
Очень часто за свой 15летний опыт работы разработчиком ПО и тимлидом я сталкиваюсь с одним и тем же. Программирование превращается в религию — редко кто пытается внедрять технологии на основе разумного выбора, аргументированно, с учетом ограничений, возможностей переносимости, оценки степени привязки к вендору, реальной цены, перспектив технологии и свободы лицензий. Разработчики ходят на конференции или читают посты — заводятся на хайповость, а их ИТ директоров и менеджеров кормят не только сказками о светлом аджайл будущем на мероприятиях различные визионеры, сейлы и консалтеры. И получается что технологии оказались в проекте не с учетом удобства разработки и внедрения, нефункциональных требований проекта, а потому что это хайпово и google у себя использует, amazon рекомендует(хотя их вакансии говорят что сами не часто используют) или принято высочайшее решение руководства компании внедрять «это».

Но особое веселье — это выбор базы данных. Чем больше объемы хранимой информации, сложнее структуры данных в проекте и их изменения/эволюция, выше требования ко времени отклика или производительности тем дороже стоит ошибка выбора в начале на поздних стадиях проекта.
У меня есть идея почему это так — если в двух словах, то создание прототипов и сравнение разных технологий — это «дорого» (временем, лицензиями, обучением или реверс инженирингом) и тут же возникает соблазн включить древние инстинкты и перейти от трудоемкой доказательной части к веселой и простой, затрагивающий бездну иррациональности. Я тоже так поступал, а еще видел как самые нелепые вещи происходят на работах у меня и моих друзей и не только по решению технических специалистов. Поэтому выбор языка программирования, фреймворков, очередей сообщений или клауд провайдера с одинаковым успехом можно делать на основе постов в сетях, докладов на конференциях, методичек от Gartner для менеджеров или гадании на кофейной гуще. Жалко, что не могу рассказать многие истории со своих работ, так как опасаюсь за свою жизнь после этого…
С моей точки зрения при выборе базы данных приходится решать как минимум следующие компромисы:
Часто достается нам в «подарок» к внедряемому решению:
Горизонтальное масштабирование систем достаточно сложное и требует экспертизы команды. Опытные разработчики достаточно дорого стоят на рынке, распределенные приложения сложнее в разработке, отладке и тестировании. Поэтому если есть возможность сменить сервер на более мощный и объемы данных системы позволяют, то часто так и делают. Сейчас сервера могут иметь на борту терабайт ОЗУ и сотни процессорных ядер. Так что как никогда раньше становится важным максимально эффективно использовать все ресурсы сервера. Важна также стоимость лицензий базы данных и если их продают по ядрам процессора, то бюджет эксплуатации даже с вертикальным масштабированием может стоить как космическая программа сверхдержавы. Поэтому важно помнить об этом, чтобы не оказаться в невозможности масштабировать производительность базы из-за лицензий.
Понятно, что с помощью маркетинга вас будут пытаться убедить, что только решение определенной фирмы решит все ваши проблемы(но о том сколько новых появится умалчивают). Не существует одной идеальной базы данных, которая будет устраивать всех и подходит для всего.
Так что в обозримом будущем мы все так же будем поддерживать несколько различных БД для обработки одних и тех же данных для разных типов запросов в различных системах. Никакие решения для Data Fabric без кеширования данных, Data Lake пока не сравнятся с базами с массово-параллельной архитектурой по производительности и оптимальности запросов. Транзакционные данные все так же будут храниться в PostgreSQL, Oracle, MS Sql Server, аналитические запросы в Citus, Greenplum, Snowflake, Redshift, Vertica, Impala, Teradata, а болота сырых данных в HDFS/S3/ADLS(Azure) будут под управлением Dremio, Redshift Spectrum, Apache Spark, Presto.
Но перечисленные выше решения плохо подходят для анализа данных временных рядов с низким временем отклика. По популярности в работе с данными временных рядов сейчас в фаворитах InfluxDB. В нише in-memory database свои места держат kdb+ и memSQL.
Что может противопоставить всем этим решениям QuestDB с открытым исходным кодом и c Apache лицензией?
Когда эта база данных может пригодиться вам — если вы разрабатываете финансовые системы на JVM с низкой задержкой и вам необходимо решение для аналитики данных в оперативной памяти. В качестве замены kdb+ из-за стоимости лицензий. Если вы собираете метрики по Influx/Telegraf протоколу, но производительность и удобство работы с InfluxDB не устраивает. Если ваш проект работает на JVM и вам нужна встроенная база данных для сохранения метрик или данных приложения которые только добавляются и не обновляются.
Новый релиз 4.2.0 с поддержкой SIMD инструкций вызвал на Reddit волну коментариев. Для любителей поучаствовать в состязании знания современного «железа» и его эффективного программирования рекомендую пообщаться с автором базы( bluestreak01) в коментариях!
Команда проекта провела тест на синтетических данных и сравнили QuestDB 4.2.0 с kdb 4.0 по аггрегации миллиарда значений, запрягая SIMD инструкции процессоров.
На платформе Intel 8850H:
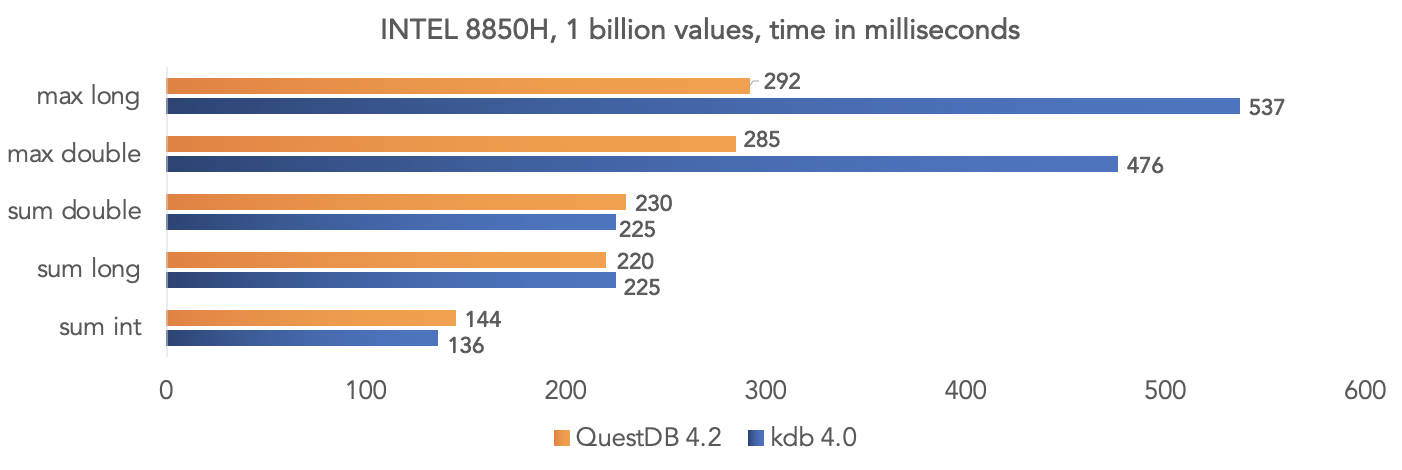
На платформе AMD Ryzen 3900X:
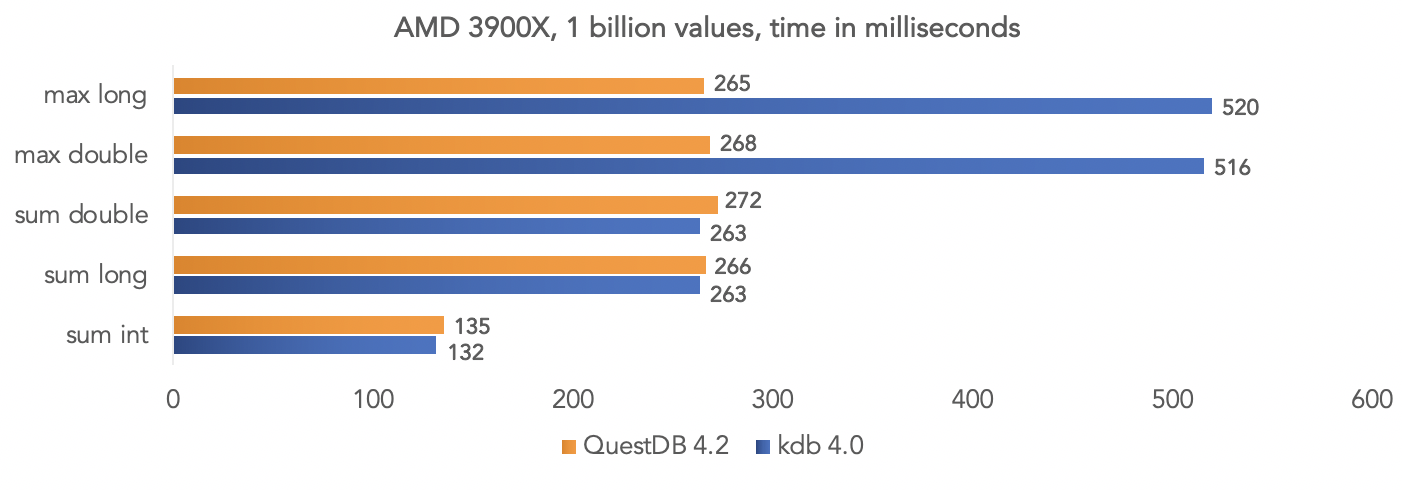
Понятно что это все тесты в «вакууме», но вы можете сравнить на ваших данных, если у вас проекте используется kdb и поделиться результатами с сообществом.
База публикуется на dockerhub при каждом релизе. Подробнее описано в документации проекта.
Получаем образ QuestDB:
Запускаем:
После этого подключиться по PostgreSQL протоколу можно к порту 8812, веб консоль доступна на порту 9000.
Добавляем в зависимости нашего проекта PostrgreSQL jdbc driver org.postgresql:postgresql:42.2.12, для этого теста я использую свой модуль QuestDB для testcontainers. Тест доступен на github вместе со скриптом сборки:
Запуск docker приводит к дополнительным накладным расходам, и этого можно избежать, просто внедрив org.questdb:core:jar:4.2.0 как зависимость проект и запустив io.questdb.ServerMain:
А вот такой вариант работы с базой данных самый быстрый, используя inprocess java API:
Проект включает в себя веб консоль для выполнения запросов к QuestDB
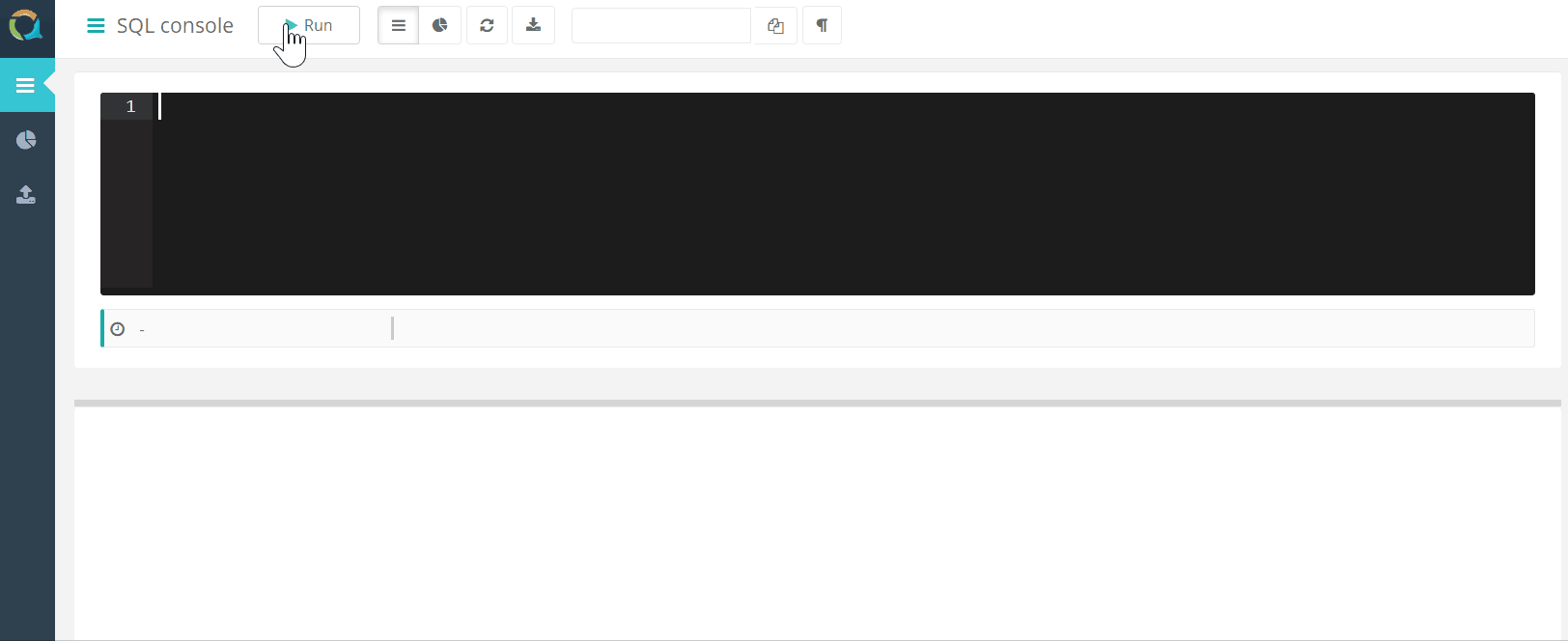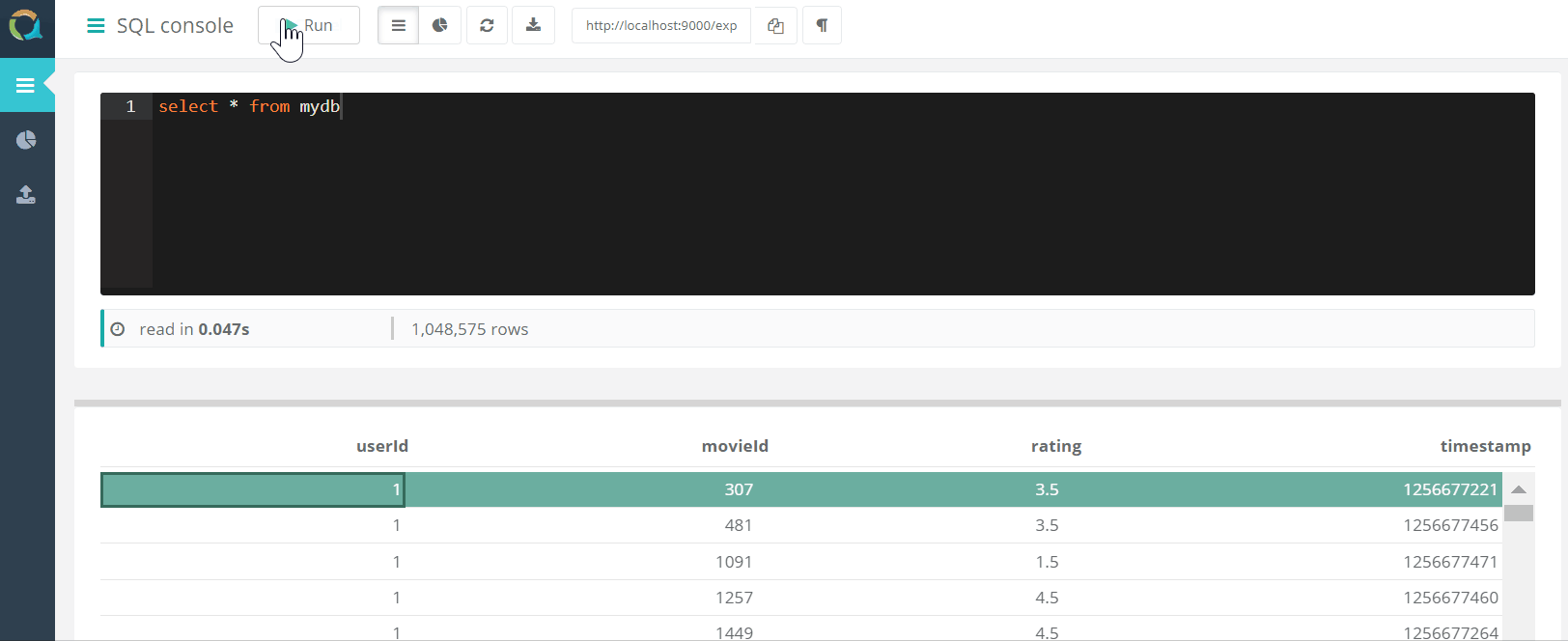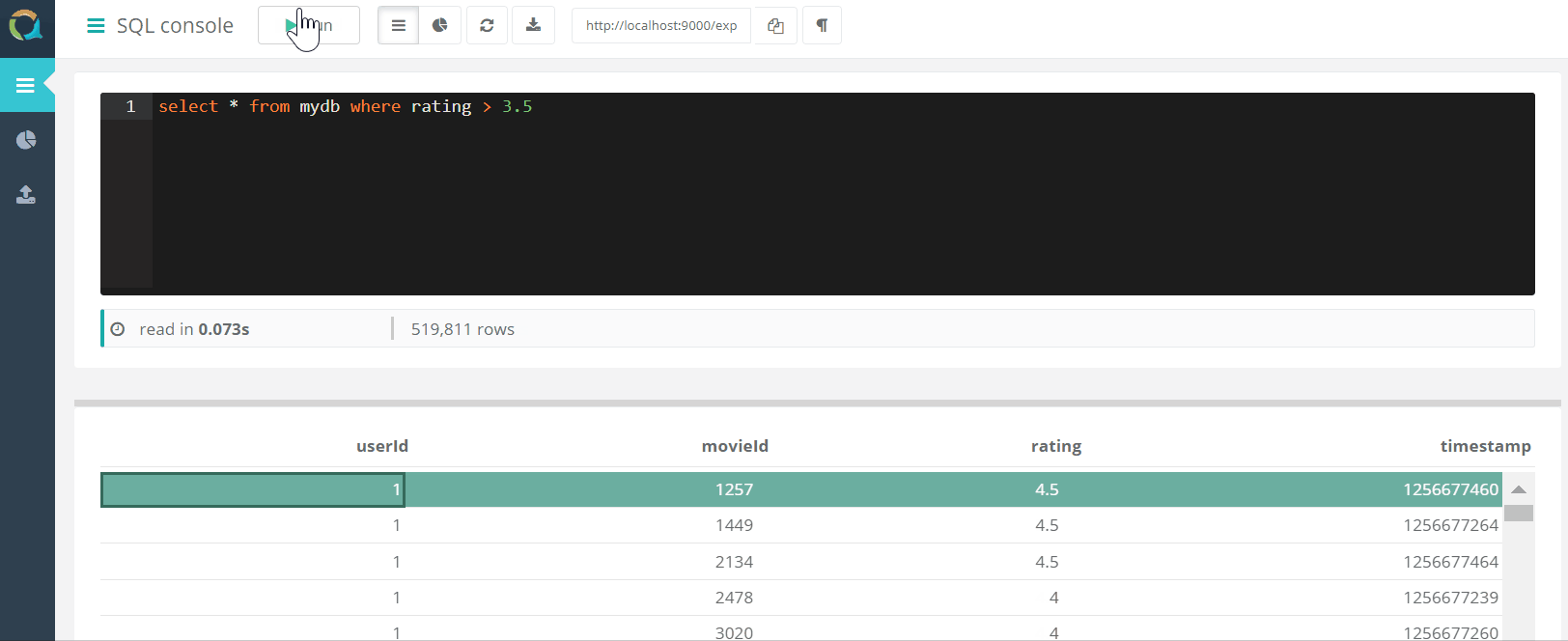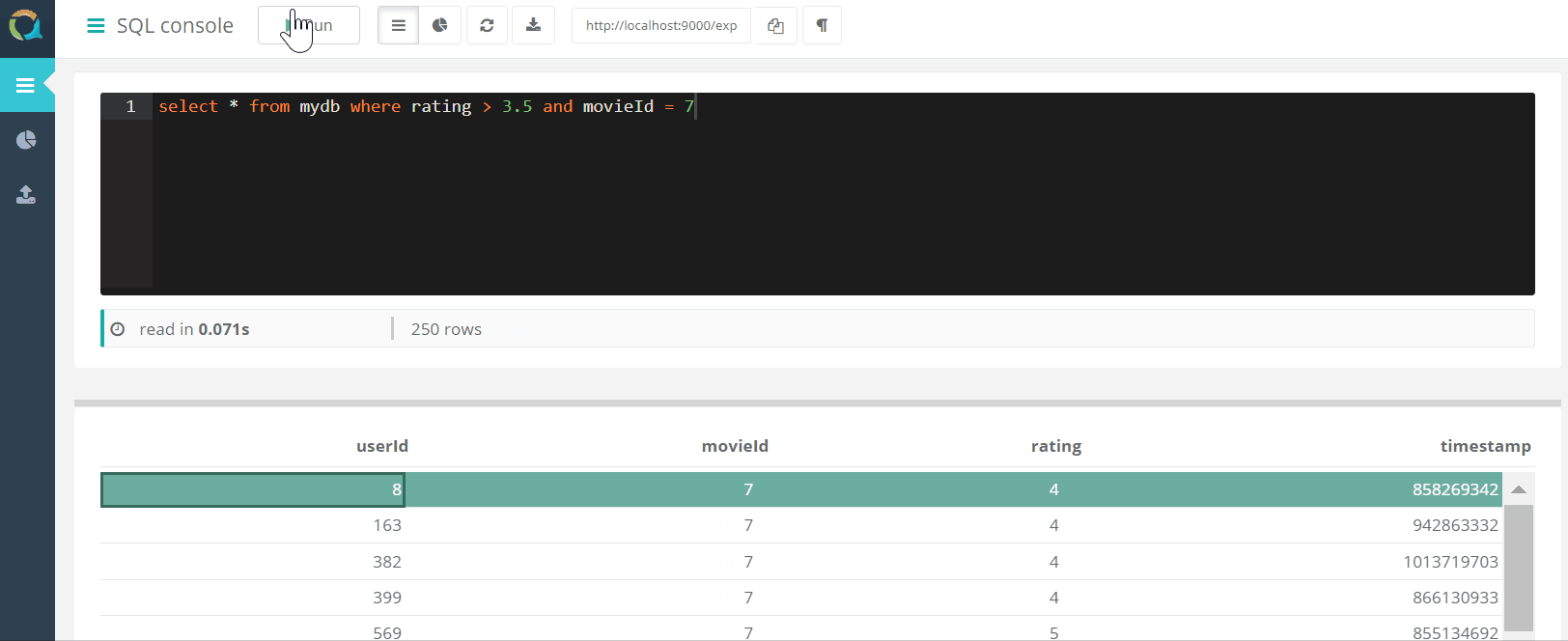
И загрузки данных в базу данных в формате csv через браузер.

Этот проект молодой и ему пока не хватает некоторых корпоративных фич, но он развивается достаточно быстро и над проектом активно работают несколько контрибьюторов. Слежу за QuestDB с августа прошлого года и разработал пару расширений для этого проекта(jdbc функция и osquery), а так же интегрировал этот проект с testcontainers. Сейчас пытаюсь решить свои текущие проблемы в Dremio с инкрементальной выгрузкой данных, партиционированием данных и длительными транзакциями к источникам данных в продакшене с помощью QuestDB, дополнив его функциями экспорта данных. Планирую поделиться своим опытом в следующих публикациях. Особенно меня подкупает, что я могу отлаживать свои функции и базу данных на привычной мне платформе, писать юнит тесты которые выполняются со «скоростью света».
Решать вам, как опытному разработчику. Еще раз повторюсь, что QuestDB не замена OLTP баз данных — PostgreSQL, Oracle, MS Sql Server, DB2 и даже не замена H2 для тестов в JVM. Это мощная специализированная база данных с открытым кодом и поддержкой сетевых протоколов PostgreSQL, Influx/Telegraf. Если ваш сценарий использования подходит под фичи которые в ней реализованы и под основной сценарий использования колоночной базы данных, то выбор оправдан!
Но особое веселье — это выбор базы данных. Чем больше объемы хранимой информации, сложнее структуры данных в проекте и их изменения/эволюция, выше требования ко времени отклика или производительности тем дороже стоит ошибка выбора в начале на поздних стадиях проекта.
У меня есть идея почему это так — если в двух словах, то создание прототипов и сравнение разных технологий — это «дорого» (временем, лицензиями, обучением или реверс инженирингом) и тут же возникает соблазн включить древние инстинкты и перейти от трудоемкой доказательной части к веселой и простой, затрагивающий бездну иррациональности. Я тоже так поступал, а еще видел как самые нелепые вещи происходят на работах у меня и моих друзей и не только по решению технических специалистов. Поэтому выбор языка программирования, фреймворков, очередей сообщений или клауд провайдера с одинаковым успехом можно делать на основе постов в сетях, докладов на конференциях, методичек от Gartner для менеджеров или гадании на кофейной гуще. Жалко, что не могу рассказать многие истории со своих работ, так как опасаюсь за свою жизнь после этого…
Что влияет на выбор базы данных
С моей точки зрения при выборе базы данных приходится решать как минимум следующие компромисы:
- обработка транзакций в реальном времени или интерактивная аналитическая обработка
- вертикально или горизонтально масштабируемая
- в случае распределенной базы — согласованность данных/доступность/устойчивость к разделению (CAP теорема)
- определенная схема данных и ограничения в базе или хранилище которое не требует схему данных
- модель данных — ключ-значение, иерархическая, графовая, документная или реляционная
- логика обработки максимально близко к данным или вся обработка в приложении
- работа преимущественно в оперативной памяти или с дисковой подсистемой
- универсальное решение или специализированное
- используем существующую экспертизу на не особо подходящей к требованиям проекта БД или нарабатываем новую в подходящей но не знакомой обучением, «кровью и потом»(это же относится не только к разработке, но и к эксплуатации)
- встраеваемая или в другом процессе/сетевая
- хипстер или ретроград
Часто достается нам в «подарок» к внедряемому решению:
- «инопланетный» язык запросов
- единственный собственный API для работы с базой, что осложнит переход на другие базы данных(потрачены время, усилия команды и бюджет проекта)
- недоступность драйверов для других платформ/языков/операционных систем
- отсутствие исходных кодов, описаний формата данных на диске(или запрет в лицензии реверс инженеринга, особенно этим отличается Oracle с глюкавым Coherence)
- рост стоимости лицензии год от года
- своя экосистема и сложность найти специалистов
- зависимость стоимости от числа ядер, числа клиентов, запросов
- эмбарго
Горизонтальное масштабирование систем достаточно сложное и требует экспертизы команды. Опытные разработчики достаточно дорого стоят на рынке, распределенные приложения сложнее в разработке, отладке и тестировании. Поэтому если есть возможность сменить сервер на более мощный и объемы данных системы позволяют, то часто так и делают. Сейчас сервера могут иметь на борту терабайт ОЗУ и сотни процессорных ядер. Так что как никогда раньше становится важным максимально эффективно использовать все ресурсы сервера. Важна также стоимость лицензий базы данных и если их продают по ядрам процессора, то бюджет эксплуатации даже с вертикальным масштабированием может стоить как космическая программа сверхдержавы. Поэтому важно помнить об этом, чтобы не оказаться в невозможности масштабировать производительность базы из-за лицензий.
Понятно, что с помощью маркетинга вас будут пытаться убедить, что только решение определенной фирмы решит все ваши проблемы(но о том сколько новых появится умалчивают). Не существует одной идеальной базы данных, которая будет устраивать всех и подходит для всего.
Так что в обозримом будущем мы все так же будем поддерживать несколько различных БД для обработки одних и тех же данных для разных типов запросов в различных системах. Никакие решения для Data Fabric без кеширования данных, Data Lake пока не сравнятся с базами с массово-параллельной архитектурой по производительности и оптимальности запросов. Транзакционные данные все так же будут храниться в PostgreSQL, Oracle, MS Sql Server, аналитические запросы в Citus, Greenplum, Snowflake, Redshift, Vertica, Impala, Teradata, а болота сырых данных в HDFS/S3/ADLS(Azure) будут под управлением Dremio, Redshift Spectrum, Apache Spark, Presto.
Но перечисленные выше решения плохо подходят для анализа данных временных рядов с низким временем отклика. По популярности в работе с данными временных рядов сейчас в фаворитах InfluxDB. В нише in-memory database свои места держат kdb+ и memSQL.
QuestDB
Что может противопоставить всем этим решениям QuestDB с открытым исходным кодом и c Apache лицензией?
- Попытка выжать максимум из аппаратного обеспечения для выполнения аналитических запросов — векторизация агрегационных функций, работа с данными через memory mapped файлы
- SQL в качестве языка DML запросов и DDL операций для управления структурой базы данных
- поддержка join таблиц, характерных для time series DB
- поддержка оконных и агрегационных функций в SQL
- возможность встраивать базу данных в приложение на JVM
- расширения функций базы даннных на любом языке для JVM, подключаются без перекомпиляции ядра базы с помощью ServiceLoader
- поддержка Influx DB line protocol (ILP) по UDP и Telegraf. Обзор архитектурных преимуществ в публикации «What makes QuestDB faster than InfluxDB»
- поддержка PostgreSql 11 протокола и возможность подключаться к базе с помощью драйверов для PostgreSQL: JDBC, ODBC или из psql клиента
- включает в себя web сервер с асинхронным вводом-выводом и REST endpoint для импорта, экспорта данных и выполнения SQL запроса с результатами сериализованными в json формате
- включает веб консоль для выполнения запросов в браузере, импорта и экспорта данных
- При встраивании базы данных в один процесс с приложением досупен zero-GC API, база не включает в себя сторонние зависимости.
- Возможно управление транзакциями к таблице для выбора между задержками при вставке и производительностью с вероятностью потерять незафиксированный фрагмент данных(на данный момент транзакция не включает более одной таблицы)
- поддержка 64разрядных версий Windows, Linux, OSX, ARM Linux и эксперементальная поддержка FreeBSD
- Проект, что редкость для open source, включает хорошую документацию
Когда эта база данных может пригодиться вам — если вы разрабатываете финансовые системы на JVM с низкой задержкой и вам необходимо решение для аналитики данных в оперативной памяти. В качестве замены kdb+ из-за стоимости лицензий. Если вы собираете метрики по Influx/Telegraf протоколу, но производительность и удобство работы с InfluxDB не устраивает. Если ваш проект работает на JVM и вам нужна встроенная база данных для сохранения метрик или данных приложения которые только добавляются и не обновляются.
Новый релиз 4.2.0 с поддержкой SIMD инструкций вызвал на Reddit волну коментариев. Для любителей поучаствовать в состязании знания современного «железа» и его эффективного программирования рекомендую пообщаться с автором базы( bluestreak01) в коментариях!
SIMD операции
Команда проекта провела тест на синтетических данных и сравнили QuestDB 4.2.0 с kdb 4.0 по аггрегации миллиарда значений, запрягая SIMD инструкции процессоров.
На платформе Intel 8850H:
На платформе AMD Ryzen 3900X:
Понятно что это все тесты в «вакууме», но вы можете сравнить на ваших данных, если у вас проекте используется kdb и поделиться результатами с сообществом.
Запуск docker образа базы
База публикуется на dockerhub при каждом релизе. Подробнее описано в документации проекта.
Получаем образ QuestDB:
docker pull questdb/questdbЗапускаем:
docker run --rm -it -p 9000:9000 -p 8812:8812 questdb/questdbПосле этого подключиться по PostgreSQL протоколу можно к порту 8812, веб консоль доступна на порту 9000.
Доступ по jdbc
Добавляем в зависимости нашего проекта PostrgreSQL jdbc driver org.postgresql:postgresql:42.2.12, для этого теста я использую свой модуль QuestDB для testcontainers. Тест доступен на github вместе со скриптом сборки:
import org.junit.jupiter.api.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import static org.assertj.core.api.Assertions.*;
public class QuestDbDriverTest {
@Test
void containerIsUpTestByJdbcInvocation() throws Exception {
try (Connection connection = DriverManager.getConnection("jdbc:tc:questdb:///?user=admin&password=quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
Запуск docker приводит к дополнительным накладным расходам, и этого можно избежать, просто внедрив org.questdb:core:jar:4.2.0 как зависимость проект и запустив io.questdb.ServerMain:
import io.questdb.ServerMain;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.Statement;
public class QuestDbJdbcTest {
@Test
void embeddedServerStartTest(@TempDir Path tempDir) throws Exception{
ServerMain.main(new String[]{"-d", tempDir.toString()});
try (DriverManager.getConnection("jdbc:postgresql://localhost:8812/", "admin", "quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
Встраивание в java приложение
А вот такой вариант работы с базой данных самый быстрый, используя inprocess java API:
import io.questdb.cairo.CairoEngine;
import io.questdb.cairo.DefaultCairoConfiguration;
import io.questdb.griffin.CompiledQuery;
import io.questdb.griffin.SqlCompiler;
import io.questdb.griffin.SqlExecutionContextImpl;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
public class TruncateExecuteTest {
@Test
void truncate(@TempDir Path tempDir) throws Exception{
SqlExecutionContextImpl executionContext = new SqlExecutionContextImpl();
DefaultCairoConfiguration configuration = new DefaultCairoConfiguration(tempDir.toAbsolutePath().toString());
try (CairoEngine engine = new CairoEngine(configuration)) {
try (SqlCompiler compiler = new SqlCompiler(engine)) {
CompiledQuery createTable = compiler.compile("create table tr_table(id long,name string)", executionContext);
compiler.compile("truncate table tr_table", executionContext);
}
}
}
}
Веб консоль
Проект включает в себя веб консоль для выполнения запросов к QuestDB
И загрузки данных в базу данных в формате csv через браузер.
Нужна ли вам другая база данных?
Этот проект молодой и ему пока не хватает некоторых корпоративных фич, но он развивается достаточно быстро и над проектом активно работают несколько контрибьюторов. Слежу за QuestDB с августа прошлого года и разработал пару расширений для этого проекта(jdbc функция и osquery), а так же интегрировал этот проект с testcontainers. Сейчас пытаюсь решить свои текущие проблемы в Dremio с инкрементальной выгрузкой данных, партиционированием данных и длительными транзакциями к источникам данных в продакшене с помощью QuestDB, дополнив его функциями экспорта данных. Планирую поделиться своим опытом в следующих публикациях. Особенно меня подкупает, что я могу отлаживать свои функции и базу данных на привычной мне платформе, писать юнит тесты которые выполняются со «скоростью света».
Решать вам, как опытному разработчику. Еще раз повторюсь, что QuestDB не замена OLTP баз данных — PostgreSQL, Oracle, MS Sql Server, DB2 и даже не замена H2 для тестов в JVM. Это мощная специализированная база данных с открытым кодом и поддержкой сетевых протоколов PostgreSQL, Influx/Telegraf. Если ваш сценарий использования подходит под фичи которые в ней реализованы и под основной сценарий использования колоночной базы данных, то выбор оправдан!

EmelyanovKonstantin
Хорошая статья.
igor_suhorukov Автор
А что именно вас заинтересовало? Вы java разработчик?
EmelyanovKonstantin
Мне понравилось введение. Хорошо написано о тенденциях, связанных с принятием решений о выборе и внедрении технологий.
igor_suhorukov Автор
Спасибо, я бы сказал наболело. На работе очередной «крестовый поход», чтобы доказать какой даталейк «православнее» AzureDL или AWS + Redshift Spectrum