
Прежде всего это экономия — экономия времени на разработку и отладку, и что не менее важно — экономия денег из бюджета проекта. Понятно что эмулятор не будет на 100% идентичен исходной среде которую пытаемся эмулировать. Но для целей ускорения разработки и автоматизации процесса существующего сходства должно хватать. Наиболее злободневное что случилось в 2018 году с AWS — это блокировки провайдерами IP адресов подсетей AWS в РФ. И эти блокировки затронули нашу инфраструктуру, размещенную в облаке Amazon. Если планируете использовать технологии AWS и размещать проект в этом облаке, то для разработки и тестирования эмуляция с лихвой окупается.
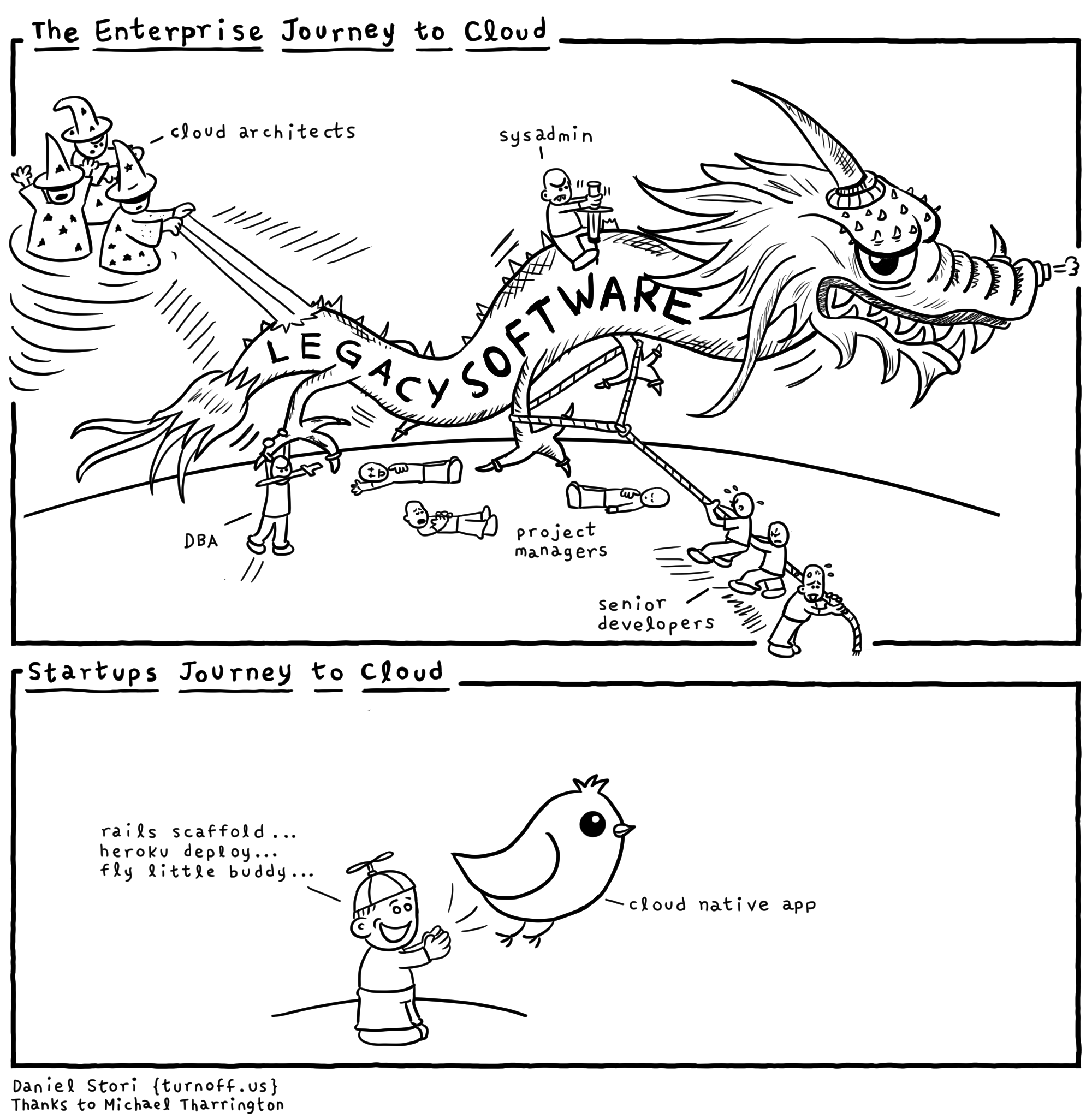
В публикации расскажу, как нам удалось выполнить такой трюк с сервисами S3, SQS, RDS PostgreSQL и Redshift при миграции существующего много лет хранилища данных на AWS.
Это лишь часть моего прошлогоднего доклада на митапе, соответствует темам хабов AWS и Java. Вторая часть относится к PostgreSQL, Redshift и колоночным базам данных и ее текстовую версию возможно опубликую в соответствующих хабах, видео и слайды есть на сайте конференции.
При разработке приложения для AWS во время блокировок подсетей AWS, команда практически их не заметила в ежедневном процессе разработки нового функционала. Так же работали тесты и можно отлаживать приложение. И только при попытке посмотреть логи приложения в logentries, метрики в SignalFX либо анализа данных в Redshift /PostgreSQL RDS ждало разочарование — сервисы были не доступны через сеть российского провайдера. Эмуляция AWS помогла нам не замечать этого и избегать гораздо больших задержек при работе с облаком Amazon через VPN сеть.
У каждого облачного провайдера «под капотом» есть много драконов и не стоит поддаваться на рекламу. Надо понимать зачем все это нужно самому поставщику услуг. Безусловно, есть преимущества у существующей инфраструктуры Amazon, Microsoft и Google. И когда вам рассказывают, что все сделано только чтобы вам удобно было разрабатывать, вас скорее всего пытаются подсадить на свою иглу и дать первую дозу бесплатно. Чтобы потом не слезли с инфраструктуры и конкретной технологии. Поэтому будем стараться избегать привязки к поставщику (vendor lock-in). Ясно, что не всегда возможно полностью абстрагироваться от конкретных решений и считаю, что довольно часто в проекте возможно абстрагироваться почти на 90%. Но оставшиеся 10% от проекта с привязкой к поставщику технологий, которые очень важны — это либо оптимизации производительности приложения, либо уникальные функции которых больше нигде нет. Всегда должны помнить о преимуществах и недостатках технологий и максимально себя обезопасить, не «подсаживаться» на конкретный API провайдера облачной инфраструктуры.
Amazon на своем сайте пишет про обработку сообщений. Суть и абстракция технологий обмена сообщения везде одна, хотя и есть нюансы — передача сообщений через очереди или через топики. Так вот, AWS рекомендуют использовать предоставляемый и управляемый ими Apache ActiveMQ для миграции приложений с существующего брокера обмена сообщениями, а для новых приложений Amazon SQS/SNS. Это как пример привязки к их собственному API, вместо стандартизованного JMS API и протоколов AMQP, MMQT, STOMP. Ясно что у данного провайдера с его решением может быть выше производительность, им поддерживаемая масштабируемость и т.п. С моей точки зрения если использовать их библиотеки, а не стандартизованные API то проблем станет гораздо больше.
В AWS есть БД Redshift. Это распределенная база данных с массивно-параллельной архитектурой. Можно загрузить большой объем ваших данных в таблицы на множестве узлов Redshft в Amazon и выполнять аналитические запросы над большими массивами данных. Это не OLTP система, где вам важно выполнять небольшие запросы на небольшом количестве записей достаточно часто с ACID гарантиями. При работе с Redshift же, предполагается, что у вас не большое число запросов в единицу времени, но они могут считать агрегаты на очень большом объеме данных. Эта система позиционируется вендором для модернизации вашего хранилища данных(warehouse) на AWS и обещают простую загрузку данных. Что совсем не правда.
Выдержка из документации про то, какие типы поддерживает Amazon Redshift. Достаточно скудный набор и если вам нужно что-то для хранения и обработки данных, что здесь не перечисленное, вам будет достаточно сложно работать. Например GUID.
Вопрос из зала «А JSON?»
— JSON можно записать только как VARCHAR и есть несколько функций для работы с JSON.
Комментарий из зала «В Postgres же есть нормальная поддержка JSON».
— Да в нем есть поддержка этого типа данных и функций. Но Redshift основан на PostgreSQL 8.0.2. Был проект ParAccel, если не ошибаюсь, технология эта 2005 года — форк постгреса в который добавлен планировщик для распределенных запросов на основе массивно-параллельной архитектуры. Прошло лет 5-6 и этот проект лицензировали для платформы Amazon Web Servces и назвали Redshift. Из исходного Postgres было кое-что убрано, много что добавлено. Добавили что связано с аутентификацией/авторизацией в AWS, с ролями, безопасностью в Amazon работает отлично. Но если нужно, например, подключиться из Redshift к другой базе с помощью Foreign Data Source, то этого вы не найдете. Нет никаких функций для работы с XML, функций для работы с JSON раз два и обчелся.
При разработке приложения стараетесь не зависеть от конкретных реализаций и код приложения зависит только от абстракций. Эти фасады и абстракции можно создать самому, но в данном случае есть множество готовых библиотек — фасадов. Которые абстрагируют код от конкретных реализаций, от конкретных фреймворков, Понятно, что они могут поддерживать не весь функционал, как «общий знаменатель» для технологий. Лучше разрабатывать ПО полагаясь на абстракции для упрощения тестирования.
Для эмуляции AWS упомяну два варианта. Первый честнее и правильнее, но медленнее работает. Второй грязный и быстрый. Я расскажу про вариант с хаком — стараемся создать всю инфраструктуру в одном процессе — будут быстрее работать тесты и кроссплатформенный вариант с работой в Windows (где не всегда docker сможет у вас заработать).
Первый же способ отлично подойдет если вы разрабатываете в linux/macos и у вас есть docker, лучше будет использовать atlassian localstack. Для интеграции localstack в JVM удобно использовать testcontainers.
Меня же от использования lockalstack в docker на проекте останавливало то, что разработка идет под Windows и за работу альфа версии docker никто не ручался, когда начинался этот проект… Также возможно не дадут устанавливать виртуальную машину с linux и docker в любой компании, которая серьезно относится к информационной безопасности. Я уж не говорю про работу в защищенном окружении в инвестбанках и запрещающих там почти весь траффик фаерволах.
Рассмотрим варианты как эмулировать Simple storage S3. Это не обычная файловая система от Amazon, а скорее распределенное хранилище объектов. В которое вы помещаете ваши данные как BLOB, без возможности модификации и дополнения данных. Есть подобные полноценные распределенные хранилища, от других производителей. Например, распределенное объектное хранилище Ceph позволяет работать со своей функциональностью используя S3 REST протокол и существующий клиентский с минимальной модификацией. Но это достаточно тяжеловесное решение для целей разработки и тестирования java приложений.
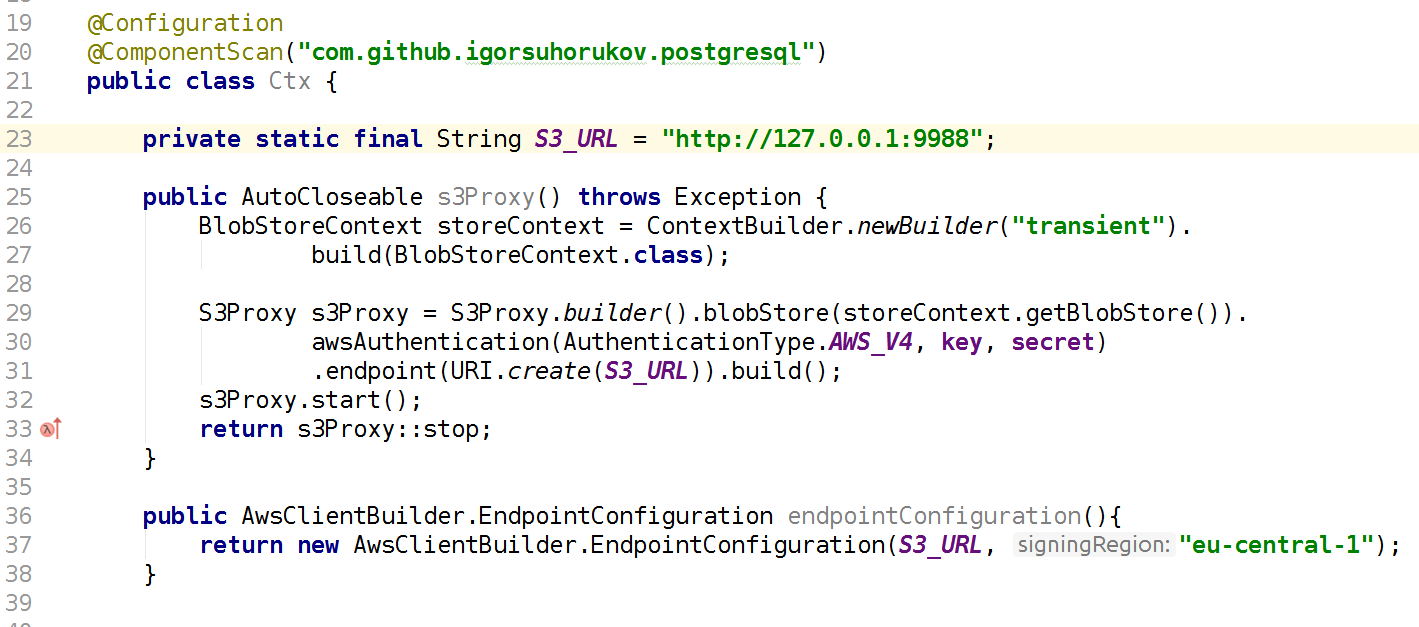
Более быстрый и подходящий проект — это java библиотека s3proxy. Она эмулирует S3 REST протокол и транслирует в соответствующие вызовы jcloud API и позволяет использовать множество реализаций для реального чтения и хранения данных. Может транслировать вызовы в Google App Engine API, Microsoft Azure API но для тестов удобнее использовать jcloud transient хранилище в оперативной памяти. Также необходимо настроить версию протокола аутентификации AWS S3 и указать значения ключа и секрета, также конфигурируем endpoint — порт и интерфейс на котором этот S3 Proxy будет слушать. Соответственно ваш код используя AWS SDK клиента должен подключаться в тестах к S3 AWS endpoint, а не AWS region. Опять же помним что s3proxy поддерживает не все функции S3 API, но все наши сценарии использования эмулируются на отлично! Даже Multipart upload для больших файлов поддерживается s3proxy.
Amazon Simple Queue Service это сервис очередей. Есть сервис очередей elasticmq, который написан на scala и он может представляться вашему приложению используя протокол Amazon SQS. Я его не использовал в проекте, поэтому приведу код инициализации, доверяя информации от его разработчиков.

В проекте я пошел другим путем и код зависит от spring-jms абстракций JmsTemplate и JmsListener и в зависимостях проекта указан JMS драйвер для SQS com.amazonaws:amazon-sqs-java-messaging-lib. Это то что касается основного кода приложения.

В тестах же мы подключаем Artemis-jms-server как embedded JMS сервер для тестов и в тестовом Spring context вместо SQS connection factory используем фабрику соединений Artemis. Artemis — это следующая версия Apache ActiveMQ полноценное свременное Message Oriented Middleware — не только решение для тестов. Возможно мы перейдем к его использованию в будещем не только в автотестах. Таким образом, используя JMS абстракции совместно со Spring мы упростили и код приложения и возможность легко тестировать его. Нужно лишь добавить зависимости org.springframework.boot:spring-boot-starter-artemis и org.apache.activemq:artemis-jms-server.

В некоторых тестах PostgreSQL можно эмулировать заменив на H2Database. Это сработает, если тесты не приемочные и не используют специфичных функций PG. При этом H2 может эмулировать подмножество wire протокола PostgreSQL без поддержки типов данных и функций. В нашем проекте мы используем Foreing Data Wrapper, поэтому этот способ не работает для нас.
Можно запускать настоящий PostgreSQL. postgresql-embedded скачивает реальный дистрибутив, точнее архив с бинарными файлами для платформы с которой запускаем, распаковывает его. В linux на tempfs в ОЗУ, в windows в %TEMP%, стартует процесс сервера postgresql, конфигурирует настройки сервера и параметры базы данных. В связи с особенностями распространения сборок, версии старше PG 11 не работаю под Linux. Для себя я сделал обертку библиотеку, которая позволяет получать двоичные сборки PostgreSQL не только c HTTP сервера но и из maven репозитария. Что может быть очень полезным при работе в изолированных сетях и сборке на CI сервере без доступа в интернет. Еще одним удобством в работе с моей оберткой является аннотации CDI компонента, что позволяет легко использовать компонент в Spring контексте например. Реализация AutoClosable интерфейса сервера появился раньше, чем в оригинальном проекте. Не надо вспоминать чтобы останавливать сервер, он остановится при закрытии Spring контекста автоматически.
При старте можно создавать БД на основе скриптов, дополняя Spring контекст соответствующими свойствами. Мы же сейчас создаем схему БД используя flyway скрипты для миграции схемы БД, которые и запускаются при каждом создании базы в тестах.
Для проверки данных после выполнения тестов используем библиотеку spring-test-dbunit. В аннотациях к методам теста указываем с какими выгрузками сравнивать состояние БД. Это избавляет от написания кода для работы с dbunit, лишь нужно добавить listener библиотеки в код теста. Можно указать в каком порядке удаляются данные из таблиц, после завершения тестового метода, если между тестами переиспользуется контекст БД. В 2019 году есть более современный подход, реализованный в database-rider, который работает с junit5. Пример использования можете посмотреть, например тут.
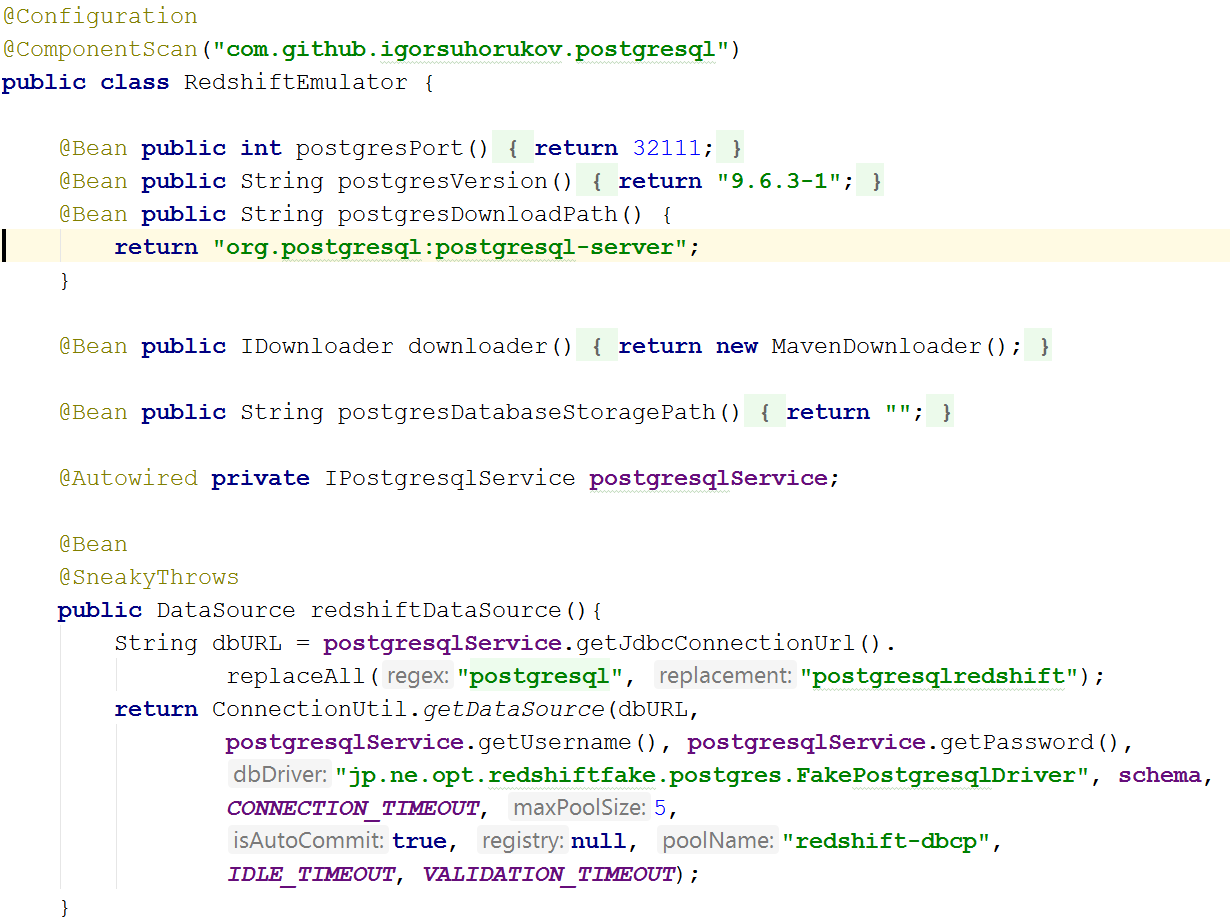
Сложнее всего оказалось эмулировать Amazon Redshift. Есть проект redshift-fake-driver проект сфокусирован на эмуляции пакетной загрузки данных в аналитическую БД от AWS. В эмуляторе протокола jdbc:postgresqlredshift реализовали команды COPY, UNLOAD, все остальные команды делегирует обычному JDBC драйверу PostgreSQL.
Поэтому в тестах не будет работать так же, как в Redshift операция update, которая использует другую таблицу как источник данных для обновления(синтаксис различается в Redshift и PostgreSQL 9+. Также замечал различную интерпретацию квотирования строчек в SQL командах между этими базами.
Из-за особенностей архитектуры реальной БД Redshift операции вставки, обновления и удаления данных достаточно медленные и «дорогие» с точки зрения операций ввода-вывода. Вставку данных с приемлемой производительностью возможно проводить только большими «пакетами» и команда COPY как раз позволяет загружать данные с распределенной файловой системы S3. Эта команда в БД поддерживает несколько форматов данных AVRO, CSV, JSON, Parquet, ORC и TXT. А проект эмулятора концентрируется на CSV, TXT, JSON.
Итак, для эмуляции Redshift в тестах понадобиться и запуск PostgreSQL базы как рассказывал раньше и запуск эмуляции S3 хранилища а при создании соединения к постгресу нужно лишь добавить redshift-fake-driver в classpath и указать класс драйвера jp.ne.opt.redshiftfake.postgres.FakePostgresqlDriver. После этого можно использовать тот же flyway для миграции схемы БД, и знакомы уже dbunit для сравнения данных после выполнения тестов.
Интересно, много ли кто из читателей использует в работе AWS и Redshift? Пишите в комментариях про ваш опыт.
Используя лишь Open Source проекты команде удалось ускорить разработку в окружении AWS, сэкономить средства из бюджета проекта и не остановить работу команды при блокировках подсетей AWS Роскомнадзором.
Комментарии (10)

kl09
20.03.2019 22:27Одна лишь картинка достойна отдельного поста

igor_suhorukov Автор
20.03.2019 22:28Как в воду глядели. В этом году на конференцию выбрали мой доклад как раз на тему управления техническим долгом в проектах)
szelga
21.03.2019 09:01sysadmin и DBA в единственном числе, а PMы лежат, прохлаждаются в теньке.
igor_suhorukov Автор
21.03.2019 10:46На картинке PMы пали жертвой сроков!
У нас нет PM вообще, команда 3разработчика, sysadmin до сих пор сидит на драконе и автоматизирует, а dba изредка помогает с оптимизацией сбора статистики и индексами и если нужно что-то понять на основе старого бэкапа. QA тестирует в препрод окружениях и помогает найти данные для приемочных тестов. Я больше половины своего времени занимаюсь разработкой, остальное время помогаю команде с архитектурными вопросами и общаюсь со смежными командами.
Hixon10
20.03.2019 23:20Я очень рад, что в амазоне растет количество Open-source продуктов, которые амазон продает, как managed: Amazon RDS for PostgreSQL, Amazon ElastiCache — Redis, Amazon Elasticsearch Service, Amazon Managed Streaming for Kafka, ну, и, вишенка — Amazon EKS — Managed Kubernetes Service.
Это позволяет брать кубернетес, и для тестовых сред использовать открытые продуты. А в проде — аналоги Амазона.
Тестовые среды, за счет кубернетеса, можно переносить между облаками, или вообще использовать свои сервера для этой цели, если уж будет необходимость.igor_suhorukov Автор
20.03.2019 23:41+1Да, это вполне работающая модель на базе open source. Все лучше, чем вещи в себе типа Redshift, Glue…
PostgreSQL RDS тот же ванильный постгрес, только с одним tablespace, ограниченным количеством модулей. Всего лишь с надстройками для Cloudwatch, бэкапами и лёгкими миграциями между разными версиями. База неспешно приближается к терабайтному рубежу и я спокоен, что ещё есть возможность масштабировать базу. А в случае чего переехать к другому вендору.
kmansoft
Очень круто но сразу пришло в голову два вопроса...
1 Если production система должна была быть всё равно в Amazon то (если бы сохранились блокировки) как бы с ней работали заказчики?
2 А не проще было поднять сетевой тоннель (OpenVPN, GRE, IPSec...) из офиса разработки и вообще не замечать блокировок?
igor_suhorukov Автор
1. Офисы по всему миру и основные пользователи системы в Америке. На них Роскомнадзор не распространяется.
2. Тоннель действительно проще и он появился благодаря вышеупомянутому органу по борьбе с подсетями AWS. Но в любом случае задержки при обращении в датацентры по всему миру не добавляют скорости в разработке и отладке приложения. Удобства с эмуляцией гораздо больше чем суеты, как и экономии. Так у каждого своя «песочница» и даже не одна.
kmansoft
Понятно, по обоим пунктам, спасибо. Тогда да, логично, круто.
igor_suhorukov Автор
Пожалуйста!