
И это, кстати, не пример очередной странности JavaScript. Автор материала, перевод которого мы сегодня публикуем, говорит, что может показать, как та же проблема проявляется при использовании практически каждого из существующих языков программирования. В частности, речь идёт о Python, Go, и даже о сценариях командной оболочки. Как с этим бороться?
Предыстория
Я впервые столкнулся с проблемой Unicode много лет назад, когда писал приложение (на Objective-C), которое импортировало список контактов из адресной книги пользователя и из его социальных сетей, после чего исключало дубликаты. В определённых ситуациях оказывалось так, что некоторые люди присутствуют в списке дважды. Происходило это из-за того, что их имена, по мнению программы, не являлись одинаковыми строками.
Хотя в вышеприведённом примере две строки выглядят абсолютно одинаково, то, как они представлены в системе, те байты, в виде которых они сохранены на диске, различаются. В первом имени
"Zoe" символ e (e с умлаутом) представляет собой одну кодовую точку Unicode. Во втором случае мы имеем дело с декомпозицией, с подходом к представлению знаков с помощью нескольких символов. Если вы, в своём приложении, работаете с Unicode-строками, вам нужно учитывать то, что одни и те же символы могут быть представлены разными способами.Как мы пришли к эмодзи: в двух словах о кодировании символов
Компьютеры работают с байтами, которые представляют собой всего лишь числа. Для того чтобы получить возможность обрабатывать на компьютерах тексты, люди договорились о соответствии символов и чисел, и пришли к соглашениям о том, как должно выглядеть визуальное представление символов.
Первое подобное соглашение было представлено кодировкой ASCII (American Standard Code for Information Interchange). Эта кодировка использовала 7 бит и могла представлять 128 символов, в состав которых входили латинский алфавит (прописные и строчные буквы), цифры и основные знаки пунктуации. В ASCII также входило множество «непечатаемых» символов, таких, как символ перевода строки, знак табуляции, символ возврата каретки и другие. Например, в ASCII латинская буква M (прописная m) кодируется в виде числа 77 (4D в шестнадцатеричном представлении).
Проблема ASCII заключается в том, что хотя 128 знаков может быть достаточно для представления всех символов, которыми обычно пользуются люди, работающие с англоязычными текстами, этого количества символов недостаточно для представления текстов на других языках и разных особых символов вроде эмодзи.
Решением этой проблемы стало принятие стандарта Unicode, который был нацелен на возможность представления каждого символа, используемого во всех современных и древних текстах, включая и символы вроде эмодзи. Например, в совсем недавно вышедшем стандарте Unicode 12.0 насчитывается более 137000 символов.
Стандарт Unicode может быть реализован с использованием множества способов кодирования символов. Самые распространённые — это UTF-8 и UTF-16. Надо отметить, что в веб-пространстве сильнее всего распространён стандарт кодирования текстов UTF-8.
Стандарт UTF-8 использует для представления символов от 1 до 4 байт. UTF-8 представляет собой надмножество ASCII, поэтому первые его 128 символов совпадают с символами, представленными в кодовой таблице ASCII. Стандарт UTF-16, с другой стороны, использует для представления 1 символа от 2 до 4 байт.
Почему существуют и тот и другой стандарты? Дело в том, что тексты на западных языках обычно эффективнее всего кодируются с использованием стандарта UTF-8 (так как большинство символов в таких текстах могут быть представлены в виде кодов размером в 1 байт). Если же говорить о восточных языках, то можно сказать, что файлы, хранящие тексты, написанные на этих языках, обычно получаются меньше при использовании UTF-16.
Кодовые точки Unicode и кодирование символов
Каждому символу в стандарте Unicode назначен идентификационный номер, который называется кодовой точкой. Например, кодовой точкой эмодзи
 является U+1F436.
является U+1F436.При кодировании этого значка он может быть представлен в виде различных последовательностей байтов:
- UTF-8: 4 байта,
0xF0 0x9F 0x90 0xB6 - UTF-16: 4 байта,
0xD83D 0xDC36
В JavaScript-коде, представленном ниже, все три команды выводят в консоль браузера один и тот же символ.
// Так соответствующая последовательность байтов просто включается в код
console.log('') // =>
// Тут используется кодовая точка Unicode (ES2015+)
console.log('\u{1F436}') // =>
// Тут используется представление этого символа в стандарте UTF-16
// с применением двух кодовых единиц (по 2 байта каждая)
console.log('\uD83D\uDC36') // => Во внутренних механизмах большинства JavaScript-интерпретаторов (включая Node.js и современные браузеры) используется UTF-16. Это означает, что рассматриваемый нами значок с собакой хранится с использованием двух кодовых единиц UTF-16 (по 16 бит каждая). Поэтому то, что выводит следующий код, не должно показаться вам непонятным:
console.log(''.length) // => 2Комбинирование символов
Теперь вернёмся к тому, с чего мы начали, а именно, поговорим о том, почему символы, выглядящие для человека одинаково, имеют различное внутреннее представление.
Некоторые символы в кодировке Unicode предназначены для модификации других символов. Их называют комбинируемыми символами (combining characters). Они применяются к базовым символам (base characters) Например:
n + ? = nu + ? = ue + ? = e
Как видно из предыдущего примера, комбинируемые символы позволяют добавлять к базовым символам диакритические знаки. Но на этом возможности Unicode по трансформации символов не ограничиваются. Например, некоторые последовательности символов могут быть представлены в виде лигатур (так ae может превратиться в ?).
Проблема заключается в том, что особенные символы могут быть представлены различными способами.
Например, букву e можно представить двумя способами:
- С помощью одной кодовой точки U+00E9.
- С помощью комбинации буквы e и знака акута, то есть — с помощью двух кодовых точек — U+0065 и U+0301.
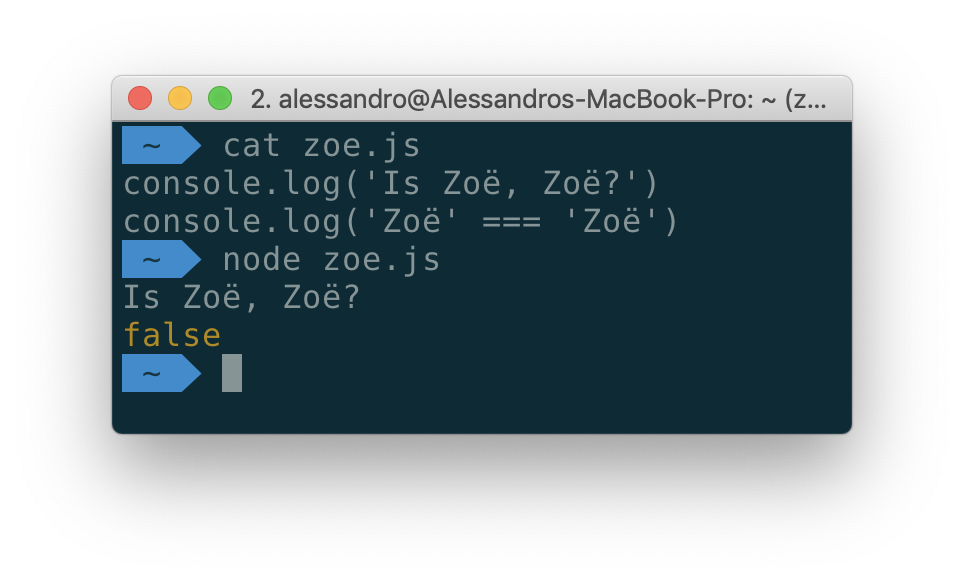
Символы, получившиеся в результате применения любого из этих способов представления буквы e, будут выглядеть одинаково, но при их сравнении окажется, что символы это разные. Строки, содержащие их, будут иметь разную длину. Убедиться в этом можно, выполнив следующий код в консоли браузера.
console.log('\u00e9') // => e
console.log('\u0065\u0301') // => e
console.log('\u00e9' == '\u0065\u0301') // => false
console.log('\u00e9'.length) // => 1
console.log('\u0065\u0301'.length) // => 2Это может привести к неожиданным ошибкам. Например, они могут выражаться в том, что программа, по непонятным причинам, не способна найти в базе данных некоторые записи, в том, что пользователь, вводя правильный пароль, не может войти в систему.
Нормализация строк
У вышеописанных проблем есть простое решение, которое заключается в нормализации строк, в приведении их к «каноническому представлению».
Существуют четыре стандартных формы (алгоритма) нормализации:
- NFC: Normalization Form Canonical Composition.
- NFD: Normalization Form Canonical Decomposition.
- NFKC: Normalization Form Compatibility Composition.
- NFKD: Normalization Form Compatibility Decomposition.
Чаще всего используется форма нормализации NFC. При использовании этого алгоритма все символы сначала подвергаются декомпозиции, после чего все комбинирующиеся последовательности подвергаются повторной композиции в порядке, определяемом стандартом. Для практического применения можно выбрать любую форму. Главное — применять её последовательно. В результате поступление на вход программы одних и тех же данных всегда будет приводить к одному и тому же результату.
В JavaScript, начиная со стандарта ES2015 (ES6), имеется встроенный метод для нормализации строк — String.prototype.normalize([form]). Пользоваться им можно в среде Node.js и практически во всех современных браузерах. Аргумент
form этого метода представляет собой строковой идентификатор формы нормализации. По умолчанию используется форма NFC.Вернёмся к ранее рассмотренному примеру, применив на этот раз нормализацию:
const str = '\u0065\u0301'
console.log(str == '\u00e9') // => false
const normalized = str.normalize('NFC')
console.log(normalized == '\u00e9') // => true
console.log(normalized.length) // => 1Итоги
Если вы разрабатываете веб-приложение и используете в нём то, что вводит пользователь, всегда выполняйте нормализацию полученных текстовых данных. В JavaScript для выполнения нормализации можно воспользоваться стандартным методом строк normalize().
Уважаемые читатели! Сталкивались ли вы с проблемами, возникающими при работе со строками, решить которых можно с помощью нормализации?

Комментарии (37)

homm
01.04.2019 16:40Хотя в вышеприведённом примере две строки выглядят абсолютно одинаково, то, как они представлены в системе, те байты, в виде которых они сохранены на диске, различаются.
Юникод вообще не про байты. Для ответа на вопрос из заголовка можно было просто опустить весь рассказ про кодировки и суррогатные пары, они никак не относятся к нормализации.
Почему существуют и тот и другой стандарты? Дело в том, что тексты на западных языках обычно эффективнее всего кодируются с использованием стандарта UTF-8.
Если бы дело было только в этом, то UTF-16 не использовался бы в большинства JavaScript-интерпретаторов. Просто при передаче важнее компактность (а UTF-8 в целом получается компактнее), а при работе со строками важнее скорость определения длины строки и положения символа в заданной позиции.

GamePad64
01.04.2019 17:27Если бы было так, то использовали бы UTF-32. Использование же UTF-16 — это по большей части легаси.

DistortNeo
02.04.2019 12:10Юникод совсем недавно прорвало за границы 2-байтной кодировки. Точнее, стандарт предполагал это давно, но массовое использование этих символов началось совсем недавно.
GamePad64
02.04.2019 12:50И после "прорыва" ситуация стала печальной: UTF-16 объединяет недостатки UTF-8 и UTF-32.
Он занимает много места (кроме иероглифов) и является кодировкой, где каждый code point кодируется последовательностью байт переменной длины ("спасибо" суррогатным парам). К тому же, старый и не очень софт не поддерживает UTF-16 (только UCS-2). Плюс, проблемы с endianness.
Поэтому, в современном софте имеет смысл использовать UTF-8 для хранения текста, UTF-32 для обработки, а про UTF-16 просто забыть.DistortNeo
03.04.2019 11:38+1Зависит от задачи. Если вам не нужна работа с текстом на уровне кодпоинтов (или вообще букв), то нет никакого смысла тратить время на перекодировку и память на хранение в менее компактном формате. Например парсить JSON, XML, HTML можно одинаково эффективно и в UTF-8, и в UTF-16 и в UTF-32.
DistortNeo
02.04.2019 12:31Если бы дело было только в этом, то UTF-16 не использовался бы в большинства JavaScript-интерпретаторов. Просто при передаче важнее компактность (а UTF-8 в целом получается компактнее), а при работе со строками важнее скорость определения длины строки и положения символа в заданной позиции.
Определение длины строки в символах и позиции символа при использовании что UTF-8, что UTF-16 одинаково геморройно, потому что требует итерации по всей строке. Не забывайте, что в UTF-16 есть кодпоинты, которые представляются двумя кодюнитами.
Поэтому строки в JS — это последовательность UTF-16 code units, а не UTF-16 code points. Просто пока вы не работаете с суррогатными парами (эмодзи всякие), вы этого не замечаете.

gurux13
01.04.2019 19:51А может кто-нибудь пояснить смысл неоднозначного представления символа? Если это один и тот же символ, это выглядит как отвратительное решение. Если разные, то не должно быть нормализаций.
//тут же вопрос — о и o — одна и та же буква? :)
Finesse
02.04.2019 03:54Это наследие однобайтовых кодировок. В таких кодировках можно записать не более 256 символов, поэтому приходилось выкручиваться, создавая отдельные символы для частей букв (
u,?) и затем соединяя их в буквы.me21
02.04.2019 10:53Я первый раз услышал про такое соединение именно в контексте Юникода. Правда есть такие кодировки? В Windows-1252, например, все символы с умляутами отдельно: en.wikipedia.org/wiki/Windows-1252#Character_set
Finesse
02.04.2019 11:43Я не знаю, в каких именно кодировках это используется. В той же википедии сказано, что возможность неоднозначного представления была добавлена для совместимости со старыми наборами символов:
This feature was introduced in the standard to allow compatibility with preexisting standard character sets, which often included similar or identical characters
Возможно, я перепутал понятия «кодировка» и «набор символов».

vanxant
03.04.2019 01:18В 7 битном ASCII умляутов нет, а для верхних 128 символов были на каждом компе три разных кодировки. В итоге в Европах просто на какое-то время отказались от умляутов в целях совместимости, чтобы условное письмо могли прочесть в соседней деревне.
me21
02.04.2019 10:53Я первый раз услышал про такое соединение именно в контексте Юникода. Правда есть такие кодировки? В Windows-1252, например, все символы с умляутами уже соединены: en.wikipedia.org/wiki/Windows-1252#Character_set
vanxant
03.04.2019 01:15Например, ударения.
Ещё всякий матан с гробиками и стрелочками со всех сторон символа.
Ещё есть языки с размытой нормой, например ss и ? в немецком это одна и то же «буква», но в одних регионах пишут так, а в других эдак.


StepanRodionov
01.04.2019 20:28Пример в заголовке статьи неудачный: конкретно Zoё может быть не Zоё, потому что буква «о» английская и русская используются.



BiOM
01.04.2019 23:34Эта проблема очень ярко проявлялась на iOS после перехода на APFS (начиная с iOS 10.3 и вплоть до iOS 11.0, в которой проблема была решена, более полугода спустя). Много нервов помотали пользователи которые через iTunes добавляли файлы в папку документов приложения, приложение файлы видело но не могло открыть. Причем у некоторых пользователей все работало, а у некоторых ничего не получалось. В итоге выяснилось, что проблема возникает с файлами, загруженными из iTunes из под Windows для файлов имеющих в названии символы Й, Ё ну и всякие умляуты и подобное. Причем у пользователей на OSX такой проблемы небыло. Пользователям рекомендовал переименовывать файлы таким образом, чтобы в названии были только латинские символы и цифры. Но виноват, в глазах пользователей, всеравно был разработчик приложения. Сильно тогда слили рейтинг приложения из за этой проблемы.
woodhead
02.04.2019 07:28Правильно ли я понял, что проблема возникает только в том случае, когда кодировки отличаются?


staticmain
02.04.2019 10:04+1const str = '\u0065\u0301' console.log(str == '\u00e9') // => false const normalized = str.normalize('NFC') console.log(normalized == '\u00e9') // => true console.log(normalized.length) // => 1
Некорректно. Нужно сравнивать не normalized и '\u00e9', а
const str1 = '\u0065\u0301' const str2 = '\u00e9' const normalized1 = str1.normalize('NFC') const normalized2 = str2.normalize('NFC') console.log(normalized1 == normalized2)

dartraiden
Пару раз в жизни встречал тексты, где вместо буквы «й» было сочетание «и + ?». Всякий раз хотелось пожелать мучительной смерти создателю такой подрянки.
port443
Мне многократно попадались на этом сайте и тексты, и комментарии, где «ы» было записано парой «ь»-«i». Так и не понял что это. Подавление поиска?
AAngstrom
Мало того, в этом подавлении поиска есть украинский след.
В украинской раскладке — сюрприз! — нет буквы «ы», потому что в украинском этот звук обозначается буквой «и».
zelenin
Украина
zelenin
мак
vanxant
Это маководам лучи добра.
vlivyur
Apple старались.
klirichek
Стандартная ситуация для кросс-платформы, где фигурирует мак.
Самое типичное — файлы с русскими именами на NFC-шаре между маком и линуксом. И именно с теми самыми двумя буквами в имени — ё и й. Внезапно обнаруживается, что записанные из линукса такие файлы мак не видит. Зато может сам записать такие, причём БЕЗ диалога о существующем файле и его замене.
И после всего этого ты смотришь на два файла с одинаковым именем и думаешь, WTF?
История реальная; набираю нотные партитуры в лилипонде; попеременно то с убунты, то с макбука...