
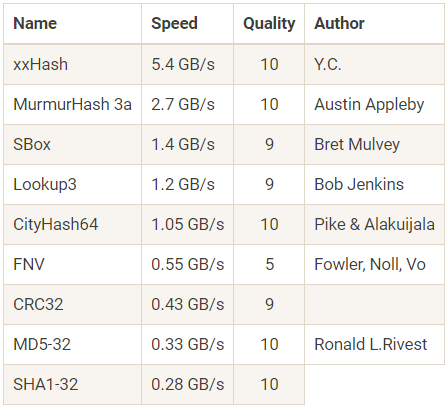
Бенчмарки сделаны в программе SMHasher на Core 2 Duo 3,0 ГГц
На Хабре неоднократно рассказывали про некриптографические хеш-функции, которые на порядок быстрее криптографических. Они применяются там, где важна скорость и нет смысла применять медленные MD5 или SHA1. Например, для построения хеш-таблиц с хранением пар ключ-значение или для быстрой проверки контрольной суммы при передаче больших файлов.
Одно из самых популярных — семейство хеш-функций xxHash, которое появилось около пяти лет назад. Хотя изначально эти хеши задумывались для проверки контрольной суммы при сжатии LZ4, но их стали применять на самых разных задачах. Оно и понятно: достаточно посмотреть на таблицу вверху со сравнением производительности xxHash и некоторых других хеш-функций. В этом тесте xxHash обходит ближайшего конкурента по производительности в два раза. Новая версия XXH3 поднимает планку ещё выше.
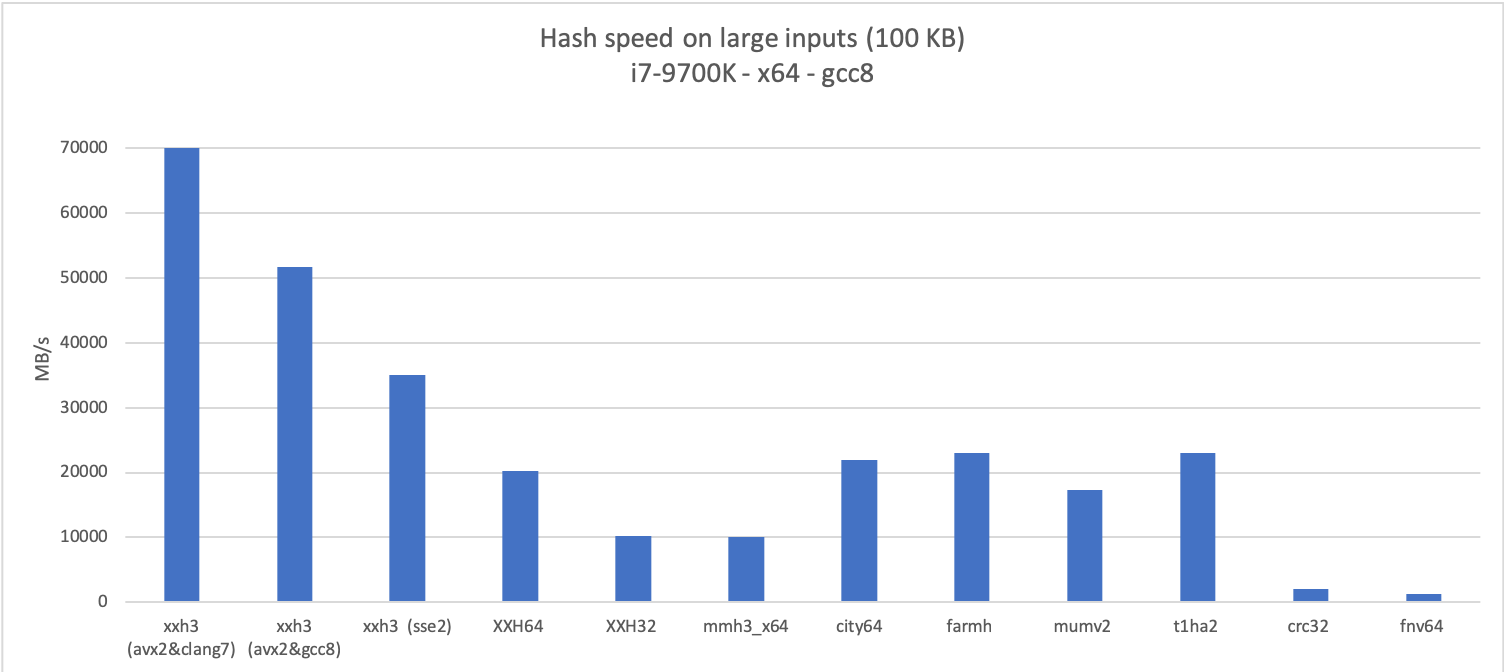
Здесь и далее диаграммы кликабельны
Автор программы Ян Колле (Yann Collet) пишет, что идея усовершенствовать алгоритм появилась в процессе реализации фильтра Блума, который требовал быстрой генерации 64 псевдослучайных бит на основе небольших входных данных переменной длины. В принципе, с этим могла бы справиться стандартная XXH64, но обработка малых входных данных никогда не являлась приоритетом при её разработке. Другими словами, возможна оптимизация. В результате этой оптимизации и появилась новая хэш-функция XXH3, в которой реализованы идеи из некоторых других хэш-алгоритмов. Что самое интересное, XXH3 значительно быстрее всех существующих вариантов xxHash не только на малых входных данных, но практически по всем вариантам использования.
XXH3 устраняет главный недостаток XXH64 — ограничение хеша длиной в 64 бита. Автор говорит, что по этой причине его часто просили выпустить хотя бы 128-битную версию. Так вот, хеш-функция XXH3 теоретически способна генерировать хеши до 256 бит.
В XXH3 внутренний цикл, который оптимально обрабатывается векторизацией. Благодаря этому функция использует аппаратную поддержку на наборах инструкций SSE2, AVX2 и NEON. Производительность зависит от комилятора. Неожиданно оказалось, что версия, скомпилированная clang, намного превосходит остальные. Ян Колле даже подумал, что производительность хеш-функции здесь превысит пропускную способность памяти. Этой версии на графике соответствует пунктирная линия.

В итоге оказалось, что у хеш-функции с поддержкой AVX2 пропускная способность гораздо выше, чем у оперативной памяти, так что важным фактором становится объём кэша. Впрочем, во многих задачах приходится обрабатывать данные, которые уже находятся в кэше, так что работа со скоростью быстрее памяти вполне имеет смысл.
Поддержка инструкций SSE2 позволяет новой хеш-функции значительно обойти XXH32 на 32-битных приложениях, которые по-прежнему часто встречаются в реальном мире (например, байткод WASM).
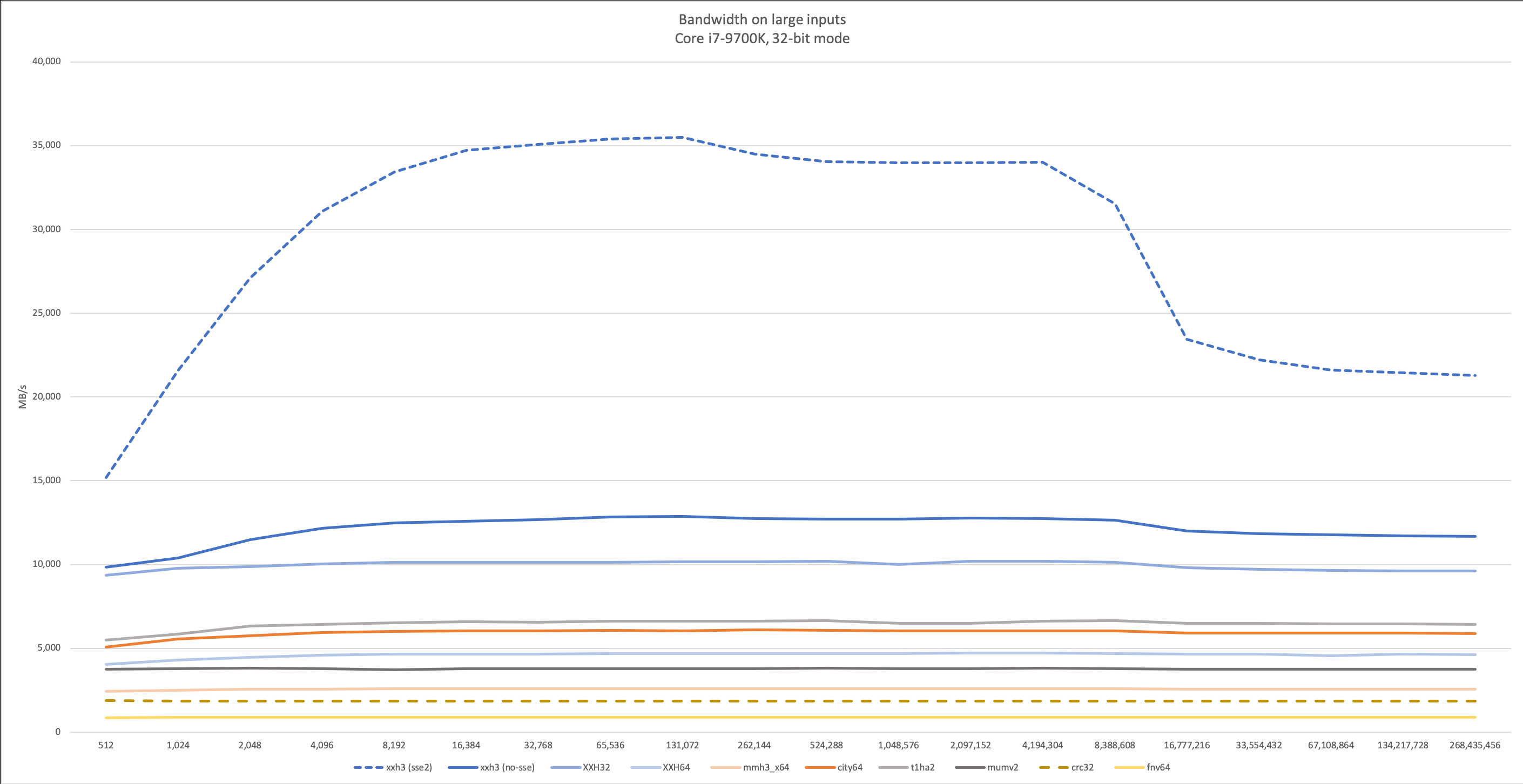
На маленьких входных данных (20-30 байт) хеш-функция XXH3 ненамного, но всё-таки превосходит CityHash от Google, а также FarmHash, которые раньше были явными лидерами.

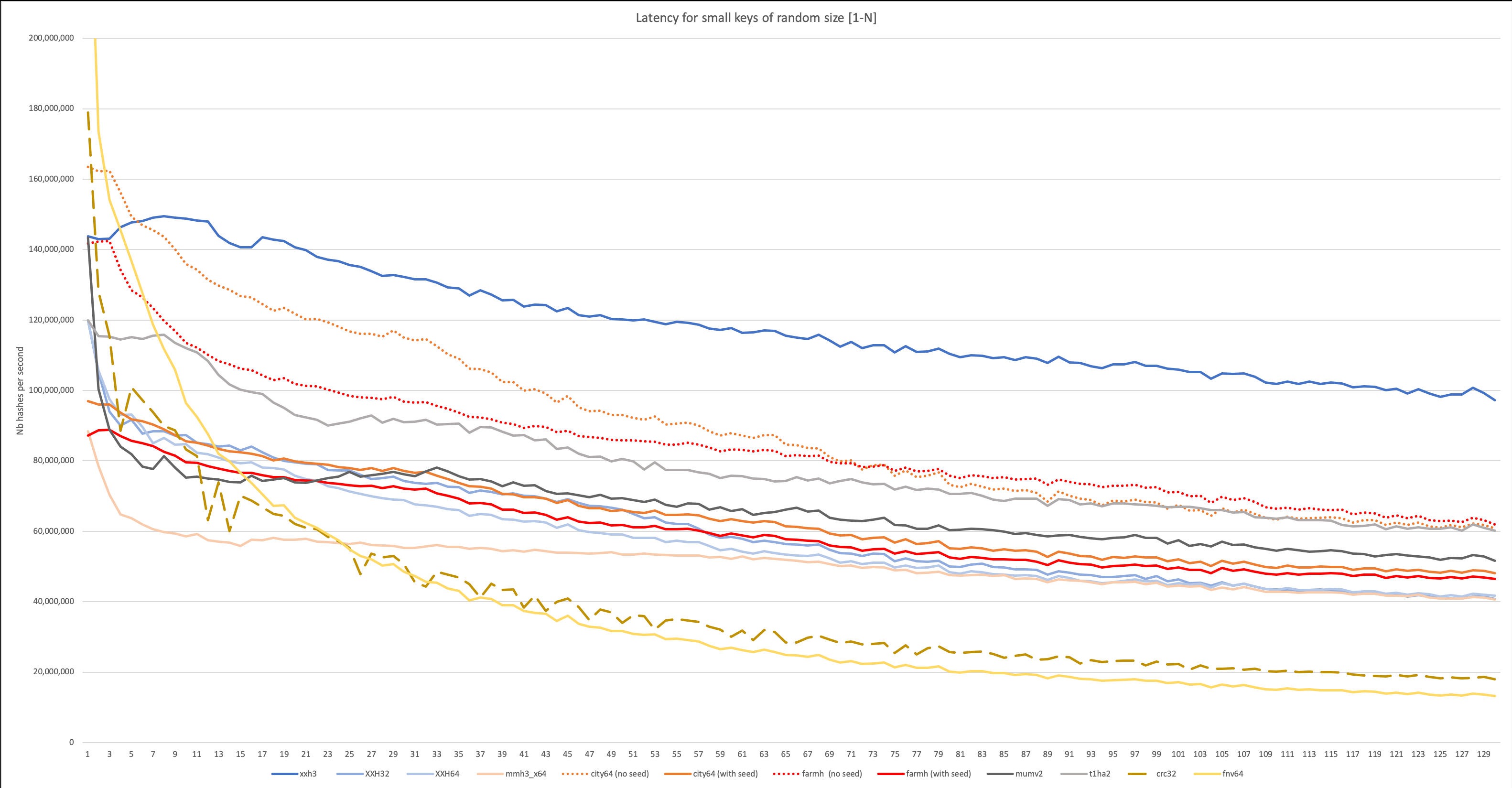
На следующем графике приведены результаты самого реалистичного теста с входными данными переменной длины (случайная величина от 1 до N).

В ещё одном тесте учитывается задержка: здесь хеширование начинается по сигналу. Идея в том, чтобы симулировать реальную рабочую нагрузку, где хеш-функция не работает непрерывно, а вызывается в другими процессами в определённый момент.
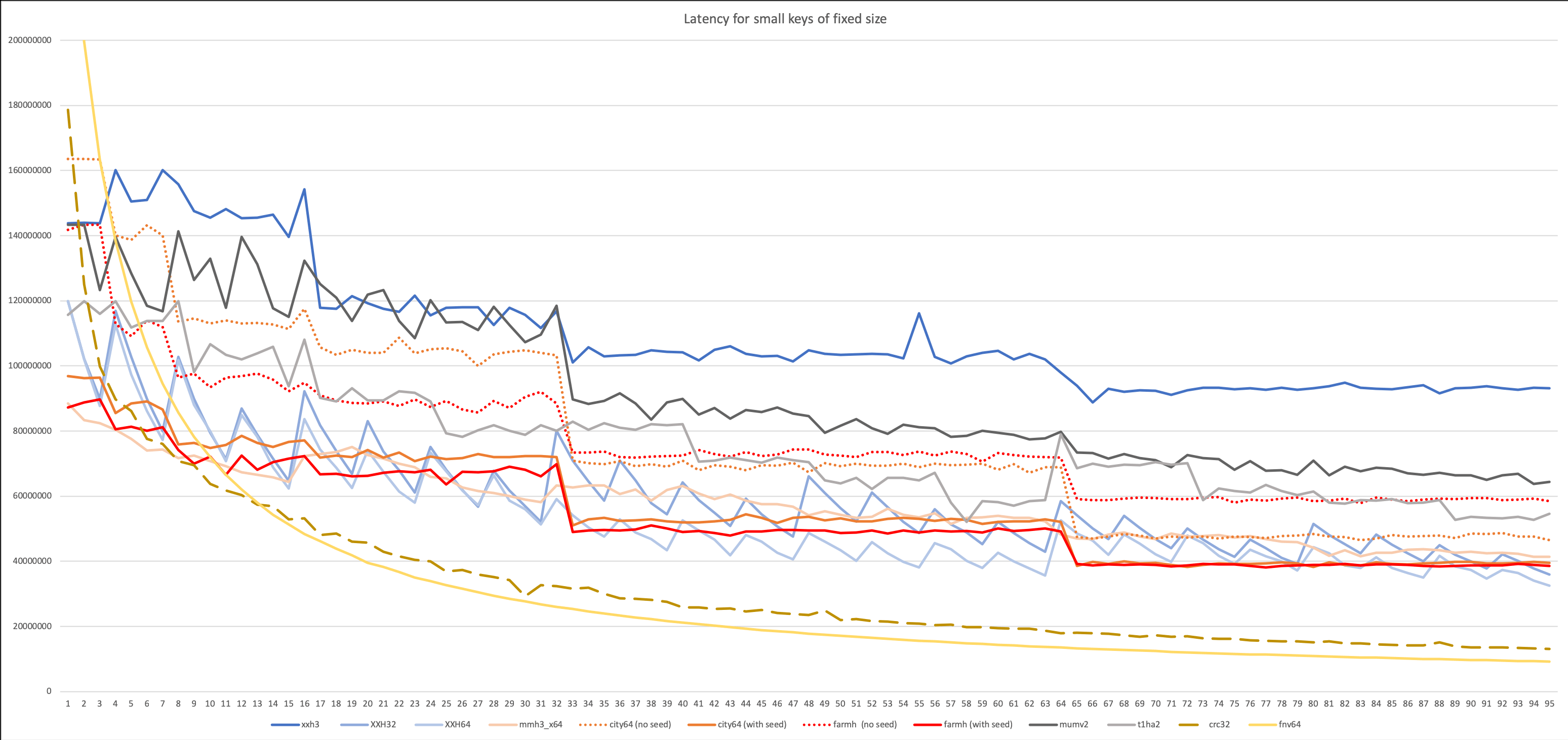
Автор пишет, что данный тест с умножением 64?64=>128 бит отдаёт предпочтение алгоритмам mumv2 от Владимира Макарова и t1ha2 от Лео Юрьева.

Наконец, вот итоговый и самый важный график, который показывает скорость хеширования на входных данных переменной длины с учётом задержки. Он отражает реальное применение хеш-функции, например, в базах данных.
XXH3 вышла в составе пакета xxHash v0.7.0. У неё стоит пометка «экспериментальная», а для разлочки нужно применить макрос
XXH_STATIC_LINKING_ONLY. Автор поясняет, что хеш-функцию пока можно использовать только на тестовых эфемерных данных, но не для реального сохранения хешей. По итогам экспериментального периода и сбора отзывов пользователей функция XXH3 получит стабильный статус в следующей версии xxHash. Сертификаты подписи документов Microsoft Office, Adobe PDF, LibreOffice и др.
Сертификаты подписи документов Microsoft Office, Adobe PDF, LibreOffice и др.GlobalSign представляет широкие возможности по внедрению доверенной цифровой подписи. От настольных, серверных до облачных вариантов реализации. Подробнее
Комментарии (6)

yleo
18.03.2019 13:41+1Не-переносимые реализации (SSE, AVX, AVX2) не совсем корректно сравнивать с переносимыми — получается волшебно большая разница. Соответственно, логично бы добавить в графики результаты t1ha0_aes.
Тем не менее, приятно видеть что t1ha2 уверенно идет на втором месте (за вычетом имеющих проблемы FNV и функций без seed).
В целом здорово что Yann Collet продолжил соревнование, так что постараюсь не отставать с t1ha3 :)
yleo
18.03.2019 14:25На всякий, у xxHash есть некоторые проблемы, причем у всех версий.
Чтобы устранить подобные недостатки (в том числе, еще пример) следует использовать Merkle–Damgard хотя-бы в варианте "fast wide pipe". С точки зрения практической реализации это означает удвоение ширины внутреннего состояния c перекрестным "опылением" его половин на каждом цикле. Также желательно обеспечивать две точки инъекции данных, чтобы не терять энтропию.
Внутри t1ha именно так и сделано (wide pipe с перекрестным перемешиванием и двумя точками инъекции). Тем не менее, свойства t1ha2 не идеальны, так как операции перемешивания сильно упрощены ради скорости. Можно сказать, что именно эти упрощения не позволяют конкурировать с SipHash.
Поэтому, в t1ha3 основное изменением будет именно в этом месте. Кроме этого, будут заменены внутренности t1ha0 (это позволяет задекларированный контракт интерфейса), в том числе вариантов с AES-NI.

firedragon
18.03.2019 19:43Как то один парень из топов сказал. Чуваки вы используете материализованные последовательности и юникс, так какого черта вы требуете что бы ваш DBL был переносим на MS SQL?
Если встает вопрос оптимизации, то уже четко понятно что будет использоваться что то XEON Gold| Platinum или CUDA.
yleo
18.03.2019 21:14+2Попросили сравнить скорость переносимых и SIMD-версий (ну и самому было интересно).
С использованием всех возможностей i7-6700K (GCC 7.3.0 с опцией
-march=native) в перерасчете тактов в GiB/s для частоты процессора 3 ГГц.
На всякий случай поясню — из t1ha-семейства тут только t1ha0(), так именно она изменяет переносимости ради скорости.
Bench for huge keys (262144 bytes): xxHash3 : 26951.000 cycle/hash, 29.180 GiB/s @3.0GHz t1ha0 : 19340.000 cycle/hash, 40.663 GiB/s @3.0GHz
Теперь переносимые реализации хеш-функций, последние три строки — это 32-битные хеши для сопоставления.
На всякий случай поясню — здесь вместо t1ha0() результаты t1ha2_atonce(), так она переносима (и будет вызвана изнутри t1ha0 на CPU без AVX и т.п.):
Bench for huge keys (262144 bytes): xxHash3 : 131694.000 cycle/hash, 5.972 GiB/s @3.0GHz t1ha2_atonce : 55506.000 cycle/hash, 14.168 GiB/s @3.0GHz StadtX : 58764.000 cycle/hash, 13.383 GiB/s @3.0GHz xxhash64 : 65642.208 cycle/hash, 11.981 GiB/s @3.0GHz -- t1ha0_32le : 117699.000 cycle/hash, 6.682 GiB/s @3.0GHz t1ha0_32be : 121929.000 cycle/hash, 6.450 GiB/s @3.0GHz xxhash32 : 131099.000 cycle/hash, 5.999 GiB/s @3.0GHz
glowingsword
18.03.2019 22:30+1Про t1ha2 слышал, xxh64(xxhash64) — юзал. А про это чудо слышу впервые, но автор вроде тот же, что и у xxh64, что внушает доверие. Это он оптимизировал дальше xxhash, вдохновляясь в том числе достижением бывшего рекордсмена — t1ha2? Или мы имеем дело просто с эволюцией семейства xxhash? Результаты бенчей выглядят хорошо, нужно будет посмотреть как в реальном применении он выглядит.
zuborg
И ни строчки про то, как конкретно, собственно, эта функция устроена (
А вообще скорость хеширования определяется двумя параметрами — скоростью потоковой обработки и задержкой на одну транзакцию (что эквивалентно максимальному кол-ву хешей в секунду). Первая решает при обработки больших кусков данных (контрольные суммы, системы дедупликации...), но при обработке целых чисел фиксированного размера скорость определяется вторым параметром. Скажем, в математическом алгоритме, где используется map[uint32]uint32, лучше использовать тот же mmh3_x64
Причем быстрый алгоритм потоковой обработки (накопления энтропии) зачастую можно адаптировать к другим хешам (с маленькой задержкой транзакции), получив ещё более производительную функцию ). И наоборот — можно к быстро накопленной энтропии применить криптографический алгоритм — и получить ультрабыстрый (в потоковом смысле) но и криптостойкий хеш.