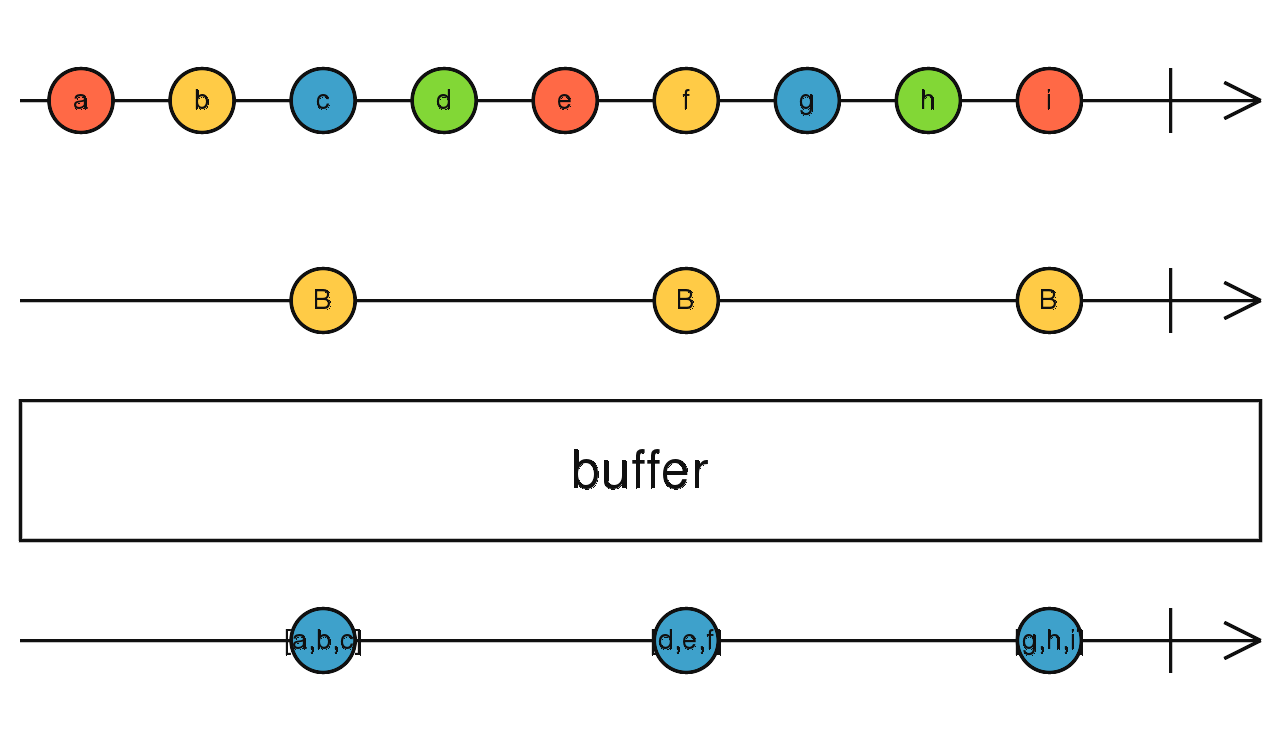
“RxJs Reference / Observable, documentation licensed under CC BY 4.0.
(тут много примеров и картинки, поясняющие, что делают различные операции с реактивными потоками)
source.bufferTime(2000).subsribe(doThings); И, наконец, пример использования.
Распознавание мышиных жестов при помощи Rx потоков
В старой Опере или её духовном наследнике — Vivaldi — было управление браузером при помощи мышиных жестов.
То есть нужно распознавать движения мышью вверх/вниз, вправо/влево и их комбинации. Это можно написать без Rx потоков, но код будет сложным и трудноподдерживаемым.
А вот как это выглядит с Rx потоками:
Начну с конца — задам, какие данные и в каком формате я буду искать в исходной последовательности:
//gestures to look for
const gestures = Rx.Observable.from([
{ name: "Left",
sequence: Rx.Observable.from([{ x: -1, y: 0 }]) },
{ name: "Right",
sequence: Rx.Observable.from([{ x: 1, y: 0 }]) },
{ name: "Up",
sequence: Rx.Observable.from([{ x: 0, y: -1 }]) },
{ name: "Down", sequence:
Rx.Observable.from([{ x: 0, y: 1 }]) },
{ name: "Down+Up", sequence:
Rx.Observable.from([{ x: 0, y: 1 }, { x: 0, y: -1 }]) },
{ name: "Up+Right", sequence:
Rx.Observable.from([{ x: 0, y: -1 }, { x: 1, y: 0 }]) }
]);Это единичные векторы и их комбинации.
Далее нужно преобразовать события мыши в Rx потоки. Во всех Rx библиотеках есть встроенные инструменты для превращения стандартных ивентов в Observables.
const mouseMoves = Rx.Observable.fromEvent(canvas, 'mousemove'),
mouseDowns = Rx.Observable.fromEvent(canvas, 'mousedown'),
mouseUps = Rx.Observable.fromEvent(canvas, 'mouseup');Далее, я группирую координаты мыши по 2 и нахожу их разницу, получая смещение мыши.
const mouseDiffs = mouseMoves
.map(getOffset)
.pairwise()
.map(pair => {
return { x: pair[1].x-pair[0].x, y: pair[1].y-pair[0].y }
});И группирую эти движения, используя события 'mousedown' и 'mouseup'.
const mouseGestures = mouseDiffs
.bufferToggle(mouseDowns, x => mouseUps)
.map(concat);Функция concat вырезает слишком короткие движения и группирует движения, примерно совпадающие по направлению.
function concat(values) {//summarize move in same direction
return values.reduce((a, v) => {
if (!a.length) {
a.push(v);
} else {
const last = a[a.length - 1];
const lastAngle = Math.atan2(last.x, last.y);
const angle = Math.atan2(v.x, v.y);
const angleDiff = normalizeAngle(angle - lastAngle);
const dist = Math.hypot(v.x, v.y);
if (dist < 1) return a;//move is too short – ignore
//moving in same direction => adding vectors
if (Math.abs(angleDiff) <= maxAngleDiff) {
last.x += v.x;
last.y += v.y;
} else {
a.push(v);
}
}
return a;
}, []);
}Если движение по оси X или Y слишком короткое, оно обнуляется. А затем от полученных координат смещения остается только знак. Таким образом, получаются единичные векторы, которые мы искали.
const normalizedMouseGestures = mouseGestures.map(arr =>
arr.map(v => {
const dist = Math.hypot(v.x, v.y);//length of vector
v.x = Math.abs(v.x) > minMove && Math.abs(v.x) * treshold > dist ? v.x : 0;
v.y = Math.abs(v.y) > minMove && Math.abs(v.y) * treshold > dist ? v.y : 0;
return v;
})
).map(arr =>
arr
.map(v => { return { x: Math.sign(v.x), y: Math.sign(v.y) }; })
.filter(v => Math.hypot(v.x, v.y) > 0)
);Результат:
gestures.map(gesture =>
normalizedMouseGestures.mergeMap(
moves =>
Rx.Observable.from(moves)
.sequenceEqual(gesture.sequence, comparer)
).filter(x => x).mapTo(gesture.name)
).mergeAll().subscribe(gestureName => actions[gestureName]());При помощи sequenceEqual можно сравнить полученные движения с исходными и, если есть совпадение, выполнить определённое действие.

> Поиграть с жестами можно тут
Обратите внимание, что, кроме распознавания жестов, здесь есть ещё отрисовка как изначальных, так и нормализованных движений мыши на HTML canvas. Читаемость кода от этого не страдает.
Из чего следует ещё одно преимущество — функционал, написанный при помощи Rx потоков, может быть легко дополнен и расширен.
Итог
- Библиотеки с Rx потоками есть почти для всех языков программирования.
- Rx потоки стоит использовать, когда есть поток событий, растянутый во времени (например, пользовательский ввод).
- Функционал, написанный при помощи Rx потоков, может быть легко дополнен и расширен.
- Значимых недостатков я не нашёл.
Комментарии (19)

timon_aeg
12.12.2018 16:23Хотелось бы сравнения с нативными потоками, кроме очевидной ленивости.

conKORD Автор
12.12.2018 16:39С какими именно и в каком языке программирования?
Тут важен контекст, так как поток можно перевести как thread, или подумать что речь идет, например, о java stream API.timon_aeg
12.12.2018 17:25Со стримами, в той же ноде. Как я вижу, обе концепции решают одинаковую задачу.
sAntee
12.12.2018 17:581) субъективно легче использовать, больше функций из коробки, более легкая обработка слияний потоков (разные варианты — flatMap, switchMap, concatMap, предлагающие разные варианты на все случаи жизни)
2) сходное API в разных языках (ну и можно один и тот же код шарить между клиентом и сервером, например)
3) стримы как будто бы больше ориентированы на работу с потоками данных, всякие кодировки, буферы и т.д. Rx же — потоками событий/состояний системы (в качестве входного потока можно использовать например setInterval). Хорошо стакается, например, с Redux
conKORD Автор
12.12.2018 18:19[быстро читает документацию к стримам в ноде]
По назначению:
Стримы в ноде больше предназначены для IO операций — взять данные из read потока и сразу записать во write поток по частям (chunk).
Rx больше для трансформации и построения сложных цепочек событий.
По сути:
Стримы это скорее pull коллеции. У них можно вызвать read что-бы, например, прочитать следующую часть файла.
Rx — push коллекции, которые сами уведомляют когда что-то происходит.
mayorovp
13.12.2018 09:27Отличия от стримов в ноде:
1. У стримов нет такого набора комбинаторов из коробки;
2. У стрима не может быть нескольких читателей;
3. Стримы не распространяют ошибки по конвейеру автоматически;
4. Стримы поддерживают backpressure, в отличии от rx.
evocatus
12.12.2018 18:10«В отличие от обычных объектов, акторы не могут вызывать методы друг друга.
Акторы могут передавать информацию только через неизменяемые сообщения»
Это именно те объекты и то ООП, которое придумал Алан Кей.
worldmind
Честно говоря ничего понятнее не стало про эти потоки, в чем разница/выгода например в сравнении с короутинами в том же питоне (async/await)?
conKORD Автор
async/await используются когда нужно получить только одно значение.
Если их много — то вместа множества await лучше использовать Observable.
mcferden
Для получения нескольких значений можно использовать асинхронные генераторы.
Тут же суть скорее в том, что корутины не обладают тем самым свойством реактивности. Они не способны реагировать на поступающие события, а могут только активно запрашивать данные из источника. Чтобы поверх них реализовать реактивность, нужна отдельная блокирующая очередь сообщений, но даже в таком случае логика обработки данных будет инвертированной.
worldmind
Чего это корутины не обладают? Это не от них зависит, если источник умеет пушить уведомления, то короутины могут отрабатывать по приходу сообщения.
mayorovp
Им для этого потребуется дополнительная структура, которая будет накапливать в себе события и операции запроса очередного события, и будет сопоставлять их друг с другом. Без подобного преобразователя обрабатывать поступающие сообщения корутины в общем случае не могут.
Ну и нагрузка на память от такого использования корутин будет куда больше, ведь на каждый шаг обработки события требуется несколько уникальных объектов.
sAntee
Давайте на примере. У вас строка поиска, которая должна предлагать варианты автозаполнения, подгруженные с сервака. Наивная имплементация делается просто — при изменении строки делать запрос, возвращать результат через колбек/Promise/Task/что-там-awaitable-в-вашем-языке.
Теперь несколько моментов (допустим набираю habr):
Решение на Rx (в JS):
Я плохо знаком с питоном, можеть быть у вас там еще красивее это решается. Пример скорее про async/await в JS или .NET
worldmind
Уже чуток понятнее, хотя задача весьма специфическая, не уверен, что таких случаем значительное количество.
technic93
Отличный пример, наконец-то понятно и на практике. А не сферические обзервабле в вакууме. Пойду искать как сделать этот debounce для сигнала в моем поделим на Qt.