
На Хабре достаточно много статей про разработку игр, однако среди них очень мало статей, которые касаются “закулисных” тем. Одной из таких тем является организация доставки, собственно, игры большому количеству пользователей на протяжении длительного времени (год, два, три). Несмотря на то, что для некоторых задача может показаться тривиальной, я решил поделиться своим опытом хождения по граблям в этом деле для одного конкретного проекта. Кому интересно — прошу.
Маленькое отступление про разглашение информации. Большинство компаний очень ревностно относятся к тому, чтобы “внутренняя кухня” не становилась доступна для широкой публики. Почему — не знаю, но что есть — то есть. В данном конкретном проекте — The Universim — мне повезло и CEO компании Crytivo Inc. (ранее — Crytivo Games Inc.) Алекс Кошельков оказался абсолютно вменяемым в подобном вопросе, так что у меня есть возможность поделиться опытом с остальными.
Немного про патчер сам по себе
Я длительное время участвую в разработке игр. В некоторых — как гейм-дизайнер и программист, в некоторых — как сплав сисадмина и программиста (я не люблю термин “девопс”, так как он не точно отражает суть выполняемых мною задач в таких проектах).
В конце 2013 года (ужас, как летит время) я задумался о доставке новых версий (билдов) пользователям. Конечно же, на тот момент существовало множество решений для подобной задачи, но желание сделать свой продукт и тяга к “велосипедостроительству” победила. К тому же мне захотелось изучить C# поглубже — поэтому я решил сделать свой патчер. Забегая вперёд, скажу, что проект удался, более десятка компаний его использовали и используют в своих проектах, некоторые обратились с просьбой сделать версию с учётом именно их пожеланий.
Классическое решение подразумевает создание дельта-пакетов (или диффов) от версии к версии. Однако, подобный подход доставляет неудобство как игрокам-тестерам, так и разработчикам — в одном случае, для того, чтобы получить последнюю версию игры, необходимо пройти через всю цепочку обновлений. Т.е. игроку надо стягивать последовательно некое количество данных, которое он(а) никогда не будет использовать, а разработчику хранить у себя на сервере (или серверах) кучу устаревших данных, которые когда-то кому-то из игроков могут потребоваться.
В другом случае — необходимо скачать именно патч для своей версии до последней, ну а разработчику надо весь этот зоопарк патчей содержать у себя. Некоторые реализации систем патчей требуют наличия определённого ПО и выполнение некоторой логики на серверах — что тоже создаёт дополнительную головную боль разработчикам. Ко всему прочему, зачастую разработчики игр вовсе не хотят заниматься чем-то, не относящимся непосредственно к разработке самой игры. Скажу даже больше — большинство не являются специалистами, которые могут заниматься настройкой серверов по раздачи контента — это просто не их область деятельности.
С учётом всего этого, мне хотелось придумать решение, которое было бы максимально простым как для пользователей (которые хотят поиграть побыстрее, а не танцевать с патчами разных версий), так и для разработчиков, которым надо писать игру, а не выяснять, что и почему не обновляется у очередного пользователя.
Зная, как работают некоторые протоколы синхронизации данных — когда анализируются данные на клиенте и передаются только изменения с сервера — я решил использовать такой же подход.
К тому же, на практике, от версии к версии в течение всего времени разработки, многие файлы игры меняются незначительно — текстура там, моделька сям, немного звуков.
В результате, мне показалось логичным каждый файл в директории игры рассматривать как набор блоков данных. При выпуске очередной версии, билд игры анализируется, строится карта блоков и сами файлы игры сжимаются поблочно. На клиенте производится анализ существующих блоков и скачивается только разница.
Изначально, патчер планировался как модуль в Unity3D, однако, выяснилась одна неприятная деталь, которая заставила меня пересмотреть это. Дело в том, что Unity3D — полностью независимое от вашего кода приложение (движок). И во время работы движка — открыта целая куча файлов, что создаёт проблемы, в том случае, когда вы хотите их обновить.
В Unix-подобных системах перезаписать открытый файл (если только он не заблокирован специально) не представляет никаких проблем, а вот в Windows без танцев с бубном подобный “финт ушами” не проходит. Именно поэтому я сделал патчер в виде отдельного, приложения, не подгружающего ничего, кроме системных библиотек. Де-факто, сам патчер получился полностью независимой от движка Unity3D утилитой, что не помешало, однако, добавить его в Unity3D store.
Алгоритм работы патчера
Итак, разработчики выпускают новые версии с определённой периодичностью. Игроки эти версии хотят заполучить. Цель разработчика — обеспечить этот процесс с минимальными затратами и с минимальной головной болью для игроков.
Со стороны разработчика
При подготовке патча алгоритм действий патчера выглядит так:
0 Создать дерево файлов игры с их атрибутами и контрольными суммами SHA512
0 Для каждого файла:
> Разбить содержимое на блоки.
> Сохранить контрольную сумму SHA256.
> Сжать блок и добавить его в карту блоков файла.
> Сохранить адрес блока в индексе.
0 Сохранить дерево файлов с их контрольными суммами.
0 Сохранить файл с данными о версии.
Разработчику остаётся загрузить полученные файлы на сервер.
Со стороны игрока
На клиенте патчер проделывает следующее:
0 Копирует себя в файл с другим именем. Это позволит обновить исполняемый файл патчера при необходимости. Затем управление передаётся копии и оригинал завершает работу.
0 Скачивает файл с версией и сравнивает с локальным файлом версии.
0 Если сравнение не выявило разницы — можно играть, у нас последняя версия. Если есть разница — следует переход к следующему пункту.
0 Скачивает дерево файлов с их контрольными суммами.
0 Для каждого файла в дереве с сервера:
> Если файл есть — считает его контрольную сумму (SHA512). Если нет — считает, что он есть, но пустой (т.е. состоит из сплошных нулей) и также считает его контрольную сумму.
> Если сумма локального файла не совпадает с контрольной суммой файла из последней версии:
> Создаёт локальную карту блоков и сравнивает с картой блоков с сервера.
> Для каждого локального блока, отличающегося от удалённого — скачивает с сервера сжатый блок и перезаписывает его локально.
0 При отсутствии ошибок — обновляет файл версии.
Размер блока данных я сделал кратным 1024 байтам, после некоторого количества тестов, я решил, что проще оперировать блоками по 64КБ. Хотя универсальность в коде осталась:
#region DQPatcher class
public class DQPatcher
{
// some internal constants
// 1 minute timeout by default
private const int DEFAULT_NETWORK_TIMEOUT = 60000;
// maximum number of compressed blocks, which we will download at once
private const UInt16 MAX_COMPRESSED_BLOCKS = 1000;
// default block size, you can use range from 4k to 64k,
//depending on average size of your files in the project tree
private const uint DEFAULT_BLOCK_SIZE = 64 * 1024;
...
#region public constants and vars section
// X * 1024 bytes by default for patch creation
public static uint blockSize = DEFAULT_BLOCK_SIZE;
...
#endregion
....Если делать блоки маленькими — то на клиенте требуется меньше изменений, когда самих изменений мало. Однако, возникает другая проблема — размер индексного файла увеличивается обратно пропорционально уменьшению размера блока — т.е. если мы оперируем блоками по 8КБ, то индексный файл будет в 8 раз больше, чем при блоках в 64КБ.
SHA256/512 для файлов и блоков я выбрал из следующих соображений: скорость по сравнению с (устаревшими) MD5/SHA128 отличается незначительно, а и блоки и файлы надо всё равно прочитать. И вероятность коллизий у SHA256/512 значительно меньше, чем у MD5/SHA128. Если быть совсем занудой — она есть и в данном случае, но она настолько мала, что этой вероятностью можно пренебречь.
Дополнительно, клиент учитывает следующие моменты:
> Блоки данных могут быть сдвинуты в разных версиях, т.е. локально у нас есть блок номер 10, а на сервере у нас это блок номер 12, или наоборот. Это учитывается, чтобы не скачивать лишних данных.
> Блоки запрашиваются не по одному, а группами — клиент старается объединять диапазоны необходимых блоков и запрашивает их с сервера при помощи Range — заголовка. Это также минимизирует нагрузку на сервер:
// get compressed remote blocks of data and return it to the caller
// Note: we always operating with compressed data, so all offsets are in the _compressed_ data file!!
// Throw an exception, if fetching compressed blocks failed
public byte[] GetRemoteBlocks(string remoteName, UInt64 startByteRange, UInt64 endByteRange)
{
if (verboseOutput) Console.Error.WriteLine("Getting partial content for [" + remoteName + "]");
if (verboseOutput) Console.Error.WriteLine("Range is [" + startByteRange + "-" + endByteRange + "]");
int bufferSize = 1024;
byte[] remoteData;
byte[] buffer = new byte[bufferSize];
HttpWebRequest httpRequest = (HttpWebRequest)WebRequest.Create(remoteName);
httpRequest.KeepAlive = true;
httpRequest.AddRange((int)startByteRange, (int)endByteRange);
httpRequest.Method = WebRequestMethods.Http.Get;
httpRequest.ReadWriteTimeout = this.networkTimeout;
try
{
// Get back the HTTP response for web server
HttpWebResponse httpResponse = (HttpWebResponse)httpRequest.GetResponse();
if (verboseOutput) Console.Error.WriteLine("Got partial content length: " + httpResponse.ContentLength);
remoteData = new byte[httpResponse.ContentLength];
Stream httpResponseStream = httpResponse.GetResponseStream();
if (!((httpResponse.StatusCode == HttpStatusCode.OK) || (httpResponse.StatusCode == HttpStatusCode.PartialContent))) // rise an exception, we expect partial content here
{
RemoteDataDownloadingException pe = new RemoteDataDownloadingException("While getting remote blocks:\n" + httpResponse.StatusDescription);
throw pe;
}
int bytesRead = 0;
int rOffset = 0;
while ((bytesRead = httpResponseStream.Read(buffer, 0, bufferSize)) > 0)
{
// if(verboseOutput) Console.Error.WriteLine("Got ["+bytesRead+"] bytes of remote data block.");
Array.Copy(buffer, 0, remoteData, rOffset, bytesRead);
rOffset += bytesRead;
}
if (verboseOutput) Console.Error.WriteLine("Total got: [" + rOffset + "] bytes");
httpResponse.Close();
}
catch (Exception ex)
{
if (verboseOutput) Console.Error.WriteLine(ex.ToString());
PatchException pe = new PatchException("Unable to fetch URI " + remoteName, ex);
throw pe;
}
return remoteData;
}Само-собой получилось, что клиент может быть прерван в любой момент и при последующем запуске он де-факто продолжит свою работу, а не будет скачивать всё с нуля.
Вот тут можно посмотреть видео, иллюстрирующее работу патчера на проекте-примере Angry Bots:
Про то, как был организован патчинг игровой вселенной
В сентябре 2015 года со мной связался Алекс Кошельков и предложил присоединиться к проекту — им требовалось решение, которое бы позволило обеспечивать 30 тысяч (с хвостиком) игроков ежемесячными обновлениями. Начальный размер игры в архиве — 600 мегабайт. До того, как обратиться ко мне, были попытки сделать свой собственный вариант с использованием Electron, но всё упёрлось в ту же самую проблему открытых файлов (к слову, нынешняя версия Electron-а это умеет) и некоторые другие. Также никто из разработчиков не понимал, как это всё будет работать — мне предоставили несколько велосипедных конструкций, серверная часть отсутствовала вообще — ею хотели заняться после того, как будут решены все остальные задачи.
Дополнительно, потребовалось решить задачу, как не допустить утечку ключей игроков — дело в том, что ключи были для платформы Steam, хотя самой игры в Steam ещё не было в открытом доступе. Раздавать игру требовалось строго по ключу — хотя и оставался шанс, что игроки могли делиться ключом игры с друзьями, но этим можно было пренебречь, так как в случае появления игры в Steam ключ можно активировать только один раз.
В обычной версии патчера, дерево данных для патча выглядит так:
./
|-- linux
| |-- 1.0.0
| `-- version.txt
|-- macosx
| |-- 1.0.0
| `-- version.txt
`-- windows
|-- 1.0.0
`-- version.txt
Мне требовалось сделать так, чтобы доступ был только у тех, кто обладает правильным ключом.
Я придумал следующее решение — для каждого ключа получаем его хеш (SHA1), затем используем его в качестве пути для доступа к данным патча на сервере. На сервере же переносим данные патча на уровень выше docroot-а, а в сам docroot добавляем символические ссылки (symlinks) на директорию с данными патча. Символические ссылки имеют те же имена, что и хеши ключей, только разбитые на несколько уровней (чтобы облегчить работу файловой системы), т.е. хеш 0f99e50314d63c30271…...ade71963e7ff будет представлен как
./0f/99/e5/0314d63c30271…..ade71963e7ff -----> /full/path/to/patch-data/
Таким образом, не требуется раздавать сами ключи тому, кто будет заниматься поддержкой серверов обновлений — достаточно передать их хеши, которые абсолютно бесполезны самим игрокам.
Для добавления новых ключей (или удаления старых) — достаточно добавить/удалить соответствующую символическую ссылку.
При такой реализации, проверка самого ключа явно нигде не производится, получение 404 ошибки на клиенте говорит о том, что ключ неверный (или был деактивирован).
Нужно отметить, что доступ по ключу не является полноценной DRM-защитой — это просто ограничения на этапе (закрытого) альфа- и бета- тестирования. А перебор легко отсекается средствами самого веб-сервера (по крайней мере в Nginx, который я использую).
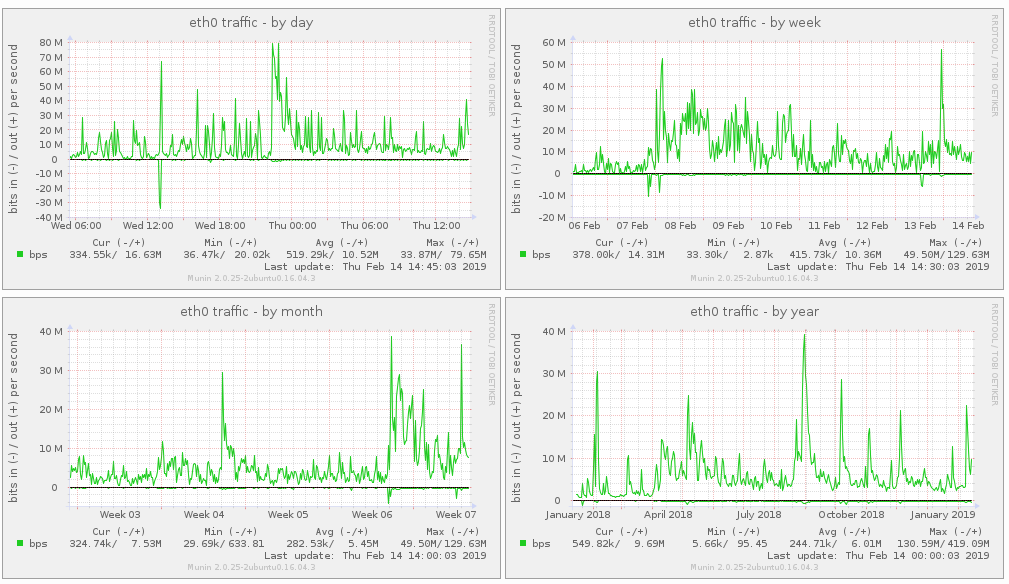
В месяц старта, только за первый день было отдано около 2.5 ТБ трафика, в последующие — примерно столько же раздаётся в среднем за месяц:

Поэтому, если вы планируете раздавать много контента — лучше всего заранее рассчитать, во сколько вам это обойдётся. По личным наблюдениям — самый дешёвый трафик у европейских хостеров, самый дорогой (я бы сказал “золотой”) у Амазона и Гугла.
На практике экономия трафика в среднем за год на проекте The Universim огромная — сравните приведённые выше цифры. Разумеется, если у пользователя игры нет вообще или она сильно устарела — чуда не случится и ему придётся скачивать очень много данных с сервера — если с нуля — то немного больше, чем занимает игра в архиве. Однако, при ежемесячных обновлениях всё становится очень хорошо. Американское зеркало за неполные 6 месяцев отдало чуть больше 10 ТБ траффика, без использования патчера это значение выросло бы в разы.
Вот так выглядит годичный трафик проекта наглядно:
Несколько слов о самых запоминающихся “граблях”, на которые пришлось наступить в процессе работы над кастомным патчером для игры “The Universim”:
? Самая большая неприятность меня ожидала со стороны антивирусов. Ну не нравятся им приложения, которые что-то там скачивают из Интернета, модифицируют файлы (в том числе и исполняемые), а затем ещё и пытаются запустить скачанное. Некоторые антивирусы не просто блокировали доступ к локальным файлам — они ещё и блокировали сами обращения к серверу обновлений, влезая непосредственно в данные, которые скачивал клиент. Решением стало использовать валидную цифровую подпись для патчера — это резко снижает паранойю у антивирусов, а использование HTTPS протокола вместо HTTP — быстро позволяет избавиться от части ошибок, связанных с любопытством антивирусов.
? Прогресс обновления. Множество пользователей (и заказчиков) хотят видеть прогресс обновления. Приходится импровизировать, так как не всегда можно достоверно показать прогресс без того, чтобы проделывать лишнюю работу. Да и точное время окончания процесса патчинга тоже отображать нельзя — так как сам патчер заранее не обладает данными о том, какие файлы нуждаются в обновлении.
? У огромного количества пользователей из США скорости подключения к серверам из Европы не очень высокие. Перенос сервера обновлений в США решил эту проблему. Для пользователей других континентов мы оставили сервер в Германии. Кстати, трафик в США значительно дороже европейского, в некоторых случаях — в несколько десятков раз.
? Apple не очень хорошо относится к подобному методу установки приложений. Официальная политика — приложения должны устанавливаться только из их магазина. Но вот беда — в магазин не допускаются приложения на стадии альфа- и бета- тестирования. И уж тем более нечего говорить о продающихся сырых приложениях из раннего доступа. Поэтому приходится писать инструкции, как танцевать на маках. Вариант с AppAnnie (тогда они ещё были самостоятельными) не рассматривался из-за ограничение на количество тестеров.
? Работа с сетью достаточно непредсказуема. Для того, чтобы приложение не сдавалось сразу, мне пришлось ввести счётчик ошибок. 9 перехваченных исключений позволяют твёрдо заявить пользователю, что у него есть проблемы с сетью.
? У 32-битных ОС есть ограничения на размеры файлов, которые отображаются в память (Memory Mapped Files — MMF) для каждой нити исполнения и для процесса в целом. Первые версии патчера использовали MMF для ускорения работы, но так как файлы игровых ресурсов могут быть огромными — пришлось от этого подхода отказаться и использовать обычные файловые потоки (file streams). Особой потери производительности, кстати, не наблюдалось — скорее всего из-за упреждающего чтения ОС.
? Надо быть готовым к тому, что пользователи будут жаловаться. Каким бы хорошим ни был бы ваш продукт — всегда найдутся недовольные. И чем больше пользователей у вашего продукта (в случае с The Universim их более 50 тысяч на данный момент) — тем больше в количественном отношении будет жалоб к вам. В процентном отношении это очень маленькое число, но вот в количественном…
Несмотря на то, что в целом проект удался, в нём есть некоторые недостатки:
? Даже при том, что я изначально вынес всю основную логику отдельно, GUI-часть отличается в реализации под MAC и Windows. Версия под Linux проблем не доставила — все проблемы были в основном только при использовании монолитного билда, не требующего Mono Runtime Environment — MRE. Но так как для распространения таких исполняемых файлов надо обладать дополнительной лицензией — решено было отказаться от монолитных билдов и просто требовать наличия MRE. Linux-версия отличается от Windows-версии только поддержкой атрибутов файлов, специфичных для *nix систем. Для своего второго проекта, который будет больше, чем просто патчер, я планирую использовать модульный подход в виде ядра-процесса, которое запускается в фоне и позволяет по локальному интерфейсу управлять всем. А само управление может осуществляться из приложения на базе Electron и ему подобных (или просто из браузера). С любыми рюшечками. Прежде чем говорить о размере дистрибутива таких приложений — посмотрите на размер игр. Демонстрационные (!!!) версии некоторых занимают 5 и более гигабайт в архиве (!!!).
? Используемые сейчас структуры не позволяют сэкономить место, когда игра выпускается для 3 платформ — де-факто, требуется держать 3 копии почти идентичных данных, пусть и сжатых.
? Нынешняя версия патчера не кэширует свою работу — каждый раз все контрольные суммы всех файлов пересчитываются. Можно было бы значительно сократить время, если бы патчер кэшировал результаты для тех файлов, которые уже лежат на клиенте. Но тут есть одна дилемма — если файл будет повреждён (или отсутствовать), но при этом сохранится запись в кэше об этом файле — то патчер его пропустит, что вызовет проблемы.
? Нынешняя версия не умеет работать одновременно с множеством серверов (разве что вы сделаете Round-robin средствами DNS) — хотелось бы перейти к “торрентоподобной” технологии, чтобы можно было одновременно использовать множество серверов. Речи об использовании клиентов как источника данных не идёт, так как это вызывает множество юридических вопросов и проще от этого отказаться изначально.
? Если требуется ограничить доступ к обновлениям — то эту логику придётся реализовывать самостоятельно. Собственно, это сложно назвать недостатком, так как у каждого могут быть свои пожелания по поводу ограничений. Простейшее ограничение с помощью ключей — без какой-либо серверной части — делается достаточно несложно, как я это показал выше.
? Патчер создан только для одного проекта за раз. Если вы хотите построить нечто аналогичное Steam — то тут уже требуется целая система доставки контента. А это уже проект совсем другого уровня.
Сам патчер я планирую выложить в открытый доступ после того, как будет реализовано “второе поколение” — система доставки игрового контента, которая будет включать в себя не только эволюционировавший патчер, но и модуль телеметрии (так как разработчикам надо знать, что делают игроки), модуль облачных сохранений пользовательских данных (Cloud Saves) и некоторые другие модули.
Если у вас некоммерческий проект и вам нужен патчер — напишите мне подробности о вашем проекте и я вам дам его копию бесплатно. Ссылок тут не будет, так как это не хаб “Я пиарюсь”.
С удовольствием отвечу на возникшие вопросы.
Комментарии (8)

Incidence
19.02.2019 22:07В результате, мне показалось логичным каждый файл в директории игры рассматривать как набор блоков данных. При выпуске очередной версии, билд игры анализируется, строится карта блоков и сами файлы игры сжимаются поблочно. На клиенте производится анализ существующих блоков и скачивается только разница.
Как вам уже заметили выше, вы переизобрели торрент-раздачу ) Она примерно по такому принципу и работает.
Greendq Автор
19.02.2019 22:34Скорее не торренты, а rsync/borg, но да, я не изобрёл абсолютно новый подход — я просто скомбинировал имеющиеся у меня знания для построения собственного велосипеда :)

perfect_genius
21.02.2019 10:10Но тут есть одна дилемма — если файл будет повреждён (или отсутствовать), но при этом сохранится запись в кэше об этом файле — то патчер его пропустит
Первоначальная сверка даты создания/изменения файла — не надёжный способ?Greendq Автор
21.02.2019 13:37Абсолютно ненадёжный, это я отбросил на самых ранних стадиях. В некоторых проектах разработчики ставят временные метки по только им понятным принципам. Максимум, что делает патчер с датой создания файлов — выставляет их в то же значение, что у оригинала актуальной версии.
gibson_dev
Делал однажды подобную вещь.
Но несколько проще:
Greendq Автор
В вашем случае не требовалось делать ограничений для тех, кто может скачать билд, как я понимаю?
gibson_dev
Это можно решить уже другими методами при желании — но нет. Тут скорее сам механизм доставки.
Mov_AX_0xDEAD
эффективность торрентов сильно зависит от того как меняются файлы, если данные внутри файлов «двигаются» хоть на один байт, торрент перекачает весь файл