
Индустрия сконцентрировалась на ускорении перемножений матриц, однако улучшение алгоритма поиска может привести к более серьёзному повышению быстродействия

В последние годы компьютерная индустрия была занята, пытаясь ускорить вычисления, требуемые для искусственных нейросетей – как для обучения, так и для получения выводов её работы. В частности, довольно много усилий было положено на разработку специального железа, на котором можно выполнять эти вычисления. В Google разработали Tensor Processing Unit, или TPU, впервые представленный публике в 2016-м. Позже Nvidia представила V100 Graphics Processing Unit, описывая его, как чип, специально разработанный для обучения и использования ИИ, а также для других высокопроизводительных вычислительных нужд. Полно и иных стартапов, концентрирующихся на других типах аппаратных ускорителей.
Возможно, все они совершают грандиозную ошибку.
Такая мысль озвучена в работе, появившейся в середине марта на сайте arXiv. В ней её авторы, Бейди Чен, Тарун Медини и Аншумали Шривастава из университета Райса, доказывают, что, возможно, специальное оборудование, разрабатываемое для работы нейросетей, оптимизируется не под тот алгоритм.
Всё дело в том, что работа нейросетей обычно зависит от того, насколько быстро оборудование может выполнять умножение матриц, используемых для определения выходных параметров каждого искусственного нейтрона – его «активации» – для заданного набора входных значений. Матрицы используются потому, что каждое входное значение для нейрона умножается на соответствующий весовой параметр, а затем все они суммируются – и это умножение со сложением и есть базовая операция перемножения матриц.
Исследователи из университета Райса, как и некоторые другие учёные, поняли, что активация многих нейронов в определённом слое нейросети оказывается слишком малой, и не влияет на выходное значение, подсчитываемое последующими слоями. Поэтому, если знать, что это за нейроны, их можно просто игнорировать.
Может показаться, что единственным способом узнать, какие нейроны в слое не активируются, будет сначала произвести все операции матричного перемножения для этого слоя. Но исследователи поняли, что на самом деле можно определиться с этим более эффективным способом, если посмотреть на проблему под другим углом. «Мы подходим к этому вопросу, как к решению задачи поиска», — говорит Шривастава.
То есть, вместо того, чтобы вычислять умножения матриц и смотреть, какие нейроны активировались для заданных входных данных, можно просто посмотреть, какие это нейроны в базе данных. Преимущество такого подхода в задаче состоит в том, что можно использовать обобщённую стратегию, давно уже усовершенствованную специалистами по информатике с целью ускорения поиска данных в базе: хеширование.
Хеширование позволяет вам быстро проверить, есть ли нужное значение в таблице базы данных, без необходимости последовательно проходить каждую её строчку. Вы используете хеш, легко рассчитываемый через применение хеш-функции к нужной величине, указывающий, где это значение должно храниться в базе. Потом можно проверить только одно это место, чтобы узнать, хранится ли там это значение.
Исследователи сделали нечто подобное для подсчётов, связанных с нейросетями. Проиллюстрировать их подход поможет следующий пример:
Допустим, мы создали нейросеть, распознающую рукописный ввод цифр. Допустим, что входные данные – это серые пиксели в массиве 16х16, то есть, всего это 256 чисел. Скормим эти данные одному скрытому слою из 512 нейронов, результаты активации которых скармливаются выходному слою из 10 нейронов, по одному на каждую из возможных цифр.
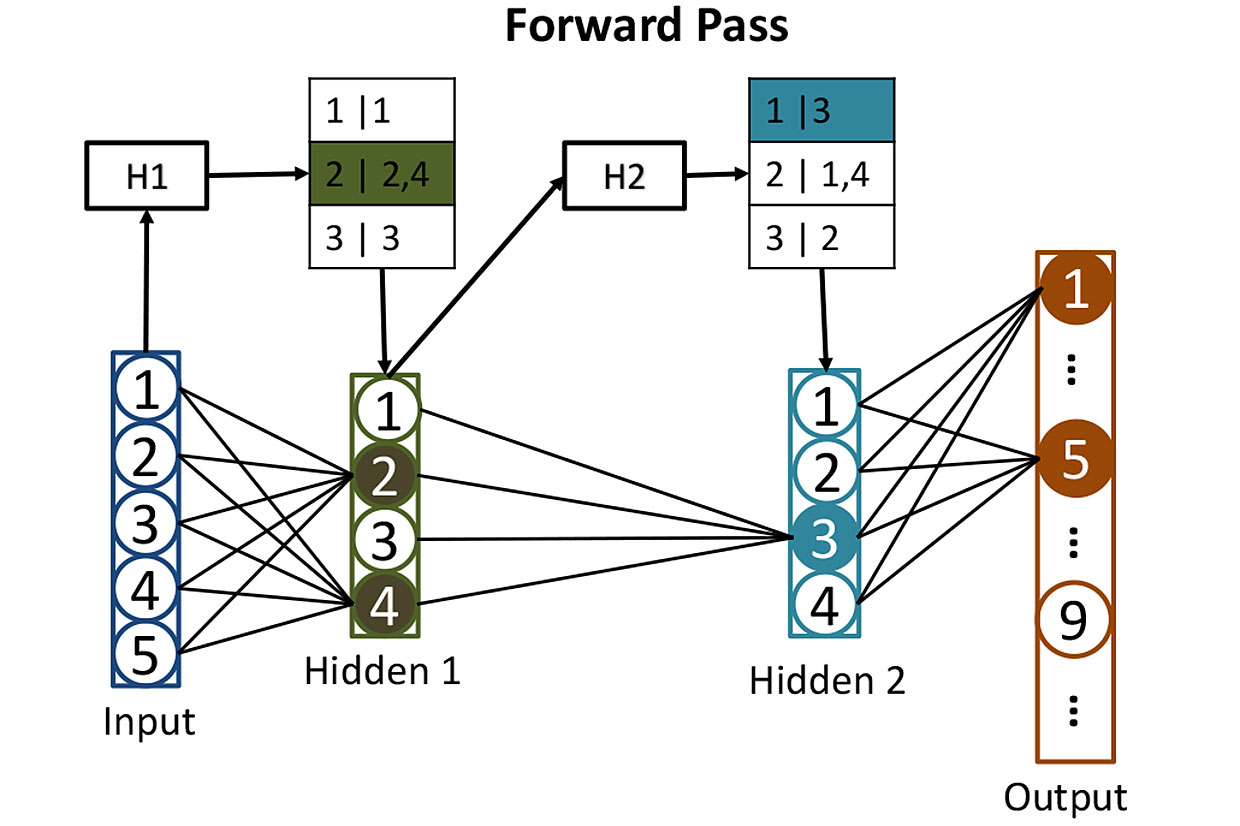
Таблицы из сетей: до расчёта активации нейронов в скрытых слоях мы используем хеши, помогающие нам определить, какие нейроны окажутся активированными. Здесь хеш входных значений H1 используется для поиска соответствующих нейронов в первом скрытом слое – в данном случае это будут нейроны 2 и 4. Второй хеш H2 показывает, какие нейроны из второго скрытого слоя внесут свой вклад. Такая стратегия уменьшает количество активаций, которые необходимо рассчитать.
Такую сеть довольно сложно тренировать, но пока что опустим этот момент, и представим, что мы уже подстроили все веса каждого из нейронов так, что нейросеть прекрасно распознаёт рукописные цифры. Когда ей на вход поступает разборчиво написанная цифра, активация одного из выходных нейронов (соответствующнго этой цифре) будет близка к 1. Активации остальных девяти будут близки к 0. Классически, работа такой неросети требует провести по одному перемножению матриц для каждого из 512 скрытых нейронов, и ещё по одной для каждого выходного – что даёт нам очень много перемножений.
Исследователи применяют иной подход. Первый шаг – хеширование весов каждого из 512 нейронов в скрытом слое при помощи «хеширования, чувствительного к расположению» [locality sensitive hashing], одно из свойств которого состоит в том, что сходные входные данные дают сходные значения хешей. Затем можно сгруппировать нейроны с похожими хешами, что будет означать, что у этих нейронов сходные наборы весов. Каждую группу можно хранить в базе данных, и определять по хешу входных значений, которые приведут к активации данной группы нейронов.
После всего этого хеширования оказывается легко определять, какие из скрытых нейронов будут активированы некими новыми входными данными. Нужно прогнать 256 входных величин через легко вычисляемые хеш-функции, и использовать результат для поиска в базе данных тех нейронов, которые будут активированы. Таким способом придётся подсчитать значения активации только для нескольких нейронов, имеющих значение. Не нужно подсчитывать активации всех остальных нейронов в слое только для того, чтобы выяснить, что они не вносят своего вклада в результат.
Подачу на вход такой нейросети данных можно представить, как выполнение поискового запроса к базе данных, который просит найти все нейроны, активировавшиеся бы при прямом подсчёте. Ответ вы получаете быстро потому, что используете для поиска хеши. А потом можно просто подсчитать активацию небольшого количества нейронов, реально имеющих значение.
Исследователи применили эту технику, названную ими SLIDE (Sub-LInear Deep learning Engine [сублинейная ситема глубокого обучения]), для обучения нейросети – для процесса, вычислительные запросы которого больше, чем у использования нейросети по назначению. Затем они сравнили быстродействие алгоритма обучения с более традиционным подходом, использующим мощный GPU – конкретно, Nvidia V100 GPU. В итоге у них получилось нечто потрясающее: «Наши результаты показывают, что на среднем CPU технология SLIDE может работать на порядки быстрее наилучшей возможной альтернативы, реализуемой на наилучшем оборудовании и с любой точностью».
Пока рановато делать выводы о том, выдержат ли эти результаты (которые ещё не оценивали эксперты) проверки и заставят ли они производителей чипов по-другому взглянуть на разработку специального оборудования для глубокого обучения. Но работа определённо подчёркивает опасность увлечения определённого типа железом в случаях, когда существует возможность появления нового и лучшего алгоритма для работы нейросетей.
Комментарии (7)

napa3um
13.04.2019 00:06Из теории информации следует, что оптимизированная описанныйм в статье способом модель тут будет эквивалентна модели, полученной путём снижения разрядности входных данных, снижения разрядности выходных данных и уменьшения количества слоёв/нейронов до соответствующей «ширины» хэш-функции. В этом же и вся идея нейросетей как раз и заключается — свести поиск тьюрингового алгоритма решения задачи в сходящийся итеративный статистический высокопаралелльный вычислительный процесс, эффективно исполняемый на определённых типах вычислителей. Т.е., исследователям нужно было решать обратную задачу — хеширование и поиск хеша реализовать в виде нейросети. Вот это бы было интереснее и полезнее. Текущий результат, описанный в статье, по-сути, является просто описанием «сжатия с потерями» нейросетки в памяти. Эдакий НейроДжпег. И мне видятся более простые и эффективные решения вопросов квантификации нейросетей, чем предложенный (даже простое снижение разрядности, как уже говорил).

VDG
14.04.2019 00:12Затем можно сгруппировать нейроны с похожими хешами, что будет означать, что у этих нейронов сходные наборы весов. Каждую группу можно хранить в базе данных, и определять по хешу входных значений, которые приведут к активации данной группы нейронов.
Осталось заменить эти группы нейронов одиночными «виртуальными», остальные выкинуть. Тогда под каждые входные данные (кластеризуемые этим хешем) будет создана своя отдельная микросеть, активируемая этими же самыми данными. По сути получаем: данные выбирают алгоритм, которым будут обработаны.
rsashka
Это будет работать только для нейронов с пороговой активацией.
И вряд ли поможет для активации ReLU или Dropuot слоя.
Daemonis
Вряд ли, там используется Locality-sensitive hashing.
rsashka
Как написано, Locality-sensitive hashing, это «хеширования, чувствительное к расположению», что бы «сходные входные данные давали сходные значения хешей».
Но каким бы хеш не был, его задача определить нейроны для которых «не нужно подсчитывать активации» (ведь именно в этом и состоит данный метод оптимизации).
Т.е. данный метод исходит из предоположения:
1. У нейронов используется пороговая активация
2. Посчитать хеш от данных проще, чем посчитать саму матрицу
leshabirukov
Вроде они именно с ReLU работают, избавляются от вычисления тех нейронов, которые уходят в заведомый минус. Не пойму, причём тут GPU — техники с разреженными матрицами на них не особо играют.