

Теперь, когда мы знаем, как работают процессоры на высоком уровне, настало время углубиться в разбор процесса проектирования их внутренних компонентов. Это вторая статья из серии, посвящённой разработке процессоров. Рекомендую изучить для начала первую часть, чтобы вы понимать изложенные ниже концепции.
Часть 1: Основы архитектуры компьютеров (архитектуры наборов команд, кэширование, конвейеры, hyperthreading)
Часть 2: Процесс проектирования ЦП (электрические схемы, транзисторы, логические элементы, синхронизация)
Часть 3: Компонование и физическое производство чипа (VLSI и изготовление кремния)
Часть 4: Современные тенденции и важные будущие направления в архитектуре компьютеров (море ускорителей, трёхмерное интегрирование, FPGA, Near Memory Computing)
Как вы возможно знаете, процессоры и большинство других цифровых устройств состоят из транзисторов. Проще всего воспринимать транзистор как управляемый переключатель с тремя контактами. Когда затвор включён, электрический ток может течь по транзистору. Когда затвор отключён, ток течь не может. Затвор похож на выключатель света в комнате, только он гораздо меньше, быстрее и может управляться электрически.
Существует два основных типа транзисторов, используемых в современных процессорах: pMOS (PМОП) и nMOS (NМОП). nMOS-транзистор пропускает ток, когда затвор (gate) заряжен или имеет высокое напряжение, а pMOS-транзистор пропускает ток, когда затвор разряжен или имеет низкое напряжение. Сочетая эти типы транзисторов комплементарным образом, мы можем создавать логические элементы КМОП (CMOS). В этой статье мы не будем подробно разбирать особенности работы транзисторов, но коснёмся этого в третьей части серии.
Логический элемент — это простое устройство, получающее входные сигналы, выполняющее какую-то операцию, и выводящее результат. Например, элемент И (AND) включает свой выходной сигнал тогда и только тогда, когда включены все входы затвора. Инвертор, или элемент НЕ (NOT) включает свой выход, если вход отключён. Можно скомбинировать эти два затвора и получить элемент И-НЕ (NAND), который включает выход, тогда и только тогда, когда не включён ни один из входов. Существуют другие элементы со своей логической функциональностью, например ИЛИ (OR), ИЛИ-НЕ (NOR), исключающее ИЛИ (XOR) и исключающее ИЛИ с инверсией (XNOR).
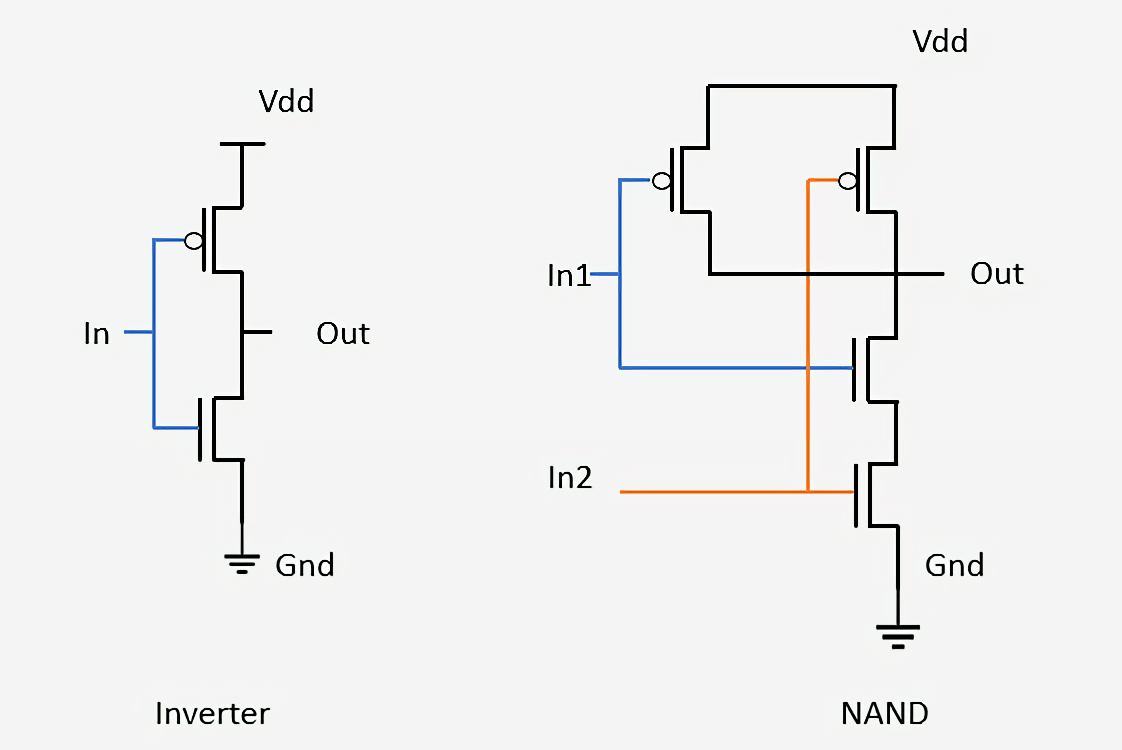
Ниже показано, как из транзисторов собраны два простых элемента: инвертор и NAND. В инверторе pMOS-транзистор (сверху) соединён с питанием, а nMOS-транзистор (снизу) соединён с заземлением. На обозначении pMOS-транзисторов есть небольшой кружок, соединённый с затвором. Мы сказали, что pMOS-устройства пропускают ток, когда вход отключен, а nMOS-устройства пропускают ток, когда вход включен, поэтому легко заметить, что сигнал на выходе (Out) будет всегда противоположным сигналу на входе (In). Взглянув на элемент NAND, мы видим, что для него требуется четыре транзистора, и что выход всегда будет отключен, если выключен хотя бы один из входов. Соединение подобным образом транзисторов для образования простых сетей — это тот же процесс, который используется для проектирования более сложных логических элементов и других схем внутри процессоров.
Строительные блоки в виде логических элементов так просты, что трудно понять, как они превращаются в функционирующий компьютер. Процесс проектирования заключается в комбинировании нескольких элементов для создания небольшого устройства, способного выполнять простую функцию. Затем можно объединить множество таких устройств, чтобы создать нечто, выполняющее более сложную функцию. Процесс комбинирования отдельных компонентов для создания работающей структуры — это именно тот процесс, который используется сегодня для создания современных чипов. Единственное отличие заключается в том, что современный чип состоит из миллиардов транзисторов.
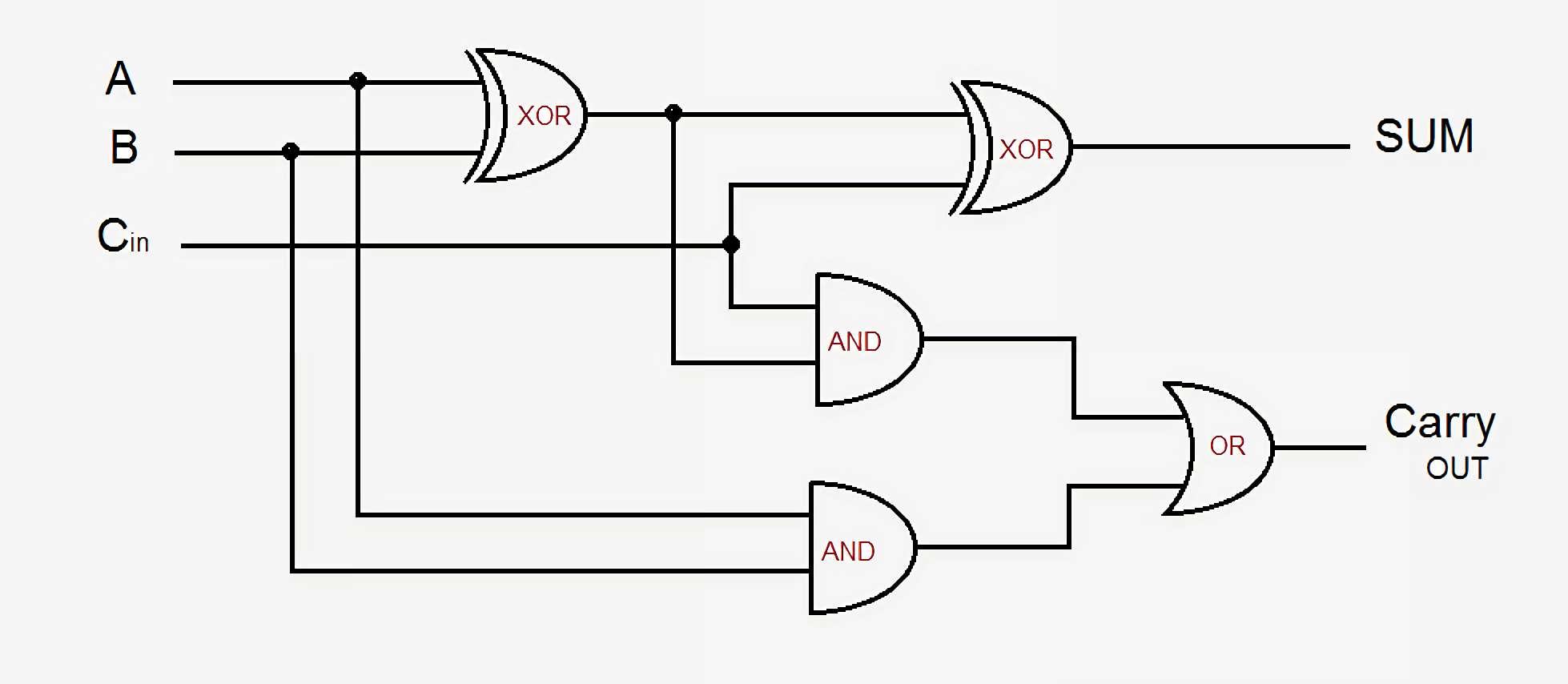
В качестве небольшого примера давайте возьмём простой сумматор — 1-битный полный сумматор. Он получает три входных сигнала — A, B, и Carry-In (входной сигнал переноса), и создаёт два выходных сигнала — Sum (сумма) и Carry-Out (выходной сигнал переноса). В простейшей схеме используется пять логических элементов, и их можно соединить вместе для создания сумматора любого размера. В современных схемах этот процесс усовершенствован оптимизацией части логики и сигналов переноса, но фундаментальные основы остаются теми же.
Выход Sum равен или A, или B, но никогда обоим, или есть входящий сигнал переноса, и тогда A и B или оба включены, или оба выключены. Выходной сигнал переноса немного сложнее. Он активен, когда или A и B включены одновременно, или есть Carry-in и один из A или B включен. Чтобы соединить несколько 1-битных сумматоров для создания более широкого сумматора, нам просто нужно соединить Carry-out предыдущего бита с Carry-in текущего бита. Чем сложнее становятся схемы, тем запутанней получается логика, но это самый простой способ сложения двух чисел. В современных процессорах используются более изощрённые сумматоры, но их схемы слишком сложны для подобного обзора. Кроме сумматоров процессоры также содержат устройства для деления, умножения и версий всех этих операций с плавающей точкой.
Подобное объединение последовательностей элементов для выполнения некой функции над входными сигналами называется комбинаторной логикой. Однако это не единственный тип логики, используемый в компьютерах. Не будет особой пользы, если мы не сможем хранить данные или отслеживать состояние. Для того, чтобы иметь возможность сохранять данные, нам нужна секвенциальная логика.
Секвенциальная логика строится аккуратным соединением инверторов и других логических элементов так, чтобы их выходы передавали сигналы обратной связи на вход элементов. Такие контуры обратной связи используются для хранения одного бита данных и называются статическим ОЗУ (Static RAM), или SRAM. Эта память называется статическим ОЗУ в противовес динамической (DRAM), потому что сохраняемые данные всегда напрямую соединены с положительным напряжением или заземлением.
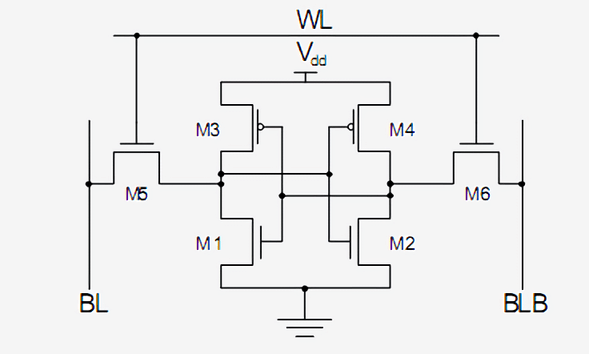
Стандартный способ реализации одного бита SRAM — это показанная ниже схема из 6 транзисторов. Самый верхний сигнал, помеченный как WL (Word Line) — это адрес, и когда он включен, то данные, хранящиеся в этой 1-битной ячейке передаются в Bit Line, помеченную как BL. Выход BLB называется Bit Line Bar; это просто инвертированное значение Bit Line. Вы должны узнать два типа транзисторов и понять, что M3 с M1, как и M4 с M2, образуют инвертор.
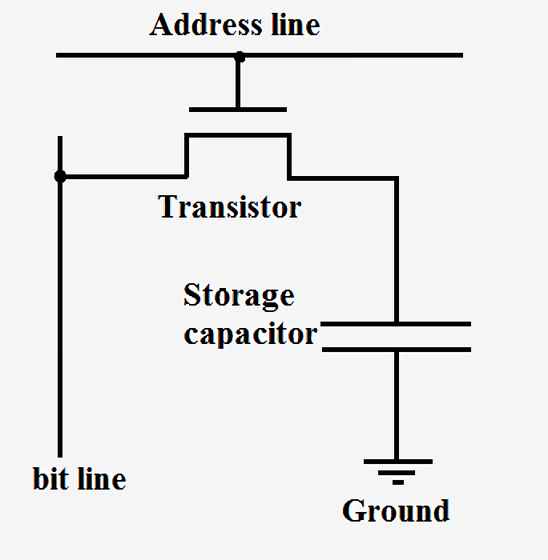
SRAM используется для построения сверхбыстрых кэшей и регистров внутри процессоров. Эта память очень стабильна, но для хранения каждого бита данных требует от шести до восьми транзисторов. Поэтому по сравнению с DRAM она чрезвычайно затратна с точки зрения стоимости, сложности и площади на чипе. С другой стороны, Dynamic RAM хранит данные в крошечном конденсаторе, а не использует логические элементы. Она называется динамической, потому что напряжение на конденсаторе может значительно изменяться, так как он не подключён к питанию или заземлению. Есть только один транзистор, используемый для доступа к хранящимся в конденсаторе данным.
Поскольку DRAM требует всего по одному транзистору на бит и очень масштабируема, её можно плотно и дёшево упаковывать. Недостаток DRAM заключается в том, что заряд конденсатора так мал, что его необходимо постоянно обновлять. Именно поэтому после отключения питания компьютера все конденсаторы разряжаются и данные в ОЗУ теряются.
Такие компании, как Intel, AMD и Nvidia, не публикуют схем работы своих процессоров, поэтому невозможно показать подобных полных электрических схем для современных процессоров. Однако этот простой сумматор позволит вам получить представление о том, что даже самые сложные части процессора можно разбить на логические и запоминающие элементы, а затем и на транзисторы.
Теперь, когда мы знаем, как производятся некоторые компоненты процессора, нам нужно разобраться, как соединить всё вместе и синхронизировать. Все ключевые компоненты процессора подключены к синхронизирующему (тактовому) сигналу (clock signal). Он попеременно имеет высокое и низкое напряжение, меняя его с заданным интервалом, называемым частотой (frequency). Логика внутри процессора обычно переключает значения и выполняет вычисления, когда синхронизирующий сигнал меняет напряжение с низкого на высокое. Синхронизируя все части, мы можем гарантировать, что данные всегда поступают в правильное время, чтобы в процессоре не возникали «глюки».
Вы могли слышать, что для повышения производительности процессора можно увеличить частоту тактовых сигналов. Это повышение производительности происходит благодаря тому, что переключение транзисторов и логики внутри процессора начинает происходить чаще, чем предусмотрено. Поскольку в секунду происходит больше циклов, то можно выполнить больше работы и процессор будет иметь повышенную производительность. Однако это справедливо до определённого предела. Современные процессоры обычно работают с частотой от 3,0 ГГц до 4,5 ГГц, и эта величина почти не изменилась за последние десять лет. Точно так же, как металлическая цепь не прочнее её самого слабого звена, процессор может работать не быстрее его самой медленной части. К концу каждого тактового цикла каждый элемент процессора должен завершить свою работу. Если какие-то части ещё её не завершили, то тактовый сигнал слишком быстрый и процессор не будет работать. Проектировщики называют эту самую медленную часть критическим путём (Critical Path) и именно он определяет максимальную частоту, с которой может работать процессор. Выше определённой частоты транзисторы просто не успевают достаточно быстро переключаться и начинают глючить или выдавать неверные выходные значения.
Повысив напряжение питания процессора, мы можем ускорить переключение транзисторов, но это тоже срабатывает до определённого предела. Если подать слишком большое напряжение, то мы рискуем сжечь процессор. Когда мы повышаем частоту или напряжение процессора, он всегда начинает излучать больше тепла и потреблять бОльшую мощность. Так происходит потому, что мощность процессора прямо пропорциональна частоте и пропорциональна квадрату напряжения. Чтобы определить энергопотребление процессора, мы рассматриваем каждый транзистор как маленький конденсатор, который нужно заряжать или разряжать при изменении его значения.
Подача питания — это настолько важная часть процессора, что в некоторых случаях до половины физических контактов на чипе может использоваться только для питания или заземления. Некоторые чипы при полной нагрузке могут потреблять больше 150 амперов, и со всем этим током нужно управляться чрезвычайно аккуратно. Для сравнения: центральный процессор генерирует больше тепла на единицу площади, чем ядерный реактор.
Тактовый сигнал в современных процессорах отнимает примерно 30-40% от его общей мощности, потому что он очень сложен и должен управлять множеством различных устройств. Для сохранения энергии большинство процессоров с низким потреблением отключает части чипа, когда они не используются. Это можно реализовать отключением тактового сигнала (этот способ называется Clock Gating) или отключением питания (Power Gating).
Тактовые сигналы создают ещё одну сложность при проектировании процессора: поскольку их частоты постоянно растут, то на работу начинают влиять законы физики. Даже несмотря на чрезвычайно высокую скорость света, она недостаточно велика для высокопроизводительных процессоров. Если подключить тактовый сигнал к одному концу чипа, то ко времени, когда сигнал достигнет другого конца, он будет рассинхронизован на значительную величину. Чтобы синхронизировать все части чипа, тактовый сигнал распределяется при помощи так называемого H-Tree. Это структура, гарантирующая, что все конечные точки находятся на совершенно одинаковом расстоянии от центра.
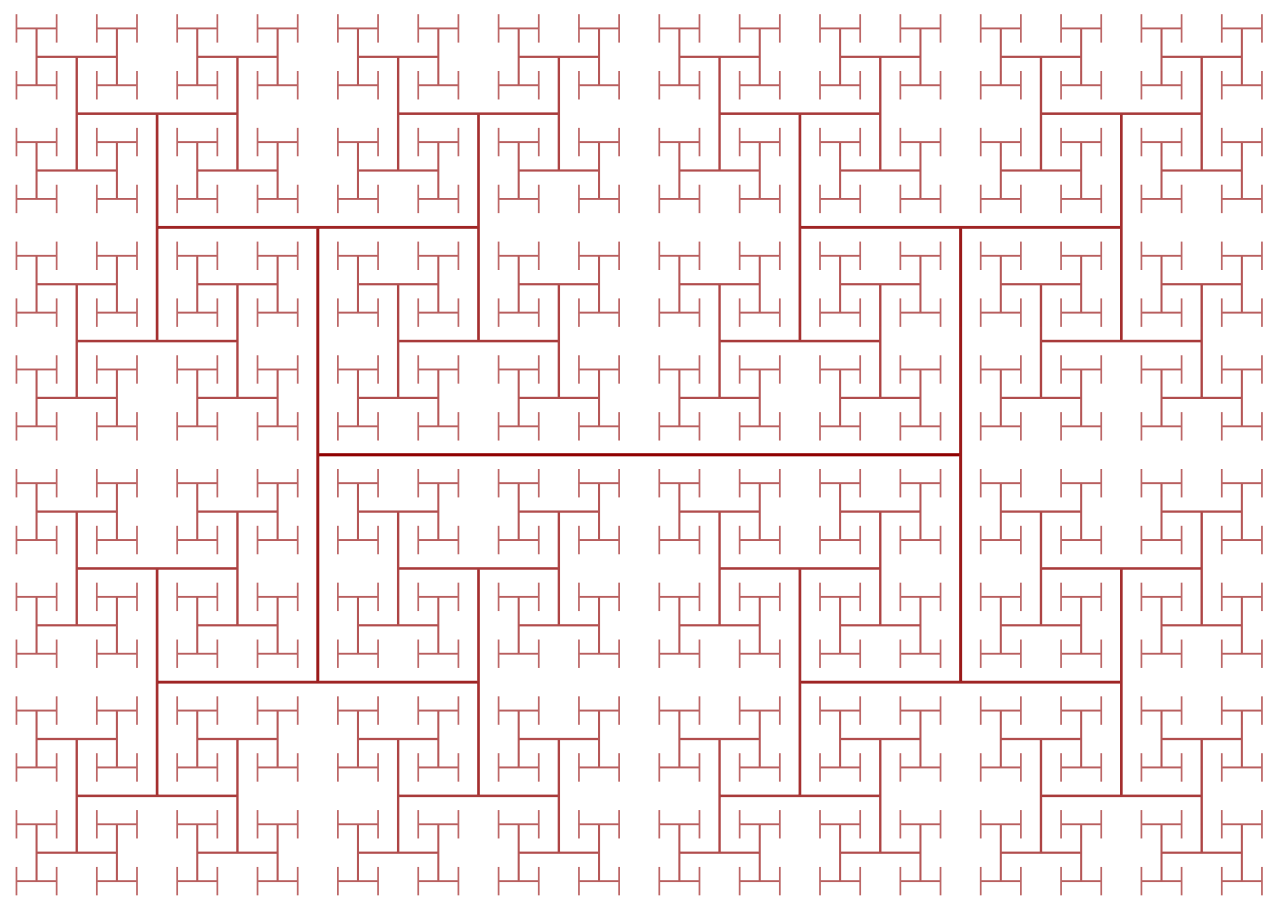
Может показаться, что проектирование каждого отдельного транзистора, тактового сигнала и контакта питания в чипе — чрезвычайно монотонная и сложная задача, и это в самом деле так. Даже несмотря на то, что в таких компаниях, как Intel, Qualcomm и AMD, работают тысячи инженеров, они не смогли бы вручную спроектировать каждый аспект чипа. Для проектирования чипов такого масштаба они используют множество сложных инструментов, автоматически генерирующих конструкции и электрические схемы. Такие инструменты обычно получают высокоуровневое описание того, что должен делать компонент, и определяют наилучшую аппаратную конфигурацию, удовлетворяющую этим требованиям. Недавно возникло направление развития под названием High Level Synthesis, которое позволяет разработчикам указывать необходимую функциональность в коде, после чего компьютеры определяют, как оптимальнее достичь её в оборудовании.
Точно так же, как вы можете описывать компьютерные программы через код, проектировщики могут описывать кодом аппаратные устройства. Такие языки, как Verilog и VHDL позволяют проектировщикам оборудования выражать функциональность любой создаваемой ими электрической схемы. После выполнения симуляций и верификации таких проектов их можно синтезировать в конкретные транзисторы, из которых будет состоять электрическая схема. Хоть этап верификации может и не кажется таким увлекательным, как проектирование нового кэша или ядра, он значительно важнее их. На каждого нанимаемого компанией инженера-проектировщика может приходиться пять или более инженеров по верификации.
Верификация нового проекта часто занимает больше времени и денег, чем создание самого чипа. Компании тратят так много времени и средств на верификацию, потому что после отправки чипа в производство его невозможно исправить. В случае ошибки в ПО можно выпустить патч, но оборудование работает иначе. Например, компания Intel обнаружила баг в модуле деления с плавающей запятой некоторых чипов Pentium, и в результате это вылилось в потери, эквивалентные современным 2 миллиардам долларов.
Сложно осмыслить то, что в одном чипе может быть несколько миллиардов транзисторов и понять, что все они делают. Если разбить чип на его отдельные внутренние компоненты, становится немного легче. Из транзисторов составляются логические элементы, логические элементы комбинируются в функциональные модули, выполняющие определённую задачу, а эти функциональные модули соединяются вместе, образуя архитектуру компьютера, которую мы обсуждали в первой части серии.
БОльшая часть работ по проектированию автоматизирована, но изложенное выше позволяет нам осознать, насколько сложен только что купленный нами новый ЦП.
Во второй части серии я рассказал о процессе проектирования ЦП. Мы обсудили транзисторы, логические элементы, подачу питания и синхронизирующих сигналов, синтез конструкции и верификацию. В третьей части мы узнаем, что требуется для физического производства чипа. Все компании любят хвастаться тем, насколько современен их процесс изготовления (Intel — 10-нанометровый, Apple и AMD — 7-нанометровый, и т.д.), но что же на самом деле означают эти числа? Об этом мы расскажем в следующей части.
Рекомендуемое чтение
Комментарии (7)

wikipro
24.06.2019 19:23- А почему в регистрах процессора не используется DRAM — там ведь данные и так постоянно перезаписываются соответственно нет необходимости восстанавливать заряд конденсаторов DRAM?
- Имеет ли смысл в регистрах / памяти ядер процессора использовать рефлективную память чтобы ядро одно ядро могло писать/читать прямо из определённого сегмента памяти другого ядра что позволяет сильно упростить межъядерные коммуникации.
nesqvic
24.06.2019 19:51-1Осмелюсь предположить, что эти вопросы следует задавать автору оригинальной статьи и на английском. Это перевод.
Brak0del
24.06.2019 20:131. DRAM нужно постоянно перезаряжать (т.е. надо какой-то контроллер, лишняя логика, лишние трассировочные линии, лишняя сложность). Регистр же не обязательно будет перезаписан так скоро, как разрядится конденсатор. Исторически DRAM (сейчас, вроде это преодолели, но сильно не проверял) требовала другой технологии изготовления, т.е. поместить вместе с логикой процессора ячейки DRAM на кристалле было технологически сложно.
2. Думаю, не имеет. Т.к. надо будет обеспечивать когерентность этого всего и будут опять предприняты все те же меры, что и для организации кэшей — т.е. сделать просто не получится. А если в процессоре ещё спекулятивное выполнение, то иногда придется отменять записи в эту рефлективную память, откатываться (или терять в скорости), в общем, сложность навернется ещё та. А чем не подходят существующие решения с общим для нескольких ядер кэшем?

vanxant
24.06.2019 21:561 — тупо медленно. Можно довольно просто показать, что с уменьшением техпроцесса уменьшается как емкость конденсатора, который хранит значение в ячейке DRAM, так и ровно настолько же — допустимый ток в дорожке (который равен произведению заряда на время). В итоге время переключения (=реальная тактовая частота DRAM) остается примерно тем же самым, что и 30 лет назад. Ну, да, за эти годы снизили напряжения раза в три (заряд есть емкость умножить на напряжение), снизили разные побочные эффекты (это еще раза 2) — вот и весь рост. Все остальное исключительно эффект массивно-параллельности. Условный intel 286 на 16-25 МГц читал-писал по 16 бит за каждые 3-4 такта. В современной DDR4 каждый чип читает параллельно сразу 8192 ячейки (бита), на планке 8 чипов, в системе 2 планки (двухканальность) — т.е. память сразу читает и пишет кусками по 131072 бита (!!!) в небольшой кэш из операционных усилителей и SRAM-защелок в каждом чипе, а потом уже отдает данные процессору из этой SRAM. Но базовая частота памяти болтается в районе 100-133 МГц, и для действительно «произвольного» доступа вам все еще нужно ждать 3 такта на этой базовой частоте 100 МГц (записать предыдущую открытую строку, открыть колонку, открыть и прочитать строку).

Mirn
25.06.2019 07:14согласен с выше перечисленными плюс хочу добавить что использовать DRAM ячейки скорее всего просто бессмысленно т.к. для регистров нужна многопортовая память, а много портовая память имеет 90% обвеса именно на сами порты записи и считывания. И поэтому становиться без разницы как именно хранится эти несколько тысяч бит. Даже если сэкономить до 10 тысяч транзисторов, то всё равно на долю обвеса потребуется пара сотен тысяч или миллионов — поэтому ВОЗМОЖНО бессмысленно совмещать два разных техпроцесса, подхода и структуры на одном кристалле.
MDreaMer
Справедливости ради, ошибку «Pentium FDIV» обнаружила не Intel, а профессор Линчбургского колледжа Томас Найсли. А они о ней знали и молчали.