
Вторая статья из цикла "Test-Driven Development приложений на Spring Boot" и в этот раз я буду говорить про тестирование доступа к базе данных, важного аспекта интеграционного тестирования. Я расскажу как через тесты определять интерфейс будущего сервиса для доступа к данным, как использовать встраиваемые in-memory базы для тестирования, работать с транзакциями и загружать тестовые данные в базу.
Я не буду много говорить про TDD и тестирование вообще, всех желающих приглашаю почитать первую статью — Как построить пирамиду в багажнике или Test-Driven Development приложений на Spring Boot / Хабр.
Начну, как и в прошлый раз, с небольшой теоретической части, и перейду к end-to-end тесту.
Пирамида тестирования
Для начала, маленькое, но необходимое, описание такой важной сущности в тестировании, как The Test Pyramid или пирамида тестирования.
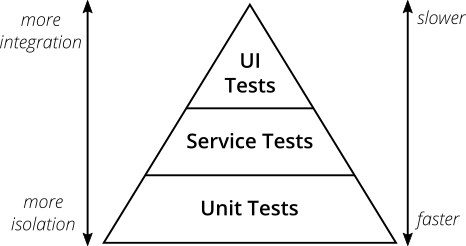
(взято с сайта The Practical Test Pyramid)
Пирамидой тестирования называется подход, когда тесты организуются в несколько уровней.
- UI (или end-to-end, E2E) тестов мало и они медленные, но тестируют реальное приложение — никаких моков и тестовых двойников. На этом уровне часто мыслит бизнес и здесь обитают все BDD фреймворки (см. Cucumber в предыдущей статьей).
- За ними идут интеграционные тесты (сервисные, компонентные — терминология у каждого своя), которые уже фокусируются на конкретном компоненте (сервисе) системы, изолируя его от остальных компонентов через моки / двойники, но по прежнему проверяющие интеграцию с реальными внешними системами — эти тесты подключаются к базе, посылают REST запросы, работаю с очередью сообщений. По-сути, это тесты которые проверяют интеграцию бизнес логики с внешним миром.
- В самом низу находятся быстрые юнит-тесты, которые тестируют минимальные блоки кода (классы, методы) в полной изоляции.
Spring помогает с написанием тестов для каждого уровня — даже для unit-тестов, хотя это может звучать странно, ведь в мире юнит-тестов никакого знания про фреймворк вообще существовать не должно. После написания E2E теста я как раз покажу, как Spring позволяет даже такие чисто "интеграционные" вещи, как контроллеры, тестировать в изоляции.
Но начну я с самой вершины пирамиды — медленного UI теста, которые стартует и тестирует полноценное приложение.
End-to-end test
Итак, новая фича:
Feature: A list of available cakes
Background: catalogue is updated
Given the following items are promoted
| Title | Price |
| Red Velvet | 3.95 |
| Victoria Sponge | 5.50 |
Scenario: a user visiting the web-site sees the list of items
Given a new user, Alice
When she visits Cake Factory web-site
Then she sees that "Red Velvet" is available with price ?3.95
And she sees that "Victoria Sponge" is available with price ?5.50И здесь сразу интересный аспект — что делать с предыдущим тестом, про приветствие на главной странице? Он вроде уже не актуален, после запуска сайта на главной уже будет каталог, а не приветствие. Здесь нет однозначного ответа, я бы сказал — зависит от ситуации. Но главный совет — не привязывайтесь к тестам! Удаляйте, когда они теряют актуальность, переписывайте, чтобы было проще читать. Особенно E2E тесты — это должна быть, по-сути, живая и актуальная спецификация. В моем случае, я просто удалил старый тесты, и заменил их новыми, используя некоторые предыдущие шаги и добавив несуществующие.
Теперь же я подошел к важному моменту — выбор технологии для хранения данных. В соответствии с lean подходом, я бы хотел отложить выбор до самого последнего момента — когда я точно будут знать, реляционная модель или нет, какие требование к консистентности, транзакционности. В общем случае, для этого есть решения — например, создание тестовых двойников и различных in-memory хранилищ, но пока я не хочу усложнять статью и сразу выберу технологию — реляционные базы данных. Но чтобы сохранить хоть какую-то возможность выбора БД, я добавлю абстракцию — Spring Data JPA. JPA сама по себе достаточно абстрактная спецификация для доступа к реляционным базам, а Spring Data делает её использование еще проще.
Spring Data JPA по умолчанию использует Hibernate в качестве провайдера, но поддерживает и другие технологии, например EclipseLink и MyBatis. Для людей не очень знакомых с Java Persistence API — JPA это как бы интерфейс, а Hibernate класс, его реализующий.
Итак, чтобы добавить поддержку JPA я добавил пару зависимостей:
implementation('org.springframework.boot:spring-boot-starter-data-jpa')
runtime('com.h2database:h2')В качестве базы данных я буду использовать H2 — встраиваемую базу данных, написанную на Java, с возможностью работать в in-memory режиме.
Используя Spring Data JPA я сразу определяю интерфейс для доступа к данным:
interface CakeRepository extends CrudRepository<CakeEntity, String> { }И сущность:
@Entity
@Builder
@AllArgsConstructor
@Table(name = "cakes")
class CakeEntity {
public CakeEntity() {
}
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
Long id;
@NotBlank
String title;
@Positive
BigDecimal price;
@NotBlank
@NaturalId
String sku;
boolean promoted;
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
CakeEntity cakeEntity = (CakeEntity) o;
return Objects.equals(title, cakeEntity.title);
}
@Override
public int hashCode() {
return Objects.hash(title);
}
}В описании сущности есть пара не самых очевидных вещей.
@NaturalIdдля поляsku. Это поле используется как “натуральный идентификатор” для проверки равенства сущностей — использование всех полей или@Idполя вequals/hashCodeметодах это, скорее, анти-паттерн. О том, как правильно проверять равенство сущностей хорошо написано, например, тут.- Чтобы хоть немного снизить количество boilerplate кода, я использую Project Lombok — annotation processor для Java. Он позволяет добавлять разные полезные вещи, вроде
@Builder— чтобы автоматически генерить билдер для класса и@AllArgsConstructorчтобы создать конструктор для всех полей.
Реализация интерфейса будет предоставлена автоматически Spring Data.
Вниз по пирамиде
Теперь время спуститься на следующий уровень пирамиды. В качестве эмпирического правила, я бы рекомендовал всегда начинать с e2e теста, потому, что это позволит определить "конечную цель" и границы новой фичи, но дальше строгих правил нет. Не обязательно писать сначала интеграционный тест, перед тем, как перейти на юнит-уровень. Просто чаще всего получается, что так удобнее и проще — и вполне естественно спускаться "вниз".
Но конкретно сейчас, я бы хотел сразу нарушить это правило и написать юнит-тест, который поможет определить интерфейс и контракт нового компонента, который пока не существует. Контроллер должен вернуть модель, которую заполнит из некоего компонента X, и я написал такой тест:
@ExtendWith(MockitoExtension.class)
class IndexControllerTest {
@Mock
CakeFinder cakeFinder;
@InjectMocks
IndexController indexController;
private Set<Cake> cakes = Set.of(new Cake("Test 1", "?10"),
new Cake("Test 2", "?10"));
@BeforeEach
void setUp() {
when(cakeFinder.findPromotedCakes()).thenReturn(cakes);
}
@Test
void shouldReturnAListOfFoundPromotedCakes() {
ModelAndView index = indexController.index();
assertThat(index.getModel()).extracting("cakes").contains(cakes);
}
}Это чистый юнит-тест — никаких контекстов, никаких баз данных тут нет, только Mockito для моков. И этот тест как раз хорошая демонстрация, как Spring помогает юнит тестам — контроллер в Spring MVC это просто класс, методы которого принимают параметры обычных типов и возвращают POJO объекты — View Models. Нет ни HTTP запросов, ни ответов, хедеров, JSON, XML — все это будет автоматически применено ниже по стеку, в виде конвертеров и сериализаторов. Да, есть небольшой "намек" на Spring в виде ModelAndView, но это обычный POJO и даже от него при желании можно избавиться, он нужен именно для UI контроллеров.
Я не буду много говорить про Mockito, можно все прочитать в официальной документации. Конкретно в этом тесте есть только интересных моментов — я используюMockitoExtension.classв качестве исполнителя тестов, и он автоматически сгенерит моки для полей, аннотированных@Mockи потом заинжектит эти моки, как зависимости в конструктор для объекта в поле помеченном@InjectMocks. Можно все это сделать вручную, используяMockito.mock()метод и потом создав класс.
И этот тест помогает определить метод нового компонента — findPromotedCakes, список тортов, которые мы хотим показать на главной странице. Он не определяет, что это такое, или как это должно работать с базой. Единственная ответственность контроллера — взять то, что ему передали, и вернуть в определенном поле модели ("cakes"). Но тем не менее, в моем интерфейсе CakeFinder уже есть первый метод, а значит можно писать для него интеграционный тест.
Я сознательно сделал все классы внутри пакетаcakespackage private, чтобы никто, за пределами пакета не смог их использовать. Единственный способ получить данные из базы — это интерфейс CakeFinder, который и есть мой “компонент Х” для доступа к базе. Он становится естественным “коннектором”, который я дальше могу легко замокать, если мне нужно будет тестировать что-то в изоляции и не трогать базу. А его единственная реализация — это JpaCakeFinder. И если, например, в будущем тип базы или источник данных поменяется — то нужно будет добавить реализацию интерфейсаCakeFinder, не меняя код, его использующий.
Интеграционный тест для JPA используя @DataJpaTest
Интеграционные тесты — это хлеб и масло Spring. В нем, вообщем-то, все так здорово сделано для интеграционного тестирования, что разработчики иногда не хотят уходить на юнит-уровень или пренебрегают UI уровнем. Это не плохо и не хорошо — повторюсь, что главная цель тестов — это уверенность. И набора быстрых и эффективных интеграционных тестов может быть достаточно, чтобы эту уверенность предоставить. Однако есть опасность, что эти тесты со временем либо будут медленнее и медленнее, либо просто начнут тестировать компоненты в изоляции, вместо интеграции.
Интеграционные тесты могут запустить приложение, как есть (@SpringBootTest), либо его отдельный компонент (JPA, Web). В моем случае, я хочу написать сфокусированный тест для JPA — поэтому мне нет необходимости конфигурировать контроллеры или любые другие компоненты. За это в Spring Boot Test отвечает аннотация @DataJpaTest. Это мета-аннотация, т.е. она комбинирует сразу несколько разных аннотаций, конфигурирующих разные аспекты теста.
- @AutoConfigureDataJpa
- @AutoConfigureTestDatabase
- @AutoConfigureCache
- @AutoConfigureTestEntityManager
- @Transactional
Сначала расскажу про каждый в отдельности, а потом покажу готовый тест.
@AutoConfigureDataJpa
Загружает целый набор конфигураций и настраивает — репозитории (автоматическая генерация реализаций для CrudRepositories), инструменты миграции базы FlyWay и Liquibase, подключение к БД используя DataSource, менеджер транзакций, и, наконец, Hibernate. По-сути, это просто набор конфигураций, актуальных для доступа к данным — сюда не включены ни DispatcherServlet из Web MVC, ни другие компоненты.
@AutoConfigureTestDatabase
Это один из самых интересных аспектов JPA теста. Эта конфигурация ищет в classpath одну из поддерживаемых embedded баз данных и переконфигурирует контекст, чтобы DataSource указывал на случайно созданную in-memory базу. Так как я добавил зависимость на H2 базу — то больше делать ничего не нужно, просто наличие этой аннотации автоматически для каждого запуска теста предоставит пустую базу, и это просто невероятно удобно.
Стоит помнить, что эта база будет полностью пустой, без схемы. Чтобы сгенерить схему, есть пара вариантов.
- Использовать фичу Auto DDL из Hibernate. Spring Boot Test автоматически поставит это значение в
create-drop, чтобы Hibernate генерировал схему из описание сущностей и удалял ее в конце сессии. Это невероятно мощная фича Hibernate, которая очень полезна для тестов. - Использовать миграции созданные Flyway или Liquibase.
Подробнее про разные подходы к инициализации базы можно прочитать в документации.
@AutoConfigureCache
Просто конфигурирует кэш на использование NoOpCacheManager — т.е. не кешировать ничего. Это полезно, чтобы избежать сюрпризов в тестах.
@AutoConfigureTestEntityManager
Добавляет в контекст специальный объект TestEntityManager, который сам по себе интересный зверь. EntityManager это главный класс JPA, который отвечает за добавление сущностей в сессию, удаление и подобными вещами. Только вот когда, например, в работу вступает Hibernate — добавление сущности в сессию не значит, что будет выполнен запрос в базу, а загрузка из сессии не означает, что будет выполнен select запрос. За счет внутренних механизмов Hibernate реальные операции с базой будут выполнятся в подходящий момент, который определит сам фреймворк. Но в тестах может быть необходимость принудительно послать что-то в базу, ведь цель тестов как раз тестировать интеграцию. И TestEntityManager это просто хелпер, который поможет некоторые операции с базой принудительно выполнится — например, persistAndFlush() заставит Hibernate выполнить все запросы.
@Transactional
Эта аннотация делает все тесты в классе транзакционными, с автоматическим откатом транзакции по завершению теста. Это просто механизм “очистки” базы перед каждым тестом, ведь иначе пришлось бы вручную удалять данные из каждой таблицы.
Должен ли тест управлять транзакцией — это не такой простой и очевидный вопрос, как может показаться. Не смотря на удобство “чистого” состояния базы, наличие@Transactionalв тестах может стать неприятным сюрпризом если “боевой” код не начинает транзакцию сам, а требует существующую. Это может привести к тому, что интеграционный тест пройдет, но при выполнении реального кода из контроллера, а не из теста, в сервисе не будет активной транзакции и метод бросит исключение. Хотя это и выглядит опасно, при наличии высокоуровневых тестов UI тестов, транзакционность тестов не так страшна. На моем опыте я видел только однажды, когда при проходящем интеграционном тесте падал продакшен код, который явно требовал наличие существующей транзакции. Но если все же нужно проверять, что сервисы и компоненты сами правильно управляют транзакциями, можно “перекрыть” аннотацию@Transactionalна тесте с нужным режимом (например, не начинать транзакцию).
Интеграционный тест со @SpringBootTest
Еще хочу отметить, что @DataJpaTest это не уникальный пример фокусного интеграционного теста, еще есть @WebMvcTest, @DataMongoTest и много других. Но одной из самых важных тестовых аннотации остается @SpringBootTest, которая запускает для тестов приложение “как есть” — со всеми настроенными компонентами и интеграциями. Возникает логичный вопрос — если можно запустить приложение целиком, зачем делать фокусные DataJpa тесты, например? Я бы сказал, что строгих правил тут снова нет.
Если возможно запускать приложения каждый раз, изолировать падения в тестах, не перегружать и не переусложнять Setup теста — то конечно можно и нужно использовать @SpringBootTest.
Однако в реальной жизни, приложения могут требовать много разных настроек, подключатся к разным системам, а я бы не хотел, чтобы мои тесты доступа к БД падали, т.к. не настроено подключение к очереди сообщений. Поэтому важно использовать здравый смысл, и если для того, чтобы заставить тест с @SpringBootTest аннотацией работать нужно замокать половину системы — то есть ли смысл тогда вообще в @SpringBootTest?
Подготовка данных для теста
Один из ключевых моментов для тестов, это подготовка данных. Каждый тест должен выполнятся в изоляции, и подготавливать окружение перед запуском, приводя систему в исходное желаемое состояние. Самый простой вариант это сделать — использовать @BeforeEach / @BeforeAll аннотации и добавлять записи в базу там, используя репозиторий, EntityManager или TestEntityManager. Но есть еще один вариант, который позволяет запустить подготовленный скрипт или выполнить нужный SQL-запрос, это аннотация @Sql. Spring Boot Test перед выполнением теста автоматически запустит указанный скрипт, избавив от необходимости добавлять @BeforeAll блок, а об очистке данных позаботиться @Transactional.
@DataJpaTest
class JpaCakeFinderTest {
private static final String PROMOTED_CAKE = "Red Velvet";
private static final String NON_PROMOTED_CAKE = "Victoria Sponge";
private CakeFinder finder;
@Autowired
CakeRepository cakeRepository;
@Autowired
TestEntityManager testEntityManager;
@BeforeEach
void setUp() {
this.testEntityManager.persistAndFlush(CakeEntity.builder().title(PROMOTED_CAKE)
.sku("SKU1").price(BigDecimal.TEN).promoted(true).build());
this.testEntityManager.persistAndFlush(CakeEntity.builder().sku("SKU2")
.title(NON_PROMOTED_CAKE).price(BigDecimal.ONE).promoted(false).build());
finder = new JpaCakeFinder(cakeRepository);
}
...
}Red-green-refactor цикл
Не смотря на такое количество текста, для разработчика тест все еще выглядит как простой класс с аннотацией @DataJpaTest, но надеюсь, что я смог показать, как много полезного происходит под капотом, о чем разработчику можно не думать. Теперь можно перейти к TDD циклу и в этот раз я покажу пару итераций TDD, с примерами рефакторинга и минимального кода. Чтобы было понятнее, я крайне советую посмотреть историю в Git, там каждый коммит это отдельный и значимый шаг с описанием что и как он делает.
Подготовка данных
Я использую подход с @BeforeAll / @BeforeEach и вручную создаю, все записи в базе. Пример с @Sql аннотацией вынесен в отдельный класс JpaCakeFinderTestWithScriptSetup, он дублирует тесты, чего быть, разумеется, не должно, и существует с единственной целью продемонстрировать подход.
Исходное состояние системы — есть две записи в системе, один торт участвует в промоушене и должен быть включен в результат, возвращенный методом, второй — нет.
Первый тест интеграционный тест
Первый тест самый простой — findPromotedCakes должен включать описание и цену торта, участвующего в промоушене.
Red
@Test
void shouldReturnPromotedCakes() {
Iterable<Cake> promotedCakes = finder.findPromotedCakes();
assertThat(promotedCakes).extracting(Cake::getTitle).contains(PROMOTED_CAKE);
assertThat(promotedCakes).extracting(Cake::getPrice).contains("?10.00");
}Тест, разумеется, падает — дефолтная реализация возвращает пустой Set.
Green
Естественным желаем будет сразу писать фильтрацию, делать запрос в базу с where и так далее. Но следуя практике TDD, я должен написать минимальный код чтобы тест прошел. И этот минимальный код — вернуть все записи в базе. Да, так просто и банально.
public Set<Cake> findPromotedCakes() {
Spliterator<CakeEntity> cakes = this.cakeRepository.findAll()
.spliterator();
return StreamSupport.stream(cakes, false).map(
cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price)))
.collect(Collectors.toSet());
}
private String formatPrice(BigDecimal price) {
return "?" + price.setScale(2, RoundingMode.DOWN).toPlainString();
}Наверное кое-кто возразит, что тут можно сделать тест зеленым даже без базы — просто захардкодить результат, ожидаемый тестом. Я периодически слышу такой аргумент, но думаю, все понимают, что TDD это не догма и не религия, нет смысла доводить это до абсурда. Но если уж очень хочется — то можно, например, рандомизировать данные на установке, чтобы их было не захардкодить.
Refactor
Я здесь не вижу особого рефакторинга, поэтому для этого конкретного теста эту фазу можно пропустить. Но я бы все равно не рекомендовал игнорировать эту фазу, лучше каждый раз в “зеленом” состоянии системы остановиться и подумать — а можно ли что-то порефакторить чтобы сделать лучше и проще?
Второй тест
А вот второй тест уже проверит, что не promoted торт не попадет в результат, возвращаемый findPromotedCakes.
@Test
void shouldNotReturnNonPromotedCakes() {
Iterable<Cake> promotedCakes = finder.findPromotedCakes();
assertThat(promotedCakes).extracting(Cake::getTitle)
.doesNotContain(NON_PROMOTED_CAKE);
}Red
Тест, ожидаемо, падает — в базе две записи и код просто возвращает их всех.
Green
И снова можно задуматься — а какой минимальный код можно написать, чтобы тест прошел? Раз уже есть stream и его сборка — можно просто добавить туда filter блок.
public Set<Cake> findPromotedCakes() {
Spliterator<CakeEntity> cakes = this.cakeRepository.findAll()
.spliterator();
return StreamSupport.stream(cakes, false)
.filter(cakeEntity -> cakeEntity.promoted)
.map(cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price)))
.collect(Collectors.toSet());
}Перезапускаем тесты — интеграционные тесты теперь зеленые. Настал важный момент — за счет комбинации юнит-теста контроллера и интеграционного теста для работы с БД моя фича готова — и UI тест теперь проходит!
Refactor
И раз все тесты зеленые — настало время рефакторинга. Думаю, не нужно пояснять, что фильтрация в памяти — не лучшая идея, лучше это делать в базе. Чтобы это сделать, я добавил новый метод в CakesRepository — findByPromotedIsTrue:
interface CakeRepository extends CrudRepository<CakeEntity, String> {
Iterable<CakeEntity> findByPromotedIsTrue();
}Для этого метода Spring Data автоматически сгенерил метод, который выполнит запрос вида select from cakes where promoted = true. Подробнее про генерацию запросов можно почитать в документации к Spring Data.
public Set<Cake> findPromotedCakes() {
Spliterator<CakeEntity> cakes = this.cakeRepository.findByPromotedIsTrue()
.spliterator();
return StreamSupport.stream(cakes, false).map(
cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price)))
.collect(Collectors.toSet());
}Это хороший пример, какую гибкость дает интеграционное тестирование и подход “черного ящика”. Если бы репозиторий был замокан, то добавить туда новый метод не меняя тесты было не невозможно.
Подключение к production базе
Чтобы добавить немного “реалистичности” и показать, как можно разделять конфигурацию для тестов и основного приложения, я добавлю конфигурацию доступа к данным для “продакшен” приложения.
Добавляется все традиционно секцией в application.yml:
datasource:
url: jdbc:h2:./data/cake-factory
Это автоматически сохранит данные в файловой системе в папке ./data. Замечу, что в тестах этой папки создано не будет — @DataJpaTest автоматически заменит подключение к файловой базе на случайную базу в памяти благодаря наличию @AutoConfigureTestDatabase аннотации.
Две полезные вещи, которые могут пригодится — это файлыdata.sqlиschema.sql. При запуске приложения, Spring Boot проверит наличие этих файлов в ресурсах и выполнит эти скрипты при их наличии. Эта фича может быть полезной при локальной разработке и прототипировании, в реальных базах, разумеется, нужно использовать инструменты миграции.
Заключение
Итак, в этот раз я показал как через тесты определить интерфейс сервисе для доступа к данным, как написать интеграционный тест, и как писать минимальный код в TDD цикле.
В следующей статье я добавлю Spring Security — покажу как тестировать приложение для разных пользователей и ролей и какие инструменты для этого предоставляет Spring, а так же как определять границы теста.
Комментарии (10)

Hixon10
24.12.2018 22:12Спринговые аннотации — это, конечно же, хорошо, но если хочется тестироваться против реальной БД, то есть замечательная встроенная PostgreSQL:
github.com/zonkyio/embedded-database-spring-test
Она прям в одно косание интегрируется со спринговым проектом, а еще умеет накатывать Flyway миграции.alek_sys Автор
25.12.2018 00:56Ну судя по тому, что я вижу, это просто wrapper для запуска Postgres в рамках тестов + попытка реализовать свой AutoconfigureTestDatabase. В этом, конечно, нет ничего плохого, просто непонятно, какую проблему это решает, которую не решает стандартная тестовая библиотека Spring? И Flyway, и Liquibase
@DataJpaTestконфигурирует.
Если уж хочется принести полноценный embedded postgres, я бы скорее порекомендовал TestContainers, там хотя бы будет изолированный сервер, а не просто запускалка локальной базы Postgres.
Hixon10
25.12.2018 01:00Тестконтейнеры — это очень замечательно, если ваш CI позволяет запустить это. Порой бывает, что Докер в докере, в докере (и так далее), и Тест контейнеры отпадают, как вариант, из-за сложности интеграции.
Я же ничего не путаю, но Spring сам по себе не запустит embedded postgresql? То есть, это будет просто какая-то in-memory БД, в которой детали реализации будут отличатся от PG?alek_sys Автор
25.12.2018 01:13Не запустит, но и не должен, это не его обязанность. Вообще немного лукаво называть
embedded-database-spring-testembedded — это самый обычный сервер Postgres (точнее, некий lightweight bundles of PostgreSQL binaries with reduced size), библиотека его просто запускает. Почему бы тогда не иметь локальный сервер Postgres и в нем создавать тестовую базу — не совсем понятно. Ну и если уж совсем-совсем надо запустить Postgres и TestContainers не подходят, то лучше использовать проверенные и поддерживаемые библиотеки, вроде https://github.com/yandex-qatools/postgresql-embedded.Hixon10
25.12.2018 01:171) Ага, от яндекса — вторая из двух известных
2) Уточню — моя ссылка — это просто обёртка над github.com/opentable/otj-pg-embedded — одни из двух известных решений
3) Почему не использовать локальную БД — такое решение плохо живёт в CI, где надо запускать «здесь и сейчас», без пробрасываняи базы данных в нужный контейнер.alek_sys Автор
25.12.2018 09:27Да, убедили, полезная вещь чтобы упомянуть. Добавлю в статью, спасибо!
poxvuibr
25.12.2018 01:47Почему бы тогда не иметь локальный сервер Postgres и в нем создавать тестовую базу — не совсем понятно.
Удобно для CI, можн удобно для разработки, потому что postgresql локально можно и не ставить, удобно потому, что не надо чистить базу между запусками тестов, то есть решает дилемму с аннотацией Transctional
poxvuibr
25.12.2018 01:43Ну судя по тому, что я вижу, это просто wrapper для запуска Postgres в рамках тестов + попытка реализовать свой AutoconfigureTestDatabase.
Эта штука скачивает дистрибутив postgresql, разворачивает и создаёт базу с нуля. А не использует уже существующий экземляр постгреса.
В этом, конечно, нет ничего плохого, просто непонятно, какую проблему это решает, которую не решает стандартная тестовая библиотека Spring?
Проблему тестирования системы в связке с живой СУБД Postgresql вместо in memory баз. Зачастую то, что работает с абстрактной базой — не будет работать с конкретной. Или наоборот.
И Flyway, и Liquibase @DataJpaTest конфигурирует.
Liquibase надо тестировать на той СУБД, которая используется в системе.
alatushkin
Так получилось что уже продолжительное время я не пользуюсь стримами java (перешел на kotlin) и подзабыл api, но вот это место мне не совсем понятно:
Для чего через spliterator? Разве нельзя сразу findAll().stream().map()...?
+Могу путать но разве в SpringDataRepository не появилась поддержка Stream<*> в качестве результата?
alek_sys Автор
Да, отличное замечание. Стандартные методы
CrudRepositoryвозвращаютIterableи я решил вернуть его же, хотя причины на это нет — Spring Data JPA может вернуть и Stream, и даже Set. Обновлю статью и код.