
Скриншот из инструментов разработчика:
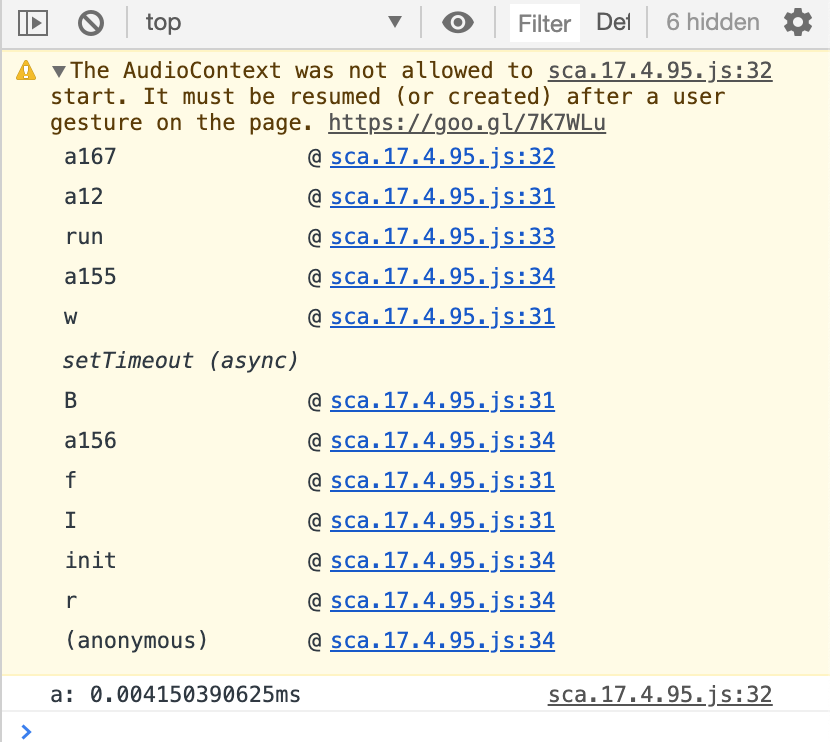
Ответ оказался интереснее, чем можно было предположить.
Сам автор внимательнее изучил трафик и разобрался, что запросы связаны со скриптом:
https://static.adsafeprotected.com/sca.17.4.95.js…и появляются только в том случае, если на странице присутствует определённый рекламный баннер, который поставляется через рекламную сеть Google AdSense.

Читатели сначала подумали, что это первоапрельская шутка. Но один из разработчиков не пожалел времени и внимательно разобрался, что конкретно делает вышеупомянутый скрипт.
Выяснилась очень интересная вещь. Оказалось, что баннер пытается использовать Audio API в качестве одного из сотен фрагментов данных, которые собирает о браузере, пытаясь осуществить его фингерпринтинг. Это нужно, чтобы однозначно идентифицировать браузер на различных сайтах, независимо от настроек конфиденциальности. Хотя браузер блокирует передачу данных конкретно по Audio API, но он не блокирует большую часть остальных данных, так что владельцы баннера успешно выполняют фингерпринтинг и, возможно, деанонимизацию пользователей.
Обнаруженная функциональность совершенно точно не нужна для работы баннера, то есть она не используется для включения или отключения каких-то интерактивных функций. Они используются только в совокупности для создания уникального «отпечатка» пользователя, который затем баннер передаёт вместе с рекламным ID при записи аналитики для рекламодателя.
Например, этот фрагмент определяет разрешение дисплея и параметры accessibility в системе:
function "==typeof matchMedia&&a239.a341.a77 ("
all and(min--moz - device - pixel - ratio: 0) and(min - resolution: .001 dpcm)
")},function(){return"
function "==typeof matchMedia&&a239.a341.a77 ("
all and(-moz - images - in -menus: 0) and(min - resolution: .001 dpcm)
")},function(){return"
function "==typeof matchMedia&&a239.a341.a77 ("
screen and(-ms - high - contrast: active) and(-webkit - min - device - pixel - ratio: 0), (-ms - high - contrast: none) and(-webkit - min - device - pixel - ratio: 0)
")},function(){return"
function "==typeof matchMedia&&a239.a341.a77 ("
screen and(-webkit - min - device - pixel - ratio: 0)
")},function(){return"Проверка наличия конкретных криптографических API:
return "function" == typeof MSCredentials && a239.a341.a66(MSCredentials)
}, function() {
return "function" == typeof MSFIDOSignature && a239.a341.a66(MSFIDOSignature)
}, function() {
return "function" == typeof MSManipulationEvent && a239.a341.a66(MSManipulationEvent)
}, function() {Получение списка установленных шрифтов:
return "object" == typeof document && a239.a341.a68("fonts", document.fonts)Определение возможностей Audio API:
return "undefined" != typeof window && "undefined" !== window.StereoPatternNode && a239.a341.a66(window.StereoPannerNode)Определение специфических API в мобильных браузерах:
return "function" == typeof AppBannerPromptResult && a239.a341.a66(AppBannerPromptResult)Проверка поддержки DRM для конкретной платформы.
}, function() {
return !!a239.a341.a72() && a239.a341.a66(a239.a341.a72().webkitGenerateKeyRequest) && a239.a341.a66(a239.a341.a72().webkitCancelKeyRequest) && a239.a341.a66(a239.a341.a72().webkitSetMediaKeys) && a239.a341.a66(a239.a341.a72().webkitAddKey)
}, function() {И сотни других параметров, которые в совокупности составляют уникальный «портрет» браузера. Ему присваивается уникальный ID, который потом используется для отслеживания действий пользователя в интернете.
Похоже, методы фингерпринтинга уже вышли из разряда «тёмных практик» и открыто применяются крупнейшими рекламодателями и рекламными сетями. Защититься от такого сканирования системы помогает блокировщик рекламы.
В такой ситуации блокировка рекламы становится не просто удобной опцией, а обязательным требованием для нормальной работы в интернете. Это минимальное, но не достаточное требование для защиты от трекинга.
Об использовании рекламодателями фингерпринтинга давно предупреждал Фонд электронных рубежей. На их сайте работает инструмент Panopticlick, который эмулирует действия враждебного трекера и определяет, насколько уникален отпечаток вашего браузера.
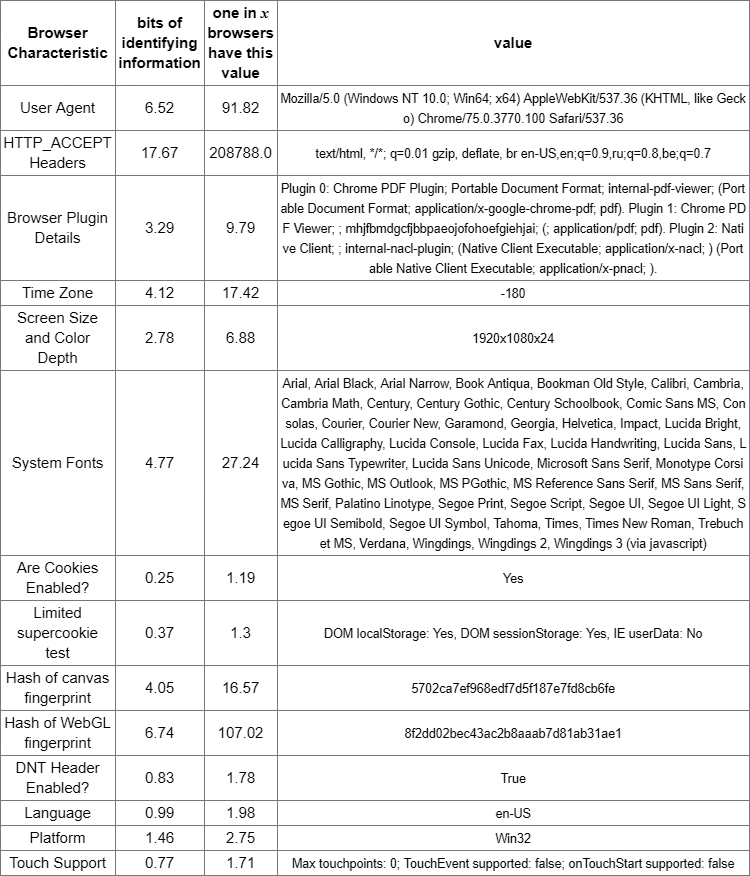
Например, таблица вверху соответствует реальным результатам сканирования браузера с выявлением 17,67 бит идентифицирующей информации. Это уникальный отпечаток среди всех 208 788 пользователей, которые проходили тестирование на сайте за последние 45 дней.
И это десктопный браузер, а на мобильном устройстве фингерпринтинг ещё проще, потому что скрипты сканируют данные с сенсоров телефона. Такие скрипты обнаружены на многих крупных сайтах в интернете. Сканирование сенсоров помогает блокировать ботов, а также используется для трекинга и аналитики.
Представители Stack Overflow сказали, что они в курсе проблемы. Им не нравится такая ситуация и они думают, как с ней бороться. Но факт в том, что баннеры с трекингом могут встретиться вам абсолютно на любом сайте.

Комментарии (65)

Gurturok
28.06.2019 11:18+1Эх, прошли те времена когда бровсер принимал набор мешанины из полезной информации и html тегов и превращал это все в читаемый вид. Теперь бровсер — это черная дыра для слива данных, ну вот зачем он передает сайтам: размер окна, установленные шрифты, статус воспроизведения медиа, движения мыши и пр.? И ведь нет ни одного современного (links и lynx для современного web слабо подходят), которы не сливают все это или позволяют однозначно отключить.

user_man
28.06.2019 11:23Шрифты нужны для управления ими — в одном месте один шрифт, в другом — более подходящий, при этом нужно знать, а установлен ли в системе нужный шрифт.
Размер окна крайне необходим. С его помощью можно подгонять размеры визуальных элементов, что бы они не вылазили за границы окна.
Воспроизведение звуков важно тем, кто слушает всяческие трансляции в браузере, ну а трансляторам нужно знать, какие форматы поддерживаются, не возникла ли ошибка при воспроизведении и т.д.
Движения мыши дают анимированный отклик браузера, что может выглядеть приятно (если не гадить, как это принято в среде разработчиков-идиотов).
A114n
28.06.2019 11:52+1Вопрос «зачем» был риторическим, понятно что у всего этого есть причины, но эти причины сами по себе сомнительного свойства.
Куда интереснее вопрос о том, почему никто до сих пор не создал браузер, который ничего этого не передаёт или передаёт это в каком-то «стандартном виде», а все страницы форматирует под голый текст, «режим чтения».
Не сказал бы, что это бесполезная задача — многие люди пользовались бы таким браузером, раз уж они постоянно пытаются запретить отслеживание и заблокировать банеры.
Не сказал бы, что это бесплатная задача — многие люди платят за протонмайл или даже за блокировщики рекламы.
Неужели эта задача настолько сложна?user_man
28.06.2019 12:35>> Неужели эта задача настолько сложна?
Просто нереальна.
Стоимость разработки приличного браузера, то есть поддерживающего кучу самых разных и довольно толстых стандартов, очень высока. Без поддержки кучи толстых стандартов вы получите этакий MS-блокнот, который покажет лишь жалкие проценты от содержимого сайта, да то — в сильно искажённом виде. Например нужна полноценная поддержка скриптов, которыми очень часто формируется содержимое сайта. Но такая поддержка сразу включает все те шрифты, размеры окон и т.д. и т.п. Без скриптов вы просто не увидите содержимое, а если вырезать «по умолчанию» какие-то фичи, то огромное количество юзеров не будет пользоваться браузером, просто потому, что именно вырезанные фичи им очень нужны. Поэтому нужна гибкая настройка всего и вся, что ещё больше удорожает стоимость разработки. В целом получаем дорогое удовольствие для аудитории, ну скажем в 100 000 человек на всей земле. Ну и представьте теперь затраты на рекламу, которая отфильтрует эти сто тысяч среди миллиардов пофигистов. Эти затраты так же нужно добавить к стоимости браузера.
В итоге получится очень приличная сумма и… И что даст этот браузер его разработчику? Исключительно лишь моральное удовольствие?
В общем всё просто — в мире, где правят деньги, не стоит задавать вопросы о чём-то бесплатном (и даже просто доступном) и при этом ещё и качественном.testdrive
01.07.2019 09:40Почему бы не передавать стандартное разрешение, стандартный список шрифтов Windows?
roscomtheend
01.07.2019 15:02"А почему у меня сайт не влезает/показывает только в углу и текст разъезжается?"
DerRotBaron
28.06.2019 16:52Для работы с основным контентом сайта эта задача решается элементарно.
В современных Firefox (особенно с патчами Tor Browser) это решается сравнительно несложно. Необходимо только вынести код вывода режима чтения наружу и не применять к нему ограничения по разрешению.
А вот со всяким сопутствующим контентом проблема. Отваливаются поиски, отваливаются комментарии, карты, интерактивности и всё такое. И происходит это потому, что каждый сам велосипедировал всё это на различных фреймворках из чего только можно без малейших попыток стандартизации хотя бы даже того, как это будет в итоге рендериться. Где-то из-за непонимания того, как это работает, где-то из желания сделать всё "удобным" (чего стоит переопределение ctrl+f на одном из форумных движков), а где-то чтобы запихнуть побольше рекламы или осложнить автоматизированное копирование "сверхценного контента"
alsoijw
28.06.2019 22:44Куда интереснее вопрос о том, почему никто до сих пор не создал браузер, который ничего этого не передаёт или передаёт это в каком-то «стандартном виде», а все страницы форматирует под голый текст, «режим чтения».
Неужели эта задача настолько сложна?
Эта задача прямо противоречит целям современного браузера. Современный браузер в первую очередь является платформой для выполнения онлайн приложений, в то время как относительно удобный анонимная работа возможена только через специального клиента, резлизующего, например отправку комментариев или же загрузку частей карты Земли. Задачу можно решить, если кто-то создаст клиент для каждого сайта, используюя то же api что и веб версия. Сайты периодически переписывают, как следствие на это время клиенты будут отваливаться.
Впрочем, если интересует только чтение, то можно найти сервис для создания скриншотов сайтов, набросать простой скрипт, который будет получать картинку и читать сайт словно бумажную книгу, забыв про гиперссылки, анимацию и прочие возможноси.
konchok
29.06.2019 09:42Надо не запрещать отдавать эти данные (всё поломается), а замешивать их с рандомом. Ну там размер окна плюс-минус пару пикселей, шрифтов добавить несуществующих итд.
alsoijw
29.06.2019 12:44Против пары тройки пикселей сработает элементарное округление. С несуществующими шрифтами сайт расползётся(если к примеру есть ascii арт). Логичнее уж стандартизировать — на каждой машине есть эти шрифты и никаких других. Разумеется это должны быть только свободные шрифты
konchok
29.06.2019 13:08Шрифтов добавить свободных, но несуществующих в природе. Чем больще им придётся всего «округлять», тем сложнее идентифицировать конкретного пользователя.
alsoijw
29.06.2019 17:38До тех пор, пока этим не станут пользоваться большинство такое округление лишь уточнит человека
konchok
29.06.2019 17:45У вас чёт с логикой. Если каждый раз браузер выдаёт немного разные данные, то хоть там обокругляйся, однозначно понять что это один и тот же юзер будет куда сложнее чем когда данные всегда одни и те же.
alsoijw
29.06.2019 19:03Важна уникальность данных. Несуществующие шрифты — уникальная вещь. Разумеется её надо добавлять рядом с уже существующими отпечатками.
konchok
29.06.2019 19:17Это просто пример, смысл чтобы реальные данные разбавлялись нереальными, но не до такой степени чтобы от этого поплыл рендер страницы. Что-то уже есть в виде плагинов — модификация User-Agent, часового пояса, списка расширений итд. Сайтам всё равно у тебя Mozilla 64.5 или 65.4 — всё будет работать, также и время MSK, EEST или UTC+3 равнозначны. Со шрифтами и остальным решается аналогично.
alsoijw
29.06.2019 21:53модификация User-Agent
Обнаружить ложный юзерагент возможно. Я не знаю, делают ли это скрипты аналитики, но в ввиду различия количества реализованых api в зависимости от браузера и операционной системы, например различия цвета фона в зависимости от браузерного движка
В некоторых браузерах (Chrome) пример выше покажет iframe зелёным. А в некоторых (Firefox) – оранжевым.
Сайтам всё равно у тебя Mozilla 64.5 или 65.4
некоторые сайты определяют версию чуть ли не по юзерагенту и в случае чего будут отправлять обновить браузер. Так что можно действовать только в сторону повышения. Разумеется обнаружить подмену всё так же возможно.
Со шрифтами и остальным решается аналогично.
Это уже реализовано?konchok
30.06.2019 08:44Они на каждой странице будут тестить все API на соответствия версиям Мозиллы? И даже если там будут расхождения то как это поможет отследить пользователя? В следующий раз у него будет версия браузера +0.1, размер окна -2 пиксела, другой список шрифтов и время на 10 секунд меньше. Желаю успехов этой аналитеге.
alsoijw
30.06.2019 11:02Веб страницы знают не только размер окна, но и разрешение экрана.
konchok
30.06.2019 11:04Да, мы здесь обсуждаем именно эту проблему. С добрым утром.
alsoijw
30.06.2019 11:39Вы предлагаете каждый раз давать новое разрешение? Разрешений экрана не так уж и много и округлением можно легко отбросить эти ваши пару пикселей. 1360*780 гораздо больше похоже на 1366*786, чем на 1920*1080.
Проверить есть ли шрифт в системе элементарно — достаточно попытаться им что-то нарисовать. Если шрифта нет, то будет использован шрифт по умолчанию.
Веб аналитика вполне может и запускаться на каждой странице, не знаю что так удивляет.konchok
30.06.2019 11:56Разрешений монитора по пальцам можно посчитать, ничего уникального там нет. А вот размер окна зависит от DPI и размера элементов интерфейса, что куда более уникально и при этом часто не меняется. Предполагается что окно развернуто на весь экран у большинства пользователей.
Если шрифта нет, то будет использован шрифт по умолчанию.
Как скрипты аналитики узнают каким шрифтом по итогами всё было отрисовано на экране пользователя? Думаю что никак.alsoijw
30.06.2019 13:17Разрешений монитора по пальцам можно посчитать, ничего уникального там нет.
Если не менять разрешение экрана, то это достаточно надёжно будет отсекать людей. Если у меня вчера был 1366*786, сегодня 1366*786, то скорее всего и завтра будет 1366*786.
Как скрипты аналитики узнают каким шрифтом по итогами всё было отрисовано на экране пользователя?
Рендерим каждым шрифтом по картинке, считаем хеш. Если хеши совпадают, то шрифт один и тот же. Для того чтобы определить шрифт по умолчанию, нужно сгенерировать несуществующее название шрифта. С каким хешем совпадёт, тот шрифт и является дефолтным.
У каждого шрифта своя форма. Дальше уже зависит от фантазии — обучать нейросеть, включать в скрипт эталонные картиннки или что-то ещё. Картинки можно включать в векторном формате, тогда они не сильно утяжелят скрипт.konchok
30.06.2019 13:35Рендерим каждым шрифтом по картинке
Никто эти не будет заниматься потому что защита элементарна и ничего клиенту не стоит — достаточно браузеру отдать не 20 шрифтов а 200 и все эти нейросети подавятся. Но возможно ещё до этого браузер прибьёт этот скрипт за пожирание CPU непонятно чем.
alsoijw
30.06.2019 17:54Почему нейросеть подавится от 200 шрифтов? И почему браузер должен прибивать этот скрипт? Это же не майнер.
konchok
30.06.2019 19:37Не подавится на двести, дадут ей такое число, на котором она подавится. Вы суть вообще не улавливаете.
alsoijw
30.06.2019 21:53Отлично, теперь вы дали уникальный признак, как себя вычислить — ШРИФТОВ БЕСКОНЕЧНЫЙ КРАЙ.
Бороться со скриптами аналитики нужно не попытками сделать ЧТО-ТО, равзе что-то сделать, а делать обдуманные вещи.konchok
01.07.2019 03:23Ставишь Ghostery — и никаких скриптов аналитики. А шрифтов должно быть плюс-минус рандом /как и других параметров/, о чём я написал вначале.
isden
01.07.2019 08:20Ghostery лучше не ставить. А если поставили — то снести и забыть. Есть инфа, что они собирают и продают данные пользователей.
Лучше и эффективнее что-то вроде ublock origin + privacy badger.
mikserok
01.07.2019 09:42Так ведь есть платные браузеры которые подменяют браузерные отпечатки или просто отключат их (иногда с потерей функционала сайта). Применяют их главным образом для мультиаккантах в соцсетях. Я могу назвать как минимум 3 разных: swSpyBrowser, multiloginapp (или его клон Indigo browser ), Linken Sphere.
thevladmartin
28.06.2019 13:06Если я правильно понял, вы оправдываете рекламодателей.
А для чего им нужны специфические API мобильных браузеров?
Я могу понять сканирование некоторых определённых параметров, которые позволяют определить принадлежность пользователя к определённой группе — например, виндоюзеров с разрешением 1920х1080 с поддержкой всех базовых шрифтов — это не поможет идентифицировать пользователя, однако сбор практически всех возможных параметров… тут уж, простите, даже если очень постараться — «необходимость» за уши не притянешь.
Почему нельзя уведомлять пользователя о том, какие данные о нём собираются и в каких целях? Почему люди должны «выкапывать» эти скрипты, чтобы понять, что они делают?alsoijw
28.06.2019 22:56+2Если я правильно понял, вы оправдываете рекламодателей.
Код написанный со злым умыслом выглядит точно так же, как и код написанный с добрым умыслом, и сам по себе интерпретатор не отличит один от другого.
Почему нельзя уведомлять пользователя о том, какие данные о нём собираются и в каких целях?
Уведомлять возможно, основной вопрос лишь в том, что пользователь будет делать со всем этим. Во-первых предупреждение на большинстве страниц быстро начнут утомлять, практические ничего не давая. Во-вторых, возможно что страницы будут ломаться, если реклама не отображается/отпечаток не получен.
konchok
30.06.2019 09:04Чтоб не выкапывать ставится какой-нибудь Ghostery и эти скрипты идут лесом. И да, на мобильных браузерах (Мозилле по крайней мере) есть все эти расширения.
equand
28.06.2019 19:34Размер окна на самом деле не нужен. Нужен размер viewport… Вся проблема из-за того что делали «странички» онлайн, а не «программы». Отсюда и вся дребедень.
Я как-то хотел написать обработчик программ на .NET, где происходила загрузка по HTTP XML файла с дефинициями форм, а c# бы тогда их собирал и отображал в программе, забросил.
Taraflex
28.06.2019 23:06Чем не подошла загрузка xaml, которая есть из коробки?
blogs.msdn.microsoft.com/ashish/2007/08/14/dynamically-loading-xamlequand
29.06.2019 09:18Тем, что там нет программной части, только отображение.
Поэтому надо было разработать XML с for loop, обработчиком ошибок, отправкой запросов по HTTP и т.п.
user_man
28.06.2019 11:19+1Нужен браузер, позволяющий гибко настраивать работу скриптов. Либо в адблокере самостоятельно выделять вражеские домены и отдельно скрипты с приемлемых доменов.
Хотя конторы уровня гуглов наверняка уже перешли на очень простое решение — закрытые договорённости с интернет-провайдерами о доступе к сервису получения идентификатора юзера по ай-пи и времени выхода в сеть.SakuradaJun
28.06.2019 12:57Скрипты — вообще больная тема сегодня, с точки зрения быстродействия.
Бесполезно искать «легкий браузер» для слабой машины, если сами страницы перегружены активными элементами. И если бы это была только реклама и разные счетчики-метрики, то можно было бы просто отключить javascript, но основной функционал все чаще работает на нем, и при отключении просто не отображается содержимое страницы, не работают кнопки, формы и т.д.
10 лет назад можно было отключить javascript, и все работало.


dom1n1k
28.06.2019 12:07+1Pydeg
28.06.2019 21:53+2Ну а теперь представьте, что все поступают так, как вы предлагаете. Станет ли от этого интернет лучше? Большинство сайтов, которые финансируется за счет контекстной рекламы, или просто исчезнут, или закроются пейволами (и станут недоступными большинству людей), или превратятся в помойки с нетаргетированной рекламой, которые будут компенсировать низкую её эффективность количеством (как это сейчас делают сайты, которые не берут в тот же адсенс)
MTyrz
28.06.2019 22:05+1Большинство сайтов, которые финансируется за счет контекстной рекламы, или просто исчезнут
Большинству сайтов, которые финансируются за счет контекстной рекламы, туда и дорога.
UPD. С их исчезновением интернет определенно станет лучше.
alsoijw
28.06.2019 23:11+3Кликбейтные заголовки вместе с рекламными статьями исчезнут, что хорошо.
Люди пишущие, чтобы донести свои мысли продолжать делиться своим мнением/своими знаниями.
Заработок за счёт рекламы придётся заменить на сбор средств на спонсирование, так что сочинять музыку, рисовать картины и так далее всё ещё можно будет. Как и сейчас всё это будет связанно с известностью.
Контент придётся хостить либо за свой счёт, либо раздавать его подобно торренту, что благоприятно скажется на отказоустойчивости и защитит от цензуры. Текст мало того что мало весит, так ещё и отлично сжимается. Вместо длинных роликов в которых докладчик подбирает слова, поскольку пишет ролик без сценария, выполнения каких-то рутинных операций(например набора кода), пустой болтовни люди будут мотивированных писать статьи. Разумеется видео тоже можно будет смотреть, но люди не захотят хранить у себя всякий мусор.
vikarti
29.06.2019 08:24Ничего не мешает гуглу нормально реализовать Google Contributor или кому то еще сделать аналог, после чего сайты будут получать финансирование по прежнему. По сути идея что вместо показа рекламы сайту просто капает денежка.
Да, это означает что у гугла будет список посещенных сайтов и карточка пользователя — но они и так есть.
Если же модель взлетит реально — вполне можно сделать аналогичные сети с пополнением баланса хоть биткоинами.
Единственное — возможно придется как то сделать возможность для сайта идентифицировать — за этого пользователя вообще оплата ожидается или нет?
Подделывать посещаемость? Так а зачем? Если деньги будут и так.

digger3d
28.06.2019 12:13+1Microsoft договорился c Google о предоставлении фингерпринтов? Канделябром!
robert_ayrapetyan
28.06.2019 17:02Всей этой истории сто лет, только раньше это не работало с мобильниками (за отсутствием кастомных шрифтов, да и вообще они все клоны почти), а сейчас прям с мобильных легче отпечаток снять — это правда?
DerRotBaron
28.06.2019 18:15Любой фингерпринтинг, основанный на особенностях железа должен работать. Разве что с айфонами сложнее, хотя и там тоже зоопарк моделей порядочный уже

Vilgelm
29.06.2019 19:24Вы можете зайти куда-нибудь сюда и проверить самостоятельно что с вашего устройства можно снять, а что нет. А потом попытаться как-то заставить браузер не разбалтывать это все (спойлер: на компьютере это частично можно прикрыть расширениями, а на мобилке никак). Да, кстати, виртуальные машины не помогут, потому что значение такого параметра как canvas будет одинаковым для хоста и геста (а это только лишь один из параметров).

Teomit
01.07.2019 10:25Для canvas проблема также может решаться расширением, например для FF: Canvas Blocker.
Полагаю, что лучше не блокировать данные, которые можно снять с браузера, а отдавать одинаковые для всех либо фейковые.

peacemakerv
29.06.2019 15:01Кто пробовал браузер Brave? Не является ли он первым приближением к браузеру, где можно защититься от этой глобальной слежки? Или тоже заявляют одно, а по сути — тоже самое?

arilou_camper
29.06.2019 16:35Я вам скажу так. Brave очень много и громко заявляет о том, как ужасны рекламные технологии, и как они крадут персональные данные у ничего не подозревающих обывателей. Они оседлали волну GDPR-истерии и регулярно набрасывают на вентилятор.
А теперь задумайтесь на минуту. Сколько бизнес-моделей вы можете вспомнить для компании-разработчика браузера?
Ну, собственно, вот: brave.com/brave-ads-waitlist
Если не можешь победить — возглавь. Только кишка у них сильно тонкая для того, чтобы сражаться с 300-миллиардной индустрией.
ionsphere
29.06.2019 17:11А какая бизнес-модель у Firefox Focus? Они блокируют: ad trackers (трекеры посещений), analytics trackers (нажатия и скроллы), social trackers (кнопки лайков и любые другие элементы соцсетей), и выключенные по умолчанию любые другие трекеры. Плюсом можно заблокировать Web-шрифты.
arilou_camper
29.06.2019 17:27Ну вообще, Mozilla — non-profit org, насколько я помню. Поэтому это оплачивается всё деньгами корпораций.
alsoijw
29.06.2019 22:08Не является ли он первым приближением к браузеру, где можно защититься от этой глобальной слежки?
Для этого им должно как минимум хватить сил поддерживать declarativeNetRequest, как и остальные фичи. Однако это не делает его менее следящим, чем например firefox. Хотя я сомневаюсь, что у них достаточно сил для уничтожения всех гугловских блобов.

bano-notit
29.06.2019 16:33Чувствую, что скоро надо будет делать браузеры, где доступ почти ко всем api надо будет делать через разрешение пользователя, как например запрашивают geo координаты или разрешение на уведомления.
Teomit
01.07.2019 09:55Тогда будет ситуация как с мобильными приложениями: некоторые отказываются работать, если нет необходимого разрешения. Правильнее будет отдавать фиктивные или одинаковые для всех данные.
bano-notit
01.07.2019 15:12Ну нужно просто понимать, какие разрешения нужны приложению, а какие нет. Если галерея отказывается работать, если я не дам ей список моих контактов, то пошла эта галерея подальше.
Можно конечно сказать "я не программист, чтобы знать, что приложению нужно", но мы живём в таком веке, в котором уже надо бы начинать интересоваться этой темой.
codecity
Это в ответ на закон о cookies?
arilou_camper
GDPR — это не только про cookies. GDPR запрещает и fingerprinting. То есть, требования закона обойти с его помощью не получится.
Это скорее способ сделать «persistent cookie» для того, чтобы строить анонимный поведенческий онлайн-профиль и таргетировать на его основе рекламу. Сам по себе он не позволит увязать ваше мобильное устройство и десктопный комп.
Cenzo
«присутствует определённый рекламный баннер, который поставляется через рекламную сеть Google AdSense» <-> «Сам по себе он не позволит увязать ваше мобильное устройство и десктопный комп.»
Кому как, гугл точно свяжет)
arilou_camper
Гуглу это нафиг не сдалось, у него есть андроид, хром, гмыло, карты, и много всего остального. Он и так все про вас знает. Очевидно скрипт поставляется через партнёра, что, возможно, нарушает TOS AdSense.